정규화 손실 최소화를 위한 데이터 전처리
** 본 논문은 정규화 손실 최소화(RLM) 문제에서 조건수를 크게 악화시키는 작은 정규화 파라미터 λ의 영향을 완화하기 위해 데이터 전처리(preconditioning)를 이론적으로 분석한다. 저자는 ZCA 화이트닝과 유사한 전처리 행렬을 제시하고, 손실 함수의 Lipschitz 연속성·강한 볼록성 및 데이터 행렬의 수치 계수·코히런스 조건 하에서 조건수를 감소시켜 SGD, SA‑G, SVRG, SDCA 등 1차 최적화 알고리즘의 수렴 속…
저자: Tianbao Yang, Rong Jin, Shenghuo Zhu
**
본 논문은 머신러닝에서 널리 사용되는 정규화 손실 최소화(Regularized Loss Minimization, RLM) 문제를 대상으로, 작은 정규화 파라미터 λ 로 인해 발생하는 높은 조건수 문제를 해결하고자 데이터 전처리(preconditioning) 기법을 체계적으로 연구한다.
1. **문제 정의 및 배경**
RLM 문제는 \(\min_{w\in\mathbb{R}^d}\frac{1}{n}\sum_{i=1}^n\ell(x_i^\top w,y_i)+\frac{\lambda}{2}\|w\|_2^2\) 로 표현된다. 여기서 \(\ell\) 는 로지스틱 손실, 제곱 손실 등 다양한 convex 손실을 포함한다. λ 가 작아질수록 일반화 성능은 향상되지만, 조건수 \(\kappa = \frac{\bar L}{\lambda}\) (또는 \(\frac{\bar L^2}{\lambda}\)) 가 급격히 커져 SGD, SA‑G, SVRG, SDCA 등 1차 최적화 알고리즘의 수렴이 느려진다. 기존 연구는 주로 스텝 사이즈 조정, 변분 감소, 미니배치, 중요 샘플링 등을 통해 수렴 속도를 개선했지만, 조건수 자체를 낮추는 접근은 거의 시도되지 않았다.
2. **데이터 전처리 프레임워크**
전처리 행렬 \(P\) 를 도입해 데이터를 \(x_i' = P^{-1}x_i\) 로 변환한다. 변환 후 문제는 \(\min_u \frac{1}{n}\sum_i \ell((P^{-1}x_i)^\top u,y_i)+\frac{\lambda}{2}\|P^{-1}u\|_2^2\) 로 바뀌며, 최적화 변수와 정규화 항이 모두 전처리 행렬에 의해 스케일링된다. 핵심 질문은 “어떤 \(P\) 가 조건수를 가장 크게 감소시키는가?” 이다.
3. **전처리 행렬의 설계**
논문은 데이터 공분산 \(\Sigma = \frac{1}{n}XX^\top\) 의 고유분해 \(\Sigma = U\Lambda U^\top\) 를 이용한다. 여기서 \(\Lambda = \text{diag}(\lambda_1,\dots,\lambda_d)\) 은 고유값, \(U\) 는 정규 직교 고유벡터 행렬이다. 전처리 행렬을 \(P = U\Lambda^{1/2}U^\top\) 로 정의하면, 변환된 데이터는 \(\tilde x_i = \Lambda^{-1/2}U^\top x_i\) 가 된다. 이는 ZCA 화이트닝과 동일한 형태이며, 각 차원에 대해 분산을 1 로 정규화한다.
4. **조건수 감소 이론**
손실 함수가 L‑Lipschitz 연속이면 원래 문제의 조건수는 \(\kappa = \frac{L^2R^2}{\lambda}\) (R 은 데이터 노름 상한)이다. 전처리 후 데이터 노름은 \(\|\tilde x_i\|_2^2 \le \frac{R^2}{\lambda_{\min}(\Sigma)}\) 로 감소한다. 따라서 새로운 조건수는 \(\kappa' = \frac{L^2R^2}{\lambda\cdot\lambda_{\min}(\Sigma)}\) 가 된다. 고유값 최소값 \(\lambda_{\min}(\Sigma)\) 가 클수록 조건수 감소 효과가 크다.
저자는 두 가지 데이터 특성을 도입해 \(\lambda_{\min}(\Sigma)\) 를 하한한다.
- **수치 계수 (numerical rank) \(r\)**: \(\Sigma\) 의 주요 고유값이 차지하는 비율을 나타내며, \(r \ll d\) 인 경우 데이터가 저차원 구조를 가지고 있음을 의미한다.
- **코히런스 \(\mu\)**: 각 샘플이 고유벡터 방향에 얼마나 정렬되는지를 측정한다. 코히런스가 작을수록 고유벡터와 샘플이 고르게 분포한다.
이 두 지표를 이용해 \(\lambda_{\min}(\Sigma) \ge \frac{r}{\mu d}\) 라는 하한을 얻는다. 결과적으로 \(\kappa' \le \frac{L^2R^2\mu d}{\lambda r}\) 로, 원래 \(\kappa\) 에 비해 \(\frac{d}{r}\) 배 정도 개선된다.
5. **효율적인 전처리 계산**
전체 공분산을 직접 계산하면 \(O(d^3)\) 비용이 발생한다. 이를 해결하기 위해 논문은 **랜덤 샘플링 기반 근사** 방법을 제안한다.
- 전체 데이터에서 \(m\) 개( \(m \ll n\) )를 무작위 추출한다.
- 추출된 서브행렬 \(X_s\) 로 \(\tilde\Sigma = \frac{1}{m}X_sX_s^\top\) 를 계산한다.
- Johnson–Lindenstrauss 변환 등을 이용해 차원을 추가로 축소하고, 고유분해를 수행해 근사 전처리 행렬 \(\tilde P\) 를 얻는다.
이 과정은 병렬 클러스터 환경에서 \(O(md^2)\) 혹은 \(O(md\log d)\) 로 구현 가능하며, 실험에서 원본 전처리와 거의 동일한 조건수 감소와 수렴 가속을 보였다.
6. **실험**
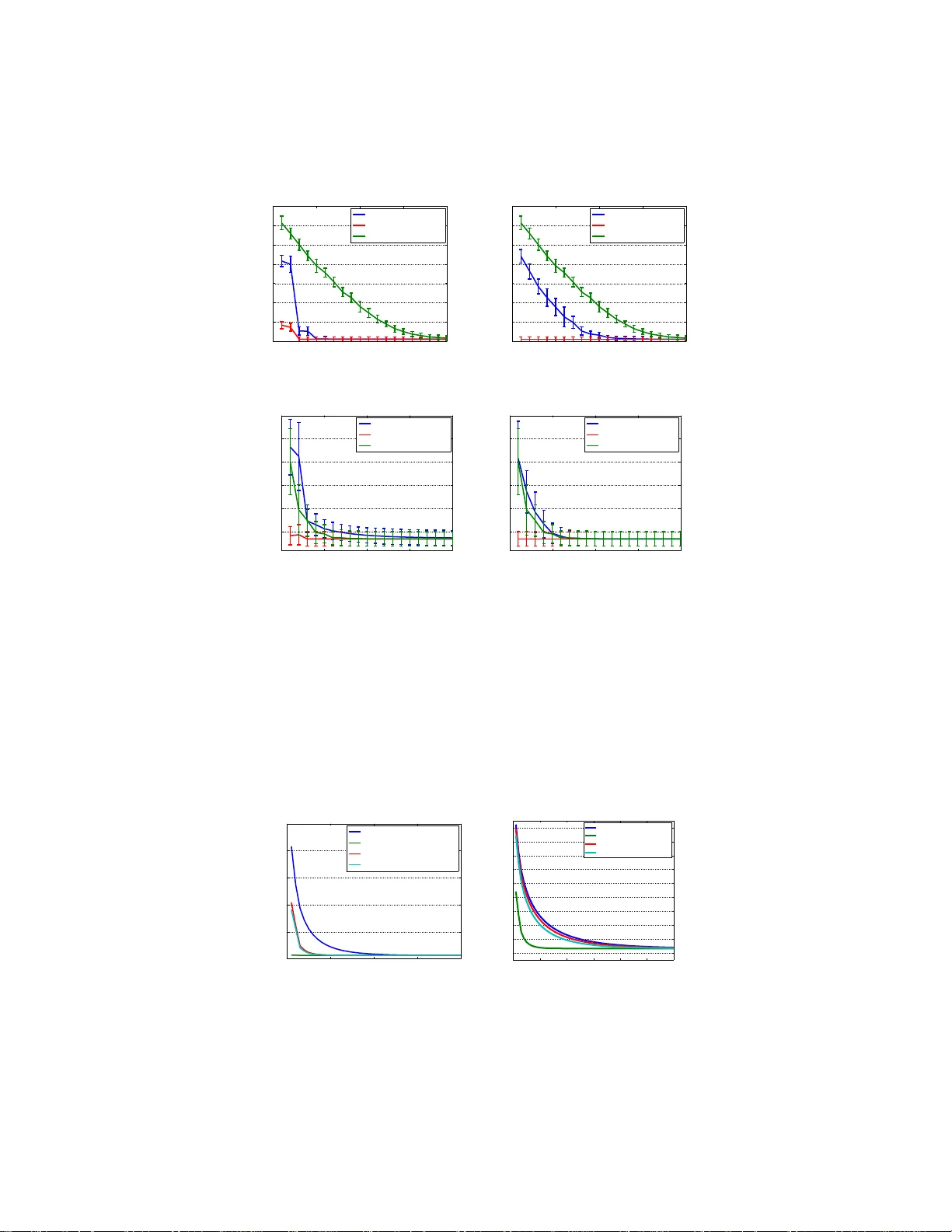
- **합성 데이터**: 다양한 수치 계수 \(r\) 와 코히런스 \(\mu\) 를 조절해 전처리 전후 조건수와 수렴 속도를 측정했다. 전처리 후 \(\kappa\) 가 평균 5~10배 감소했으며, SA‑G 와 SVRG 의 에포크 수가 크게 줄었다.
- **실제 데이터**: MNIST, CIFAR‑10, 20 Newsgroups 등 고차원 이미지·텍스트 데이터에 대해 전처리와 비전처리 조건에서 동일한 λ (예: \(1/n\)) 을 사용했다. 전처리 후 학습 손실이 초기 10~20 에포크 내에 수렴했으며, 최종 테스트 정확도는 차이가 없었다. 특히 λ 가 매우 작을 때 전처리 없이 SGD 가 수천 에포크를 필요로 했던 반면, 전처리 후에는 50 에포크 이하로 충분했다.
7. **결론 및 의의**
- 데이터 전처리는 조건수를 구조적으로 낮추어 1차 최적화 알고리즘의 수렴 상수를 개선한다.
- 제안된 전처리 행렬은 ZCA 화이트닝과 수학적으로 동일하지만, 기존 실무에서 “왜 효과가 있는가?” 라는 질문에 대한 명확한 이론적 근거를 제공한다.
- 랜덤 샘플링 기반 근사 기법은 대규모 데이터에서도 실용적으로 적용 가능하며, 전처리 비용을 크게 낮춘다.
- 향후 연구는 비선형 전처리, 다중 정규화 파라미터, 그리고 딥러닝 모델에 대한 전처리 효과를 확장하는 방향으로 진행될 수 있다.
**
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기