대규모 멀티태스크 신경망으로 약물 발견 가속화
본 논문은 200여 개 이상의 생물학적 타깃에 대해 4천만 건에 달하는 공개 데이터를 수집하고, 이를 기반으로 다중 작업 신경망(Multitask Neural Network)을 학습시켜 단일 작업 모델보다 뛰어난 예측 성능을 입증한다. 작업 수와 데이터 양이 증가할수록 성능이 지속적으로 향상되며, 제한된 전이 학습 능력도 확인한다.
저자: Bharath Ramsundar, Steven Kearnes, Patrick Riley
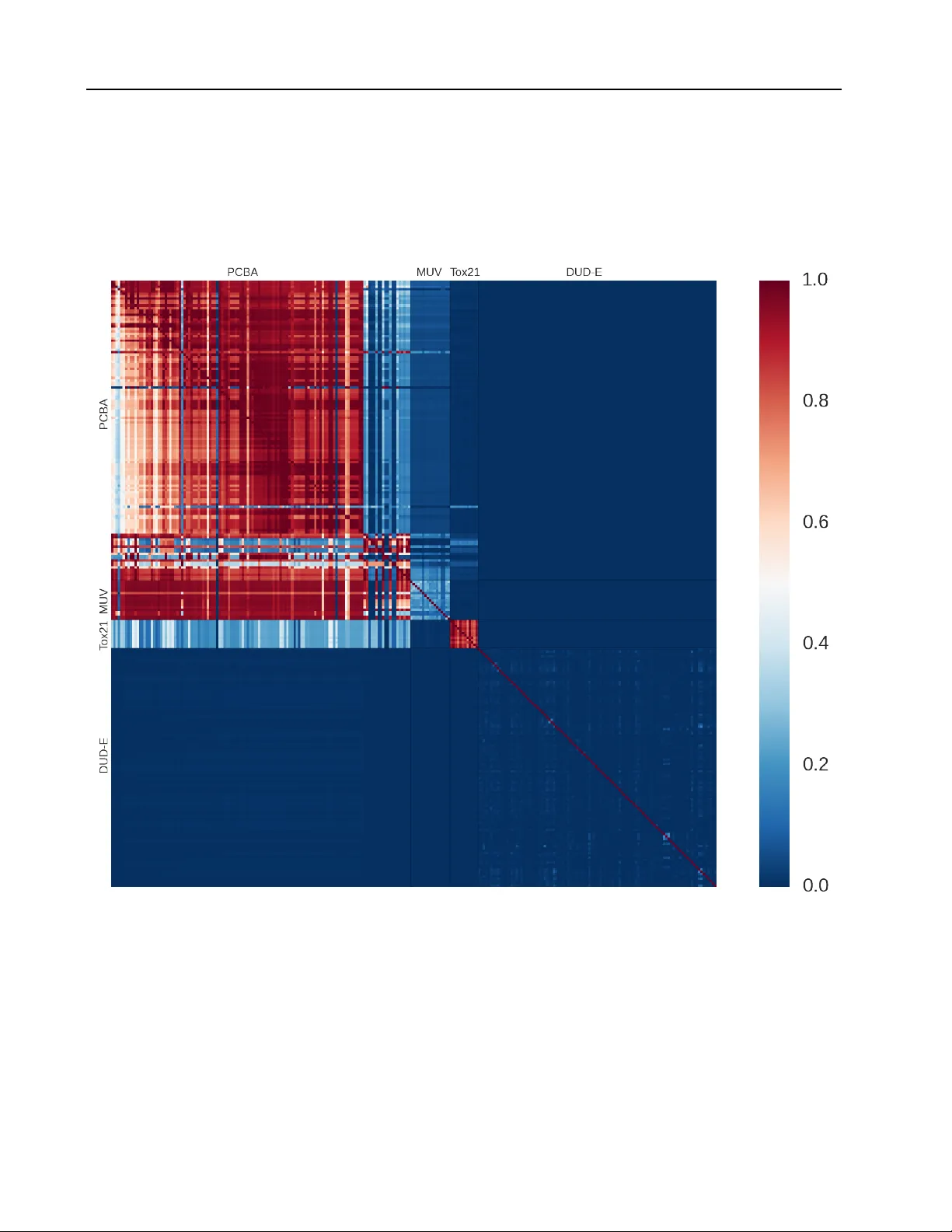
본 논문은 약물 발견 과정에서 발생하는 데이터 부족, 불균형, 그리고 실험 비용 문제를 해결하고자 ‘대규모 멀티태스크 신경망(Massively Multitask Networks)’이라는 새로운 학습 프레임워크를 제안한다. 저자들은 공개된 화학·생물학 데이터베이스인 PubChem BioAssay, MUV, DUD‑E, Tox21 등을 활용해 259개의 개별 데이터셋을 구성했으며, 이들 데이터셋은 총 3,780만 건의 실험 측정값과 160만 개의 화합물을 포함한다. 각 화합물은 RDKit을 이용해 ECFP4(1024‑비트) 피처로 변환했으며, 일부 결함이 있는 화합물은 제외하였다.
모델 설계는 크게 네 부분으로 구성된다. 첫 번째는 입력 레이어(1024개의 바이너리 노드)이며, 두 번째와 세 번째는 각각 2000노드와 100노드로 구성된 피라미드형 은닉층이다. 이 구조는 넓은 저차원 공간에서 복잡한 특성을 학습하고, 이후 좁은 고차원 공간으로 차원을 축소함으로써 각 작업별 파라미터 수를 크게 감소시킨다. 네 번째는 각 작업(데이터셋)마다 독립적인 소프트맥스 출력층을 두어 이진 분류를 수행한다. 활성화 함수는 ReLU를 사용했으며, 과적합 방지를 위해 드롭아웃(0.25)과 L2 정규화가 적용되었다.
평가 방법으로는 데이터 불균형을 고려해 stratified 5‑fold 교차 검증을 수행했으며, ROC‑AUC를 주요 성능 지표로 채택했다. DUD‑E 데이터셋은 모든 모델이 AUC≥0.99를 기록해 비교가 어려웠으므로, 통계 분석에서는 제외하였다. 실험 결과, 피라미드형 멀티태스크 네트워크(PMTNN)는 로지스틱 회귀(LR), 랜덤 포레스트(RF), 단일 작업 신경망(STNN), 그리고 퍼포먼스 최적화된 단일 작업 네트워크(PSTNN) 등 기존 방법들을 전반적으로 능가했다. 특히, 평균 AUC와 중앙값 AUC 모두 0.01 이하의 차이로 거의 동일한 수준이었으며, 이는 멀티태스크 학습이 작은 데이터셋에서도 안정적인 성능 향상을 제공함을 의미한다.
다음으로 작업 수와 데이터 양이 성능에 미치는 영향을 조사하였다. 10, 20, 40, 80, 160, 249개의 작업을 포함하는 서브셋을 각각 학습시킨 결과, AUC는 꾸준히 상승했으며 ‘계속 상승(still climbing)’ 형태의 성장 곡선을 보였다. 이는 작업 수가 증가함에 따라 공유된 화학적 패턴이 더 풍부해져 모델이 일반화 능력을 강화한다는 증거이다. 또한, 동일한 작업 수라도 데이터 양을 늘리면 성능이 더욱 향상되는 것을 확인했으며, 이는 데이터와 작업 수가 서로 보완적인 역할을 한다는 결론을 뒷받침한다.
전이 학습(transfer learning) 실험에서는, 멀티태스크 네트워크에 포함되지 않은 새로운 타깃에 대해 학습된 피처를 고정하고 선형 분류기를 훈련시켰다. 결과는 기존 단일 작업 모델보다 약간 높은 AUC를 보였지만, 기대했던 큰 이득은 없었다. 이는 멀티태스크 네트워크가 공유된 화학적 특성을 어느 정도 포착하지만, 타깃 고유의 생물학적 메커니즘까지 완전히 일반화하기엔 한계가 있음을 시사한다.
또한, 활성 화합물의 공유 정도와 멀티태스크 성능 향상 사이에 중간 정도의 양의 상관관계가 있음을 보고했으며, 타깃의 생물학적 클래스(예: GPCR, kinase 등)는 성능에 유의미한 영향을 미치지 않았다. 이는 화합물 구조 자체가 멀티태스크 학습에 더 큰 영향을 미친다는 점을 강조한다.
논문의 주요 기여는 다음과 같다. 첫째, 4천만 건 이상의 대규모 공개 데이터를 체계적으로 수집·정제하여 멀티태스크 학습에 활용했다. 둘째, 파라미터 효율성을 고려한 피라미드형 네트워크 설계가 멀티태스크 학습에서 과적합을 억제하고 성능을 극대화함을 입증했다. 셋째, 작업 수와 데이터 양이 동시에 성능에 기여한다는 실증적 증거를 제공했다. 넷째, 제한적인 전이 학습 가능성을 확인함으로써 향후 멀티모달·멀티태스크 통합 연구의 방향성을 제시했다.
마지막으로 저자들은 데이터 공유의 중요성을 강조하며, 더 정교한 피처(그래프 신경망, 메시 네트워크 등)와 멀티모달(유전체, 단백질 구조, 세포 이미지 등) 정보를 결합한 차세대 멀티태스크 프레임워크가 약물 발견 속도를 크게 가속화할 수 있다고 전망한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기