중첩 무선 네트워크에서의 상관 무정부상태
본 논문은 다수의 이기적인 사용자가 여러 무선 접속점 사이를 동적으로 전환하는 상황을 비협력 게임으로 모델링한다. 사용자는 사전에 정의된 제한된 전략 집합을 이용해 브로드캐스트되는 훈련 신호를 처리하고, 반복 학습을 통해 진화적으로 안정된 균형에 수렴한다. 저자는 이 균형의 효율성을 가격‑무정부상태(price of anarchy) 개념으로 정량화하고, 복제법(replica method)을 사용해 분석적 식을 도출한다. 흥미롭게도 가격‑무정부상태…
저자: Panayotis Mertikopoulos, Aris L. Moustakas
본 논문은 현대 무선 통신 환경에서 다수의 사용자가 서로 다른 무선 접속점(노드) 사이를 동적으로 전환할 수 있는 상황을 비협력 게임 이론으로 모델링한다. 서론에서는 IEEE 802.11 및 5G와 같은 다양한 표준을 동시에 지원하는 디바이스가 증가함에 따라, 사용자는 여러 겹쳐진 네트워크 중 하나를 선택해야 하는 현실적인 문제를 제시한다. 기존 연구들은 전송 확률 최적화, 전력 할당, 가격 메커니즘 등을 다루었지만, 사용자가 중앙 조정 없이 자율적으로 효율적인 배분을 달성할 수 있는 메커니즘은 부족했다.
이에 저자는 ‘Simplex Game’이라는 새로운 게임 구조를 제안한다. N명의 사용자는 B개의 노드 중 하나에 연결하고, 각 노드 r은 강도 y_r(스펙트럼 효율 등)을 갖는다. 사용자가 N_r명 해당 노드에 연결하면 얻는 스루풋은 û_r = y_r·N_r/N으로 근사한다. 대규모 시스템에서는 이 식을 선형화하여 u_r = 1 − (N_r y_r)/N 형태의 보상으로 변환한다. 이때 Nash 균형은 모든 사용자가 동일한 기대 보상 û_0=1을 얻는 ‘공정’ 배분이며, 이는 노드 강도와 무관하게 존재한다.
하지만 실제 사용자는 직접 노드를 선택하지 않는다. 대신, 시스템은 M개의 훈련 신호 m∈{1,…,M}를 동기화된 브로드캐스트 형태로 제공하고, 각 사용자는 S개의 사전 정의된 전략 c_i^s: M→B를 보유한다. 전략은 무작위로 생성되며, 특정 신호 m에 대해 노드 q_r을 반환할 확률이 y_r와 동일하도록 설계된다. 이는 사용자가 노드 강도에 대한 사전 기대를 반영한다.
게임 진행 절차는 다음과 같다. (1) 초기화 단계에서 모든 사용자는 S개의 전략을 무작위로 프로그래밍한다. (2) 훈련 신호 m이 방송되고, 각 사용자는 자신의 혼합 전략 p_i(s) (∑_s p_i(s)=1)에 따라 하나의 전략 s를 선택한다. (3) 선택된 전략이 반환한 노드에 연결하고, 전체 베팅 벡터 b=∑_i b_i를 계산한다. (4) 각 사용자는 u_i = −(1/N)·b_i·b 라는 선형 보상을 받는다. 이 보상은 사용자가 선택한 노드와 전체 선택 분포 사이의 내적이 작을수록(즉, ‘소수’에 속할수록) 큰 보상을 의미한다.
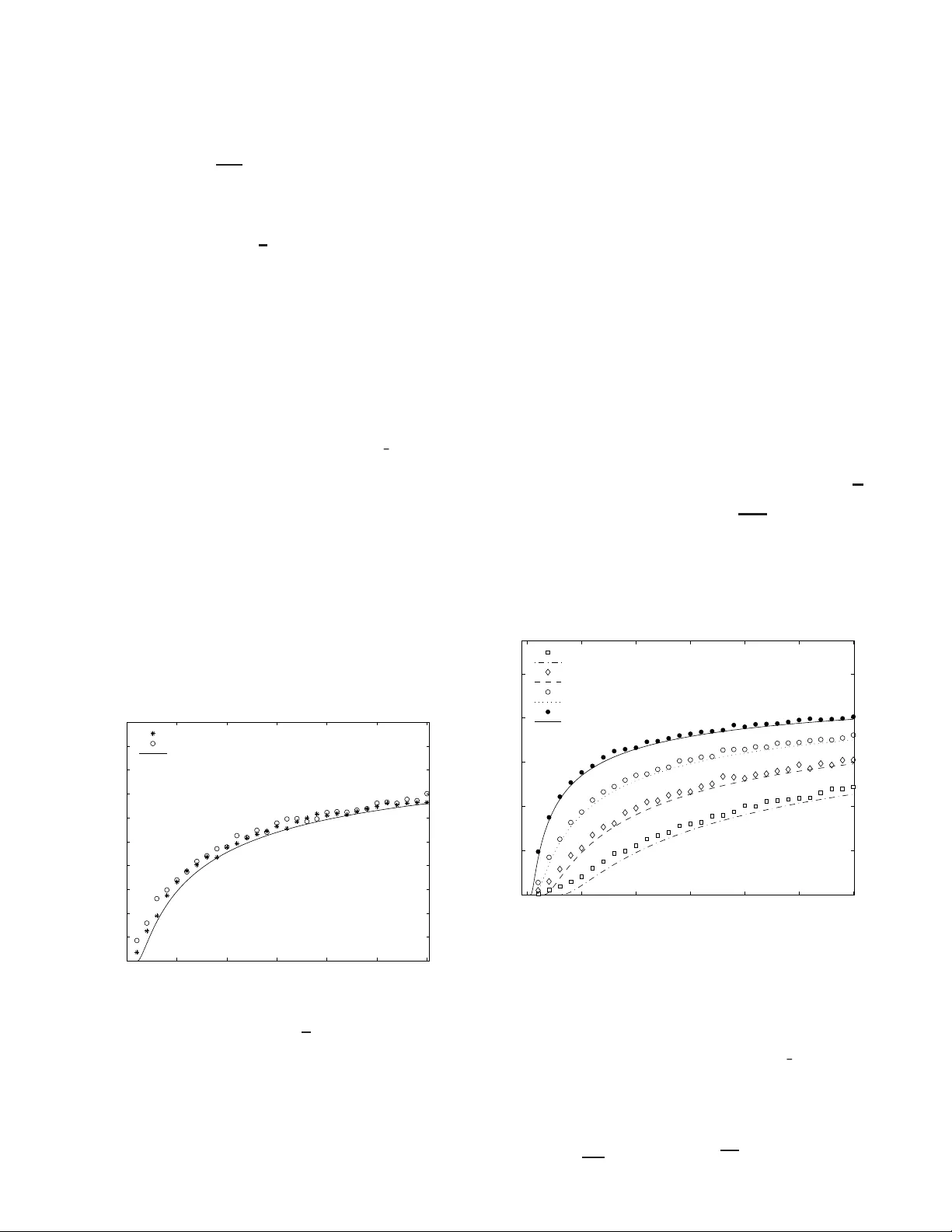
저자는 이 과정을 반복 학습(iterated exponential learning)으로 모델링하고, 복제법(replica method)을 이용해 무한 사용자(N→∞) 한계에서 시스템의 자유 에너지와 평균 보상을 분석한다. 주요 정리 11은 위 학습 메커니즘이 진화적으로 안정된 균형(Evolutionarily Stable Strategy, ESS)으로 수렴함을 증명한다. 정리 14는 가격‑무정부상태(Price of Anarchy, PoA)가 노드 강도 y_r와 무관하고, 오직 전략 수 S와 파라미터 α=λ·B/N (λ=M/N)만으로 결정된다는 것을 보여준다. 복제법을 통해 얻은 PoA 식은
\
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기