실용적 선형 TD 학습을 위한 새로운 하이브리드 알고리즘 탐구
** 본 논문은 오프‑정책 예측 문제에서 선형 복잡도를 유지하면서 안정성을 확보하는 두 가지 새로운 하이브리드 TD 알고리즘, HTD(λ)와 true‑online HTD(λ)를 제안한다. 또한 기존의 선형 TD 계열(예: GTD, TO‑GTD, ETD 등)을 다양한 벤치마크와 Baird’s counterexample에 대해 실험적으로 비교하여, 오프‑정책 견고성이 필요할 때는 GTD(λ)·TO‑GTD(λ)를, 그렇지 않은 경우는 TO‑ETD…
저자: Adam White, Martha White
**
본 논문은 오프‑정책 강화학습에서 선형 함수 근사를 사용한 가치 예측 문제를 다룬다. 기존에는 TD(λ)와 같은 전통적 방법은 온‑정책에서는 효율적이지만 오프‑정책에서는 발산 위험이 있었고, 이를 해결하기 위해 GTD, TDC, ETD 등 그라디언트‑TD 계열이 제안되었다. 그러나 이들 방법은 보조 가중치 h와 별도의 학습률 α_h를 필요로 하며, 중요도 가중치 ρ에 의해 높은 분산을 초래한다. 또한 최근에는 true‑online TD와 true‑online GTD가 제시돼 전방‑후방 뷰의 불일치를 해소했지만, 구현 복잡도가 증가하고 오프‑정책 견고성은 여전히 제한적이었다.
이러한 배경에서 저자들은 “하이브리드” 접근을 재조명한다. 하이브리드 TD는 온‑정책 데이터에서는 순수 TD 업데이트를, 오프‑정책 데이터에서는 그라디언트‑TD 형태의 보정을 적용한다는 아이디어다. 기존 연구에서는 HTD(0)만이 제안되었고, 트레이스 λ를 포함한 확장은 없었다. 논문은 이를 확장해 HTD(λ)와 true‑online HTD(λ)를 도출한다. 핵심은 MSPBE의 그라디언트를 재구성하면서, C⁻¹ 대신 행동 정책에 대한 양의 정부호 행렬 A→μ을 사용해 보정 항을 도출하는 것이다. 이 보정 항은 ( xₜ−γₜ₊₁xₜ₊₁ )(eₜ−e^μₜ)ᵀ hₜ 로, 온‑정책에서는 사라지고 오프‑정책에서는 GTD와 유사한 역할을 한다.
알고리즘은 다음과 같이 정의된다.
1) 중요도 가중치 ρₜ와 λ, γ를 이용해 오프‑정책 트레이스 eₜ를 계산하고, 온‑정책 트레이스 e^μₜ를 별도로 유지한다.
2) 주 가중치 w는 δₜ eₜ와 보정 항 (γₜ₊₁xₜ₊₁−xₜ)(e^μₜ−eₜ)ᵀ hₜ 로 업데이트된다.
3) 보조 가중치 h는 동일한 샘플을 사용해 A→μ‑기반 업데이트를 수행한다.
true‑online 버전은 TD와 동일한 “증분” 구조를 적용해, 매 스텝마다 정확한 전방‑후방 일치를 보장한다.
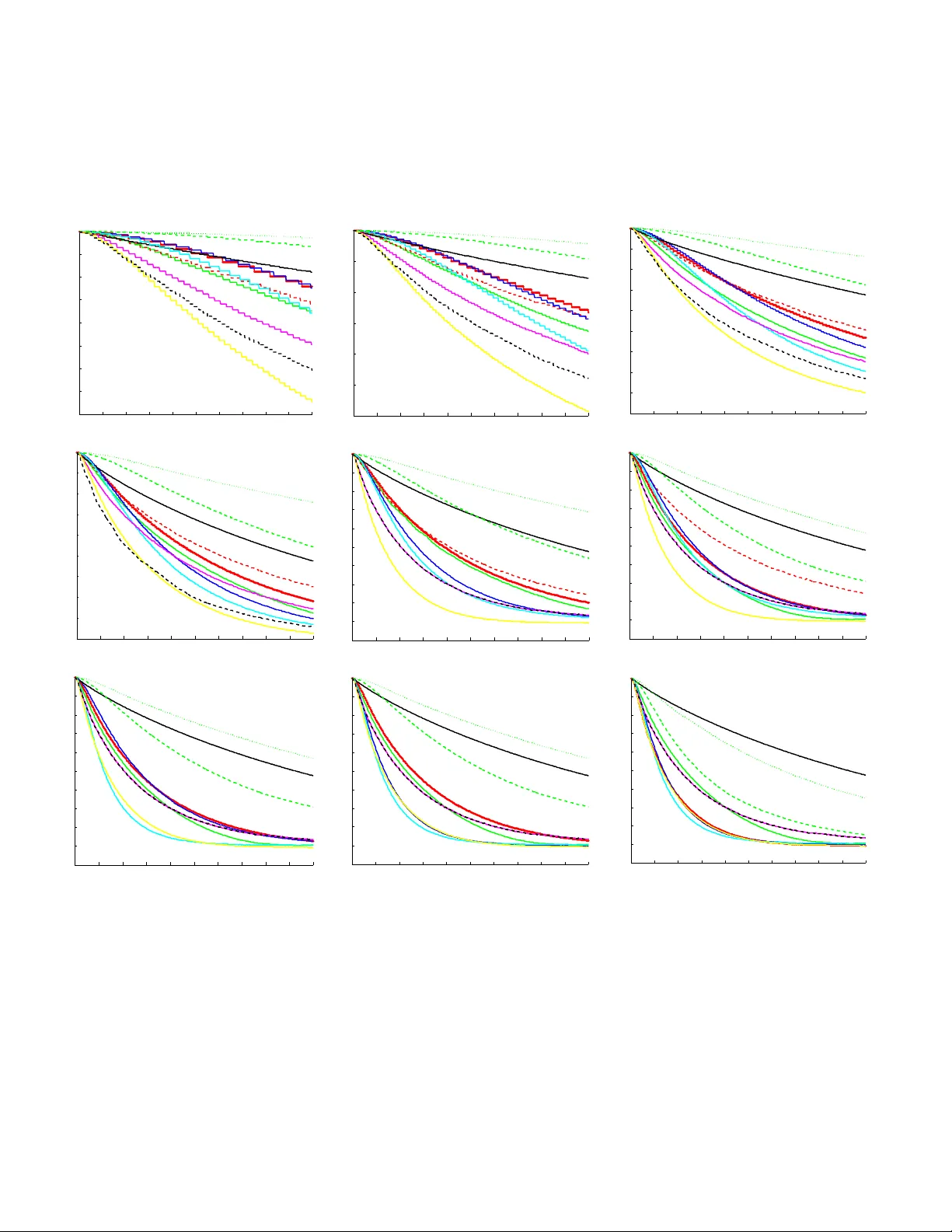
실험 설계는 7개의 MRP(마크오프 체인, 랜덤 MRP, Baird’s counterexample 등)와 4개의 λ값, β값, 학습률 조합을 포함한다. 총 12개의 알고리즘(HTD, true‑online HTD, GTD, TO‑GTD, ETD, TO‑ETD 등)을 비교했으며, 평가 지표는 평균 제곱 TD 오차와 수렴 속도, 파라미터 민감도이다.
주요 결과는 다음과 같다.
- **견고성**: GTD(λ)와 TO‑GTD(λ)는 모든 오프‑정책 시나리오에서 안정적으로 수렴했으며, 특히 높은 ρ 분산 상황에서 다른 방법보다 우수했다.
- **효율성**: 동일한 연산량 기준에서 GTD(λ)가 TO‑GTD(λ)보다 빠르게 수렴했으며, 메모리 사용량도 적었다.
- **전반적 성능**: 오프‑정책 견고성이 크게 요구되지 않을 때는 TO‑ETD(λ,β)가 가장 빠른 수렴과 낮은 파라미터 민감도를 보였다. 단, Baird’s counterexample에서는 GTD 계열이 여전히 최상위였다.
- **하이브리드 알고리즘**: HTD(λ)와 true‑online HTD(λ)는 온‑정책에서는 TD와 동일한 학습 효율을 유지하면서, 오프‑정책에서도 발산 없이 동작했다. 다만, GTD 계열에 비해 약간의 성능 저하가 있었으며, 이는 보조 가중치 h의 추정 정확도에 의존한다.
결론적으로, 논문은 실무에서 알고리즘 선택 시 다음과 같은 가이드를 제시한다.
1) **오프‑정책 견고성 필요** → GTD(λ) 혹은 TO‑GTD(λ) 선택.
2) **연산 시간 제한** → GTD(λ) 우선.
3) **일반적인 상황** → TO‑ETD(λ,β) 사용.
4) **온‑정책 중심** → HTD(λ) 혹은 true‑online HTD(λ)로 복잡도 절감.
이 연구는 기존 선형 TD 계열의 장단점을 체계적으로 정리하고, 새로운 하이브리드 방법을 제안함으로써 오프‑정책 학습의 실용성을 크게 향상시켰다. 향후 연구에서는 HTD 계열의 이론적 수렴 증명을 완성하고, 비선형 함수 근사와 딥러닝 기반 정책 평가에 확장하는 방향이 제시된다.
**
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기