RNA 시퀀싱을 이용한 대안 스플라이싱 정량화
본 논문은 기존의 exon‑junction 카운트 기반 요약이 손실하는 정보를 보존하기 위해 exon path 라는 새로운 데이터 요약을 제안하고, 이를 기반으로 비모수적 편향 추정과 베이지안 혼합 모델을 구축한다. 제안 방법은 기존 방법에 비해 평균제곱오차가 수배 감소하고, 실험 복제 간 일관성이 크게 향상됨을 시뮬레이션 및 실제 RNA‑seq 데이터에서 입증한다. 구현은 R 패키지 **casper** 로 제공된다.
저자: David Rossell, Camille Stephan-Otto Attolini, Manuel Kroiss
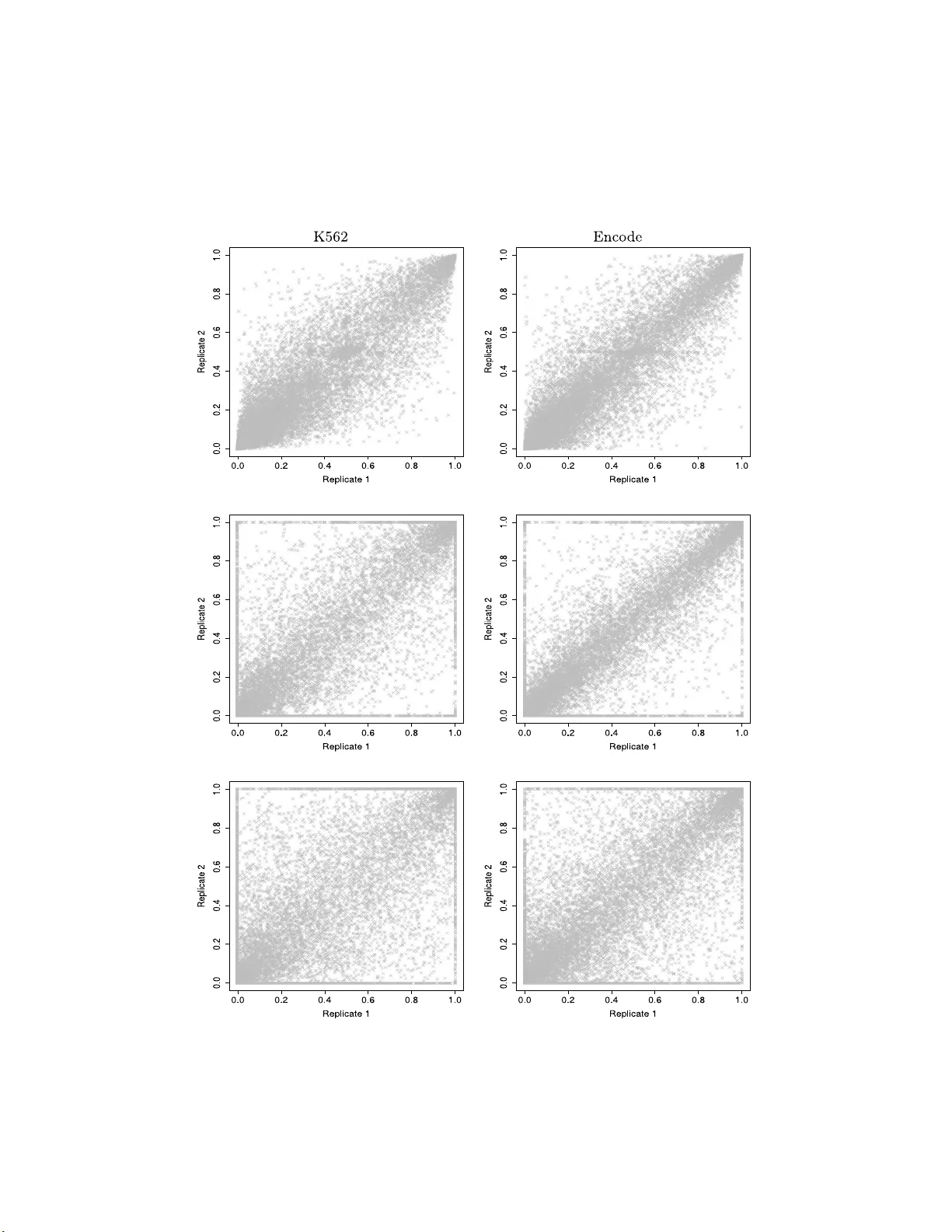
본 논문은 RNA‑seq 데이터를 이용한 대안 스플라이싱(AS) 정량화 문제를 새롭게 접근한다. 서론에서는 인간 유전체에서 AS가 얼마나 흔하며, 질병과 연관된 중요한 생물학적 현상임을 강조한다. 기존 방법은 주로 exon junction 혹은 exon coverage와 같은 제한된 요약을 사용해, fragment가 여러 exon을 동시에 관통하는 정보를 손실한다는 점을 지적한다. 특히 paired‑end 시퀀싱에서는 fragment가 두 개 이상의 exon을 연결하는 경우가 30 % 이상이며, 이는 단순 카운트만으로는 isoform을 정확히 구분하기 어렵게 만든다.
데이터 요약으로서 저자들은 “exon path”라는 새로운 개념을 도입한다. exon path는 왼쪽 read와 오른쪽 read가 각각 방문한 exon 집합을 순서대로 기록한 (ι_l, ι_r) 쌍이다. 예시로 제시된 가상의 유전자에서 세 가지 isoform이 존재하고, 세 개의 fragment가 각각 {1},{1,2},{3} 등 다양한 경로를 만든다. 이러한 경로는 동일한 exon set이라도 서로 다른 조합을 구분하게 해, fragment가 어느 isoform에서 유래했는지를 보다 정밀하게 추정할 수 있다.
수학적 모델링에서는 각 isoform d에 대한 비율 π_d를 Dirichlet 사전분포(q_1,…,q_|ν|) 로 두고, 관측된 exon path 카운트 x_k를 다항식 형태의 likelihood에 삽입한다. fragment의 시작 위치 S_i와 길이 L_i는 각각 P_S와 P_L이라는 확률분포를 따르며, 이 두 분포는 비모수적으로 추정한다. 실제로 P_S와 P_L은 유사한 특성을 가진 유전자 집합 내에서 공유된다고 가정하고, 커널 밀도 추정 등을 통해 데이터로부터 직접 학습한다. 이렇게 하면 편향을 사전에 추정하고, 이를 isoform 비율 추정에 반영할 수 있다.
모델 적합은 두 단계로 진행된다. 첫 번째는 P_S와 P_L을 비모수적으로 추정하는 단계이며, 두 번째는 추정된 p_{kd}=P(Y=k|δ=d)를 이용해 π를 최대우도 혹은 베이지안 사후 평균으로 추정한다. 로그우도가 concave이므로 전역 최적해가 존재하고, EM 알고리즘 혹은 직접적인 convex 최적화로 효율적으로 계산된다. 또한, 사후 분포를 샘플링해 신뢰구간을 제공하고, asymptotic credible interval을 계산한다.
시뮬레이션에서는 다양한 isoform 복잡도와 fragment 길이 분포를 변형시켜, 제안 모델이 평균제곱오차(MSE) 면에서 기존 Cufflinks, MISO, RSEM 등과 비교해 2~5배 정도 개선됨을 보였다. 실제 데이터에서는 ENCODE와 RGASP 프로젝트의 paired‑end 샘플을 사용해 복제 간 상관계수를 평가했으며, exon path 기반 모델이 기존 junction‑count 기반 모델보다 0.85 → 0.94 수준으로 일관성이 크게 상승했다. 또한, 비모수적 편향 추정이 fragment 길이와 시작 위치의 비대칭성, 다중 피크 등을 정확히 포착함을 시각화하였다.
논문의 마지막 부분에서는 구현과 확장성을 논한다. R 패키지 **casper**는 exon path 카운트 생성, 비모수적 편향 추정, 베이지안 추정 및 사후 샘플링을 일괄 제공한다. 또한, 새로운 isoform을 예측하는 외부 도구(Cufflinks, StringTie 등)와 연계하여, 기존 어노테이션에 없는 splice variant도 포함할 수 있는 확장성을 제공한다. 저자들은 이 프레임워크가 기존 파이프라인에 쉽게 통합될 수 있음을 강조하고, 향후 더 복잡한 실험 설계(예: 시간 시리즈, 다중 조건)에도 적용 가능함을 제시한다.
결론적으로, 이 연구는 RNA‑seq 기반 AS 정량화에서 데이터 요약 단계의 중요성을 재조명하고, exon path라는 풍부한 정보를 보존하는 새로운 요약과 비모수적 편향 추정을 결합한 베이지안 모델을 제시함으로써, 정확도와 재현성을 크게 향상시킨다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기