데이터센터 자동화를 위한 데이터 기반 고장 예측 모델 연구
본 논문은 구글 12 K노드 클러스터 로그를 활용해 24시간 이내 노드 고장을 예측하는 모델을 구축한다. 빅쿼리로 수백 테라바이트 데이터를 전처리·특징 추출하고, 랜덤 포레스트 기반 앙상블 분류기를 적용해 5 % 이하의 위양성률을 유지하면서 27 %~88 %의 재현율을 달성하였다. 결과는 데이터‑드리븐 자동화 관리 시스템에 적용 가능함을 시사한다.
저자: Alina S^irbu, Ozalp Babaoglu
현대 데이터센터는 인터넷 서비스의 근간을 이루며, 그 규모가 급격히 확대됨에 따라 운영 인력의 한계가 심각한 병목으로 작용한다. 기존 자동화 도구는 자원 할당·스케줄링 정도에 머물러 있어, 장애 발생 후에야 복구 조치를 취하는 반응형 방식이다. 저자들은 이러한 한계를 극복하고자 ‘데이터‑드리븐 자동화’를 제안한다. 이는 로그, 전력·냉각·네트워크 등 다양한 센서 데이터를 통합해 전체 시스템을 하나의 생태계로 모델링하고, 머신러닝 기반 예측 모델을 지속적으로 학습·갱신함으로써 사전 예방적 제어를 가능하게 한다.
연구에 사용된 데이터는 구글이 공개한 Borg 클러스터 트레이스로, 12 453대의 머신에서 29일간 수집된 작업 이벤트와 사용량 로그를 포함한다. 총 100 억 건 이상의 작업 이벤트와 1 천억 건 이상의 사용량 레코드가 12 TB 규모의 테이블에 저장돼 있다. 저자들은 Google Cloud의 BigQuery를 활용해 SQL‑like 쿼리로 데이터를 집계하고, 5분 간격으로 12개의 기본 특성을 추출했다. 여기에는 현재 실행 중인 작업 수, 최근 5분간 시작·종료·실패·퇴출·소실된 작업 수, 그리고 CPU·메모리·디스크 시간·CPI·MAI와 같은 부하 지표가 포함된다.
다음 단계에서는 각 기본 특성에 대해 최근 30분(6개 5분 윈도우) 동안의 평균, 표준편차, 변동계수(CV)를 계산해 216개의 파생 특성을 만든다. 또한, 7개의 핵심 특성(실행 작업 수, 시작 작업 수, 실패 작업 수, CPU, 메모리, 디스크 시간, CPI) 간 상관관계를 1~96시간 윈도우별로 21쌍씩 구해 126개의 상관 특성을 추가했다. 이 과정을 통해 최종적으로 416개의 특성을 확보했으며, 전체 데이터 포인트는 104 197 215개(≈300 GB)이다.
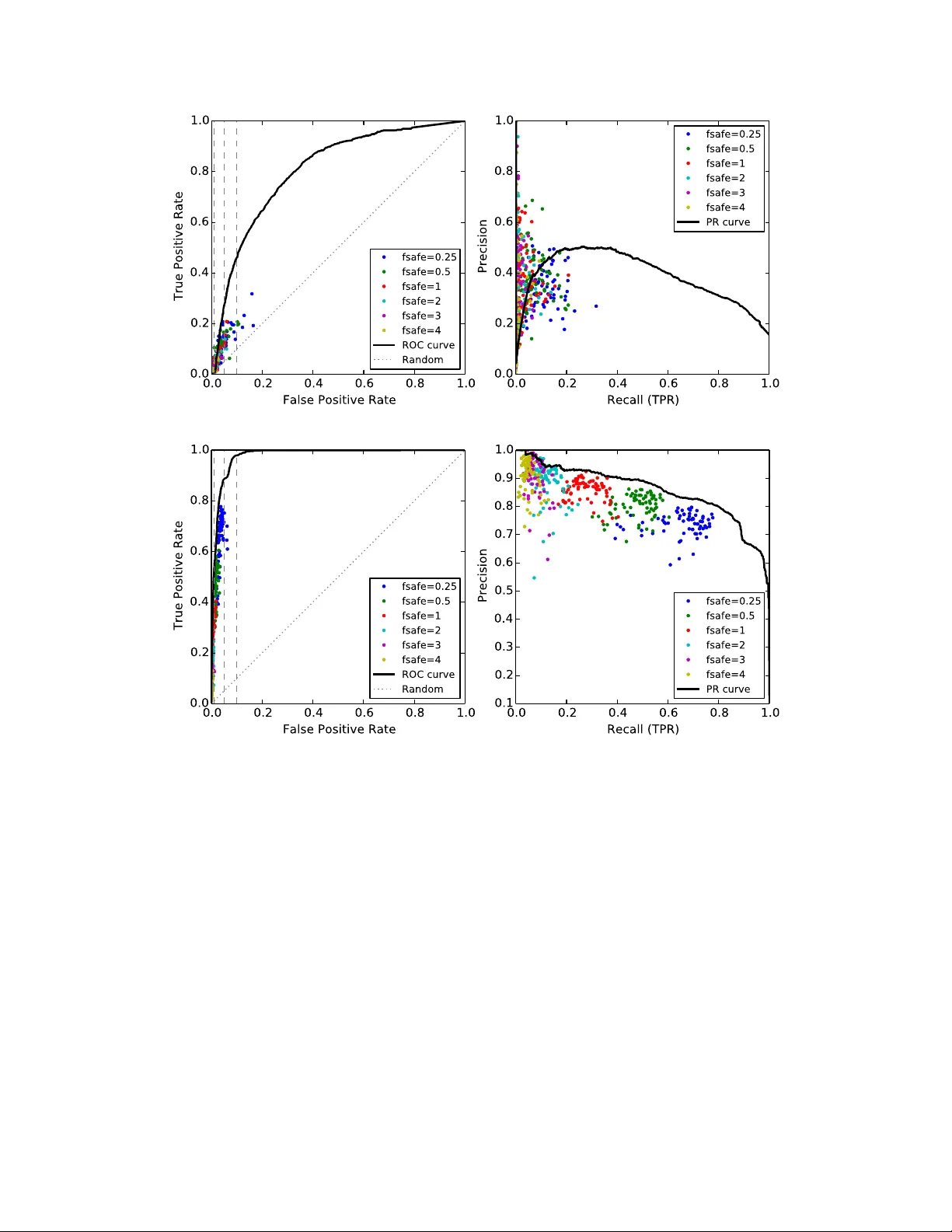
고장 라벨링은 ‘REMOVE’ 이벤트를 기준으로 수행했다. REMOVE 이벤트가 발생한 후 동일 머신에 대한 다음 ‘ADD’ 이벤트까지의 다운 타임이 2시간 이상이면 실제 하드웨어 고장으로 간주하고, 이를 ‘FAIL’ 클래스에 할당했다. 전체 REMOVE 이벤트 중 2 298건이 고장으로 분류됐으며, 이들을 목표 라벨로 삼았다. 안전 클래스는 전체 데이터 중 0.5%만 무작위 추출해 불균형을 완화했고, 최종 학습 데이터는 108 365개의 FAIL 포인트와 544 985개의 SAFE 포인트(총 653 350개)로 구성됐다.
분류 모델은 Random Forest를 기반으로 하며, 다수의 RF를 독립적으로 학습시킨 뒤 bagging과 데이터 서브샘플링을 결합한 앙상블을 구축했다. 각 RF는 서로 다른 특성 서브셋과 데이터 서브셋을 사용해 다양성을 확보하고, 최종 예측에서는 정밀도 가중 투표 방식을 적용해 소수 클래스에 대한 재현율을 높였다. 모델은 24시간 이내에 발생할 고장을 예측하도록 설계됐으며, 평가 지표는 위양성률(FPR) 5 % 이하에서의 재현율(TPR)과 정밀도(P)였다.
실험 결과는 일별로 변동이 있었지만, 최고 성능일 때 TPR 88 %와 P 72 %를 달성했다. 최저 성능일 때도 TPR 27 %와 P 50 %를 유지했으며, 모든 경우에서 FPR은 5 % 이하였다. 이러한 성능은 기존 연구와 비교해 동등하거나 우수한 수준이며, 특히 대규모 로그 데이터를 실시간 스트리밍 환경에 적용할 수 있다는 점에서 실용성이 강조된다.
BigQuery를 활용한 데이터 처리 과정도 상세히 보고했다. 기본 특성 집계는 1 시간 윈도우당 139~939초, 부하 특성은 3 585~9 096초가 소요됐으며, 전체 416개 특성을 포함한 최종 테이블은 7 GB(104 M 행) 규모였다. 장시간 윈도우(1~96시간) 평균·표준편차·CV 계산은 197~960초, 상관관계 계산은 49.6 GB~4.33 TB의 데이터를 처리해 5 USD/TB 비용이 발생했다. 이러한 비용·시간 분석은 클라우드 기반 대규모 데이터 파이프라인 설계 시 중요한 참고 자료가 된다.
마지막으로, 저자들은 예측 모델을 데이터‑드리븐 자동화 관리자의 핵심 의사결정 모듈로 배치하고, 실시간 로그 스트림을 통해 지속적으로 모델을 업데이트하는 아키텍처를 제안한다. 모델 출력은 고장 가능성이 높은 머신을 사전에 식별해, 사전 점검·재배치·예방적 유지보수 작업을 트리거한다. 이를 통해 운영 인력의 부담을 크게 줄이고, 데이터센터의 가용성을 향상시킬 수 있다.
결론적으로, 이 논문은 (1) 빅데이터 플랫폼을 이용한 대규모 로그 전처리와 풍부한 특성 생성 방법, (2) 불균형 데이터에 강인한 랜덤 포레스트 앙상블 설계, (3) 실제 데이터센터 운영에 적용 가능한 예측 성능 입증, (4) 비용·시간 효율성을 고려한 클라우드 기반 구현 방안을 모두 제시함으로써, 데이터‑드리븐 자동화의 실현 가능성을 실증적으로 보여준다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기