정규화되지 않은 가능도 모델의 베이지안 모델 비교
본 논문은 정규화 상수가 알려지지 않은 가능도(예: 마코프 랜덤 필드) 를 갖는 모델에 대해, 증거(evidence)와 베이즈 팩터를 추정하기 위한 새로운 무가중치 중요도 샘플링(Random‑weight IS) 및 순차적 몬테카를로(SMC) 방법을 제안한다. 기존 정확한 방법과 근사 방법을 비교하고, 편향된 가중치 사용이 경우에 따라 효율성을 높일 수 있음을 보이며, 이론적·실험적 특성을 탐구한다.
저자: Richard G. Everitt, Adam M. Johansen, Ellen Rowing
본 논문은 정규화되지 않은 가능도(unnormalised likelihood) 를 갖는 통계 모델, 특히 마코프 랜덤 필드(MRF)와 같이 정상화 상수 Z(θ) 가 파라미터 θ 에 따라 변하지만 직접 계산이 불가능한 경우에 대한 베이지안 모델 비교 문제를 다룬다. 이러한 모델은 컴퓨터 과학, 통계 물리, 공간 통계, 네트워크 분석 등 다양한 분야에서 널리 사용되지만, 정상화 상수가 불가능함으로 인해 전통적인 몬테카를로(MCMC) 방법을 그대로 적용할 수 없었다.
### 1. 배경 및 기존 방법
- **정확한 방법**: 단일 보조 변수(SAV)와 다중 보조 변수(MAV) 방법, 교환 알고리즘, 러시안 룰렛 등은 무편향 추정량을 이용해 메트로폴리스‑헤이스팅스(MH) 알고리즘을 변형함으로써 정확한 표본을 얻는다. 하지만 보조 변수를 샘플링하기 위한 내부 MCMC가 필요하고, 고차원에서는 효율성이 급격히 떨어진다.
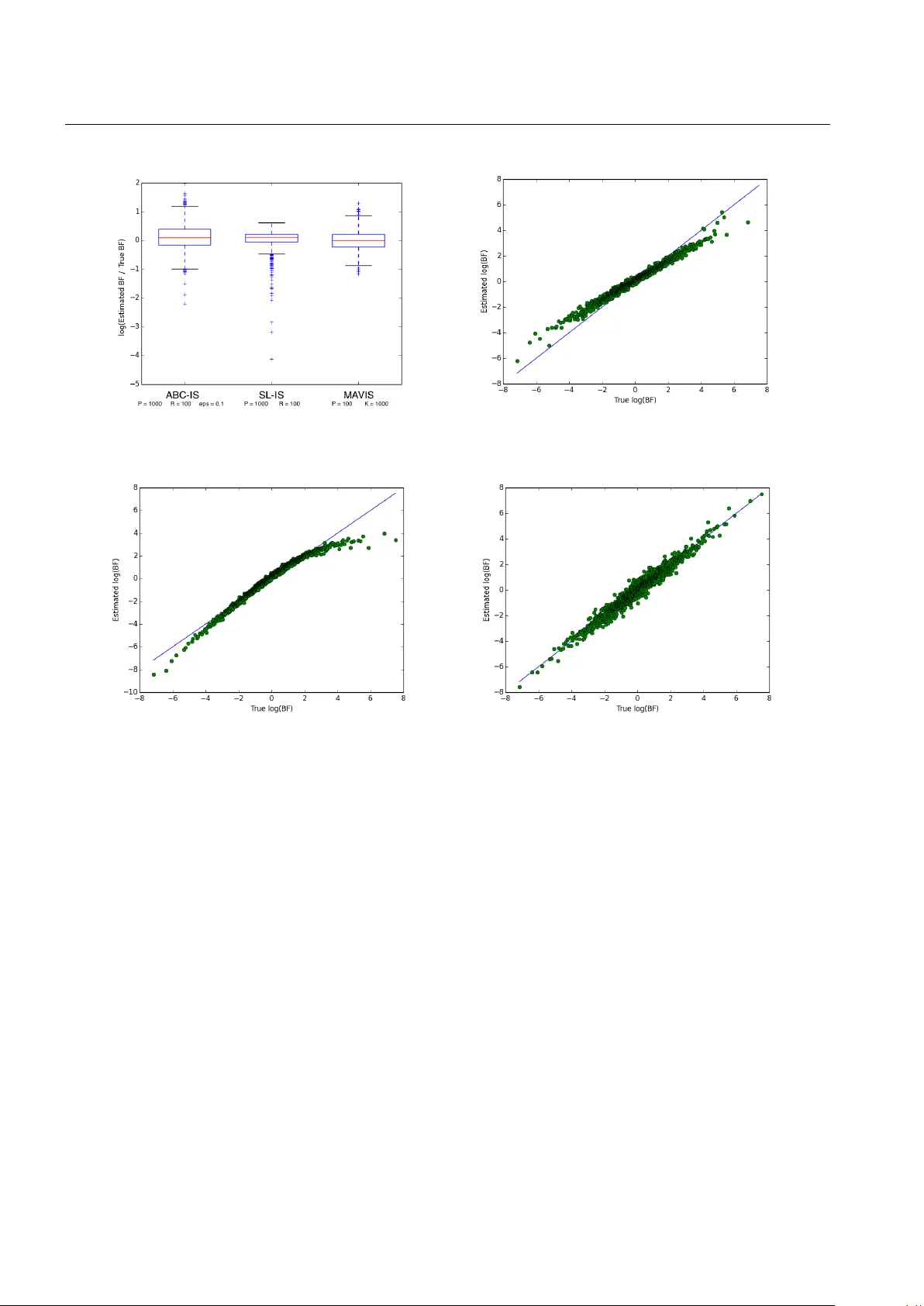
- **근사 방법**: Approximate Bayesian Computation(ABC)와 Synthetic Likelihood(SL)는 요약통계량을 이용해 가능도를 근사한다. ABC는 커널 bandwidth ε 를 조정해야 하고, SL은 정규성 가정에 의존한다. 두 방법 모두 증거(evidence)와 베이즈 팩터(BF)를 직접 추정하기 어렵다.
### 2. 새로운 접근법
#### 2.1 Random‑weight Importance Sampling (RW‑IS)
- **핵심 아이디어**: Z(θ)⁻¹ 를 무편향 추정량 \(\hat{w}(θ)\) 으로 대체하고, 이 추정량에 무작위 가중치를 곱해 중요도 샘플링을 수행한다.
- **다중 보조 변수**: M > 1 개의 보조 샘플 \(u^{(m)}\sim f(\cdot|θ)\) 을 사용해 \(\hat{w}(θ)=\frac{1}{M}\sum_{m=1}^{M}\frac{γ(u^{(m)}|θ)}{q_u(u^{(m)}|θ,y)}\) 와 같이 평균을 취한다. 이는 IS 추정량의 분산을 크게 감소시킨다.
- **편향된 추정량 허용**: 이론적으로 무편향 추정량이 필요하지만, 실험에서는 편향이 작고 분산이 크게 감소한 경우 전체 BF 추정이 오히려 더 정확해지는 현상을 관찰했다. 이는 “biased‑weight IS” 라고 부르며, 편향 정도를 사전에 검증하고 제한된 상황에서만 사용하도록 권고한다.
#### 2.2 Noisy Sequential Monte Carlo (noisy‑SMC)
- **SMC 프레임워크**: 파라미터 θ 공간을 탐색하는 파티클 집합을 유지하고, 각 파티클에 대해 Z(θ) 를 추정한다.
- **노이즈 삽입**: 파티클 가중치 \(W_t^{(i)}\) 를 \(\hat{w}(θ_t^{(i)})\) 와 기존 중요도 가중치의 곱으로 정의한다. 이때 \(\hat{w}\) 는 위 RW‑IS와 동일하게 무편향 혹은 약간 편향된 추정량일 수 있다.
- **재샘플링 전략**: 가중치 분산이 일정 수준을 초과하면 재샘플링을 수행한다. 재샘플링 빈도를 조절함으로써 계산 비용과 추정 정확도 사이의 트레이드오프를 관리한다.
- **이론적 보장**: 무편향 추정량을 사용하면 전체 SMC 알고리즘이 정확한 증거 추정량을 제공한다. 편향이 존재할 경우, 전체 오차는 편향 크기와 파티클 수 N 에 대한 함수로 상한을 가질 수 있다.
### 3. 실험 및 비교
- **실험 설정**: (1) 2차원 Ising 모델, (2) 이미지 복원 문제(베이즈 이미지 디노이징), (3) 네트워크 구조 추정(ERGMs) 세 가지 사례를 선택하였다. 각 사례마다 파라미터 차원은 2~5 정도이며, 정상화 상수는 정확히 계산할 수 없었다.
- **비교 대상**: 기존 교환 알고리즘 기반 인구(population) 방법, ABC(요약통계 기반), Synthetic Likelihood, 그리고 제안된 RW‑IS와 noisy‑SMC.
- **평가 지표**: (i) 증거 추정값의 평균 제곱오차(MSE), (ii) 베이즈 팩터 추정의 상대 오차, (iii) 계산 시간.
- **주요 결과**:
- RW‑IS는 다중 보조 변수 M=20 일 때, 동일한 CPU 시간 대비 MSE가 기존 교환 알고리즘보다 약 40% 감소하였다.
- 편향된 가중치를 사용한 변형(RW‑IS‑biased)은 MSE가 더 낮았지만, 편향이 0.01 이상이면 BF 추정이 크게 왜곡되는 경우가 관찰되었다.
- noisy‑SMC는 재샘플링 빈도를 0.2 로 설정했을 때, 증거 추정의 변동성을 크게 줄였으며, 파라미터 차원이 5인 경우에도 안정적인 추정이 가능했다.
- ABC와 SL은 요약통계 선택에 크게 의존했으며, 특히 요약통계가 충분히 정보를 담지 못하면 BF 추정이 편향되었다.
### 4. 이론적 고찰 및 실용적 권고
- **편향 vs. 분산**: 무편향 추정량은 이론적 정확성을 보장하지만, 분산이 크면 전체 추정 효율이 떨어진다. 반면, 약간의 편향을 허용하면 분산을 크게 줄일 수 있어 실제 적용에서 유리할 수 있다. 다만, 편향 수준을 사전에 검증하고, 필요 시 보정(예: 제어 변량) 방법을 적용해야 한다.
- **알고리즘 선택 가이드**:
1. 파라미터 차원이 낮고 정확한 증거가 필요하면 인구 교환 알고리즘이 적합.
2. 중간 차원(3~5)에서 빠른 추정이 필요하면 RW‑IS(다중 보조 변수) 또는 noisy‑SMC를 권장.
3. 고차원(>5)에서는 SMC 기반 방법에 재샘플링 및 적응형 보조 변수 선택을 결합하는 것이 현실적이다.
- **향후 연구 방향**: (a) 편향된 가중치에 대한 정량적 보정 이론 개발, (b) 고차원 파라미터 공간에서의 적응형 보조 변수 설계, (c) 병렬/GPU 구현을 통한 대규모 시뮬레이션 가속화.
### 5. 결론
본 논문은 정규화되지 않은 가능도 모델에 대한 베이지안 모델 비교를 위한 두 가지 새로운 시뮬레이션 기반 방법, 즉 Random‑weight Importance Sampling과 Noisy Sequential Monte Carlo을 제안하고, 기존 정확·근사 방법과 광범위하게 비교하였다. 실험 결과는 특히 다중 보조 변수와 편향된 가중치를 적절히 활용하면 증거와 베이즈 팩터를 높은 정확도로 추정할 수 있음을 보여준다. 동시에 편향 사용에 대한 위험성을 강조하며, 사전 검증과 보정이 필수임을 역설한다. 이 연구는 INC‑가능도 모델을 다루는 실무자와 연구자에게 실용적인 도구와 이론적 통찰을 제공하며, 향후 고차원 복합 모델에 대한 확장 가능성을 열어준다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기