이상치 기반 분류와 확장 알고리즘
본 논문은 이상치 탐지를 데이터 내부의 불일치 정도로 정의하고, 통합 불일치 비율(IIR)을 이용한 확장 알고리즘을 제안한다. IIR은 구간 확대 비율과 억제 비율을 결합해 이상치와 정상 데이터를 구분한다. 실험에서는 기존의 Boxplot, MAD, 평균‑표준편차 방식보다 일관된 검출 성능을 보였으며, 다중 클래스 문제에 적용한 Oscillator 알고리즘도 소개한다.
저자: 원문 참고
논문은 ‘분류는 인지의 기초이며, 이상치 탐지는 본질적인 분류 과정’이라는 관점에서 출발한다. 서론에서는 18세기 Peirce 기준부터 현대의 Boxplot, MAD, LMS·LTS 등 다양한 이상치 탐지 기법을 소개하고, 이들 방법이 결과가 일관되지 않으며 인간 눈에 보이는 이상치와 차이가 발생한다는 문제점을 제시한다. 이어서 저자는 이상치를 ‘데이터 집합의 나머지와 일관성이 없는 관측값’이라고 정의하고, 이러한 일관성 부재를 정량화하기 위해 통합 불일치 비율(IIR)을 고안한다. IIR은 두 단계의 비율, 즉 현재 구간이 평균 구간에 비해 얼마나 확대되었는지를 나타내는 확대 비율(Er)과, 이전 최대 구간 대비 현재 구간의 억제 정도(Ihr)를 결합한 값이다. Er·(N‑1)/Δ 로 구하고, Ihr·δi/(δi‑maxΔ) 로 정의한 뒤, IIR=Er/Ihr 로 계산한다. IIR 값이 사전에 정한 임계값 c 이상이 되는 최초 위치를 경계점으로 잡아, 그 이후의 관측값을 이상치로 판정한다. 알고리즘 1은 정렬된 1차원 데이터에 직접 적용하는 절차이며, 알고리즘 1′은 중앙값 집합을 확장하면서 양쪽으로 경계를 탐색하는 변형이다.
민감도 파라미터 c는 Weber 법칙(K=ΔI/I)과 연결해 이론적 근거를 마련한다. K가 0에 가까울수록 시스템이 민감해지고, 논문에서는 K=0.05에 해당하는 IIR≈1.81을 기본값으로 채택한다.
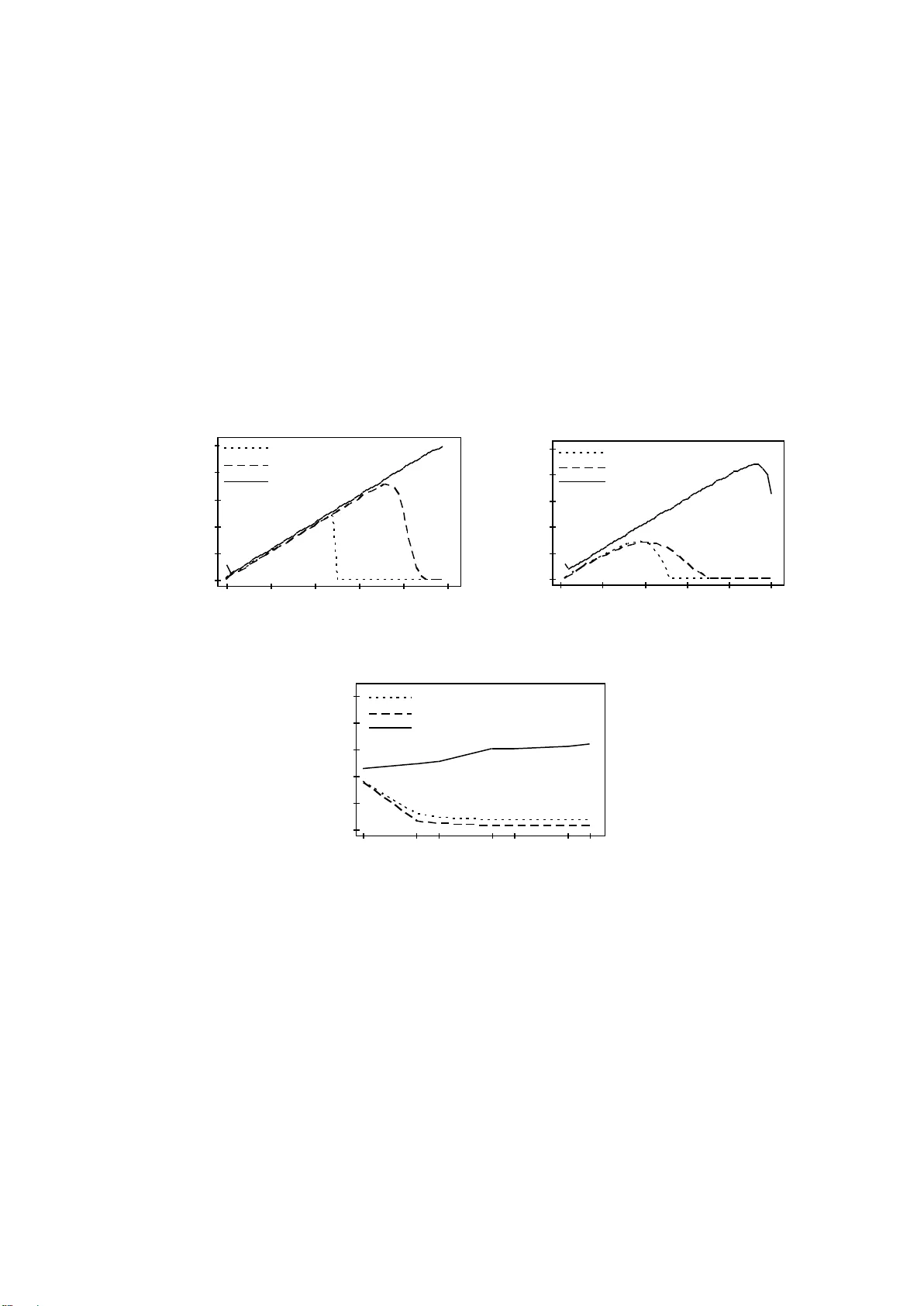
실험 부분에서는 두 정규분포(μ=0, σ=1)와(μ=10, σ=1) 혹은(μ=5, σ=1)에서 오염 비율을 0%~49%까지 변화시키며 1000번 반복 시뮬레이션을 수행한다. 결과는 Boxplot과 MAD가 각각 25%·37% 혹은 19%·20%에서 검출 능력이 급격히 떨어지는 반면, IIR 알고리즘은 47%까지 안정적으로 검출한다. 표본 크기 변화 실험에서도 IIR은 10~10000 사이에서 검출 비율이 0.5%~1% 수준으로 꾸준히 유지돼, 큰 표본에서도 작은 편차를 포착한다는 장점을 보인다.
실제 데이터로는 2001개의 고도 방사선 측정값을 사용했으며, Hampel 내부 절차가 396개의 이상치를 식별한 것과 비교해 IIR은 398개를 검출하면서 정상 구간을 더 정확히 설정한다. 기존 방법들은 전역적인 통계량에 의존해 국부적 경계를 놓치는 반면, IIR은 구간 간 차이를 직접 이용해 보다 정밀한 경계를 제공한다.
논의에서는 1846년 Venus 반경 측정 데이터(15개)와 같은 고전 사례를 재검토한다. Peirce 기준, Grubbs, Tietjen‑Moore 등 다양한 기존 방법이 서로 다른 결과를 내는 반면, IIR은 임계값에 따라 -1.40만을 이상치로 판정해 일관성을 유지한다.
다중 클래스 확장으로는 Oscillator 알고리즘을 제시한다. Ruspini 데이터셋(75점, 4~5클러스터)에서 확장 알고리즘을 적용해 클러스터 경계를 자동으로 탐색하고, k‑means와 비교해 비슷하거나 더 나은 군집화를 달성한다.
결론에서는 IIR 기반 확장 알고리즘이 기존 통계적 기준보다 데이터 내부의 불일치를 직접 측정함으로써 더 견고하고 민감도 조절이 가능하다고 주장한다. 다만 임계값 선택에 대한 경험적 의존성과 고차원·다변량 데이터에 대한 적용 가능성은 추후 연구가 필요하다고 언급한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기