Fine-Tuning Large Language Models for Cooperative Tactical Deconfliction of Small Unmanned Aerial Systems
The growing deployment of small Unmanned Aerial Systems (sUASs) in low-altitude airspaces has increased the need for reliable tactical deconfliction under safety-critical constraints. Tactical deconfliction involves short-horizon decision-making in d…
Authors: Iman Sharifi, Alex Zongo, Peng Wei
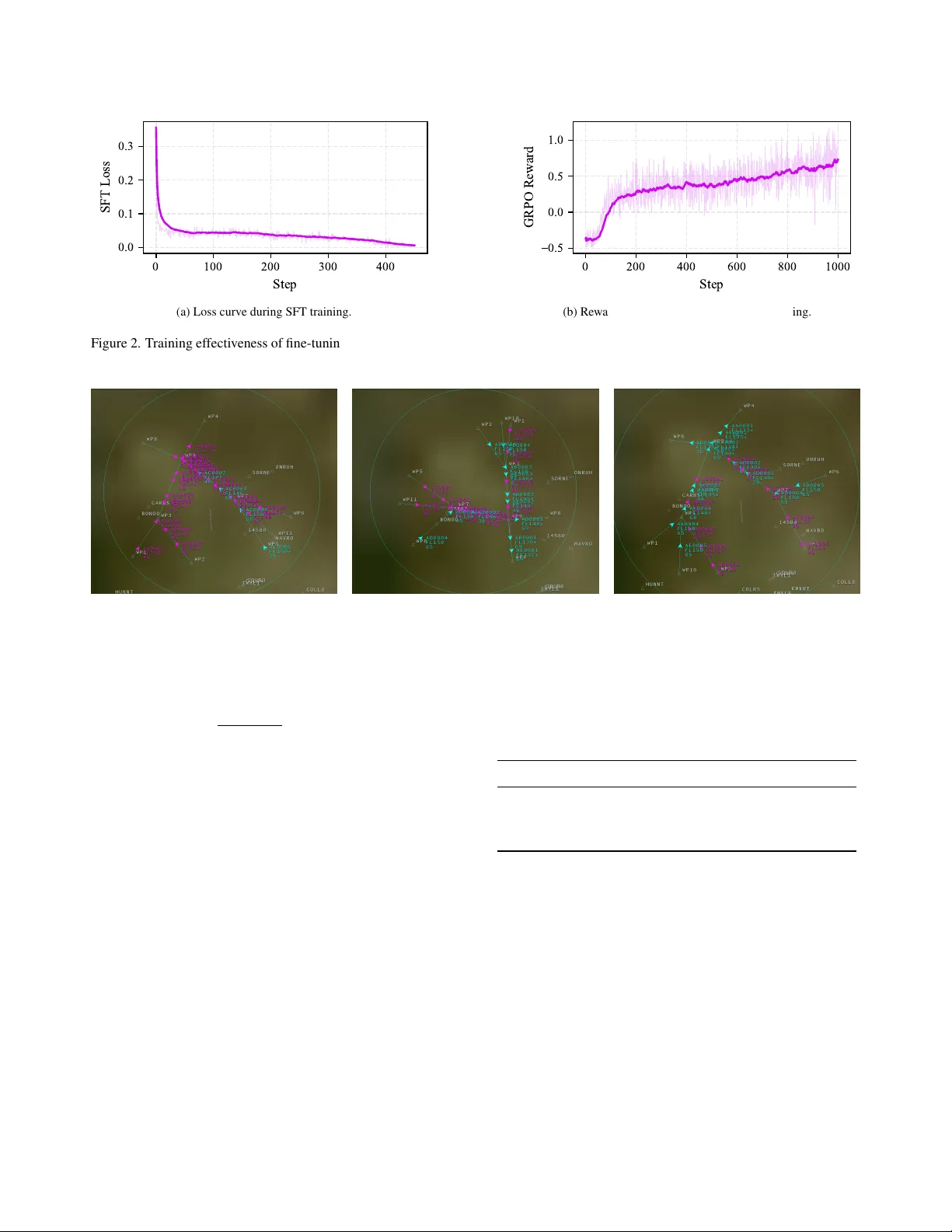
Fine-T uning Large Language Models f or Cooperativ e T actical Deconfliction of Small Unmanned Aerial Systems Iman Sharifi ∗ Alex Zongo ∗ Peng W ei George W ashington Univ ersity { i.sharifi,a.zongo,pwei } @gwu.edu ∗ Equal contribution Abstract The gr owing deployment of small Unmanned Aerial Sys- tems (sU ASs) in low-altitude airspaces has incr eased the need for r eliable tactical deconfliction under safety-critical constraints. T actical deconfliction in volves short-horizon decision-making in dense, partially observable, and het- er ogeneous multi-agent en vir onments, wher e both cooper- ative separation assurance and operational efficiency must be maintained. While Larg e Langua ge Models (LLMs) e x- hibit str ong r easoning capabilities, their dir ect application to air traffic contr ol r emains limited by insufficient domain gr ounding and unpr edictable output inconsistency . This pa- per in vestigates LLMs as decision-makers in cooperative multi-agent tactical deconfliction using fine-tuning strate- gies that align model outputs to human operator heuris- tics. W e pr opose a simulation-to-language data gener- ation pipeline based on the BlueSky air traffic simula- tor that pr oduces rule-consistent deconfliction datasets r e- flecting established safety practices. A pr etrained Qwen- Math-7B model is fine-tuned using two parameter -efficient strate gies: supervised fine-tuning with Low-Rank Adapta- tion (LoRA) and pr eference-based fine-tuning combining LoRA with Gr oup-Relative P olicy Optimization (GRPO). Experimental r esults on validation datasets and closed- loop simulations demonstrate that supervised LoRA fine- tuning substantially impr oves decision accuracy , consis- tency , and separation performance compared to the pre- trained LLM, with significant r eductions in near mid-air collisions. GRPO pr ovides additional coor dination bene- fits but exhibits r educed r obustness when interacting with heter ogeneous ag ent policies. 1. Introduction The rapid growth in civil and commercial deployment of small Unmanned Aerial Systems (sU ASs), including pack- age deli very , infrastructure inspection, and emergenc y re- sponse, has intensified the demand for safe and ef ficient op- erations in low-altitude, shared airspaces [ 10 , 25 ]. As traf- fic density increases, conflicts between vehicles become in- evitable, particularly near intersections, merging corridors, and other constrained airspace re gions. T actical decon- fliction, which in volves real-time, short-horizon decision- making that maintains safe separation while preserving operational efficiency , has therefore emerged as a central challenge in UAS traffic management (UTM) ecosystems. Unlike strategic planning [ 22 ] or trajectory optimization, tactical deconfliction must operate under strict time con- straints, partial observ ability , and complex multi-agent in- teractions, where delayed or overly conservati ve decisions can significantly degrade both safety and traffic through- put [ 29 ]. Rule-based approaches lack flexibility and scala- bility [ 8 , 16 ], while optimization-based and learning-based methods often struggle with latency , robustness, or inter- pretability under safety-critical constraints [ 6 , 27 ]. Recent advances in Large Language Models (LLMs) hav e sho wn strong capabilities in reasoning [ 18 , 24 ], contextual understanding [ 20 ], and sequential decision- making [ 30 ], making them a promising candidate for tactical deconfliction in dense, uncertain multi-agent airspaces [ 7 ]. Y et, general-purpose LLMs are not de- signed for safety-critical aviation [ 33 ]: zero-shot or prompt- based use can yield inconsistent and prompt-sensitiv e out- puts [ 9 , 14 ], misaligned with human safety norms [ 19 ], and uninformed about domain-specific trade-offs [ 19 ]. These limitations motiv ate systematic alignment of LLM beha vior with human tactical reasoning in sU AS operations. Human experts (e.g., air traffic controllers and experi- enced pilots) resolv e conflicts by applying implicit safety principles, i.e., prioritizing separation, anticipating others’ intent and reasoning over short horizons, rather than opti- mizing explicit rew ard functions [ 23 ]. W e therefore advo- cate leveraging human-aligned datasets that encode expert knowledge as logical rules, and fine-tuning LLMs to trans- fer these judgments and preferences into inference-time be- havior [ 26 ]. Compared to trial-and-error multi-agent rein- forcement learning [ 5 ], human-aligned fine-tuning can in- ject domain-appropriate reasoning priors while promoting interpretability and behavioral consistenc y [ 2 ]. In this paper , we present a simulation-to-language dataset generation pipeline that enables systematic learning of human-aligned cooperative tactical deconfliction behav- iors from high-fidelity air traffic simulations. The proposed pipeline generates div erse multi-agent scenarios, encodes human tactical knowledge through logical rules, and trans- forms raw simulation data into structured prompt–response pairs suitable for training LLMs. Using this dataset, we study two complementary fine-tuning strategies for adapt- ing pre-trained LLMs to tactical deconfliction in multi- agent sU AS environments. T o the best of our knowledge, this work constitutes the first systematic in vestigation of fine-tuned LLMs for tactical deconfliction ev aluated both on held-out datasets and in closed-loop air traffic simula- tions. The main contributions of this work are as follo ws: • W e de velop a simulation-to-language dataset genera- tion pipeline based on the BlueSky air traffic simula- tor [ 15 ] that enables rapid construction of large-scale, rule-consistent tactical deconfliction datasets, allo wing LLMs to internalize human safety heuristics and opera- tional preferences. • W e demonstrate that parameter-efficient Supervised Fine- T uning (SFT) with Low-Rank Adaptation (LoRA) [ 17 ] substantially improves LLM decision accuracy , behav- ioral consistency , and separation safety compared to a pretrained baseline, as validated through both of fline e val- uation and closed-loop simulation. • W e e valuate the performance of the preference-based fine-tuning using Group-Relati ve Policy Optimization (GRPO) compared to SFT , providing insight into the strengths and limitations of reinforcement-style align- ment for tactical deconfliction. The remainder of this paper is or ganized as follows. Sec- tion 2 revie ws the related works. Section 3 formulates the tactical deconfliction problem and the fine-tuning strategies. Section 4 describes the simulation-to-language dataset gen- erator pipeline. Section 5 elaborates on the two fine-tuning strategies. Section 6 reports experimental results and com- parativ e ev aluations. Finally , Section 7 draws conclusions. 2. Related W ork Recent research has explored the application of LLMs to air traffic control. These efforts have primarily positioned LLMs as high-lev el reasoning, interface, or knowledge- support components rather than direct low-le vel controllers. Sev eral studies employ LLMs as natural-language inter- faces integrated with e xisting conflict resolution solvers, allowing air traffic controllers to express preferences and constraints while preserving safety guarantees through re- stricted LLM outputs limited to filtering or ranking candi- date solutions [ 21 ]. Other work in vestigates LLMs as em- bodied or tool-augmented agents capable of directly issu- ing control commands in simulation environments [ 3 ], of- ten augmented with role decomposition or experience li- braries to improve reasoning consistency . Complemen- tary efforts leverage LLMs for air traffic scenario genera- tion [ 13 ], aviation-domain knowledge modeling [ 31 ], and systematic ev aluation of LLM reliability , recall, and reason- ing performance in aviation conte xts [ 12 ]. These studies re veal recurring limitations, including sensitivity to prompt structure, hallucinations, limited re- call, inference latency , and the absence of explicit align- ment with human operational preferences, that pose sig- nificant challenges for real-time, safety-critical tactical de- confliction. Unlike prior LLM-based A TC approaches that rely on zero-shot prompting or prompt engineer- ing with function-calling at inference time [ 3 ], this pa- per adopts a systematic fine-tuning strategy grounded in human-aligned data and achieves near -real-time perfor- mance. By adapting pre-trained LLMs through parameter- efficient fine-tuning and preference-aware optimization on rule-consistent, simulator-generated datasets, our approach positions LLMs as human-aligned tactical decision-makers rather than free-form reasoning agents. This directly ad- dresses the reliability and consistency concerns highlighted in existing LLM-based A TC research. 3. Problem F ormulation and Methodology 3.1. T actical Deconfliction with LLM-based P olicies W e consider a tactical deconfliction problem in a shared low-altitude airspace populated by multiple sU ASs with heterogeneous configurations and decision-making poli- cies. Agents may dif fer in kinematic limits, sensing capabil- ities, maneuverability , and onboard autonomy architecture. The objectiv e of tactical deconfliction is to maintain, coop- erativ ely , safe separation while minimizing unnecessary de- viations from nominal mission trajectories. Decisions must be made in real time under partial observ ability and amid complex multi-agent interactions. Rather than addressing deconfliction through continuous control or trajectory optimization, we formulate the prob- lem at the policy lev el. At each decision step, an agent observes a structured representation of the surrounding en- vironment, including its own state, nearby traffic informa- tion, and safety constraints. Based on this context, the agent selects a discrete tactical action, such as accelerat- ing, maintaining speed, or decelerating. The LLM serv es as a high-level policy that maps structured agent state de- scriptions to tactical decisions. The LLM outputs abstract actions that are subsequently executed by UAS flight con- trol modules, allowing the model to reason ov er heteroge- neous agent interactions and implicit safety priorities with- out requiring access to e xplicit models of low-le vel dynam- ics. T o align the LLM behavior with domain-specific op- erational requirements, we fine-tuned the model on a large- scale dataset spanning div erse traffic scenarios. 3.2. Fine-T uning Strategies 3.2.1. Supervised Fine-T uning (SFT) This first strategy adapts a pre-trained LLM to tactical de- confliction through supervised learning on human-aligned, rule-consistent datasets. Each training sample consists of a structured description of the ownship’ s local traffic con- text paired with a tar get tactical action deriv ed from human- designed safety rules. Giv en a dataset D = { ( x i , y i ) } N i =1 , where x i denotes the ownship context and y i the corre- sponding target action, the objecti ve is to maximize the con- ditional likelihood of human-aligned decisions under the fine-tuned model. Formally , SFT minimizes the negativ e log-likelihood loss L SFT = − E ( x,y ) ∼D [log p θ ( y | x )] , where p θ denotes the LLM parameterized by θ . Minimizing this loss transfers human decision heuristics into the model’ s inference behav- ior , encouraging consistent reproduction of safety-oriented tactical actions across similar agent state configurations. T o enable ef ficient domain adaptation without updat- ing the full parameter set of the LLM, we employ Low- Rank Adaptation (LoRA) [ 17 ], as sho wn in Figure 1 , which injects trainable low-rank updates into selected pro- jection layers while keeping the pretrained weights frozen. This parameter-efficient design enables scalable adaptation while preserving the general reasoning capabilities of the base model. 3.2.2. Group-Relati ve Policy Optimization (GRPO) The second fine-tuning strategy employs GRPO, a preference-based alignment method that refines LLM be- havior using sampled candidate actions and scalar re- ward feedback. For a given agent context x , the pre- trained LLM generates a set of candidate tactical responses { y (1) , . . . , y ( K ) } via high-temperature sampling, promoting decision exploration be yond deterministic imitation. Each candidate response is e valuated using a task- specific rew ard function R ( x, y ) that encodes human- aligned safety rules and operational preferences, assign- ing higher scores to actions that maintain separation, re- spect right-of-way precedence, and fav or conservati ve, in- terpretable maneuvers. These rewards are used to compute a group-relativ e advantage ˆ A ( k ) = R ( x, y ( k ) ) − 1 K K X j =1 R ( x, y ( j ) ) , (1) which measures the relati ve quality of each response within the sampled group. Model parameters are then updated using an objective based on Proximal Policy Optimization (PPO) loss that in- creases the likelihood of higher-advantage responses while constraining policy updates for stability . The resulting GRPO loss is giv en by L GRPO = − E x,y ( k ) [ min( ρ ( k ) ˆ A ( k ) , clip ( ρ ( k ) , 1 − ϵ, 1 + ϵ ) ˆ A ( k ) )] , (2) where ρ ( k ) = p θ ( y ( k ) | x ) p θ old ( y ( k ) | x ) denotes the lik elihood ratio be- tween the updated and pre vious policies, and ϵ is a clipping parameter . As in SFT , GRPO updates are applied exclu- siv ely through LoRA parameters, leaving the base model unchanged. By combining stochastic exploration, rule-based reward ev aluation, and PPO-style optimization, GRPO enables preference-driv en refinement of LLM decision-making be- yond direct imitation. Unlike SFT , which enforces align- ment through supervised reproduction of human actions, GRPO encourages relativ e improvement among competing candidate responses. This distinction enables a principled comparison between imitation-based and preference-based alignment for safety-critical tactical deconfliction. 4. Dataset Generation Pipeline As major companies increasingly deploy sU AS fleets in shared airspace, safety- and priv acy-related constraints hav e become central considerations to their operational frame- works. Due to proprietary concerns and re gulatory sensiti v- ities, high-fidelity operational data rele vant to tactical de- confliction is rarely publicized, limiting the av ailability of real-world datasets for learning-based methods. This lack of accessible data poses a fundamental barrier to the dev el- opment and e valuation of data-dri ven deconfliction policies, which typically rely on large-scale, representativ e training corpora. T o address this challenge, we design a simulation- based dataset generation pipeline that enables systematic, priv acy-preserving collection of human-aligned tactical de- cision data, while remaining e xtensible to future integration with real-world observ ations as such data become av ailable. Thus, to collect trainable datasets including pairs of prompts and rule-based responses, we designed a simulation-to-language pipeline that generates scenarios and conv erts them to trainable prompt-answer pairs. Fig- ure 1 illustrates an o verview of the pipeline, in which we initially collect a series of high-fidelity multi-agent simu- lations using the BlueSky Air Traf fic Simulator [ 15 ]. The simulation en vironment was configured to emulate low- altitude airspace over the city of Frisco, T exas, a represen- tativ e urban hub for drone deliv ery operations. The dataset generation pipeline includes the following stages: Scenario Configurations: W e generated diverse multi- agent flight scenarios to capture the traffic complexity and Scenario Generation Raw Data Collection Prompt Engineering Ownship ID: A02, speed: 48, location: ... First Front Intruder ID: B03, speed: 31, location: ... Second Front Intruder ID: C01, speed: 57, location: ... Rule-based Action Decelerate Simulation-to-Language Dataset Generation Pipeline Inference LoRA Frozen LLM Fine-Tuning Fine-Tuned LLM User Prompt Given the following information of the ownship and the two intruders: .... What action should the ownship take? (Accelerate/Hold/Decelerate) System Prompt You are an airspace tactical deconfliction assistant. At each time step, you have access to... . Based on the information, what is the recommended action for the ownship agent? Answer The recommended action is: Decelerate. BlueSky: Multi-Agent Implementation Prompt Generator Rule-based Policy Figure 1. Architecture over view . The figure illustrates the end-to-end system architecture and the role of the proposed simulation-to- language dataset generation pipeline. Multi-agent traffic scenarios are generated in the BlueSky simulator, from which raw state data are extracted and conv erted into structured natural-language prompts using rule-based supervision. The resulting prompt–response pairs constitute the training dataset for LoRA-based fine-tuning. At deployment, the fine-tuned LLM generates tactical actions for multiple agents, which are ex ecuted in BlueSky , closing the simulation loop. interaction patterns characteristic of urban low-altitude op- erations. Each scenario in volves 20–30 sU ASs operating concurrently in shared airspace and includes two mer ging points and one intersection, reflecting common bottlenecks in drone delivery corridors. T o introduce variability in traf- fic density and agent state geometry , the number of activ e flight routes per scenario was randomly v aried between four and six, producing heterogeneous traf fic flows with inter- secting and merging trajectories. T o model realistic fleet div ersity , we defined two dis- tinct agent configurations characterized by different speed limits, acceleration capabilities, and sensing ranges. These configurations represent heterogeneous vehicle capabilities commonly observed across different drone operators and enable systematic e valuation of an LLM’ s ability to gen- eralize across agents with varying dynamics. Specifically , we consider configurations X and Y , where configuration X exhibits stronger kinematic and sensing capabilities than configuration Y . The speed and acceleration limits for con- figurations X and Y are selected based on the performance specifications of the Google W ing Hummingbird drone [ 32 ] and the Amazon MK30 drone [ 11 ], respectively . Sens- ing ranges reflect current technological constraints associ- ated with Remote ID-based communication or radar-based detection systems, ensuring realistic perception asymmetry among agents. T able 1 summarizes the kinematic and sensing specifi- cations for each configuration. By incorporating heteroge- neous vehicle capabilities and structurally complex airspace layouts, the proposed scenario design yields a challenging and representati ve testbed for learning and ev aluating coop- erativ e tactical deconfliction policies under realistic drone deliv ery operations. Rule-Based P olicy Design: T o generate human-aligned T able 1. Kinematic and sensing specifications for UAS configura- tions X (strong) and Y (weak). Parameter Notation Configuration X (str ong) Y (weak) Speed Range (m/s) [ v min , v max ] [0 , 44 . 88] [0 , 30 . 12] Acceleration (m/s 2 ) ∆ v / ∆ t {− 1 . 71 , 0 , 1 . 71 } {− 1 . 02 , 0 , 1 . 02 } Sensing Range (m) R 1000 750 supervisory signals for tactical deconfliction, we designed a deterministic rule-based policy that enforces safe separa- tion across all simulated scenarios. The policy is intended to emulate human pilot or controller reasoning by prescrib- ing actions through interpretable if–then rules deriv ed from operational heuristics. At each decision step, the polic y ev aluates the local traf- fic context of a giv en agent (referred to as the ownship) and selects an appropriate tactical action based on multi- ple state-dependent factors. These include the ownship’ s current and desired speeds, distance to the next waypoint, the number of nearby intruders, and relativ e spatial relation- ships with those intruders. T o balance computational effi- ciency with behavioral fidelity , only the two closest front in- truders are considered, as they typically represent the most critical conflict threats in dense airspace configurations. The policy further distinguishes between intruders oper- ating on the same route and those on intersecting or merging routes. The policy is then enabled to modulate maneuver aggressiv eness based on conflict geometry . Based on the ev aluated conditions, the rule engine outputs one of three discrete tactical actions: Accelerate , Hold , or Decelerate . These actions serve as human-aligned supervisory labels for dataset generation rather than as optimized control com- mands. The complete rule hierarchy , decision thresholds, and tie-breaking logic are detailed in Supplementary Material (Appendix A). Raw Data Collection: For each simulation episode, state information was recorded for every o wnship at discrete time steps. The collected data include the ownship’ s position, velocity , heading, route identifier, and distance to the next waypoint, along with detailed information about the two closest front intruder agents, such as their relati ve positions, velocities, and distances to their respecti ve waypoints. T o support flexible prompt construction and preserve contextual richness, both essential and supplementary at- tributes were retained during data logging. This design choice ensures that no potentially relev ant information is lost during post-processing and allo ws multiple prompt for - mulations to be explored without re-running simulations. The resulting dataset captures dynamic multi-agent inter- actions across thousands of time steps and diverse traf fic configurations. An example of the raw observation record is pro vided in Supplementary Material (Appendix B). In to- tal, over 38K state–action samples were collected in under 10 minutes. The data collection pipeline is fully modular , enabling additional scenarios and samples to be generated as needed. Prompt Engineering: As illustrated in Figure 1 , fol- lowing data collection, the raw numerical and categorical state information was transformed into structured natural- language prompts suitable for LLM training. Each prompt consists of two components: a system pr ompt , which de- fines the model’ s operational role and high-level objecti ves (e.g., ensuring safe separation in shared airspace), and a user pr ompt , which describes the current local traffic sit- uation of the ownship and nearby intruders in natural lan- guage. An illustrative e xample of the prompt format is pre- sented in Supplementary Material (Appendix C). This translation process con verts lo w-lev el simulator states into human-readable descriptions that emphasize rel- ativ e relationships, safety-rele vant constraints, and decision context. As a result, the LLM is encouraged to infer tacti- cal reasoning patterns rather than merely learning numerical correlations. The prompt format is kept consistent across training and inference to ensure behavioral stability . The resulting pipeline produces a large-scale, context- rich dataset that embeds human tactical reasoning through interpretable rule-based supervision. The pipeline is com- putationally efficient, enabling rapid generation of train- ing data and straightforward scaling to larger datasets as needed. Moreov er , the pipeline’ s modular architecture al- lows both the rule-based policy and prompt engineering strategy to be replaced without modifying the underlying simulation infrastructure. By grounding LLM training data in high-fidelity simulations while maintaining fle xibility and scalability , the pipeline pro vides a principled and exten- sible foundation for aligning LLM inference behavior with safety-critical deconfliction objectiv es. 5. LLM Selection and Fine-T uning For this study , we selected Qwen-Math-7B [ 1 , 4 , 28 ] as the pretrained backbone for all fine-tuning experiments. Qwen-Math-7B is a member of the Qwen-2.5 family of transformer-based language models and is optimized for en- hanced reasoning, mathematical comprehension, and logi- cal consistenc y . Unlike general-purpose instruction-tuned models, Qwen-Math-7B incorporates domain-focused pre- training on scientific and quantitati ve corpora, enabling robust structured reasoning and symbolic manipulation. These characteristics make it well suited for tactical decon- fliction tasks, which require reasoning o ver spatial relation- ships, safety margins, and action consequences under un- certainty . Throughout this paper, we refer to the pretrained model as the Base model. LoRA Configuration: As illustrated in Figure 1 , we adapt the Base (Frozen) LLM to the tactical deconflic- tion domain via LoRA-based fine-tuning, implemented us- ing the transformers library with a PyT orch backend. LoRA adapters were applied to the feed-forward projec- tion layers ( up proj , down proj , and gate proj ) as well as attention projection layers ( q proj , k proj , and v proj ) to enhance conte xtual reasoning. For both SFT and GRPO, the LoRA rank, scaling factor , and dropout were set to 8, 32, 0.05, respectiv ely . The learning rates for SFT and GRPO are set to 10 − 4 and 5 × 10 − 6 , respectiv ely . The rest of the parameters are set to default values in the cor- responding Python packages. These hyperparameters were chosen to balance adaptation capacity , training stability , and computational efficienc y . Due to memory limitations, we restricted output gener- ation to 10 tokens to reduce inference time when serving multiple agents. Similarly , GRPO fine-tuning sampled four candidate responses per prompt to compute the advantage function following Eq ( 1 ) and using maximum temperature to encourage exploration. Both SFT and GRPO training were conducted for a single epoch, requiring approximately 6 and 14 hours, respectively . Optimization was performed using the AdamW optimizer with a cosine learning-rate schedule and warm-up steps to ensure stable con ver gence. Reward Function in GRPO: The rew ard signal guiding GRPO optimization combines two complementary com- ponents: a format rew ard and an action re ward. The format re ward, denoted as r format , encourages adherence to the desired response structure by quantifying normal- ized textual similarity between the generated response ˆ y and the ground-truth response y via Levenshtein similar- 0 100 200 300 400 Step 0.0 0.1 0.2 0.3 SFT Loss (a) Loss curve during SFT training. 0 200 400 600 800 1000 Step 0.5 0.0 0.5 1.0 GRPO Reward (b) Rew ard progression during GRPO fine-tuning. Figure 2. T raining ef fectiveness of fine-tuning methods. (a) sho ws the supervised learning progress through loss reduction, hence accurac y increase, while (b) shows the GRPO re ward e volution across training iterations. (a) Scenario A (b) Scenario B (c) Scenario C Figure 3. Traf fic snapshots for the three scenarios (A, B, C) used in T able 3 . The LLM agents and the Rule-based agents are colored in pink and green, respectively . Each scenario has 5-6 routes, each of which hosts 5 agents with random spawning times. Throughout all scenarios, we considered 10 LLM agents, and the rest are Rule-based agents. ity: r format = 1 − Γ( ˆ y ,y ) max( | ˆ y | , | y | ) γ , where Γ( · ) denotes the Lev enshtein distance and γ ∈ [1 , ∞ ) controls sensiti vity to formatting de viations. The action rew ard, denoted as r action , enforces decision correctness by verifying whether the ac- tion specified in the generated response matches the ground- truth action label: r action = I [ action ( ˆ y ) = action ( y )] − 0 . 5 , where I [ · ] is the indicator function. The offset of − 0 . 5 cen- ters the reward around zero, penalizing incorrect actions while rewarding correct ones. The overall reward is com- puted as r ( y k , x ) = λ f r format ( y k , x ) + λ a r action ( y k , x ) , with weighting coefficients λ f and λ a balancing structural com- pliance and decision accuracy . All experiments were conducted on two NVIDIA R TX 3090 GPUs using mixed-precision training to reduce memory consumption and improve throughput. GRPO training was implemented using the TRL framework. Through this fine-tuning process, Qwen-Math-7B internal- izes both rule-based decision logic and context-dependent tactical reasoning, yielding interpretable and safety-aligned decision policies suitable for cooperative multi-agent tacti- T able 2. Performance comparison on the ev aluation dataset. All numbers are reported in percent (%). Model Accuracy Pr ecision Recall F1-scor e Base 27 75 20 31 SFT 88 75 66 69 GRPO 53 75 40 50 cal deconfliction. 6. Experimental Results and Discussions Figure 2 illustrates the training dynamics of the two fine- tuning approaches. The SFT loss curve exhibits stable con- ver gence, indicating ef fective supervised alignment with human-labeled actions, while the GRPO reward trajectory reflects gradual preference-based policy refinement. These trends suggest that both methods effecti vely incorporate training signals, albeit through different learning mecha- nisms. T o comprehensi vely assess the fine-tuned models, we use two strategies: 6.1. Evaluation with Datasets W e first assess the ef fectiv eness of the proposed fine-tuning strategies on a held-out dataset of prompt–response pairs different from the training data. Each sample consists of a natural-language description of a local traffic situation and a corresponding ground-truth tactical action. This ev aluation assesses how accurately each model reproduces the desired decision giv en identical inputs. During testing, all models were prompted with the same ev aluation set, and their generated responses were com- pared against the reference labels. A prediction was deemed corr ect if the response contained the target action ( Acceler - ate , Hold , or Decelerate ); otherwise, it was classified as incorrect. This criterion enables a consistent comparison among the pretrained Base model, the SFT model, and the GRPO fine-tuned model. Quantitativ e results on the ev aluation dataset are reported in T able 2 using standard classification metrics. The Base model achie ves an accuracy of 27%, underscoring the chal- lenge posed by tactical deconfliction for general-purpose LLMs without domain adaptation. In contrast, SFT with LoRA substantially improves performance, achie ving an accuracy of 88% and an F1-score of 69%, indicating effec- tiv e alignment with the structured decision patterns encoded in the dataset. The improvement in recall indicates that the SFT model generalizes more reliably across di verse conflict geometries. The GRPO fine-tuned model attains moderate gains ov er the Base model, with an accuracy of 53% and an F1-score of 50%. While preference-based optimization improv es re- sponse structure and consistency , its performance remains below that of SFT under the current reward formulation. This outcome suggests that, for this task, direct supervised alignment with human-labeled actions provides a stronger learning signal than relativ e preference optimization alone. 6.2. Evaluation with BlueSk y Simulations W e next ev aluate the fine-tuned LLM policies in closed- loop multi-agent simulations using the BlueSky simulator . Figure 1 illustrates the Infer ence loop. At each simulation time step, the state information of ev ery LLM-controlled agent is transformed into a structured prompt by the prompt generator and passed to the fine-tuned LLM, which outputs the corresponding tactical actions. These actions are then applied to the simulator to update the en vironment. The process repeats iteratively until all agents exit the scenario. Unlike the dataset-lev el ev aluation, which assesses single- step decision accuracy , this experiment examines emergent system-lev el behavior , including safety , coordination, and operational efficiency , under realistic multi-agent interac- tions in unseen scenarios. T able 3 summarizes safety and performance metrics across three representativ e traffic sce- narios depicted in Figure 3 . Across all scenarios, the pretrained Base model exhibits poor safety and reliability , with high near mid-air collision (NMA C) rates and very low success rates. Success rate is defined as the fraction of LLM agents that complete the sce- nario without any collision e vent. These results indicate that zero-shot LLM reasoning, without domain-specific align- ment, is insufficient for tactical deconfliction in dense and heterogeneous airspace. In contrast, both fine-tuning strate- gies substantially improve safety and mission completion, confirming the necessity of domain adaptation for closed- loop deployment. The SFT model consistently achiev es the strongest o ver- all performance across scenarios A, B, and C. It yields the lowest total NMA C rates and the highest success rates, while maintaining reasonable flight times among successful episodes. This behavior suggests that supervised alignment with human-labeled tactical decisions enables the model to internalize safety-oriented heuristics that generalize across div erse conflict geometries. Notably , SFT reduces both LLM–LLM (L–L) and LLM–Rule-based (L–R) NMACs, indicating improved coordination not only among learning agents but also in mix ed-policy en vironments. The GRPO model demonstrates intermediate perfor- mance, consistently improving over the Base model but falling short of SFT in overall safety and reliability . While GRPO reduces NMA C rates and increases success rates rel- ativ e to the pretrained baseline, its performance v aries more strongly across scenarios. In particular , GRPO achieves the lowest L–L NMA C rate in Scenario C, suggesting that preference-based optimization can enhance coordination among LLM agents in dense traffic. Howe ver , this bene- fit is accompanied by higher L–R NMAC rates and lower success rates compared to SFT , highlighting a trade-off be- tween relativ e coordination and global safety consistency . Flight time analysis further illustrates this trade-of f. The Base model’ s shorter average flight times primarily reflect early episode termination due to NMACs. In contrast, the longer flight times observed for SFT and GRPO correspond to successful mission completion and more conservati ve de- confliction behavior . Among methods achieving compara- ble success rates, SFT attains the lowest average flight time, indicating a fav orable balance between safety and opera- tional efficienc y . The BlueSky e valuation demonstrates that supervised fine-tuning with human-aligned labels yields the most consistent and reliable closed-loop behavior across het- erogeneous scenarios. Preference-based optimization via GRPO offers complementary benefits in specific coordina- tion settings but exhibits reduced robustness under mixed- policy interactions. These results reinforce the importance of human-aligned supervision for deploying LLM-based T able 3. Safety and efficienc y across configurations and LLM models (mean ± std, for 10 episodes). Rates are NMA Cs/episode. Abbrevi- ations: L–L = NMA Cs between two LLM agents; L–R = NMA Cs between an LLM agent and a Rule-based agent; All = L–L + L–R ; SR = success rate of LLM agents (fraction completing without NMACs); T ime = average flight time of successful LLM agents. Bold indicates best values: lowest NMA C for (All, L–L, L–R), highest SR, and lo west Time among methods with SR ≥ 0 . 9 × SR best for the scenario. Base SFT GRPO Scen. All L–L L–R SR Time All L–L L–R SR T ime All L–L L–R SR Time A 3.5 ± 1.1 2.7 ± 0.5 0.8 ± 1.0 0.12 ± 0.38 3.7 ± 4.1 1.0 ± 0.8 0.7 ± 0.7 0.3 ± 0.5 0.77 ± 0.29 5.7 ± 0.6 1.7 ± 0.5 1.1 ± 0.7 0.6 ± 0.5 0.57 ± 0.31 5.2 ± 0.1 B 3.4 ± 1.1 1.8 ± 1.4 1.6 ± 0.9 0.20 ± 0.56 3.3 ± 7.0 1.9 ± 1.2 0.9 ± 0.7 1.0 ± 0.8 0.62 ± 0.36 8.1 ± 0.9 3.0 ± 0.7 1.3 ± 0.4 1.7 ± 0.5 0.27 ± 0.22 6.9 ± 0.3 C 4.0 ± 0.9 2.5 ± 1.2 1.5 ± 1.2 0.05 ± 0.58 1.6 ± 5.0 1.9 ± 0.7 0.8 ± 0.6 1.1 ± 0.9 0.52 ± 0.37 7.5 ± 0.7 2.3 ± 0.8 0.6 ± 0.5 1.7 ± 0.7 0.42 ± 0.29 6.6 ± 0.1 tactical deconfliction policies in safety-critical airspace en vironments. 6.3. Limitations and Broader Impacts Despite the encouraging results, se veral limitations cur- rently constrain the deployment of LLM-based policies in real-time coordinated multi-agent sUAS operations. A pri- mary challenge is inference latency . Even under optimized inference settings, the Base model requires approximately 0.2 seconds to generate a short response for a single agent, with latency scaling linearly with the number of agents and output length. This o verhead limits scalability in dense traf- fic scenarios and restricts the use of more computationally intensiv e reasoning techniques, such as chain-of-thought prompting or retriev al-augmented generation, which could otherwise enhance decision transparency . A second limitation concerns prompt sensiti vity and sta- bility . LLM behavior is highly dependent on prompt struc- ture, and de viations between the formats used during fine- tuning and inference can lead to degraded performance or partial re version to pretrained behavior . While structured prompt design mitigates this effect, longer and more de- scriptiv e prompts further increase inference time, introduc- ing a trade-of f between reasoning richness and real-time re- sponsiv eness. Moreov er, reinforcement-based fine-tuning introduces practical constraints. GRPO requires sampling multiple candidate responses per query to estimate relative adv an- tages, resulting in significant computational and memory demands. In this study , hardware limitations constrained the number of sampled responses, likely reducing explo- ration di versity and training stability . Scaling preference- based optimization for large LLMs therefore remains an open challenge requiring more ef ficient training strategies and distributed infrastructure. Despite these constraints, this w ork demonstrates the po- tential of large language models to support human-aligned and interpretable decision-making in autonomous air traf- fic coordination, particularly in heterogeneous and dynamic en vironments. At the same time, the identified limitations underscore the need for careful system-lev el integration, emphasizing latency-aw are design, resource efficienc y , and safety assurance. From a broader perspecti ve, the computa- tional cost associated with large-scale fine-tuning moti vates continued exploration of lightweight architectures and hy- brid symbolic–neural approaches. This study contributes to a gro wing body of evidence that LLMs can augment, but not yet replace, established decision-making frame works in real-time, safety-critical applications such as aircraft tacti- cal deconfliction. 7. Conclusion This study examined fine-tuned Large Language Models (LLMs) as high-level decision-making policies for tactical deconfliction in dense, heterogeneous, cooperative multi- agent air traffic en vironments. By introducing a “simulation-to-language” dataset gen- eration pipeline grounded in interpretable rule-based hu- man decision heuristics, we sho wed that LLMs, specifically Qwen-Math-7B, can acquire structured, safety-oriented rea- soning capabilities for sU AS tactical deconfliction. Using this dataset, we ev aluated two complementary parameter - efficient alignment strategies: Supervised Fine-Tuning (SFT) and Group-Relativ e Policy Optimization (GRPO). Evaluations on held-out datasets and closed-loop BlueSky simulations demonstrate that SFT provides the most consistent impro vements over the baseline LLM in de- cision accuracy , behavioral stability , and separation safety relativ e to the pretrained baseline. In contrast, GRPO en- ables preference-based refinement that improves coordina- tion among LLM agents in certain traffic configurations b ut exhibits reduced robustness in mixed-policy en vironments. Despite these adv ances, challenges remain, including in- ference latency , sensiti vity to prompt structure, and the computational demands of reinforcement-style fine-tuning. Overcoming these constraints will be essential for deploy- ing LLM-based tactical deconfliction policies to real-time, large-scale sU AS operations. Future work should further benchmark LLM-based ap- proaches against established rule-based and reinforcement- learning-based methods. References [1] Alibaba Group AI T eam. Qwen-Math: Mathematical Rea- soning Models from Alibaba Cloud AI. T echnical report, Alibaba Group, 2024. 5 [2] Dario Amodei, Chris Olah, Jacob Steinhardt, Paul Chris- tiano, John Schulman, and Dan Man ´ e. Concrete Problems in AI Safety, 2016. 2 [3] Justas Andriu ˇ ske vi ˇ cius and Junzi Sun. Automatic Control W ith Human-Like Reasoning: Exploring Language Model Embodied Air T raffic Agents. In 14th SESAR Innovation Days, SIDS 2024 , 2024. 2 [4] Y uhang Bai, Zhihong Deng, W ei Liu, et al. Qwen T echnical Report. arXiv preprint , 2023. 5 [5] Marc Brittain and Peng W ei. Autonomous separation as- surance in an high-density en route sector: A deep multi- agent reinforcement learning approach. In 2019 IEEE In- telligent T ransportation Systems Confer ence (ITSC) , pages 3256–3262, 2019. 2 [6] Fabio Suim Chagas, Neno Ruseno, and Aurilla Aure- lie Arntzen Bechina. Artificial Intelligence Approaches for U A V Deconfliction: A Comparativ e Revie w and Framework Proposal. Automation , 6(4), 2025. 1 [7] Long Cheng, Bowen Zhou, and Xinyi Zhang. From Lan- guage to Action: A Review of Large Language Models as Autonomous Agents and T ool Users. Artificial Intelligence Revie w , 59:71, 2026. 1 [8] Stijn V an Dam, Max Mulder, and Ren ´ e Paassen. The Use of Intent Information in an Airborne Self-Separation Assistance Display Design. In AIAA Guidance , Navigation, and Contr ol Confer ence , 2009. 1 [9] Federico Errica, Davide Sanvito, Giuseppe Siracusano, and Roberto Bifulco. What Did I Do Wrong? Quantifying LLMs’ Sensiti vity and Consistency to Prompt Engineer- ing. In Pr oceedings of the 2025 Conference of the Na- tions of the Americas Chapter of the Association for Com- putational Linguistics: Human Language T echnologies (V ol- ume 1: Long P apers) , pages 1543–1558, Albuquerque, New Mexico, 2025. Association for Computational Linguistics. 1 [10] Federal A viation Administration. F AA Makes Drone History in Dallas Area, 2024. 1 [11] Federal A viation Administration. Amazon Prime Air Amendment to Operations Specifications (OpSpecs). T ech- nical report, U.S. Department of T ransportation, 2025. 4 [12] Kathleen Ge and William Coupe. A viation-Specific Large Language Model Fine-Tuning and LLM-as-a-Judge Evalua- tion. In AIAA A VIATION FORUM AND ASCEND 2025 , page 3712, 2025. 2 [13] Dewi Gould, Geor ge De Ath, Ben Carvell, and Nick Pepper . AirT rafficGen: Configurable Air T raffic Scenario Genera- tion with Large Language Models. ArXiv , abs/2508.02269, 2025. 2 [14] Bryan Guan, T an ya Roosta, Peyman Passban, and Mehdi Rezagholizadeh. The Order Effect: In vestigating Prompt Sensitivity to Input Order in LLMs. arXiv preprint arXiv:2502.04134 , 2025. 1 [15] Jacco Hoekstra and Joost Ellerbroek. BlueSky A TC Simula- tor Project: an Open Data and Open Source Approach. 2016. 2 , 3 [16] J.M Hoekstra, R.N.H.W van Gent, and R.C.J Ruigrok. De- signing for safety: the ‘free flight’ air traf fic management concept. Reliability Engineering & System Safety , 75(2): 215–232, 2002. 1 [17] Edward J. Hu, Y elong Shen, Phillip W allis, et al. LoRA: Low-Rank Adaptation of Large Language Models. In In- ternational Confer ence on Learning Repr esentations (ICLR) , 2022. 2 , 3 [18] Shima Imani, Liang Du, and Harsh Shriv astava. Math- Prompter: Mathematical Reasoning using Large Language Models, 2023. 1 [19] Hantao Jiang et al. T raining Lar ge Language Models on Nar - row T asks Can Lead to Broad Misalignment. Nature , 649: 584–589, 2026. 1 [20] T ak eshi K ojima, Shixiang Shane Gu, Machel Reid, Y utaka Matsuo, and Y usuke Iwasaw a. Large language models are zero-shot reasoners. In Pr oceedings of the 36th International Confer ence on Neural Information Pr ocessing Systems , Red Hook, NY , USA, 2022. Curran Associates Inc. 1 [21] Y ucheng Liu. Large language models for air transportation: A critical revie w . J ournal of the Air T ransport Resear ch So- ciety , 2:100024, 2024. 2 [22] Y anchao Liu and Timothy C. Henderson. Strategic Decon- fliction of Unmanned Aircraft Based on Hexagonal T essella- tion and Integer Programming. Journal of Guidance, Con- tr ol, and Dynamics , 46(8):1–14, 2023. 1 [23] Shayne Loft, Penelope Sanderson, Andrew Neal, and Mark Mooij. Modeling and Predicting Mental W orkload in En Route Air Traf fic Control: Critical Revie w and Broader Im- plications. Human F actors , 49(3):376–399, 2007. 1 [24] Francesco Manigrasso, Stefan Schouten, Lia Morra, and Pe- ter Bloem. Probing LLMs for Logical Reasoning. In Neural- Symbolic Learning and Reasoning: 18th International Con- fer ence, NeSy 2024, Proceedings, P art I , page 257–278, Berlin, Heidelberg, 2024. Springer -V erlag. 1 [25] Y . L. Marquand. F AA Authorises Zipline and W ing for BV - LOS Operations in Dallas, 2024. 1 [26] Long Ouyang, Jeff W u, Xu Jiang, Diogo Almeida, Car- roll W ainwright, Pamela Mishkin, et al. T raining language models to follow instructions with human feedback. arXiv pr eprint arXiv:2203.02155 , 2022. 1 [27] Bizhao Pang, Kin Huat Low , and Chen Lv . Adapti ve con- flict resolution for multi-UA V 4D routes optimization using stochastic fractal search algorithm. T ransportation Resear ch P art C: Emerging T echnologies , 139:103666, 2022. 1 [28] Qwen T eam. Qwen2.5 T echnical Report. arXiv pr eprint arXiv:2410.13848 , 2024. 5 [29] Marta Ribeiro, Joost Ellerbroek, and Jacco Hoekstra. Re view of Conflict Resolution Methods for Manned and Unmanned A viation. Aer ospace , 7(6):79, 2020. 1 [30] Guanzhi W ang, Y uqi Xie, Y unfan Jiang, Ajay Mandlekar, Chaowei Xiao, Y uke Zhu, Linxi Fan, and Anima Anandku- mar . V oyager: An Open-Ended Embodied Agent with Lar ge Language Models. T ransactions on Machine Learning Re- sear ch , 2024. 1 [31] Liya W ang, Jason Chou, Xin Zhou, Alex T ien, and Diane M. Baumgartner . A viationGPT : A Large Language Model for the A viation Domain. ArXiv , abs/2311.17686, 2023. 2 [32] W ing. Meet the drones taking deliv ery to new heights. https : / / wing . com / technology , 2024. Accessed: January 2026. 4 [33] Liangqi Y uan, Chuhao Deng, Dong-Jun Han, Inseok Hwang, Sabine Brunswicker , and Christopher G. Brinton. Next- Generation LLM for UA V : From Natural Language to Au- tonomous Flight. arXiv preprint , 2025. 1 Supplementary Material This supplementary document accompanies the main paper and provides additional implementation details to support repro- ducibility . The main paper is fully self-contained; these appendices offer extended technical specifications that complement the methodology described therein. A. Rule-Based Conflict Resolution Policy This appendix describes the deterministic rule-based policy used for action selection in the multi-agent flight environment. The policy is hand-crafted and does not in volve learning or parameter tuning. At each decision step, an agent selects one of three discrete actions: Decelerate , Hold , or Accelerate . Action selection is gov erned by the ownship’ s distance to the next waypoint, the presence and relativ e position of nearby intruders, route alignment, and speed constraints. All rules are ev aluated sequentially and are mutually exclusi ve after speed constraint enforcement. Decision Rules The decision rules are partitioned into three sets based on the agent’ s position relativ e to bottleneck waypoints, as illustrated in Figure 4 . The key parameters go verning these rules are: • d wp o : Distance from the ownship to its ne xt waypoint • d safe o : Safety distance threshold for triggering deconfliction maneuvers Far fr om the next waypoint: When the ownship is sufficiently far from the next waypoint, i.e., , actions are selected as follows: If no intruder is present within the safety distance, the ownship accelerates when its current speed is below the desired speed; otherwise, it maintains its current speed. If an intruder is present within the safety distance and is located ahead of the ownship, the ownship decelerates. If an intruder is present within the safety distance and is located behind the ownship, the ownship accelerates. Near the next waypoint: When the ownship is close to the next waypoint, i.e., , the following rules apply: If an intruder is located ahead of the ownship on the same route, the ownship decelerates. If an intruder is located ahead of the ownship on a different route, the ownship decelerates. If the ownship and a front intruder are within the collision distance threshold, action selection depends on relative speeds: the ownship accelerates if it has a speed advantage, decelerates if it has a speed disadvantage, and randomly selects between acceleration and deceleration when both agents have equal speeds. In this case, the intruder is assigned the opposite action to maintain separation. If no intruder is located ahead of the ownship within the safety distance, the ownship accelerates toward the waypoint. Speed constraint enforcement: After an action is selected, speed constraints are enforced as follows: If the chosen action would cause the ownship to violate its minimum or maximum speed limits, the action is overridden and replaced with maintaining the current speed. Figure 4. Decision rules for the rule-based policy , organized by ownship proximity to the next waypoint. The policy distinguishes between situations where the ownship is far from the waypoint ( d wp o > d safe o ) and near the waypoint ( d wp o ≤ d safe o ), with speed constraint enforcement applied as a final ov erride. Far fr om the Next W aypoint ( d wp o > d safe o ) When the ownship is suf ficiently far from the next w aypoint, actions are selected as follows: • If no intruder is present within the safety distance, the ownship accelerates when its current speed is belo w the desired speed; otherwise, it maintains its current speed. • If an intruder is present within the safety distance and is located ahead of the ownship, the o wnship decelerates. • If an intruder is present within the safety distance and is located behind the ownship, the o wnship accelerates. Near the Next W aypoint ( d wp o ≤ d safe o ) When the ownship is close to the ne xt waypoint, the following rules apply: • If an intruder is located ahead of the ownship on the same route, the o wnship decelerates. • If an intruder is located ahead of the ownship on a dif ferent route, the ownship decelerates. • If the o wnship and a front intruder are within the collision distance threshold, action selection depends on relativ e speeds: the ownship accelerates if it has a speed adv antage, decelerates if it has a speed disadv antage, and randomly selects between acceleration and deceleration when both agents ha ve equal speeds. In this case, the intruder is assigned the opposite action to maintain separation. • If no intruder is located ahead of the ownship within the safety distance, the o wnship accelerates tow ard the waypoint. Speed Constraint Enfor cement After an action is selected, speed constraints are enforced as a final step: • If the chosen action would cause the ownship to violate its minimum or maximum speed limits, the action is overridden and replaced with maintaining the current speed ( Hold ). B. Example Raw Agent Observation This appendix presents an e xample raw observation r ecor d collected for a single agent at one simulation time step. Listing 1 shows the exact data structure provided to the rule-based policy prior to action selection, including ownship state variables, information about the two closest front intruders, and the resulting action. The observation record captures all state information necessary for tactical decision-making, including: • Ownship state: Position, velocity , heading, route identifier , distance to next w aypoint, and speed constraints • Intruder information: Relativ e positions, velocities, and route identifiers for the two closest front intruders • Collision metrics: Time-to-collision estimates and Euclidean distances to intruders Ownship info: id: A03 type: Amazon Prime Air - MK30 Model lat: 33.137421, lon: -96.861632 next_wpt_id: WP4 next_wpt_type: Intersection dist_to_nxt_wpt(m): 4759.71 speed(m/s): 34.98 min_spd(m/s): 0.0, max_spd(m/s): 41.16 speed_change_per_second(m/s2): 1.7 heading(deg): 20.13 altitude(m): 376.82 route_id: R_3 last_action: hold num_intruders_ahead: 2 desired_spd(m/s): 33.44 time_to_collision_with_intruder1(s): 116.05 intruder1_on_same_route: True did_ownship_have_NMAC: False time_to_collision_with_intruder2(s): inf intruder2_on_same_route: True distance_to_intruder1(m): 1074.77 distance_to_intruder2(m): 501.82 First closest front intruder info: id: D02 type: Google X-Wing lat: 33.14653, lon: -96.85777 next_wpt_id: WP4 next_wpt_type: Intersection dist_to_nxt_wpt(m): 3685.01 speed(m/s): 25.72 min_spd(m/s): 0.0, max_spd(m/s): 30.87 speed_change_per_second(m/s2): 1.03 heading(deg): 20.31 altitude(m): 347.56 route_id: R_4 last_action: hold Second closest front intruder info: id: C04 type: Amazon Prime Air - MK30 Model lat: 33.141682, lon: -96.859853 next_wpt_id: WP4 next_wpt_type: Intersection dist_to_nxt_wpt(m): 4257.95 speed(m/s): 34.98 min_spd(m/s): 0.0, max_spd(m/s): 41.16 speed_change_per_second(m/s2): 1.7 heading(deg): 20.24 altitude(m): 355.92 route_id: R_3 last_action: hold Ownship action: Hold. Listing 1. Raw observation snapshot for a single agent at one simulation time step. This record is provided to the rule-based policy for action selection and subsequently transformed into a natural-language prompt for LLM training. C. Example Prompt f or Action Recommendation This appendix illustrates the prompt format used for LLM training and inference. The raw observation data (Appendix B ) is transformed into a structured natural-language prompt comprising two components: 1. System Pr ompt: Defines the model’ s operational role as a tactical deconfliction assistant, specifying the decision conte xt and expected response format. 2. User Prompt: Describes the current local traffic situation in natural language, including o wnship state, intruder informa- tion, and relev ant spatial relationships. This translation process conv erts low-le vel simulator states into human-readable descriptions that emphasize relativ e re- lationships, safety-relev ant constraints, and decision context. As a result, the LLM is encouraged to infer tactical reasoning patterns rather than merely learning numerical correlations. Prompt Structur e Figure 5 presents a complete example prompt constructed from raw state information. The prompt uses qualitativ e descriptors (e.g., “very safe, ” “very long”) deri ved from the numerical state values to f acilitate natural-language reasoning. System Prompt: Y ou are an airspace tactical deconfliction assistant. At each time step, an ownship agent is approaching a bottleneck waypoint, such as merging or intersections points, where other agents (intruders) are approaching as well. Based on the information of the ownship and intruders, the ownship should take an action to avoid collisions. The ownship agent only has access to the information of the front intruders, but there might be other intruders behind the ownship. Y our task is to help the ownship aircraft avoid collisions with front intruder aircraft by suggesting appropriate speed adjustments. The ownship cannot unnecessarily decelerate since it might occlude the airspace for other agents behind it. Y our response should start with 'The recommended action is: ' followed by one of the actions: Decelerate, Hold, or Accelerate. User Pr ompt: Given the information of the ownship and intruders as follows: - Ownship: - Speed is medium (12.86 m/s), where minimum possible speed is 0.0 m/s and maximum possible speed is 30.87 m/s. - Speed is lower than the desired speed. - Speed is not minimum and is not maximum. - Distance to the next waypoint is very long (3299.46 m). - There are two intruders ahead. - Front Intruder 1: - The euclidean distance to the ownship is very safe (1774.78 m). - The intruder is not on the same route as the ownship. - The intruder distance to the next waypoint is very long (1665.31 m). - The intruder distance to the next waypoint is significantly dif ferent than the ownship. - The intruder speed is 25.21 m/s. - The intruder is moving at a moderately higher speed compared to the ownship. - Front Intruder 2: - The euclidean distance to the ownship is very safe (1548.81 m). - The intruder is on the same route as the ownship. - The intruder distance to the next waypoint is very long (1750.64 m). - The intruder distance to the next waypoint is significantly dif ferent than the ownship. - The intruder speed is 25.21 m/s. - The intruder is moving at a moderately higher speed compared to the ownship. Based on the above information, what actions should the ownship take? (Decelerate/Hold/Accelerate) Y our response should start with 'The recommended action is: ' followed by one of the actions: Decelerate, Hold, or Accelerate. Figure 5. Example prompt for tactical deconfliction at a single time step. The system prompt establishes the model’ s role and constraints, while the user prompt provides a structured description of the current traffic situation. Qualitative descriptors are derived from numerical thresholds to support natural-language reasoning. Response F ormat The expected response format is shown in Figure 6 . The model is trained to produce a brief, structured response beginning with “The recommended action is:” followed by one of the three discrete actions: Accelerate , Hold , or Decelerate . Answer: The recommended action is: Accelerate. Figure 6. T ar get response format corresponding to the prompt in Figure 5 . The constrained response format ensures consistent parsing during both training and closed-loop inference. Prompt Design Considerations Sev eral design choices guide the prompt engineering process: • Qualitative descriptors: Numerical v alues are con verted to qualitati ve categories (e.g., distance “v ery safe” vs. “critical”) to align with human reasoning patterns and reduce sensitivity to e xact numerical values. • Relative comparisons: Intruder information emphasizes relative quantities (e.g., “moving at a moderately higher speed compared to the ownship”) rather than absolute values, supporting transferable reasoning across diverse traffic configura- tions. • Constrained output format: The response format is strictly specified in both the system prompt and the closing instruc- tion, ensuring consistent parsing during ev aluation and deployment. • Safety emphasis: The system prompt explicitly frames the task in terms of collision av oidance and airspace safety , priming the model tow ard conservati ve, safety-oriented decisions. The prompt format is kept consistent across training and inference to ensure behavioral stability . This consistency is critical for maintaining alignment between the fine-tuned model’ s behavior and the human-aligned supervisory signals encoded in the training dataset.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment