저밀도 사용자‑아이템 행렬의 비선형 완성을 통한 차세대 Top‑N 추천
본 논문은 사용자‑아이템 행렬을 저랭크 가정하에 비선형(log‑det) 함수로 근사하고, 증강 라그랑주 승수(ALM) 기반 효율적 최적화 알고리즘을 설계한다. 원본 관측값을 그대로 유지하면서 결측값을 복원한 뒤 Top‑N 아이템을 순위 매겨 추천한다. 실험 결과, 기존 ItemKNN, PureSVD, WRMF, BPR, SLIM, LorSLIM 등과 비교해 Hit‑Rate와 ARHR 모두 유의하게 향상됨을 보인다.
저자: Zhao Kang, Chong Peng, Qiang Cheng
본 논문은 온라인 마켓플레이스와 소셜 플랫폼에서 사용되는 Top‑N 추천 시스템의 정확도 향상을 목표로, 사용자‑아이템 행렬을 저랭크 가정하에 복원하는 새로운 알고리즘을 제안한다. 기존의 협업 필터링 기법은 크게 이웃 기반(ItemKNN), 모델 기반(MF, PureSVD, WRMF) 및 순위 기반(BPR, SLIM, LorSLIM)으로 구분되지만, 각각 데이터 희소성, 랭크 제약의 부정확성, 혹은 계산 복잡도 등의 한계를 가지고 있다. 특히, LorSLIM은 저랭크 제약을 핵노름으로 구현했지만, 비균등 샘플링 상황에서 편향된 해를 초래한다는 문제가 있다.
이를 해결하기 위해 저자들은 두 가지 핵심 아이디어를 도입한다. 첫 번째는 랭크 함수를 직접 근사하는 비선형 함수인 로그‑determinant(log‑det) 함수를 사용한다는 점이다. 로그‑det는 행렬 X의 특이값 σ_i에 대해 f(σ_i)=log(σ_i+1) 형태로 정의되며, 이는 특이값이 0에 가까울 때도 부드러운 페널티를 제공한다. 수학적으로 log‑det ≤ 핵노름이므로, 핵노름보다 더 타이트한 저랭크 근사를 제공한다. 두 번째는 증강 라그랑주 승수(ALM) 기반 최적화 프레임워크를 설계한다. 원문 문제는
min_X log det((XᵀX)^{1/2}+I) s.t. X_{ij}=M_{ij} (i,j)∈Ω, X≥0
와 같이 비선형 제약을 포함한다. 이를 위해 보조 변수 Y를 도입하고,
min_{X,Y} log det((XᵀX)^{1/2}+I)+𝟙_{X≥0}(Y) s.t. P_Ω(X)=P_Ω(M), X=Y
의 형태로 변형한다. 여기서 𝟙_{X≥0}는 비음수 제약을 나타내는 지시 함수이다. ALM은 라그랑주 승수 Z와 패널티 파라미터 μ를 도입해
L(X,Y,Z)=log det((XᵀX)^{1/2}+I)+𝟙_{X≥0}(Y)+ (μ/2)‖X−Y+Z/μ‖_F²
를 최소화한다.
알고리즘은 다음과 같이 진행된다. (1) 현재 Y와 Z를 고정하고 X를 업데이트한다. X‑업데이트는 특이값 분해 X=UΣVᵀ를 수행한 뒤, 각 특이값 σ_i에 대해
σ_i = arg min_{σ≥0} log(σ+1)+ (μ/2)(σ−σ_i^{(Y)}+Z_i/μ)²
를 풀어 얻는다. 이는 1/(1+σ)+μ(σ−σ_i^{(Y)}+Z_i/μ)=0 형태의 2차 방정식이며, 폐쇄형 해가 존재한다. 구해진 σ_i*를 이용해 X_{t+1}=U diag(σ_i*) Vᵀ를 구성하고, 관측값 위치는 원본 M으로 강제한다 (식 10). (2) Y‑업데이트는 비음수 제약만 남게 되므로,
Y_{t+1}=max(X_{t+1}+Z_t/μ, 0)
로 간단히 계산된다. (3) 라그랑주 승수 Z와 패널티 μ를 순차적으로 업데이트한다. μ는 γ>1 배씩 증가시켜 수렴 속도를 높인다. 전체 절차는 Algorithm 1에 요약된다.
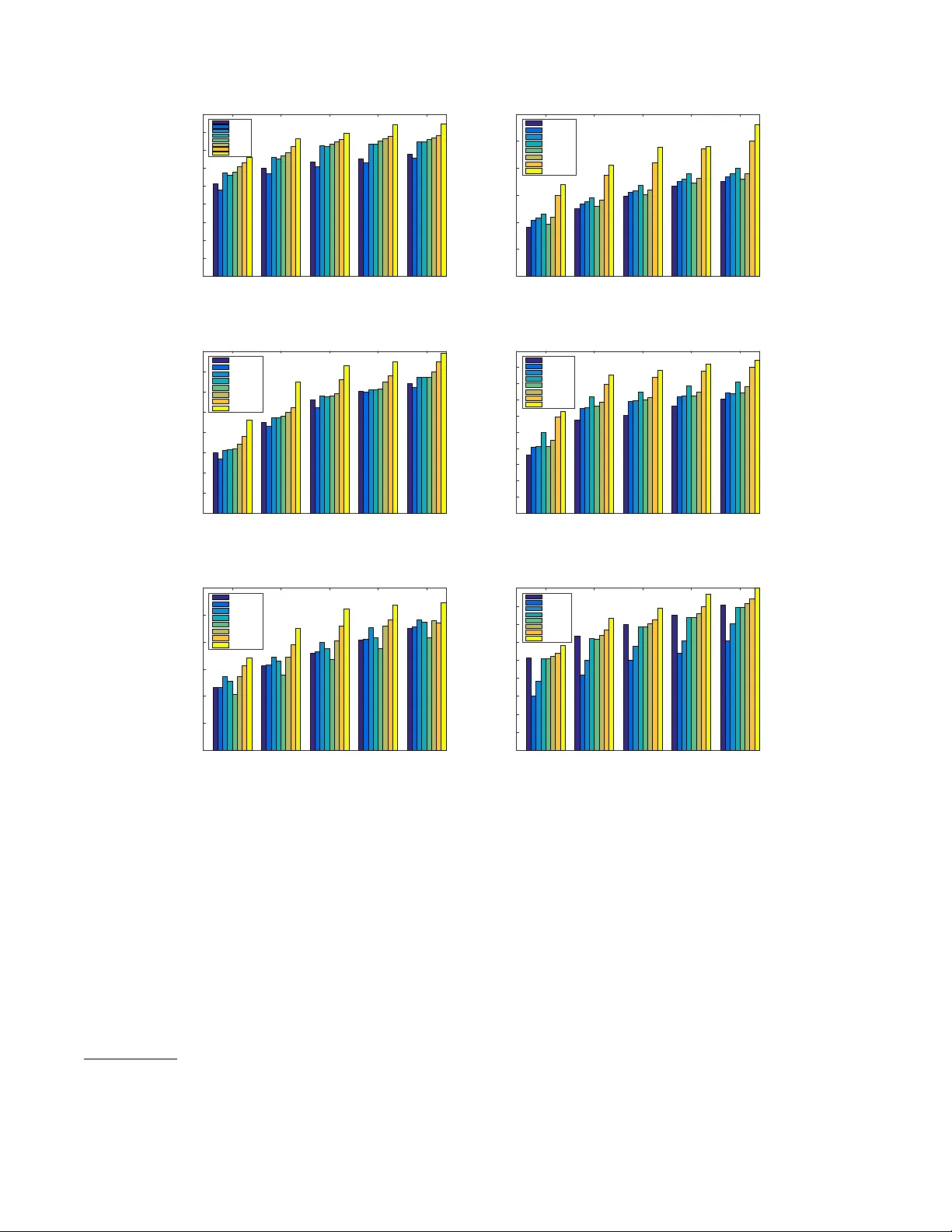
실험은 6개의 공개 데이터셋(Delicious, lastfm, BX, ML100K, Netflix, Yahoo)에서 5‑fold 교차 검증을 수행하였다. 각 데이터셋은 사용자·아이템 수, 평균 평점 수, 밀도 등 다양한 특성을 가지고 있어, 제안 방법의 일반화 능력을 검증한다. 평가 지표는 Top‑N( N=10) 추천에서 가장 널리 쓰이는 Hit‑Rate(HR)와 Average Reciprocal Hit Rank(ARHR)이다. HR은 테스트 아이템이 추천 리스트에 포함되는 비율을, ARHR은 포함된 위치에 따라 가중치를 부여한다.
표 2의 결과는 제안 방법이 모든 데이터셋에서 HR과 ARHR 모두 최고값을 기록함을 보여준다. 예를 들어, Netflix 데이터에서 기존 최고 성능을 보인 BPRMF(HR 0.210, ARHR 0.118)에 비해 제안 방법은 HR 0.226, ARHR 0.127을 달성했으며, 특히 희소도가 0.24%에 불과한 상황에서도 강건하게 작동한다. 또한, 기존 SLIM과 LorSLIM이 아이템 간 유사도 행렬을 학습하는 반면, 본 방법은 전체 사용자‑아이템 행렬 자체를 복원함으로써 더 풍부한 잠재 구조를 포착한다.
파라미터 설정 측면에서는 µ₀와 γ만을 조정했으며, 다른 하이퍼파라미터는 기존 방법과 동일하게 유지했다. 이는 알고리즘이 복잡한 정규화 파라미터 튜닝에 크게 의존하지 않음을 의미한다. 또한, 연산 복잡도는 매 반복마다 한 번의 SVD와 원소별 max 연산으로 구성돼, 대규모 실무 환경에서도 GPU 가속을 통해 실시간에 가까운 속도를 기대할 수 있다.
결론적으로, 이 논문은 (1) 로그‑det 함수를 통한 보다 정확한 저랭크 근사, (2) ALM 기반 효율적 비선형 최적화, (3) 다양한 데이터 특성에 대한 일관된 성능 향상이라는 세 축을 동시에 달성한다. 제안된 프레임워크는 기존 협업 필터링, 랭크 기반 모델, 순위 학습 모델을 대체하거나 보완할 수 있는 강력한 도구로, 향후 사용자 맞춤형 서비스, 콘텐츠 추천, 광고 배치 등 실무 응용에 널리 활용될 가능성이 크다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기