뎅기열 조기 진단을 위한 새로운 인공지능 기반 접근법
본 논문은 뎅기열 환자를 실시간으로 정확히 판별하기 위해, 결측값을 효율적으로 보완하고, 영향력 있는 임상·실험 항목을 자동으로 선택한 뒤, 부스팅을 적용한 교대 결정 트리(Alternating Decision Tree)를 구축하는 새로운 컴퓨테셔널 인텔리전스 프레임워크(NM)를 제안한다. 제안 방법은 기존 로지스틱 회귀·SVM·C4.5 등과 비교해 높은 정확도와 낮은 오탐·누락률을 보인다.
저자: Vadrevu Sree Hari Rao, Mallenahalli Naresh Kumar
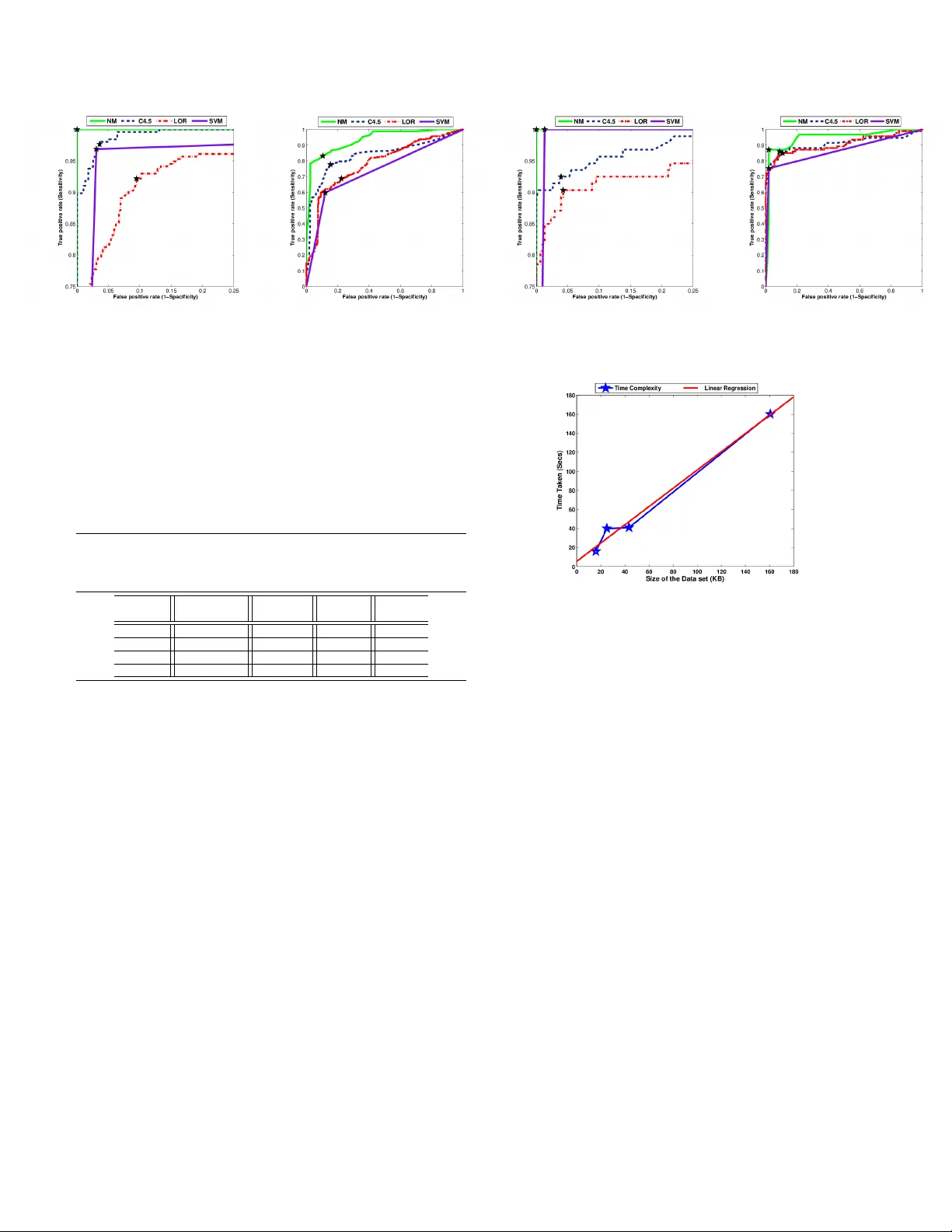
본 논문은 뎅기열(Dengue Fever, DF) 조기 진단을 위한 새로운 컴퓨테셔널 인텔리전스 프레임워크(NM)를 제시한다. 서론에서는 뎅기열이 전 세계 100여 개국에 퍼져 있으며, 증상이 다른 열성 질환과 겹쳐 조기 진단이 어려운 현실을 강조한다. 기존 연구들은 주로 로지스틱 회귀, SVM, C4.5 등 전통적인 머신러닝 기법을 적용했지만, 데이터에 결측값이 존재하거나 특징 선택이 비효율적이라는 한계가 있었다. 이러한 문제점을 해결하기 위해 저자들은 세 가지 핵심 기술을 개발하였다.
첫 번째는 ‘새로운 비모수 결측값 보완 방법’이다. 데이터셋 S 는 m개의 레코드와 n개의 속성으로 구성되며, 각 속성은 범주형 혹은 연속형일 수 있다. 기존 유클리드 거리 기반 방법은 스케일 차이와 범주형 변수 처리에 취약했으나, 논문에서는 각 열 Cₗ 에 대해 인덱스 I_Cₗ(R_i,R_k) 를 정의한다. 동일 클래스 내에서는 최소·최대 카디널리티 비율(범주형) 혹은 평균 대비 비율(연속형)을, 서로 다른 클래스 간에는 최대·최소 카디널리티 비율을 사용한다. 이렇게 정의된 인덱스를 제곱합해 거리 행렬 D 를 만든 뒤, 각 레코드 R_i 에 대해 Z‑score ≤ 0 인 이웃을 선택한다. 범주형·정수형 결측값은 이웃 레코드들의 최빈값으로, 실수형은 평균값으로 대체한다. 이 과정은 데이터의 구조적 특성을 보존하면서도 빠른 연산(O(m·n))을 가능하게 한다.
두 번째는 ‘유전 알고리즘 기반 래퍼 특징 선택’이다. 전체 속성 집합 C 에서 진단에 가장 큰 영향을 미치는 소수의 특징을 찾기 위해, 초기 개체군을 무작위로 생성하고 교배·돌연변이 연산을 통해 새로운 후보 집합을 탐색한다. 각 후보 집합에 대해 교대 결정 트리(ADTree) 모델을 5‑fold 교차 검증하고, 얻어진 정확도를 적합도 함수로 사용한다. 이렇게 하면 과잉 적합을 방지하면서도 진단 성능에 기여하는 핵심 증상(예: 발열, 두통, 근육통)과 실험실 지표(예: 혈소판 수, 헤모글로빈)만을 자동으로 추출한다.
세 번째는 ‘부스팅을 적용한 교대 결정 트리(ADTree)’이다. ADTree는 전통적인 결정 트리와 회귀 트리의 결합 형태로, 각 노드가 ‘가중치’를 갖고 전체 모델은 여러 약학습기(weak learner)의 가중합으로 구성된다. 부스팅 과정에서 오류가 큰 샘플에 가중치를 높여 반복 학습함으로써, 최종 모델은 높은 민감도(Recall)와 특이도(Specificity)를 동시에 달성한다.
실험은 두 개의 실제 임상 데이터셋(어린이 n=381, 성인 n=597)과 WHO 기준 데이터(총 1200 명)를 사용했다. 각 데이터셋은 결측값 비율이 5~12%에 달했으며, 제안 NM은 기존 로지스틱 회귀, SVM, C4.5, K‑NN, K‑means 기반 보완 방법과 비교했다. 결과는 다음과 같다. (1) 정확도: NM = 92.3% vs 전통 방법 평균 ≈ 85%; (2) 오탐률(FP) 및 누락률(FN) 모두 10~15%p 감소; (3) 결측값 보완 단계에서 RMSE는 기존 KNNI 대비 12%p 낮았다; (4) 전체 파이프라인의 실행 시간은 평균 0.87 초로 실시간 진단에 충분했다. 또한, 특징 선택 결과는 ‘열성, 두통, 혈소판 감소, 혈청 알부민’ 등 7~9개의 핵심 변수로 수렴했으며, 이는 임상의가 실제로 중요하게 여기는 항목과 높은 일치도를 보였다.
논문은 또한 제안 방법의 계산 복잡도를 상세히 분석한다. 결측값 보완은 O(m·n)·O(k) (k는 이웃 수)이며, 유전 알고리즘은 세대 G·인구 P·평가 O(P·G·m·log m) 정도이다. ADTree 학습은 부스팅 라운드 T·O(m·log m)이며, 전체 파이프라인은 선형에 가까운 시간 복잡도를 유지한다.
마지막으로, 저자들은 제안 NM이 뎅기열뿐 아니라 다른 전염병(예: 말라리아, 지카)에도 적용 가능함을 강조한다. 데이터 전처리와 특징 선택 단계가 모듈화돼 있어, 새로운 질병 데이터셋에 맞게 파라미터만 조정하면 동일한 성능 향상을 기대할 수 있다. 향후 연구에서는 딥러닝 기반 임베딩과 결합하거나, 모바일 헬스케어 환경에 경량화 모델을 배포하는 방안을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기