조건부 생성과 스냅샷 학습을 활용한 신경대화 시스템 설계
본 논문은 LSTM 기반 조건부 언어 모델을 대화 시스템에 적용하면서, 조건 벡터와 언어 모델 간의 경쟁 관계를 분석한다. 조건 벡터를 통합하는 세 가지 아키텍처(LM, 메모리, 하이브리드)와 어텐션·요약된 belief state를 비교하고, ‘스냅샷 학습’이라는 보조 교차 엔트로피 손실을 도입해 조건 벡터의 판별력과 투명성을 강화한다. 실험 결과, 스냅샷 학습은 아키텍처에 관계없이 일관된 성능 향상을 제공하며, 조건 벡터의 해석 가능성이 모델…
저자: Tsung-Hsien Wen, Milica Gasic, Nikola Mrksic
본 논문은 LSTM 기반 조건부 언어 모델을 활용한 대화 시스템의 설계와 학습 방법을 체계적으로 탐구한다. 먼저, 대화 시스템을 ‘인코더‑디코더’ 구조로 정의하고, 인코더는 사용자 의도 네트워크, belief tracker, 데이터베이스 연산자, 정책 네트워크 네 개의 서브모듈로 구성된다. 사용자 의도 네트워크는 LSTM을 이용해 입력 토큰 시퀀스를 임베딩 zₜ로 변환하고, belief tracker는 슬롯‑별 확률 분포 pₛₜ를 유지한다. DB 연산자는 belief state를 기반으로 매칭 엔티티 수를 6‑bin 원-핫 벡터 xₜ로 표현한다. 정책 네트워크는 zₜ, pₛₜ, xₜ를 선형 변환 후 tanh를 적용해 최종 조건 벡터 mₜ를 만든다.
디코더는 이 mₜ를 조건으로 받아 응답을 토큰 단위로 생성한다. 여기서 세 가지 조건부 생성 아키텍처가 제안된다. (1) LM‑type은 mₜ를 입력 임베딩 wⱼ와 이전 은닉 상태 hⱼ₋₁에 concatenate해 기존 LSTM에 그대로 투입한다. (2) 메모리‑type은 별도 읽기 게이트 rⱼ를 두어 mₜ를 셀 상태 cⱼ에 직접 더함으로써 조건 정보를 메모리와 분리한다. (3) 하이브리드‑type은 메모리‑type의 구조를 확장해 mₜ를 은닉 상태 hⱼ에 직접 더하고, 셀 상태와 은닉 상태를 완전히 분리한다. 하이브리드‑type은 조건 벡터와 언어 모델이 서로 간섭하지 않아 해석 가능성이 높고, 장기 의존성을 필요로 하지 않는다.
조건 벡터의 효율적 활용을 위해 어텐션 메커니즘과 belief state의 요약 표현을 도입한다. 어텐션은 각 슬롯 s에 대한 가중치 αⱼₛ를 현재 디코딩 단계와 슬롯 상태, 입력 토큰, 은닉 상태를 기반으로 계산해, 정책 네트워크에 동적으로 반영한다. belief state는 전체 확률 분포와 요약(전체 확률 합, ‘don’t care’, ‘미언급’) 두 형태로 제공되어 파라미터 효율성을 검증한다.
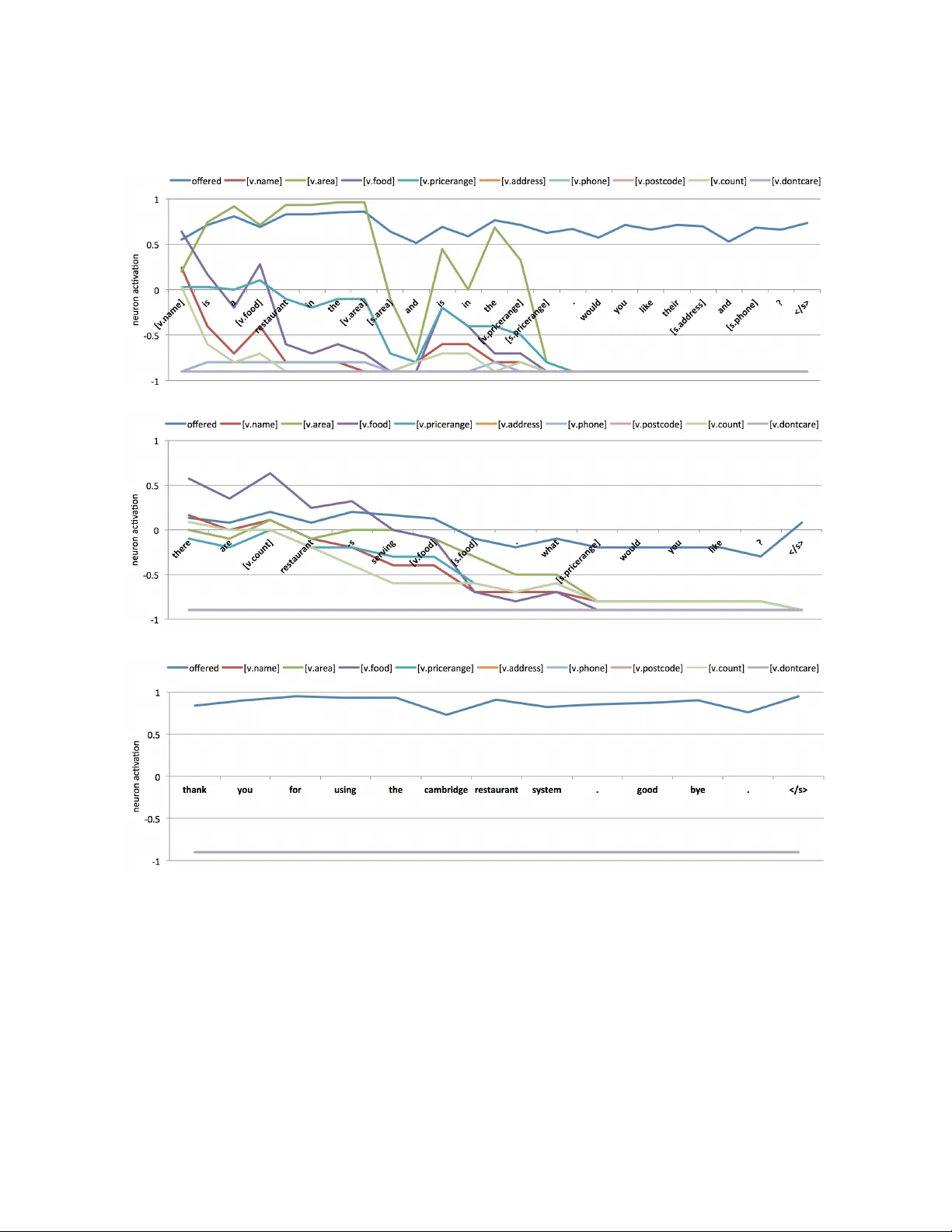
핵심 기여인 스냅샷 학습은 디코딩 단계 j에서 남은 출력 문장 Tₜ,ⱼ을 분석해 미래에 발생할 이벤트(특정 슬롯 값 등장 여부, 엔티티 제안 여부 등)를 0‑1 라벨 Υⱼₜ로 만든다. 이 라벨은 시스템 응답을 delexicalized 형태로 변환해 자동 생성한다. 그런 다음 조건 벡터의 일부 \hat{m}ⱼₜ에 대해 교차 엔트로피 손실 H(Υⱼₜ, \hat{m}ⱼₜ)를 추가한다. 이 보조 손실은 조건 벡터가 미래 출력과 직접적인 연관성을 학습하도록 강제하고, vanishing gradient 문제를 완화하며, 조건 벡터의 서브스페이스를 보다 판별력 있고 투명하게 만든다.
실험은 Cambridge 지역 레스토랑 도메인에서 위자드‑오즈 방식으로 수집한 대규모 대화 데이터셋을 사용한다. 평가 지표는 BLEU, 성공률, 그리고 조건 벡터의 해석 가능성을 정량화한 별도 메트릭을 포함한다. 결과는 다음과 같다. (1) 하이브리드‑type이 가장 높은 BLEU와 성공률을 기록했으며, 이는 조건 벡터와 LM이 완전히 분리돼 각자 최적화될 수 있었기 때문이다. (2) 어텐션을 적용하면 메모리‑type과 하이브리드‑type 모두에서 성능이 크게 상승했으며, 특히 슬롯 가중치가 동적으로 변하는 상황에서 유리했다. (3) 스냅샷 학습은 모든 아키텍처에서 평균 1.5‑2.0% BLEU 향상을 가져왔으며, 특히 LM‑type처럼 조건 벡터와 LM이 경쟁하는 경우에 효과가 두드러졌다. (4) 요약 belief는 파라미터 수를 줄이면서도 성능 저하가 거의 없었으며, 모델이 핵심 정보에 집중하도록 돕는다.
종합적으로, 논문은 조건부 생성 모델 설계 시 ‘조건 벡터의 판별력·투명성’이 핵심임을 강조한다. 스냅샷 학습과 어텐션은 이러한 조건 벡터를 강화하는 실용적인 방법이며, 하이브리드‑type과 같은 구조적 분리는 모델의 해석 가능성을 높이고 성능을 최적화한다. 이러한 접근은 복수의 소스 정보를 통합해야 하는 실제 대화 시스템에 적용 가능하며, 향후 강화학습이나 멀티도메인 확장에도 유용한 기반을 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기