근사 정책 반복 알고리즘 비교와 성능 분석
본 논문은 무한히 긴 할인 마코프 의사결정 과정(MDP)에서 사용되는 네 가지 근사 정책 반복(Approximate Policy Iteration) 변형—API, CPI, PSDP∞, NSPI(m)—의 이론적 성능 경계, 수렴 속도, 메모리 요구량을 집중적으로 비교한다. 특히 집중 가능성(concentrability) 상수의 계층 구조를 제시하여, CPI가 API보다 훨씬 강력한 보장을 제공하지만 반복 횟수가 지수적으로 늘어나는 트레이드오프를 …
저자: Bruno Scherrer (INRIA Nancy - Gr, Est / LORIA)
본 논문은 무한히 긴 할인 마코프 의사결정 과정(MDP)에서 최적 정책을 근사적으로 찾기 위한 네 가지 정책 반복(Policy Iteration) 변형을 체계적으로 비교한다. 먼저 MDP의 기본 구성 요소와 정책 가치 함수 vπ, 벨만 연산자 Tπ, 최적 연산자 T를 정의하고, 근사 그리디 연산자 Gε를 도입한다. Gε는 주어진 분포 ν와 가치 함수 v에 대해 ε-근사 그리디 정책을 반환하도록 설계되며, 이는 Q‑함수 회귀, LSTD, 비용 민감 분류 등 다양한 방법으로 구현될 수 있다.
네 알고리즘은 다음과 같다. (1) Approximate Policy Iteration(API): 매 반복마다 현재 정책 πk의 가치 vπk에 대해 Gε를 호출해 새로운 결정적 정책 πk+1을 완전 교체한다. 오류가 없으면 정확한 정책 반복과 동일한 수렴을 보인다. (2) Conservative Policy Iteration(CPI): 현재 정책의 점유 분포 dπk,ν를 사용해 Gε를 호출하고, 새로운 정책을 기존 정책과 스텝 사이즈 αk로 혼합한다. 이 보수적 업데이트는 정책의 급격한 변화를 억제하면서도 기대 가치가 향상되도록 설계되었다. CPI의 변형으로 고정된 α를 사용하는 CPI(α)와 API(α)도 제시된다. (3) Policy Search by Dynamic Programming 무한 버전(PSDP∞): 비정적(non‑stationary) 정책 σk=πkπk‑1…π1을 구성하고, 그 가치 vσk에 대해 Gε를 적용해 새로운 정책을 앞에 삽입한다. σk는 k‑단계 유한 정책이며, 최종 출력은 σk를 무한히 반복하는 정책 (σk)∞이다. 이 방식은 API의 전진성(Full step)과 CPI의 보수성(점진적 변화)을 동시에 갖는다. (4) Non‑Stationary Policy Iteration with fixed period NSPI(m): 메모리 사용을 제한하기 위해 고정된 길이 m의 슬라이딩 윈도우를 도입한다. 최신 m개의 정책만 보관하고, 각 단계에서 (σm,k)∞의 가치에 대해 Gε를 호출한다. m=1이면 API와 동일하고, m→∞이면 PSDP∞와 동등해진다.
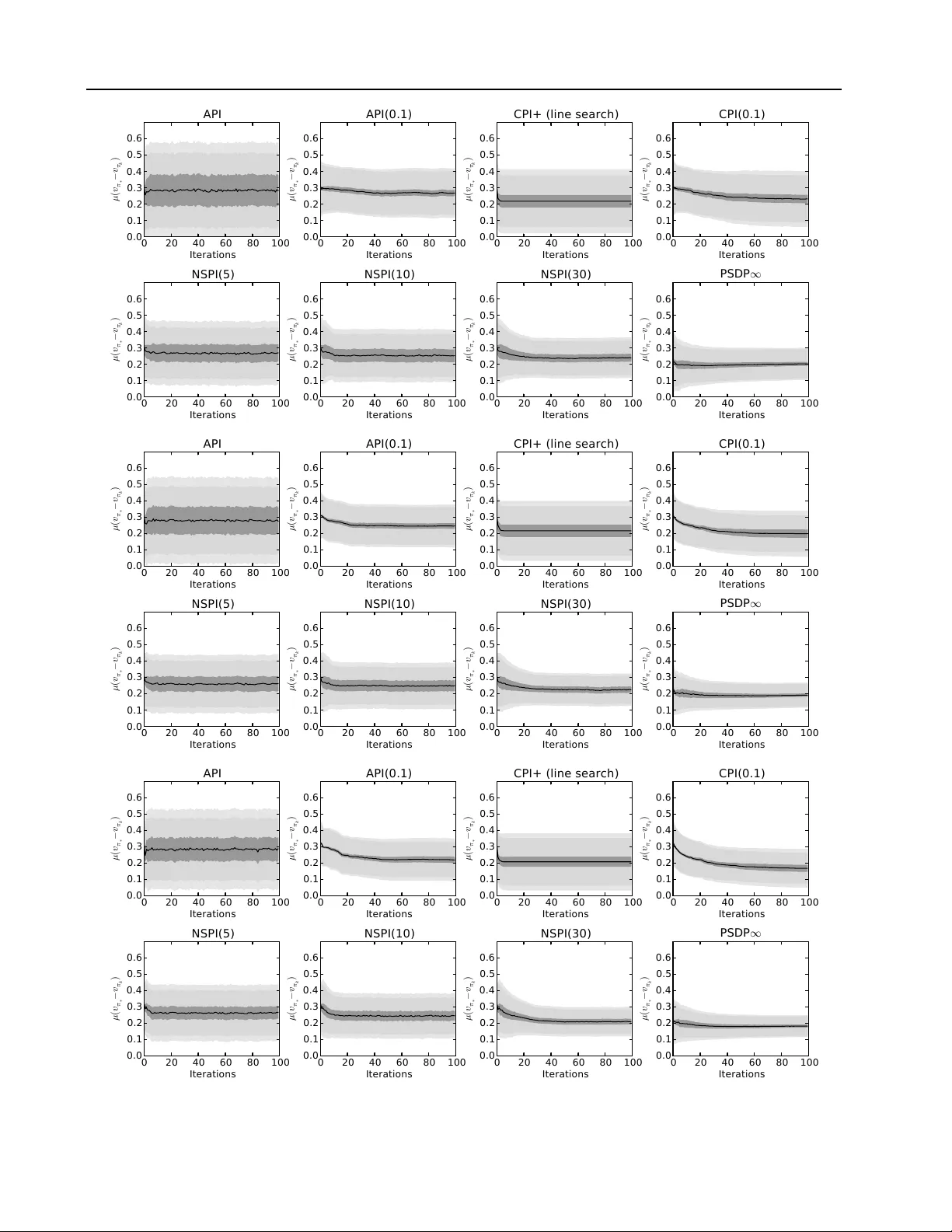
성능 분석에서는 각 알고리즘에 대한 기대 손실 μ(vπ*−vπ)의 상한을 집중 가능성(concentrability) 상수와 ε, γ, α, m 등의 파라미터로 표현한다. 표 1에 정리된 바와 같이, API는 C(2,1,0)·(1‑γ)⁻²·ε·log(1/ε) 형태의 경계를 갖는다. CPI는 Cπ*·(1‑γ)⁻³·ε·log(1/ε)·(1/α) 등 더 강력한 상수를 사용하지만, 수렴에 필요한 반복 횟수가 O(1/ε²)로 지수적으로 늘어난다. 반면 PSDP∞는 Cπ*·(1‑γ)⁻²·ε·log(1/ε)·(1/(1‑γ)) 형태로, CPI와 비슷한 보장을 제공하면서도 O(log(1/ε)) 단계만 필요하다. NSPI(m)은 m에 따라 C(2,m,0)·(1‑γ)⁻¹·ε·log(1/ε)·(1/(1‑γ^m)) 등 복합적인 경계를 가지며, m을 크게 하면 메모리와 성능 사이의 균형을 조절한다.
논문은 또한 집중 가능성 상수들의 계층 구조를 그래프(Figure 1)로 제시한다. 최상위 Cπ*는 가장 강력한 보장을 제공하고, 하위에 위치한 C(1)π*·, C(1,0)·, C(2,1,0)· 등은 점차 약해진다. 이 계층은 “B가 유한하면 A도 유한”이라는 포함 관계로 정의되며, 특정 MDP에 대해 어떤 상수는 유한하지만 그 하위 상수는 무한할 수 있음을 보여준다. 따라서 CPI가 API보다 이론적으로 우수하지만, 실제 적용 시 메모리와 연산 복잡도 측면에서 비용이 크게 증가한다는 트레이드오프가 명확히 드러난다.
실험에서는 GridWorld, Random MDP 등 다양한 환경에서 네 알고리즘을 구현하고, 근사 그리디 오류 ε를 변화시키며 수렴 속도와 최종 손실을 측정한다. 결과는 이론적 경계와 일치한다. CPI는 가장 낮은 손실을 달성하지만 반복 횟수가 급격히 늘어나고, PSDP∞는 비슷한 손실을 훨씬 적은 반복으로 달성한다. NSPI(m)은 m을 증가시킬수록 손실이 감소하지만 메모리 사용량도 증가하는 전형적인 비용‑효율 곡선을 보여준다.
결론적으로, 논문은 근사 정책 반복 알고리즘 간의 성능‑복잡도 트레이드오프를 정량적으로 분석하고, 실제 적용 시 요구되는 메모리와 연산 자원을 고려해 적절한 알고리즘을 선택할 수 있는 가이드라인을 제공한다. 특히, CPI와 PSDP∞는 각각 보수적·전진적 특성을 갖고 있으며, NSPI(m)은 이 둘 사이를 조정하는 파라미터 m을 통해 메모리와 성능을 균형 있게 관리할 수 있음을 강조한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기