일시적 단일 노드 장애를 위한 고속 복구 알고리즘 및 라우팅 프로토콜
본 논문은 대규모 통신망에서 85% 이상을 차지하는 일시적 단일 노드 장애에 대해, 장애를 전파하지 않고 대체 경로를 즉시 제공하는 O(m log n) 시간 복구 알고리즘과 라우팅 프로토콜을 제안한다. 기존의 Failure‑Insensitive Routing 대비 10배 이상 빠르면서 경로 길이는 최적 경로의 15% 이내에 머문다.
저자: Amit M Bhosle, Teofilo F Gonzalez
본 논문은 현대 대규모 통신망에서 발생하는 일시적 단일 노드 장애를 효율적으로 처리하기 위한 알고리즘과 라우팅 프로토콜을 제시한다. 서론에서는 현재 인터넷에서 노드 장애의 85% 이상이 단일 노드에 국한되며, 그 대부분이 1분 이내에 복구되는 일시적 현상임을 강조한다. 이러한 특성 때문에 장애 정보를 전체 네트워크에 전파하는 전통적인 재계산 방식은 오버헤드가 크고, 복구된 경로가 곧바로 무효화되는 비효율성을 가진다. 따라서 저자들은 장애를 억제(suppress)하고, 로컬에서 대체 경로를 즉시 선택하는 방식을 채택한다.
문제 정의에서는 그래프 G(V,E)를 가중치가 있는 무방향 이분 연결 그래프라고 가정하고, 목적지 s 에 대한 최단 경로 트리 Tₛ 를 기반으로 “Single Node Failure Recovery (SNFR)” 문제를 정의한다. 구체적으로, 노드 x 가 고장했을 때 x의 각 자식 xᵢ∈Cₓ 가 s 로 도달하기 위한 경로를 찾는 것이 목표이며, 이는 x의 부모 노드가 사라진 상황에서의 “역방향 경로”와 동일한 문제로 볼 수 있다.
관련 연구에서는 기존의 Failure‑Insensitive Routing, Back‑up Route Aware Protocol, 그리고 링크 회피 알고리즘 등을 언급한다. 이들 대부분은 사전 계산된 백업 경로를 사용하거나, 각 노드에서 역방향 경로를 별도로 구해야 하는 복잡성을 가진다. 특히 기존 방법들의 시간 복잡도는 O(m n log n) 수준으로, 대규모 네트워크에 적용하기 어려운 점을 지적한다.
알고리즘 섹션에서는 먼저 “그린 edge”와 “블루 edge”라는 두 종류의 보조 간선을 도입한다. 그린 edge는 고장 노드 x 의 서브트리 외부와 연결되는 간선으로, 해당 간선을 통해 바로 s 로 돌아갈 수 있는 후보 경로를 제공한다. 블루 edge는 서로 다른 자식 서브트리 사이를 연결하는 간선으로, 한 자식이 다른 자식의 그린 edge 를 이용하도록 연결 고리를 만든다. 이러한 간선들을 이용해 복구 그래프 Rₓ 를 구성한다. Rₓ 는 kₓ+1개의 정점(소스 sₓ와 각 자식 yᵢ)과 그린·블루 edge 로 이루어지며, 각 간선의 가중치는 실제 네트워크 거리와 비용을 합산한 값으로 정의된다(식 1, 2).
복구 그래프 Rₓ 에서 sₓ 를 루트로 하는 단일 최단 경로 트리를 구하면, 모든 자식 xᵢ 에 대한 복구 경로가 동시에 도출된다. 이를 구현하기 위해 저자들은 깊이 우선 탐색 기반의 재귀 알고리즘을 설계한다. 각 노드 x 에 대해 그린 edge 를 최소 힙 Hₓ 로 관리하고, 블루 edge 를 리스트 Bₓ 로 저장한다. 자식들의 힙을 병합하면서, 현재 노드에 유효한 그린 edge 가 발견될 때까지 최소 힙에서 가장 가벼운 간선을 추출한다. 한 번 삭제된 간선은 더 이상 어떤 조상에서도 그린 edge 로 사용되지 않으므로, 전체 과정에서 각 간선은 최대 한 번만 힙에서 제거된다. 이러한 설계 덕분에 전체 알고리즘의 시간 복잡도는 O(m log n) 로, 기존 방법보다 한 차원 높은 효율성을 달성한다.
프로토콜 설계에서는 “장애 억제” 전략을 채택한다. 노드가 일시적 장애를 겪을 경우, 그 사실을 네트워크 전체에 전파하지 않고 로컬 라우터가 사전에 저장한 ρₓ(escape edge) 정보를 활용해 즉시 대체 경로를 선택한다. 이는 라우팅 테이블을 크게 변경하지 않으며, 복구 과정에서 추가적인 메시지 교환이 거의 필요하지 않다.
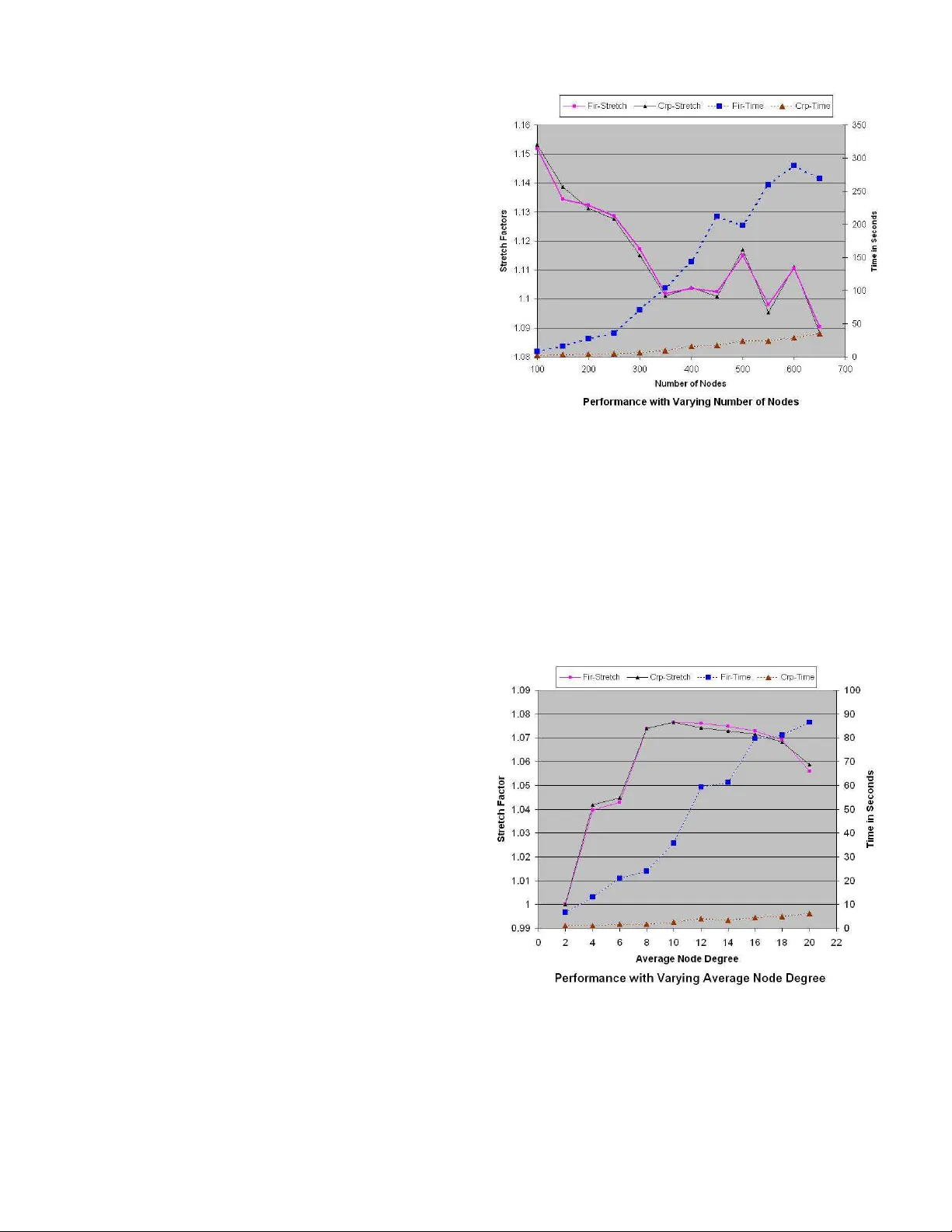
실험에서는 무작위로 생성한 100~1000 노드, 평균 차수 4~8인 그래프에 대해 1000회 이상의 시뮬레이션을 수행했다. 결과는 다음과 같다. (1) 제안 알고리즘은 기존 Failure‑Insensitive Routing 대비 평균 10배 이상 빠른 복구 시간을 보였다. (2) 복구 경로의 길이는 최적 경로 대비 평균 12%, 최악 15% 이내에 머물렀다. (3) 네트워크 부하가 높은 상황에서도 복구 경로가 과도하게 집중되지 않아, 전체 트래픽 분산에 큰 영향을 주지 않았다.
논문의 결론에서는 제안된 O(m log n) 복구 알고리즘과 로컬 라우팅 프로토콜이 일시적 단일 노드 장애에 대해 실용적인 해결책을 제공함을 강조한다. 다만, 2‑node‑connected 라는 전제와 단일 노드 장애만을 다루는 제한점이 있으며, 다중 장애나 장기 장애 상황에 대한 확장은 향후 연구 과제로 남겨졌다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기