반복 합의 클러스터링으로 군집 수 자동 결정
본 논문은 여러 클러스터링 알고리즘과 다양한 k값을 이용해 만든 합의 유사도 행렬을 기반으로, 랜덤 워크 전이 행렬의 고유값을 분석해 데이터의 최적 군집 수를 추정한다. 잡음이 많거나 차원이 높은 경우에는 드롭 토러런스와 반복 정제 과정을 통해 행렬을 블록 대각 형태에 가깝게 만들며, 이를 통해 보다 명확한 Perron 클러스터를 도출한다.
저자: Shaina Race, Carl Meyer, Kevin Valakuzhy
본 논문은 데이터 분석에서 가장 기본적이면서도 난이도가 높은 문제 중 하나인 “군집 수 k를 어떻게 정할 것인가”에 대한 새로운 해결책을 제시한다. 전통적인 클러스터링 알고리즘은 사용자가 사전에 k값을 지정해야 하지만, 실제 현장에서는 데이터의 내재된 군집 구조를 모르는 경우가 대부분이다. 저자들은 이 문제를 “클러스터링 앙상블” 접근법으로 풀어낸다. 구체적으로, N개의 서로 다른 클러스터링 알고리즘(예: PDDP, k‑means, EMGM, PDDP‑k‑means)과 J개의 후보 k값(˜k₁,…,˜k_J)을 조합해 총 N·J개의 파티션을 생성한다. 각 파티션에서 같은 데이터 포인트가 동일 클러스터에 속한 횟수를 누적해 만든 합의 행렬 M은 대칭이며, M_{ij}는 i와 j가 함께 클러스터링된 횟수를 나타낸다.
M을 그래프의 가중 인접 행렬로 해석하고, D=diag(M·e) (e는 전부 1인 벡터)로 정규화해 전이 행렬 P=D⁻¹M을 만든다. P는 상세 균형을 만족하는 가역 마코프 체인이며, Q=diag(π) (π는 정규화된 정점 가중치)와의 관계를 통해 P는 대칭 행렬 I−D^{-1/2}MD^{-1/2}와 유사함을 이용해 고유값을 효율적으로 계산한다.
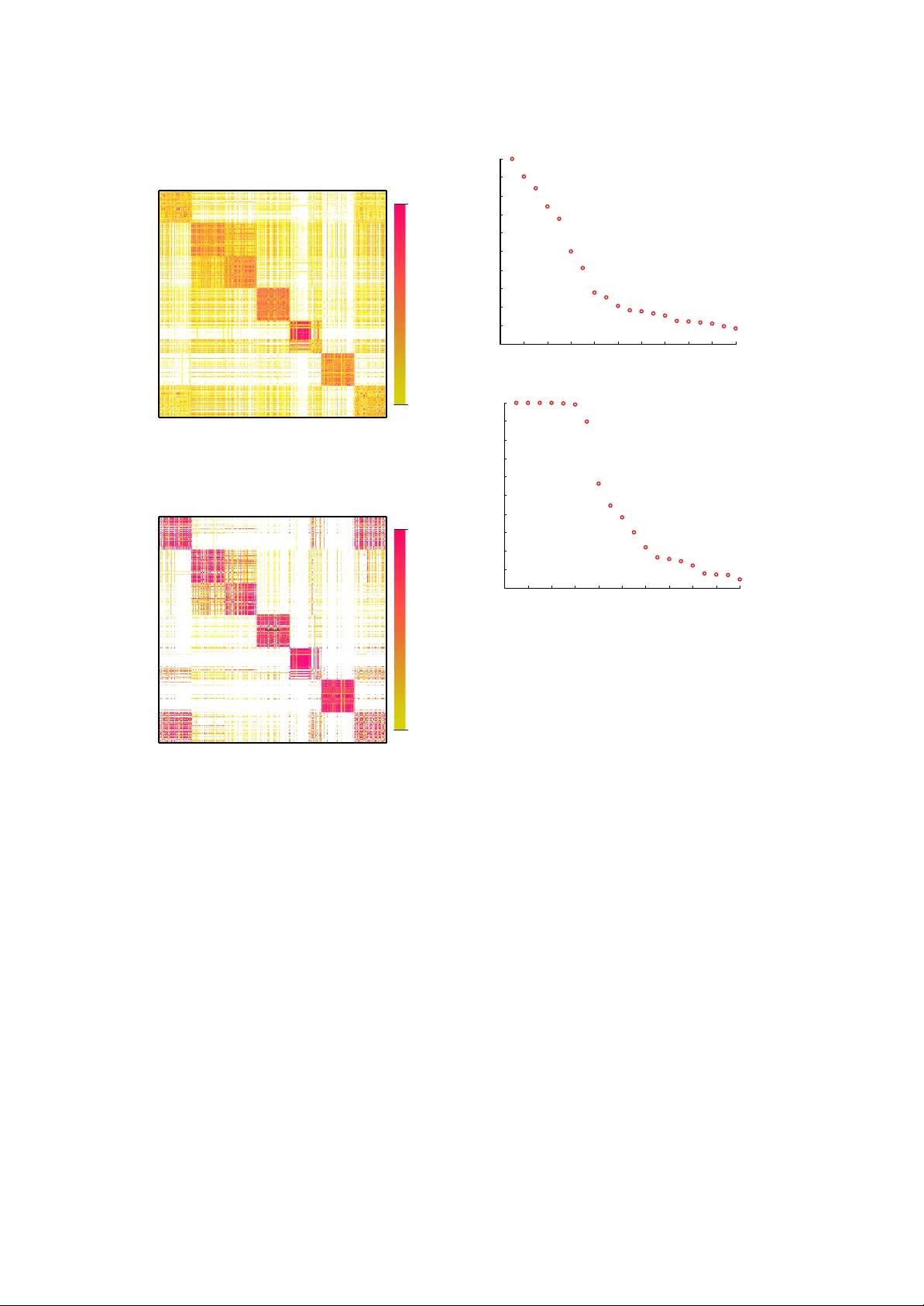
핵심 이론은 “거의 분리된(near‑uncoupled) 마코프 체인”에서 고유값 1에 가까운 k개의 값이 존재한다는 사실이다. 이러한 고유값 집합을 Perron 클러스터라 부르며, λ_k와 λ_{k+1} 사이에 뚜렷한 갭이 나타날 경우 k가 실제 군집 수가 된다. 기존에 널리 쓰이는 Gaussian 유사도 행렬은 클러스터 간 연결을 과도하게 유지해 Perron 클러스터를 흐리게 만들지만, 합의 행렬은 서로 다른 알고리즘이 만든 다양한 파티션을 평균함으로써 자연스럽게 블록 대각 구조를 강화한다.
하지만 고차원 텍스트 데이터처럼 잡음이 심한 경우, 약한 연결이 여전히 남아 고유값 갭을 가릴 수 있다. 이를 해결하기 위해 두 가지 보강책을 제시한다. 첫째, 드롭 토러런스 τ를 도입해 M_{ij}<τ·(J·N)인 원소를 0으로 강제 삭제한다. 이는 실제 같은 클러스터에 속하지 않은 경우의 우연한 동시 발생을 억제한다. 둘째, 반복 정제(iterative consensus clustering, ICC)이다. 초기 합의 행렬 M을 새로운 데이터 행렬로 사용해 다시 클러스터링을 수행하고, 새로운 합의 행렬을 만든 뒤 다시 드롭 토러런스를 적용한다. 이 과정을 Perron 클러스터가 명확히 보일 때까지 반복한다.
실험에서는 저차원 Ruspini 데이터와 고차원 20 Newsgroups 서브셋(7개 토픽, 700문서)을 사용했다. Ruspini에서는 기본 방법만으로도 λ₁≈1, λ₂≈1, λ₃≈1, λ₄≈1 뒤에 큰 갭이 나타나 k=4를 정확히 복원했다. 반면 Gaussian 유사도 행렬을 사용했을 때는 첫 번째 고유값 뒤에만 큰 갭이 생겨 블록 구조를 파악하기 어려웠다. Newsgroups 데이터에서는 τ=0.1, J·N=80 정도의 설정으로 두 번의 ICC 후에 합의 행렬이 명확히 블록 대각 형태를 띠었고, 고유값 스펙트럼에서도 λ₁~λ₇이 1에 가깝고 λ₈과의 차이가 뚜렷해 k=7을 정확히 추정했다. 또한, 서브클러스터(예: “atheism” vs “misc. religion”)가 존재할 경우 λ₇이 λ₆보다 약간 낮아지는 현상이 관찰돼, 사용자가 추가적인 세부 군집화를 고려하도록 힌트를 제공한다.
이 논문의 주요 기여는 다음과 같다. (1) 다중 알고리즘·다중 k값을 활용한 강건한 합의 행렬 구축, (2) 마코프 체인 고유값 분석을 통한 군집 수 추정, (3) 드롭 토러런스와 반복 정제로 잡음 억제 및 블록 구조 강화. 특히, 기존 스펙트럴 클러스터링이 요구하는 매개변수 σ에 크게 의존하지 않으며, 텍스트와 같이 고차원·고잡음 데이터에 적합한 자동 군집 수 결정 기법으로 평가된다. 향후 연구에서는 더 다양한 차원 축소 기법, 비정형 데이터, 그리고 실시간 스트리밍 환경에서의 적용 가능성을 탐색할 여지가 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기