경쟁적 분포 추정
본 논문은 샘플로부터 알파벳 크기 k 에 관계없이 KL 발산 손실을 최소화하는 새로운 경쟁적 프레임워크를 제시한다. 오라클이 (1) 심볼 순열만 알거나 (2) 정확한 분포를 알지만 “자연스러운” 추정기만 사용할 때, 제안된 알고리즘은 경쟁적 후회를 min(k/n, ~O(1/√n)) 으로 제한한다. 선형 시간 구현과 실험을 통해 이 경계가 최적임을 확인한다.
저자: Alon Orlitsky, An, a Theertha Suresh
**1. 서론 및 배경**
분포 추정 문제는 샘플 X₁,…,Xₙ 이 i.i.d. p 에서 생성될 때, p 를 KL 발산 D(p‖q) 관점에서 얼마나 정확히 복원할 수 있는지를 묻는다. 기존 최소‑최대 분석에 따르면, 전체 단순체 Δₖ 에 대해 최적 후회는 rₙ(Δₖ) ≈ (k‑1)/(2n) 이며, 이는 k 가 n 보다 크게 증가하면 손실이 상수 수준에 머무른다. 하지만 실제 응용에서는 k 가 n 과 비슷하거나 더 클 때가 많아, 보다 강건한 방법이 요구된다.
**2. 경쟁적 프레임워크 정의**
오라클이 완전 정보를 갖는 경우와 달리, 두 가지 제한을 고려한다.
- **(a) 순열 등가 클래스**: 오라클은 p 의 정확한 심볼 라벨을 모른다. 대신 p 와 같은 확률 다중집합(순열에 불변)만 안다. 이는 파티션 P_σ 을 형성한다.
- **(b) 자연스러운 추정기**: 오라클은 p 를 완전히 안다. 하지만 추정기는 “자연스러워야” 한다. 즉, 동일 빈도 t 를 가진 모든 심볼에 동일 확률을 할당한다.
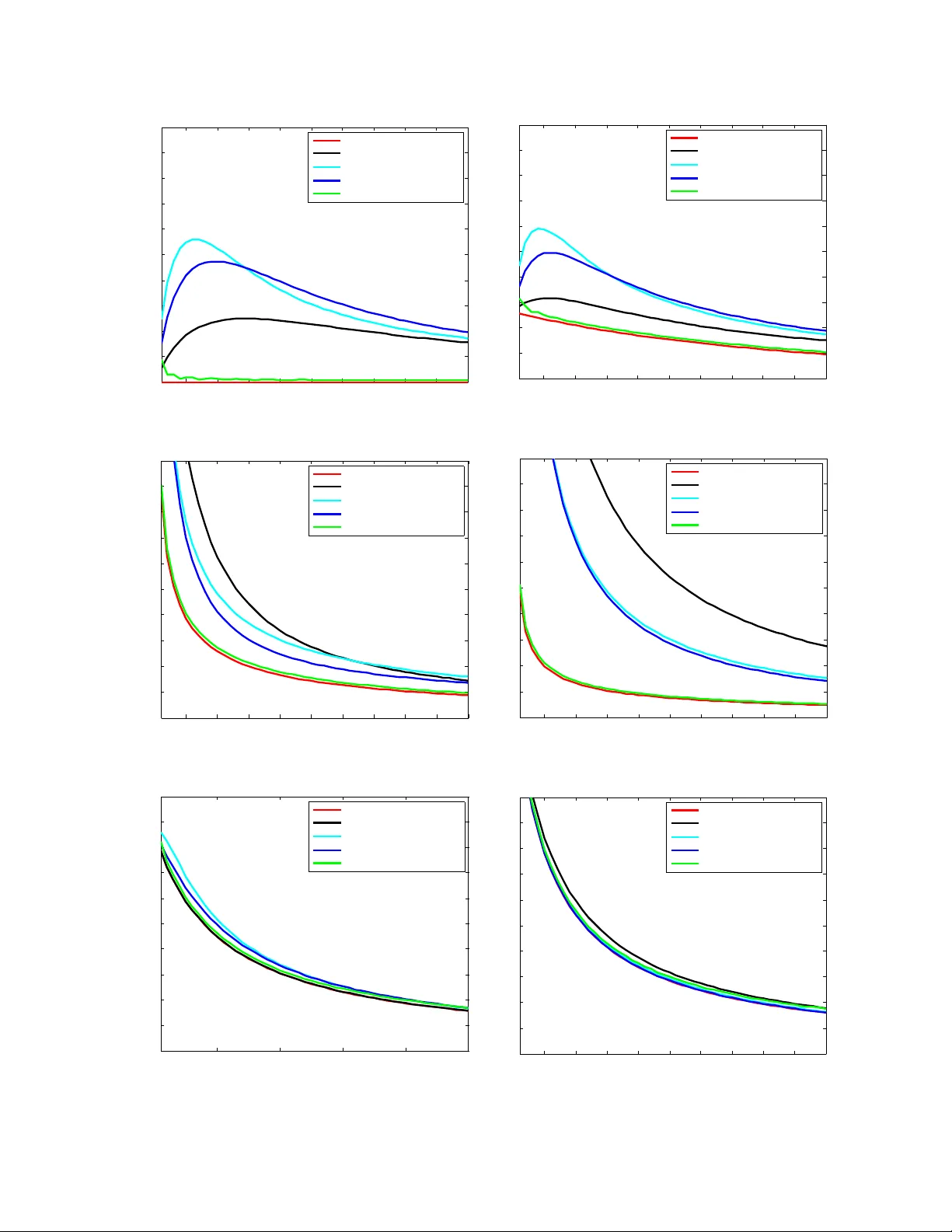
각 경우에 대해 경쟁적 후회는
\
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기