중간 규모 베이지안 네트워크 구조 학습을 위한 효율적 샘플링
본 논문은 베이지안 모델 평균화(BMA) 하에 베이지안 네트워크 구조(DAG) 학습을 수행하기 위한 새로운 샘플링 알고리즘을 제안한다. 기존 DP 기반 방법은 모듈러 특징만 다룰 수 있었고, MCMC 기반 방법은 수렴 보장이 없었다. 저자들은 DP 결과를 이용해 정확한 순서 사후분포를 샘플링하고, 이를 바탕으로 DAG를 직접 샘플링하는 DDS 알고리즘을 개발하였다. 또한, 순서‑모듈러 사전의 편향을 보정하는 IW‑DDS를 제시해, 어떠한 비모듈…
저자: Ru He, Jin Tian, Huaiqing Wu
본 논문은 베이지안 네트워크(BN) 구조 학습을 베이지안 모델 평균화(BMA) 관점에서 접근한다. BMA는 단일 MAP 구조 대신 모든 가능한 DAG에 대한 사후확률을 평균함으로써 작은 데이터셋에서도 과도한 과적합을 방지한다. 그러나 가능한 DAG 수가 n ! 2^{n(n−1)/2} 로 급증하기 때문에 정확한 사후 계산은 실질적으로 불가능하다. 기존 연구는 두 갈래로 나뉜다. 첫 번째는 동적 프로그래밍(DP) 기반으로 순서 공간에서 정확한 모듈러 특징(예: 개별 에지)의 사후를 계산하는 방법이다. 이 방법은 O(n 2ⁿ) 메모리를 요구해 변수 수가 25 정도까지 제한된다. 두 번째는 MCMC 기반으로 DAG 혹은 순서 공간을 탐색해 근사 샘플을 얻는 방법이다. Structure MCMC, Order MCMC, Partial Order MCMC, Hybrid MCMC 등 다양한 변형이 제안됐지만, 수렴 속도가 느리거나 사전 편향(order‑modular prior) 때문에 결과가 왜곡될 위험이 있다.
이러한 한계를 극복하기 위해 저자들은 세 단계의 새로운 알고리즘을 설계했다.
1) **정확한 순서 샘플링**: Koi visto와 Sood(2004)의 DP 알고리즘이 제공하는 순서별 점수 테이블을 역추적해, 순서‑모듈러 사전 하에서 정확히 p≺(π|D) 를 따르는 순서를 직접 샘플링한다. 이 과정은 DP 테이블을 한 번만 계산하면 되므로 전체 복잡도는 O(n 2ⁿ) 이지만, 샘플링 자체는 O(n) 수준이다.
2) **DAG 샘플링(DDS)**: 샘플링된 순서 π에 대해 각 변수 i의 부모 집합을 독립적으로 선택한다. 선택 확률은 p_i(Pa_i)·score_i(Pa_i) 에 비례하도록 정의되며, 이는 DAG가 정확히 p≺(G|D) 를 따르게 만든다. 따라서 DDS는 “order‑modular prior” 하에서 **정확한 DAG 사후 샘플링**을 최초로 구현한다.
3) **편향 보정(IW‑DDS)**: 순서‑모듈러 사전은 DAG가 가질 수 있는 순서 수에 비례해 사전이 가중되므로, 실제로는 균등 사전이나 구조‑모듈러 사전이 더 바람직하다. Ellis와 Wong(2008)의 가중치 보정 아이디어를 확장해, 각 DAG 샘플에 역가중치 w(G)=p⊀(G)/p≺(G) 를 곱한다. 이렇게 하면 기대값이 p⊀(G|D) 에 맞춰지며, 사전 편향이 완전히 제거된다.
이론적 분석에서는 다음을 증명한다.
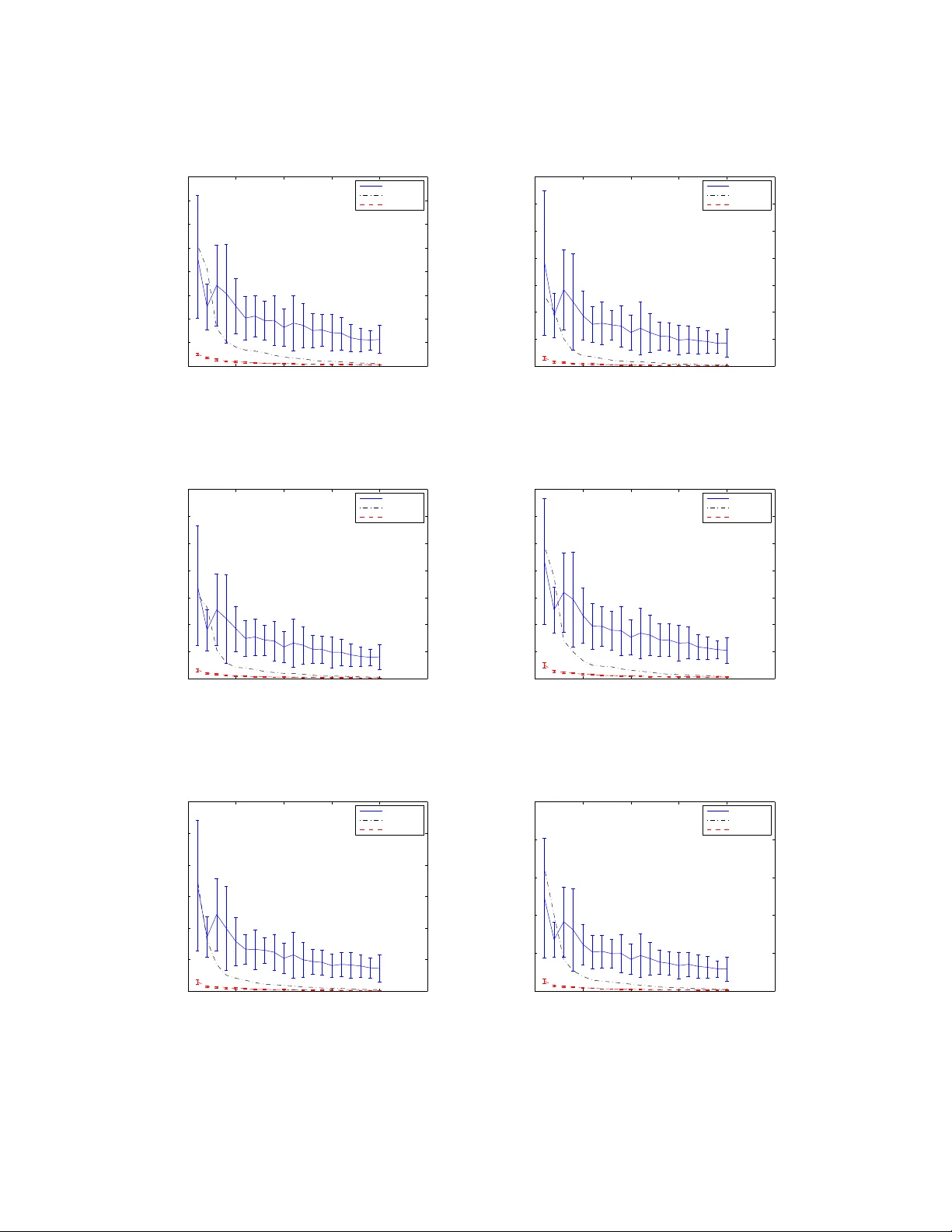
- **정확성**: DDS가 생성하는 샘플 집합 {G₁,…,G_T} 은 i.i.d. 로 p≺(G|D) 를 따른다. IW‑DDS는 가중치를 적용해 p⊀(G|D) 로부터 샘플링한 것과 동일한 기대값을 가진다.
- **수렴 속도**: 임의의 구조 특징 f에 대한 추정값 ˆp(f|D)= (1/T)∑ f(G_i) 은 편향이 0이고, 분산이 Var
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기