음성 인식에서 전화(Phone) 우도 캘리브레이션 연구
본 논문은 Kaldi DNN 기반 음성 인식 시스템에서 프레임 수준의 posterior를 전화 수준의 likelihood로 변환하고, 강제 정렬된 테스트 데이터를 이용해 다중 클래스 교차 엔트로피(H_mc)를 캘리브레이션 민감도 지표로 평가한다. 프레임 로그우도를 합산, 평균, 평균에 로그 지속시간을 곱하는 세 가지 결합 방식을 비교한 결과, 평균 방식이 자연스럽게 잘 캘리브레이션되며, 평균·로그 지속시간 방식은 약간의 추가 스케일링을 통해 더…
저자: David A. van Leeuwen, Joost van Doremalen
본 논문은 딥 뉴럴 네트워크(DNN)를 이용한 음성 인식 시스템에서 발생하는 전화(phone) 수준의 확률값이 얼마나 잘 캘리브레이션(보정)되어 있는지를 정량적으로 평가한다. Kaldi 툴킷의 표준 레시피를 사용해 WSJ 데이터베이스(WSJ0, WSJ1)로 학습한 DNN은 ‘pdf‑id’라는 HMM 상태별 공유 Gaussian를 목표로 하며, 각 프레임에 대해 pdf‑id posterior p(i|x)를 출력한다. 저자들은 이러한 pdf‑id posterior를 전화별 posterior p(f|x)로 집계하고, 사전 확률 p(i)와 결합해 로그우도 λ_f(x)=log p(f|x)/p(i)+const를 계산한다(식 5‑6).
핵심 연구 질문은 “프레임 수준의 로그우도를 어떻게 결합하면 전화 수준의 로그우도가 자연스럽게 캘리브레이션될까?”이다. 이를 위해 세 가지 결합 방식을 실험한다. 1) 프레임 로그우도의 단순 합계(P_t λ_t) – 전통적인 ASR 디코딩에서 사용되는 방식으로, 프레임 독립성을 가정한다. 2) 프레임 로그우도의 평균(P_t λ_t / n) – 프레임 간 상관관계를 완전하게 고려해 평균화함으로써 노이즈를 감소시킨다. 3) 평균에 로그 지속시간을 곱한 형태(P_t λ_t · log n) – 전화가 길수록 더 많은 증거가 축적된다는 직관을 반영한다.
캘리브레이션 평가는 다중 클래스 교차 엔트로피(H_mc)와 그 최소값(H_min_mc)을 사용한다. H_mc는 실제 정답 전화에 대한 로그 posterior의 평균 손실이며, 과신·과소신에 민감한 proper scoring rule이다. H_min_mc는 affine 변환 λ' = α λ + β(식 4)를 적용해 최적의 스케일링 α와 오프셋 β를 찾음으로써 얻는다. 실험 결과는 다음과 같다.
- **합계 방식(P_t λ_t)**: H_mc가 크게 높고, H_min_mc와의 차이가 크다(예: eval’92에서 H_mc=1.081, H_min_mc=0.260). 최적 α≈0.16으로, 이는 전통적인 acoustic scaling factor(≈1/6)와 유사하다. 즉, 프레임 독립성 가정이 잘못돼 전체 로그우도가 과대평가됨을 의미한다.
- **평균 방식(P_t λ_t / n)**: H_mc와 H_min_mc가 거의 일치(예: eval’92에서 H_mc=0.261, H_min_mc=0.232)하고, 최적 α≈1에 가까워 추가 스케일링이 거의 필요하지 않다. 이는 프레임 간 상관관계를 고려한 평균화가 자연스럽게 캘리브레이션을 맞춘다는 것을 보여준다.
- **평균·로그 지속시간 방식(P_t λ_t · log n)**: 초기 캘리브레이션이 다소 떨어지지만(H_mc=0.309, H_min_mc=0.226), 최적 α≈0.586으로 스케일링을 적용하면 가장 낮은 H_min_mc를 달성한다. 이는 전화 길이가 길수록 더 많은 정보가 축적된다는 가정을 반영했을 때, 적절한 스케일링을 통해 성능을 끌어올릴 수 있음을 시사한다.
또한, 한 테스트 셋에서 학습한 캘리브레이션 파라미터(α,β)를 다른 셋에 그대로 적용했을 때도 H_mc가 개선되는 것을 확인했다(표 2). 이는 파라미터가 동일한 도메인 내에서 어느 정도 일반화 가능함을 의미한다. 반면, 강제 정렬을 의도적으로 잘못된 전사와 결합하면 H_mc가 급격히 상승하고, 캘리브레이션 후에도 높은 값이 유지돼 H_mc가 단순히 “자기 충족”이 아님을 입증했다.
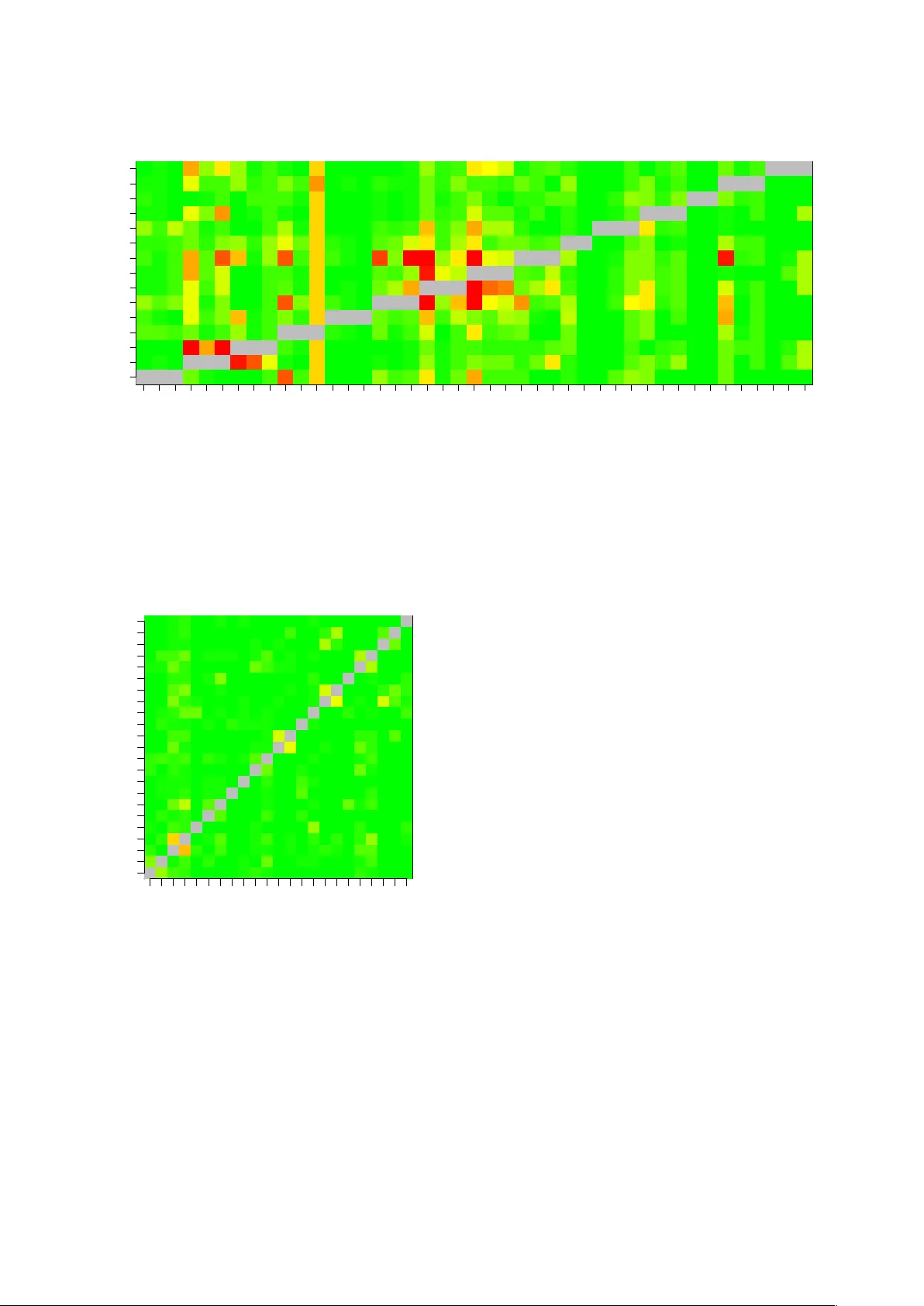
마지막으로, 전화별 혼동 행렬을 EER(동등 오류율) 기준으로 시각화했다. 모음의 경우 스트레스가 없는 형태가 스트레스가 있는 형태보다 구분이 어려운 경향을 보였으며, 이는 Kaldi의 pdf‑id가 스트레스 정보를 공유하기 때문에 발생한다. 자음 혼동 행렬도 제공해 모델이 어떤 자음 쌍을 혼동하는지 직관적으로 파악할 수 있다.
결론적으로, DNN이 프레임 수준에서 cross‑entropy 손실을 최소화하도록 학습되었기 때문에 프레임 posterior는 기본적으로 잘 캘리브레이션된다. 전화 수준으로 확장할 때는 프레임 로그우도를 어떻게 결합하느냐가 핵심이며, 평균 방식이 가장 자연스러운 캘리브레이션을 제공한다. 평균·로그 지속시간 방식은 추가 스케일링을 통해 더 낮은 H_min_mc를 달성할 잠재력을 가지고 있다. 이러한 캘리브레이션 기법은 대규모 어휘 인식(LVCSR)에서의 acoustic scaling과는 다르게 전화 단위에 적용되며, 발음 변이 분석이나 특정 도메인에서의 정밀 평가에 유용할 수 있다. 향후 연구에서는 도메인 간 전이, 파라미터 정규화, 그리고 캘리브레이션에 강인한 결합 함수 설계가 필요하다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기