병렬 Gaussian Process 회귀와 저랭크 공분산 행렬 근사
본 논문은 대규모 데이터에 대한 실시간 예측을 목표로, 저랭크 공분산 행렬 근사를 이용한 두 가지 병렬 Gaussian Process(GP) 회귀 방법을 제안한다. 제안된 p‑PITC/p‑PIC와 p‑ICF 기반 GP는 중앙집중식 근사 방법과 동일한 예측 정확도를 유지하면서 계산·메모리 복잡도를 크게 낮추고, 클러스터 환경에서 높은 스케일러빌리티와 속도 향상을 입증한다.
저자: Jie Chen, Nannan Cao, Kian Hsiang Low
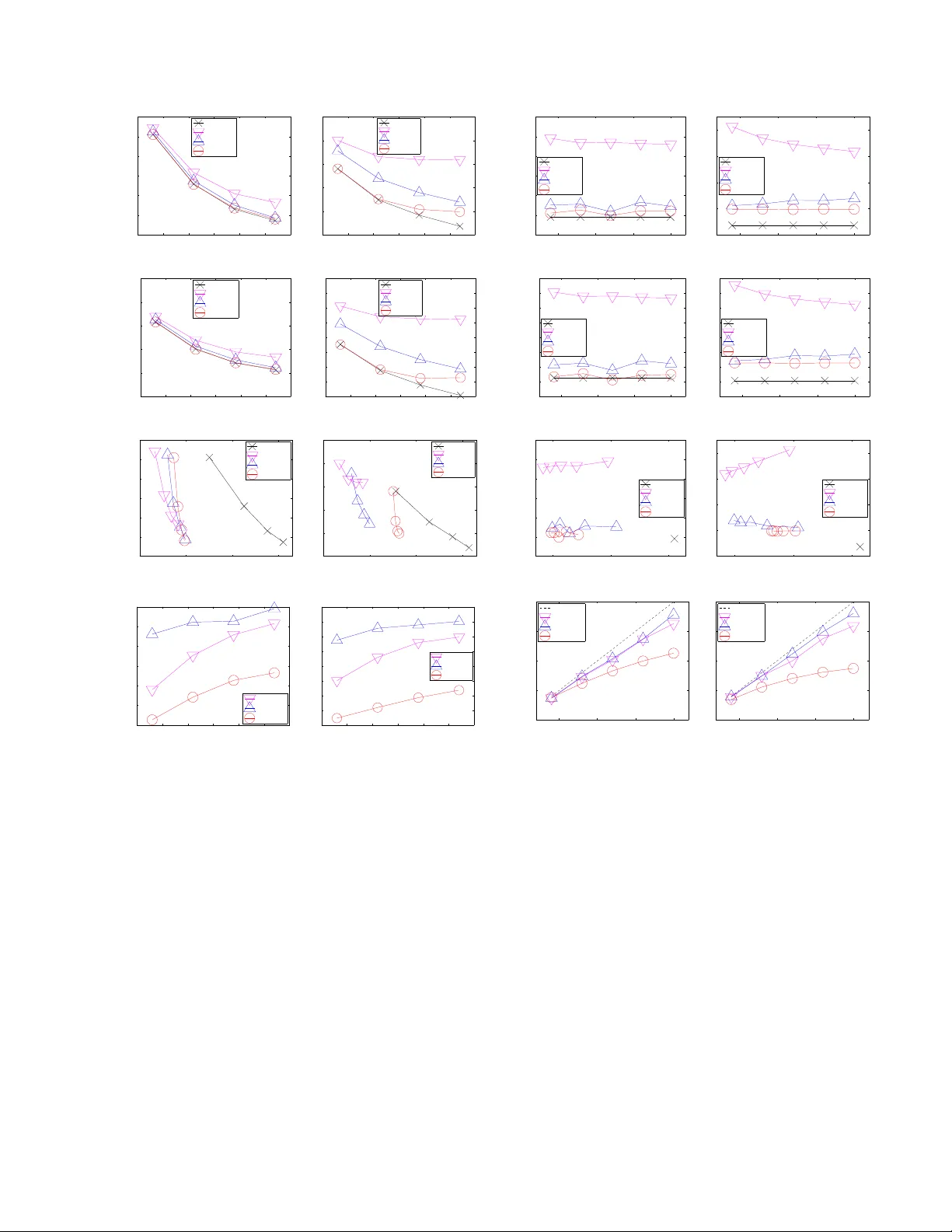
본 논문은 Gaussian Process(GP) 회귀 모델이 대규모 데이터에 적용될 때 발생하는 O(N³) 시간 복잡도와 O(N²) 메모리 요구량을 해결하고자, 저랭크 공분산 행렬 근사를 이용한 두 가지 병렬 GP 회귀 방법을 제안한다. 첫 번째 방법은 지원 집합(Support Set) 기반의 부분 독립 조건(PITC)과 부분 독립 조건(PIC) 근사를 병렬화한 p‑PITC와 p‑PIC이다. 데이터 집합 D를 M개의 워커에 균등하게 분할하고, 모든 워커가 공통 지원 집합 S를 공유한다. 각 워커는 자신의 로컬 데이터 Dₘ과 S를 이용해 로컬 요약(벡터 ˙yₘˢ와 행렬 ˙Σₘˢˢ)을 계산하고 마스터에게 전송한다. 마스터는 모든 로컬 요약을 합산해 글로벌 요약(¨yˢ, ¨Σˢˢ)을 만든 뒤, 이를 다시 워커에게 전파한다. 워커는 글로벌 요약을 이용해 자신에게 할당된 예측 입력 Uₘ에 대한 예측 평균과 공분산을 계산한다. p‑PITC는 전통적인 PITC와 동일한 예측 분포를 제공함을 정리 1을 통해 증명한다. 그러나 PITC는 로컬 데이터와 지원 집합 사이의 조건부 독립 가정 때문에 예측 정확도가 떨어질 수 있다. 이를 보완하기 위해 p‑PIC은 로컬 데이터와 글로벌 요약을 동시에 활용한다. 구체적으로, 각 워커는 로컬 요약과 로컬 데이터 Dₘ을 이용해 추가적인 보정 항을 계산하고, 이를 글로벌 요약과 결합해 최종 예측 평균과 공분산을 얻는다(식 12‑13). p‑PIC은 조건부 독립 가정을 완화하고, Dₘ과 Uₘ을 상관도가 높은 쌍으로 매칭하기 위해 간단한 병렬 클러스터링을 적용한다. 이 과정은 입력 공간을 여러 클러스터 중심에 할당하고, 각 클러스터에 속한 데이터와 예측 포인트를 동일한 워커에 모아 조건부 독립성을 강화한다.
두 번째 방법은 불완전 Cholesky 분해(Incomplete Cholesky Factorization, ICF)를 이용한 저랭크 근사이다. 전체 공분산 Σ_DD를 R‑랭크 상삼각 행렬 F의 곱으로 근사하고, Σ_DD ≈ FᵀF + σ²I 형태로 표현한다. 여기서 R은 |D|보다 훨씬 작은 차원이다. 기존의 열 기반 병렬 ICF 대신, 논문은 행 기반 병렬 ICF를 채택한다. 행 기반 ICF는 각 워커가 자신의 데이터 블록 Dₘ에 해당하는 행 부분 Fₘ을 독립적으로 계산하고 저장하게 하여, 메모리 사용량과 통신량을 최소화한다. 각 워커는 로컬 데이터와 Fₘ을 이용해 로컬 요약(벡터와 행렬)을 만든 뒤 마스터에게 전송한다. 마스터는 이를 집계해 전역 요약을 구성하고, 이를 기반으로 전체 예측을 수행한다. 이 과정은 중앙집중식 ICF 기반 GP와 동일한 예측 결과를 제공함을 정리 2에서 증명한다.
논문은 세 가지 복잡도 차원을 정량적으로 비교한다. 시간 복잡도 측면에서 p‑PITC/p‑PIC은 O(|S|³ + M·|S|²)이며, p‑ICF는 O(R³ + M·R²)이다. 메모리 복잡도는 각각 O(|S|²)와 O(R²)로, 전체 GP의 O(N²)보다 크게 감소한다. 통신 복잡도는 로컬·글로벌 요약 교환에 국한되며, 요약 크기가 지원 집합 크기 또는 저랭크 차원에 비례한다.
실험에서는 20대의 컴퓨팅 노드가 있는 클러스터에서 두 개의 실제 데이터셋(환경 센서 데이터와 교통 흐름 데이터)을 사용했다. 실험 결과, p‑PIC은 전체 GP와 거의 동일한 RMSE와 음의 로그 가능도(NLL)를 기록했으며, p‑PITC보다 현저히 높은 정확도를 보였다. p‑ICF는 저랭크 차원 R을 적절히 선택하면 전체 GP와 비슷한 예측 품질을 유지하면서 메모리 사용량을 70% 이상 절감했다. 또한, 스케일업 실험에서 노드 수를 늘릴수록 거의 선형에 가까운 속도 향상이 관찰되었으며, 이는 제안된 병렬 구조가 대규모 실시간 예측에 적합함을 입증한다.
결론적으로, 이 논문은 저랭크 공분산 근사와 병렬화라는 두 축을 결합해, 대규모 데이터에 대한 GP 회귀의 실시간 적용 가능성을 크게 확대한다. 지원 집합 선택, 데이터 클러스터링, 행 기반 ICF 등 구현상의 세부 전략을 제시함으로써, 연구자와 실무자가 클라우드·엣지 환경에서 GP 기반 예측 서비스를 구축하는 데 필요한 구체적인 설계 지침을 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기