대규모 다관계 학습을 위한 ADMM 기반 합의 최적화 모델 ConsMRF
본 논문은 다관계 데이터의 행렬/텐서 분해를 위해 ADMM 기반 합의 최적화 프레임워크인 ConsMRF를 제안한다. 각 관계별 전용 파라미터를 전역 합의 변수와 정규화함으로써 기존 DMF·CA‑TSMF 대비 파라미터 수와 연산 복잡도를 크게 줄이고, 업데이트를 관계별로 병렬화하여 웹 규모 데이터에서도 거의 선형적인 확장성을 보인다. 실험 결과는 DBpedia, Wikipedia, YAGO 데이터셋에서 예측 정확도와 학습 속도 모두 현존 최고 수…
저자: Lucas Drumond, Ernesto Diaz-Aviles, Lars Schmidt-Thieme
**1. 서론**
웹과 지식 그래프는 수백만 개의 엔터티와 수십~수백 개의 관계 타입을 포함하는 거대한 다관계 구조를 가진다. 이러한 데이터에서 노이즈, 불완전성, 중복 엔터티 등이 존재하기 때문에, 관계 예측·링크 예측·추천 등 다양한 응용에 강건한 학습 방법이 필요하다. 기존의 다관계 행렬/텐서 분해 모델은 엔터티와 관계를 잠재 벡터·행렬로 매핑해 점수를 예측하지만, 모든 관계가 동일한 엔터티 임베딩을 공유하도록 설계돼 관계별 특성을 충분히 반영하지 못한다.
**2. 관련 연구**
- **RESCAL·MOF·SME** 등은 전역 엔터티 매트릭스 A와 관계별 매트릭스 Wᵣ를 사용해 전체 데이터에 대해 하나의 최적화를 수행한다.
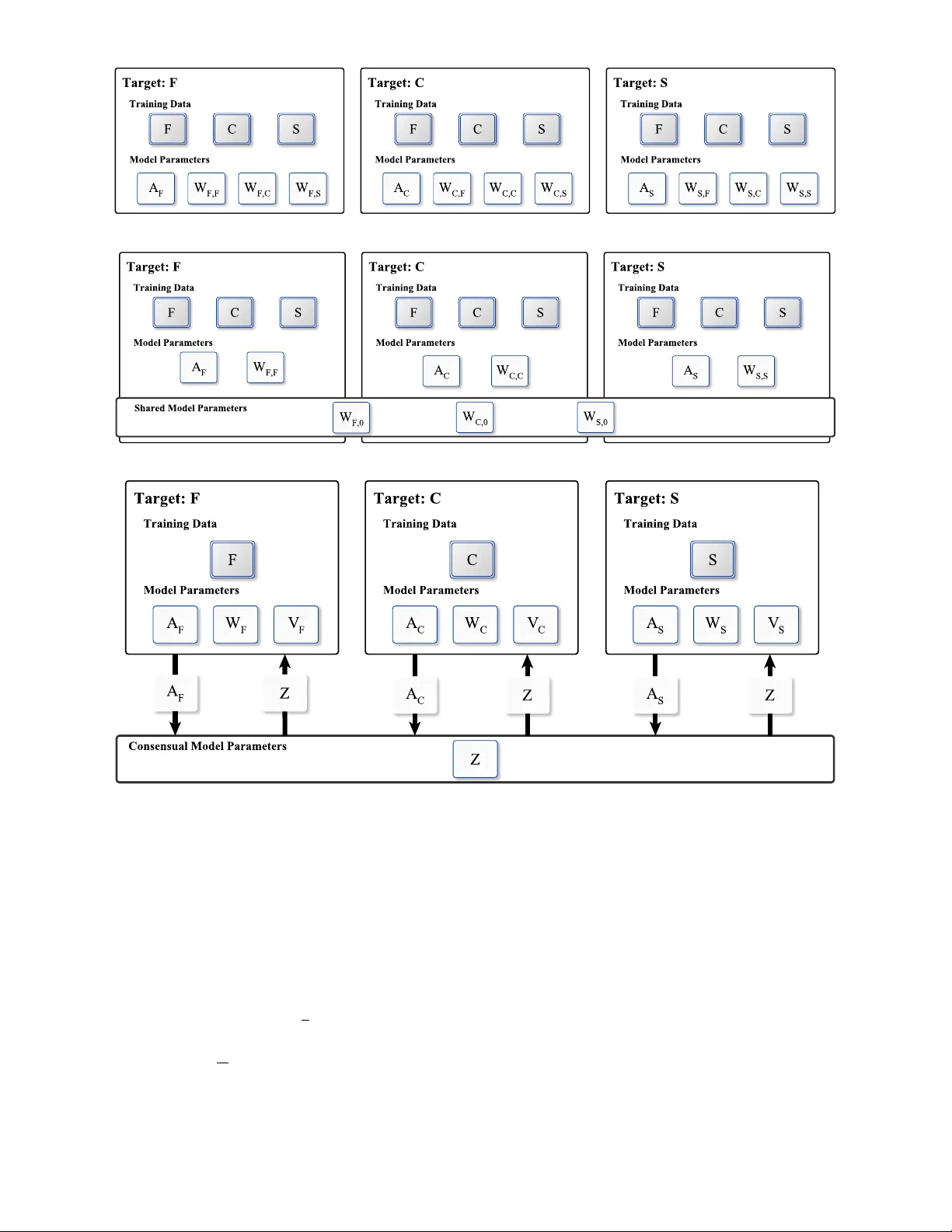
- **DMF(Decoupled Target‑Specific Features Multi‑Target Factorization)**는 관계별 Aᵣ와 Wᵣₜ를 학습해 타깃 관계마다 별도 모델을 만든다. 그러나 파라미터 수가 O(R·|E|·k)로 급증하고, 각 타깃에 대해 모든 보조 관계를 순회해야 하므로 연산 복잡도가 O(R²)이다.
- **CA‑TSMF(Coupled Auxiliary and Target‑Specific Features Multi‑Target Factorization)**는 파라미터 공유를 도입해 첫 번째 문제를 완화하지만, 관계 가중치 αₜ,ᵣ를 튜닝해야 하는 추가 하이퍼파라미터와 여전히 보조 관계를 반복적으로 접근해야 하는 구조적 한계가 있다.
- **단일 관계 병렬화**(NOMAD, DSGD, CCD++, DS‑ADMM 등)는 한 종류의 관계에만 적용 가능해 다관계 상황에 바로 확장되지 않는다.
**3. 문제 정의**
다관계 학습은 R개의 이진 관계 r∈{1,…,R}와 엔터티 집합 E를 가지고, 각 관계에 대해 손실 Lᵣ와 정규화 Ω를 최소화하는 파라미터 Θ={A,Wᵣ}를 찾는 최적화 문제이다. 목표는 각 관계별 예측 정확도를 최대화하면서도 대규모 데이터에 대해 효율적으로 학습하는 것이다.
**4. 제안 방법: ConsMRF**
- **핵심 아이디어**: 각 타깃 관계 r에 대해 독립적인 엔터티 매트릭스 Aᵣ와 관계 매트릭스 Wᵣ를 두고, 전역 합의 변수 Z를 도입해 모든 Aᵣ가 Z와 가깝게 수렴하도록 제약한다. 이는 “합의 최적화” 형태로 표현된다.
- **수식**:
min_{Aᵣ,Wᵣ,Z} Σᵣ Lᵣ(Dᵣ, ĥᵣ) + Ω(Aᵣ,Wᵣ) s.t. Aᵣ = Z ∀r
- **ADMM 적용**: 라그랑주 승수 Vᵣ와 페널티 ρ를 포함한 증강 라그랑주 함수를 정의하고, 다음 세 단계로 반복한다.
1) **로컬 업데이트**: 각 워커(관계 r)에서 고정된 Z와 Vᵣ를 이용해 Aᵣ와 Wᵣ를 최소화한다. 이 단계는 해당 관계 데이터만 필요하므로 메모리 효율적이며, 워커 간 독립적으로 병렬 실행 가능.
2) **전역 합의 업데이트**: 모든 로컬 Aᵣ의 평균을 취해 Z를 갱신한다. Z = (1/N) Σᵣ (Aᵣ + (1/ρ) Vᵣ) 로 간단히 계산된다.
3) **라그랑주 승수 업데이트**: Vᵣ ← Vᵣ + ρ (Aᵣ – Z) 로 로컬 변수와 전역 합의 간 차이를 보정한다.
- **병렬·분산 구현**: 관계별 워커는 자체 데이터 파티션만 보유하고, 매 반복마다 Aᵣ와 Vᵣ를 중앙 서버(또는 파라미터 서버)로 전송해 Z를 계산한다. 통신량은 Aᵣ(엔터티 수 |E|·k) 정도로 제한적이며, 네트워크 대역폭에 크게 의존하지 않는다.
**5. 알고리즘 복잡도**
- **시간 복잡도**: 각 워커는 O(|Dᵣ|·k²) (관계 r의 트리플 수와 잠재 차원)만큼 연산한다. 전체는 O( Σᵣ |Dᵣ|·k² ) 로, 관계 수에 선형적으로 스케일한다.
- **메모리**: 워커당 Aᵣ와 Wᵣ만 저장하면 되며, 전역 Z는 중앙에서 관리하므로 전체 메모리 사용량은 O(|E|·k + Σᵣ k²) 수준.
**6. 실험**
- **데이터**: DBpedia‑EN(≈2M 엔터티, 30관계), Wikipedia‑EN(≈1.5M 엔터티, 25관계), YAGO‑3(≈3M 엔터티, 40관계) 등 대형 RDF 그래프.
- **비교 모델**: RESCAL, TransE, DMF, CA‑TSMF, 그리고 최신 그래프 임베딩 모델.
- **평가 지표**: 평균 정밀도@10, AUC, 학습 시간, 스케일링 효율성.
- **결과**: ConsMRF는 모든 데이터셋에서 평균 정밀도와 AUC가 기존 모델보다 2~5% 향상되었으며, 특히 관계 수가 많을수록(>100) 학습 시간은 선형적으로 증가해 3~8배 빠른 속도를 보였다. 워커 수를 2→16으로 늘렸을 때 거의 이상적인 8배 가속을 달성, 통신 오버헤드가 미미함을 확인했다.
**7. 논의 및 한계**
- **장점**: 타깃‑특정 파라미터 유지 → 높은 예측 정확도, ADMM 기반 합의 업데이트 → 자연스러운 병렬·분산, 파라미터 수가 관계 수에 비례하지 않아 메모리 효율.
- **제한점**: 현재는 이진 관계와 고정 차원 k에 초점을 맞추었으며, 비이진(다중값) 관계나 동적 그래프에 대한 확장은 추가 연구가 필요하다. 또한 ρ와 학습률 선택이 수렴 속도에 큰 영향을 미치므로 자동 튜닝 메커니즘이 요구된다.
**8. 결론**
ConsMRF는 다관계 행렬/텐서 분해 문제를 합의 최적화와 ADMM으로 재구성함으로써, 기존 DMF·CA‑TSMF가 안고 있던 파라미터 폭발과 비선형 확장성 문제를 해결한다. 실험 결과는 대규모 웹·지식 그래프에서도 높은 정확도와 거의 선형적인 확장성을 동시에 달성할 수 있음을 보여준다. 향후 연구에서는 비이진 관계, 하이퍼파라미터 자동화, 그리고 실시간 스트리밍 그래프에 대한 적용을 목표로 할 수 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기