분류 기반 회귀 포레스트 성장: 객체 자세 추정의 새로운 접근
본 논문은 회귀 트리의 노드 분할을 기존의 이진 분할 방식에서 목표 공간의 군집화를 먼저 수행하고, 이를 분류 문제로 전환하여 최적의 분할 규칙을 찾는 방법으로 개선한다. K‑클러스터 회귀 포레스트(KRF)와 자동 K 선택 AKRF를 제안하고, 원형 목표 공간을 위한 확장도 제공한다. 헤드 포즈와 차량 방향 추정 실험에서 각각 38.5%와 22.5%의 오류 감소를 달성하였다.
저자: Kota Hara, Rama Chellappa
본 논문은 회귀 트리와 회귀 포레스트의 핵심 구성 요소인 노드 분할 방식을 혁신적으로 바꾸는 방법을 제안한다. 전통적인 회귀 트리는 입력 공간을 이진 하이퍼플레인(단일 차원 임계값)으로 분할하는데, 이는 사전에 정의된 후보 규칙 집합을 전부 시험해 보는 ‘trial‑and‑error’ 방식이다. 이러한 제한은 복잡한 입력‑목표 관계를 충분히 포착하지 못하고, 트리 깊이가 깊어지면서 과적합 위험이 커진다.
저자들은 먼저 목표 공간(t)에서 k‑means 군집화를 수행해 K개의 클러스터 T₁,…,T_K를 만든다. 이 단계는 손실(제곱 오차) 최소화에 직접 초점을 맞추며, 입력 공간을 전혀 고려하지 않기 때문에 목표 값 자체의 구조를 가장 잘 반영한다. 각 클러스터는 평균 a_k= (1/|T_k|)∑_{i∈T_k} t_i 로 정의된다.
그 다음, 입력 공간(x)에서 각 클러스터를 라벨로 삼아 K‑class 분류 문제를 설정한다. 여기서는 L2‑regularized L2‑loss 선형 SVM을 one‑vs‑rest 방식으로 학습한다. 최적화 식은
min_{w_k} ||w_k||² + C∑_{i=1}^N (max(0,1−l_{ki} w_k^T x_i))²,
여기서 l_{ki}=+1이면 i∈T_k, −1이면 그렇지 않다. 학습된 w_k를 이용해 샘플 x_i를 argmax_k w_k^T x_i 로 가장 가까운 클러스터에 할당하고, 해당 클러스터에 대응하는 자식 노드로 전파한다. 이렇게 하면 분할 규칙이 단순히 축에 수직인 하이퍼플레인이 아니라, 다차원 선형 결합 형태가 될 수 있다. 또한 K가 2보다 클 경우 하나의 노드가 다중 자식(K) 노드를 갖게 되므로 트리 구조가 보다 넓게 퍼지고, 깊이가 얕아져 연산 효율이 향상된다.
K값 선택은 중요한 하이퍼파라미터이다. 고정된 K를 사용하면 교차 검증이 필요하지만, 저자는 베이지안 정보 기준(BIC)을 이용해 각 노드에서 자동으로 K를 결정한다. BIC는 로그 가능도와 모델 복잡도(파라미터 수)를 결합한 지표이며, 여기서는 목표 데이터가 공유 분산 σ²를 갖는 등방성 가우시안 혼합 모델이라고 가정한다. σ²는 전체 군집 내 제곱 오차 평균으로 추정하고, 각 군집의 데이터 밀도는
p(t)=|T_k|/N·(1/√(2πσ²))·exp(−||t−a_k||²/(2σ²))
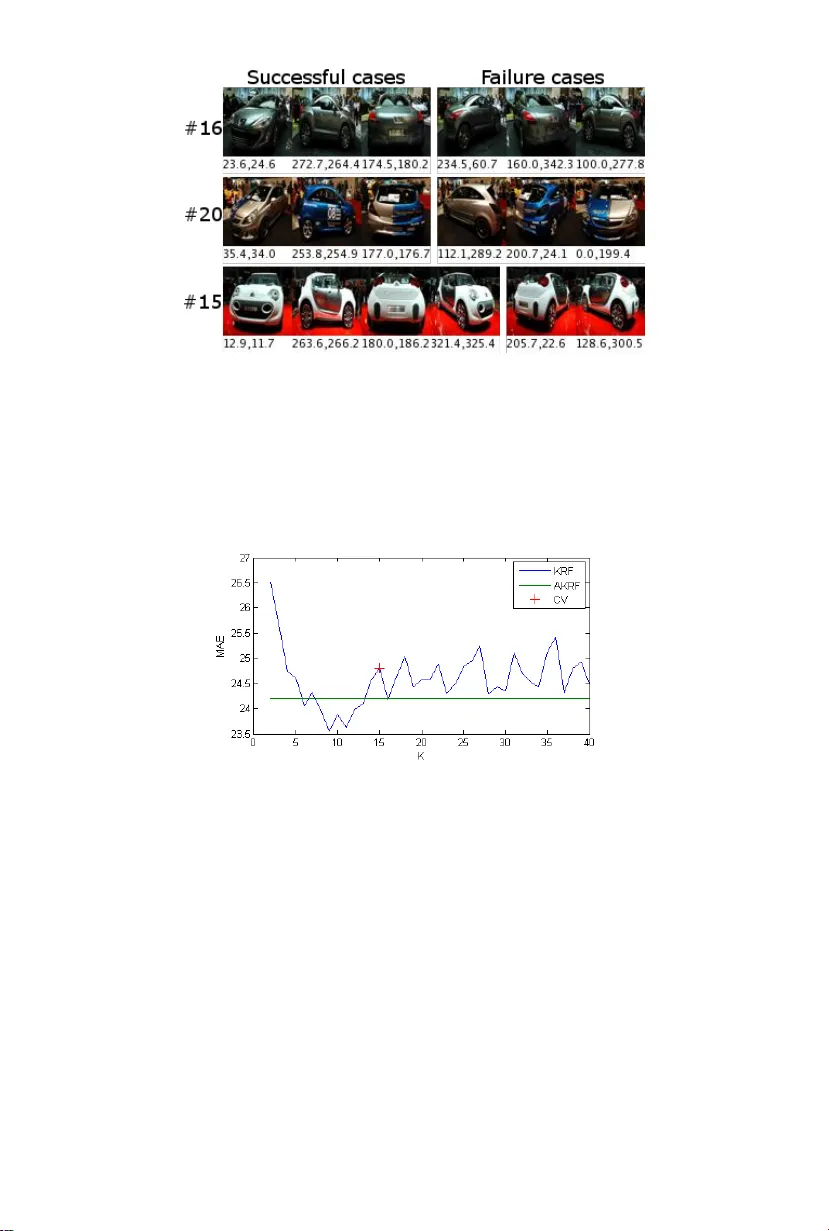
로 계산한다. 로그 가능도와 파라미터 수(K−1+qK+1)를 이용해 BIC_K = −2·ln L + (K−1+qK+1)·ln N을 구하고, 가장 작은 BIC를 갖는 K를 선택한다. 실험에서는 K를 2~40 범위에서 탐색했으며, 복잡한 목표 분포에서는 큰 K가, 단순한 경우 작은 K가 자동으로 선택되었다.
원형 목표 공간(예: 차량 방향)에서는 유클리드 거리 대신 원호 길이를 거리 측정으로 사용해 k‑means와 BIC를 수정한다. 이는 0°와 360°가 동일한 점이라는 토폴로지를 정확히 반영한다. 클러스터 중심은 2차원 단위 원 위에 위치시키고, 각 샘플은 가장 짧은 각도 차이를 기준으로 할당한다.
제안된 방법을 K‑clusters Regression Forest(KRF)와 자동 K 선택 AKRF라고 부른다. 두 모델을 헤드 포즈 추정용 Pointing’04 데이터셋과 차량 방향 추정용 EPFL Multi‑view Car 데이터셋에 적용했다. 헤드 포즈 실험에서는 평균 절대 각도 오차가 기존 회귀 포레스트 대비 38.5% 감소했으며, 차량 방향 실험에서는 원형 목표 공간 처리를 통해 22.5% 오류 감소를 달성했다. 또한, KRF/AKRF는 일반적인 회귀 방법(선형 회귀, RBF 네트워크, 기존 회귀 포레스트)보다도 일관되게 우수한 성능을 보였다.
결론적으로, 이 논문은 (1) 목표 공간 기반 군집 → 입력 공간 분류라는 두 단계 분할 전략, (2) 다중 자식 노드를 허용하는 유연한 트리 구조, (3) BIC 기반 자동 K 선택, (4) 원형 목표 공간에 대한 통계적 처리라는 네 가지 핵심 기여를 통해 회귀 포레스트의 효율성과 정확성을 크게 향상시켰다. 이러한 접근은 고차원 이미지 피처와 저차원 연속 레이블 사이의 복잡한 매핑을 학습하는 다양한 컴퓨터 비전 과제에 적용 가능하며, 기존 이진 분할 기반 회귀 트리의 한계를 효과적으로 극복한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기