가우시안 무작위 행렬에서 큰 평균을 갖는 부분 행렬 찾기와 알고리즘 한계
** 본 논문은 i.i.d. 표준 가우시안 원소를 가진 n×n 행렬에서 k×k 부분 행렬의 평균값을 최대화하는 문제를 다룬다. 기존 연구가 제시한 전역 최적 평균값 2√(log n/k)와 달리, 가장 간단한 탐욕적 알고리즘(LAS)은 평균값이 √2배 정도 낮은 √(2 log n/k) 수준임을 증명한다. 또한, 클리크 탐색과의 유사성을 이용한 또 다른 탐욕적 알고리즘도 동일한 성능을 보이며, 새로운 “증분 탐욕(Incremental Greed…
저자: David Gamarnik, Quan Li
**
본 논문은 표준 가우시안 원소가 i.i.d.로 채워진 n×n 행렬 Cₙ에서 k×k 부분 행렬의 평균값을 최대화하는 문제를 다각도로 탐구한다. 먼저, Bhamidi·et al. (2012)의 비구성적 결과에 따르면, 전역 최적 평균값은 (1+o(1))·2√(log n/k)이며, 이는 k=O(log n/ log log n) 범위에서 고확률적으로 성립한다. 그러나 실제 알고리즘적 접근에서는 이 최적값에 도달하기가 어려운 것으로 알려져 있다.
**1. LAS 알고리즘 분석**
LAS는 임의의 k행·k열 집합을 시작점으로, 행 고정 후 평균을 최대화하는 k열을 선택하고, 그 다음 열 고정 후 평균을 최대화하는 k행을 선택하는 과정을 반복한다. 논문은 k가 상수일 때 LAS가 최종적으로 생성하는 행렬의 평균값이 (1+o(1))·√(2 log n/k)임을 엄밀히 증명한다. 핵심은 각 반복 단계에서 “새로운 최적 행렬”이 아직 탐색되지 않은 k×n 스트립에서 가장 큰 평균을 갖는 행렬과 거의 독립적인 분포를 가진다는 점을 보이는 조건부 확률 분석이다. 이를 통해 LAS가 일정 확률 ψ<1로 매 단계마다 진행을 멈출 확률이 존재함을 보이고, 전체 반복 횟수가 기하급수적으로 감소하는 확률 변수로 상한이 잡힌다. 결과적으로 LAS는 전역 최적값 2√(log n/k)보다 정확히 √2배 낮은 수준에 머무른다.
**2. 클리크 기반 탐욕 알고리즘**
행렬 원소를 임계값 θ로 이진화하면 양쪽 이분 그래프 G(n,n,p_θ)의 인접 행렬이 된다. 여기서 p_θ=Pr(Z>θ)이며 Z∼N(0,1)이다. θ를 적절히 선택하면 G에서 k×k 완전 이분 클리크가 존재할 확률이 1에 가까워지고, 이 클리크에 해당하는 원소들은 모두 θ 이상이므로 평균값은 약 √(2 log n/k)와 동일한 수준이 된다. 따라서 이 탐욕 알고리즘도 LAS와 같은 성능을 보이며, k=O(log n)까지 확장 가능함을 보인다.
**3. Incremental Greedy Procedure (IGP)**
IGP는 초기 하나의 원소에서 시작해 행과 열을 번갈아가며 하나씩 추가하는 방식으로 k까지 확장한다. 각 단계에서 현재 행·열 집합에 대해 가장 큰 평균을 제공하는 후보를 선택함으로써, 전체 평균값을 (4/3)·√(2 log n/k)까지 끌어올린다. 이 결과는 k=o(n) 범위에서 유효하며, 기존 탐욕 알고리즘보다 33% 정도 향상된 성능을 보여준다. 분석은 각 단계에서 선택된 원소가 아직 선택되지 않은 원소들보다 평균적으로 더 큰 값임을 확률적으로 보이고, 이를 누적해 전체 평균을 하한한다.
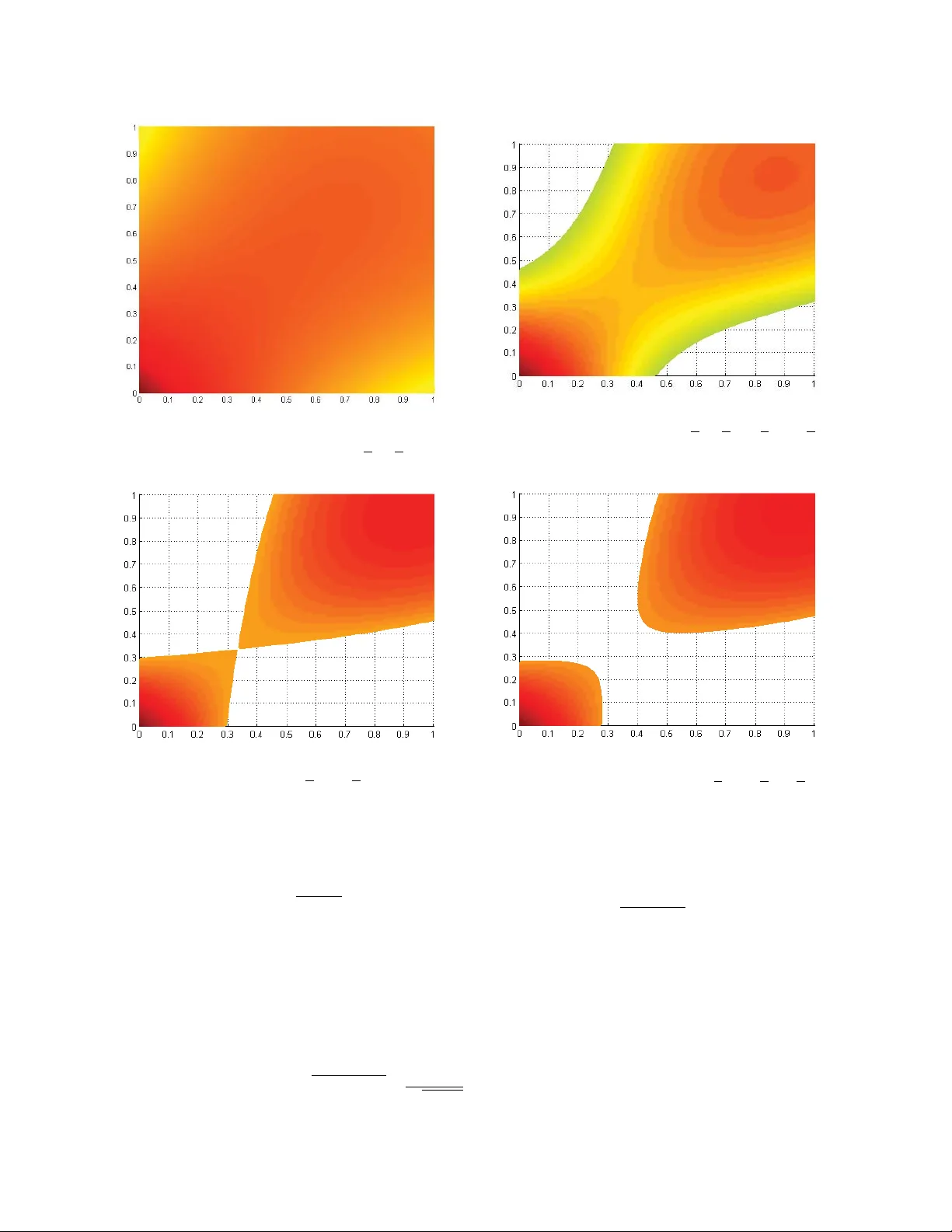
**4. Overlap Gap Property (OGP)와 알고리즘적 난이도**
저자들은 평균값이 α·√(2 log n/k)인 부분 행렬들의 겹침 구조를 기대값(overlap) 분석을 통해 조사한다. 두 행렬 A₁, A₂의 겹침은 행 집합 교집합 비율 x와 열 집합 교집합 비율 y로 정의한다. α를 고정하고 (x,y)∈
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기