LSTM 기반 영역 임베딩으로 텍스트 분류 성능 혁신
본 논문은 텍스트 영역 임베딩을 위한 새로운 프레임워크를 제시한다. 고정 크기 영역만을 다루는 기존 one‑hot CNN의 한계를 넘어, 가변 길이 영역을 효율적으로 표현할 수 있는 LSTM 기반 임베딩을 설계한다. 단순화된 one‑hot LSTM 구조에 풀링, 문서 절단(chopping), 입·출력 게이트 제거, 양방향 확장을 적용해 학습 속도와 정확도를 동시에 향상시켰으며, 무라벨 데이터로 사전 학습한 LSTM 임베딩과 CNN 임베딩을 결합…
저자: Rie Johnson, Tong Zhang
본 논문은 텍스트 분류에서 영역 임베딩을 활용한 최신 접근법을 재조명하고, LSTM을 이용해 보다 유연하고 강력한 영역 임베딩을 구현한다. 서론에서는 기존의 선형 모델과 bag‑of‑words 기반 방법이 한계에 봉착했으며, 단어 순서를 고려한 비선형 모델, 특히 one‑hot CNN이 뛰어난 성능을 보였지만 고정된 영역 크기와 파라미터 규모의 제약이 있다는 점을 지적한다. 이를 일반화된 ‘텍스트 영역 임베딩 + 풀링’ 프레임워크로 확장하고, 가변 길이 영역을 자연스럽게 처리할 수 있는 LSTM 기반 임베딩을 제안한다.
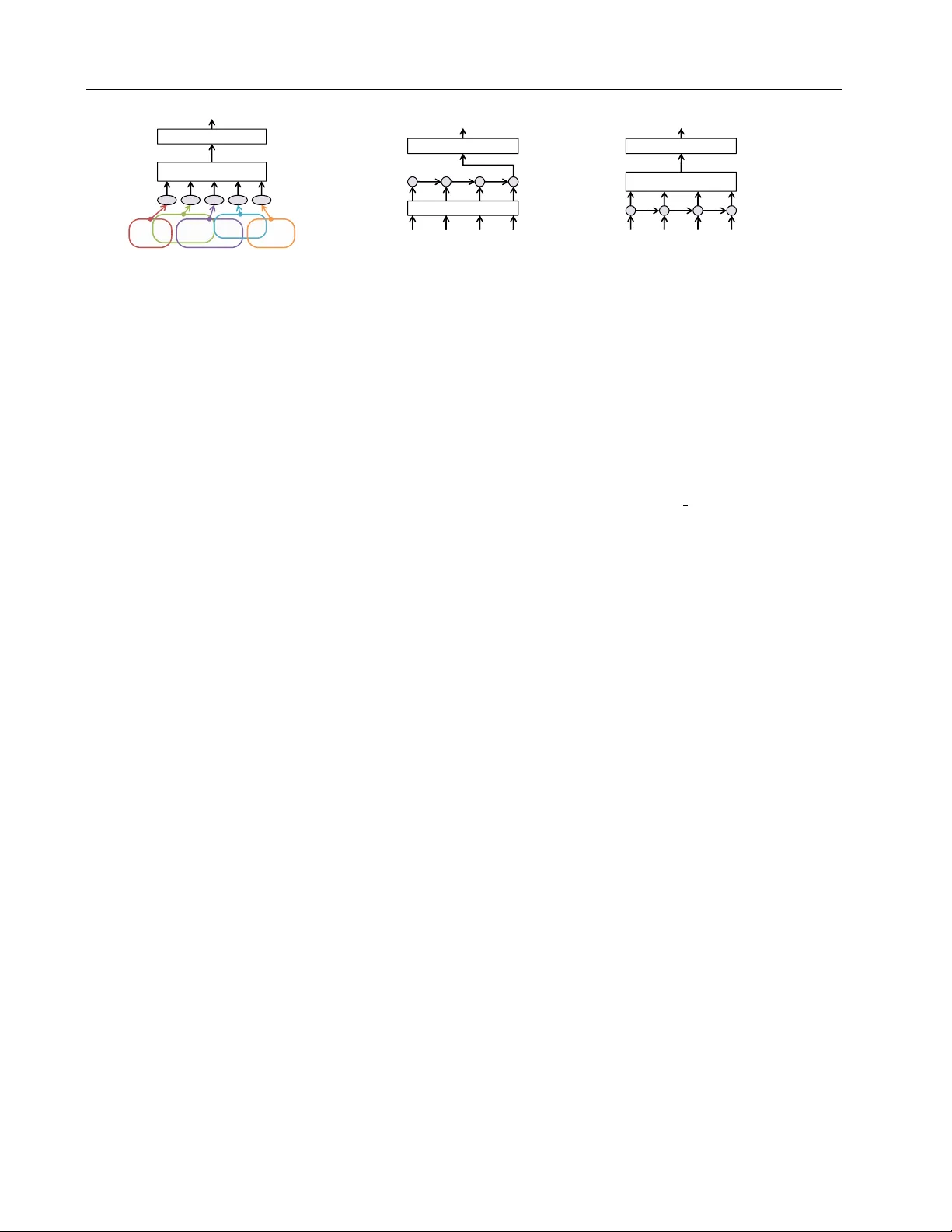
LSTM의 기본 수식과 기존 word‑vector LSTM(wv‑LSTM) 구조를 소개한 뒤, 저자들은 wv‑LSTM이 학습 불안정성과 긴 문서 처리 시 높은 연산 비용을 초래한다는 문제점을 제시한다. 이에 대한 해결책으로 첫 번째 단계는 word‑embedding 레이어를 완전히 제거하고 원‑핫 벡터를 직접 LSTM에 입력하는 one‑hot LSTM를 설계한다. 이때 word‑embedding 행렬 V를 LSTM 가중치에 흡수함으로써 모델의 표현력은 유지하면서 파라미터 수를 감소시킨다.
다음으로, ‘풀링’ 메커니즘을 도입해 각 시점의 은닉 상태 hₜ를 문서 전체 벡터로 집계한다. 풀링은 max‑pooling 혹은 average‑pooling이 가능하며, 이를 통해 LSTM이 전체 문서를 기억해야 하는 부담을 경감하고, 중요한 구문을 지역적으로 포착하도록 만든다. 풀링 덕분에 ‘chopping’이라는 기법을 도입할 수 있는데, 이는 긴 문서를 일정 길이(예: 50~100 토큰)로 잘라 미니배치 내에서 병렬 처리함으로써 학습 속도를 크게 높인다. 테스트 단계에서는 원본 전체 문서를 그대로 입력해 정확도를 유지한다.
또한, 입·출력 게이트(i‑gate, o‑gate)를 제거함으로써 연산량과 메모리 사용량을 절반 수준으로 줄였다. 풀링이 이미 불필요한 정보를 걸러내는 역할을 수행하므로, 게이트가 없는 단순화된 LSTM는 성능 저하 없이 효율성을 극대화한다. 마지막으로, 순방향 LSTM에 역방향 LSTM을 병렬로 연결한 양방향 구조(oh‑2LSTMp)를 도입해 문맥 정보를 양쪽에서 포착하도록 하였다. 이 구조는 특히 긴 문서에서 앞뒤 문맥이 중요한 경우 정확도 향상에 크게 기여한다.
반지도학습 설정에서는 무라벨 데이터에 대해 LSTM을 사전 학습시켜 영역 임베딩을 얻고, 이를 기존 one‑hot CNN의 임베딩과 결합한다. 두 종류의 임베딩은 서로 보완적인 특성을 가지며, 결합 모델은 단일 모델보다 월등히 높은 정확도를 기록한다.
실험은 IMDB(감성 분석), Elec(전자 제품 리뷰), RCV1(주제 분류), 20NG(뉴스 그룹) 네 개 데이터셋에서 수행되었다. vocab은 가장 빈번한 30K 단어로 제한하고, dropout을 적용해 과적합을 방지하였다. 결과는 다음과 같다. (1) one‑hot LSTM는 word‑vector LSTM 대비 학습 속도가 5~10배 빨라졌으며, 정확도도 소폭 개선되었다. (2) 풀링과 chopping을 적용한 모델은 추가적인 정확도 향상을 보였고, 입·출력 게이트를 제거함으로써 학습 시간이 절반 이하로 감소했다. (3) 양방향 LSTM을 도입한 oh‑2LSTMp는 가장 높은 정확도를 달성했으며, 특히 RCV1과 20NG에서 큰 폭의 개선을 보였다. (4) 무라벨 데이터로 사전 학습한 LSTM 임베딩과 one‑hot CNN 임베딩을 결합한 최종 모델은 기존 최고 기록을 크게 넘어섰다(예: IMDB에서 7.64% → 6.3% 이하).
결론적으로, 텍스트 영역 임베딩을 위한 LSTM 기반 접근법은 고정 크기 CNN의 한계를 극복하고, 가변 길이 구문을 효과적으로 포착한다. 모델을 단순화(원‑핫 입력, 풀링, 게이트 제거)하고, 문서 절단을 통해 학습 효율성을 높이며, 양방향 구조와 반지도학습을 결합함으로써 현재 텍스트 분류 분야에서 가장 강력한 성능을 달성하였다. 코드와 실험 상세 내용은 공개된 URL에서 확인 가능하다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기