소음이 만든 활력: 포화 활성함수의 새로운 학습법
포화되는 활성함수(예: hard‑sigmoid, hard‑tanh)의 기울기 소실 문제를 해결하기 위해, 저자들은 포화 구간에만 잡음(noise)을 주입하는 ‘노이즈 활성함수’를 제안한다. 잡음의 크기는 포화 정도에 비례하도록 설계하고, 학습 초기에 큰 잡음으로 탐색성을 확보한 뒤 점차 감소시켜 시뮬레이티드 어닐링 효과를 얻는다. 실험 결과, 기존 포화 함수들을 동일 구조의 네트워크에 교체했을 때 학습이 크게 개선되고, 특히 어려운 과제(커리큘…
저자: Caglar Gulcehre, Marcin Moczulski, Misha Denil
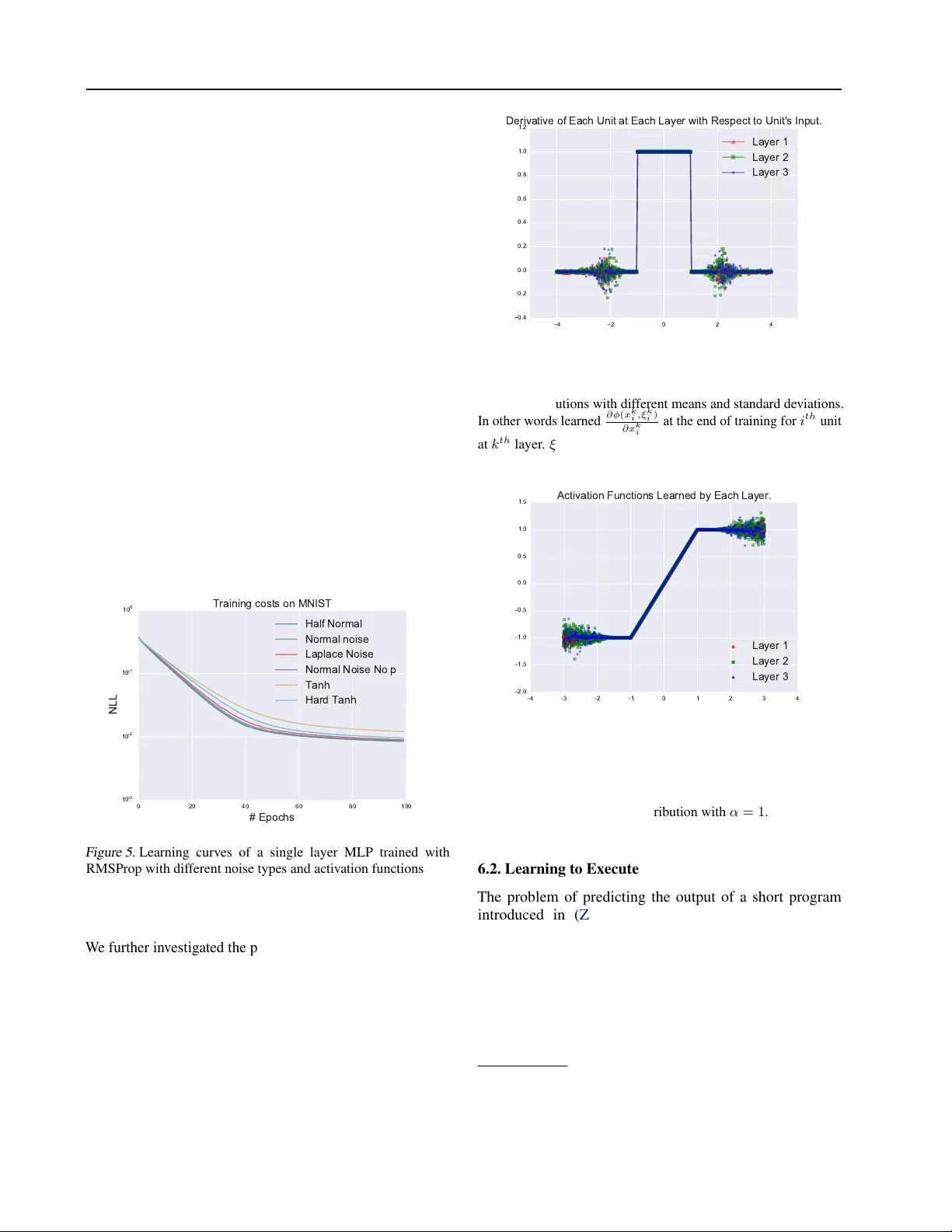
본 논문은 딥러닝 모델에서 흔히 사용되는 포화형 활성함수(soft‑saturating 함수와 hard‑saturating 함수)의 학습 어려움을 해결하기 위해 “노이즈 활성함수(Noisy Activation Functions)”라는 새로운 접근법을 제안한다. 포화형 함수는 입력이 큰 절댓값을 가질 때 출력이 일정값에 수렴하고, 그 구간에서는 미분값이 0이 되기 때문에 역전파 시 기울기가 사라지는 vanishing gradient 문제를 일으킨다. 특히 LSTM·GRU와 같은 게이트 구조에서는 이러한 포화가 게이트가 완전히 열리거나 닫히는 hard‑decision을 가능하게 하지만, 동시에 학습이 정체되는 병목이 된다.
저자들은 먼저 hard‑sigmoid와 hard‑tanh를 1차 테일러 전개를 통해 선형 근사 u(x)와 차이 Δ=h(x)‑u(x) 로 정의한다. Δ는 포화되지 않은 영역에서는 0이며, 포화가 심해질수록 절대값이 커진다. 이를 이용해 잡음의 표준편차 σ(x)를 다음과 같이 설계한다.
σ(x)=c·(sigmoid(p·|Δ|)‑0.5)²
여기서 p는 학습 과정에서 자동으로 조정되는 스칼라 파라미터이며, c는 잡음 규모를 조절하는 하이퍼파라미터이다. 이 식은 포화 정도가 클수록 σ가 커지게 하여, 포화 구간에만 강한 잡음을 주입한다는 목표를 구현한다.
노이즈는 평균이 0인 정규분포 혹은 절반 정규분포에서 샘플링된다. 가장 간단한 형태는 φ(x,ξ)=h(x)+σ(x)·ξ 로, ξ∼N(0,1) 이다. 포화되지 않은 구간에서는 Δ=0이므로 σ=0, 즉 φ(x,ξ)=u(x)와 동일하게 동작한다. 반면 포화 구간에서는 h′(x)=0이지만 φ′(x,ξ)=σ′(x)·ξ 가 거의 확률적으로 비제로가 되므로, 역전파 시 기울기가 완전히 차단되지 않는다. 또한, 잡음의 부호를 입력 x의 부호와 일치시키는 d(x)=‑sgn(x)·sgn(1‑α) 를 도입해, 잡음이 포화된 유닛을 비포화 영역으로 “밀어내는” 효과를 만든다. 이렇게 하면 잡음이 때때로 잘못된 방향으로 기울기를 전달하는 현상을 최소화하고, 포화된 유닛이 다시 학습 가능한 상태로 돌아가도록 유도한다.
학습 전략은 두 단계로 구성된다. 첫 번째 단계에서는 σ를 크게 설정해 탐색성을 극대화한다. 이때 SGD는 큰 잡음으로 인해 손실 표면의 다양한 지역을 자유롭게 이동하며, saddle point나 나쁜 로컬 최소점에서 탈출할 확률이 높아진다. 두 번째 단계에서는 σ를 점진적으로 감소시켜(annealing) 잡음이 사라지면 deterministic한 hard‑activation으로 전환된다. 이는 시뮬레이티드 어닐링과 유사한 효과를 제공하며, 최종적으로는 잡음이 없는 상태에서 정밀한 파라미터 튜닝이 이루어진다.
실험에서는 여러 데이터셋과 과제에 대해 기존 포화 함수와 noisy 버전을 교체 적용하였다. 이미지 분류, 음성 인식, 언어 모델링 등에서 noisy hard‑sigmoid·hard‑tanh를 사용한 모델은 학습 속도가 빨라지고, 최종 정확도·퍼플렉시티가 향상되었다. 특히 커리큘럼 학습이 필요하거나, 목표 함수가 매우 비볼록한 경우(예: 복잡한 시퀀스‑투‑시퀀스 변환)에는 기존 방법이 수렴하지 못하는 반면, 제안된 방법은 안정적으로 수렴하며 state‑of‑the‑art 수준의 성능을 달성했다.
결론적으로, 이 논문은 포화 구간에만 잡음을 주입하고, 잡음 규모를 포화 정도에 따라 동적으로 조절함으로써, 기울기 소실 문제를 회피하고 탐색‑수렴 트레이드오프를 효과적으로 관리하는 새로운 활성함수 설계와 학습 프레임워크를 제시한다. 이는 기존 ReLU‑계열이나 soft‑saturating 함수에 비해 더 넓은 함수군을 학습 가능하게 만들며, 특히 게이트형 구조에서 hard‑decision을 유지하면서도 학습 효율을 크게 높이는 장점을 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기