문장 길이 저주를 극복하는 자동 구문 분할 방법
본 논문은 신경망 기반 기계번역(NMT)이 긴 문장에서 성능이 급락하는 문제를 해결하기 위해, 입력 문장을 의미 단위인 구절로 자동 분할한 뒤 각각을 독립적으로 번역하고 결과를 연결하는 방법을 제안한다. 구절별 번역 신뢰도를 양방향 번역 모델의 로그 확률을 이용해 점수화하고, 전체 점수를 최대화하는 최적 분할을 정수 계획법으로 효율적으로 찾는다. 실험 결과, 특히 30단어 이상 장문에서 기존 NMT보다 BLEU 점수가 크게 향상되었으며, 구절 …
저자: Jean Pouget-Abadie, Dzmitry Bahdanau, Bart van Merrienboer
본 논문은 최근 신경망 기반 기계번역(NMT)이 짧은 문장에서는 기존 통계적 기계번역(SMT)과 견줄 만한 성능을 보이지만, 길이가 긴 문장에서는 번역 품질이 급격히 저하된다는 문제점을 지적한다. 이러한 현상은 RNN Encoder‑Decoder 구조가 입력 문장을 고정 차원의 컨텍스트 벡터에 압축해야 하는 설계상의 제약과, 학습 데이터에 긴 문장이 부족한 점에서 기인한다. 저자들은 이 문제를 해결하기 위해 입력 문장을 의미 단위인 구절(phrase)로 자동 분할하고, 각 구절을 독립적으로 번역한 뒤 순차적으로 연결하는 새로운 파이프라인을 제안한다.
구절 분할을 위한 핵심 아이디어는 ‘신뢰도 점수’를 정의하는 것이다. 구절 eᵢⱼ (입력 문장의 i번째부터 j번째까지의 연속 토큰)와 후보 번역 fₖ 에 대해, 양방향 번역 모델(영→프와 프→영)에서 얻은 로그 확률 log p(fₖ|eᵢⱼ)와 log q(eᵢⱼ|fₖ) 를 합산하고, 구절 길이에 대한 로그 패널티 2·|log(j−i+1)| 로 나누어 c(eᵢⱼ,fₖ) 를 계산한다. 구절 eᵢⱼ 에 대해 가능한 번역 후보 중 최대 점수를 갖는 cᵢⱼ 을 구함으로써, 구절 자체에 대한 신뢰도 점수를 얻는다.
이후 전체 문장의 최적 구절 분할은 0‑1 변수 xᵢⱼ (구절 eᵢⱼ 을 선택하면 1) 로 표현된 정수 선형 계획문제로 모델링된다. 목적 함수는 ∑ᵢⱼ cᵢⱼ xᵢⱼ 을 최대화하고, 제약식은 각 토큰이 정확히 하나의 구절에 포함되도록 ∑_{i≤k≤j} xᵢⱼ = 1 (∀k) 을 강제한다. 제약 행렬이 전역적으로 유니모듈러이기 때문에, 이 문제는 다항 시간에 해결 가능하다. 실제 구현에서는 동적 계획법을 이용해 sⱼ = max_{1≤i≤j}(cᵢⱼ + s_{i−1}) 와 Sⱼ = argmax_{1≤i≤j}(cᵢⱼ + s_{i−1}) 을 재귀적으로 계산하고, 최종적으로 Sₙ 부터 역추적해 최적 구절 경로를 복원한다. 이 알고리즘은 O(n²) 시간 복잡도를 가지며, 문장 길이에 비례해 실용적인 실행 시간을 보인다.
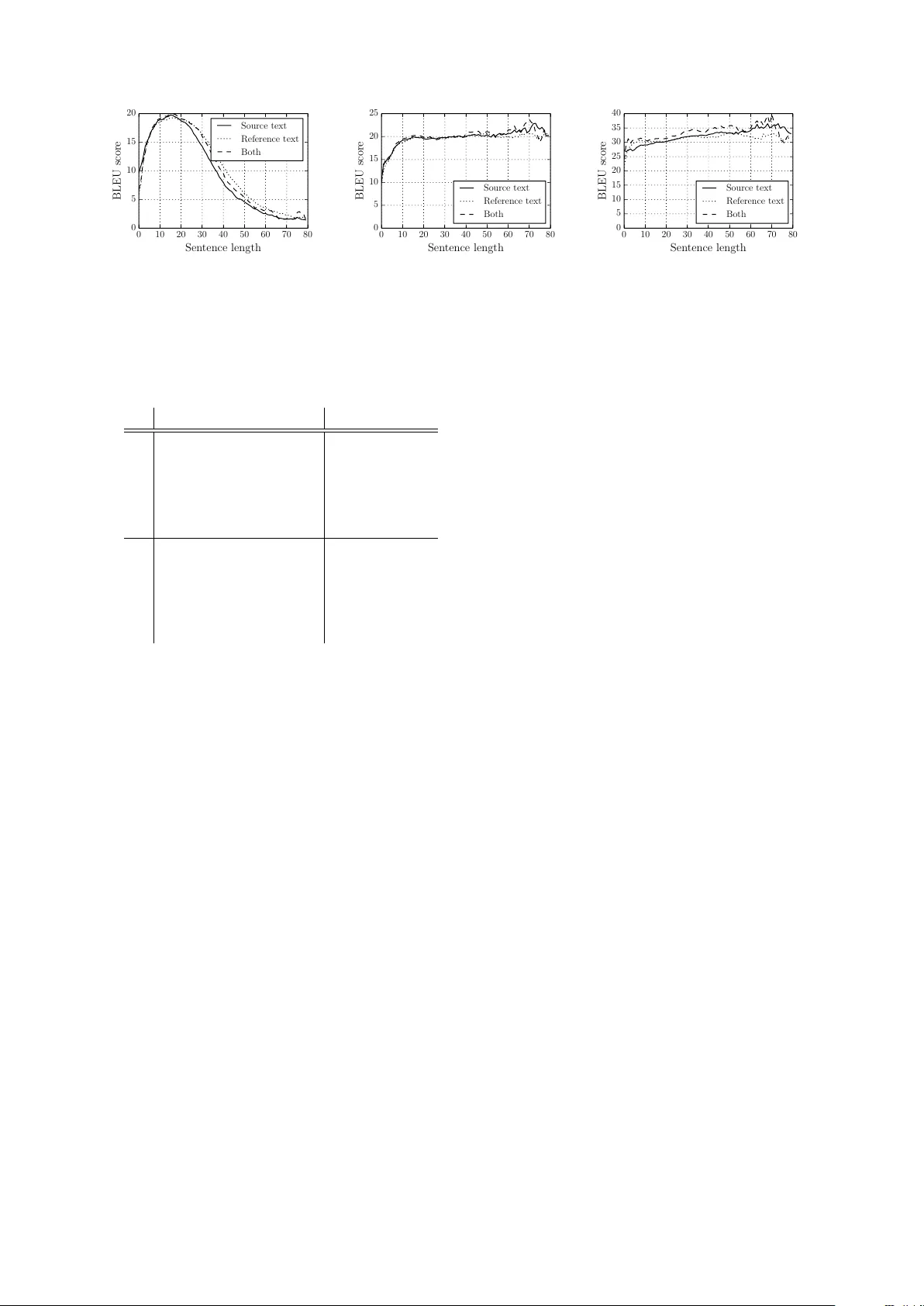
실험은 영어‑프랑스어 병렬 코퍼스를 사용해 수행되었다. 학습 단계에서는 문장 길이가 30단어 이하인 쌍만을 사용해 어휘를 30,000개로 제한했으며, 이는 실제 번역 시스템이 긴 문장을 직접 학습하기 어려운 상황을 모사한다. 평가 데이터는 WMT 2012‑2014 뉴스 테스트 세트를 사용했으며, 기준 시스템으로는 동일 RNNenc 모델(분할 없이)과 전통적인 구문 기반 SMT 시스템인 Moses를 포함했다.
결과는 다음과 같다. (1) 무분할 RNNenc는 30단어 이하에서는 평균 BLEU 13~14점을 기록했지만, 30단어를 초과하는 장문에서는 급격히 하락한다. (2) 제안된 구절 분할을 적용한 RNNenc는 전체 테스트 셋에서 BLEU 20~26점대로 크게 개선되었으며, 특히 40단어 이상 장문에서 10점 이상의 상승을 보였다. (3) 무작위 구절 분할조차도 무분할 모델보다 높은 BLEU를 기록했으며, 이는 구절 단위로 번역하는 것이 기본적인 장문 처리 문제를 완화한다는 것을 시사한다. (4) 신뢰도 점수에 양방향 모델을 모두 사용하고 짧은 구절에 대한 패널티를 적용했을 때 가장 높은 성능을 얻었으며, 단일 방향 모델만 사용할 경우 성능이 현저히 떨어졌다. (5) 미지어휘(UNK) 비율이 높은 문장에서도 구절 분할은 각 구절당 UNK 수를 감소시켜 번역 품질 저하를 억제한다.
논문의 한계로는 구절 간 순서 재배열이 필요할 경우 단순 연결이 문법 오류를 초래할 수 있다는 점을 들었다. 영어‑프랑스어처럼 어순이 유사한 경우에는 큰 문제가 없지만, 어순 차이가 큰 언어쌍에서는 추가적인 재배열 모듈이 필요하다. 또한, 모든 구절에 대해 양방향 모델을 호출해 점수를 계산하는 과정이 계산 비용이 크게 소요되며, 이를 병렬화하거나 후보 구절 수를 제한하는 최적화가 필요하다.
결론적으로, 이 연구는 NMT가 고정 길이 컨텍스트 벡터에 의존하는 구조적 한계를 구절 기반 자동 분할과 신뢰도 점수 최적화를 통해 효과적으로 보완한다는 것을 실증하였다. 향후 연구는 (i) 구절 재배열 및 문맥 흐름 유지 기법, (ii) 더 큰 어휘와 심층 모델을 활용한 확장, (iii) 다양한 언어쌍에 대한 일반화 가능성 검증 등을 포함한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기