공간 변이 구조를 드러내는 동적 클러스터링
본 논문은 시공간적으로 연관된 함수형 데이터를 대상으로, 각 클러스터의 공간 변이성을 대표하는 변곡선(variogram)을 프로토타입으로 삼는 동적 클러스터링 알고리즘을 제안한다. 변곡선 기반 적합 기준을 반복적으로 최적화함으로써, 공간적 변이 구조가 유사한 함수들을 군집화하고, 각 군집에 대한 대표 변이 모델을 동시에 추정한다. 시뮬레이션 및 실제 환경 데이터에 적용한 결과, 제안 방법이 기존 방법보다 공간적 이질성을 효과적으로 포착함을 확인…
저자: Elvira Romano, Antonio Balzanella, Rosanna Verde
본 논문은 공간적으로 연관된 함수형 데이터, 즉 각 관측 지점에서 시간에 따라 연속적인 현상을 기록한 데이터를 대상으로, 이러한 데이터의 공간 변이 구조를 효과적으로 파악하고 군집화하기 위한 새로운 방법론을 제시한다. 연구 배경으로는 환경 과학, 해양학, 지질학 등에서 온도, 강수량, 오염 물질 농도 등과 같은 시계열 데이터가 넓은 지역에 걸쳐 수집되며, 이들 데이터는 시간적 연속성뿐 아니라 공간적 상관성을 동시에 갖는다는 점을 들었다. 기존의 공간 함수형 데이터 분석(SFDA)은 주로 변량 분석, 회귀, 예측(kriging) 등에 초점을 맞추었으며, 군집화에 대해서는 가중 거리 기반 계층적 방법, 모델 기반 베이지안 방법, 그리고 제한적인 동적 클러스터링 방법만이 제안된 상태였다. 이러한 기존 방법들은 (1) 공간 가중치를 단순히 거리 함수에 매핑하거나, (2) 복잡한 베이지안 추정으로 인해 계산 비용이 크게 증가하거나, (3) 함수 자체의 고차원 특성을 충분히 반영하지 못한다는 한계를 가지고 있었다.
이에 저자는 “변곡선 기반 동적 클러스터링(Dynamic Clustering based on Variogram)”이라는 새로운 프레임워크를 고안한다. 핵심 아이디어는 각 군집을 대표하는 변곡선(variogram) 모델을 프로토타입으로 설정하고, 개별 함수가 해당 변곡선과 얼마나 일치하는지를 측정하여 군집을 재배정한다는 것이다. 변곡선은 공간적 변이의 정도를 거리 h에 따라 정량화한 함수이며, 전통적인 지리통계학에서 공간 상관을 파악하는 데 사용된다. 여기서는 함수형 데이터에 대해 ‘중심 변곡선(centered variogram)’ γ_{s_i}(h)를 정의한다. 이는 특정 위치 s_i에서 시작해 다른 모든 위치와의 차이 제곱을 거리별로 평균한 것으로, 식 (5)–(6)에서 제시된다.
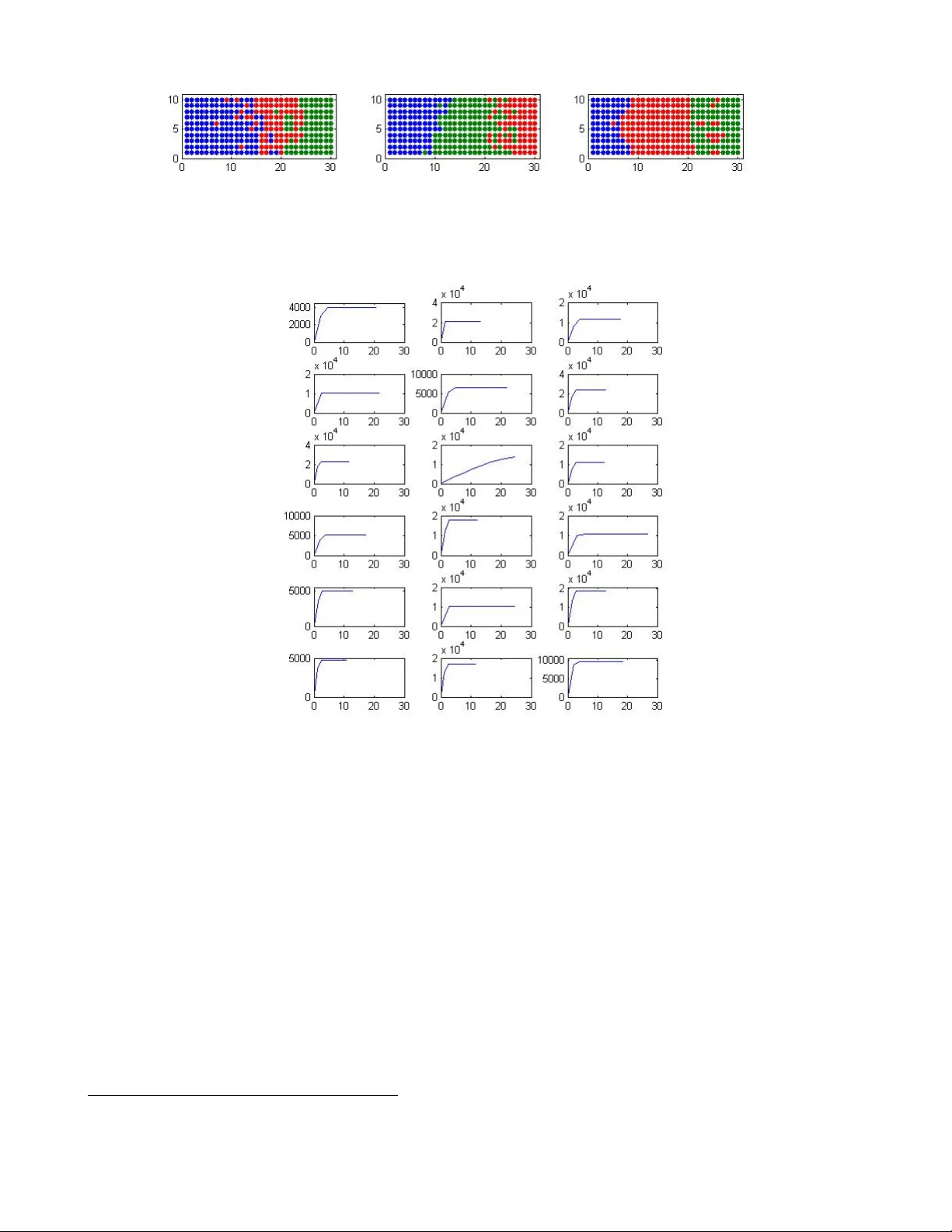
알고리즘은 다음과 같은 두 단계로 구성된다.
1. **표현 단계 (Representation Step)**: 현재 군집 C_k에 속한 모든 함수들의 중심 변곡선을 계산하고, 이를 평균하여 군집의 대표 변곡선 γ*_k(h)를 추정한다. 이때 변곡선 모델은 구형, 가우시안, 지수형 등 전통적인 형태 중 하나를 선택하고, 최소제곱(OLS) 혹은 가중 최소제곱(WLS) 방법으로 파라미터를 추정한다.
2. **할당 단계 (Allocation Step)**: 각 함수 χ_{s_i}(t)에 대해 그 함수의 중심 변곡선 γ_{s_i,k}(h)와 모든 군집의 대표 변곡선 γ*_k(h) 사이의 제곱 거리(가중치 ρ_k를 포함)를 계산한다. 거리 계산은 h*라는 임계 거리 구간
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기