대규모 마코프 논리 네트워크 추론을 위한 작업 분해와 라그랑주 완화
본 논문은 마코프 논리 네트워크(MLN)의 추론을 대규모 텍스트 코퍼스로 확장하기 위해, 라그랑주 완화 기법을 이용해 MLN 프로그램을 여러 작은 작업으로 분해하고, 각 작업을 특화된 알고리즘(분류, 코어퍼런스 등)으로 처리하는 시스템 Felix을 제안한다. RDBMS 기반 아키텍처와 비용 기반 물리화 전략을 결합해 데이터 이동을 최소화하고, 자동 작업 인식 컴파일러를 제공한다. 실험 결과, 1.8 M 문서 규모의 지식베이스 구축에서 기존 시스…
저자: Feng Niu, Ce Zhang, Christopher Re
본 논문은 대규모 텍스트 기반 지식베이스 구축을 목표로, 기존의 마코프 논리 네트워크(MLN) 추론이 직면한 메모리·연산량 한계를 극복하기 위한 새로운 시스템 Felix를 제안한다. MLN은 가중 논리 규칙을 통해 불확실성을 모델링하지만, 모든 규칙을 하나의 그래프에 결합해 추론하면 변수 수가 급증하고, 특히 대규모 코퍼스(수백만 문서)에서는 grounding 단계 자체가 불가능해진다. 이러한 문제를 해결하기 위해 저자들은 두 가지 핵심 아이디어를 도입한다.
첫 번째는 **라그랑주 완화(Lagrangian relaxation)** 를 이용한 **작업 분해**이다. MLN 전체를 하나의 최적화 문제로 보는 대신, 라그랑주 승수를 도입해 각 서브태스크(예: 분류, 인물·기관 코어퍼런스)를 독립적인 최적화 문제로 나눈다. 각 서브태스크는 자체적인 목적 함수를 갖고, 라그랑주 메시지를 통해 전역 제약(예: 규칙의 일관성)을 교환한다. 이 과정은 기존 그래프 기반 추론에서 사용되는 Belief Propagation과 유사하지만, 여기서는 변수 수준이 아니라 **관계(테이블) 수준**에서 분해가 이루어진다.
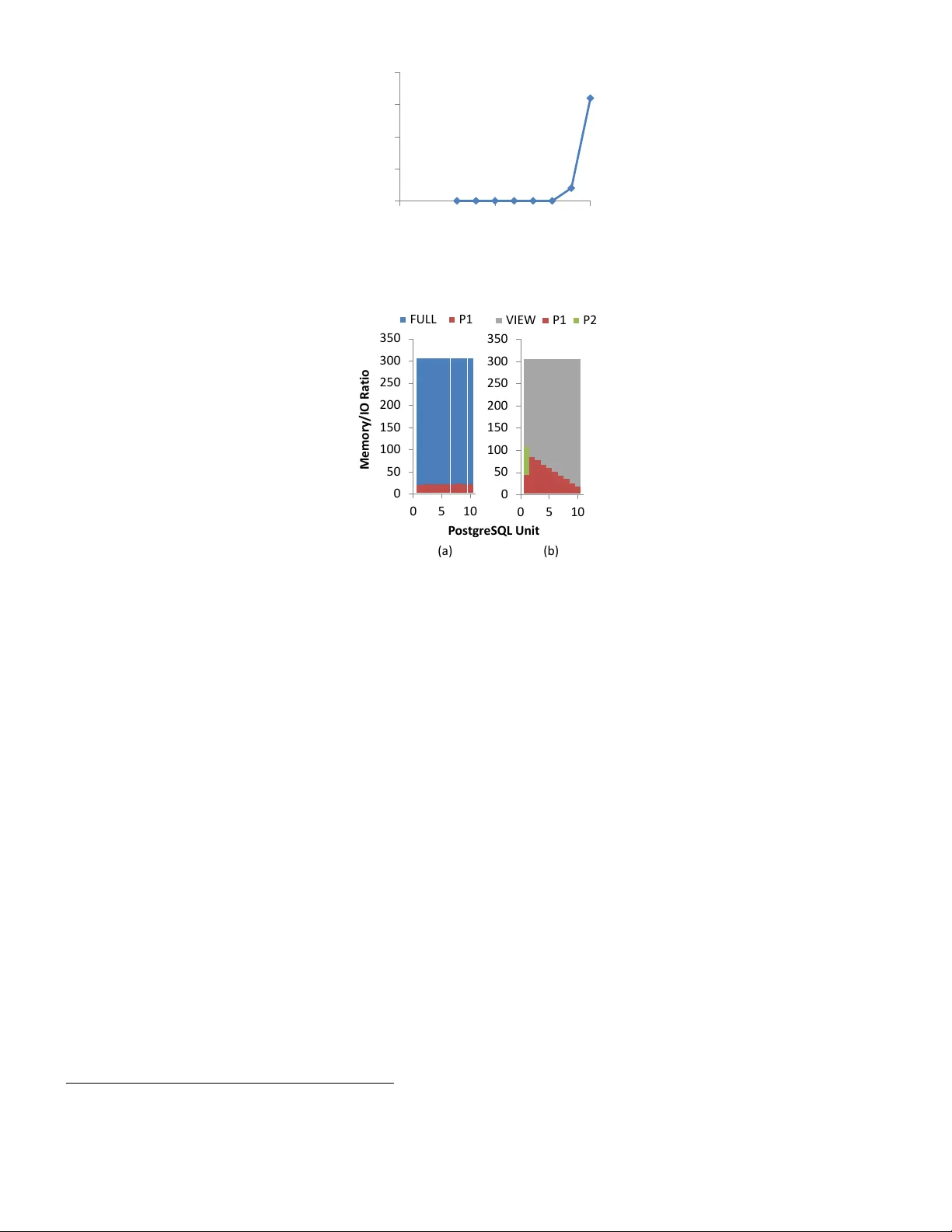
두 번째는 **RDBMS 기반 구현**이다. 모든 입력·출력·중간 데이터는 관계형 테이블에 저장되며, 데이터 이동과 변환은 순수 SQL 쿼리로 표현된다. 이를 통해 데이터베이스 엔진의 집합 연산 최적화, 인덱스 활용, 병렬 처리 등을 그대로 활용한다. 특히, 중간 결과를 언제 물리화할지 결정하는 **비용 기반 물리화 전략**을 도입한다. 저자는 ‘지연(lazy)’과 ‘선제(eager)’ 두 극단을 넘어, 작업별 접근 패턴을 분석해 일부 서브쿼리를 미리 물리화하고, 나머지는 필요 시점에만 생성하도록 최적화한다. 비용 모델은 데이터베이스의 비용 추정 기능을 활용해, 예상 I/O·CPU 비용을 계산하고 최적의 실행 계획을 선택한다. 실험에서는 이 전략이 전통적인 eager 물리화 대비 2‑3배, 순수 lazy 대비 10‑100배의 성능 향상을 보였다.
Felix는 또한 **자동 작업 인식 컴파일러**를 제공한다. 사용자는 일반적인 MLN 프로그램만 작성하면 되며, 컴파일러는 프로그램을 분석해 ‘분류’와 ‘코어퍼런스’와 같은 흔히 사용되는 서브태스크를 식별하고, 각각에 맞는 특화 알고리즘(예: CRF 기반 분류, 멀티패스 코어퍼런스)으로 매핑한다. 이 문제는 이론적으로 Π₂^P‑complete 혹은 경우에 따라 결정 불가능함을 증명하지만, 실용적인 heuristic 기반 접근을 통해 sound(오탐 최소)하지만 완전하지는 않은 컴파일러를 구현한다.
시스템 전체 흐름은 다음과 같다. 1) 사용자는 스키마·증거·규칙을 포함한 MLN 프로그램을 제출한다. 2) 컴파일러가 프로그램을 분석해 작업 분해와 특화 알고리즘 매핑을 수행한다. 3) 각 작업은 독립적인 SQL 기반 파이프라인으로 실행되며, 라그랑주 메시지는 추가 SQL 업데이트로 구현된다. 4) 비용 모델이 물리화 전략을 결정하고, 실행 계획을 최적화한다. 5) 모든 작업이 수렴하면 최종 결과(예: 엔티티 링크, 슬롯 필링)를 데이터베이스에 저장한다.
실험은 네 개의 공개 IE 데이터셋(Enron, NELL 등)과 TAC‑KBP 챌린지의 1.8 M 문서 코퍼스를 대상으로 수행되었다. 기존 시스템인 Alchemy와 Tuffy는 메모리 초과·시간 초과로 대규모 데이터에 대해 실험을 진행할 수 없었으며, 작은 샘플에서도 수십 배 느렸다. 반면 Felix는 동일한 하드웨어 환경에서 **수십 배 빠른 실행 시간**과 **수 GB 수준의 메모리 사용**을 기록했다. 품질 측면에서는 엔티티 링크에서 F1 = 0.80(인간 0.90에 근접), 슬롯 필링에서 F1 = 0.34(최신 최첨단 수준)이라는 결과를 얻었다. 또한, 특화 알고리즘을 비활성화하면 성능이 급격히 저하되는 것을 확인해, 작업 분해와 특화 알고리즘이 시스템 효율성의 핵심임을 입증했다.
결론적으로, Felix는 라그랑주 완화라는 수학적 원리를 데이터베이스 친화적인 실행 모델과 결합함으로써, 기존 MLN 시스템이 직면한 스케일링 한계를 뛰어넘는다. 작업 단위의 분해, 비용 기반 물리화, 자동 작업 인식이라는 세 가지 기술적 기여가 서로 시너지를 내어, 대규모 텍스트에서의 지식베이스 구축을 실용적인 수준으로 끌어올렸다. 향후 연구에서는 더 다양한 서브태스크(예: 관계 추출, 이벤트 모델링)와 다중 데이터베이스 환경을 지원하는 확장성을 탐색할 여지가 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기