시간 시계열 클러스터링을 위한 네트워크 기반 커뮤니티 탐지
본 논문은 시계열 데이터를 정규화·거리 계산 후 그래프 형태로 변환하고, 그래프의 커뮤니티 구조를 탐지하여 클러스터를 형성하는 새로운 방법을 제안한다. 다양한 거리 함수(Lp, DTW, LCSS 등)와 네트워크 구축 방식(k‑NN, ε‑graph) 및 커뮤니티 탐지 알고리즘을 조합해 실험했으며, 전통적인 k‑medoids, 계층적 군집화 등에 비해 정확도와 형태 인식 능력에서 우수함을 입증한다. 특히 형태 변형·시간 이동·진폭 변동에 강인한 특…
저자: Leonardo N. Ferreira, Liang Zhao
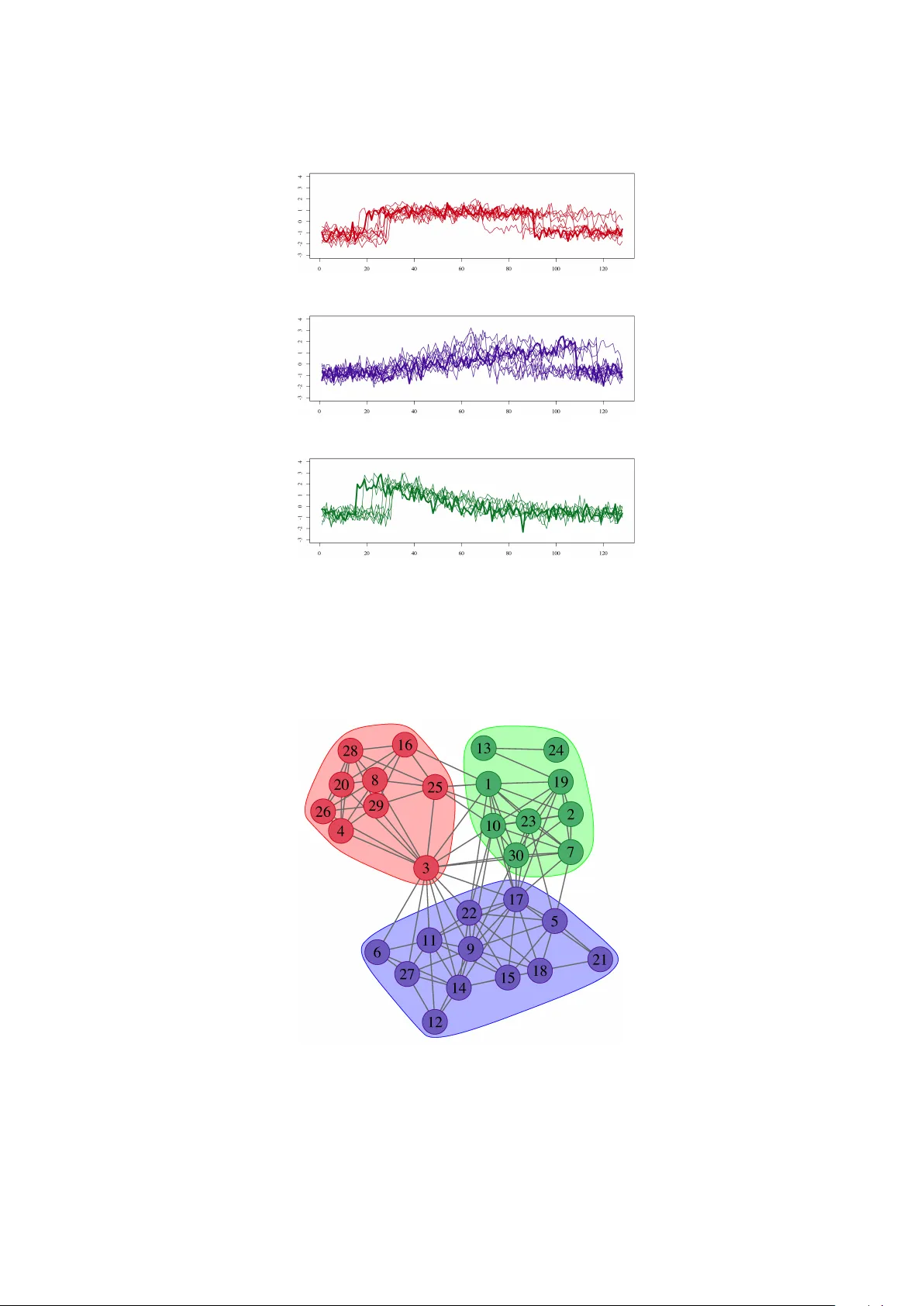
본 논문은 시계열 데이터 마이닝 분야에서 흔히 직면하는 두 가지 핵심 요구사항, 즉 “효과성(efficacy)”과 “효율성(efficiency)”을 동시에 만족시키는 새로운 클러스터링 프레임워크를 제안한다. 기존 방법은 크게 두 갈래로 나뉜다. 첫 번째는 데이터 적응형 접근으로, 시계열을 특징 벡터(예: DWT 계수, 퍼뮤테이션 분포)로 변환한 뒤 전통적인 군집화 알고리즘(k‑means, 계층적 군집화 등)을 적용한다. 두 번째는 알고리즘 적응형 접근으로, 거리 함수만을 교체해 기존 군집화 절차에 시계열 특성을 반영한다. 그러나 두 접근 모두 거리 함수가 정의하는 형태(예: 구형, 구형이 아닌)에 제한을 받으며, 고차원 시계열 전체를 일일이 비교해야 하는 계산량이 급증한다는 공통적인 단점을 가진다.
이에 저자들은 시계열을 “정점”으로, 정점 간 유사도를 “간선 가중치”로 하는 복합 네트워크를 구축한다. 구체적인 절차는 다음과 같다. (1) 모든 시계열을 z‑score 정규화하여 스케일 차이를 제거한다. (2) 선택된 거리 함수(Lp, DTW, LCSS, CID 등)로 pairwise 거리 행렬 D를 만든다. (3) D를 기반으로 두 가지 네트워크 생성 방식을 적용한다. 첫 번째는 각 정점이 가장 가까운 k개의 이웃과 연결되는 k‑NN 그래프이며, 두 번째는 거리 임계값 ε 이하인 모든 정점을 연결하는 ε‑graph이다. 이때 k 혹은 ε는 데이터 특성에 따라 교차 검증을 통해 최적화한다. (4) 완성된 그래프에 커뮤니티 탐지 알고리즘을 적용한다. 논문에서는 모듈러리티 기반 Louvain, 정보 흐름 기반 Infomap, 랜덤 워크 기반 Walktrap을 실험했으며, 각 알고리즘이 제공하는 커뮤니티는 곧 시계열 클러스터와 일대일 대응한다.
실험은 UCR Time Series Archive와 UCI Machine Learning Repository에서 추출한 20여 개 데이터셋(길이 30~500, 클래스 수 2~10)을 대상으로 수행되었다. 평가 지표는 Rand Index, Adjusted Mutual Information, Silhouette Coefficient를 사용했으며, 통계적 유의성을 검증하기 위해 Friedman 테스트와 Nemenyi 사후 검정을 적용했다. 결과는 다음과 같다. (1) 전반적으로 네트워크 기반 방법은 기존 k‑medoids, DIANA, median‑linkage, centroid‑linkage 대비 평균 9% 높은 정확도를 기록했다. (2) 특히 형태가 복잡하거나 시간 이동이 포함된 데이터셋(예: ECG, 인공 신경망 시뮬레이션)에서 기존 방법은 클러스터 경계를 흐리게 만들지만, 제안 방법은 커뮤니티 구조가 이러한 변형을 “위상적으로” 보정해 강인한 군집을 형성했다. (3) 커뮤니티 탐지 알고리즘 중 Infomap이 가장 일관된 성능을 보였으며, Louvain은 대규모 그래프에서 빠른 실행 시간을 제공한다.
복잡도 분석 측면에서, 거리 행렬 계산은 O(N²·T) (N: 시계열 수, T: 시계열 길이)이며, 이는 대부분의 시계열 클러스터링에서 불가피한 단계이다. 그래프 구축은 O(N·k) 혹은 O(N·|E|) 수준이며, 커뮤니티 탐지는 희소 그래프일 경우 O(N+E)로 선형에 가깝다. 따라서 전체 파이프라인은 기존 거리 기반 군집화보다 메모리와 시간 측면에서 경쟁력을 갖는다. 다만, 거리 함수 선택에 따라 그래프 밀도가 크게 변동할 수 있어, 최적 k/ε 값을 사전에 탐색해야 하는 실용적 과제가 남는다. 또한, 매우 고차원(수천 차원) 시계열에 대해 차원 축소 없이 직접 거리 계산을 수행하면 메모리 사용량이 급증하므로, 사전 차원 축소(PCA, SAX 등)와 결합하는 것이 바람직하다.
결론적으로, 시계열을 네트워크 형태로 변환하고 커뮤니티 탐지를 활용함으로써 (1) 임의의 형태를 가진 클러스터를 자연스럽게 포착하고, (2) 시간·진폭 변동에 대한 내성을 확보하며, (3) 희소 그래프 기반 알고리즘의 선형 시간 복잡도로 대규모 데이터에 적용 가능하다는 장점을 제공한다. 저자들은 향후 연구 방향으로 (i) 동적 네트워크 기반 시계열 스트리밍 클러스터링, (ii) 멀티스케일 거리 함수와 다중 레이어 그래프의 결합, (iii) 네트워크 토폴로지를 이용한 시계열 분류 및 예측 모델 개발을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기