20개의 상자와 20질문: 효율적인 이진 탐색과 허프만 코딩
본 논문은 20개의 상자 중 하나에 숨은 공을 찾는 “20질문 문제”를 통해 이진 질문의 정보량과 소스 코딩 기법을 설명한다. 일대일 탐색, 상향 분할, 하향 병합(허프만 코딩) 세 가지 전략을 비교하고, 하향 병합이 평균 비트 사용량과 최적 코드 길이 측면에서 최적임을 증명한다.
저자: Barco You
본 논문은 “Twenty Questions Problem”(TQP)을 사례로 삼아 이진 질문을 통한 정보 획득과 소스 코딩 방법을 탐구한다. 서론에서는 현대 컴퓨터가 이진 연산에 기반한다는 점을 강조하며, ‘예/아니오’ 질문이 1비트의 연산 자원을 소비한다는 직관을 제시한다. 이후 20개의 상자 중 하나에 공이 숨겨져 있다는 설정을 통해 구체적인 문제를 정의한다.
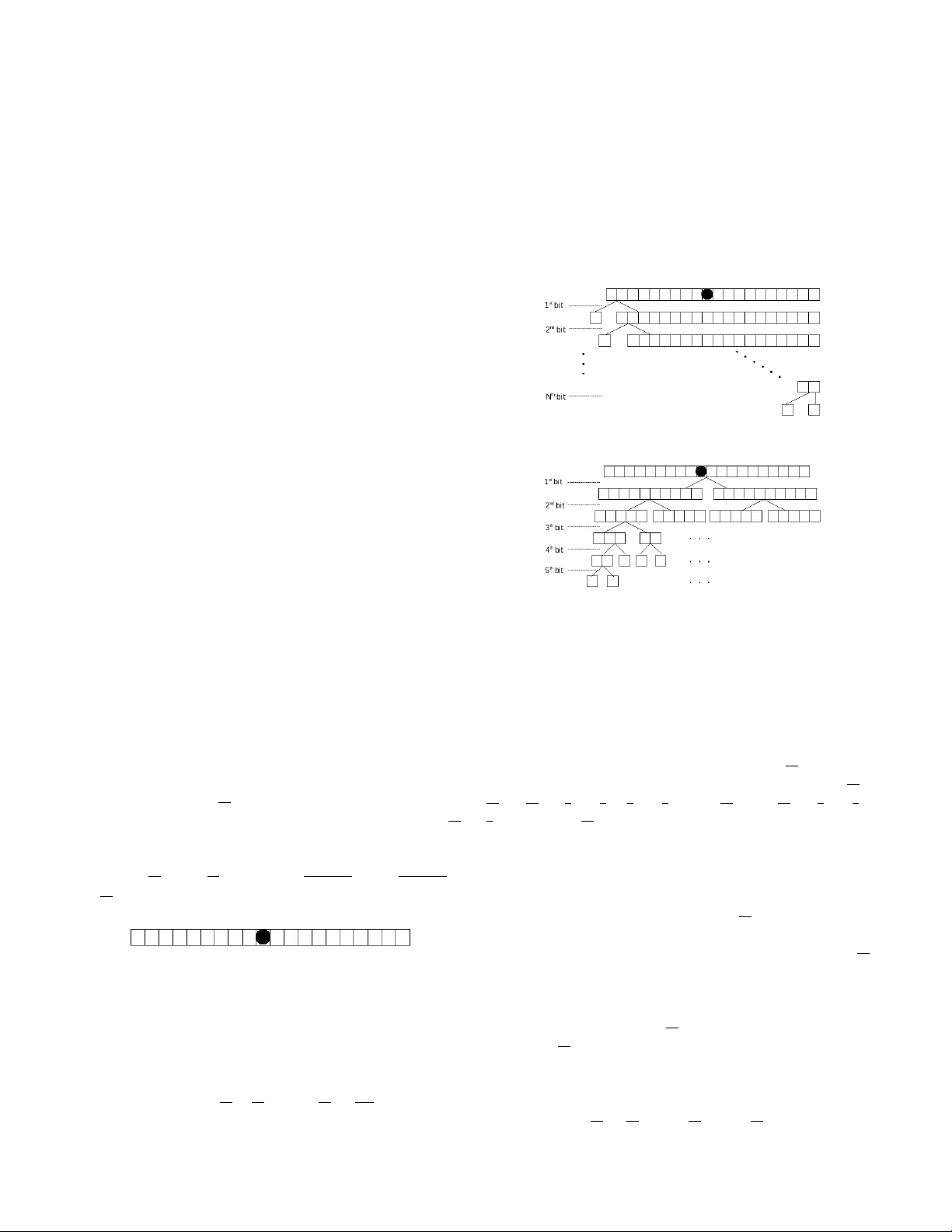
제Ⅰ절 “One‑by‑One Asking”에서는 가장 단순한 전략을 설명한다. 상자를 왼쪽부터 차례로 열어가며 공이 있는지 묻는 방식이다. 각 질문은 1비트를 사용하고, 공이 N번째 상자에 있을 경우 누적 정보량은 \(\log_2 20\)≈4.3219비트가 된다. 그러나 기대 비트 수는 \(\frac{1+19/20+18/20+\dots+2/20}{1}=10.45\)비트로, 실제 필요 비트보다 크게 초과한다. 이는 순차 탐색이 비효율적임을 보여준다.
제Ⅱ절 “Top‑Down Division”에서는 이진 탐색과 유사한 방법을 제시한다. 매 질문마다 남은 상자를 두 그룹으로 거의 동일하게 나누어 ‘공이 어느 그룹에 있는가’를 묻는다. 이 과정을 반복하면 최악의 경우 ⌈log₂20⌉=5번의 질문만 필요하고, 기대 비트 수는 4.4비트 정도로 크게 개선된다. 논문은 이 방법이 정보량 측면에서 엔트로피에 근접하지만, 그룹 크기가 정확히 반으로 나뉘지 않을 경우 약간의 비효율이 존재한다고 언급한다.
제Ⅲ절 “Down‑Top Merging”은 허프만 코딩(Huffman Coding)과 동일한 병합 과정을 적용한다. 초기에는 20개의 심볼(각 상자) 모두 확률 1/20을 가진다. 가장 작은 두 확률을 가진 심볼을 합쳐 새로운 심볼(확률 2/20)을 만든 뒤, 다시 가장 작은 두 심볼을 선택해 병합한다. 이 과정을 반복해 1이 되는 루트 심볼까지 진행한다. 병합 과정에서 발생하는 비트 비용은 각 병합 단계에서 합쳐진 확률의 합에 1비트를 곱한 값이다. 최종적으로 기대 비트 수는 4.4비트이며, 이는 Top‑Down Division과 동일하지만 실제 코드 길이와 평균 비트 사용 효율성 면에서 최적임을 주장한다.
제Ⅳ절에서는 두 방법의 차이를 정리하고, “Down‑Top Merging”이 최적임을 강조한다. 논문은 핵심 정리로 “허프만 코드는 모든 심볼 코딩 방법 중 평균 코드 길이가 최소이다”라는 정리를 제시하고, 간단한 증명을 제공한다. 증명에서는 각 레벨에서 가장 작은 확률 두 개를 병합하는 것이 전체 비트 소비를 최소화한다는 논리를 전개한다.
또한, 정리 1의 일반성을 보여주기 위해 확률 집합 \(\{2/5, 1/3, 1/5, 1/15\}\)를 예시로 든다. 허프만 병합을 적용하면 평균 코드 길이가 1.87비트가 되지만, 단순한 ‘그리디 분할’ 방식은 2비트가 된다. 이를 통해 허프만 병합이 실제로 더 효율적임을 실증한다.
결론에서는 세 가지 전략이 모두 동일한 정보량(엔트로피) \(\log_2 20\)≈4.3219비트를 제공하지만, 평균 비트 사용량과 구현 효율성에서 차이가 있음을 정리한다. 특히 “Down‑Top Merging”(허프만 코딩)이 최적이며, “Top‑Down Division”은 서브옵티멀하지만 여전히 실용적인 방법이라고 평가한다. 논문은 마지막에 핵심 메시지를 “질문을 이진 트리 형태로 설계하면 최소 비트로 목표를 달성한다”는 형태로 마무리한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기