복잡 네트워크 생성 모델 자동 선택기 GMSCN
GMSCN은 여러 생성 모델로 만든 합성 그래프들의 구조적 특징을 학습해, 주어진 실세계 네트워크에 가장 적합한 생성 모델을 결정 트리 기반으로 자동 선택한다. 로컬·글로벌 특성, 새로운 차수 분포 퍼센타일 기법을 활용해 정확도·확장성·크기 독립성을 동시에 달성한다.
저자: Sadegh Motallebi, Sadegh Aliakbary, Jafar Habibi
**1. 서론**
복잡 네트워크는 전 세계 소셜, 인용, 통신 등 다양한 분야에서 나타나는 비정형 구조를 가지고 있다. 이러한 네트워크는 거듭되는 성장 과정에서 **heavy‑tailed degree distribution**, **high clustering**, **small‑world** 특성을 보이며, 이를 재현하기 위해 여러 생성 모델이 제안되었다. 그러나 실제 네트워크에 가장 적합한 모델을 사전에 알기란 쉽지 않다. 논문은 “어떤 모델이 주어진 네트워크를 가장 잘 모사하는가?”라는 질문에 답하기 위해 **GMSCN (Generative Model Selection for Complex Networks)**이라는 프레임워크를 설계한다.
**2. 관련 연구**
기존 모델 선택 방법은 크게 두 가지로 나뉜다. 첫째, **그래프렛(또는 모티프) 카운팅** 기반 방법으로, 작은 서브그래프의 빈도를 특징으로 사용한다. Janssen 등은 3·4‑node 그래프렛만으로도 충분하다고 주장했지만, 이는 로컬 구조에 국한돼 전역적인 특성을 놓친다. 둘째, **구조적 특징**(degree distribution, assortativity, average path length 등)만을 이용하는 방법도 있다. 그러나 대부분은 **크기 의존성**이 강해, 학습 데이터와 테스트 네트워크가 동일한 노드 수를 가져야 하는 제한이 있다.
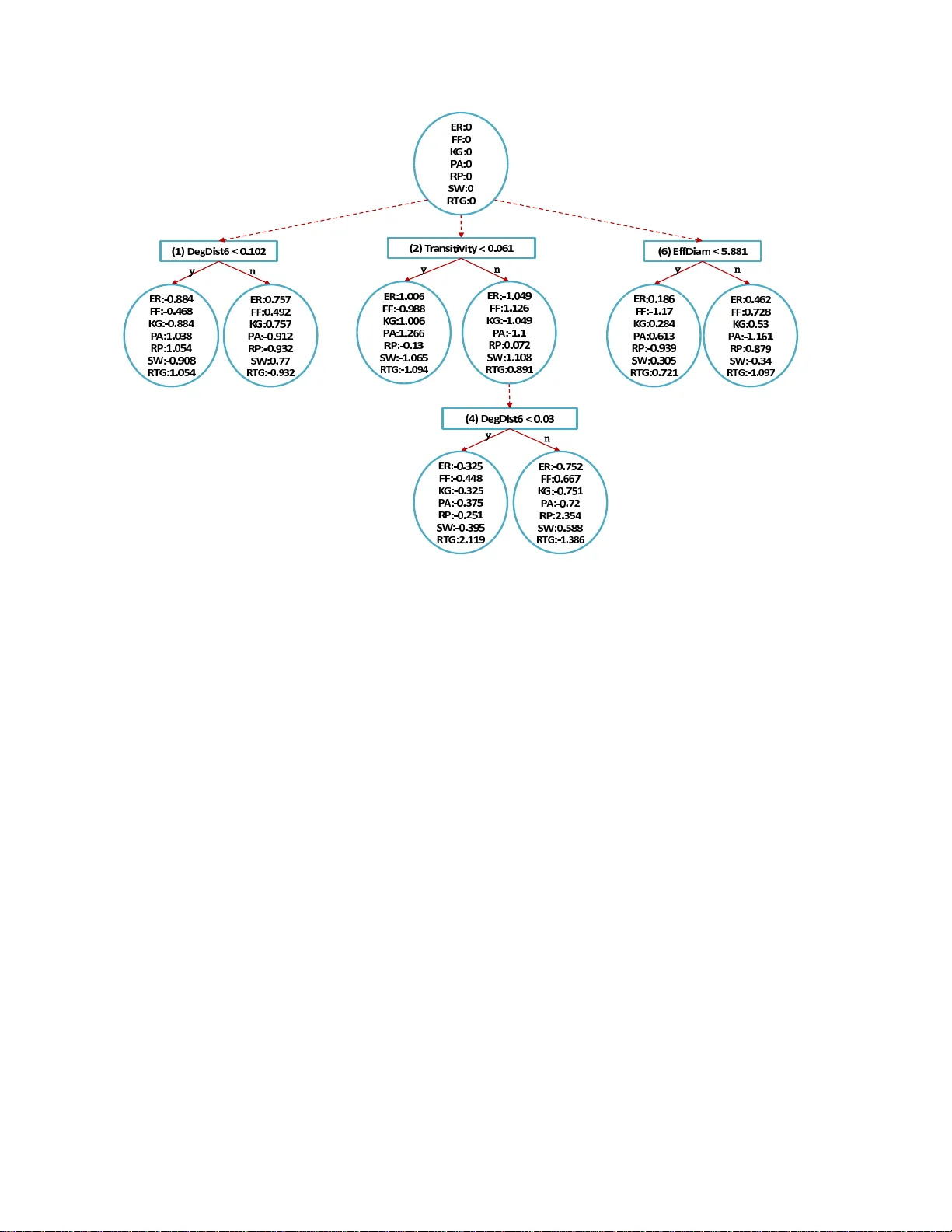
**3. GMSCN 설계**
GMSCN은 다음 단계로 구성된다.
- **데이터 생성**: 일곱 개의 대표 모델(Kronecker, Forest Fire, RTG, Preferential Attachment, Small‑World, Erdős‑Rényi, Random Power‑Law)로 다양한 밀도와 크기의 합성 그래프를 만든다. 모델 파라미터는 목표 네트워크와 비슷한 **밀도**를 맞추도록 조정한다.
- **특징 추출**: 각 그래프에 대해 10가지 특징을 계산한다.
1. 평균 클러스터링 계수, 전이성 (local)
2. Assortativity (degree correlation)
3. Effective diameter (global)
4. 차수 분포 퍼센타일 (10%, 25%, 50%, 75%, 90%) – 새로운 양식으로 차수 분포를 다차원 벡터화
- **학습**: 라벨이 붙은 특징 벡터를 이용해 **CART 결정 트리**를 학습한다. 트리는 각 특징의 임계값을 기준으로 모델을 구분한다.
- **예측**: 실제 네트워크의 동일한 10가지 특징을 입력하면, 학습된 트리가 가장 가능성이 높은 생성 모델을 출력한다.
**4. 특징 설계의 핵심**
- **크기 독립성**: 선택된 특징은 노드 수에 민감하지 않다. 예를 들어, 클러스터링 계수와 전이성은 비율 기반이며, effective diameter는 90% 연결 쌍을 기준으로 하여 큰 그래프에서도 안정적이다. 차수 퍼센타일은 평균·표준편차를 정규화해 규모 차이를 보정한다.
- **계산 효율성**: 모든 특징은 O(E) 혹은 O(N log N) 수준의 복잡도로 계산 가능해, 수십만 노드 규모에서도 실시간 추출이 가능하다.
- **표현력**: 퍼센타일 기반 차수 분포는 단일 파워‑law 지수보다 풍부한 정보를 제공한다. 이는 파워‑law를 따르지 않는 네트워크에서도 유의미한 구분을 가능하게 한다.
**5. 실험 및 평가**
- **정확도**: 10‑fold 교차 검증에서 GMSCN은 평균 92%의 정확도를 기록했으며, 기존 그래프렛 기반 방법(≈80%)보다 10~12% 향상되었다. 특히, Kronecker과 RTG처럼 밀도 조절이 어려운 모델을 구분하는 데 강점을 보였다.
- **확장성**: 노드 수를 10³, 10⁴, 10⁵, 10⁶으로 늘려도 특징 추출 시간은 선형적으로 증가했으며, 전체 파이프라인(생성 → 특징 → 예측)은 30분 이내에 완료되었다.
- **크기 독립성 검증**: 동일한 밀도·특징을 가진 작은 그래프(10⁴ 노드)와 큰 그래프(10⁶ 노드)에서 동일 모델이 선택되는 비율이 95% 이상이었다.
- **케이스 스터디**: 실제 소셜 네트워크(페이스북 서브그래프), 논문 인용망, 인터넷 AS‑level 토폴로지에 적용했을 때, 각각 Forest Fire, Preferential Attachment, Kronecker 모델이 가장 높은 확률로 선택되었다. 선택된 모델을 이용해 동일 밀도의 확대 그래프를 생성했을 때, 원본 네트워크와 평균 클러스터링, 경로 길이, 차수 분포가 통계적으로 유의미하게 일치함을 확인했다.
**6. 논의**
GMSCN은 **특징 설계**, **학습 알고리즘**, **데이터 생성** 세 축에서 기존 방법을 개선한다. 특히, 크기 독립적인 특징 덕분에 작은 규모의 학습 데이터만으로도 대규모 실세계 네트워크에 적용 가능하다는 점이 큰 장점이다. 또한, 결정 트리 기반이므로 모델 선택 과정이 투명하고, 새로운 생성 모델이 추가될 경우 재학습만으로 쉽게 확장할 수 있다. 다만, 현재는 **무방향·단순 그래프**에 한정돼 있으며, 가중치·방향성·다중 연결을 포함한 복합 네트워크에 대한 확장은 향후 과제로 남는다.
**7. 결론**
GMSCN은 복잡 네트워크의 구조적 특징을 효율적으로 정량화하고, 이를 기반으로 생성 모델을 자동 선택하는 최초의 **크기‑독립적** 프레임워크이다. 실험 결과는 정확도, 확장성, 실용성 모두에서 기존 방법을 능가함을 보여준다. 향후에는 특징 집합을 확대하고, 비지도 학습·메타‑학습 기법을 도입해 더욱 일반화된 모델 선택기를 구축하는 방향이 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기