월드컵 트윗 텍스트 마이닝 사례 연구: 클러스터링 알고리즘 비교와 노이즈 제거
본 논문은 월드컵 이전에 수집한 약 30 000개의 트윗을 대상으로 텍스트 마이닝을 수행한다. DBSCAN과 합의 행렬(consensus matrix)을 결합한 노이즈 제거 절차를 제안하고, 정제된 데이터에 대해 k‑means와 비음수 행렬 분해(NMF)를 적용해 주요 주제를 추출한다. 두 알고리즘의 결과는 유사하지만 NMF가 더 빠르고 해석이 용이함을 확인하였다. 시각화 도구인 Gephi와 Wordle을 활용해 클러스터 구조와 핵심 단어를 직…
저자: Daniel Godfrey, Caley Johns, Carl Meyer
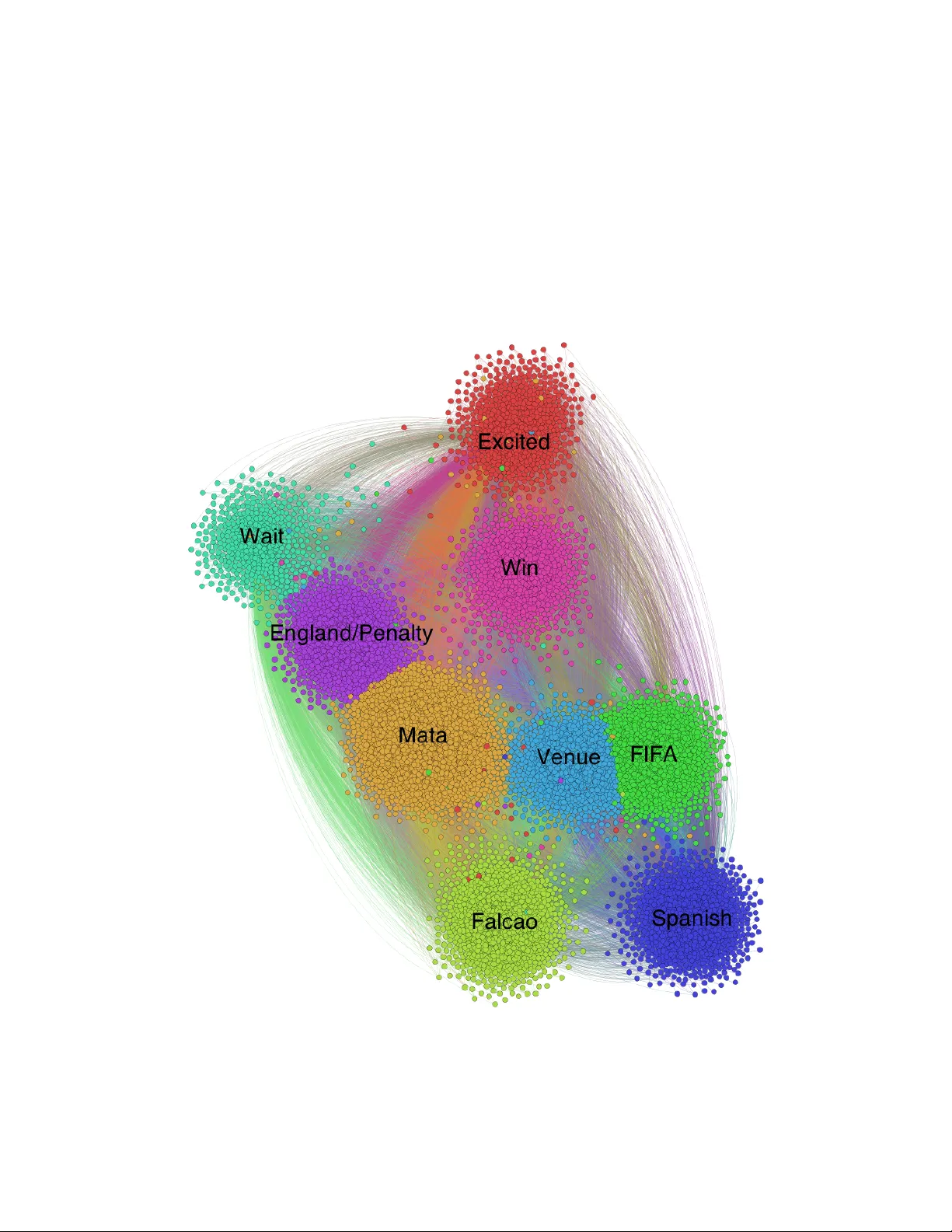
본 논문은 월드컵 개최 직전 트위터에서 ‘world cup’이라는 키워드가 포함된 트윗을 29 353개 수집하고, 이를 텍스트 마이닝을 통해 주요 주제를 도출하는 과정을 상세히 기술한다. 초기 데이터는 영어와 스페인어가 혼합된 형태였으며, 중복된 리트윗을 제거하고 TF‑IDF 가중치를 적용해 17 023개의 의미‑중심 트윗을 확보하였다. 텍스트 데이터는 일반적으로 노이즈가 많아 분석 정확도를 저해하므로, 저자들은 노이즈 제거를 위해 세 가지 상보적인 알고리즘을 설계하였다.
첫 번째 알고리즘은 다양한 k값으로 다중 실행한 k‑means 결과를 기반으로 합의 행렬을 구축하고, 트윗 쌍이 10 % 이하로 동시에 클러스터링된 경우 해당 값을 0으로 만든 뒤, 행 합이 평균 이하인 트윗을 노이즈로 판정한다. 두 번째 알고리즘은 코사인 거리 기반 DBSCAN을 여러 ε값으로 반복 적용해 각 트윗을 ‘밀도 포인트’, ‘경계 포인트’, ‘노이즈 포인트’로 분류하고, 50 % 이상에서 경계·노이즈로 표시된 트윗을 제거한다. 세 번째 알고리즘은 앞선 두 결과를 합의 행렬에 다시 매핑해 동일 기준으로 노이즈를 식별한다. 최종적으로 세 알고리즘 중 최소 두 개에서 노이즈로 판단된 트윗을 삭제함으로써 3 558개의 추가 트윗을 제외하고, 총 13 465개의 정제된 트윗을 분석에 사용하였다.
주제 수를 결정하기 위해 합의 행렬로부터 라플라시안 행렬 L = D − C를 계산하고, 가장 작은 50개의 고유값을 조사하였다. 첫 6개의 고유값 사이에 뚜렷한 갭이 나타나 6~8개의 토픽이 적절하다고 판단하였다.
클러스터링 단계에서는 k‑means와 비음수 행렬 분해(NMF)를 동일한 토픽 수(k)로 적용하였다. k‑means는 초기 중심점에 민감하고, 최적 k값을 사전에 지정해야 하는 제약이 있다. 반면 NMF는 비음수 제약을 통해 토픽‑워드 행렬(W)과 문서‑토픽 행렬(H)을 직관적으로 해석할 수 있다. 저자들은 ALS와 ACLS 변형을 사용해 NMF를 수행했으며, 특히 ACLS가 가장 빠른 수렴 속도와 희소성 유지라는 장점을 보여 30 % 정도의 시간 절감 효과를 얻었다. 결과적으로 k‑means와 NMF가 도출한 토픽은 전반적으로 유사했지만, NMF가 제공하는 토픽별 핵심 단어 리스트가 더 명확하고 해석이 용이했다.
시각화 측면에서 저자들은 Gephi를 이용해 클러스터 간 연결 구조와 중심성을 그래프 형태로 시각화했으며, Wordle을 활용해 각 토픽의 핵심 단어 구름을 생성했다. 이를 통해 비전문가도 각 토픽의 의미를 직관적으로 파악할 수 있었다.
결론적으로, 본 연구는 (1) DBSCAN과 합의 행렬을 결합한 다단계 노이즈 제거 기법, (2) k‑means와 NMF의 성능 및 해석 차이 비교, (3) 라플라시안 고유값을 이용한 토픽 수 결정, (4) 시각화 도구를 통한 결과 전달이라는 네 가지 핵심 기여를 제시한다. 제안된 파이프라인은 텍스트 데이터가 다량이고 잡음이 많은 소셜 미디어 분석에 적용 가능하며, 향후 다른 도메인에서도 재현성을 기대할 수 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기