이중 강인 정책 평가와 최적화
본 논문은 컨텍스트 밴드잇 환경에서 새로운 정책의 가치를 오프라인 데이터로 평가하고 최적화하기 위해 이중 강인(Doubly Robust) 추정기를 도입한다. 보상 모델과 탐색 정책 중 하나만 정확하면 편향이 없으며, 기존의 직접 추정(DM)과 역확률 가중치(IPS) 방식보다 분산이 크게 감소한다. 이론적 비대칭 비정상성 분석과 실험을 통해 제안 방법이 전반적으로 더 정확하고 안정적임을 입증한다.
저자: Miroslav Dudik, Dumitru Erhan, John Langford
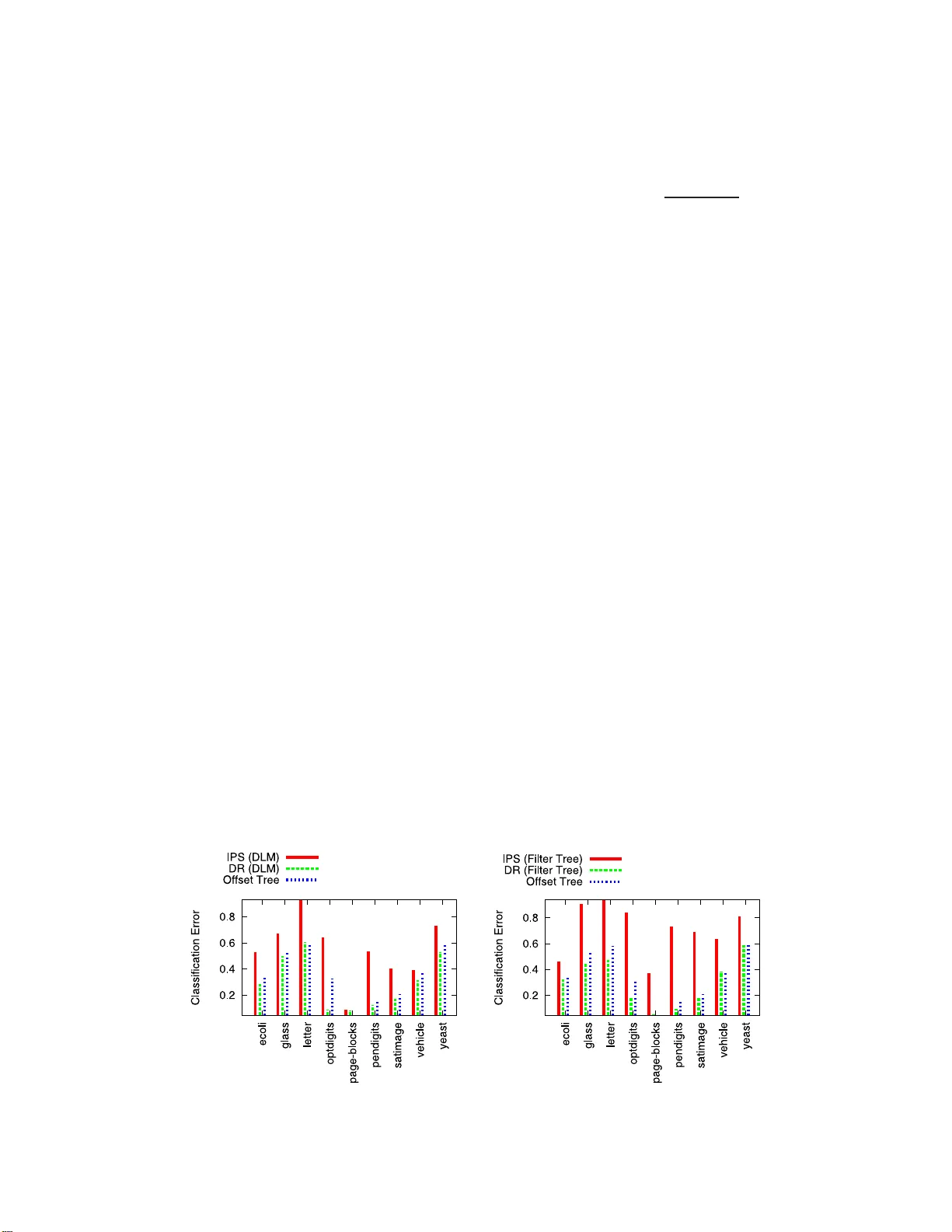
본 논문은 컨텍스트 밴드잇(contextual bandit)이라는 순차적 의사결정 문제를 다룬다. 이 문제는 매 라운드마다 컨텍스트 \(x\)가 주어지고, 행동 \(a\)를 선택하면 보상 \(r\)이 관측되지만, 선택하지 않은 행동에 대한 보상은 전혀 알 수 없는 상황이다. 실제 서비스(광고, 콘텐츠 추천, 맞춤형 의료 등)에서는 과거 로그 데이터를 이용해 새로운 정책 \(\nu\)의 기대 보상 \(V(\nu)\)를 오프라인에서 추정하고, 최적의 정책을 설계해야 한다.
전통적인 두 접근법은 (1) 직접 방법(DM)으로, 보상 함수를 \(\hat r(x,a)\)로 추정하고 이를 정책에 대입해 \(\hat V_{\text{DM}} = \frac{1}{n}\sum_{k}\sum_{a}\nu(a|x_k)\hat r(x_k,a)\) 로 평가한다. 이 방법은 보상 모델이 정확해야 편향이 작지만, 실제로는 모델링 오류가 크게 발생한다. (2) 역확률 가중치(IPS) 방법으로, 과거 정책 \(\mu\)의 행동 확률을 이용해 \(\hat V_{\text{IPS}} = \frac{1}{n}\sum_{k}\frac{\nu(a_k|x_k)}{\mu(a_k|x_k)}r_k\) 로 추정한다. IPS는 보상 모델이 필요 없지만, \(\mu\)와 \(\nu\)가 크게 다르면 가중치가 폭발해 분산이 급증한다.
이 두 방법의 장단점을 동시에 보완하고자 저자들은 ‘이중 강인(Doubly Robust, DR)’ 추정기를 도입한다. DR 추정식은
\
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기