Dataset Distillation Efficiently Encodes Low-Dimensional Representations from Gradient-Based Learning of Non-Linear Tasks
Dataset distillation, a training-aware data compression technique, has recently attracted increasing attention as an effective tool for mitigating costs of optimization and data storage. However, progress remains largely empirical. Mechanisms underly…
Authors: Yuri Kinoshita, Naoki Nishikawa, Taro Toyoizumi
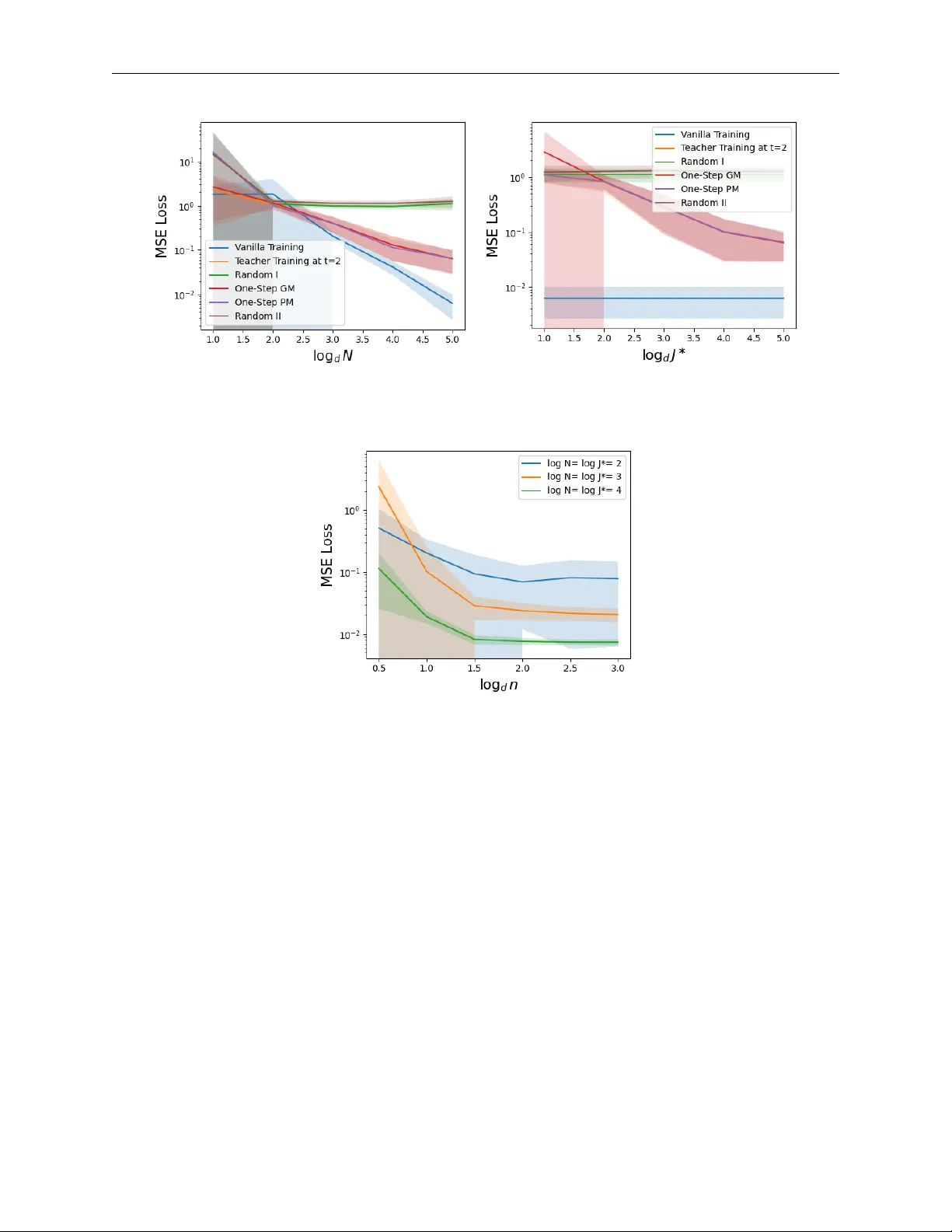
D A T A S E T D I S T I L L A T I O N E FFI C I E N T L Y E N C O D E S L O W - D I M E N S I O N A L R E P R E S E N T A T I O N S F R O M G R A D I E N T - B A S E D L E A R N I N G O F N O N - L I N E A R T A S K S A P R E P R I N T Y uri Kinoshita 1 , 2 ∗ , Naoki Nishikawa 1 , 3 , T ar o T oyoizumi 1 , 2 1 Department of Mathematical Informatics, Graduate School of Information Science and T echnology , The Univ ersity of T okyo, T ok yo, Japan. 2 Laboratory for Neural Computation and Adaptation, RIKEN Center for Brain Science, W ako, Japan. 3 Center for Advanced Intelligence Project, RIKEN Center for Brain Science, W ako, Japan. A B S T R AC T Dataset distillation, a training-aw are data compression technique, has recently attracted increasing attention as an effecti ve tool for mitigating costs of optimization and data storage. Howe ver , progress remains largely empirical. Mechanisms underlying the e xtraction of task-relev ant information from the training process and the ef ficient encoding of such information into synthetic data points remain elusiv e. In this paper , we theoretically analyze practical algorithms of dataset distillation applied to the gradient-based training of two-layer neural networks with width L . By focusing on a non-linear task structure called multi-index model, we prov e that the low-dimensional structure of the problem is ef ficiently encoded into the resulting distilled data. This dataset reproduces a model with high generalization ability for a required memory complexity of ˜ Θ( r 2 d + L ) , where d and r are the input and intrinsic dimensions of the task. T o the best of our knowledge, this is one of the first theoretical works that include a specific task structure, leverage its intrinsic dimensionality to quantify the compression rate and study dataset distillation implemented solely via gradient-based algorithms. 1 Introduction 1.1 Background Over the past few years, deep learning has advanced in tandem with a training paradigm that benefits substantially from systematic increases in data scale. While this approach has yielded unprecedented results across a wide range of domains, it entails fundamental limitations, notably in terms of the costs of training, data storage and its transmission. Dataset distillation (DD), also kno wn as dataset condensation, addresses these challenges by constructing a small set of trained synthetic data points that distill essential information from the learning scenario of a gi ven problem so that training with these resulting instances reproduces a high generalization score on the task ( W ang et al. , 2018 ; Zhao et al. , 2021 ; Cazena vette et al. , 2022 ; W ang et al. , 2022 ). The ef fectiv eness of DD in reducing the amount of data required to obtain a high-performing model has been reportedly observed and is no wadays attracting increasing attention in v arious fields that span modalities such as images ( W ang et al. , 2018 ), text ( Sucholutsky and Schonlau , 2021 ), medical data ( Li et al. , 2020 ), time series ( Ding et al. , 2024 ) and electrophysiological signals ( Guo et al. , 2025 ). ∗ Correspondence to: yuri-kinoshita111@g.ecc.u-tok yo.ac.jp Dataset Distillation Efficiently Encodes Lo w-Dimensional Representations A P R E P RI NT T able 1: Comparison of our contrib utions with prior work. They all treat regression problems of the form { x n , f ∗ ( x n ) + ϵ n } with noise ϵ n . W e cite only the most relev ant results for KRR with non-linear kernels. N is the training data size, d the input dimension, r the intrinsic dimension of multi-index model, L the width of two-layer neural netw orks, q the feature dimension of the kernels which equals to L if the model is a two-layer neural network. f ∗ form Optimizations T rained Model Memory Cost Izzo and Zou ( 2023 ) Unspecified Exact Linear (Gaussian kernel) Θ( N d ) Maalouf et al. ( 2023 ) Unspecified Exact Linear (shift in variant k ernels) Θ( q d ) Chen et al. ( 2024a ) Unspecified Exact Linear (any kernel) Θ( q d ) Ours Multi-index Gradient-based Non-Linear ˜ Θ( r 2 d + L ) Beyond this efficienc y , DD offers a set of condensed training summaries, whose replay can be applied to promote transfer learning ( Lee et al. , 2024 ), neural architecture search ( Zhao et al. , 2021 ), continual learning ( Liu et al. , 2020 ; Masarczyk and T autkute , 2020 ; Kong et al. , 2024 ), federated learning ( Zhou et al. , 2020 ), data priv acy ( Dong et al. , 2022 ) and model interpretability ( Cazenav ette et al. , 2025 ). In parallel to ongoing empirical development, theoretical work has been led to explain why DD can compress a substantial training effort, arising from the complex interaction between task structure, model architecture, and optimization dynamics, into a few iterations over a small number of synthetic data points. On the one hand, some studies hav e primarily considered the number of data points suf ficient to reconstruct the e xact linear ridge regression (LRR) or kernel ridge re gression (KRR) solution of the training data ( Izzo and Zou , 2023 ; Maalouf et al. , 2023 ; Chen et al. , 2024a ). On the other hand, a scaling law for the required number of distilled samples was recently prov ed ( Luo and Xu , 2025 ). Despite these advances, e xisting analyses either focus on essentially linear models or do not explicitly characterize how the intrinsic task structure mediates distillation. Especially , lev eraging lo w-dimensionality of the problem is known to be central to the efficienc y and adapti vity of gradient-based algorithms ( Damian et al. , 2022 ). Similar considerations appear to apply in DD, where more challenging tasks tend to require larger distilled sets ( Zhao et al. , 2021 ). In short, the rigorous mechanisms through which DD operates in complex practical learning regimes, encompassing task structure, non-linear models, and gradient-based optimization dynamics, remain underexplored. Therefore, in this paper , we precisely theoretically study DD in such a framework, focusing on ho w task structure can be lev eraged to achiev e low memory comple xity of distilled data that realizes high generalization ability when used at training. Particularly , we analyze two state-of-the-art DD algorithms, performance matching ( W ang et al. , 2018 ) and gradient matching ( Zhao et al. , 2021 ), applied to the training of two-layer ReLU neural networks under a non-trivial non-linear task endo wed with a latent structure called multi-index models . All optimization procedures follo w finite time gradient-based algorithms. 1.2 Contributions Our major contributions can be summarized as follo ws: • T o the best of our knowledge, this is one of the first theoretical works to study DD (gradient and performance matching) implemented solely via gradient-based algorithms and to include a specific task structure with low intrinsic dimensionality . • W e prove that DD applied to two-layer ReLU neural networks with width L learning a class of non-linear functions called multi-index models ef ficiently encode latent representations into distilled data. • W e show that this dataset reproduces a model with high generalization ability for a memory complexity of ˜ Θ( r 2 d + L ) , where d and r are the input and intrinsic dimensions of the task. See T able 1 for comparison. • Theoretical results and its application to transfer learning are discussed and illustrated with experiments. 1.3 Related W orks This work connects perspecti ves and insights from three dif ferent lines of work. Empirical in vestigations of DD ha ve been applied to both re gression ( Ding et al. , 2024 ; Mahowald et al. , 2025 ) and classification tasks ( W ang et al. , 2018 ), and depending on which aspect of training information the distillation algorithm prioritizes, existing methods can be grouped into several categories ( Y u et al. , 2024 ). Among them, performance matching (PM) directly focuses on minimizing the training loss of a model trained on the distilled data ( W ang et al. , 2018 ; Sucholutsky and Schonlau , 2021 ; Nguyen et al. , 2021a , b ; Zhou et al. , 2022 ), while gradient matching (GM) 2 Dataset Distillation Efficiently Encodes Lo w-Dimensional Representations A P R E P RI NT learns synthetic instances so that gradients of the loss mimic those induced by real data ( Zhao et al. , 2021 ; Liu et al. , 2022 ; Jiang et al. , 2023 ). Such algorithms constitute the ingredients of DD and can be incorporated into a wide variety of strategies. They ha ve been dev eloped to improve scalability ( Cui et al. , 2023 ; Chen et al. , 2024b ), incorporate richer information ( Son et al. , 2025 ; Zhao and Bilen , 2021 ; Deng and Russakovsk y , 2022 ; Liu et al. , 2022 ), and be tailored to pre-trained models ( Cazena vette et al. , 2025 ). In this paper , we follow the procedure of Chen et al. ( 2024b ) called pr ogr essive dataset distillation , which learns a distilled dataset for each partitioned training phase. Current theory of DD is mainly formulated as the number of synthetic data points required to infer the exact final parameter optimized for the training data. Izzo and Zou ( 2023 ) showed that this number equals the input dimension for LRR, and the size of the original training set for KRR with a Gaussian kernel. For shift-in variant kernels ( Maalouf et al. , 2023 ) or general kernels ( Chen et al. , 2024a ), this amount becomes the dimension of the kernel. Under LRR and KRR with surjecti ve kernels, Chen et al. ( 2024a ) refined the bounds to one distilled point per class. Izzo and Zou ( 2023 ) showed that one data point suf fices for a specific type of model called generalized linear models. As for recent work, Luo and Xu ( 2025 ) characterize the generalization error of models trained with distilled data o ver a set of algorithm and initialization configurations. Nev ertheless, these prior theoretical works do not take into account any kind of task structure. Gradient-based algorithms of DD such as GM for non-linear neural networks are not considered either . W e provide a frame work that both fills this gap and re veals the high compression rate of DD. Our theory builds on analytical studies of feature learning in neural networks via gradient descent. Their optimization dynamics are rigorously inspected, yielding lo wer bounds on the sample comple xity of training data required for lo w generalization loss of non-linear tasks with low-dimensional structures, such as single-inde x ( Dhifallah and Lu , 2020 ; Gerace et al. , 2020 ; Ba et al. , 2022 ; Oko et al. , 2024a ; Nishikawa et al. , 2025 ), multi-index ( Damian et al. , 2022 ; Abbe et al. , 2022 ; Bietti et al. , 2023 ), and additive models ( Oko et al. , 2024b ; Ren et al. , 2025 ). T ypically , these results provide theoretical support for the effecti ve feature learning of neural networks observed in practice beyond neural tangent kernel (NTK) re gimes. This framework is thus suited to elucidate the intricate mechanism of DD beyond the NTK and KRR settings of pre vious works on this topic. W e will indeed prove that feature learning happens in DD as well, leading to a compact memory complexity that le verages the lo w-dimensionality of the problem. Organization In Section 2 , we will explain the basic formulation of DD and its algorithms. In Section 3 , we will div e into a detailed clarification of our problem setting. Section 4 will be dev oted to the description of our theoretical analysis. Section 5 will illustrate our theoretical results, and their discussion will be provided in Section 6 . Notation Throughout this paper , the Euclidean norm of a vector x is defined as ∥ x ∥ , and the inner product as ⟨· , ·⟩ . For matrices, ∥ A ∥ denotes the l 2 operator norm A and ∥ A ∥ F its Frobenius norm. S d − 1 corresponds to the unit sphere in R d . When we state for two algorithms A : = A ′ , A is defined as A ′ with the input arguments inherited from A . [ i ] is the set { 1 , . . . , i } and a ∨ b = max { a, b } . ˜ O ( · ) and ˜ Ω( · ) represent O ( · ) and Ω( · ) but with hidden polylogarithmmic terms. 2 Preliminaries In this section, we explain the mathematical background of DD and its algorithms. 2.1 General Strategy Let us consider a usual optimization framew ork O T r of a model f θ , where θ is optimized based on a training data D T r = { ( x n , y n ) } N n =1 and a loss L so that the resulting θ ∗ realizes a low generalization error E ( x,y ) ∼P [ L ( θ ∗ , ( x, y ))] , where P is the data distrib ution. The goal of DD is to create a synthetic dataset D S = { ( ˜ x m , ˜ y m ) } M m =1 and, occasionally , an alternati ve optimization framew ork O S , so that training f θ with D S along O S returns a parameter ˜ θ ∗ that achie ves low E ( x,y ) ∼P [ L ( ˜ θ ∗ , ( x, y ))] . Ultimately , we expect that the memory complexity of D S is smaller than that of D T r and, preferably , than the storage cost of the whole model; otherwise, saving f θ may be sufficient in some settings. DD thus compares two training paradigms, teac her training O T r tuned for the original training data and student tr aining O S that employs instead the distilled data. Then, it distills information from this comparison so that retr aining the model on distilled data can reproduce the performance or optimization dynamics of the teacher . These three phases are summarized in Algorithm 1 . Here, A and M are algorithms, ξ is the number of iteration, η the step size, and λ the L 2 regularization coef ficient. W e opt for the strategy of pr ogr essive DD proposed by Chen et al. ( 2024b ), which separates training into multiple phases and applies DD within each of them. This allows DD to cov er and distill the whole training procedure and enables us to precisely characterize what information is distilled at each time step. Although Chen et al. ( 2024b ) reuse distilled data from pre vious interv als in subsequent phases, in this w ork, we adopt a simplified v ariant where we learn an independent distilled set for each of them. 3 Dataset Distillation Efficiently Encodes Lo w-Dimensional Representations A P R E P RI NT 2.2 Distillation Algorithms M One of the primary interests of research in DD lies in identifying which properties of teacher training the distilled data should encode and in building an objective function according to this. The direct approach to achiev e a low generalization error E ( x,y ) ∼P [ L ( ˜ θ ∗ , ( x, y ))] is to minimize the training loss L ( ˜ θ ∗ , D T r ) so that by definition, training on D S captures the information of the whole training ( W ang et al. , 2018 ). This method is called performance matching (PM). While PM tries to find the best D S , this requires a complex bi-le vel optimization ( V icol et al. , 2022 ). A simple one-step version learning D S that trains in one step a model with low training loss can be defined based on W ang et al. ( 2018 ) as follows: Definition 2.1. Consider a one-step student training A S that outputs ˜ θ (1) ( D S ) = θ − η S ∇ θ L ( θ , D S ) + λ S θ for a given initial parameter θ , data D S and loss L ( θ , D S ) . The one-step PM with input ˜ θ (1) ( D S ) is defined as M P ( D S , ˜ θ (1) ( D S ) , D T r , ξ , η , λ ) so that D S τ = D S τ − 1 − η ( ∇ D S L ( ˜ θ (1) ( D S τ − 1 ) , D T r ) + λ D S τ − 1 ) for τ = 1 , . . . ξ with D S 0 = D S and M P outputs D S ξ . On the other hand, gradient matching (GM) focuses on local representati ve information, namely , the gradient infor- mation, and optimizes D S so that the gradient with respect to θ of the loss e valuated on D S matches that induced by the training data ( Zhao et al. , 2021 ). Notably , a one-step GM can be inferred by their implementation and subsequent works ( Jiang et al. , 2023 ), defined as follo ws: Definition 2.2. Consider sets of gradients fr om T iterations of teacher training G T r = { G T r t } t ∈ [ T ] and one iteration of student training G S ( D S ) = { G S 1 } . Each gradient is divided by layer s with index l ∈ [ L ] and by random initialization of the training with j ∈ [ J ] . The one-step GM is defined as M G ( D S , G T r , G S ( D S ) , η , λ ) which pr ovides as outputs D S 1 = D S − η ( ∇ D S m ( G T r , G S ( D S )) + λ D S ) wher e m ( G T r , G S ) = 1 /J P j (1 − 1 /L P l ⟨ P t G T r t,j,l , G S 1 ,j,l ⟩ ) . In the original work of Zhao et al. ( 2021 ), m w as defined as the cosine similarity . Here, we omitted the normalization factor . This is acceptable in our case because we consider only a single update step, which does not risk diver ging, and our main concern is the dir ection of D S after one update. W e now make the follo wing important remark for GM. Remark 2.3. GM is not well-defined for ReLU activation function, as the gradient update leads to second derivatives of the activation function thr ough ∇ D S G S 1 ,j,l . Ther efore , we need to slightly adjust the student training and pr opose two appr oaches. W e either r eplace the ReLU activation function in the student training with a surr ogate h wher e h ′′ is well-defined, and pr ove a rather str ong r esult that applies to any well-behaved h , or , we pr opose a well-defined one-step GM update for ReLU. The former is tr eated in the main paper with Assumption 3.8 , and the latter in Appendix C . Both lead to the same r esult qualitatively . 3 Problem Setting and Assumptions In this section, we provide details on the problem setting, including task structure, model and algorithms. 3.1 T ask Setup It has been repeatedly reported that, for simple tasks such as MNIST , as little as one distilled image per class can produce strong performance after retraining, whereas on CIF AR-10 ev en 50 images per class is insuf ficient ( Zhao et al. , 2021 ). Based on the manifold hypothesis , which posits that real-world data distrib utions concentrate near a low-dimensional manifold ( T enenbaum et al. , 2000 ; Fefferman et al. , 2016 ), we hypothesize that the intrinsic structure of the task plays an important role in DD. W e formalize and analyze this phenomenon by considering a task, called multi-index model , that captures the essence of the complex interaction between latent structure and optimization procedure. This is a common setup in analyses of feature learning of neural netw orks trained under gradient descent ( Damian et al. , 2022 ; Abbe et al. , 2022 ; Bietti et al. , 2023 ). Assumption 3.1. T raining data D T r is given by N i.i.d. points { ( x n , y n ) } N n =1 with, x n ∼ N (0 , I d ) ∈ R d , y n = f ∗ ( x n ) + ϵ n ∈ R wher e ϵ n ∼ {± ζ } with ζ > 0 . f ∗ : R d → R is a normalized de gr ee p polynomial with E x [ f ∗ ( x ) 2 ] = 1 , and there exist a B = ( β 1 , . . . , β r ) ∈ R d × r and a function σ ∗ : R r → R such that f ∗ ( x ) = σ ∗ ( B ⊤ x ) = σ ∗ ( ⟨ β 1 , x ⟩ , . . . , ⟨ β r , x ⟩ ) . W ithout loss of gener ality , we assume B ⊤ B = I r . When r = 1 , we call it single inde x model ( Dhifallah and Lu , 2020 ). W e define its principal subspace and orthogonal projection. Definition 3.2. S ∗ : = span { β 1 , . . . , β r } is the principal subspace of f ∗ and Π ∗ the orthogonal pr ojection onto S ∗ . 4 Dataset Distillation Efficiently Encodes Lo w-Dimensional Representations A P R E P RI NT Algorithm 1 Dataset Distillation 1: Input: T raining dataset D T r , model f θ , loss function L , reference parameter θ (0) 2: Output: Distilled data D S 3: Initialize distilled data D S 0 randomly , α = 1 N P N n =1 y n , γ = 1 N P N n =1 y n x n , preprocess y n ← y n − α − ⟨ γ , x n ⟩ 4: Sample initial states { θ (0) j } J j =0 5: for t = 1 to T DD do 6: If progressiv e step: keep old D S ← D S ∪ D S t − 1 , prepare new D S t − 1 7: I. T r aining Phase 8: for j = 0 to J do 9: T eacher Training I T r j = { θ ( t ) j , G ( t ) j } where I T r j ← A T r t ( θ ( t − 1) j , D T r , ξ T r t − 1 , η T r t − 1 , λ T r t − 1 ) 10: Student T raining I S j = { ˜ θ ( t ) j , ˜ G ( t ) j } where I S j ← A S t ( θ ( t − 1) j , D S t − 1 , ξ S t − 1 , η S t − 1 , λ S t − 1 ) 11: end for 12: II. Distillation Phase 13: D S t ← M t ( D S t − 1 , D T r , { I T r j , I S j } , ξ D t − 1 , η D t − 1 , λ D t − 1 ) 14: III. Retraining Phase 15: θ ( t ) j ← A R t ( θ ( t − 1) j , D S t , ξ R t − 1 , η R t − 1 , λ R t − 1 ) for all j = 0 , . . . , J 16: Resample { θ ( t ) j } J j =0 if necessary 17: end for 18: return D Understanding how and when DD captures this principal subspace constitutes one of the main focuses of this analysis. W e impose the follo wing additional condition on the structure of f ∗ . This guarantees that the gradient information is non-degenerate. Assumption 3.3. H : = E x [ ∇ 2 x f ∗ ( x )] has rank r and satisfies span( H ) = S ∗ . H is well-conditioned, with maximal eigen value λ max , minimal non-zer o eigen value λ min and κ : = λ max /λ min . 3.2 T rained Model The task defined above is learned by a two-layer ReLU neural network f θ with width L and activ ation function σ ( x ) = max(0 , x ) , i.e., for a ∈ R L , W = ( w 1 , . . . , w L ) ∈ R d × L , b ∈ R L , θ = ( a, W, b ) , f θ ( x ) : = P L i =1 a i σ ( ⟨ w i , x ⟩ + b i ⟩ . For a dataset D = { ( x n , y n ) } N n =1 , the empirical loss is defined as L ( θ , D ) : = 1 2 N P N n =1 ( f ( x n ) − y n ) 2 (MSE loss). While this model may be simple, it is more complex than previous analyses of linear layers and embodies the complex interaction of task, model, and optimization we are interested in. W e use a symmetric initialization. As mentioned in other work ( Damian et al. , 2022 ; Oko et al. , 2024a ), small random initializations should not change our statements qualitativ ely . Assumption 3.4. L is even. f θ is initialized as ∀ i ∈ [ L/ 2] , a i ∼ {± 1 } , a i = − a L − i , w i ∼ N (0 , I d /d ) , w i = w L − i and b i = b L − i = 0 . Damian et al. ( 2022 ) showed that N ≥ ˜ Ω( d 2 ∨ d/ϵ ∨ 1 /ϵ 4 ) data points are required for a gradient-based training (See Definition 3.5 ) to achiev e a generalization error below ϵ . The preprocessing of Algorithm 1 is inspired by their work. 3.3 Optimization Dynamics and Algorithms Each algorithm of Algorithm 1 can be no w presented straightforwardly . Please refer to Algorithm 2 in Appendix D.6 for the complete specification. T eacher and Student T raining W e opt for the gradient-based training from Damian et al. ( 2022 ) (Algorithm 1 in their work) as the teacher training since its mechanism is well studied for multi-index models. This is divided into tw o phases as sho wn in Definition 3.5 belo w . For our progressi ve type of DD, we prepare tw o different distilled datasets, one for each phase. Student training follows the same update rule but with only one iteration, which is suf ficient for one-step PM and one-step GM. Damian et al. ( 2022 ) reinitialize b between the two parts which is also incorporated just before t = 2 . For each step, we output the final parameter and gradient of the loss with respect to the parameter of each iteration as follows: 5 Dataset Distillation Efficiently Encodes Lo w-Dimensional Representations A P R E P RI NT Definition 3.5. Based on the two phases of Algorithm 1 in Damian et al. ( 2022 ), we define the following pr ocedur es for θ = ( a, W, b ) . A (I) ( θ , D , η , λ ) : = {− η g , { g }} , wher e g = ∇ W L ( θ , D ) , and A (II) ( θ , D , ξ , η , λ ) : = { a ( ξ ) , { g τ } ξ τ =1 } , wher e a ( τ ) = a ( τ − 1) − η g τ ( τ ∈ [ ξ ]) , g τ = ∇ a L (( a ( τ − 1) , W , b ) , D ) + λa , and a (0) = a . Distillation and Retraining One-step PM (Definition 2.1 and one-step GM (Definition 2.2 ) are the two DDs we study . For the first phase t = 1 , we only consider the former as we do not hav e access to the final state of the model and cannot apply PM. The retraining algorithm follows the teacher training, e xcept for PM which supposes a one step gradient update by definition. T o e valuate DD, we retrain the model from a fixed reference initialization θ (0) , and build DD accordingly (see Assumptions 3.6 and 3.7 ), which is consistent with existing analyses ( Izzo and Zou , 2023 ). 2 Fixing θ (0) enables controlled e valuation and facilitates isolating fundamental interactions, an essential step to wards understanding the mechanism of DD. In summary , the whole formulation of each optimization dynamics can be presented as follows. Assumption 3.6. Algorithm 1 applied to our pr oblem setting is defined as follows. T DD = 2 , and for each t we cr eate a separate synthetic data, D S 1 and D S 2 . F or t = 1 , A T r 1 , A S 1 , and A R 1 ar e all set to be A (I) with their r espective ar guments. As for the distillation, M 1 = M G with the gradient information of A T r 1 and A S 1 as inputs. F or t = 2 , A T r 2 = A (II) and A S 2 = A (II) , with their respective hyperparameters and ξ S 2 = 1 . If we use one-step GM at t = 2 , M 2 = M G with the gradient information of A T r 2 and A S 2 as inputs, and A R 2 = A (II) , otherwise if we use one-step PM at t = 2 , M 2 = M P with input ˜ θ (2) 0 , and A R 2 = A (II) with ξ R 2 = 1 . The hyperparameters of A T r 1 and A T r 2 ar e kept the same as Theor em 1 of Damian et al. ( 2022 ). and those of A S 1 is also the same as the former . The rest of the undefined hyperparameters will be specified later . Batch initializations are defined as follows. Assumption 3.7. F or t = 1 , { θ (0) j } J j =1 ar e sampled following the initialization of Assumption 3.4 , with θ (0) 0 = ( a (0) , W (0) , 0) , wher e the r efer ence θ (0) = ( a (0) , W (0) , b (0) ) satisfies ∀ i ∈ [ L ] , a i ∈ {± 1 } , a i = − a L − i , w i = w L − i and b (0) ∼ N (0 , I L ) . F or t = 2 , we r esample { θ (1) j } J j =1 by W (1) j = W (1) 0 = W (1) , b (1) j = b (0) , a (1) j ∼ {± 1 } for j ∈ [ J ] , and a (1) 0 = 0 . Finally , based on Remark 2.3 , the student training at t = 1 is approximated as follo ws: Assumption 3.8. ReLU activation function σ of the student training at t = 1 , is r eplaced by a (surr ogate) C 2 function h so that h ′′ ( t ) > 0 for all t ∈ [ − 1 , 1] . The last condition is satisfied by a large v ariety of continuous functions including surrogates of ReLU such as softplus. 4 Main Result W e now state our main result followed by a proof sketch. Our goal is to 1) explicitly formulate the result of each distillation process (at t = 1 and t = 2 ) and 2) ev aluate the required size of created synthetic datasets D S 1 and D S 2 so that retraining f θ with the former in the first phase and with the latter in the second phase leads to a parameter ˜ θ ∗ whose generalization performance preserves that of the baseline trained on the lar ge dataset D T r across both phases. Theorem 4.1 establishes the behavior of the first distilled dataset, Theorem 4.2 then ev aluates the sufficient size of D S 1 to successfully substitute D T r in the first phase, and Theorem 4.5 analyzes the behavior and the sufficient size of D S 2 to replace D T r in the second phase. Please refer to Appendix B for the proof of single index models, and Appendix D for that of multi-index models. 4.1 Structure Distillation and Memory Complexity Our first result is that the lo w-dimensional intrinsic structure of the task, represented here as S ∗ , is encoded into the first distilled data D S 1 by Algorithm 1 . Theorem 4.1 (Latent Structure Encoding) . Under Assumptions 3.1 , 3.3 , 3.4 , 3.6 , 3.7 and 3.8 , we consider D S 1 with initializations { ˜ x (0) m , ˜ y (0) m } M 1 m =1 wher e ∥ ˜ x (0) m ∥ ∼ U ( S d − 1 ) and ˜ y (0) m is some constant. Then, with high pr obability , Algorithm 1 r eturns D S 1 = { ˜ x (1) m , ˜ y (0) m } M 1 m =1 with ˜ x (1) m ∝ H ˜ x (0) m + (lo wer order term) for all m ∈ [ M 1 ] . 2 θ (0) can be vie wed as a pre-trained model ( Cazenav ette et al. , 2025 ), or a structured initialization reducing its storage cost to some constant order . If the pre-trained model θ (0) is trained more than once, then DD becomes beneficial as it avoids the storage of each fine-tuned model. 6 Dataset Distillation Efficiently Encodes Lo w-Dimensional Representations A P R E P RI NT Please refer to Appendices B.3 and D.3 for the proofs. Assumption 3.3 directly implies that ˜ x (0) m is effecti vely projected onto the principal subspace S ∗ up to lo wer order terms, and D S 1 now contains much cleaner information on the latent structure than randomly generated training points. This set can be applied on its o wn to transfer learning (see Section 5 ). W (0) can be trained with D S 1 from θ (0) = ( a (0) , W (0) , 0) , resulting in θ (1) = ( a (0) , W (1) , b (0) ) (retraining phase of step t = 1 ) where b (0) is the v alue after reinitialization. Interestingly , only M 1 ∼ ˜ Θ( r 2 ) is suf ficient to guarantee that the teacher training of t = 2 can train the second layer and infer a model with lo w population loss. 3 Theorem 4.2. Under assumptions of Theorem 4.1 , consider the teacher training at t = 2 of f θ (1) 0 with θ (1) = ( a (0) , W (1) , b (0) ) . If M 1 ≥ ˜ Ω( r 2 ) , d ≥ ˜ Ω( r 8 p +3 ) N ≥ ˜ Ω( r 8 p +1 d 4 ) , LJ ≥ ˜ Ω( r 8 p +1 d 4 ) and ( ˜ y (0) m ) 2 ∼ χ ( d ) . Then, ther e exist hyperparameters η D 1 , λ D 1 , η R 1 , λ R 1 , η T r 2 , λ T r 2 and ξ T r 2 so that at t = 2 the teacher training finds a ∗ that satisfies with pr obability at least 0.99 with θ ∗ = ( a ∗ , W (1) , b (0) ) , E x,y [ | f θ ∗ ( x ) − y | ] − ζ ≤ ˜ O r dr 3 p N + r r 3 p L + 1 N 1 / 4 ! . Please refer to Appendix D.4 for the proof. Importantly , Theorem 1 of Damian et al. ( 2022 ) states learning f ∗ requires ˜ Ω( d 2 ∨ d/ϵ ∨ 1 /ϵ 4 ) general training data points. In contrast, thanks to DD, we only need to save D S 1 and the information of a ∗ , which amounts to a memory comple xity of ˜ Θ( r 2 d + L ) . This clearly sho ws that one of the ke y mechanisms behind the empirical success of DD in achie ving a high compression rate resides in its ability to capture the low-dimensional structure of the task and translate it into well-designed distilled sets for smoother training. For single index models, we can prov e a stronger result which shows that one distilled data point M 1 = 1 can be sufficient. Theorem 4.3. Under assumptions of Theorem 4.1 , consider the teacher training at t = 2 of f θ (1) 0 with θ (1) = ( a (0) , W (1) , b (0) ) . F or r = 1 , if M 1 = 1 , N ≥ ˜ Ω( d 4 ) , J ≥ ˜ Ω( d 4 ) , and ⟨ β 1 , ˜ x (0) 1 ⟩ is not too small (i.e., with order ˜ Θ( d − 1 / 2 ) ), then ther e exist hyperpar ameters η D 1 , λ D 1 , η R 1 , λ R 1 , η T r 2 , λ T r 2 and ξ T r 2 so that at t = 2 the teacher tr aining finds a ∗ that satisfies with pr obability at least 0.99 with θ ∗ = ( a ∗ , W (1) , b (0) ) , E x,y [ | f θ ∗ ( x ) − y | ] − ζ ≤ ˜ O r d N + r 1 L + 1 N 1 / 4 ! . Please refer to Appendix B.5 for the proof. 4.2 Distillation of Second Phase t = 2 W e no w turn to the second DD (distillation phase t = 2 ) which distills the teacher training that finds a ∗ of Theorems 4.2 and 4.3 . W e start by observing that a ∗ already has a compact memory storage of Θ( L ) , and we may just store it to achiev e the lowest memory cost. Below , we discuss DD methods that creates D S 2 with the same order of memory complexity . On the one hand, we can prepare a set of points { ˆ p m , ˆ y m } M 2 m =1 where ˆ p m lies in the featur e space R L . Since we only train the second layer at the second step, this training is equi valent to a LRR. W e can then employ the result of Chen et al. ( 2024a ) and conclude that M 2 = 1 is sufficient. On the other hand, we show that Algorithm 1 also constructs a compact set and reproduces such a ∗ at retraining under a regularity condition on the initialization of D S 2 = { ( ˆ x (0) m , ˆ y (0) m ) } m ∈ [ M 2 ] . Assumption 4.4 (Regularity Condition) . The second distilled dataset D S 2 is initialized as { ( ˆ x (0) m , ˆ y (0) m ) } M 2 m =1 so that the kernel of f θ (1) after t = 1 , ( ˜ K ) im = σ ( ⟨ w (1) i , ˆ x (0) m ⟩ + b (0) i ) has the maximum attainable rank, and its memory cost does not exceed ˜ Θ( r 2 d + L ) . When D : = { i | w (1) i = 0 } , the maximum attainable rank is | D | + 1 if ther e exists an i 0 ∈ [ L ] \ D such that b i 0 > 0 , and | D | otherwise . Please refer to Appendix B.8 for further discussion. 4 Under this condition, one-step GM and one-step PM can directly create D S 2 that reconstructs the final layer . 3 W e only show the dependence on r and d for the bounds here. The precise formulation of the statement can be found in the appendices. 4 W e believe that such a construction can be obtained empirically , since increasing M 2 nev er decreases the rank of ˜ K , and makes unfa vorable e vent almost unlikely by randomness of b (0) . In Appendix B.8 we provide a construction that works well in our experiments, has a theoretical guarantee and compact memory cost as required. 7 Dataset Distillation Efficiently Encodes Lo w-Dimensional Representations A P R E P RI NT Theorem 4.5. Under assumptions of Theor em 4.2 and r e gularity condition 4.4 , ther e exist hyperpar ameters λ S 2 , η D 2 , λ D 2 , ξ D 2 , η R 2 , λ R 2 , ξ R 2 so that second distillation phase of Algorithm 1 (both one-step PM and one-step GM) finds D S 2 = { ( ˆ x (0) m , ˆ y ( ξ D 2 ) m ) } M 2 m =1 so that r etraining with initial state θ (0) and dataset D S 1 ∪ D S 2 pr ovides ˜ θ ∗ that achie ves the same err or bound as θ ∗ of Theor em 4.2 . In all cases discussed abov e, we obtain the same memory complexity as follo ws Theorem 4.6. The overall memory comple xity in terms of training data to obtain an f θ with generalization err or below ϵ is reduced by DD fr om Θ( d 3 ∨ d 2 /ϵ ∨ d/ϵ 4 ∨ dL ) to ˜ Θ( r 2 d + L ) , which is lower than the model storage cost of Θ( dp ) . Please refer to Appendices B.7 and D.5 for the proofs. 4.3 Proof Sk etch The key points of our proof can be summarized as the follo wing three parts. (i) F eature Extraction at t = 1 W e show that the teacher gradient extracts information from the principal subspace (Lemma B.14 ), which follo ws from Damian et al. ( 2022 ), and then that this is transmitted to the population gradient (Theorem B.18 and D.8 ), leading to D S 1 projected onto S ∗ . (ii) T eacher Learning at t = 2 Since D S 1 now captures the information of the lo w dimensional structure, we prove by construction that a second layer with a good generalization ability of the whole task exists. Intuitively , as we already hav e the information of B in f ∗ ( x ) = σ ∗ ( B ⊤ x ) , we look for the right coefficient to reconstruct σ ∗ with the last layer . By equi valence between ridge regression and norm constrained linear regression, the ridge re gression of teacher training at t = 2 can find a second layer as good as the one we constructed. (iii) Second Distillation Phase W e show that the final direction of the parameters can be encoded into D S 2 under a regularity condition 4.4 , especially into its labels, with both one-step PM and GM. The crux is that under this condition, a ∗ ∈ col( ˜ K ) , and we can import information of the last layer to the set ˆ y (1) m , which reconstructs a ∗ at retraining. 5 Synthetic Experiments 5.1 Theoretical Illustration Here, we present an illustration of our result in terms of sample complexity of N and J and show that it matches our theory . W e set f ∗ ( x ) = σ ∗ ( ⟨ β , x ⟩ ) where σ ∗ ( z ) = He 2 (z) / 2 + He 4 (z) / 4! , ζ = 0 , r = 1 , d = 10 , and L = 100 . Since this is a single index model, we prepare one synthetic point for D S 1 = { ( ˜ x (0) , ˜ y (0) ) } following Theorem 4.3 . D S 2 is initialized following the construction of Appendix B.8 . W e run Algorithm 1 and compare the generalization error of the network trained according to five dif ferent paradigms, namely , the vanilla training with the full training data, that with the obtained distilled data and its corresponding random baseline where we replaced D S 1 and D S 2 used in the training with random points of D T r (Random II), the result of teacher training at t = 2 and its corresponding random baseline where we replaced D S 1 used in the training by a random point of the original dataset D T r (Random I). Results are plotted in Figure 1 for dif ferent sizes of N = { 10 , 10 2 , 10 3 , 10 4 , 10 5 } and ef fective random initialization J ∗ = LJ / 2 = { 10 , 10 2 , 10 3 , 10 4 , 10 5 } , which is the actual number of directions the gradient update can see for the first distillation step (see Corollary B.7 ). As we can observe, random baselines cannot reproduce a performance close to the original training, while one data of distilled D S 1 is enough. Furthermore, the generalization loss of the distilled data decreases as J and N increase. These illustrate the compression efficienc y of DD and the necessity of large N and J implied in Theorem 4.5 . 5.2 Application to T ransfer Learning An implication of Theorem 4.2 is that D S 1 can be used to learn other functions f ∗ ( x ) = σ ∗ ( B ⊤ x ) that possess the same principal subspace but dif ferent σ ∗ . W e use D S 1 obtained from the previous e xperiment to learn a novel function g ∗ ( x ) = He 3 ( ⟨ β , x ⟩ ) / √ 3! with the identical underlying structure as f ∗ . D S 1 is computed with N training data of f ∗ and J ∗ initializations follo wing Algorithm 1 . W eights were then pre-trained with the resulting D S 1 , and we fine-tuned the second layer with n samples from g ∗ . The result is plotted in Figure 2 . 8 Dataset Distillation Efficiently Encodes Lo w-Dimensional Representations A P R E P RI NT Figure 1: Dependence of training data size with J ∗ = 10 5 (left figure) and initialization batch size with N = 10 5 (right) with respect to the achiev ed MSE loss. Mean and standard deviation o ver fiv e seeds. Figure 2: MSE loss with respect to the training data size n used to fine-tune a model pre-trained with data distilled from the earlier training of a function with the same principal subspace. N and J ∗ are the parameters for this training before. Mean and standard deviation o ver fi ve seeds. Theorem 3 of Damian et al. ( 2022 ) states that with such pre-trained weights the number of n does not scale with d anymore. W e can observe the same phenomenon in Figure 2 where population loss is already low for smaller n compared to Figure 1 . Note that learning g ∗ is a difficult problem and neural tangent kernel requires n ≳ d 3 to achiev e non-trivial loss ( Damian et al. , 2022 ). Importantly , this result was computed o ver random initializations of the whole network, sho wing the robustness of this approach ov er initial configurations in this kind of problems. This result aligns with general transfer learning scenarios where we assume sev eral tasks share a common underlying structure, and one general pre-trained model can be fine-tuned with lo w training cost to each of them. Since our distilled dataset needs less memory storage than the pre-trained model, this experiment supports the idea that DD provides a compact summary of previous kno wledge that can be deployed at lar ger scale for applications such as transfer learning ( Lee et al. , 2024 ). 6 Discussion and Conclusion One notable feature of our result is that DD exploits the intrinsic dimensionality of the task to realize a high compression rate, primarily during the early stage of distillation, as frequently suggested in prior work ( Zhao et al. , 2021 ). This also confirms prior empirical findings that DD encodes information from the beginning of teacher training, which can be sufficient to attain strong distillation performance on certain tasks ( Zhao et al. , 2021 ; Y ang et al. , 2024 ). While the first distillation principally captures information from S ∗ and can be utilized to other tasks such as transfer learning, the second distillation can be interpreted as an architecture-specific distillation that encodes more fine-tuned information of 9 Dataset Distillation Efficiently Encodes Lo w-Dimensional Representations A P R E P RI NT the training. Since a factor of d is unav oidable as soon as we save a point in the input dimension, the obtained memory complexity of ˜ Θ( r 2 d + L ) depends only fundamentally on the intrinsic structure of the task and the architecture of the neural network. At the same time, this ef ficient retraining and compact distilled dataset come at the cost of increased computation relativ e to standard training. Especially , the initialization batch size J scales with d . While we expect the exponents can be improved, this computational overhead appears to be the price for the strong performance of DD. Moreov er , our analysis rev eals a clear trade-off between PM and GM. The former has lower computational complexity during distillation b ut higher cost during retraining, and vice versa . Finally , our result supports a principled strategy for DD. Distilling earlier training phases may capture intrinsic features that are not captured later . Consequently , aggregating information from the entire training trajectory into a single distilled dataset may be inefficient, and a careful distillation appropriate to each phase of the training constitutes a ke y factor to improv e the performance of DD. From this perspectiv e, the progressiv e DD approach of Cazenavette et al. ( 2025 ) not only f acilitates a cleaner analysis of the complex machinery of DD b ut also contributes to creating ef fectiv e distilled datasets. Comparison with Prior W orks T o the best of our knowledge, we provide the first analysis of DD dynamics that accounts for task structure, non-linear models, and gradient-based optimization. This leads to se veral novel results that pre vious research could not obtain. Notably , our theoretical framework sho ws that DD can identify the intrinsic structure of the task, which helps explain why the performance of DD varies in function of task dif ficulty , beyond previous KRR settings. By carefully tracking the algorithmic mechanism when all layers of the model are trained, we could quantify the memory complexity of DD as ˜ Θ( r 2 d + L ) . In comparison, for the same model, Chen et al. ( 2024a ) would require a memory complexity Θ( Ld ) . Θ( Ld ) is also the storage cost of the entire two-layer neural network. Our result is prov ed for one-step distillation methods, which also helps to explain why such techniques can be competiti ve in practice. Furthermore, throughout our proofs, random initializations play a crucial role in isolating the fundamental information to be distilled. This feature was not considered in prior work, and we highlight it accordingly . Potential Benefit of Pr e-T rained Models In our theorem, the dependence on d is mainly absorbed into N and J . This dependence may be improv ed by lev eraging information from pre-trained models which are also subjected to DD to reduce their fine-tuning cost ( Cazenavette et al. , 2025 ). Indeed, as such models have been trained on a wide range of tasks, their weights may concentrate on a lower -dimensional structure that reflects a moderately small effecti ve dimension r ∗ of the en vironment which includes the small r -dimensional subspace of our problem setting. As a result, rather than using generic isotropic distributions for the initialization of the parameters as in our analysis, one could estimate a task-relev ant subspace directly from the pre-trained weights, extracting a principal subspace of dimension r ∗ and restrict the sampling distribution to that r ∗ -dimensional subspace. This would replace the dependence of N and J on d by a dependence on r ∗ . W e believ e this is a promising approach for future work. Limitations One limitation of our work resides in the function class we analyze, that of multi-index models, which may not fully represent practical settings. Nev ertheless, this captures the essence of the complex interaction that happens inside DD, such as the lo w-dimensional latent structure of the task, which was not considered in prior theoretical in vestigations of DD. Our work on its o wn thus advances theoretical understanding and dev elops tools that can serve as a foundation for even more practice-aligned models. The initialization of D S 1 and D S 2 may also look too model-specific. Ho wever , the scope of our work does not include cross-architecture generalization, and thus this does not undermine the validity of our results. Analogous construction procedures could be dev eloped for other deeper neural networks, which is also left for future work. In conclusion, we analyzed DD applied to an optimization frame work for two-layer neural networks with ReLU activ ation functions trained on a task endowed with lo w-dimensional latent structures. W e proved not only that DD lev erages such a latent structure and encodes its information into well-designed distilled data, but also that the memory storage necessary to retrain a neural network with high generalization score is decreased to ˜ Θ( r 2 d + L ) . While the primary goal of this work was to elucidate how DD exploits intrinsic patterns of a training regime, the setting we analyzed remains simplified relativ e to practical deployments, and extending the theory to more realistic regimes constitutes an essential avenue for future work. Nev ertheless, we believ e this paper contributes on its own to the dev elopment and deeper understanding of DD, ultimately helping advance it towards a reliable methodology for reducing the data and computational burdens of modern deep learning. Acknowledgements YK was supported by JST A CT -X (JPMJ AX25CA) and JST BOOST (JPMJBS2418). NN was partially supported by JST A CT -X (JPMJ AX24CK) and JST BOOST (JPMJBS2418). TT is supported by RIKEN Center for Brain Science, 10 Dataset Distillation Efficiently Encodes Lo w-Dimensional Representations A P R E P RI NT RIKEN TRIP initiativ e (RIKEN Quantum), JST CREST program JPMJCR23N2, and JSPS KAKENHI 25K24466. W e thank T aiji Suzuki for helpful discussions. References T ongzhou W ang, Jun-Y an Zhu, Antonio T orralba, and Alexei A Efros. Dataset distillation. arXiv preprint arXiv:1811.10959 , 2018. Bo Zhao, K onda Reddy Mopuri, and Hakan Bilen. Dataset condensation with gradient matching. 2021. George Cazenavette, T ongzhou W ang, Antonio T orralba, Alex ei A. Efros, and Jun-Y an Zhu. Dataset distillation by matching training trajectories. In Proceedings of the IEEE/CVF Conference on Computer V ision and P attern Recognition (CVPR) W orkshops , pages 4750–4759, June 2022. Kai W ang, Bo Zhao, Xiangyu Peng, Zheng Zhu, Shuo Y ang, Shuo W ang, Guan Huang, Hakan Bilen, Xinchao W ang, and Y ang Y ou. CAFE: Learning to condense dataset by aligning features. In Pr oceedings of the IEEE/CVF Confer ence on Computer V ision and P attern Recognition (CVPR) , pages 12196–12205, June 2022. Ilia Sucholutsk y and Matthias Schonlau. Soft-label dataset distillation and te xt dataset distillation. In 2021 International Joint Confer ence on Neural Networks (IJCNN) , pages 1–8, 2021. doi: 10.1109/IJCNN52387.2021.9533769. Guang Li, Ren T ogo, T akahiro Ogawa, and Miki Hase yama. Soft-label anonymous gastric X-ray image distillation. In 2020 IEEE International Confer ence on Image Pr ocessing (ICIP) , pages 305–309, 2020. doi: 10.1109/ICIP40778. 2020.9191357. Jianrong Ding, Zhanyu Liu, Guanjie Zheng, Haiming Jin, and Linghe Kong. CondTSF: One-line plugin of dataset condensation for time series forecasting. In A. Globerson, L. Mackey , D. Belgrave, A. Fan, U. P aquet, J. T omczak, and C. Zhang, editors, Advances in Neural Information Pr ocessing Systems , volume 37, pages 128227–128259. Curran Associates, Inc., 2024. doi: 10.52202/079017- 4072. Hanfei Guo, Junhao Xu, Chang Li, W ei Zhao, Hu Peng, Zhihui Han, Y uanguo W ang, and Xun Chen. Single-channel EEG-based sleep stage classification via hybrid data distillation. Journal of Neural Engineering , 22(6):066013, 2025. Dong Bok Lee, Seanie Lee, Joonho Ko, Kenji Kawaguchi, Juho Lee, and Sung Ju Hwang. Self-supervised dataset distillation for transfer learning. International Confer ence on Learning Repr esentations , 2024. Y aoyao Liu, Y uting Su, An-An Liu, Bernt Schiele, and Qianru Sun. Mnemonics training: Multi-class incremental learning without for getting. In Pr oceedings of the IEEE/CVF Conference on Computer V ision and P attern Recognition (CVPR) , June 2020. W ojciech Masarczyk and Ivona T autkute. Reducing catastrophic forgetting with learning on synthetic data. In Pr oceedings of the IEEE/CVF Confer ence on Computer V ision and P attern Recognition (CVPR) W orkshops , June 2020. Jiangtao K ong, Jiacheng Shi, Ashley Gao, Shaohan Hu, Tian yi Zhou, and Huajie Shao. Hybrid memory replay: Blending real and distilled data for class incremental learning. arXiv pr eprint arXiv:2410.15372 , 2024. Y anlin Zhou, George Pu, Xiyao Ma, Xiaolin Li, and Dapeng W u. Distilled one-shot federated learning. arXiv preprint arXiv:2009.07999 , 2020. T ian Dong, Bo Zhao, and Lingjuan L yu. Priv acy for free: How does dataset condensation help pri v acy? In Kamalika Chaudhuri, Stefanie Je gelka, Le Song, Csaba Szepesv ari, Gang Niu, and Siv an Sabato, editors, Pr oceedings of the 39th International Confer ence on Mac hine Learning , volume 162 of Pr oceedings of Machine Learning Resear ch , pages 5378–5396. PMLR, 17–23 Jul 2022. George Cazena vette, Antonio T orralba, and V incent Sitzmann. Dataset distillation for pre-trained self-supervised vision models. In Advances in Neural Information Pr ocessing Systems , 2025. Zachary Izzo and James Zou. A theoretical study of dataset distillation. In NeurIPS 2023 W orkshop on Mathematics of Modern Machine Learning , 2023. Alaa Maalouf, Murad T ukan, Noel Loo, Ramin Hasani, Mathias Lechner, and Daniela Rus. On the size and approxima- tion error of distilled datasets. In A. Oh, T . Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Le vine, editors, Advances in Neural Information Pr ocessing Systems , volume 36, pages 61085–61102. Curran Associates, Inc., 2023. Y ilan Chen, W ei Huang, and Tsui-W ei W eng. Prov able and efficient dataset distillation for kernel ridge regression. In A. Globerson, L. Mackey , D. Belgrav e, A. Fan, U. Paquet, J. T omczak, and C. Zhang, editors, Advances in Neural Information Pr ocessing Systems , volume 37, pages 88739–88771. Curran Associates, Inc., 2024a. doi: 10.52202/079017- 2816. 11 Dataset Distillation Efficiently Encodes Lo w-Dimensional Representations A P R E P RI NT Zhengquan Luo and Zhiqiang Xu. Utility boundary of dataset distillation: Scaling and configuration-cov erage laws. arXiv pr eprint arXiv:2512.05817 , 2025. Alexandru Damian, Jason Lee, and Mahdi Soltanolkotabi. Neural networks can learn representations with gradient descent. In Po-Ling Loh and Maxim Raginsky , editors, Pr oceedings of Thirty Fifth Confer ence on Learning Theory , volume 178 of Pr oceedings of Machine Learning Resear ch , pages 5413–5452. PMLR, 02–05 Jul 2022. Jamie Maho wald, Ravi Sriniv asan, and Zhangyang W ang. T oward dataset distillation for regression problems. In ES-F oMo III: 3r d W orkshop on Efficient Systems for F oundation Models , 2025. Ruonan Y u, Songhua Liu, and Xinchao W ang. Dataset distillation: A comprehensiv e revie w . IEEE T ransactions on P attern Analysis and Machine Intelligence , 46(1):150–170, 2024. doi: 10.1109/TP AMI.2023.3323376. T imothy Nguyen, Zhourong Chen, and Jaehoon Lee. Dataset meta-learning from kernel ridge-regression. 2021a. T imothy Nguyen, Roman Novak, Lechao Xiao, and Jaehoon Lee. Dataset distillation with infinitely wide conv olutional networks. In M. Ranzato, A. Beygelzimer , Y . Dauphin, P .S. Liang, and J. W ortman V aughan, editors, Advances in Neural Information Pr ocessing Systems , volume 34, pages 5186–5198. Curran Associates, Inc., 2021b. Y ongchao Zhou, Ehsan Nezhadarya, and Jimmy Ba. Dataset distillation using neural feature regression. In S. K oyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors, Advances in Neural Information Pr ocessing Systems , volume 35, pages 9813–9827. Curran Associates, Inc., 2022. Songhua Liu, Kai W ang, Xingyi Y ang, Jingwen Y e, and Xinchao W ang. Dataset distillation via factorization. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors, Advances in Neural Information Pr ocessing Systems , volume 35, pages 1100–1113. Curran Associates, Inc., 2022. Zixuan Jiang, Jiaqi Gu, Mingjie Liu, and David Z. Pan. Delving into effecti ve gradient matching for dataset condensation. In 2023 IEEE International Confer ence on Omni-layer Intelligent Systems (COINS) , pages 1–6, 2023. doi: 10.1109/ COINS57856.2023.10189244. Justin Cui, Ruochen W ang, Si Si, and Cho-Jui Hsieh. Scaling up dataset distillation to ImageNet-1K with constant memory . In Andreas Krause, Emma Brunskill, K yunghyun Cho, Barbara Engelhardt, Siv an Sabato, and Jonathan Scarlett, editors, Pr oceedings of the 40th International Confer ence on Machine Learning , v olume 202 of Pr oceedings of Machine Learning Resear ch , pages 6565–6590. PMLR, 23–29 Jul 2023. Xuxi Chen, Y u Y ang, Zhangyang W ang, and Baharan Mirzasoleiman. Data distillation can be like v odka: Distilling more times for better quality . 2024b. Byunggwan Son, Y oungmin Oh, Donghyeon Baek, and Bumsub Ham. FYI: Flip your images for dataset distillation. In Aleš Leonardis, Elisa Ricci, Stefan Roth, Olga Russakovsk y , T orsten Sattler , and Gül V arol, editors, Computer V ision – ECCV 2024 , pages 214–230, Cham, 2025. Springer Nature Switzerland. Bo Zhao and Hakan Bilen. Dataset condensation with differentiable siamese augmentation. In Marina Meila and T ong Zhang, editors, Pr oceedings of the 38th International Confer ence on Machine Learning , volume 139 of Pr oceedings of Machine Learning Resear ch , pages 12674–12685. PMLR, 18–24 Jul 2021. Zhiwei Deng and Olga Russakovsky . Remember the past: Distilling datasets into addressable memories for neural networks. In S. Ko yejo, S. Mohamed, A. Agarwal, D. Belgrav e, K. Cho, and A. Oh, editors, Advances in Neural Information Pr ocessing Systems , volume 35, pages 34391–34404. Curran Associates, Inc., 2022. Oussama Dhifallah and Y ue M Lu. A precise performance analysis of learning with random features. arXiv preprint arXiv:2008.11904 , 2020. Federica Gerace, Bruno Loureiro, Florent Krzakala, Marc Mezard, and Lenka Zdeborova. Generalisation error in learning with random features and the hidden manifold model. In Hal Daumé III and Aarti Singh, editors, Pr oceedings of the 37th International Confer ence on Machine Learning , volume 119 of Pr oceedings of Machine Learning Resear ch , pages 3452–3462. PMLR, 13–18 Jul 2020. Jimmy Ba, Murat A Erdogdu, T aiji Suzuki, Zhichao W ang, Denny W u, and Greg Y ang. High-dimensional asymptotics of feature learning: Ho w one gradient step improves the representation. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrav e, K. Cho, and A. Oh, editors, Advances in Neural Information Pr ocessing Systems , volume 35, pages 37932–37946. Curran Associates, Inc., 2022. Kazusato Oko, Y ujin Song, T aiji Suzuki, and Denny W u. Pretrained transformer efficiently learns low-dimensional target functions in-conte xt. In A. Globerson, L. Mackey , D. Belgrav e, A. Fan, U. Paquet, J. T omczak, and C. Zhang, editors, Advances in Neural Information Pr ocessing Systems , v olume 37, pages 77316–77365. Curran Associates, Inc., 2024a. 12 Dataset Distillation Efficiently Encodes Lo w-Dimensional Representations A P R E P RI NT Naoki Nishikawa, Y ujin Song, Kazusato Oko, Denny W u, and T aiji Suzuki. Nonlinear transformers can perform inference-time feature learning. In Aarti Singh, Maryam Fazel, Daniel Hsu, Simon Lacoste-Julien, Felix Berkenkamp, T egan Maharaj, Kiri W agstaff, and Jerry Zhu, editors, Pr oceedings of the 42nd International Confer ence on Machine Learning , volume 267 of Pr oceedings of Machine Learning Resear ch , pages 46554–46585. PMLR, 13–19 Jul 2025. Emmanuel Abbe, Enric Boix Adsera, and Theodor Misiakiewicz. The merged-staircase property: A necessary and nearly sufficient condition for SGD learning of sparse functions on tw o-layer neural networks. In Po-Ling Loh and Maxim Raginsky , editors, Pr oceedings of Thirty F ifth Confer ence on Learning Theory , volume 178 of Pr oceedings of Machine Learning Resear ch , pages 4782–4887. PMLR, 02–05 Jul 2022. Alberto Bietti, Joan Bruna, and Loucas Pillaud-V ivien. On learning gaussian multi-index models with gradient flo w . arXiv pr eprint arXiv:2310.19793 , 2023. Kazusato Oko, Y ujin Song, T aiji Suzuki, and Denny W u. Learning sum of diverse features: Computational hardness and ef ficient gradient-based training for ridge combinations. In Shipra Agra wal and Aaron Roth, editors, Pr oceedings of Thirty Seventh Confer ence on Learning Theory , volume 247 of Pr oceedings of Machine Learning Researc h , pages 4009–4081. PMLR, 30 Jun–03 Jul 2024b. Y unwei Ren, Eshaan Nichani, Denny W u, and Jason D Lee. Emergence and scaling la ws in SGD learning of shallo w neural networks. 2025. Paul V icol, Jonathan P Lorraine, Fabian Pedregosa, David Duvenaud, and Roger B Grosse. On implicit bias in ov erparameterized bilevel optimization. In Kamalika Chaudhuri, Stefanie Jegelka, Le Song, Csaba Szepesvari, Gang Niu, and Siv an Sabato, editors, Pr oceedings of the 39th International Confer ence on Machine Learning , volume 162 of Pr oceedings of Machine Learning Resear ch , pages 22234–22259. PMLR, 17–23 Jul 2022. Joshua B. T enenbaum, V in de Silv a, and John C. Langford. A global geometric frame work for nonlinear dimensionality reduction. Science , 290(5500):2319–2323, 2000. Charles Fefferman, Sanjo y Mitter , and Hariharan Narayanan. T esting the manifold hypothesis. Journal of the American Mathematical Society , 29(4):983–1049, 2016. W illiam Y ang, Y e Zhu, Zhiwei Deng, and Olga Russako vsky . What is dataset distillation learning? In Ruslan Salakhutdinov , Zico K olter, Katherine Heller , Adrian W eller , Nuria Oliver , Jonathan Scarlett, and Felix Berkenkamp, editors, Pr oceedings of the 41st International Conference on Machine Learning , volume 235 of Pr oceedings of Machine Learning Resear ch , pages 56812–56834. PMLR, 21–27 Jul 2024. Roman V ershynin. High-dimensional pr obability: An intr oduction with applications in data science , volume 47. Cambridge univ ersity press, 2018. Alex Damian, Eshaan Nichani, Rong Ge, and Jason D Lee. Smoothing the landscape boosts the signal for SGD: Optimal sample complexity for learning single index models. In A. Oh, T . Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Le vine, editors, Advances in Neural Information Pr ocessing Systems , volume 36, pages 752–784. Curran Associates, Inc., 2023. 13 Dataset Distillation Efficiently Encodes Lo w-Dimensional Representations A P R E P RI NT A Further Notations, T ensor Computation and Hermite Polynomials A.1 Notations In this paper , we employ the notion of high probability e vents defined as follo ws: Definition A.1. Thr oughout the pr oofs, ι is used to denote any quantity such that ι = C ι log ( N Ld ) for sufficiently lar ge constant C ι , and will be r edefined accor dingly . Mor eover , an event is said to happen with high pr obability if its pr obability is at least 1 − p oly( N , L, d )e − ι wher e p oly( N , L, d ) is a polynomial of N , L and d that does not depend on C ι . Any union bound of a number of p oly( N , L, d ) of high probability e vents is itself a high probability e vents. Since all our parameters will scale up to p oly( N , L, d ) orders, we can take such union bound safely . For example, the follo wing holds for the Gaussian distribution and the uniform distrib ution ov er S d − 1 . Lemma A.2. If x ∼ N (0 , I d ) , then ∥ x ∥ 2 = ˜ Θ( d ) with high pr obability . Pr oof. From Theorem 3.1.1 of V ershynin ( 2018 ), √ d − t ≤ ∥ x ∥ ≤ √ d + t with probability at least 1 − 2e − ct 2 , where c is a univ ersal constant independent of d and t . t = 1 2 √ d leads to 1 2 √ d ≤ ∥ x ∥ ≤ 3 2 √ d with probability at least 1 − 2e − cd , which is a high probability ev ent. Lemma A.3. If x ∼ U ( S d − 1 ) and ∥ β ∥ = 1 , then |⟨ x, β ⟩| ≲ 1 / √ d with high pr obability . Pr oof. This follows from Corollary 46 of Damian et al. ( 2022 ). W e also denote for a matrix K the span of its column as col( K ) . A.2 T ensor Computation Our proofs for single-index and multi-index models inv olve tensor computations. Therefore, we present a brief clarification of symbols and notations used in this paper . Those are usual notations also used in other works ( Damian et al. , 2022 , 2023 ; Oko et al. , 2024a ). Definition A.4. A k -tensor is defined as the generalization of matrices with multiple indices. Let A ∈ ( R d ) ⊗ k and B ∈ ( R d ) ⊗ l be respectively a k -tensor and an l -tensor . The ( i 1 , . . . , i k ) -th entry of A is denoted by A i 1 ,...,i k with i 1 , . . . , i k ∈ [ d ] . Moreo ver , when k ≥ l , the tensor action A ( B ) is defined as A ( B ) i 1 ,...,i k − l : = X j 1 ,...,j l A i 1 ,...,i k − l ,j 1 ,...,j l B j 1 ,...,j l and is thus a k − l -tensor . W e also r emind the following usual definitions. Definition A.5. F or a vector v ∈ R d , v ⊗ k is a k -tensor with ( i 1 , . . . , i k ) -th entry v i 1 · · · v i k . Definition A.6. F or differ entiable function f : R d → R , ∇ k f ( x ) is a k -tensor with ( i 1 , . . . , i k ) -th entry ∂ ∂ x i 1 · · · ∂ ∂ x i k f ( x ) . Definition A.7. F or a matrix M ∈ R d × r , we define the action M ⊗ k on a k -tensor A ∈ ( R r ) ⊗ k as M ⊗ k A ∈ ( R d ) ⊗ k with ( i 1 , . . . , i k ) -th entry X j 1 ,...,j k ∈ [ r ] M i 1 ,j 1 · · · M i k ,j k A j 1 ,...,j k . Lemma A.8. F or a sufficiently smooth function σ ∗ : R r → R and B ∈ R d × r , ∇ k x σ ∗ ( B ⊤ x ) = B ⊗ k ∇ k z σ ∗ ( B ⊤ x ) . Pr oof. Let x ∈ R d , and set z = B ⊤ x ∈ R r . Then, z j = d X i =1 B ij x i . 14 Dataset Distillation Efficiently Encodes Lo w-Dimensional Representations A P R E P RI NT By the chain rule, ∂ ∂ x i = r X j =1 ∂ z j ∂ x i ∂ ∂ z j = r X j =1 B ij ∂ ∂ z j . As a result, ∂ k σ ∗ ( B ⊤ x ) ∂ x i 1 · · · ∂ x i k = r X j 1 =1 B i 1 j 1 ∂ ∂ z j 1 · · · r X j k =1 B i k j k ∂ ∂ z j k σ ∗ ( z ) = r X j 1 ,...,j k =1 k Y l =1 B i l j l ! ∂ k σ ∗ ( z ) ∂ z j 1 · · · ∂ z j k . Lemma A.9. F or an orthogonal matrix B ∈ R d × r with B ⊤ B = I r and a T ∈ ( R r ) ⊗ k , ∥ B ⊗ k T ∥ F = ∥ T ∥ F . Pr oof. By definition of the Frobenius norm, ∥ B ⊗ k T ∥ 2 F = B ⊗ k T ( B ⊗ k T ) = T (( B ⊤ ) ⊗ k B ⊗ k T ) = T (( B ⊤ B ) ⊗ k T ) = T ( T ) = ∥ T ∥ F . W e also define the symmetrization as follows. Definition A.10. F or a k -tensor T , its symmetrization Sym( T ) is defined as (Sym( T )) i 1 ,...,i k : = 1 k ! X π ∈P k T i π (1) ,...,i π ( k ) , wher e π is a permutation and P k is the symmetric gr oup on 1 , . . . , k . Lemma A.11. F or any tensor T , ∥ Sym( T ) ∥ F ≤ ∥ T ∥ F . Pr oof. Please refer to Lemma 1 of Damian et al. ( 2023 ). Definition A.12. A k -tensor T is symmetric if for any permutation π ∈ P k , T i 1 ,...,i k = T i π (1) ,...,i π ( k ) . Lemma A.13. v ⊗ k is a symmetric k -tensor . If f is sufficiently smooth, then ∇ k f ( x ) is also a symmetric k -tensor . Lemma A.14. If C is a symmetric k -tensor and B an l -tensor so that l ≤ k , then C ( B ) = C (Sym( B )) . Pr oof. By definition, C (Sym( B )) i 1 ,...,i k − l = X j 1 ,...,j l C i 1 ,...,i k − l ,j 1 ,...,j l Sym( B ) j 1 ,...,j l = X j 1 ,...,j l C i 1 ,...,i k − l ,j 1 ,...,j l 1 l ! X π ∈P l B j π (1) ,...,j π ( l ) = 1 l ! X π ∈P l X j 1 ,...,j l C i 1 ,...,i k − l ,j 1 ,...,j l B j π (1) ,...,j π ( l ) . Since the permutation π is a bijective operation, the change of v ariable j ′ 1 = j π (1) , . . . , j ′ l = j π ( l ) leads to C (Sym( B )) i 1 ,...,i k − l = 1 l ! X π ∈P l X j 1 ,...,j l C i 1 ,...,i k − l ,j 1 ,...,j l B j π (1) ,...,j π ( l ) = 1 l ! X π ∈P l X j ′ 1 ,...,j ′ l C i 1 ,...,i k − l ,j ′ π − 1 (1) ,...,j ′ π − 1 ( l ) B j ′ 1 ,...,j ′ l = 1 l ! X π ∈P l X j ′ 1 ,...,j ′ l C i 1 ,...,i k − l ,j ′ 1 ,...,j ′ l B j ′ 1 ,...,j ′ l = 1 l ! X π ∈P l C ( B ) i 1 ,...,i k − l = 1 l ! l ! C ( B ) i 1 ,...,i k − l = C ( B ) i 1 ,...,i k − l , where we used the symmetry of C in the third equality . 15 Dataset Distillation Efficiently Encodes Lo w-Dimensional Representations A P R E P RI NT A.3 Hermite Polynomials Based on the abov e notation, we introduce Hermite Polynomials and Hermite expansion. These will be briefly used to explain a fe w properties. Definition A.15. The k -th Hermite polynomial He k is a k -tensor in ( R d ) ⊗ k defined as He k ( x ) : = ( − 1) k ∇ k µ ( x ) µ ( x ) , wher e µ ( x ) = 1 (2 π ) d/ 2 e −∥ x ∥ 2 / 2 . Definition A.16. The Hermite expansion of a function f : R d → R with E x ∼ N (0 ,I d ) [ f ( x ) 2 ] < ∞ is defined as f = X k ≥ 0 1 k ! ⟨ He k ( x ) , T k ⟩ , wher e T k is a symmetric k -tensor such that T k = E x ∼ N (0 ,I d ) [ ∇ k x f ( x ) 2 ] . For e xample, the Hermite expansion of σ ( x ) = max { 0 , x } is σ ( x ) = 1 √ 2 π + 1 2 x + 1 √ 2 π X k ≥ 1 ( − 1) k − 1 k !2 k (2 k − 1) He 2 k ( x ) = : X k ≥ 0 c k k ! He k ( x ) , where 0 = c 3 = c 5 = . . . . For its deri vati ve, we obtain σ ′ ( x ) = 1 2 + 1 √ 2 π X k ≥ 0 ( − 1) k k !2 k (2 k + 1) He 2 k +1 ( x ) = X k ≥ 0 c k +1 k ! He k ( x ) . B Proof of Main Theor ems: Single Index Models In this appendix, we prove our result for the single index setting where we define f ∗ ( x ) as σ ∗ ( ⟨ β , x ⟩ ) , notably showing that M 1 = 1 can be enough. Please refer to Appendix D for the general multi-index case. Some statements will be prov ed in the multi-index setting so that the y can be used later in Section D , while others correspond to the concrete case r = 1 of theorems, lemmas, or corollaries presented in that later section. Their proofs are nevertheless included here, as single-index models are extensi vely studied as an independent topic within the broader framework of machine learning ( Dhifallah and Lu , 2020 ; Gerace et al. , 2020 ; Ba et al. , 2022 ; Oko et al. , 2024a ; Nishika wa et al. , 2025 ). The proof is constructed follo wing each step of Algorithm 1 to keep as much clarity as possible. That is, we analyze Algorithm 1 phase by phase, using the result of each phase to study the next. Our goal is to 1) explicitly formulate the result of each distillation process (at t = 1 and t = 2 ) and 2) ev aluate the required size of created synthetic datasets D S 1 and D S 2 so that retraining f θ with the former in the first phase and with the latter in the second phase leads to a parameter ˜ θ ∗ whose generalization performance preserves that of the baseline trained on the large dataset D T r across both phases. As ReLU is in variant to scaling, we can consider without loss of generality that all the weights are normalized ∥ w i ∥ = 1 and w i ∼ U ( S d − 1 ) . W e use abbreviations like L T r ( · ) and L S ( · ) when the data we use to ev aluate the loss for a gi ven parameter is clear . B.1 t = 1 T eacher T raining The corresponding equation in Algorithm 1 is I T r j = { θ (1) j , G (1) j } = A T r 1 ( θ (0) j , D T r , ξ T r 1 , η T r 1 , λ T r 1 ) . From Assumption 3.6 , this is equiv alent to W (1) j = W (0) j − η T r 1 n ∇ W L T r ( θ (1) j ) + λ T r 1 W (1) j o , 16 Dataset Distillation Efficiently Encodes Lo w-Dimensional Representations A P R E P RI NT where η T r 1 = ˜ Θ( √ d ) and λ T r 1 = η T r 1 − 1 . The teacher gradient for the j -th initialization of weight w i can be defined as g T r i,j : = ( G (1) j ) i = ∇ w i L T r ( θ (0) j ) . ∇ w i L T r ( θ (0) j ) can be concretely computed with the following lemma. W e denote w (0) i,j as the j -th realization of the initialization of the i -th weight w i . Definition B.1. W e define ˆ f ∗ ( x ) as f ∗ ( x ) − α − ⟨ γ , x ⟩ . Lemma B.2. Given a training data D = { ( x n , y n ) } N n =1 , the gradient of the training loss with r espect to the weight w i is ∇ w i L ( θ , D ) = 1 N X n ( f θ ( x n ) − y n ) ∇ w i f θ ( x n ) = 1 N X n ( f θ ( x n ) − y n ) a i x n σ ′ ( ⟨ w i , x n ⟩ ) . Pr oof. This follows directly from the definition of the loss and neural network. Corollary B.3. F or our training data, due to pr epr ocessing and noise, ∇ w i L T r ( θ ) = 1 N X n f θ ( x n ) − ˆ f ∗ ( x n ) − ϵ n ∇ w i f θ ( x n ) = 1 N X n f θ ( x n ) − ˆ f ∗ ( x n ) − ϵ n a i x n σ ′ ( ⟨ w i , x n ⟩ ) . B.2 t = 1 Student T raining The corresponding equation in Algorithm 1 is I S j = { ˜ θ (1) j , ˜ G (1) j } = A S 1 ( θ (0) j , L S ( θ (0) j ) , ξ S 1 , η S 1 , λ S 1 ) . From Assumption 3.6 , this is equiv alent to ˜ W (1) j = W (0) j − η S 1 n ∇ W L ( θ (0) j , D S 1 ) + λ S 1 W (0) j o , where λ S 1 = η S 1 − 1 . The teacher gradient for the j -th initialization of weight w i can be defined as g S i,j : = ( ˜ G (1) j ) i = ∇ w i L S ( θ (0) j ) . B.3 t = 1 Distillation B.3.1 Problem F ormulation and Result For the distillation, we consider one-step gradient matching. As mentioned in the main paper , it is difficult to consider performance matching since we do not hav e access to the final result of each training yet. Then, D S 1 ← M 1 ( D S 0 , D T r , { I T r j , I S j } , ξ D 1 , η D 1 , λ D 1 ) becomes D S 1 = D S 0 − η D 1 1 J X j ∇ D S 1 − 1 L L X i =1 ⟨ g S i,j , g T r i,j ⟩ ! + λ D 1 D S 0 , (1) where we set λ D 1 = ( η D 1 ) − 1 . When D 0 = { ( ˜ x (0) , ˜ y (0) ) } , we can show that ˜ x (1) aligns to β , i.e., the principal subspace S ∗ of the problem: Theorem B.4. Under Assumptions 3.1 , 3.3 , 3.4 , 3.6 , and 3.8 , when D 0 = { ( ˜ x (0) , ˜ y (0) ) } , wher e ˜ x (0) ∼ U ( S d − 1 ) , the first step of distillation gives ˜ x (1) such that with high pr obability , ˜ x (1) = − η D 1 ˜ y (0) c d ⟨ β , ˜ x ⟩ β + ˜ O d 1 2 N − 1 2 + d − 2 + d 1 2 J ∗ − 1 2 , wher e c d = ˜ Θ d − 1 , J ∗ = LJ / 2 . W e prov e this theorem step by step from the next section (from Section B.3.2 to B.3.4 ) . 17 Dataset Distillation Efficiently Encodes Lo w-Dimensional Representations A P R E P RI NT B.3.2 Formulation of distilled data point In our setting of gradient matching, the right hand side of Equation ( 1 ) can be simplified to ˜ x (1) = − η D 1 J X j ∇ D S 1 − 1 L X i ⟨ g S i,j , g T r i,j ⟩ ! , (2) which can be written further as follows: Lemma B.5. Under Assumptions 3.1 , 3.3 , 3.4 , 3.6 , 3.7 and 3.8 , ˜ x (1) = − η D 1 ˜ y (0) ( G + ϵ ) , wher e G = 1 LJ X i,j g i,j h ′ ( ⟨ w (0) i,j , ˜ x (0) ⟩ ) + 1 LJ X i,j w (0) i,j h ′′ ( ⟨ w (0) i,j , ˜ x (0) ⟩ ) D g i,j , ˜ x (0) E ϵ = 1 LJ X i,j ( 1 N X n ϵ n x n σ ′ ( ⟨ w (0) i,j , x n ⟩ ) ) h ′ ( ⟨ w (0) i,j , ˜ x (0) ⟩ ) + 1 LJ X i,j w (0) i,j h ′′ ( ⟨ w (0) i,j , ˜ x (0) ⟩ ) * 1 N X n ϵ n x n σ ′ ( ⟨ w (0) i,j , x n ⟩ ) , ˜ x (0) + , with g i,j = 1 N P n ˆ f ∗ ( x n ) x n σ ′ ( ⟨ w (0) i,j , x n ⟩ ) . Pr oof. From Equation ( 2 ), ˜ x (1) = − η D 1 J X j ∇ ˜ x (0) 1 − 1 L L X i =1 ⟨ g S i,j , g T r i,j ⟩ ! = η D 1 LJ X i,j ∇ ˜ x (0) g S i,j , g T r i,j = η D 1 LJ X i,j ∇ ⊤ ˜ x (0) n f θ (0) j ( ˜ x (0) ) − ˜ y (0) ∇ w i f θ (0) j ( ˜ x (0) ) o 1 N X n f θ (0) j ( x n ) − ˆ f ∗ ( x n ) − ϵ n ∇ w i f θ (0) j ( x n ) = η D 1 LJ X i,j n ∇ ⊤ ˜ x (0) f θ (0) j ( ˜ x (0) ) ∇ w i f θ (0) j ( ˜ x (0) ) + ˜ y (0) ∇ ⊤ ˜ x (0) ∇ w i f θ (0) j ( ˜ x (0) ) o 1 N X n ˆ f ∗ ( x n ) + ϵ n ∇ w i f θ (0) j ( x n ) = η D 1 LJ X i,j ˜ y (0) ∇ ⊤ ˜ x (0) a (0) i ˜ x (0) h ′ ( ⟨ w (0) i,j , ˜ x (0) ⟩ ) 1 N X n ˆ f ∗ ( x n ) + ϵ n a (0) i x n σ ′ ( ⟨ w (0) i,j , x n ⟩ ) + η D 1 LJ X i,j ( a (0) i ) 2 ∇ ⊤ ˜ x (0) h ( ⟨ w (0) i,j , ˜ x (0) ⟩ ) ∇ w i h ( ⟨ w (0) i,j , ˜ x (0) ⟩ ) 1 N X n ˆ f ∗ ( x n ) + ϵ n a (0) i x n σ ′ ( ⟨ w (0) i,j , x n ⟩ ) = η D 1 ˜ y (0) LJ X i,j ( h ′ ( ⟨ w (0) i,j , ˜ x (0) ⟩ ) I + ˜ x (0) w (0) ⊤ i,j h ′′ ( ⟨ w (0) i,j , ˜ x (0) ⟩ )) ( 1 N X n ˆ f ∗ ( x n ) + ϵ n a (0) i x n σ ′ ( ⟨ w (0) i,j , x n ⟩ ) ) + 0 = η D 1 ˜ y (0) LJ X i,j g i,j h ′ ( ⟨ w (0) i,j , ˜ x (0) ⟩ ) + η D 1 ˜ y (0) LJ X i,j w (0) i,j h ′′ ( ⟨ w (0) i,j , ˜ x (0) ⟩ ) D g i,j , ˜ x (0) E + η D 1 ˜ y (0) LJ X i,j ( 1 N X n ϵ n x n σ ′ ( ⟨ w (0) i,j , x n ⟩ ) ) h ′ ( ⟨ w (0) i,j , ˜ x (0) ⟩ ) + η D 1 ˜ y (0) LJ X i,j w (0) i,j h ′′ ( ⟨ w (0) i,j , ˜ x (0) ⟩ ) * 1 N X n ϵ n x n σ ′ ( ⟨ w (0) i,j , x n ⟩ ) , ˜ x (0) + , 18 Dataset Distillation Efficiently Encodes Lo w-Dimensional Representations A P R E P RI NT where we defined g i,j : = 1 N P n ˆ f ∗ ( x n ) x n σ ′ ( ⟨ w (0) i,j , x n ⟩ ) at the last equality , used Lemma B.2 and Corollary B.3 for the third equality , the symmetric initialization such that f θ (0) j ( x ) = 0 ∀ x in the fourth equality , and a (0) i 2 = 1 for the last equality . Note that by symmetry of a (0) i and w (0) i , the second term of the fifth equality is equiv alent to 0. Remark B.6. As mentioned in the main paper , the update of ˜ x is not well-defined for ReLU activation function in the case of gradient matching, and any other type of DD that include gradient information of ˜ x in the distillation loss. W e believe this is a fundamental pr oblem that will be unavoidable in futur e theor etical work as well. Ther efor e, we have to substitute ReLU that comes fr om student gradients with an appr oximation h whose second derivative is well-defined. Actually , in this paper , we show a somewhat str onger r esult. That is, for any h whose second derivative is well defined, h ′ and h ′′ ar e bounded, and h ′ ( t ) > h ′ ( − t ) for all t ∈ (0 , 1) , suc h as most continuous surr ogates of ReLU such as softplus, DD (Algorithm 1 ) will output a set of synthetic points with mainly the same compr ession efficiency and generalization ability . Mor eover , in Appendix C , we will tr eat a well-defined update for ReLU , which will also lead to similar r esult shown in this appendix. From this lemma, we can drastically simplify the notation as follows: Corollary B.7. ˜ x (1) can be r e gar ded as taking J ∗ = LJ / 2 dr aws w j ∼ U ( S d − 1 ) ( j = 1 , . . . , J ∗ ) , and written as ˜ x (1) = − η D 1 ˜ y (0) ( G + ϵ ) , wher e G = 1 J ∗ J ∗ X j =1 g j h ′ ( ⟨ w j , ˜ x (0) ⟩ ) + 1 J ∗ J ∗ X j =1 h ′′ ( ⟨ w j , ˜ x (0) ⟩ ) D g j , ˜ x (0) E ϵ = 1 J ∗ J ∗ X j =1 ( 1 N X n ϵ n x n σ ′ ( ⟨ w j , x n ⟩ ) ) h ′ ( ⟨ w j , ˜ x (0) ⟩ ) + 1 J ∗ J ∗ X j =1 w j h ′′ ( ⟨ w j , ˜ x (0) ⟩ ) * 1 N X n ϵ n x n σ ′ ( ⟨ w j , x n ⟩ ) , ˜ x (0) + , with g j = 1 N P n ˆ f ∗ ( x n ) x n σ ′ ( ⟨ w j , x n ⟩ ) . Pr oof. This follows from the symmetric assumption of w i,j = w L − i,j (Assumption 3.4 ). Remark B.8. Note that we will only use this corollary to keep notation clean. W e will never use this to blindly oversimplify our conclusion. B.3.3 Formulation of P opulation Gradient In this section, we will focus on the population version of the empirical gradient G deri ved in Corollary B.7 and analyze its properties. It can be written as follows: Definition B.9. W e define the population gradient of G as ˆ G : = E w h E x h ˆ f ∗ ( x ) xσ ′ ( ⟨ w , x ⟩ ) i h ′ ( ⟨ w , ˜ x ⟩ ) i + E w h w h ′′ ( ⟨ w , ˜ x ⟩ ) D E x h ˆ f ∗ ( x ) xσ ′ ( ⟨ w , x ⟩ ) i , ˜ x Ei , wher e ˜ x : = ˜ x (0) . Let us first remind some properties from Damian et al. ( 2022 ). Definition B.10. W e define the Hermite expansion of ˆ f ∗ as ˆ f ∗ ( x ) = p X k =0 ⟨ ˆ C k , He k ( x ) ⟩ k ! , wher e ˆ C k is a symmetric k -tensor defined as ˆ C k : = E x ∼N (0 ,I d ) [ ∇ k x ˆ f ∗ ( x )] ∈ ( R d ) ⊗ k , and likewise , f ∗ ( x ) = p X k =0 ⟨ ¯ C k , He k ( x ) ⟩ k ! , and σ ∗ ( z ) = p X k =0 C k k ! He k ( z ) , wher e ¯ C k : = E x ∼N (0 ,I d ) [ ∇ k x f ∗ ( x )] ∈ ( R d ) ⊗ k and C k : = E z ∼N (0 ,I r ) [ ∇ k z σ ∗ ( x )] ∈ ( R r ) ⊗ k . 19 Dataset Distillation Efficiently Encodes Lo w-Dimensional Representations A P R E P RI NT The following relation holds between ˆ C k , ¯ C k and C k . Lemma B.11. Under Assumption 3.1 , ˆ C k = ¯ C k = B ⊗ k C k for k ≥ 2 , ˆ C 0 = ¯ C 0 − α and ˆ C 1 = ¯ C 1 − γ . Pr oof. Clearly ˆ C k = ¯ C k for k ≥ 2 , ˆ C 0 = ¯ C 0 − α and ˆ C 1 = ¯ C 1 − γ (see Definition B.1 ). No w , between ¯ C k and C k , f ∗ ( x ) = σ ∗ ( B ⊤ x ) implies that ∇ k x f ( x ) = ∇ k x σ ∗ ( B ⊤ x ) = B ⊗ k ∇ k z σ ∗ ( B ⊤ x ) , where we used Lemma A.14 . T aking the expectation ov er x ∼ N (0 , I d ) and since B ⊤ B = I r , E x [ ∇ k x f ( x )] = B ⊗ k E x [ ∇ k z σ ∗ ( B ⊤ x )] = B ⊗ k E z [ ∇ k z σ ∗ ( z )] = B ⊗ k C k , where we used that z ∼ N (0 , B ⊤ B ) = N (0 , I r ) . This leads to the following lemma. Lemma B.12. F or the ˆ C k defined as above and k ≥ 2 , under Assumption 3.1 , ∥ ˆ C k ∥ 2 F ≤ k ! , and ∥ C k ∥ 2 F ≤ k ! Pr oof. From Lemma 9 from Damian et al. ( 2022 ), ∥ ¯ C k ∥ 2 ≤ k ! . Therefore, ∥ C k ∥ 2 F = ∥ B ⊗ k C k ∥ 2 F = ∥ ˆ C k ∥ 2 F = ∥ ¯ C k ∥ 2 F ≤ k ! , where we used Lemma A.9 for the first equality and Lemma B.11 for the second and third equalities. Note that under Assumption 3.1 , we also hav e C k x ⊗ k = C k (Π ∗ x ) ⊗ k . Especially for ˆ C 0 and ˆ C 1 , we know the follo wing results: Lemma B.13 (Lemma 10 from Damian et al. ( 2022 )) . Under Definition B.10 and Assumption 3.1 , with high pr obability | ˆ C 0 | = ˜ O 1 √ N , and ∥ ˆ C 1 ∥ = ˜ O r d N ! . Now we can compute the population gradient of E x h ˆ f ∗ ( x ) xσ ′ ( ⟨ w , x ⟩ ) i in closed form. Lemma B.14. Under Assumptions 3.1 , with high pr obability , E x h ˆ f ∗ ( x ) xσ ′ ( ⟨ w , x ⟩ ) i = p − 1 X k =1 c k +1 ˆ C k +1 ( w ⊗ k ) k ! + w p X k =2 c k +2 ˆ C k ( w ⊗ k ) k ! + ˜ O r d N ! . Pr oof. The following equality immediately follo ws from the proof of Lemma 13 of Damian et al. ( 2022 ): E x h ˆ f ∗ ( x ) xσ ′ ( ⟨ w , x ⟩ ) i = C 1 2 + w C 0 √ 2 π + p − 1 X k =1 c k +1 ˆ C k +1 ( w ⊗ k ) k ! + w p X k =2 c k +2 ˆ C k ( w ⊗ k ) k ! , which leads to the statement by Lemma B.13 , Corollary B.15. F or single index models, with high pr obability , ˆ G = β p − 1 X k =1 c k +1 C k +1 k ! E w [ ⟨ β , w ⟩ k h ′ ( ⟨ w , ˜ x ⟩ )] + p X k =2 c k +2 C k k ! E w [ w ⟨ β , w ⟩ k h ′ ( ⟨ w , ˜ x ⟩ )] + p − 1 X k =1 c k +1 C k +1 k ! ⟨ β , ˜ x ⟩ E w [ w ⟨ β , w ⟩ k h ′′ ( ⟨ w , ˜ x ⟩ )] + p X k =2 c k +2 C k k ! E w [ w ⟨ w, ˜ x ⟩⟨ β , w ⟩ k h ′′ ( ⟨ w , ˜ x ⟩ )] + ˜ O r d N ! . 20 Dataset Distillation Efficiently Encodes Lo w-Dimensional Representations A P R E P RI NT Pr oof. By combining Lemma B.11 and Lemma B.14 , we obtain E x h ˆ f ∗ ( x ) xσ ′ ( ⟨ w , x ⟩ ) i = β p − 1 X k =1 c k +1 C k +1 ⟨ β , w ⟩ k k ! + w p X k =2 c k +2 C k ⟨ β , w ⟩ k k ! + ˜ O r d N ! . It suffices to substitute this to the definition of ˆ G (Definition B.9 ) to obtain the desired result. Let us now estimate each e xpectation present in the formulation of ˆ G as sho wn in the abov e corollary . Lemma B.16. When the activation function is a C 2 class function h with sup | z |≤ 1 | h ′ ( z ) | ≤ M 1 and sup | z |≤ 1 | h ′′ ( z ) | ≤ M 2 , and ∥ β ∥ = 1 , ∥ ˜ x ∥ = 1 , then for k ≥ 0 , E w [ w ⟨ β , w ⟩ k h ′ ( ⟨ w , ˜ x ⟩ )] = A k ( d ) ˜ x + B k ( d ) β ⊥ , E w [ ⟨ β , w ⟩ k h ′ ( ⟨ w , ˜ x ⟩ )] = D k ( d ) , E w [ w ⟨ β , w ⟩ k h ′′ ( ⟨ w , ˜ x ⟩ )] = E k ( d ) ˜ x + F k ( d ) β ⊥ , E w [ w ⟨ w, ˜ x ⟩⟨ β , w ⟩ k h ′′ ( ⟨ w , ˜ x ⟩ )] = G k ( d ) ˜ x + H k ( d ) β ⊥ , wher e β ⊥ = β − ⟨ β , ˜ x ⟩ ˜ x , A k ( d ) = O ( M 1 d − k +1 2 ) , B k ( d ) = O ( M 1 d − k +1 2 ) , D k ( d ) = O ( M 1 d − k 2 ) , E k ( d ) = O ( M 2 d − k +1 2 ) , F k ( d ) = O ( M 2 d − k +1 2 ) , G k ( d ) = O ( M 2 d − k +2 2 ) , and H k ( d ) = O ( M 2 d − k +2 2 ) . Pr oof. Let us first prove the first equality . Let t = ⟨ w , ˜ x ⟩ , then we can write w = t ˜ x + √ 1 − t 2 v where v ∼ U ( { v | v ∈ S d − 1 , ⟨ v , ˜ x ⟩ = 0 } ) ∼ = U ( S d − 2 ) . Since ∥ ˜ x ∥ 2 = 1 , the distrib ution of t is equi valent to that of the first coordinate w 1 which is f d ( t ) = Γ( d 2 ) √ π Γ( d − 1 2 ) (1 − t 2 ) d − 3 2 . Moreov er , ⟨ β , w ⟩ = st + p 1 − t 2 ⟨ β ⊥ , v ⟩ , where s = ⟨ β , ˜ x ⟩ , and β ⊥ = β − ⟨ β , ˜ x ⟩ ˜ x . Now , E w [ w ⟨ β , w ⟩ k h ′ ( ⟨ w , ˜ x ⟩ )] = E t,v t ˜ x + p 1 − t 2 v st + ∥ β ⊥ ∥ p 1 − t 2 ⟨ β ⊥ / ∥ β ⊥ ∥ , v ⟩ k h ′ ( t ) = Γ( d 2 ) √ π Γ( d − 1 2 ) Z 1 − 1 h ′ ( t )(1 − t 2 ) d − 3 2 E v t ˜ x + p 1 − t 2 v st + ∥ β ⊥ ∥ p 1 − t 2 ⟨ β ⊥ / ∥ β ⊥ ∥ , v ⟩ k d t. Since st + ∥ β ⊥ ∥ p 1 − t 2 ⟨ β ⊥ / ∥ β ⊥ ∥ , v ⟩ k = k X i =0 k i ( st ) k − i ( ∥ β ⊥ ∥ p 1 − t 2 ) i ⟨ β ⊥ / ∥ β ⊥ ∥ , v ⟩ i , we can further dev elop the expectation as follo ws: E w [ w ⟨ β , w ⟩ k h ′ ( ⟨ w , ˜ x ⟩ )] = Γ( d 2 ) √ π Γ( d − 1 2 ) Z 1 − 1 h ′ ( t )(1 − t 2 ) d − 3 2 E v t ˜ x + p 1 − t 2 v st + ∥ β ⊥ ∥ p 1 − t 2 ⟨ β ⊥ / ∥ β ⊥ ∥ , v ⟩ k d t = Γ( d 2 ) √ π Γ( d − 1 2 ) Z 1 − 1 h ′ ( t )(1 − t 2 ) d − 3 2 ( t k X i =0 k i ( st ) k − i ( ∥ β ⊥ ∥ p 1 − t 2 ) i E v ⟨ β ⊥ / ∥ β ⊥ ∥ , v ⟩ i ˜ x + p 1 − t 2 k X i =0 k i ( st ) k − i ( ∥ β ⊥ ∥ p 1 − t 2 ) i E v ⟨ β ⊥ / ∥ β ⊥ ∥ , v ⟩ i v ) d t. By rotation symmetry , E v ⟨ β ⊥ / ∥ β ⊥ ∥ , v ⟩ i = E z ∼ U ( S d − 2 ) [ z i 1 ] = c i 2 ( d ) if i is even and 0 if i is odd. Likewise, E v ⟨ β ⊥ / ∥ β ⊥ ∥ , v ⟩ i v = E z ∼ U ( S d − 2 ) [ z i +1 1 ] β ⊥ / ∥ β ⊥ ∥ = c i +1 2 ( d ) β ⊥ / ∥ β ⊥ ∥ if i is odd and 0 if i is ev en. Here, we used the definition of c k ( d ) defined in Lemma B.24 . 21 Dataset Distillation Efficiently Encodes Lo w-Dimensional Representations A P R E P RI NT Therefore, E w [ w ⟨ β , w ⟩ k h ′ ( ⟨ w , ˜ x ⟩ )] = Γ( d 2 ) √ π Γ( d − 1 2 ) Z 1 − 1 h ′ ( t )(1 − t 2 ) d − 3 2 t ⌊ k 2 ⌋ X i =0 k 2 i ( st ) k − 2 i ( ∥ β ⊥ ∥ p 1 − t 2 ) 2 i c i ( d ) ˜ x + p 1 − t 2 ⌊ k − 1 2 ⌋ X i =0 k 2 i + 1 ( st ) k − (2 i +1) ( ∥ β ⊥ ∥ p 1 − t 2 ) 2 i +1 c i +1 ( d ) β ⊥ / ∥ β ⊥ ∥ d t = Γ( d 2 ) √ π Γ( d − 1 2 ) ⌊ k 2 ⌋ X i =0 k 2 i s k − 2 i ∥ β ⊥ ∥ 2 i c i ( d ) Z 1 − 1 h ′ ( t )(1 − t 2 ) d − 3 2 + i t k − 2 i +1 d t · ˜ x + Γ( d 2 ) √ π Γ( d − 1 2 ) ⌊ k − 1 2 ⌋ X i =0 k 2 i + 1 s k − (2 i +1) ∥ β ⊥ ∥ 2 i c i +1 ( d ) Z 1 − 1 h ′ ( t )(1 − t 2 ) d − 3 2 + i +1 t k − (2 i +1) d t · β ⊥ = A k ( d ) ˜ x + B k ( d ) β ⊥ , where we defined A k ( d ) : = Γ( d 2 ) √ π Γ( d − 1 2 ) ⌊ k 2 ⌋ X i =0 k 2 i s k − 2 i ∥ β ⊥ ∥ 2 i c i ( d ) Z 1 − 1 h ′ ( t )(1 − t 2 ) d − 3 2 + i t k − 2 i +1 d t, and B k ( d ) : = Γ( d 2 ) √ π Γ( d − 1 2 ) ⌊ k − 1 2 ⌋ X i =0 k 2 i + 1 s k − (2 i +1) ∥ β ⊥ ∥ 2 i c i +1 ( d ) Z 1 − 1 h ′ ( t )(1 − t 2 ) d − 3 2 + i +1 t k − (2 i +1) d t. Using Lemma B.23 , we obtain | A k ( d ) | ≤ Γ( d 2 ) √ π Γ( d − 1 2 ) ⌊ k 2 ⌋ X i =0 k 2 i s k − 2 i ∥ β ⊥ ∥ 2 i c i ( d ) Z 1 − 1 h ′ ( t )(1 − t 2 ) d − 3 2 + i t k − 2 i +1 d t ≤ Γ( d 2 ) √ π Γ( d − 1 2 ) ⌊ k 2 ⌋ X i =0 k 2 i | s | k − 2 i ∥ β ⊥ ∥ 2 i c i ( d ) Z 1 − 1 h ′ ( t )(1 − t 2 ) d − 3 2 + i t k − 2 i +1 d t ≤ 2 M 1 Γ( d 2 ) √ π Γ( d − 1 2 ) ⌊ k 2 ⌋ X i =0 k 2 i | s | k − 2 i ∥ β ⊥ ∥ 2 i c i ( d ) Z 1 0 (1 − t 2 ) d − 3 2 + i t k − 2 i +1 d t =2 M 1 Γ( d 2 ) √ π Γ( d − 1 2 ) ⌊ k 2 ⌋ X i =0 k 2 i | s | k − 2 i ∥ β ⊥ ∥ 2 i c i ( d ) 1 2 Beta k − 2 i + 2 2 , d − 3 2 + i + 1 ≲ M 1 Γ( d 2 ) Γ( d − 1 2 ) ⌊ k 2 ⌋ X i =0 c i ( d )Beta k − 2 i + 2 2 , d − 3 2 + i + 1 ≲ M 1 d 1 / 2 ⌊ k 2 ⌋ X i =0 d − i d − 3 2 + i + 1 − k − 2 i +2 2 ≲ M 1 d 1 / 2 ⌊ k 2 ⌋ X i =0 d − i d − k +2 2 + i ≲ M 1 d − k +1 2 , 22 Dataset Distillation Efficiently Encodes Lo w-Dimensional Representations A P R E P RI NT where we used the definition of the Beta function Beta( p 1 , p 2 ) : = Z 1 − 1 t p 1 − 1 (1 − t ) p 2 − 1 d t = 2 Z 1 0 t 2 p 1 − 1 (1 − t 2 ) p 2 − 1 d t, p 1 , p 2 > 0 , in the equality , and Stirling’ s approximation when the second argument p 2 is large in the fifth inequality . Like wise, for B k ( d ) , we obtain | B k ( d ) | ≤ 2 M 1 Γ( d 2 ) √ π Γ( d − 1 2 ) ⌊ k − 1 2 ⌋ X i =0 k 2 i + 1 | s | k − (2 i +1) ∥ β ⊥ ∥ 2 i c i +1 ( d ) Z 1 0 (1 − t 2 ) d − 3 2 + i +1 t k − (2 i +1) d t =2 M 1 Γ( d 2 ) √ π Γ( d − 1 2 ) ⌊ k − 1 2 ⌋ X i =0 k 2 i + 1 | s | k − (2 i +1) ∥ β ⊥ ∥ 2 i c i +1 ( d ) 1 2 Beta k − 2 i 2 , d − 3 2 + i + 2 ≲ M 1 Γ( d 2 ) Γ( d − 1 2 ) ⌊ k − 1 2 ⌋ X i =0 c i +1 ( d )Beta k − 2 i 2 , d − 3 2 + i + 2 ≲ M 1 d 1 2 ⌊ k − 1 2 ⌋ X i =0 d − ( i +1) d − 3 2 + i + 2 − k − 2 i 2 ≲ M 1 d 1 2 ⌊ k − 1 2 ⌋ X i =0 d − ( i +1) d − k 2 + i ≲ M 1 d − k +1 2 . W e can proof analogously for E w [ w ⟨ β , w ⟩ k h ′′ ( ⟨ w , ˜ x ⟩ )] and obtain E w [ w ⟨ β , w ⟩ k h ′′ ( ⟨ w , ˜ x ⟩ )] = E k ( d ) ˜ x + F k ( d ) β ⊥ such that E k ( d ) = O ( M 2 d − k +1 2 ) , and F k ( d ) = O ( M 2 d − k +1 2 ) . Next, we similarly prove the second equality of the statement. By the same change of variable, E w [ ⟨ β , w ⟩ k h ′ ( ⟨ w , ˜ x ⟩ )] = Γ( d 2 ) √ π Γ( d − 1 2 ) Z 1 − 1 h ′ ( t )(1 − t 2 ) d − 3 2 E v st + ∥ β ⊥ ∥ p 1 − t 2 ⟨ β ⊥ / ∥ β ⊥ ∥ , v ⟩ k d t = Γ( d 2 ) √ π Γ( d − 1 2 ) Z 1 − 1 h ′ ( t )(1 − t 2 ) d − 3 2 k X i =0 k i ( st ) k − i ( ∥ β ⊥ ∥ p 1 − t 2 ) i E v ⟨ β ⊥ / ∥ β ⊥ ∥ , v ⟩ i d t = Γ( d 2 ) √ π Γ( d − 1 2 ) Z 1 − 1 h ′ ( t )(1 − t 2 ) d − 3 2 ⌊ k 2 ⌋ X i =0 k 2 i ( st ) k − 2 i ( ∥ β ⊥ ∥ p 1 − t 2 ) 2 i c i ( d )d t = Γ( d 2 ) √ π Γ( d − 1 2 ) ⌊ k 2 ⌋ X i =0 k 2 i s k − 2 i ∥ β ⊥ ∥ 2 i c i ( d ) Z 1 − 1 h ′ ( t )(1 − t 2 ) d − 3 2 + i t k − 2 i d t ≤ Γ( d 2 ) √ π Γ( d − 1 2 ) ⌊ k 2 ⌋ X i =0 k 2 i s k − 2 i ∥ β ⊥ ∥ 2 i c i ( d ) Z 1 − 1 h ′ ( t )(1 − t 2 ) d − 3 2 + i t k − 2 i d t ≤ 2 M 1 Γ( d 2 ) √ π Γ( d − 1 2 ) ⌊ k 2 ⌋ X i =0 k 2 i | s | k − 2 i ∥ β ⊥ ∥ 2 i c i ( d ) Z 1 0 (1 − t 2 ) d − 3 2 + i t k − 2 i d t =2 M 1 Γ( d 2 ) √ π Γ( d − 1 2 ) ⌊ k 2 ⌋ X i =0 k 2 i | s | k − 2 i ∥ β ⊥ ∥ 2 i c i ( d ) 1 2 Beta k − 2 i + 1 2 , d − 3 2 + i + 1 . 23 Dataset Distillation Efficiently Encodes Lo w-Dimensional Representations A P R E P RI NT Therefore, D k ( d ) : = E w [ ⟨ β , w ⟩ k h ′ ( ⟨ w , ˜ x ⟩ )] ≲ M 1 Γ( d 2 ) Γ( d − 1 2 ) ⌊ k 2 ⌋ X i =0 c i ( d )Beta k − 2 i + 1 2 , d − 3 2 + i + 1 ≲ M 1 d − k 2 . Finally , let us focus on E w [ w ⟨ w, ˜ x ⟩⟨ β , w ⟩ k h ′′ ( ⟨ w , ˜ x ⟩ )] . Follo wing the same approach, we can reformulate this expectation as E w [ w ⟨ β , w ⟩ k ⟨ w , ˜ x ⟩ h ′′ ( ⟨ w , ˜ x ⟩ )] = E t,v t ˜ x + p 1 − t 2 v st + ∥ β ⊥ ∥ p 1 − t 2 ⟨ β ⊥ / ∥ β ⊥ ∥ , v ⟩ k th ′′ ( t ) = Γ( d 2 ) √ π Γ( d − 1 2 ) Z 1 − 1 th ′′ ( t )(1 − t 2 ) d − 3 2 E v t ˜ x + p 1 − t 2 v st + ∥ β ⊥ ∥ p 1 − t 2 ⟨ β ⊥ / ∥ β ⊥ ∥ , v ⟩ k d t = Γ( d 2 ) √ π Γ( d − 1 2 ) Z 1 − 1 th ′′ ( t )(1 − t 2 ) d − 3 2 ( t k X i =0 k i ( st ) k − i ( ∥ β ⊥ ∥ p 1 − t 2 ) i E v ⟨ β ⊥ / ∥ β ⊥ ∥ , v ⟩ i ˜ x + p 1 − t 2 k X i =0 k i ( st ) k − i ( ∥ β ⊥ ∥ p 1 − t 2 ) i E v ⟨ β ⊥ / ∥ β ⊥ ∥ , v ⟩ i v ) d t = Γ( d 2 ) √ π Γ( d − 1 2 ) ⌊ k 2 ⌋ X i =0 k 2 i s k − 2 i ∥ β ⊥ ∥ 2 i c i ( d ) Z 1 − 1 h ′′ ( t )(1 − t 2 ) d − 3 2 + i t k − 2 i +2 d t · ˜ x + Γ( d 2 ) √ π Γ( d − 1 2 ) ⌊ k − 1 2 ⌋ X i =0 k 2 i + 1 s k − (2 i +1) ∥ β ⊥ ∥ 2 i c i +1 ( d ) Z 1 − 1 h ′ ( t )(1 − t 2 ) d − 3 2 + i +1 t k − (2 i +1)+1 d tβ ⊥ = G k ( d ) ˜ x + H k ( d ) β ⊥ , where we defined G k ( d ) : = Γ( d 2 ) √ π Γ( d − 1 2 ) ⌊ k 2 ⌋ X i =0 k 2 i s k − 2 i ∥ β ⊥ ∥ 2 i c i ( d ) Z 1 − 1 h ′ ( t )(1 − t 2 ) d − 3 2 + i t k − 2 i +2 d t, and H k ( d ) : = Γ( d 2 ) √ π Γ( d − 1 2 ) ⌊ k − 1 2 ⌋ X i =0 k 2 i + 1 s k − (2 i +1) ∥ β ⊥ ∥ 2 i c i +1 ( d ) Z 1 − 1 h ′ ( t )(1 − t 2 ) d − 3 2 + i +1 t k − (2 i +1)+1 d t. 24 Dataset Distillation Efficiently Encodes Lo w-Dimensional Representations A P R E P RI NT Therefore, | G k ( d ) | ≤ Γ( d 2 ) √ π Γ( d − 1 2 ) ⌊ k 2 ⌋ X i =0 k 2 i | s | k − 2 i ∥ β ⊥ ∥ 2 i c i ( d ) Z 1 − 1 h ′ ( t )(1 − t 2 ) d − 3 2 + i t k − 2 i +2 d t ≤ 2 M 2 Γ( d 2 ) √ π Γ( d − 1 2 ) ⌊ k 2 ⌋ X i =0 k 2 i | s | k − 2 i ∥ β ⊥ ∥ 2 i c i ( d ) Z 1 0 (1 − t 2 ) d − 3 2 + i t k − 2 i +2 d t ≤ 2 M 2 Γ( d 2 ) √ π Γ( d − 1 2 ) ⌊ k 2 ⌋ X i =0 k 2 i | s | k − 2 i ∥ β ⊥ ∥ 2 i c i ( d ) 1 2 Beta k − 2 i + 3 2 , d − 3 2 + i + 1 ≲ M 2 Γ( d 2 ) Γ( d − 1 2 ) ⌊ k 2 ⌋ X i =0 c i ( d )Beta k − 2 i + 3 2 , d − 3 2 + i + 1 ≲ M 2 d 1 / 2 ⌊ k 2 ⌋ X i =0 d − i d − 3 2 + i + 1 − k − 2 i +3 2 ≲ M 2 d 1 / 2 ⌊ k 2 ⌋ X i =0 d − i d − k +3 2 + i ≲ M 2 d − k +2 2 , and | H k ( d ) | ≤ 2 M 2 Γ( d 2 ) √ π Γ( d − 1 2 ) ⌊ k − 1 2 ⌋ X i =0 k 2 i + 1 | s | k − (2 i +1) ∥ β ⊥ ∥ 2 i c i +1 ( d ) Z 1 0 (1 − t 2 ) d − 3 2 + i +1 t k − (2 i +1)+1 d t =2 M 2 Γ( d 2 ) √ π Γ( d − 1 2 ) ⌊ k − 1 2 ⌋ X i =0 k 2 i + 1 | s | k − (2 i +1) ∥ β ⊥ ∥ 2 i c i +1 ( d ) 1 2 Beta k − 2 i + 1 2 , d − 3 2 + i + 2 ≲ M 2 Γ( d 2 ) Γ( d − 1 2 ) ⌊ k − 1 2 ⌋ X i =0 c i +1 ( d )Beta k − 2 i + 1 2 , d − 3 2 + i + 2 ≲ M 2 d 1 2 ⌊ k − 1 2 ⌋ X i =0 d − ( i +1) d − 3 2 + i + 2 − k − 2 i +1 2 ≲ M 2 d 1 2 ⌊ k − 1 2 ⌋ X i =0 d − ( i +1) d − k +1 2 + i ≲ M 2 d − k +2 2 . W e provide tighter bounds for a fe w lower order terms. Corollary B.17. If ˜ x ∼ U ( S d − 1 ) and h ′ and h ′′ ar e non-zer o continuous in [ − 1 , 1] , then with high pr obability , D 1 ( d ) + D 3 ( d ) + A 2 ( d ) ˜ x + B 2 ( d ) β ⊥ + ⟨ β , ˜ x ⟩ ( E 1 ( d ) β + F 1 ( d ) β ⊥ ) = c d ⟨ β , ˜ x ⟩ β + ˜ O ( d − 2 ) , wher e c d = Θ( d − 1 ) . Pr oof. Please refer to Corollary D.7 , which proves the statement for the general multi-inde x case. Combining this with Corollary B.15 , we obtain the following result. 25 Dataset Distillation Efficiently Encodes Lo w-Dimensional Representations A P R E P RI NT Theorem B.18. Under Assumptions 3.1 , 3.3 , 3.4 , 3.6 , and 3.8 , with high pr obability , ˆ G = c d ⟨ β , ˜ x ⟩ β + ˜ O d 1 2 N − 1 2 + d − 2 , wher e c d = ˜ Θ d − 1 . Pr oof. ˆ G = β p − 1 X k =1 c k +1 C k +1 k ! E w [ ⟨ β , w ⟩ k h ′ ( ⟨ w , ˜ x ⟩ )] + p X k =2 c k +2 C k k ! E w [ w ⟨ β , w ⟩ k h ′ ( ⟨ w , ˜ x ⟩ )] + p − 1 X k =1 c k +1 C k +1 k ! ⟨ β , ˜ x ⟩ E w [ w ⟨ β , w ⟩ k h ′′ ( ⟨ w , ˜ x ⟩ )] + p X k =2 c k +2 C k k ! E w [ w ⟨ w, ˜ x ⟩⟨ β , w ⟩ k h ′′ ( ⟨ w , ˜ x ⟩ )] + ˜ O r d N ! = β p − 1 X k =1 c k +1 C k +1 k ! D k ( d ) + p X k =2 c k +2 C k k ! ( A k ( d ) ˜ x + B k ( d ) β ⊥ ) + p − 1 X k =1 c k +1 C k +1 k ! ⟨ β , ˜ x ⟩ ( E k ( d ) ˜ x + F k ( d ) β ⊥ ) + p X k =2 c k +2 C k k ! ( G k ( d ) ˜ x + H k ( d ) β ⊥ ) + ˜ O r d N ! = β c 2 C 2 1! D 1 ( d ) + β c 4 C 4 3! D 3 ( d ) + β p − 1 X k =4 c k +1 C k +1 k ! D k ( d ) + c 4 C 2 2! ( A 2 ( d ) ˜ x + B 2 ( d ) β ⊥ ) + p X k =3 c k +2 C k k ! ( A k ( d ) ˜ x + B k ( d ) β ⊥ ) + c 2 C 2 1! ⟨ β , ˜ x ⟩ ( E 1 ( d ) ˜ x + F 1 ( d ) β ⊥ ) + p − 1 X k =3 c k +1 C k +1 k ! ⟨ β , ˜ x ⟩ ( E k ( d ) ˜ x + F k ( d ) β ⊥ ) + p X k =2 c k +2 C k k ! ( G k ( d ) ˜ x + H k ( d ) β ⊥ ) + ˜ O r d N ! = c d ⟨ β , ˜ x ⟩ β + ˜ O d − 2 + ˜ O r d N ! , where we used Corollary B.17 for the last equality , where c d = ˜ Θ( d − 1 ) . B.3.4 Concentration of Empirical Gradient No w that we hav e computed the population gradient, we ev aluate the concentration of the empirical gradient around the population gradient. Theorem B.19. Under Assumptions 3.1 , 3.3 , 3.4 , 3.6 , 3.7 and 3.8 , with high probability , G = c d ⟨ β , ˜ x ⟩ β + ˜ O d − 1 2 N − 1 2 + d − 2 + d − 1 2 J ∗ − 1 2 . Pr oof. Since G = ˆ G + G − ˆ G ≤ ˆ G + sup ˜ x ∈ S d − 1 ∥ G − ˆ G ∥ , 26 Dataset Distillation Efficiently Encodes Lo w-Dimensional Representations A P R E P RI NT and the first term is already e valuated in Theorem B.18 , we will e valuate the second. From the form of G and ˆ G , we can divide it into the follo wing two terms: ∆ 1 : = sup ˜ x 1 J ∗ X j g j h ′ ( ⟨ w j , ˜ x ⟩ ) − E w h E x h ˆ f ∗ ( x ) xσ ′ ( ⟨ w , x ⟩ ) i h ′ ( ⟨ w , ˜ x ⟩ ) i , ∆ 2 : = sup ˜ x 1 J ∗ X j w j h ′′ ( ⟨ w j , ˜ x ⟩ ) ⟨ g j , ˜ x ⟩ − E w h w h ′′ ( ⟨ w , ˜ x ⟩ ) D E x h ˆ f ∗ ( x ) xσ ′ ( ⟨ w , x ⟩ ) i , ˜ x Ei , such that sup ˜ x ∥ G − ˆ G ∥ ≤ ∆ 1 + ∆ 2 , and g j = 1 N P n ˆ f ∗ ( x n ) σ ′ ( ⟨ w j , x n ⟩ ) . Let us first ev aluate ∆ 1 . ∆ 1 = sup ˜ x ∈ S d − 1 1 J ∗ N X j,n ˆ f ∗ ( x n ) x n σ ′ ( ⟨ w j , x n ⟩ ) h ′ ( ⟨ w j , ˜ x ⟩ ) − E w,x h ˆ f ∗ ( x ) xσ ′ ( ⟨ w , x ⟩ ) h ′ ( ⟨ w , ˜ x ⟩ ) i = sup ˜ x ∈ S d − 1 1 J ∗ N X j,n ˆ f ∗ ( x n ) x n σ ′ ( ⟨ w j , x n ⟩ ) h ′ ( ⟨ w j , ˜ x ⟩ ) − 1 J ∗ X j E x h ˆ f ∗ ( x ) xσ ′ ( ⟨ w j , x ⟩ ) h ′ ( ⟨ w j , ˜ x ⟩ ) i + sup ˜ x ∈ S d − 1 1 J ∗ X j E x h ˆ f ∗ ( x ) xσ ′ ( ⟨ w j , x ⟩ ) h ′ ( ⟨ w j , ˜ x ⟩ ) i − E w,x h ˆ f ∗ ( x ) xσ ′ ( ⟨ w , x ⟩ ) h ′ ( ⟨ w , ˜ x ⟩ ) i . W e define the first term of the right hand side as ∆ 1 , 1 and the second as ∆ 1 , 2 . As for ∆ 1 , 1 , ∆ 1 , 1 = sup ˜ x ∈ S d − 1 1 J ∗ X j ( 1 N X n ˆ f ∗ ( x n ) x n σ ′ ( ⟨ w j , x n ⟩ ) h ′ ( ⟨ w j , ˜ x ⟩ ) − E x h ˆ f ∗ ( x ) xσ ′ ( ⟨ w j , x ⟩ ) h ′ ( ⟨ w j , ˜ x ⟩ ) i ) ≤ sup ˜ x ∈ S d − 1 sup w ∈ S d − 1 1 N X n ˆ f ∗ ( x n ) x n σ ′ ( ⟨ w j , x n ⟩ ) h ′ ( ⟨ w j , ˜ x ⟩ ) − E x h ˆ f ∗ ( x ) xσ ′ ( ⟨ w j , x ⟩ ) h ′ ( ⟨ w j , ˜ x ⟩ ) i = sup ˜ x ∈ S d − 1 sup w ∈ S d − 1 ( 1 N X n ˆ f ∗ ( x n ) x n σ ′ ( ⟨ w j , x n ⟩ ) − E x h ˆ f ∗ ( x ) xσ ′ ( ⟨ w j , x ⟩ ) i ) h ′ ( ⟨ w j , ˜ x ⟩ ) ≤ sup ˜ x ∈ S d − 1 sup w ∈ S d − 1 1 N X n ˆ f ∗ ( x n ) x n σ ′ ( ⟨ w j , x n ⟩ ) − E x h ˆ f ∗ ( x ) xσ ′ ( ⟨ w j , x ⟩ ) i , where for the last inequality we used that the deriv ativ e of h is bounded. Now , from Lemma 32 of Damian et al. ( 2022 ), we know that with high probability , sup w ∈ S d − 1 1 N X n ˆ f ∗ ( x n ) x n σ ′ ( ⟨ w j , x n ⟩ ) − E x h ˆ f ∗ ( x ) xσ ′ ( ⟨ w j , x ⟩ ) i = ˜ O r d N ! . As a result, ∆ 1 , 1 = ˜ O r d N ! . (3) Let us now focus on ∆ 1 , 2 = sup ˜ x ∈ S d − 1 1 J ∗ X j E x h ˆ f ∗ ( x ) xσ ′ ( ⟨ w j , x ⟩ ) h ′ ( ⟨ w j , ˜ x ⟩ ) i − E w,x h ˆ f ∗ ( x ) xσ ′ ( ⟨ w , x ⟩ ) h ′ ( ⟨ w , ˜ x ⟩ ) i . W e will proceed analogously to the proof of Lemma 32 of Damian et al. ( 2022 ). W e define Y ( ˜ x ) as Y ( ˜ x ) : = 1 J ∗ X j E x h ˆ f ∗ ( x ) xσ ′ ( ⟨ w j , x ⟩ ) h ′ ( ⟨ w j , ˜ x ⟩ ) i = 1 J ∗ X j E x h ˆ f ∗ ( x ) xσ ′ ( ⟨ w j , x ⟩ ) i h ′ ( ⟨ w j , ˜ x ⟩ ) . 27 Dataset Distillation Efficiently Encodes Lo w-Dimensional Representations A P R E P RI NT Moreov er , we define an ϵ -net N ϵ such that for all ˜ x ∈ S d − 1 , there exists ˆ x ∈ N ϵ such that ∥ ˜ x − ˆ x ∥ ≤ ϵ . By a standard argument, such net e xist with size |N ϵ | ≤ e C d log (1 /ϵ ) , for some constant C . Here, we will set ϵ = q d J ∗ , and also denote N 1 4 , the minimal 1 4 -net of S d − 1 with |N 1 4 | ≤ e C d . Then, ∆ 1 , 2 = sup ˜ x ∈ S d − 1 1 J ∗ X j E x h ˆ f ∗ ( x ) xσ ′ ( ⟨ w j , x ⟩ ) h ′ ( ⟨ w j , ˜ x ⟩ ) i − E w,x h ˆ f ∗ ( x ) xσ ′ ( ⟨ w , x ⟩ ) h ′ ( ⟨ w , ˜ x ⟩ ) i = sup ˜ x ∈ S d − 1 ∥ Y ( ˜ x ) − E w [ Y ( ˜ x )] ∥ = sup ˜ x ∈ S d − 1 sup u ∈ S d − 1 ⟨ u, Y ( ˜ x ) − E w [ Y ( ˜ x )] ⟩ ≤ 2 sup ˜ x ∈ S d − 1 sup u ∈N 1 / 4 ⟨ u, Y ( ˜ x ) − E w [ Y ( ˜ x )] ⟩ . Since h ′ is O (1) -Lipschitz, for a fixed u ∈ S d − 1 , Y w ( ˜ x ) : = E x h ˆ f ∗ ( x ) ⟨ u, x ⟩ σ ′ ( ⟨ w , x ⟩ ) h ′ ( ⟨ w , ˜ x ⟩ ) i is also O (1) - Lipschitz. Indeed, | Y w ( ˜ x 1 ) − Y w ( ˜ x 2 ) | = | E x h ˆ f ∗ ( x ) ⟨ u, x ⟩ σ ′ ( ⟨ w , x ⟩ ) i | h ′ ( ⟨ w , ˜ x 1 ⟩ ) − h ′ ( ⟨ w , ˜ x 2 ⟩ ) | ≲ E x h ˆ f ∗ ( x ) ⟨ u, x ⟩ σ ′ ( ⟨ w , x ⟩ ) i ∥ ˜ x 1 − ˜ x 2 ∥ ≤ E x h ˆ f ∗ ( x ) 2 i 1 / 2 E x ⟨ u, x ⟩ 2 1 ⟨ w,x ⟩ > 0 1 / 2 ∥ ˜ x 1 − ˜ x 2 ∥ , where for the last inequality we used Cauchy-Shwarz inequality . As ⟨ u, x ⟩ ∼ N (0 , 1) , by symmetry , E x ⟨ u, x ⟩ 2 1 ⟨ w,x ⟩ > 0 = 1 2 E x [ ⟨ u, x ⟩ 2 ] = 1 2 , which implies E x h ˆ f ∗ ( x ) ⟨ u, x ⟩ σ ′ ( ⟨ w , x ⟩ ) i ≤ 1 √ 2 , (4) which prov es the O (1) -Lipschitzness of Y w ( ˜ x ) . Consequently , ⟨ u, Y ( ˜ x ) ⟩ and ⟨ u, E w [ Y ( ˜ x )] ⟩ are also O (1) -Lipschitz since Lipschitzness is preserved under mean and expectation, and ⟨ u, Y ( ˜ x ) − E w [ Y ( ˜ x )] ⟩ as well since the dif ference of two L -Lipschitz functions is 2 L -Lipschitz. Now , for all ˜ x ∈ S d − 1 and any u , there exist a ˆ x ∈ N ϵ such that ∥ ˜ x − ˆ x ∥ ≤ ϵ . Combining with the Lipschitzness of ⟨ u, Y ( ˜ x ) − E w [ Y ( ˜ x )] ⟩ , we obtain |⟨ u, Y ( ˜ x ) − E w [ Y ( ˜ x )] ⟩| = |⟨ u, Y ( ˆ x ) − E w [ Y ( ˆ x )] ⟩| + |⟨ u, Y ( ˜ x ) − E w [ Y ( ˜ x )] ⟩ − ⟨ u, Y ( ˆ x ) − E w [ Y ( ˆ x )] ⟩| ≤|⟨ u, Y ( ˆ x ) − E w [ Y ( ˆ x )] ⟩| + O ( ϵ ) ≤ sup ˆ x ∈N ϵ sup u ∈N 1 / 4 |⟨ u, Y ( ˆ x ) − E w [ Y ( ˆ x )] ⟩| + O ( ϵ ) . Therefore, sup ˜ x ∈ S d − 1 sup u ∈N 1 / 4 ⟨ u, Y ( ˜ x ) − E w [ Y ( ˜ x )] ⟩ ≤ sup ˜ x ∈N ϵ sup u ∈N 1 / 4 |⟨ u, Y ( ˆ x ) − E w [ Y ( ˆ x )] ⟩| + O ( ϵ ) . Let us denote Z j ( ˆ x ) : = E x h ˆ f ∗ ( x ) ⟨ u, x ⟩ σ ′ ( ⟨ w j , x ⟩ ) h ′ ( ⟨ w j , ˆ x ⟩ ) i . Since E x h ˆ f ∗ ( x ) ⟨ u, x ⟩ σ ′ ( ⟨ w j , x ⟩ ) i ≤ 1 2 as prov ed earlier in equation ( 4 ) and sup | z |≤ 1 h ′ ( z ) < ∞ , Z j is bounded and O (1) -sub gaussian. As a result, for each u ∈ N 1 4 , 1 J ∗ X j Z j ( ˆ x ) − E [ Z j ( ˆ x )] = ⟨ u, Y ( ˆ x ) − E w [ Y ( ˆ x )] ⟩ ≲ r 2 z J ∗ , with probability 1 − 2e − z . By taking the union bound over N ϵ and N 1 / 4 , we obtain that with probability 1 − 2e C d log ( J ∗ /ϵ ) − z , 2 sup ˜ x ∈N ϵ ,u ∈N 1 4 ⟨ u, Y ( ˜ x ) − E w [ Y ( ˜ x )] ⟩ ≲ r 2 z J ∗ . 28 Dataset Distillation Efficiently Encodes Lo w-Dimensional Representations A P R E P RI NT W e choose z = ˜ Θ( C d log ( J ∗ /ϵ )) and ϵ = γ − 1 p d/J ∗ to obtain with high probability ∆ 1 , 2 = sup ˜ x ∈ S d − 1 ∥ Y ( ˜ x ) − E w [ Y ( ˜ x )] ∥ = ˜ O r d J ∗ ! . (5) W e combine the obtained two inequalities ( 3 ) and ( 5 ) to deri ve ∆ 1 ≤ ∆ 1 , 1 + ∆ 1 , 2 = ˜ O r d N + r d J ∗ ! . (6) W e will now focus on the second term ∆ 2 : = sup ˜ x 1 J ∗ X j w j h ′′ ( ⟨ w j , ˜ x ⟩ ) ⟨ g j , ˜ x ⟩ − E w h w h ′′ ( ⟨ w , ˜ x ⟩ ) D E h ˆ f ∗ ( x ) xσ ′ ( ⟨ w , x ⟩ ) i , ˜ x Ei . W e can similarly decompose this into two dif ferent terms ∆ 2 , 1 : = sup ˜ x 1 J ∗ X j w j h ′′ ( ⟨ w j , ˜ x ⟩ ) ⟨ g j , ˜ x ⟩ − 1 J ∗ X j w j h ′′ ( ⟨ w j , ˜ x ⟩ ) D E h ˆ f ∗ ( x ) xσ ′ ( ⟨ w j , x ⟩ ) i , ˜ x E , ∆ 2 , 2 : = sup ˜ x 1 J ∗ X j w j h ′′ ( ⟨ w j , ˜ x ⟩ ) D E h ˆ f ∗ ( x ) xσ ′ ( ⟨ w j , x ⟩ ) i , ˜ x E − E w h w h ′′ ( ⟨ w , ˜ x ⟩ ) D E h ˆ f ∗ ( x ) xσ ′ ( ⟨ w , x ⟩ ) i , ˜ x Ei . In order to keep the notation simple, we define ˆ g j : = E x h ˆ f ∗ ( x ) xσ ′ ( ⟨ w j , x ⟩ ) i . Concerning the first term, ∆ 2 , 1 = sup ˜ x 1 J ∗ X j w j h ′′ ( ⟨ w j , ˜ x ⟩ ) ⟨ g j , ˜ x ⟩ − 1 J ∗ X j w j h ′′ ( ⟨ w j , ˜ x ⟩ ) ⟨ ˆ g j , ˜ x ⟩ = sup ˜ x 1 J ∗ X j w j h ′′ ( ⟨ w j , ˜ x ⟩ ) ⟨ g j − ˆ g j , ˜ x ⟩ . Under the same conditions as the first half of the proof, with high probability , we already have ∆ 2 , 1 ≤ sup ˜ x 1 J ∗ X j ∥ h ′′ ( ⟨ w j , ˜ x ⟩ ) w j ⟨ g j − ˆ g j , ˜ x ⟩∥ ≤ sup ˜ x 1 J ∗ X j | h ′′ ( ⟨ w j , ˜ x ⟩ ) |∥ w j ∥∥ g j − ˆ g j ∥∥ ˜ x ∥ ≲ r d N sup ˜ x 1 J ∗ X j h ′′ ( ⟨ w j , ˜ x ⟩ ) , where we used Lemma 32 of Damian et al. ( 2022 ), ∥ w j ∥ = ∥ ˜ x ∥ = 1 for the third inequality . Since h ′′ is bounded, ∆ 2 , 1 ≲ r d N . (7) 29 Dataset Distillation Efficiently Encodes Lo w-Dimensional Representations A P R E P RI NT As for ∆ 2 , 2 , ∆ 2 , 2 = 1 J ∗ X j w j h ′′ ( ⟨ w j , ˜ x ⟩ ) ⟨ ˆ g j , ˜ x ⟩ − E w [ w h ′′ ( ⟨ w , ˜ x ⟩ ) ⟨ ˆ g j , ˜ x ⟩ ] = sup u ∈ S d − 1 * u, 1 J ∗ X j w j h ′′ ( ⟨ w j , ˜ x ⟩ ) ⟨ ˆ g j , ˜ x ⟩ − E w [ w h ′′ ( ⟨ w , ˜ x ⟩ ) ⟨ ˆ g j , ˜ x ⟩ ] + = sup u ∈ S d − 1 1 J ∗ X j ⟨ u, w j ⟩ h ′′ ( ⟨ w j , ˜ x ⟩ ) ⟨ ˆ g j , ˜ x ⟩ − E w [ ⟨ u, w j ⟩ h ′′ ( ⟨ w , ˜ x ⟩ ) ⟨ ˆ g j , ˜ x ⟩ ] ≤ 2 sup u ∈N 1 / 4 1 J ∗ X j ⟨ u, w j ⟩ h ′′ ( ⟨ w j , ˜ x ⟩ ) ⟨ ˆ g j , ˜ x ⟩ − E w [ ⟨ u, w j ⟩ h ′′ ( ⟨ w , ˜ x ⟩ ) ⟨ ˆ g j , ˜ x ⟩ ] . W e define Z j ( u, ˜ x ) : = ⟨ u, w j ⟩ h ′′ ( ⟨ w j , ˜ x ⟩ ) ⟨ ˆ g j , ˜ x ⟩ − E w [ ⟨ u, w j ⟩ h ′′ ( ⟨ w , ˜ x ⟩ ) ⟨ ˆ g j , ˜ x ⟩ ] . Then, | Z j ( u, ˜ x ) | ≤ |⟨ u, w j ⟩ h ′′ ( ⟨ w j , ˜ x ⟩ ) ⟨ ˆ g j , ˜ x ⟩| + | E w [ ⟨ u, w j ⟩ h ′′ ( ⟨ w , ˜ x ⟩ ) ⟨ ˆ g j , ˜ x ⟩ ] | ≤ |⟨ u, w j ⟩| | h ′′ ( ⟨ w j , ˜ x ⟩ ) | |⟨ ˆ g j , ˜ x ⟩| + E w [ |⟨ u, w j ⟩| | h ′′ ( ⟨ w , ˜ x ⟩ ) | |⟨ ˆ g j , ˜ x ⟩| ] ≤ 2 · 1 · sup | z |≤ 1 | h ′′ ( z ) | · 1 √ 2 ≲ 1 , where we used |⟨ u, ˜ x ⟩| ≤ 1 , and ⟨ ˆ g j , ˜ x ⟩ ≤ 1 / √ 2 from Equation ( 4 ) for the fourth inequality , and that h ′′ is bounded on the compact set for the last inequality . Since h ′′ ( ⟨ w j , ˜ x ⟩ ) and ⟨ ˆ g j , ˜ x ⟩ are bounded, and Lipschitz ( C 2 functions on a compact set is Lipschitz), Z j ( u, ˜ x ) is O (1) -Lipschitz with respect to ˜ x . Therefore, similarly to the previous ar gument, we obtain sup ˜ x ∈ S d − 1 sup u ∈N 1 / 4 1 J ∗ X j Z j ( u, ˜ x ) = sup ˆ x ∈N ϵ sup u ∈N 1 / 4 1 J ∗ X j Z j ( u, ˆ x ) + O ( ϵ ) . Since Z j ( u, ˜ x ) is O (1) -sub Gaussian, for each u ∈ N 1 / 4 , we hav e with probability 1 − 2e − z 1 J ∗ X j Z j ( u, ˜ x ) ≲ r 2 z J ∗ , which by union bound ov er N ϵ and N 1 / 4 and setting z and ϵ accordingly leads to ∆ 2 , 2 = ˜ O r d J ∗ ! . (8) By combining the two inequalities ( 7 ) and ( 8 ), we obtain ∆ 2 = ˜ O r d N + r d J ∗ ! . (9) Finally , combining the three bounds ( 6 ) and ( 9 ) with Lemma B.18 , we conclude the desired result. Lemma B.20. Under Assumptions 3.1 , 3.3 , 3.4 , 3.6 , 3.7 and 3.8 , with high pr obability , ϵ = ˜ O d 1 2 N − 1 2 + d 1 2 J ∗ − 1 2 . wher e ϵ is defined in Cor ollary B.7 . 30 Dataset Distillation Efficiently Encodes Lo w-Dimensional Representations A P R E P RI NT Pr oof. The statement follows by sho wing that with high probability , sup w,x 1 J ∗ N X j,n ϵ n x n σ ′ ( ⟨ w i,j , x n ⟩ ) h ′ ( ⟨ w i,j , ˜ x ⟩ ) = ˜ O d 1 2 N − 1 2 , and sup w,x 1 J ∗ X j w i,j h ′′ ( ⟨ w i,j , ˜ x ⟩ ) * 1 N X n ϵ n x n σ ′ ( ⟨ w i,j , x n ⟩ ) , ˜ x + = ˜ O d 1 2 N − 1 2 + d 1 2 J ∗ − 1 2 . The first equation is a direct consequence of Lemma 33 of Damian et al. ( 2022 ) since ∥ h ′ ∥ ∞ = 1 . The second inequality can be shown with the same approach as the deriv ation of ∆ 2 in the proof of Lemma B.19 by replacing ˆ f ∗ with ϵ n which is bounded. Finally , we can prove Theorem B.4 . Pr oof of Theor em B.4 . W e just need to substitute G and ϵ in Corollary B.7 with the bounds we obtained in Theorem B.19 and Lemma B.20 . Therefore, the first phase of DD captures the latent structure of the original problem and translates it into the input space. B.3.5 Concentration of Empirical Gradient (for softplus) In this part, we complement the pre vious proof by showing a version customized for the softplus acti v ation function h ( z ) = 1 γ s log(1 + e γ s z ) . W e show that the dependence of γ s can be absorbed into J ∗ , the parameter that appears as a feature of distillation. Theorem B.21. Under Assumptions 3.1 , 3.3 , 3.4 , 3.6 and 3.7 , if we use the softplus activation function h ( z ) = 1 γ s log(1 + e γ s z ) , then with high pr obability , G = c d ⟨ β , ˜ x ⟩ β + ˜ O dN − 1 2 + γ s d − 2 + γ 1 2 s d 3 4 J ∗ − 1 2 + γ s dJ ∗− 1 . Pr oof. Since G = ˆ G + G − ˆ G ≤ ˆ G + sup ˜ x ∈ S d − 1 ∥ G − ˆ G ∥ , and the first term is already e valuated in Theorem B.18 , we will e valuate the second. From the form of G and ˆ G , we can divide it into the follo wing two terms: ∆ 1 : = sup ˜ x 1 J ∗ X j g j h ′ ( ⟨ w j , ˜ x ⟩ ) − E w h E x h ˆ f ∗ ( x ) xσ ′ ( ⟨ w , x ⟩ ) i h ′ ( ⟨ w , ˜ x ⟩ ) i , ∆ 2 : = sup ˜ x 1 J ∗ X j w j h ′′ ( ⟨ w j , ˜ x ⟩ ) ⟨ g j , ˜ x ⟩ − E w h w h ′′ ( ⟨ w , ˜ x ⟩ ) D E h ˆ f ∗ ( x ) xσ ′ ( ⟨ w , x ⟩ ) i , ˜ x Ei , such that sup ˜ x ∥ G − ˆ G ∥ ≤ ∆ 1 + ∆ 2 , and g j = 1 N P n ˆ f ∗ ( x n ) σ ′ ( ⟨ w j , x n ⟩ ) . Let us first ev aluate ∆ 1 . ∆ 1 = sup ˜ x ∈ S d − 1 1 J ∗ N X j,n ˆ f ∗ ( x n ) x n σ ′ ( ⟨ w j , x n ⟩ ) h ′ ( ⟨ w j , ˜ x ⟩ ) − E w,x h ˆ f ∗ ( x ) xσ ′ ( ⟨ w , x ⟩ ) h ′ ( ⟨ w , ˜ x ⟩ ) i = sup ˜ x ∈ S d − 1 1 J ∗ N X j,n ˆ f ∗ ( x n ) x n σ ′ ( ⟨ w j , x n ⟩ ) h ′ ( ⟨ w j , ˜ x ⟩ ) − 1 J ∗ X j E x h ˆ f ∗ ( x ) xσ ′ ( ⟨ w j , x ⟩ ) h ′ ( ⟨ w j , ˜ x ⟩ ) i + sup ˜ x ∈ S d − 1 1 J ∗ X j E x h ˆ f ∗ ( x ) xσ ′ ( ⟨ w j , x ⟩ ) h ′ ( ⟨ w j , ˜ x ⟩ ) i − E w,x h ˆ f ∗ ( x ) xσ ′ ( ⟨ w , x ⟩ ) h ′ ( ⟨ w , ˜ x ⟩ ) i . 31 Dataset Distillation Efficiently Encodes Lo w-Dimensional Representations A P R E P RI NT W e defined the first term of the right hand side as ∆ 1 , 1 and the second as ∆ 1 , 2 . As for ∆ 1 , 1 , ∆ 1 , 1 = sup ˜ x ∈ S d − 1 1 J ∗ X j ( 1 N X n ˆ f ∗ ( x n ) x n σ ′ ( ⟨ w j , x n ⟩ ) h ′ ( ⟨ w j , ˜ x ⟩ ) − E x h ˆ f ∗ ( x ) xσ ′ ( ⟨ w j , x ⟩ ) h ′ ( ⟨ w j , ˜ x ⟩ ) i ) ≤ sup ˜ x ∈ S d − 1 sup w ∈ S d − 1 1 N X n ˆ f ∗ ( x n ) x n σ ′ ( ⟨ w j , x n ⟩ ) h ′ ( ⟨ w j , ˜ x ⟩ ) − E x h ˆ f ∗ ( x ) xσ ′ ( ⟨ w j , x ⟩ ) h ′ ( ⟨ w j , ˜ x ⟩ ) i = sup ˜ x ∈ S d − 1 sup w ∈ S d − 1 ( 1 N X n ˆ f ∗ ( x n ) x n σ ′ ( ⟨ w j , x n ⟩ ) − E x h ˆ f ∗ ( x ) xσ ′ ( ⟨ w j , x ⟩ ) i ) h ′ ( ⟨ w j , ˜ x ⟩ ) ≤ sup ˜ x ∈ S d − 1 sup w ∈ S d − 1 1 N X n ˆ f ∗ ( x n ) x n σ ′ ( ⟨ w j , x n ⟩ ) − E x h ˆ f ∗ ( x ) xσ ′ ( ⟨ w j , x ⟩ ) i , where for the last inequality , we used that the deri vati ve of h is bounded by 1. Now , from Lemma 32 of Damian et al. ( 2022 ), we know that with high probability , sup w ∈ S d − 1 1 N X n ˆ f ∗ ( x n ) x n σ ′ ( ⟨ w j , x n ⟩ ) − E x h ˆ f ∗ ( x ) xσ ′ ( ⟨ w j , x ⟩ ) i = ˜ O r d N ! . As a result, ∆ 1 , 1 = ˜ O r d N ! . (10) Let us now focus on ∆ 1 , 2 = sup ˜ x ∈ S d − 1 1 J ∗ X j E x h ˆ f ∗ ( x ) xσ ′ ( ⟨ w j , x ⟩ ) h ′ ( ⟨ w j , ˜ x ⟩ ) i − E w,x h ˆ f ∗ ( x ) xσ ′ ( ⟨ w , x ⟩ ) h ′ ( ⟨ w , ˜ x ⟩ ) i . W e will proceed analogously to the proof of Lemma 32 of Damian et al. ( 2022 ). W e define Y ( ˜ x ) as Y ( ˜ x ) : = 1 J ∗ X j E x h ˆ f ∗ ( x ) xσ ′ ( ⟨ w j , x ⟩ ) h ′ ( ⟨ w j , ˜ x ⟩ ) i = 1 J ∗ X j E x h ˆ f ∗ ( x ) xσ ′ ( ⟨ w j , x ⟩ ) i h ′ ( ⟨ w j , ˜ x ⟩ ) . Moreov er , we define an ϵ -net N ϵ such that for all ˜ x ∈ S d − 1 , there exists ˆ x ∈ N ϵ such that ∥ ˜ x − ˆ x ∥ ≤ ϵ . By a standard argument, such net e xists with size |N ϵ | ≤ e C d log (1 /ϵ ) , for some constant C . Here, we will set ϵ = γ − 1 s q d J ∗ , and also denote N 1 4 , the minimal 1 4 -net of S d − 1 with |N 1 4 | ≤ e C d . Then, ∆ 1 , 2 = sup ˜ x ∈ S d − 1 1 J ∗ X j E x h ˆ f ∗ ( x ) xσ ′ ( ⟨ w j , x ⟩ ) h ′ ( ⟨ w j , ˜ x ⟩ ) i − E w,x h ˆ f ∗ ( x ) xσ ′ ( ⟨ w , x ⟩ ) h ′ ( ⟨ w , ˜ x ⟩ ) i = sup ˜ x ∈ S d − 1 ∥ Y ( ˜ x ) − E w [ Y ( ˜ x )] ∥ = sup ˜ x ∈ S d − 1 sup u ∈ S d − 1 ⟨ u, Y ( ˜ x ) − E w [ Y ( ˜ x )] ⟩ ≤ 2 sup ˜ x ∈ S d − 1 sup u ∈N 1 / 4 ⟨ u, Y ( ˜ x ) − E w [ Y ( ˜ x )] ⟩ . Since h ′ is O ( γ s ) -Lipschitz, for a fixed u ∈ S d − 1 , Y w ( ˜ x ) : = E x h ˆ f ∗ ( x ) ⟨ u, x ⟩ σ ′ ( ⟨ w , x ⟩ ) h ′ ( ⟨ w , ˜ x ⟩ ) i is also O ( γ s ) - Lipschitz. Indeed, | Y w ( ˜ x 1 ) − Y w ( ˜ x 2 ) | = | E x h ˆ f ∗ ( x ) ⟨ u, x ⟩ σ ′ ( ⟨ w , x ⟩ ) i | h ′ ( ⟨ w , ˜ x 1 ⟩ ) − h ′ ( ⟨ w , ˜ x 2 ⟩ ) | ≲ γ s E x h ˆ f ∗ ( x ) ⟨ u, x ⟩ σ ′ ( ⟨ w , x ⟩ ) i ∥ ˜ x 1 − ˜ x 2 ∥ ≤ γ s E x h ˆ f ∗ ( x ) 2 i 1 / 2 E x ⟨ u, x ⟩ 2 1 ⟨ w,x ⟩ > 0 1 / 2 ∥ ˜ x 1 − ˜ x 2 ∥ , 32 Dataset Distillation Efficiently Encodes Lo w-Dimensional Representations A P R E P RI NT where for the last inequality , we used Cauchy-Shwarz inequality . As ⟨ u, x ⟩ ∼ N (0 , 1) , by symmetry , E x ⟨ u, x ⟩ 2 1 ⟨ w,x ⟩ > 0 = 1 2 E x [ ⟨ u, x ⟩ 2 ] = 1 2 , which implies E x h ˆ f ∗ ( x ) ⟨ u, x ⟩ σ ′ ( ⟨ w , x ⟩ ) i ≤ 1 √ 2 , (11) which prov es the O ( γ s ) -Lipschitzness of Y w ( ˜ x ) . Consequently , ⟨ u, Y ( ˜ x ) ⟩ and ⟨ u, E w [ Y ( ˜ x )] ⟩ are also O ( γ s ) -Lipschitz since Lipschitzness is preserved under mean and expectation, and ⟨ u, Y ( ˜ x ) − E w [ Y ( ˜ x )] ⟩ as well since the dif ference of two L -Lipschitz functions is 2 L -Lipschitz. Now , for all ˜ x ∈ S d − 1 and any u , there exists a ˆ x ∈ N ϵ such that ∥ ˜ x − ˆ x ∥ ≤ ϵ . Combining with the Lipschitzness of ⟨ u, Y ( ˜ x ) − E w [ Y ( ˜ x )] ⟩ , we obtain |⟨ u, Y ( ˜ x ) − E w [ Y ( ˜ x )] ⟩| = |⟨ u, Y ( ˆ x ) − E w [ Y ( ˆ x )] ⟩| + |⟨ u, Y ( ˜ x ) − E w [ Y ( ˜ x )] ⟩ − ⟨ u, Y ( ˆ x ) − E w [ Y ( ˆ x )] ⟩| ≤|⟨ u, Y ( ˆ x ) − E w [ Y ( ˆ x )] ⟩| + O ( γ s ϵ ) ≤ sup ˆ x ∈N ϵ sup u ∈N 1 / 4 |⟨ u, Y ( ˆ x ) − E w [ Y ( ˆ x )] ⟩| + O ( γ s ϵ ) . Therefore, sup ˜ x ∈ S d − 1 sup u ∈N 1 / 4 ⟨ u, Y ( ˜ x ) − E w [ Y ( ˜ x )] ⟩ ≤ sup ˜ x ∈N ϵ sup u ∈N 1 / 4 |⟨ u, Y ( ˆ x ) − E w [ Y ( ˆ x )] ⟩| + O ( γ s ϵ ) . Let us denote Z j ( ˆ x ) : = E x h ˆ f ∗ ( x ) ⟨ u, x ⟩ σ ′ ( ⟨ w j , x ⟩ ) h ′ ( ⟨ w j , ˆ x ⟩ ) i . Since E x h ˆ f ∗ ( x ) ⟨ u, x ⟩ σ ′ ( ⟨ w j , x ⟩ ) i ≤ 1 2 as prov ed earlier and sup | z |≤ 1 h ′ ( z ) < ∞ , Z j is bounded and O (1) -sub gaussian. As a result, for each u ∈ N 1 4 , 1 J ∗ X j Z j ( ˆ x ) − E [ Z j ( ˆ x )] = ⟨ u, Y ( ˆ x ) − E w [ Y ( ˆ x )] ⟩ ≲ r 2 z J ∗ , with probability 1 − 2e − z . By taking the union bound over N ϵ and N 1 / 4 , we obtain that with probability 1 − 2e C d log ( J ∗ /ϵ ) − z , 2 sup ˜ x ∈N ϵ ,u ∈N 1 4 ⟨ u, Y ( ˜ x ) − E w [ Y ( ˜ x )] ⟩ ≲ r 2 z J ∗ . W e choose z = ˜ Θ( C d log ( J ∗ /ϵ )) and ϵ = γ − 1 s p d/J ∗ to obtain with high probability ∆ 1 , 2 = sup ˜ x ∈ S d − 1 ∥ Y ( ˜ x ) − E w [ Y ( ˜ x )] ∥ = ˜ O r d J ∗ ! . (12) W e combine the obtained two inequalities ( 10 ) and ( 12 ) to deri ve ∆ 1 ≤ ∆ 1 , 1 + ∆ 1 , 2 = ˜ O r d N + r d J ∗ ! . (13) W e will now focus on the second term ∆ 2 : = sup ˜ x 1 J ∗ X j w j h ′′ ( ⟨ w j , ˜ x ⟩ ) ⟨ g j , ˜ x ⟩ − E w h w h ′′ ( ⟨ w , ˜ x ⟩ ) D E h ˆ f ∗ ( x ) xσ ′ ( ⟨ w , x ⟩ ) i , ˜ x Ei . W e can similarly decompose this into two dif ferent terms ∆ 2 , 1 : = sup ˜ x 1 J ∗ X j w j h ′′ ( ⟨ w j , ˜ x ⟩ ) ⟨ g j , ˜ x ⟩ − 1 J ∗ X j w j h ′′ ( ⟨ w j , ˜ x ⟩ ) D E h ˆ f ∗ ( x ) xσ ′ ( ⟨ w j , x ⟩ ) i , ˜ x E , ∆ 2 , 2 : = sup ˜ x 1 J ∗ X j w j h ′′ ( ⟨ w j , ˜ x ⟩ ) D E h ˆ f ∗ ( x ) xσ ′ ( ⟨ w j , x ⟩ ) i , ˜ x E − E w h w h ′′ ( ⟨ w , ˜ x ⟩ ) D E h ˆ f ∗ ( x ) xσ ′ ( ⟨ w , x ⟩ ) i , ˜ x Ei . 33 Dataset Distillation Efficiently Encodes Lo w-Dimensional Representations A P R E P RI NT In order to keep the notation simple, we define ˆ g j : = E x h ˆ f ∗ ( x ) xσ ′ ( ⟨ w j , x ⟩ ) i . Concerning the first term, ∆ 2 , 1 = sup ˜ x 1 J ∗ X j w j h ′′ ( ⟨ w j , ˜ x ⟩ ) ⟨ g j , ˜ x ⟩ − 1 J ∗ X j w j h ′′ ( ⟨ w j , ˜ x ⟩ ) ⟨ ˆ g j , ˜ x ⟩ = sup ˜ x 1 J ∗ X j w j h ′′ ( ⟨ w j , ˜ x ⟩ ) ⟨ g j − ˆ g j , ˜ x ⟩ . Under the same conditions as the first half of the proof, with high probability , we already have ∆ 2 , 1 ≤ sup ˜ x 1 J ∗ X j ∥ h ′′ ( ⟨ w j , ˜ x ⟩ ) w j ⟨ g j − ˆ g j , ˜ x ⟩∥ ≤ sup ˜ x 1 J ∗ X j | h ′′ ( ⟨ w j , ˜ x ⟩ ) |∥ w j ∥∥ g j − ˆ g j ∥∥ ˜ x ∥ ≲ r d N sup ˜ x 1 J ∗ X j h ′′ ( ⟨ w j , ˜ x ⟩ ) , where we used Lemma 32 of Damian et al. ( 2022 ), ∥ w j ∥ = ∥ ˜ x ∥ = 1 , and h ′′ ≥ 0 for the third inequality . Now by using Lemma B.25 , we can show that ∆ 2 , 1 = ˜ O r d 2 N + r d N r γ s d 3 / 2 J ∗ + γ s d J ∗ !! . (14) As for ∆ 2 , 2 , ∆ 2 , 2 = 1 J ∗ X j w j h ′′ ( ⟨ w j , ˜ x ⟩ ) ⟨ ˆ g j , ˜ x ⟩ − E w [ w h ′′ ( ⟨ w , ˜ x ⟩ ) ⟨ ˆ g j , ˜ x ⟩ ] = sup u ∈ S d − 1 * u, 1 J ∗ X j w j h ′′ ( ⟨ w j , ˜ x ⟩ ) ⟨ ˆ g j , ˜ x ⟩ − E w [ w h ′′ ( ⟨ w , ˜ x ⟩ ) ⟨ ˆ g j , ˜ x ⟩ ] + = sup u ∈ S d − 1 1 J ∗ X j ⟨ u, w j ⟩ h ′′ ( ⟨ w j , ˜ x ⟩ ) ⟨ ˆ g j , ˜ x ⟩ − E w [ ⟨ u, w j ⟩ h ′′ ( ⟨ w , ˜ x ⟩ ) ⟨ ˆ g j , ˜ x ⟩ ] ≤ 2 sup u ∈N 1 / 4 1 J ∗ X j ⟨ u, w j ⟩ h ′′ ( ⟨ w j , ˜ x ⟩ ) ⟨ ˆ g j , ˜ x ⟩ − E w [ ⟨ u, w j ⟩ h ′′ ( ⟨ w , ˜ x ⟩ ) ⟨ ˆ g j , ˜ x ⟩ ] . W e define, Z j ( u, ˜ x ) : = ⟨ u, w j ⟩ h ′′ ( ⟨ w j , ˜ x ⟩ ) ⟨ ˆ g j , ˜ x ⟩ − E w [ ⟨ u, w j ⟩ h ′′ ( ⟨ w , ˜ x ⟩ ) ⟨ ˆ g j , ˜ x ⟩ ] . Then, | Z j ( u, ˜ x ) | ≤ |⟨ u, w j ⟩ h ′′ ( ⟨ w j , ˜ x ⟩ ) ⟨ ˆ g j , ˜ x ⟩| + | E w [ ⟨ u, w j ⟩ h ′′ ( ⟨ w , ˜ x ⟩ ) ⟨ ˆ g j , ˜ x ⟩ ] | ≤ |⟨ u, w j ⟩| | h ′′ ( ⟨ w j , ˜ x ⟩ ) | |⟨ ˆ g j , ˜ x ⟩| + E w [ |⟨ u, w j ⟩| | h ′′ ( ⟨ w , ˜ x ⟩ ) | |⟨ ˆ g j , ˜ x ⟩| ] ≤ 2 · 1 · γ s 4 · 1 √ 2 , where we used |⟨ u, ˜ x ⟩| ≤ 1 , ∥ h ′′ ∥ ∞ = γ s / 4 , and ⟨ ˆ g j , ˜ x ⟩ ≤ 1 / √ 2 from Equation ( 11 ) for the last inequality . Similarly , E Z j ( u, ˜ x ) 2 ≲ E w [ h ′′ ( ⟨ w , ˜ x ⟩ ) 2 ] = m γ , where m γ is defined in Lemma B.25 . Therefore, by Bernstein inequality , P 1 J ∗ X j Z j ( u, ˜ x ) ≥ C r m γ z J ∗ + γ s z J ∗ ≤ 2e − z . 34 Dataset Distillation Efficiently Encodes Lo w-Dimensional Representations A P R E P RI NT Since, h ′′ ( ⟨ w j , ˜ x ⟩ ) and ⟨ ˆ g j , ˜ x ⟩ are respectiv ely bounded by O ( γ s ) and O (1) , and Lipschitz with respect to ˜ x with constants O ( γ 2 s ) and O (1) , Z j ( u, ˜ x ) is O ( γ 2 s ) -Lipschitz with respect to ˜ x . Therefore, similarly to the pre vious ar gument, we obtain sup ˜ x ∈ S d − 1 sup u ∈N 1 / 4 | Z j ( u, ˜ x ) | = sup ˆ x ∈N ϵ sup u ∈N 1 / 4 | Z j ( u, ˆ x ) | + O ( γ 2 s ϵ ) , which by union bound ov er N ϵ and N 1 / 4 leads to ∆ 2 , 2 = ˜ O r γ s d 3 / 2 J ∗ + γ s d J ∗ ! . (15) By combining the two inequalities ( 14 ) and ( 15 ), we obtain ∆ 2 = ˜ O r d 2 N + r d N r γ s d 3 / 2 J ∗ + γ s d J ∗ ! + r γ s d 3 / 2 J ∗ + γ s d J ∗ ! . (16) Finally , combining the three bounds ( 13 ) and ( 16 ) with Lemma B.18 , we conclude the desired result. Lemma B.22. Under Assumptions 3.1 , 3.3 , 3.4 , 3.6 , 3.7 and 3.8 , W ith high pr obability , when the activation function is Softplus with parameter γ s ϵ = ˜ O dN − 1 2 + γ 1 2 s d 3 2 J ∗− 1 2 + γ s dJ ∗− 1 . wher e ϵ is defined in Cor ollary B.7 . Pr oof. The statement follows by sho wing that sup w,x 1 J ∗ N X j,n ϵ n x n σ ′ ( ⟨ w i,j , x n ⟩ ) h ′ ( ⟨ w i,j , ˜ x ⟩ ) = ˜ O d 1 2 N − 1 2 , and sup w,x 1 J ∗ X j w i,j h ′′ ( ⟨ w i,j , ˜ x ⟩ ) * 1 N X n ϵ n x n σ ′ ( ⟨ w i,j , x n ⟩ ) , ˜ x + = ˜ O dN − 1 2 + γ 1 2 s d 3 2 J ∗− 1 2 + γ s dJ ∗− 1 . The first equation is a direct consequence of Lemma 33 of Damian et al. ( 2022 ) since ∥ h ′ ∥ ∞ = 1 . The second inequality can be shown with the same approach as the deriv ation of ∆ 2 in the proof of Lemma B.19 by replacing ˆ f ∗ to ϵ n which is bounded. Finally , we can prove Theorem B.4 . Pr oof of Theor em B.4 . W e just need to substitute G and ϵ in Corollary B.7 with the bounds we obtained in Theorem B.19 and Lemma B.20 . W e will use the general bound in the remainder of the proof. B.3.6 Other Lemmas Lemma B.23. F or non-ne gative constants p 1 and p 2 , bounded function m suc h that sup | t |≤ 1 | m ( t ) | = M < ∞ , Z 1 − 1 m ( t )(1 − t 2 ) p 1 t p 2 d t ≤ 2 M Z 1 0 (1 − t 2 ) p 1 t p 2 d t. 35 Dataset Distillation Efficiently Encodes Lo w-Dimensional Representations A P R E P RI NT Pr oof. This can be proved as follo ws: Z 1 − 1 m ( t )(1 − t 2 ) p 1 t p 2 d t ≤ Z 1 − 1 m ( t )(1 − t 2 ) p 1 t p 2 d t ≤ Z 1 − 1 | m ( t ) | (1 − t 2 ) p 1 | t | p 2 d t ≤ M Z 1 − 1 (1 − t 2 ) p 1 | t | p 2 d t =2 M Z 1 0 (1 − t 2 ) p 1 t p 2 d t. Lemma B.24. let z ∼ S d − 2 . Then, E z [ z 2 k 1 ] = E µ ∼ N (0 , 1) [ µ 2 k ] E ν ∼ χ ( d − 1) [ ν 2 k ] = : c k ( d ) = Θ( d − k ) . Pr oof. If µ ∼ N (0 , I d − 1 ) , we can equi v alently write it as µ = ν z with independent ν ∼ χ ( d − 1) and z ∼ S d − 2 . Thus, µ 1 = z 1 ν and z 2 k 1 = µ 2 k 1 /ν 2 k . The numerator is independent of d , and the denominator is of order Θ( d k ) (Lemma 44 of Damian et al. ( 2022 )). Lemma B.25. When h ( z ) = 1 γ s log(1 + e γ s z ) , with high pr obability , sup ˜ x ∈ S d − 1 1 J X j h ′′ ( ⟨ w j , ˜ x ⟩ ) = ˜ O d 1 / 2 + r γ s d 3 / 2 J + γ s d J !! . Pr oof. Let t = ⟨ w, ˜ x ⟩ . When w ∼ U ( S d − 1 ) , t follo ws the probability distribution p d ( t ) = C d (1 − t 2 ) d − 3 2 , C d = Γ( d/ 2) √ π Γ(( d − 1) / 2) . Note that ∥ h ′′ ( t ) ∥ ∞ = γ s / 4 . Moreover , µ γ : = E w [ h ′′ ( ⟨ w , ˜ x ⟩ )] = Z 1 − 1 h ′′ ( t ) p d ( t )d t ≤ C d Z 1 − 1 h ′′ ( t )d t = C d ( h ′ (1) − h ′ ( − 1)) = C d tanh( γ s / 2) ≤ C d , and m γ : = E w [ h ′′ ( ⟨ w , ˜ x ⟩ ) 2 ] = Z 1 − 1 h ′′ ( t ) 2 p d ( t )d t ≤ C d Z R h ′′ ( t ) 2 d t = C d γ s 6 , where we used Lemma B.26 for the last equality . By Bernstein inequality , for any z > 0 P 1 J X j h ′′ ( ⟨ w j , ˜ x ⟩ ) − µ γ ≥ C r m γ z J + ∥ h ′′ ( t ) ∥ ∞ z J ≤ 2e − z . Furthermore, h ′′ ( ⟨ w j , ˜ x ⟩ ) is O ( γ 2 s ) -Lipschitz with respect to ˜ x , which implies its mean is also O ( γ 2 s ) -Lipschitz. Consider now the ϵ -net N ϵ ov er ˜ x , then for all ˜ x ∈ S d − 1 , by definition, there exists a ˆ x ∈ N such that 1 J X j h ′′ ( ⟨ w j , ˜ x ⟩ ) ≤ 1 J X j h ′′ ( ⟨ w j , ˆ x ⟩ ) + 1 J X j h ′′ ( ⟨ w j , ˜ x ⟩ ) − 1 J X j h ′′ ( ⟨ w j , ˆ x ⟩ ) ≤ sup ˜ x ∈N ϵ 1 J X j h ′′ ( ⟨ w j , ˆ x ⟩ ) + O ( γ 2 s ϵ ) . By union bound ov er |N ϵ | ≤ e C d log ( J/ϵ ) , with probability 1 − 2e C d log ( J/ϵ ) − z , sup ˜ x ∈N ϵ 1 J X j h ′′ ( ⟨ w j , ˆ x ⟩ ) ≤ µ γ + C r m γ z J + ∥ h ′′ ( t ) ∥ ∞ z J . 36 Dataset Distillation Efficiently Encodes Lo w-Dimensional Representations A P R E P RI NT By setting z = C d log( J /ϵ ) + ˜ O (1) , we obtain with high probability sup ˜ x ∈N ϵ 1 J X j h ′′ ( ⟨ w j , ˆ x ⟩ ) ≲ d 1 / 2 + C r γ s d 3 / 2 log( J /ϵ ) J + γ s d log( J /ϵ ) J ! , where we also used C d ∼ d 1 / 2 . Finally , ϵ = γ − 2 s q d J giv es with high probability sup ˜ x ∈ S d − 1 1 J X j h ′′ ( ⟨ w j , ˜ x ⟩ ) = ˜ O d 1 / 2 + r γ s d 3 / 2 J + γ s d J !! . Lemma B.26. When h ( z ) = 1 γ s log(1 + e γ s z ) , Z R h ′′ ( t ) 2 d t = γ s 6 . Pr oof. First, since h ′ ( t ) = e γ s t 1+e γ s t h ′′ ( t ) = γ s e γ s t (1 + e γ s t ) 2 = γ s 4 2 e γ s t/ 2 1 + e γ s t 2 = γ s 4 sec h 2 γ s t 2 . The integral becomes Z R h ′′ ( t ) 2 d t = γ 2 s 16 Z R sec h 4 γ s t 2 d t = γ s 8 Z R sec h 4 ( t ) d t. By substitution u = tanh( t ) , d u = sech 2 ( t )d t and sec h 2 ( t ) = 1 − tanh( t ) 2 = 1 − u 2 , which leads to Z R h ′′ ( t ) 2 d t = γ s 8 Z 1 − 1 1 − u 2 d u = γ s 6 . B.4 t = 1 Retraining Now , by retraining according to the teacher training with the distilled data set D S 1 = { ( ˜ x (1) , ˜ y (0) ) } from Theorem B.4 , θ (1) ← A R 1 ( θ (0) , L ( θ (0) , D S 1 ) , ξ R 1 , η R 1 , λ R 1 ) becomes as follows. W e set η D 1 = ˜ Θ( √ d ) , λ D 1 = ( η D 1 ) − 1 , and λ R 1 = ( η R 1 ) − 1 Lemma B.27. Under the Assumptions of Theor em B.4 , with the synthetic data D S 1 fr om the distillation phase at t = 1 , we obtain the following parameter at the end of this first step (i.e ., after the r etraining phase of t = 1 ): W (1) = W (0) − η R 1 n ∇ W L S ( θ (0) ) + λ R 1 W (0) o = − η R 1 ˜ y (0) ˜ x (1) a ⊙ σ ′ ( W (0) ⊤ ˜ x (1) ) ⊤ . Index-wise , this means w (1) i = a i σ ′ ( ⟨ w (0) i , ˜ x (1) ⟩ ) g ( x ) , wher e g ( x ) = − η R 1 ˜ y (0) ˜ x (1) = − η R 1 η D 1 ( ˜ y (0) ) 2 c d ⟨ β , ˜ x (0) ⟩ β + ˜ O d 1 2 N − 1 2 + d − 2 + d 1 2 J ∗ − 1 2 . Note that a (the second layer of the neural network) r emains unchang ed. Remark B.28. Since σ ′ ( z ) = 1 z > 0 , we may have in expectation L/ 2 weights w (1) j that are just 0. In the following analysis, we will tr eat neural networks with an effective width L ∗ , denoting the number of non-zer o weights after t = 1 . When L = ˜ Θ( L ∗ ) , this is satisfied with high pr obability . 5 5 In our final bound, we thus replace L ∗ with L . 37 Dataset Distillation Efficiently Encodes Lo w-Dimensional Representations A P R E P RI NT B.5 t = 2 T eacher T raining B.5.1 Problem F ormulation and Result W e will now focus on the second step of our algorithm. Note that by the progressiv e nature of Algorithm 1 , W 1 is now fix ed (see Lemma B.27 ) and the training phase will concentrate on the second layer, which means the distillation algorithm will also distill information of the second layer . After resetting the biases (see Assumption 3.7 ), teacher training runs ridge regression on the last layer (see Assumption 3.6 ). As a result, I T r j = { θ (2) j , G (2) j } = A T r 2 ( θ (1) j , L T r ( θ (1) j ) , η T r 2 , λ T r 2 ) . becomes a ( τ ) = a ( τ − 1) − η T r 2 1 N K ( K ⊤ a ( τ − 1) − y ) + λ T r 2 a ( τ − 1) , a (0) = a (0) j , and we output the ξ T r 2 -th step of the ridge regression with kernel K where ( K ) in = σ ( ⟨ w (1) i , x n ⟩ + b (0) i ) . Gradient information is G (2) j = { g T r τ ,j } ξ T r 2 − 1 τ =0 = 1 N K ( K ⊤ a ( τ ) − y ) + λ T r 2 a ( τ ) ξ T r 2 − 1 τ =0 . Interestingly , one distilled data point is enough so that this a ( ξ T r 2 ) is a good solution for the problem in question. W e fix j = 0 . Theorem B.29. Under the assumptions of Theor em B.4 and ⟨ β , ˜ x (0) ⟩ is not too small with or der ˜ Θ( d − 1 / 2 ) , N ≥ ˜ Ω( d 4 ) J ∗ ≥ ˜ Ω( d 4 ) , η D 1 = ˜ Θ( √ d ) , and η R 1 = ˜ Θ( d ) ther e exists λ T r 2 such that if η T r 2 is sufficiently small and ξ T r 2 = ˜ Θ( { η T r 2 λ T r 2 } − 1 ) , then the final iterate of the teacher training at t = 2 output a parameter a ∗ = a ( ξ T r 2 ) that satisfies with pr obability at least 0.99, E x,y [ | f ( a ( ξ T r 2 ) ,W (1) ,b (0) ) ( x ) − y | ] − ζ ≤ ˜ O r d N + 1 √ L ∗ + 1 N 1 / 4 ! . B.5.2 Proof of Theor em B.29 Lemma B.30 (Lemma 23 from Nishikawa et al. ( 2025 ) restated) . Suppose ther e exists g ( x ) such that g ( x ) = P ⟨ β , x ⟩ + c ( x ) , where P = ˜ Θ(1) and c ( x ) = o d ( P log − 2 p +2 d ) . Then, ther e exists π ( a, b ) such that E a ∼ Unif {± 1 } ,b ∼ N (0 ,I ) [ π ( a, b ) σ ( v · g ( x ) + b )] − f ∗ ( x ) = o d (1) , and sup a,b | π ( a, b ) | = ˜ O (1) . Pr oof. The proof follows from Lemma 23 of Nishikaw a et al. ( 2025 ), and the fact that we can redefine π ( a, b ) defined for b ∼ [ − 1 , 1] to 1 | b |≤ 1 √ 2 π 2e − x 2 / 2 π ( a, b ) for b ∼ N (0 , I ) . Lemma B.31 (Lemma 24 from Nishikawa et al. ( 2025 ) restated) . Under the assumptions of Lemma B.30 , ther e exists a ‡ ∈ R m such that L ∗ X i =1 a ‡ i σ ( v i · g ( x ) + b j ) − f ∗ ( x ) = O L ∗− 1 2 + o d (1) , with high pr obability over x ∼ N (0 , I d ) , wher e ∥ a ‡ ∥ 2 = ˜ O (1 /L ∗ ) with high pr obability . Pr oof. This also follows from Nishikaw a et al. ( 2025 ) Lemma 24. Pr oof of Theor em B.29 . W e will first e v aluate conditions on η R 1 , η D 1 , N and J ∗ = LJ / 2 to satisfy conditions P = ˜ Θ(1) and c ( x ) = o d ( P log − 2 p +2 d ) of Lemma B.30 . From Lemma B.27 , we know that P = − η R 1 η D 1 ( ˜ y (0) ) 2 c d ⟨ β , ˜ x (0) ⟩ and c ( x ) = − η R 1 η D 1 ( ˜ y (0) ) 2 ⟨ ϵ, x ⟩ where ϵ = ˜ O d 1 2 N − 1 2 + d − 2 + d 1 2 J ∗ − 1 2 . If we set η D 1 = ˜ Θ( √ d ) and η R 1 = ˜ Θ( d ) , the first condition is fulfilled since ˜ y (0) is constant and c d ⟨ β , ˜ x (0) ⟩ = ˜ Θ( d − 3 / 2 ) by assumption. Now , from Corollary B.15 38 Dataset Distillation Efficiently Encodes Lo w-Dimensional Representations A P R E P RI NT and Lemma B.16 , ⟨ ϵ, x ⟩ can be decomposed into the ˜ O d 1 2 N − 1 2 + d − 2 + d 1 2 J ∗ − 1 2 coef ficients and the inner products ⟨ β , x ⟩ , ⟨ β ⊥ , x ⟩ , and ⟨ ˜ x, x ⟩ which are of O (log d ) with high probability . As a result, c ( x ) = ˜ O d 2 N − 1 2 + d − 1 2 + d 2 J ∗ − 1 2 , it suffices that N ≥ ˜ Ω( d 4 ) and J ∗ ≥ ˜ Ω( d 4 ) . From Lemma B.31 and Lemma 26 from Damian et al. ( 2022 ), we know that with high probability there exists a ‡ such that if θ = ( a ‡ , W (1) , b (0) ) , L T r ( θ ) − ζ 2 = O 1 /L ∗ + 1 / √ N . As result, by the equiv alence between norm constrained linear regression and ridge regression, there e xists λ > 0 such that if a ( ∞ ) = min a L ( a, W (1) , b (1) ) + λ 2 ∥ a ∥ 2 , then L ( a ( ∞ ) , W (1) , b (1) ) ≤ L ( a ‡ , W (1) , b (1) ) , and a ( ∞ ) ≤ ∥ a ‡ ∥ . By the same procedure as Lemma 14 by Damian et al. ( 2022 ), we can conclude that E x,y [ | f a ( T ) ,W (1) ( x ) − y | ] − ζ ≤ ˜ O r d N + 1 √ L ∗ + 1 N 1 / 4 ! B.6 t = 2 Student T raining Here, the student training for the distillation dataset { ( ˆ x (0) m , ˆ y (0) m ) } M 2 m =1 will be a one-step regression. I S j = A D 2 ( θ (1) j , L S ( θ (1) j ) , ξ S 2 , η S 2 , λ S 2 ) becomes ˜ a (1) j = a (0) j − η S 2 M 2 ˜ K ( ˜ K ⊤ a (0) j − ˆ y (0) ) = I − η S 2 M 2 ˜ K ˜ K ⊤ a (0) j + η S 2 M 2 ˜ K ˆ y (0) , where ( ˜ K ) im = σ ( ⟨ w (1) i , ˆ x (0) m ⟩ + b (0) i ) and ˆ y = ( ˆ y (0) 1 · · · ˆ y (0) M 2 ) ⊤ . Gradient information for the j -th initialization is { g S 0 ,j } = 1 M 2 ˜ K ( ˜ K ⊤ a (0) j − ˆ y (0) ) . B.7 t = 2 Distillation and Retraining Now , based on the teacher and student trainings above, we analyze the behavior of the distillation and retraining phases. These two phases are considered at the same time here. The initial state of the second dataset D S 2 is denoted as { ˆ x (0) m , ˆ y (0) m } M 2 m =1 . B.7.1 One-step gradient matching For the one-step gradient matching, ˆ y is updated as follows: ˆ y (1) = ˆ y (0) − η D 2 1 J J X j =1 ∇ ˆ y 1 − * ξ T r 2 − 1 X τ =0 g T r τ ,j , g S 0 ,j + , (17) where we set ξ D 2 = 1 , and λ D 2 = 0 . W e assume ˆ y (0) i = 1 J P j f θ (1) j ( ˆ x (0) i ) . 39 Dataset Distillation Efficiently Encodes Lo w-Dimensional Representations A P R E P RI NT At the retraining, we consider the regression setting similarly to the teacher training with a (0) = 0 and use the resulting D S 2 = { ˆ x (0) m , ˆ y (1) m } . θ (2) j ← A R 2 ( θ (1) j , L S ( θ (1) j ) , ξ R 2 , η R 2 , λ R 2 ) becomes, ˜ a ( τ +1) = ˜ a ( τ ) − η R 2 ∇ a 1 M 2 ∥ ˜ K ⊤ ˜ a ( τ ) − ˆ y (1) ∥ 2 , ˜ a (0) = a (0) , where λ R 2 = 0 and we output ˜ a ( ξ R 2 ) . Indeed, this ˜ a ( ξ R 2 ) can reconstruct the generalization ability of the teacher . Theorem B.32. Based on the Assumptions of Theorem B.29 , if { ˆ x (0) m } satisfies the r e gularity condition B.36 , η D 2 = M 2 η T r 2 , then for a sufficiently small η R 2 and ξ R 2 = ˜ Θ(( η R 2 σ min ) − 1 ) , where σ min > 0 is the smallest eigen value of ˜ K ⊤ ˜ K , the one-step gr adient matching ( 17 ) finds M 2 labels ˜ y (1) m so that E x,y [ | f (˜ a ( ξ R 1 ) ,W (1) ,b (0) ) ( x ) − y | ] − ζ ≤ ˜ O r d N + 1 √ L ∗ + 1 N 1 / 4 ! , The overall memory cost is O ( d + L ) . Pr oof. From the definition of g T r t,j , with T = ξ T r 2 , a ( T ) j = a ( T − 1) j − η T r 2 g T r T − 1 ,j = a (0) j − η T r 2 T − 1 X τ =0 g T r τ ,j , which implies T − 1 X τ =0 g T r τ ,j = − ( a ( T ) − a (0) ) /η T r 2 . Consequently , ˆ y (1) = ˆ y (0) − η D 2 ∇ ˆ y 1 − 1 J J X j =1 ⟨− ( a ( T ) j − a (0) j ) /η T r 2 , g S t ⟩ = 1 J X j ˜ K ⊤ a (0) j + η D 2 η T r 2 M 2 ˜ K ⊤ 1 J J X j =1 ( a ( T ) j − a (0) j ) = 1 J J X j =1 ˜ K ⊤ a ( T ) j . Now , gi ven our distilled dataset { ˜ x i , ˆ y (1) i } on retraining, a is updated following the teacher training which follo ws ˜ a ( t +1) = ˜ a ( t ) − η R 2 ∇ a n ∥ ˜ K ⊤ ˜ a ( t ) − ˆ y (1) ∥ 2 o , ˜ a (0) = 0 . By the implicit bias of gradient descent on linear regression, ˜ a ( ∞ ) = ( ˜ K ⊤ ) † ˆ y (1) , where ( K ⊤ ) † is the Moore-Penrose pseudoin verse. Since by Lemma B.34 , a ( T ) j is in col( K ) , Lemma B.37 implies that a ( T ) j is in col( ˜ K ) as well. Therefore, ˜ a ( ∞ ) = ( ˜ K ⊤ ) † y (1) = ( ˜ K ⊤ ) † ˜ K ⊤ 1 J P J j =1 a ( T ) j = 1 J P J j =1 a ( T ) j . Note that we can make a ( T ) j arbitrarily close to a ( ∞ ) j = a ( ∞ ) within ξ T r 2 = ˜ θ (( η T r 2 λ T r 2 ) − 1 ) steps since each a ( T ) j con ver ges to the same limit and a (0) j is bounded. For a finite iteration, we can approximate ˜ a ( ∞ ) by ˜ a ( ξ R 2 ) within an arbitrary accuracy with ξ R 2 = ˜ Θ(( η R 2 σ min ) − 1 ) , where σ min > 0 is the smallest eigen v alue of ˜ K ˜ K ⊤ . Therefore, we can reconstruct an ˜ a ( ξ R 2 ) that is dominated by the same error as Theorem B.29 . 40 Dataset Distillation Efficiently Encodes Lo w-Dimensional Representations A P R E P RI NT B.7.2 One-step performance matching For the one-step gradient matching, ˜ y is updated as follows: ˆ y ( τ +1) = ˆ y ( τ ) − η D 2 ∇ ˜ y 1 N ∥ K ˜ a (1) − y ∥ 2 + λ D 2 2 ∥ ˆ y ( τ ) ∥ 2 , ( τ = 0 , . . . , ξ D 2 − 1) . At the retraining, we consider the one-step regression setting follo wing the performance matching incentiv e. θ (2) j ← A R 2 ( θ (1) j , L S ( θ (1) j ) , ξ R 2 , η R 2 , λ R 2 ) becomes, ˜ a (1) = a (0) − η R 2 M 2 ˜ K ( ˜ K ⊤ ˜ a (0) − ˆ y ( ξ D 2 ) ) = I − η R 2 M 2 ˜ K ˜ K ⊤ a (0) + η R 2 M 2 ˜ K ˆ y ( ξ D 2 ) , where λ R 2 = 0 and we output ˜ a (1) ( ξ R 2 = 1 ). Indeed, this ˜ a (1) can reconstruct the generalization ability of the teacher . W e fix j = 0 . Theorem B.33. Based on the Assumptions of Theor em B.29 , if { ˆ x (0) m } satisfies the r e gularity condition B.36 , η S 2 = η R 2 , η D 2 is sufficiently small and ξ D 2 = ˜ Θ(( η D 2 λ D 2 ) − 1 ) then ther e exists a λ D 2 such that one-step performance matching can find with high pr obability a distilled dataset at the second step of distillation with E x,y [ | f (˜ a (1) ,W (1) ,b (0) ) ( x ) − y | ] − ζ ≤ ˜ O r d N + 1 √ L ∗ + 1 N 1 / 4 ! , wher e ˜ a (1) is the output of the r etraining algorithm at t = 2 with ˜ a (0) = 0 . The overall memory usage is only O ( d + L ) . Pr oof. In the one-step performance matching, we run one gradient update and then minimize the training loss. That is, a (1) = a (0) − η S 2 M 2 ˜ K ( ˜ K ⊤ a (0) − ˆ y ) = I − η S 2 M 2 ˜ K ˜ K ⊤ a (0) + η S 2 M 2 ˜ K ˆ y = η S 2 M 2 ˜ K ˆ y , where ( ˜ K ) ij = σ ( ⟨ w (1) i , ˜ x j ⟩ + b i ) . Since for the reference a (0) is set to 0 , The training loss becomes L (( a, (1) , W (1) , b (0) ) , D T r ) = 1 N ∥ f ( a (1) ,W (1) ,b (0) ) ( X ) − y ∥ 2 = 1 N K ⊤ η S 2 M 2 ˜ K ˆ y − y 2 , where ( K ) ij = σ ( ⟨ w (1) i , x j ⟩ + b i ) . From the training step of t = 2 , we know there e xists a ( ∞ ) such that 1 N ∥ f ( a ( ∞ ) ,W (1) ,b (0) ) ( X ) − y ∥ 2 = 1 N ∥ K ⊤ a ( ∞ ) − y ∥ 2 = ˜ O 1 /L ∗ + 1 / √ N . Similarly to Theorem B.29 , if we can assure there exists a ˆ y ∗ such that with high probability η S 2 M 2 ˜ K ˆ y ∗ = a ( ∞ ) , (18) then there exists a λ D 2 such that ˆ y ( ∞ ) = argmin ˆ y L T r (( a (1) , W (1) , b (0) ) , D T r ) + λ D 2 2 ∥ ˆ y ∥ 2 = argmin ˆ y L η S 2 M 2 ˜ K ˆ y , W (1) , b (0) , D T r + λ D 2 2 ∥ ˆ y ∥ 2 , which satisfies with L T r ( · ) : = L ( · , D T r ) L T r η S 2 M 2 ˜ K ˆ y ( ∞ ) , W (1) , b (0) ≤ L T r η S 2 M 2 ˜ K ˆ y ∗ , W (1) b (0) = L T r (( a ( ∞ ) , W (1) , b (0) )) . The right hand side is equal to = ˜ O 1 /L ∗ + 1 / √ N . It now suf fices to consider the condition for Equation ( 18 ) to be satisfied. Howe ver , since we want a ∈ span { σ ( W (1) ˆ x 1 + b (0) ) , . . . , σ ( W (1) ˆ x m + b (0) ) } , 41 Dataset Distillation Efficiently Encodes Lo w-Dimensional Representations A P R E P RI NT this is satisfied by Lemma B.37 and our assumption since a ( ∞ ) ∈ col( K ) by Lemma B.34 . As a result, the one-step PM can find a ˆ y ( ∞ ) by solving its distillation loss ˆ y ( ∞ ) = argmin ˆ y L T r (( a (1) , W (1) , b (0) )) + λ D 2 2 ∥ ˆ y ∥ 2 . that satisfies an error of ˜ O 1 /L ∗ + 1 / √ N . Since we can approximate ˆ y ( ∞ ) by ˆ y ( ξ D 2 ) within an arbitrary accuracy , by similarly proceeding as Theorem B.29 , by retraining a on { ˆ x (0) m , ˆ y ( ξ D 2 ) m } for one step, we obtain a ˜ a (1) such that E x,y [ | f (˜ a (1) ,W (1) ,b (0) ) ( x ) − y | ] − ζ ≤ ˜ O r d N + 1 √ L ∗ + 1 N 1 / 4 ! . B.7.3 Other Lemmas Lemma B.34. Consider the following ridge r egr ession of a ∈ R m for a given K ∈ R m × n , b ∈ R n and λ > 0 : a ( ∞ ) = argmin a L ( a ) : = argmin a ∥ K ⊤ a − y ∥ 2 + λ 2 ∥ a ∥ 2 . and the finite time iterate at time t = 0 , 1 , . . . a ( t +1) = a ( t ) − η ∇ L ( a ( t ) ) , a (0) = 0 . Then, both a ( ∞ ) and a ( t ) ar e in the column space of K . Pr oof. Let us define k j ( j = 1 , . . . , n ) as the columns of K and V : = span { k 1 , . . . , k n } . If we define the orthogonal complement of V as V ⊥ , then ∀ a ∈ R m , a = v + u, v ∈ V , u ∈ V ⊥ . Therefore, ∥ K ⊤ a − y ∥ 2 + λ 2 ∥ a ∥ 2 = ∥ K ⊤ ( v + u ) − y ∥ 2 + λ 2 ∥ v + u ∥ 2 = ∥ K ⊤ v − y ∥ 2 + λ 2 ∥ v ∥ 2 + λ 2 ∥ u ∥ 2 , since ⟨ u, v ⟩ = 0 ∀ v ∈ V , u ∈ V ⊥ . As a result, the minimization of the above objecti ve function requires u = 0 , which implies a ( ∞ ) ∈ col( K ) . Furthermore, a ( t +1) = (1 − η λ ) a ( t ) − η K ( K ⊤ a ( t ) − y ) directly shows that if a ( t ) ∈ col( K ) , then a ( t +1) ∈ col( K ) since the second term is already in the column space of K . Now , as we set a (0) = 0 , we obtain the desired result by mathematical induction. Corollary B.35. If K is a kernel with ( K ) ij = σ ( ⟨ w (1) i , x j ⟩ + b i ) , then for some c ∈ R n a ( ∞ ) i = n X j =1 c j σ ( ⟨ w (1) i , x j ⟩ + b i ) . B.8 Construction of Initializations of D S 2 The suf ficient condition for one-step GM and one-step PM to perfectly distill the information of the second layer as described in the abov e proofs is the following. Assumption B.36 (Regularity Condition) . The second distilled dataset D S 2 is initialized as { ( ˆ x (0) m , ˆ y (0) m ) } M 2 m =1 so that the kernel of f θ (1) after t = 1 , ( ˜ K ) im = σ ( ⟨ w (1) i , ˆ x (0) m ⟩ + b (0) i ) has the maximum attainable rank, and its memory cost does not exceed ˜ Θ( r 2 d + L ) . When D : = { i | w (1) i = 0 } , the maximum attainable rank is | D | + 1 if ther e exists an i 0 ∈ [ L ] \ D such that b i 0 > 0 , and | D | otherwise . 6 6 W e may accept a memory cost up to ˜ Θ( r 2 d + p oly ( r ) L ) . Since d ≫ r in our theory , this will still lead to smaller storage cost than the whole network. 42 Dataset Distillation Efficiently Encodes Lo w-Dimensional Representations A P R E P RI NT Lemma B.37. Consider the two kernels K ∈ R L × N and ˜ K ∈ R L × M 2 ( L ≥ 2 ) wher e ( K ) in = σ ( ⟨ w (1) i , x n ⟩ + b i ) , ( ˜ K ) im = σ ( ⟨ w (1) i , ˆ x m ⟩ + b i ) , and w (1) i = ca i 1 M 1 P m σ ′ ( ⟨ w (0) i , ˜ x (1) m ⟩ ) ˜ x (1) m ( c is a constant) with a i ∼ {− 1 , 1 } and w (0) i ∼ U ( S d − 1 ) . If the r egularity condition B.36 is satisfied and a ∗ ∈ col( K ) , then a ∗ ∈ col( ˜ K ) . Pr oof. a ∗ ∈ col( ˜ K ) is equiv alent to stating that there is a ˜ y ∈ R M such that a ∗ i = M 2 X m =1 ˆ y m σ ( ⟨ w (1) i , ˆ x m ⟩ + b i ) , ∀ i = 1 , . . . , L. (19) W e define the set D = { i | w (1) i = 0 } . Then for i ∈ D , Equation ( 19 ) becomes a ∗ i = M 2 X m =1 ˆ y m σ ( b i ) = σ ( b i ) M 2 X m =1 ˆ y m . Therefore, for Equation ( 19 ) to be satisfied, we need at least that α ∗ ∈ span { σ ( b ) } for the indices not in D . Howe ver , this follows from the assumption of a ∗ ∈ col( K ) as for i / ∈ D a ∗ i = n X j =1 c j σ ( ⟨ w (1) i , x j ⟩ + b i ) = n X j =1 c j σ ( b i ) = σ ( b i ) n X j =1 c j . Since we can rearrange ˜ K such that the rows in D are grouped to the beginning, Equation ( 19 ) can be simplified to the first L ∗ : = | D | rows ˜ K [ L ∗ ] (plus one constant non-zero row if such a ro w exists). a ∗ i = M X m =1 ˜ y m σ ( ⟨ w (1) i , ˜ x m ⟩ + b i ) = m X m =1 ˜ y m σ ( ca i σ ′ ( ⟨ w (0) i , ˜ x (1) ⟩ ) ⟨ ˜ x (1) , ˜ x m ⟩ + b i ) , ∀ i = 1 , . . . , L ∗ . (20) It suffices to consider the full ro w rank condition of ˜ K [ L ∗ ] . This is satisfied by the regularity condition. While randomly sampling ˆ x (0) m from a continuous distribution may be a relatively safe strategy to achiev e Assump- tion B.36 , this would require too much memory storage. Here, we propose a construction with reasonable properties that works well in practice and, at the same time, provides low memory cost. W e start from the observation that we can find one v ∈ R d such that ⟨ w (1) i , v ⟩ = 0 for all i ∈ D = { i | w (1) i = 0 } . Then, σ ( ⟨ w (1) i , s m v ⟩ + b i ) can be written as σ ( cα i s m + b i ) for c ∈ R \ { 0 } , α ∈ R L and b ∈ R L . W e provide a construction of { s m } so that { ˆ x (0) m } = { s m v } provides some guaranteed behavior and achie ves the best possible rank for this configuration. This can be stated as follows. Lemma B.38. F or each s ∈ R , we define v ( s ) ∈ R L as v i ( s ) = σ ( c α i s + b i ) , i = 1 , . . . , L, wher e c ∈ R \ { 0 } , α i ∈ R and b ∈ R L . F or any finite set S = { s 1 , . . . , s M 2 } ⊂ R define K ( S ) ∈ R L × M 2 by K ( S ) : = [ v ( s 1 ) · · · v ( s m )] . Mor eover , D : = { i : α i = 0 } , L ∗ : = | D | , and assume there e xists an i 0 with α i 0 = 0 and b i 0 > 0 . F or each i ∈ D , we define the hinge t i : = − b i cα i , which ar e all differ ent almost sur ely . Let us reor der them as { τ 1 < · · · < τ L ∗ } and define the open intervals I 0 : = ( −∞ , τ 1 ) , I k : = ( τ k , τ k +1 ) ( k = 1 , . . . , L ∗ − 1) , I L ∗ : = ( τ L ∗ , ∞ ) . Now , for each k = 1 , . . . , L ∗ − 1 we pr epare two points s (1) k : = 3 τ k + τ k +1 4 , s (2) k : = τ k + 3 τ k +1 4 , and two points in each unbounded interval C left : = { τ 1 − ¯ τ , τ 1 − 2 ¯ τ } , C right : = { τ L ∗ + ¯ τ , τ L ∗ + 2 ¯ τ } , 43 Dataset Distillation Efficiently Encodes Lo w-Dimensional Representations A P R E P RI NT wher e ¯ τ : = 1 + max 1 ≤ j ≤ L ∗ | τ j | . Let C ′ be the union of all these points { s (1) 1 , s (2) 1 , . . . , s (1) L ∗ − 1 , s (2) L ∗ − 1 } ∪ C left ∪ C right and consider { s m } = C = C ′ ∪ ( − C ′ ) . Then, for every finite S ⊂ R , rank( K ( S )) ≤ L ∗ + 1 . Mor eover , the matrix K ( C ) attains the maximal achie vable rank rank( K ( C )) = max S :finite rank( K ( S )) . Consequently , either rank( K ( C )) = L ∗ + 1 (and rank L ∗ + 1 is attainable), or else rank( K ( C )) < L ∗ + 1 (and rank L ∗ + 1 is impossible for this specific ( a, b, c ) ). The memory cost of C is Θ( L ∗ ) = O ( L ) (or sufficiently Θ( L )) . If i 0 does not exist, the whole statement is valid by r eplacing L ∗ + 1 by L ∗ . Pr oof. If α i = 0 , then v i ( s ) = σ ( b i ) is independent of s . As a result, all rows with α i = 0 span a subspace of dimension of 1 , since there exist an inde x i 0 so that α i 0 = 0 and b i 0 > 0 ., and rank( K ( S )) ≤ L ∗ + 1 for an y S . Fix an interval I k . For any acti ve index i ∈ D , the affine function cα i s + b i can change sign only at s = t i , and by construction no hinge lies inside I k . Therefore, on I k , each coordinate v i ( s ) = σ ( cα i s + b i ) is either identically 0 or equals the affine function cα i s + b i . Hence, there exist vectors u k , w k ∈ R L such that for all s ∈ I k , v ( s ) = u k + s w k . In other words, two points suffice to span the whole interv al. Indeed, consider s, s ′ ∈ I k with s = s ′ . From the affine form abov e, w k = v ( s ′ ) − v ( s ) s ′ − s , u k = v ( s ) − s w k . As a result, for any t ∈ I k , v ( t ) = u k + tw k ∈ span { v ( s ) , v ( s ′ ) } . This also implies that for V := span { v ( s ) : s ∈ R } and V C := span { v ( s ) : s ∈ C } , V = V C . Finally , for any finite S , the columns of K ( S ) are vectors v ( s ) with s ∈ S , so col( K ( S )) ⊆ V , which means rank( K ( S )) ≤ dim( V ) . On the other hand, col( K ( C )) = V C = V , so rank( K ( C )) = dim( V ) . Therefore rank( K ( C )) = max S rank( K ( S )) . Since max S rank( K ( S )) ≤ L ∗ + 1 and K ( C ) achiev es this maximum, either rank( K ( C )) = L ∗ + 1 or else rank L ∗ + 1 is impossible for the gi ven ( a, b, c ) . Corollary B.39. The overall memory comple xity of C is Θ( L ) . Based on the abov e lemma, we propose two heuristic strategies for the choice of v . • W e prepare M 1 candidates of v as { v i } i ∈ [ M 1 ] = { ˜ x (1) m } m ∈ [ M 1 ] . In other words, we reuse distilled data of D S 1 . This does not increase the memory cost. For each v i , we apply Lemma B.38 , to obtain a set of scalars customized for v i as C i = { s k,i } and define { ˆ x (0) m } : = { s k,i v i } . The ov erall memory cost is Θ( M 1 L ) = Θ(p oly(r)L) . • A more compact choice is to compute one common C = { s k } for all { v i } m ∈ [ M 1 ] = { ˜ x (1) m } m ∈ [ M 1 ] . Therefore, we apply Lemma B.38 to the representative choice of P i ∈ [ M 1 ] v i / M 1 , and define { ˆ x (0) m } : = { s k v i } . This requires only a memory complexity of Θ( L ) . W e call this the compact construction. W e report experiments in Figure 3 and T ables 2 , 3 and 4 to illustrate that the above constructions satisfy our re gularity condition B.36 , suggesting that compact distillation is also possible for the second phase of Algorithm 1 . W e show this by comparing 1) the rank of ˜ K , where ( ˜ K ) im = σ ( ⟨ w (1) i , ˆ x (0) m ⟩ + b i ) and { ˆ x (0) m } is defined following our proposed constructions, with the maximum attainable rank defined in the regularity condition B.36 , and 2) test loss of f ˜ θ ∗ (output of retraining at t = 2 ) with that of f θ ∗ (output of teacher training at t = 2 ). 7 GM was used in the distillation phase of t = 2 . T able 2 presents the result for the single index models with increasing width of the tw o-layer neural network. Furthermore, Figure 3 and T ables 3 and 4 share the behavior for multi-index models with r = 3 or r = 10 with increasing size of D S 1 . The remaining experimental setup is exactly the same as Experiment 5.1 . W e can observe that in both settings the suggested formations of { ˆ x (0) m } consistently achiev e an almost 100 % reproduc- tion accuracy . Notably , the proposed compact construction behav es more stably , with a lo wer v ariability and a closer percentage around 100. 7 W e compare these two outputs as our initialization of ˆ x (0) should reconstruct the performance of the model with parameters θ ∗ as stated in Theorems B.32 and B.33 . 44 Dataset Distillation Efficiently Encodes Lo w-Dimensional Representations A P R E P RI NT T able 2: Rank rate and MSE reconstruction rate for single inde x model ( r = 1 ) case with d = 10 . Note that our two methods are the same when r = 1 . L = 10 L = 100 L = 500 L = 1000 Rank Rate ( % ) 100 . 0 ± 0 . 0 100 . 0 ± 0 . 0 100 . 0 ± 0 . 0 99 . 6 ± 0 . 4 MSE Reconstruction Rate ( % ) 100 . 0 ± 0 . 0 100 . 0 ± 0 . 0 100 . 0 ± 0 . 0 100 . 0 ± 0 . 0 Figure 3: Reconstruction percentage when using D S 2 with different size ( 1 , 10 , 50 , 100 ) constructed following Lemma B.38 and its compact v ariant with respect to the MSE of teacher training t = 2 (MSE loss) and the maximal attainable rank L ∗ + 1 (Rank), for r = 3 (left) and r = 10 (right). d was set to 100 . C Proof of Main Theor ems: Single Index Models (for ReLU Acti vation Function) C.1 W ell-defined Gradient Matching for ReLU In this appendix, we consider a gradient matching algorithm that is well-defined for student gradient information formulated with ReLU activ ation function. As ReLU is inv ariant to scaling, we can consider without loss of generality that all weights are normalized ∥ w i ∥ = 1 , which means that w i ∼ U ( S d − 1 ) . The idea is to look back at Lemma B.5 and define a nov el update rule that is well-defined in the case h = σ (where σ = ReLU). W e only sho w the result for the single index model as the proof for multi-inde x model follows similarly . Definition C.1 (W ell-defined Gradient Matching for ReLU) . W e defined the gradient update of ˜ x (1) as follows: ˜ x (1) = − η D 1 ˜ y (0) ( G + ϵ ) , wher e G = 1 LJ X i,j g i,j σ ′ ( ⟨ w (0) i,j , ˜ x ⟩ ) ϵ = 1 LJ X i,j ( 1 N X n ϵ n x n σ ′ ( ⟨ w (0) i,j , x n ⟩ ) ) σ ′ ( ⟨ w (0) i,j , ˜ x ⟩ ) , with g i,j = 1 N P n ˆ f ∗ ( x n ) x n σ ′ ( ⟨ w (0) i,j , x n ⟩ ) . C.2 Analysis Since in Appendix B , we always treated h ′ and h ′′ separately , we can prov e all lemmas and theorems by analogy , substituting the case h ′ = σ ′ is bounded by 1 and h ′′ = 0 . The corresponding population gradient becomes as follows. Definition C.2. W e define the population gradient of G as ˆ G : = E w h E x h ˆ f ∗ ( x ) xσ ′ ( ⟨ w , x ⟩ ) i σ ′ ( ⟨ w , ˜ x ⟩ ) i , wher e ˜ x : = ˜ x (0) . 45 Dataset Distillation Efficiently Encodes Lo w-Dimensional Representations A P R E P RI NT T able 3: Numerical details of Figure 3 for the first construction of { ˆ x (0) m } . M 1 = 1 L = 10 L = 50 L = 100 Rank Rate ( % ) 99 . 7 ± 0 . 4 100 . 0 ± 0 . 0 100 . 0 ± 0 . 0 100 . 0 ± 0 . 0 MSE Reconstruction Rate ( % ) 100 . 0 ± 0 . 0 100 . 0 ± 0 . 0 100 . 0 ± 0 . 0 100 . 0 ± 0 . 0 Rank Rate r = 10 ( % ) 99 . 1 ± 0 . 8 100 . 0 ± 0 . 0 100 . 0 ± 0 . 0 100 . 0 ± 0 . 0 MSE Reconstruction Rate r = 10 ( % ) 100 . 0 ± 0 . 0 100 . 0 ± 0 . 0 100 . 0 ± 0 . 0 100 . 0 ± 0 . 0 T able 4: Numerical details of Figure 3 for the second compact construction of { ˆ x (0) m } . L = 10 L = 100 L = 500 L = 1000 Rank Rate r = 3 ( % ) 99 . 7 ± 0 . 4 100 . 0 ± 0 . 0 100 . 0 ± 0 . 0 100 . 0 ± 0 . 0 MSE Reconstruction Rate r = 3 ( % ) 100 . 0 ± 0 . 0 100 . 0 ± 0 . 0 100 . 0 ± 0 . 0 100 . 0 ± 0 . 0 Rank Rate r = 10 ( % ) 99 . 1 ± 0 . 8 100 . 0 ± 0 . 0 100 . 0 ± 0 . 0 100 . 0 ± 0 . 0 MSE Reconstruction Rate r = 10 ( % ) 100 . 0 ± 0 . 0 100 . 0 ± 0 . 0 100 . 0 ± 0 . 0 100 . 0 ± 0 . 0 This leads to the following bound. Theorem C.3. Under Assumptions 3.1 , 3.3 , 3.4 and 3.6 , with high pr obability , ˆ G = c d ⟨ β , ˜ x ⟩ β + ˜ O d 1 2 N − 1 2 + d − 2 , wher e c d = Θ d − 1 is a constant coefficient. Pr oof. This can be proved by reusing Lemma B.16 . The concentration of the empirical gradient around the population gradient can be also computed similarly . Theorem C.4. Under Assumptions 3.1 , 3.3 , 3.4 , 3.6 , and 3.8 and Definition C.2 , and Definition C.2 , G = c d ⟨ β , ˜ x ⟩ β + ˜ O d 1 2 N − 1 2 + d − 2 + d 1 2 J ∗− 1 2 . Lemma C.5. Under Assumptions 3.1 , 3.3 , 3.4 , 3.6 , and 3.8 and Definition C.2 , and Definition C.2 , with high pr obability , ϵ = ˜ O d 1 2 N − 1 2 , wher e ϵ is defined in Cor ollary B.7 . Therefore, this well-defined distillation also captures the latent structure of the original problem and translates it into the input space. Theorem C.6. Under Assumptions 3.1 , 3.3 , 3.4 , 3.6 , and 3.8 and Definition C.2 , when D 0 = { ( ˜ x (0) , ˜ y (0 ) } , where ˜ x (0) ∼ U ( S d − 1 ) , the first step of distillation gives ˜ x (1) such that ˜ x (1) = − η D 1 ˜ y (0) c d ⟨ β , ˜ x (0) ⟩ β + ˜ O d 1 2 N − 1 2 + d − 2 + d 1 2 J ∗− 1 2 , wher e c d = ˜ O d − 1 , J ∗ = LJ / 2 . The remainder of the analysis also follows Appendix B . Especially , for the teacher training at t = 2 , the following theorem holds. Theorem C.7. Under the assumptions of Theorem B.4 , ⟨ β , ˜ x (0) ⟩ is not too small with order ˜ Θ( d − 1 / 2 ) , N ≥ ˜ Ω( d 4 ) and J ∗ ≥ ˜ Ω( d 4 ) , there exists λ T r 2 such that if η T r 2 is sufficiently small and ξ T r 2 = ˜ Θ( { η T r 2 λ T r 2 } − 1 ) so that the final iterate of the teac her training at t = 2 output a par ameter a ∗ = a ( ξ T r 2 ) that satisfies with pr obability at least 0.99, E x,y [ | f ( a ( ξ T r 2 ) ,W (1) ,b (1) ) ( x ) − y | ] − ζ ≤ ˜ O r d N + 1 √ L ∗ + 1 N 1 / 4 ! . W e defer the readers to Appendix B.7 for the remainder of the proof, which does not change for this appendix. 46 Dataset Distillation Efficiently Encodes Lo w-Dimensional Representations A P R E P RI NT D Proof of Main Theor ems: Multi-index Models (General Case) In this appendix, we pro ve our main result for multi-inde x models. As ReLU is in variant to scaling, we can consider without loss of generality that all weights are normalized ∥ w i ∥ = 1 , which means that w i ∼ U ( S d − 1 ) . Throughout this section, we will repeatedly refer to statements and proofs of Appendix B to keep the presentation clear and av oid redundancy . D.1 Proof Flow The proof flow mainly follo ws that of Appendix B and is constituted of three parts: the distillation at t = 1 , the teacher learning at t = 2 and the distillation at t = 2 . The remainder of the analysis is the same as Appendix B.7 . D.2 Concrete F ormulation of Theorem 4.2 W e first present our main Theorem for this appendix which is the analogue of Theorem B.29 in Appendix B . Theorem D .1. Under Assumptions 3.1 , 3.3 , 3.4 , 3.6 , 3.7 and 3.8 , with par ameters η D 1 = ˜ Θ( √ d ) , η R 1 = ˜ Θ( r − 1 √ d ) , λ R 1 = 1 /η R 1 , λ D 1 = 1 /η D 1 , M ≥ ˜ Ω( ˆ κ 2 p λ 2 min λ 2 max r 2 ) , d ≥ ˜ Ω( ˆ r 2 p r 2 ∨ r 3 λ 2 min ˆ κ 2 p ) , N ≥ ˜ Ω( ˆ r 2 p d 4 ∨ r λ 2 min ˆ κ 2 p d 4 ∨ d 4 ) , J ∗ ≥ ˜ Ω( ˆ r 2 p d 4 ∨ rλ 2 min ˆ κ 2 p d 4 ∨ d 4 ) , where ˆ r p = r 4 p +1 / 2 ˆ κ 4 p +1 p λ 4 p +1 min λ 8 p +1 max and ˆ κ p = max 1 ≤ i ≤ 4 k, 1 ≤ k ≤ p κ k/i , there exists λ T r 2 such that if η T r 2 is sufficiently small and T = ˜ Θ( { η T r 2 λ T r 2 } − 1 ) so that the final iter ate of the teacher tr aining at t = 2 output a par ameter a ( ξ T r 2 ) that satisfies with pr obability at least 0.99, E x,y [ | f ( a ( ξ T r 2 ) ,W (1) ,b (1) ) ( x ) − y | ] − ζ ≤ ˜ O r dr 3 p κ 2 p N + r r 3 p κ 2 p L ∗ + 1 N 1 / 4 ! . D.3 t = 1 Distillation Based on our results for single index models, we can directly start from the formulation of population gradient which we remind below . The main difference lies in the number of M 1 required, but this only comes into play in Section D.4 . In this section, we thus only consider the behavior of one ˜ x (0) . Definition D.2. W e define the population gradient of G as ˆ G : = E w h E x h ˆ f ∗ ( x ) xσ ′ ( ⟨ w , x ⟩ ) i h ′ ( ⟨ w , ˜ x ⟩ ) i + E w h w h ′′ ( ⟨ w , ˜ x ⟩ ) D E x h ˆ f ∗ ( x ) xσ ′ ( ⟨ w , x ⟩ ) i , ˜ x Ei , wher e ˜ x : = ˜ x (0) m . By Lemma B.14 , this can be reformulated as follows: Corollary D .3. Under Assumption 3.1 , with high pr obability , ˆ G = p − 1 X k =1 c k +1 k ! E w h ˆ C k +1 ( w ⊗ k ) h ′ ( ⟨ w , ˜ x ⟩ ) i + p X k =2 c k +2 k ! E w h w ˆ C k ( w ⊗ k ) h ′ ( ⟨ w , ˜ x ⟩ ) i + p − 1 X k =1 c k +1 k ! E w h w h ′′ ( ⟨ w , ˜ x ⟩ ) D ˆ C k +1 ( w ⊗ k ) , ˜ x Ei + p X k =2 c k +2 k ! E w h w h ′′ ( ⟨ w , ˜ x ⟩ ) ˆ C k ( w ⊗ k ) ⟨ w , ˜ x ⟩ i + ˜ O r d N ! . Let us now compute each e xpectation. W e define each term as follows: T ( k ) 1 : = E w h ˆ C k +1 ( w ⊗ k ) h ′ ( ⟨ w , ˜ x ⟩ ) i , T ( k ) 2 : = E w h w ˆ C k ( w ⊗ k ) h ′ ( ⟨ w , ˜ x ⟩ ) i , T ( k ) 3 : = E w h w h ′′ ( ⟨ w , ˜ x ⟩ ) ⟨ ˆ C k +1 ( w ⊗ k ) , ˜ x ⟩ i , T ( k ) 4 : = E w h w h ′′ ( ⟨ w , ˜ x ⟩ ) ˆ C k ( w ⊗ k ) ⟨ w , ˜ x ⟩ i . 47 Dataset Distillation Efficiently Encodes Lo w-Dimensional Representations A P R E P RI NT Lemma D.4. Under Assumptions 3.1 , T ( k ) 1 = B ⌊ k/ 2 ⌋ X l =0 k 2 l c l ( d ) C k +1 ( S k,l ) I k − 2 l,l [ h ′ ] , T ( k ) 2 = ˜ x ⌊ k/ 2 ⌋ X l =0 k 2 l c l ( d ) C k ( S k,l ) I k − 2 l +1 ,l [ h ′ ] + B ⊥ ⌊ ( k − 1) / 2 ⌋ X l =0 k 2 l + 1 C l c l +1 ( d ) C k ( ¯ S k,l ) I k − 2 l − 1 ,l +1 [ h ′ ] , T ( k ) 3 = ˜ x ⌊ k/ 2 ⌋ X l =0 k 2 l c l ( d ) ˜ C k +1 ( S k,l ) I k − 2 l +1 ,l [ h ′′ ] + B ⊥ ⌊ ( k − 1) / 2 ⌋ X l =0 k 2 l + 1 C l c l +1 ( d ) ˜ C k +1 ( ¯ S k,l ) I k − 2 l − 1 ,l +1 [ h ′′ ] , T ( k ) 4 = ˜ x ⌊ k/ 2 ⌋ X l =0 k 2 l c l ( d ) C k ( S k,l ) I k − 2 l +2 ,l [ h ′′ ] + B ⊥ ⌊ ( k − 1) / 2 ⌋ X l =0 k 2 l + 1 C l c l +1 ( d ) C k ( ¯ S k,l ) I k − 2 l,l +1 [ h ′′ ] , wher e B ⊥ = P B , P = I d − ˜ x ˜ x ⊤ , I p 1 ,p 2 [ i ] = R 1 − 1 t p 1 (1 − t 2 ) p 2 i ( t ) f d ( t )d t , f d ( t ) = Γ( d 2 ) √ π Γ( d − 1 2 ) (1 − t 2 ) d − 3 2 , S k,l : = Sym(( B ⊤ ˜ x ) ⊗ k − 2 l ⊗ Σ ⊗ l ) with ˆ v ∼ N (0 , Σ) , ¯ S k,l : = Sym(( B ⊤ ˜ x ) ⊗ k − 2 l − 1 ⊗ Σ ⊗ l ) , ˜ C k +1 = C k +1 ( b ) and Σ = B ⊤ ( I − ˜ x ˜ x ⊤ ) B . Pr oof. In this proof, we simplify the notation by treating T ( k ) i as T i ( i = 1 , 2 , 3 , 4 ). Similarly to the single index case, we use a change of v ariable. Let t = ⟨ w , ˜ x ⟩ , then we can write w = t ˜ x + √ 1 − t 2 v where v ∼ U ( { v | v ∈ S d − 1 , ⟨ v , ˜ x ⟩ = 0 } ) ∼ = U ( S d − 2 ) . Since ∥ ˜ x ∥ 2 = 1 , the distribution of t is can be shown to be f d ( t ) = Γ( d 2 ) √ π Γ( d − 1 2 ) (1 − t 2 ) d − 3 2 . Moreov er , ⟨ β , w ⟩ = st + p 1 − t 2 ⟨ β ⊥ , v ⟩ , where s = ⟨ β , ˜ x ⟩ , and β ⊥ = β − ⟨ β , ˜ x ⟩ ˜ x . W e also define a : = B ⊤ w = bt + √ 1 − t 2 η , where b : = B ⊤ ˜ x and η : = B ⊤ v , P : = I d − ˜ x ˜ x ⊤ , B ⊥ : = P B , Σ : = B ⊤ P B = I r − bb ⊤ . By Lemma B.11 , since ˆ C k = B ⊗ k C k , ˆ C k ( w ⊗ k ) = C k ( a ⊗ k ) and ˆ C k +1 ( w ⊗ k ) = B C k +1 ( a ⊗ k ) . Now , let us first consider T 1 = E t,v B C k +1 ( a ⊗ k ) h ′ ( t ) . Since C k +1 is a symmetric tensor , C k +1 ( a ⊗ k ) = C k +1 (Sym( a ⊗ k )) = C k +1 k X l =0 k l t k − l (1 − t 2 ) l/ 2 Sym( b ⊗ k − l ⊗ η ⊗ l ) ! . Therefore, by taking the expectation o ver v and by symmetry , E v [ C k +1 ( a ⊗ k ) | t ] = C k +1 ⌊ k/ 2 ⌋ X l =0 k 2 l t k − 2 l (1 − t 2 ) l Sym( b ⊗ k − 2 l ⊗ E v [ η ⊗ 2 l ]) . E v [ η ⊗ 2 l ] can be computed by using Lemma 45 from Damian et al. ( 2022 ) as E v [ η ⊗ 2 l ] = E v [( B ⊤ v ) ⊗ 2 l ] = ( B ⊤ ) ⊗ 2 l E v [ v ⊗ 2 l ] = c l ( d )( B ⊤ ) ⊗ 2 l E g [( P g ) ⊗ 2 l ] = c l ( d ) E ˆ v [ ˆ v ⊗ 2 l ] = : c l ( d ) S l , where we used that fact that v = P g /ν with ν ∼ χ ( d ) and g ∼ N (0 , I d ) and defined ˆ v ∼ N (0 , Σ) . T o summarize, we obtain, T 1 = B ⌊ k/ 2 ⌋ X l =0 k 2 l c l ( d ) C k +1 ( S k,l ) Z 1 − 1 t k − 2 l (1 − t 2 ) l h ′ ( t ) f d ( t )d t, where S k,l : = Sym( b ⊗ k − 2 l ⊗ S l ) . 48 Dataset Distillation Efficiently Encodes Lo w-Dimensional Representations A P R E P RI NT Next, by proceeding similarly , T 2 = E t,v ( t ˜ x + √ 1 − t 2 v ) C k ( a ⊗ k ) h ′ ( t ) . W e can divide this into two terms where T 2 , 1 : = E t,v tC k ( a ⊗ k ) h ′ ( t ) ˜ x, T 2 , 2 : = E t,v h p 1 − t 2 v C k ( a ⊗ k ) h ′ ( t ) i . By analogy from T 1 , we immediately obtain T 2 , 1 = ˜ x ⌊ k/ 2 ⌋ X l =0 k 2 l c l ( d ) C k ( S k,l ) Z 1 − 1 t k − 2 l +1 (1 − t 2 ) l h ′ ( t ) f d ( t )d t. W e now focus on T 2 , 2 . E v v C k ( a ⊗ k ) = ⌊ ( k − 1) / 2 ⌋ X l =0 k 2 l + 1 t k − 2 l − 1 (1 − t 2 ) (2 l +1) / 2 E v v C k Sym( b ⊗ k − 2 l − 1 ⊗ η ⊗ 2 l +1 ) . W e define the tensor V l : = C k Sym( b ⊗ k − 2 l − 1 ) . Since E v [ v V l ( η ⊗ 2 l +1 )] = E v [ v ⊗ η ⊗ 2 l +1 ] ( V l ) , we obtain E v v C k ( a ⊗ k ) = ⌊ ( k − 1) / 2 ⌋ X l =0 k 2 l + 1 t k − 2 l − 1 (1 − t 2 ) (2 l +1) / 2 E v [ v ⊗ η ⊗ 2 l +1 ] ( V l ) . Let a ∈ [ d ] and i 1 , . . . , i 2 l +1 ∈ [ r ] . Put j 0 = a and j t = b t for t ≥ 1 . Using η i = P d b =1 B bi v b , E [ v a η i 1 · · · η i 2 l +1 ] = X b 1 ,...,b 2 l +1 2 l +1 Y t =1 B b t i t E [ v a v b 1 · · · v b 2 l +1 ] = c l +1 ( d ) X π ∈P 2 l +2 X b 1 ,...,b 2 l +1 2 l +1 Y t =1 B b t i t Y ( p,q ) ∈ π P j p j q , where P 2 l +1 is the set of all permutations for 2 l + 1 elements and we used Lemma 36 from Damian et al. ( 2022 ). For one fixed π , index 0 is paired with exactly one s ∈ { 1 , . . . , 2 l + 1 } . The factor in volving b s is B b s i s P ab s , whose sum ov er b s equals ( P B ) ai s . Each remaining pair ( p, q ) contrib utes X b p ,b q ( B ) b p i p P b p b q ( B ) b q i q = ( B ⊤ P B ) i p i q = Σ i p i q . Since the sum over π is equiv alent to choosing the partner s of index 0 (there are 2 l + 1 choices) and a pairing π ′ of the remaining 2 l indices, we can conclude E v [ v ⊗ η ⊗ 2 l +1 ] = C l c l +1 ( d )Sym( P B ⊗ Σ ⊗ l ) , where C l is a constant that only depends on l . Putting back to our equation, we hav e E v v C k ( a ⊗ k ) = ⌊ ( k − 1) / 2 ⌋ X l =0 k 2 l + 1 t k − 2 l − 1 (1 − t 2 ) (2 l +1) / 2 E v [ v ⊗ η ⊗ 2 l +1 ] ( V l ) = ⌊ ( k − 1) / 2 ⌋ X l =0 k 2 l + 1 C l c l +1 ( d ) t k − 2 l − 1 (1 − t 2 ) (2 l +1) / 2 Sym( P B ⊗ Σ ⊗ l ) ( V l ) = ⌊ ( k − 1) / 2 ⌋ X l =0 k 2 l + 1 C l c l +1 ( d ) t k − 2 l − 1 (1 − t 2 ) (2 l +1) / 2 P B ( C k (Sym( b ⊗ k − 2 l − 1 ⊗ Σ ⊗ l ))) = ⌊ ( k − 1) / 2 ⌋ X l =0 k 2 l + 1 C l c l +1 ( d ) t k − 2 l − 1 (1 − t 2 ) (2 l +1) / 2 P B ( C k ( ¯ S k,l )) , where we defined ¯ S k,l : = Sym( b ⊗ k − 2 l − 1 ⊗ Σ ⊗ l ) . Combining with the definition of T 2 . 1 , we obtain T 2 , 2 = P U ⌊ ( k − 1) / 2 ⌋ X l =0 k 2 l + 1 C l c l +1 ( d ) C k ( ¯ S k,l ) Z 1 − 1 t k − 2 l − 1 (1 − t 2 ) l +1 h ′ ( t ) f d ( t )d t. 49 Dataset Distillation Efficiently Encodes Lo w-Dimensional Representations A P R E P RI NT Next, we consider T 3 . Actually , since ⟨ ˆ C k +1 ( w ⊗ k ) , ˜ x ⟩ = ⟨ C k +1 ( a ⊗ k ) , b ⟩ = ˜ C k +1 ( a ⊗ k ) , where ˜ C k +1 = C k +1 ( b ) , we can directly reuse the result of T 2 , leading to T 3 = ˜ x ⌊ k/ 2 ⌋ X l =0 k 2 l c l ( d ) ˜ C k +1 ( S k,l ) Z 1 − 1 t k − 2 l +1 (1 − t 2 ) l h ′′ ( t ) f d ( t )d t + P B ⌊ ( k − 1) / 2 ⌋ X l =0 k 2 l + 1 C l c l +1 ( d ) ˜ C k +1 ( ¯ S k,l ) Z 1 − 1 t k − 2 l − 1 (1 − t 2 ) l +1 h ′′ ( t ) f d ( t )d t = ˜ x ⌊ k/ 2 ⌋ X l =0 k 2 l c l ( d ) ⟨ C k +1 ( S k,l ) , B ⊤ ˜ x ⟩ Z 1 − 1 t k − 2 l +1 (1 − t 2 ) l h ′′ ( t ) f d ( t )d t + P B ⌊ ( k − 1) / 2 ⌋ X l =0 k 2 l + 1 C l c l +1 ( d ) ⟨ C k +1 ( ¯ S k,l ) , B ⊤ ˜ x ⟩ Z 1 − 1 t k − 2 l − 1 (1 − t 2 ) l +1 h ′′ ( t ) f d ( t )d t. Finally , T 4 = E t,v w h ′′ ( t ) tC k ( a ⊗ k ) t , this is again T 2 with an additional factor of t . As result, by analogy , T 4 = ˜ x ⌊ k/ 2 ⌋ X l =0 k 2 l c l ( d ) C k ( S k,l ) Z 1 − 1 t k − 2 l +2 (1 − t 2 ) l h ′′ ( t ) f d ( t )d t + P B ⌊ ( k − 1) / 2 ⌋ X l =0 k 2 l + 1 C l c l +1 ( d ) C k ( ¯ S k,l ) Z 1 − 1 t k − 2 l (1 − t 2 ) l +1 h ′′ ( t ) f d ( t )d t. Let us now estimate each term. Lemma D.5. When sup | z |≤ 1 | h ′ ( z ) | ≤ M 1 , sup | z |≤ 1 | h ′′ ( z ) | ≤ M 2 , B ⊤ B = I r and ∥ ˜ x ∥ = 1 , then for k ≥ 0 , T ( k ) 1 = ˜ O ( d − k/ 2 r ⌊ k/ 2 ⌋ / 2 ) , T ( k ) 2 = ˜ O ( d − ( k +1) / 2 r ⌊ k/ 2 ⌋ / 2 ) , T ( k ) 3 = ˜ O ( d − ( k +1) / 2 r ⌊ k/ 2 ⌋ / 2 ) and T ( k ) 4 = ˜ O ( d − ( k +2) / 2 r ⌊ k/ 2 ⌋ / 2 ) . Pr oof. As a reminder , from the proof of Lemma B.16 , we know that for a smooth bounded function i defined on [ − 1 , 1] , we hav e |I p 1 ,p 2 [ i ] | ∼ d − p 1 / 2 . Therefore, ∥ T 1 ∥ ≤ B ⌊ k/ 2 ⌋ X l =0 k 2 l c l ( d ) C k +1 ( S k,l ) I k − 2 l,l [ h ′ ] ≤ ⌊ k/ 2 ⌋ X l =0 k 2 l c l ( d ) ∥ C k +1 ( S k,l ) ∥|I k − 2 l,l [ h ′ ] | ≤ ⌊ k/ 2 ⌋ X l =0 k 2 l c l ( d ) ∥ C k +1 ∥ F ∥ Sym(( B ⊤ ˜ x ) ⊗ k − 2 l ⊗ Σ ⊗ l ) ∥|I k − 2 l,l [ h ′ ] | ≤ ⌊ k/ 2 ⌋ X l =0 k 2 l c l ( d ) ∥ C k +1 ∥ F ∥ Σ ∥ l F |I k − 2 l,l [ h ′ ] | ≲ ⌊ k/ 2 ⌋ X l =0 d − l r l/ 2 d − ( k − 2 l ) / 2 ≲ d − k/ 2 r ⌊ k/ 2 ⌋ / 2 , where we used ∥ C k +1 ∥ F = O (1) from Lemma B.12 , ∥ ˜ x ∥ = 1 and ∥ Σ ∥ F ≤ √ r . Likewise, we can follo w the same procedure to conclude, T 2 = ˜ O ( d − ( k +1) / 2 r ⌊ k/ 2 ⌋ / 2 ) , T 3 = ˜ O ( d − ( k +1) / 2 r ⌊ k/ 2 ⌋ / 2 ) and T 4 = ˜ O ( d − ( k +2) / 2 r ⌊ k/ 2 ⌋ / 2 ) . 50 Dataset Distillation Efficiently Encodes Lo w-Dimensional Representations A P R E P RI NT In the next lemma, we pro vide tighter bounds for a few lo wer order terms. Lemma D.6. If h ′ and h ′′ ar e continuous and h ′′ ( t ) > 0 in the interval [ − 1 , 1] , then with high pr obability , T (1) 1 = 1 d E z [ h ′′ ( z )] H ˜ x , T (1) 3 = 1 d − 1 E t [(1 − t 2 ) h ′′ ( t )] H ˜ x + ˜ O ( rd − 2 ) , T (3) 1 = ˜ O ( rd − 2 ) and T (2) 2 = ˜ O ( rd − 2 ) , wher e the pr obability density function of the random variable t is f d ( t ) = Γ( d 2 ) √ π Γ( d − 1 2 ) (1 − t 2 ) d − 3 2 , and that of z is f d +2 ( t ) . Pr oof. The assumption on h ′ and h ′′ implies that h ′ ( t ) ≤ M 1 and m 2 ≤ h ′ ( t ) ≤ M 2 for all t ∈ [ − 1 , 1] . W e first prov e an important equality that we will use throughout the proof. Since d d t (1 − t 2 ) d − 1 2 = − ( d − 1) t (1 − t 2 ) d − 3 2 , the integration by part leads to E [ th ′ ( t )] = Z 1 − 1 th ′ ( t ) f d ( t )d t = − 1 d − 1 h ′ ( t )(1 − t 2 ) d − 1 2 1 − 1 + Z 1 − 1 1 d − 1 Γ( d 2 ) √ π Γ( d − 1 2 ) h ′′ ( t )(1 − t 2 ) d − 1 2 d t = 1 d − 1 Γ( d 2 ) √ π Γ( d − 1 2 ) √ π Γ( d +1 2 ) Γ( d +2 2 ) Z 1 − 1 Γ( d +2 2 ) √ π Γ( d +1 2 ) h ′′ ( z )(1 − z 2 ) d − 1 2 d z = 1 d − 1 Γ( d 2 ) √ π Γ( d − 1 2 ) √ π d − 1 2 Γ( d − 1 2 ) d 2 Γ( d 2 ) E [ h ′′ ( z )] = 1 d E [ h ′′ ( z )] . (21) From this equation, we can deriv e the following relations. E [ t 2 ] = 1 d , (22) | E [ t 3 h ′ ( t )] | ≤ 2 M 1 + M 2 d , (23) | E [ t (1 − t 2 ) h ′ ( t )] | ≤ 2 M 1 + M 2 d , (24) where we used equation ( 21 ) once for each relation. Moreov er , E t [(1 − t 2 )] = Z 1 − 1 c d (1 − t 2 ) d − 1 2 d t = c d c d +2 = Θ(1) , (25) and following Corollary 46 ( Damian et al. , 2022 ), with probability 1 − 2e − ι ∥ B ⊤ ˜ x ∥ ≲ r r ι d . (26) Based on the parity of k , T (1) 3 introduces an additional p rι d factors, leading to the bound of the statement. Let us now mo ve on to pro ving our main statements. The e valuation of T (1) 1 is straightforward as T (1) 1 = E [ ˆ C 2 ( w ⊗ 1 ) h ′ ( ⟨ w , ˜ x ⟩ )] = H E [ w h ′ ( ⟨ w , ˜ x ⟩ )] = H ˜ x E [ th ′ ( t )] = 1 d E [ h ′′ ( t )] H ˜ x, where we used the same change of v ariable and reasoning as Lemma D.4 for the third inequality , and equation 21 for the last equality . 51 Dataset Distillation Efficiently Encodes Lo w-Dimensional Representations A P R E P RI NT Again with the same change of v ariable, for T (1) 3 , we obtain T (1) 3 = E w [ w h ′′ ( ⟨ w , ˜ x ⟩ ) ⟨ ˆ C 2 ( w ) , ˜ x ⟩ ] = E w [ w h ′′ ( ⟨ w , ˜ x ⟩ ) ⟨ H w , ˜ x ⟩ ] = E w [ w w ⊤ h ′′ ( ⟨ w , ˜ x ⟩ )] H ˜ x = E v ,t [( t ˜ x + p 1 − t 2 v )( t ˜ x + p 1 − t 2 v ) ⊤ h ′′ ( t )] H ˜ x = E v ,t [ t 2 ˜ x ˜ x ⊤ h ′′ ( t ) + (1 − t 2 ) v v ⊤ h ′′ ( t )] H ˜ x = E t [ t 2 h ′′ ( t )]( ˜ x ⊤ H ˜ x ) ˜ x + E t [(1 − t 2 ) h ′′ ( t )] E v [ v v ⊤ ] H ˜ x = E t [ t 2 h ′′ ( t )]( ˜ x ⊤ H ˜ x ) ˜ x + E t [(1 − t 2 ) h ′′ ( t )] P d − 1 H ˜ x = E t [ t 2 h ′′ ( t )]( ˜ x ⊤ H ˜ x ) ˜ x + 1 d − 1 E t [(1 − t 2 ) h ′′ ( t )] H ˜ x − 1 d − 1 E t [(1 − t 2 ) h ′′ ( t )]( ˜ x ⊤ H ˜ x ) ˜ x, where we used that ( d − 1) E [ v v ⊤ ] = P : = I − ˜ x ˜ x ⊤ for the se venth equality . Since | ˜ x ⊤ H ˜ x | = ˜ O ( rd − 1 ) by Lemma B.11 and equation ( 26 ) , the third term is ˜ O ( rd − 2 ) . The first term is also O ( rd − 2 ) as | E t [ t 2 h ′′ ( t )] | ≤ M 2 E [ t 2 ] = M 2 /d where we used equation ( 22 ) . The second term is the dominant term as H ˜ x is ˜ O ( d − 1 / 2 ) and E t [(1 − t 2 ) h ′′ ( t )] = Θ(1) since m 2 E [(1 − t 2 )] ≤ E t [(1 − t 2 ) h ′′ ( t )] ≤ M 2 and equation 25 holds. Consequently , T (1) 3 = 1 d − 1 E t [(1 − t 2 ) h ′′ ( t )] H ˜ x + ˜ O ( rd − 2 ) . The bound for T (3) 1 follows immediately by the result of Lemma D.5 , as T (3) 1 includes a coef ficient b that we omitted in the computation of the upper bound in the proof of Lemma D.4 , which adds an additional p r /d coefficient to the bounds, leading to ˜ O ( rd − 2 ) . Finally , as for T (2) 2 , we carefully dev elop its expression as follo ws: T (2) 2 = E w [ w ˆ C 2 ( w ⊗ 2 ) h ′ ( ⟨ w , ˜ x ⟩ )] = E w [ w w ⊤ H wh ′ ( ⟨ w , ˜ x ⟩ )] = E t,v [( t ˜ x + p 1 − t 2 v )( t ˜ x + p 1 − t 2 v ) ⊤ H ( t ˜ x + p 1 − t 2 v ) h ′ ( t )] = E t,v t 3 ( ˜ x ⊤ H ˜ x ) ˜ x + T r( P H ) d − 1 t (1 − t 2 ) ˜ x + 2 t (1 − t 2 ) P H d − 1 ˜ x h ′ ( t ) = E t,v [ t 3 h ′ ( t )]( ˜ x ⊤ H ˜ x ) ˜ x + T r( P H ) d − 1 E [ t (1 − t 2 ) h ′ ( t )] ˜ x + 2 E [ t (1 − t 2 ) h ′ ( t )] P H d − 1 ˜ x. Here, the first and third terms are ˜ O ( rd − 2 ) by equations 23 , 24 and 26 . Concerning the second term, we will just need to prov e that T r( P H ) is independent of d as the remainder is O ( d − 2 ) follo wing equation 24 . Howe ver , | T r( P H ) | ≤ | T r( H ) | + | T r( ˜ x ˜ x ⊤ H ) | ≤ | T r( H ) | + | T r( ˜ x ⊤ H ˜ x ) | ≲ | T r( H ) | = | T r( B C 2 B ⊤ ) | = | T r( C 2 B ⊤ B ) | = | T r( C 2 ) | ≤ √ r ∥ C 2 ∥ F ≲ √ r , where we used Lemma B.11 in the first equality and Lemma B.12 for the last inequality . Therefore, we hav e proved the desired statements. Corollary D .7. Notably , we obtain T (1) 1 + T (1) 3 + T (3) 1 + T (2) 2 = c d H ˜ x + ˜ O ( rd − 2 ) , wher e c d = Θ( d − 1 ) . 52 Dataset Distillation Efficiently Encodes Lo w-Dimensional Representations A P R E P RI NT Pr oof. This follows as E z [ h ′′ ( z )] = Θ(1) and E t [(1 − t 2 ) h ′′ ( t )] = Θ(1) , which implies T (1) 1 + T (1) 3 = 1 d E z [ h ′′ ( z )] + 1 d − 1 E t [(1 − t 2 ) h ′′ ( t )] H ˜ x + O ( r d − 2 ) . Therefore, by defining c d : = 1 d E z [ h ′′ ( z )] + 1 d − 1 E t [(1 − t 2 ) h ′′ ( t )] = Θ( 1 d ) > 0 , we obtain the desired result. This leads to the following result. Theorem D .8. 3.3 , 3.4 , 3.6 , 3.7 and 3.8 , when ˜ x (0) ∼ U ( S d − 1 ) , with high pr obability , ˆ G = c d H ˜ x + ˜ O d 1 2 N − 1 2 + r d − 2 , wher e c d = Θ d − 1 is a constant coefficient. Pr oof. From Lemma D.3 and Corollary D.7 , ˆ G = p − 1 X k =1 c k +1 k ! E w h ˆ C k +1 ( w ⊗ k ) h ′ ( ⟨ w , ˜ x ⟩ ) i + p X k =2 c k +2 k ! E w h w ˆ C k ( w ⊗ k ) h ′ ( ⟨ w , ˜ x ⟩ ) i + p − 1 X k =1 c k +1 k ! E w h w h ′′ ( ⟨ w , ˜ x ⟩ ) D ˆ C k +1 ( w ⊗ k ) , ˜ x Ei + p X k =2 c k +2 k ! E w h w h ′′ ( ⟨ w , ˜ x ⟩ ) ˆ C k ( w ⊗ k ) ⟨ w , ˜ x ⟩ i + ˜ O r d N ! = p − 1 X k =1 c k +1 k ! T ( k ) 1 + p X k =2 c k +2 k ! T ( k ) 2 + p − 1 X k =1 c k +1 k ! T ( k ) 3 + p X k =2 c k +2 k ! T ( k ) 4 + ˜ O r d N ! = c 2 1! T (1) 1 + c 4 3! T (3) 1 + c 4 2! T (2) 2 + c 2 1! T (1) 3 + p − 1 X k =4 c k +1 k ! T ( k ) 1 + p X k =3 c k +2 k ! T ( k ) 2 + p − 1 X k =2 c k +1 k ! T ( k ) 3 + p X k =2 c k +2 k ! T ( k ) 4 + ˜ O r d N ! = c 2 1! T (1) 1 + c 2 1! T (1) 3 + c 4 3! T (3) 1 + c 4 2! T (2) 2 + ˜ O ( rd − 2 + d 1 / 2 N − 1 / 2 ) = c d H ˜ x + ˜ O ( rd − 2 + d 1 / 2 N − 1 / 2 ) . The remainder of this section (the proof of the div ergence between the population and empirical gradients) follows exactly that of the single inde x model. In other words, we obtain the following theorem. Theorem D.9. Under Assumptions 3.4 and 3.1 , 3.3 , 3.4 , 3.6 and 3.8 , then for k ≥ 0 , when D S 0 = { ( ˜ x (0) m , ˜ y (0 m ) } m ∈ [ M 1 ] , wher e ˜ x (0) m ∼ U ( S d − 1 ) , the first step of distillation gives ˜ x (1) m such that ˜ x (1) m = − η D 1 ˜ y (0) m c d H ˜ x (0) m + ˜ O r d − 2 + d 1 2 N − 1 2 + d 1 2 J ∗ − 1 2 , wher e c d = ˜ Θ d − 1 , J ∗ = LJ / 2 . W e will also need the following corollary later . Corollary D .10. ˜ x (1) m can be decomposed into − η D 1 ˜ y (0) m c d H ˜ x m and an err or term η D 1 ˜ y ϵ depending on ˜ x . Consider M 1 samples ˜ x (0) m ∼ U ( S d − 1 ) , then with pr obability at least 1 − δ , max m ∥ ϵ ( ˜ x (0) m ) ∥ = ˜ O ( rd − 2 + d 1 2 N − 1 2 + d 1 2 J ∗ − 1 2 ) . This is a high pr obability event in our definition. 53 Dataset Distillation Efficiently Encodes Lo w-Dimensional Representations A P R E P RI NT D.4 t = 2 T eacher T raining Let us now consider the teacher training at t = 2 . The updated weights, based on D S 1 can be written as follows: w (1) i = − η R 1 a i 1 M 1 X m ˜ y (0) m ˜ x (1) m σ ′ ( ⟨ w (0) i , ˜ x (1) m ⟩ ) , where ˜ x (1) m = η D 1 ˜ y (0) c d H ˜ x (0) + η D 1 ˜ y (0) ϵ m . W e drop the indices such as (0) and (1) for simplicity sake and suppose that there are L ∗ neurons that are not 0 . The goal of this subsection is to provide a similar proof flo w as Damian et al. ( 2022 ) to analyze the behavior of DD and show that the resulting distilled data provide high generalization performance at retraining. Moreover , by setting ( ˜ y (0) ) 2 ∼ χ ( d ) , we can absorb the randomness of ˜ y (0) into ˜ x (1) m . T o summarize, the gradient of the teacher training using M 1 distilled data points can be defined with the property as follows: Lemma D.11. Under the assumptions of Theor em D.9 , the gradient of step t = 2 of the teac her training is g M ( w ) : = η D 1 M X m ˜ z m σ ′ ( ⟨ w , ˜ z m ⟩ ) , wher e ˜ z m = c d H ˜ x m + ˜ ϵ m , wher e ˜ x m ∼ N (0 , I d ) , and ˜ ϵ m = ˜ O ( rd − 3 2 + dN − 1 2 + dJ ∗ − 1 2 ) , with high pr obability . Pr oof. Note that 1 M 1 X m ˜ y (0) m ˜ x (1) m σ ′ ( ⟨ w (0) i , ˜ x (1) m ⟩ ) = 1 M 1 X m ˜ y (0) m η D 1 ˜ y (0) c d H ˜ x (0) + η D 1 ˜ y (0) ϵ m σ ′ ( ⟨ w (0) , η D 1 ˜ y (0) c d H ˜ x (0) + η D 1 ˜ y (0) ϵ m ⟩ ) = η D 1 M 1 X m c d H ( ˜ y (0) ) 2 ˜ x (0) + ( ˜ y (0) ) 2 ϵ m σ ′ ( ⟨ w (0) , c d H ( ˜ y (0) ) 2 ˜ x (0) + ( ˜ y (0) ) 2 ϵ m ⟩ ) , where we used that σ ′ ( t 2 z ) = σ ′ ( z ) for all t > 0 . No w since ( ˜ y (0) ) 2 ˜ x (0) ∼ N (0 , I d ) , and with high probability , ( ˜ y (0) ) 2 = ˜ Θ( √ d ) from Lemma A.2 , we obtain the desired formulation by combining with D.10 . W e now consider population gradient of g M with no perturbation ˜ ϵ m . Lemma D.12. Under ˜ x m ∼ N (0 , I d ) , g ( w ) : = E ˜ x 1 ,..., ˜ x M " η D 1 M 1 X m c d H ˜ x m σ ′ ( ⟨ w , c d H ˜ x m ⟩ ) # = α d H 2 w ∥ H w ∥ , wher e α d = η D 1 c d √ 2 π . Pr oof. Since ˜ x 1 , . . . , ˜ x M are all i.i.d. and H ⊤ = H , we can consider one sample. Consequently , g ( w ) = η D 1 c d H E ˜ x 1 [ ˜ x 1 σ ′ ( ⟨ H w, ˜ x 1 ⟩ )] . By rotational symmetry , the expectation has to align with H w , which means the expectation can be simplified as g ( w ) = η D 1 c d H E Z [ Z σ ′ ( Z )] H w ∥ H w ∥ , with Z ∼ N (0 , 1) . Since the expectation is 1 √ 2 π , we obtain the desired result. W ith this g ( w ) , the following two inequalities hold. These constitute the ingredients to pro ve a lemma similar to Lemma 21 ( Damian et al. , 2022 ). Lemma D.13. Under the assumptions of Theor em D.9 , for all ∥ T ∥ F = 1 , k ≥ 1 and i ∈ [ k ] , E w [ ⟨ T , g ( w ) ⊗ k ⟩ 2 ] ≳ α 2 k d r − k κ − 2 k , E w [ ∥ T ( g ( w ) ⊗ k − i ) ∥ 2 F ] ≲ α − 2 i d r i κ 2 k λ 2 i min E w [ ⟨ T , g ( w ) ⊗ k ⟩ 2 ] , wher e κ = λ max /λ min . 54 Dataset Distillation Efficiently Encodes Lo w-Dimensional Representations A P R E P RI NT Pr oof. Before starting computing the expectation, we make the follo wing observ ation. Let us consider the decomposi- tion H = D Λ D ⊤ , where Λ ∈ R r × r , D ∈ R d × r and D ⊤ D = I r . Such a decomposition exists by Assumption 3.3 . In other words, g ( w ) = α d D Λ 2 D ⊤ w ∥ D Λ D ⊤ w ∥ = α d D Λ 2 D ⊤ w ∥ Λ D ⊤ w ∥ . No w , by rotational symmetry and the fact that g ( w ) is in v ariant to scaling of w , all e xpectations o ver w that only include g ( w ) are equiv alent to the following g ( u ) with u ∼ S r − 1 , 8 g ( u ) = α d D Λ 2 u ∥ Λ u ∥ . T aking into account this, we obtain E w [ ⟨ T , g ( w ) ⊗ k ⟩ 2 ] = E u [ ⟨ T , g ( u ) ⊗ k ⟩ 2 ] = α 2 k d E u ⟨ T , ( D Λ 2 u ) ⊗ k ⟩ 2 / ∥ Λ u ∥ 2 k . Since ∥ Λ u ∥ ≤ λ max , E w [ ⟨ T , g ( w ) ⊗ k ⟩ 2 ] ≥ α 2 k d λ − 2 k max E u h ⟨ ˆ T , u ⊗ k ⟩ 2 i , where ˆ T is defined by ˆ T ( u 1 , . . . , u k ) = T ( D Λ 2 u 1 , . . . , D Λ 2 u k ) . As a result, by the same procedure as the proof of Lemma 21 of Damian et al. ( 2022 ), E w [ ⟨ T , g ( w ) ⊗ k ⟩ 2 ] ≳ α 2 k d λ − 2 k max r − k ∥ ˆ T ∥ F ≥ α 2 k d λ − 2 k max r − k λ 2 k min ∥ T ∥ F . W e now proof the second inequality of the statement. E w [ ∥ T ( g ( w ) ⊗ k − i ) ∥ 2 F ] = α d λ min 2( k − i ) E u [ ∥ T (( D Λ 2 u ) ⊗ k − i ) ∥ 2 F ] = α d λ min 2( k − i ) E u [ ∥ ˆ T ( u ⊗ k − i ) ∥ 2 F ] ≲ α d λ min 2( k − i ) r i E u [ ⟨ ˆ T , u ⊗ k ⟩ 2 ] = α d λ min 2( k − i ) r i E u " ⟨ T , ( α d D Λ 2 u/ ∥ Λ u ∥ ) ⊗ k ⟩ 2 · ∥ Λ u ∥ α d 2 k # = α − 2 i d r i λ max λ min 2 k λ 2 i min E u ⟨ T , g ( u ) ⊗ k ⟩ 2 . Definition D.14. F or w ∈ S d − 1 , we define r ( w ) : = g M ( w ) − g ( w ) . This error can be bounded as follows. Lemma D.15. W ith probability at least 1 − δ , we have for j ≤ 4 p , if d ≳ 144 α 2 r 2 λ 2 min , N ≳ 144 α 2 d 4 λ 2 min and J ∗ ≳ 144 α 2 d 4 λ 2 min , E w [ ∥ Π ∗ r ( w ) ∥ j ] 1 /j ≲ λ max η D 1 c d s r + log(1 /δ ) M 1 + λ min η D 1 c d 4 α + λ max η D 1 c d √ r + s log 1 /δ M 1 4 αϵ λ min c d 1 /j + η D 1 ϵ, wher e ϵ = ˜ O ( rd − 3 2 + dN − 1 2 + dJ ∗ − 1 2 ) . Pr oof. Since r ( w ) = η D 1 M 1 X m ˜ z m σ ′ ( ⟨ w , ˜ z m ⟩ ) − η D 1 E ˜ x 1 [ c d H ˜ x 1 σ ′ ( ⟨ H w, c d ˜ x 1 ⟩ )] , 8 W e can first substitute w with g ∼ N (0 , I d ) by the scale in variance of g , then use the rotation in variance of the Gaussian distribution to change D ⊤ g to ˜ u ∼ N (0 , I r ) , and finally by the scale in variance of g again, replace ˜ u by u ∼ S r − 1 . 55 Dataset Distillation Efficiently Encodes Lo w-Dimensional Representations A P R E P RI NT where ˜ z m = c d H ˜ x m + ˜ ϵ m , r can be divided into the follo wing three terms. R 1 = η D 1 M 1 X m c d H ˜ x m σ ′ ( ⟨ w , c d H ˜ x m ⟩ ) − η D 1 E ˜ x 1 [ c d H ˜ x 1 σ ′ ( ⟨ H w, c d ˜ x 1 ⟩ )] R 2 = η D 1 M 1 X m c d H ˜ x m σ ′ ( ⟨ w , c d H ˜ x m + ˜ ϵ m ⟩ ) − η D 1 M 1 X m c d H ˜ x m σ ′ ( ⟨ w , c d H ˜ x m ⟩ ) R 3 = η D 1 M 1 X m ˜ ϵ m σ ′ ( ⟨ w , c d H ˜ x m + ˜ ϵ m ⟩ ) . Consequently , E w [ ∥ Π ∗ r ( w ) ∥ j ] 1 /j ≤ E w [ ∥ Π ∗ R 1 ( w ) ∥ j ] 1 /j + E w [ ∥ Π ∗ R 2 ( w ) ∥ j ] 1 /j + E w [ ∥ Π ∗ R 3 ( w ) ∥ j ] 1 /j . W e start by bounding E w [ ∥ Π ∗ R 1 ( w ) ∥ j ] 1 /j . Since E w [ ∥ Π ∗ R 1 ( w ) ∥ j ] 1 /j ≤ sup w ∈ S d − 1 ∥ Π ∗ R 1 ( w ) ∥ , we will bound the right hand side. sup w ∈ S d − 1 ∥ Π ∗ R 1 ( w ) ∥ = sup w ∈ S d − 1 sup z ∈ S d − 1 ⟨ z , Π ∗ R 1 ( w ) ⟩ . W e can thus proceed similarly to Theorem B.19 , by observing that ⟨ z , H ˜ x m ⟩ σ ′ ( ⟨ w , H ˜ x m ⟩ ) = ⟨ D ⊤ z , Λ D ⊤ ˜ x m ⟩ σ ′ ( ⟨ D ⊤ w , Λ D ⊤ ˜ x m ⟩ ) , and using rotational symmetry , all vectors are projected to a r -dimensional subspace. In other words, sup w ∈ S d − 1 sup z ∈ S d − 1 ⟨ z , Π ∗ R 1 ( w ) ⟩ = sup w ∈ S r − 1 sup z ∈ S r − 1 ⟨ z , Λ b m ⟩ σ ′ ( ⟨ w , Λ b m ⟩ ) , with samples b m = D ⊤ ˜ x (0) m ∈ R r . This is a λ max -sub-gaussian random v ariable in R r . This thus yields with probability at least 1 − δ over data { x m } sup w ∈ S d − 1 ∥ Π ∗ R 1 ( w ) ∥ ≲ λ max η R 1 c d s r + log(1 /δ ) M 1 . Let us now focus on E w [ ∥ Π ∗ R 2 ( w ) ∥ j ] 1 /j . Define ∆ m : = σ ′ ( ⟨ w , c d H ˜ x m + ˜ ϵ m ⟩ ) − σ ′ ( ⟨ w , c d H ˜ x m ⟩ ) . Then, E w [ ∥ Π ∗ R 2 ( w ) ∥ j ] 1 /j = E w η D 1 c d M ! X m H ˜ x m ∆ m j 1 /j ≤ η D 1 c d M 1 X m ∥ H ˜ x m ∥ E w [ ∥ ∆ m ∥ j ] 1 /j . Since ∆ m only takes v alues in {− 1 , 0 , 1 } , E w [ ∥ ∆ m ∥ j ] 1 /j = P(∆ m = 0) 1 /j . Denote θ m the angle between c d H ˜ x m + ˜ ϵ m and c d H ˜ x m , and s m : = c d H ˜ x m , then P(∆ m = 0) 1 /j = ( θ /π ) 1 /j , since w is isotropic. If ∥ ˜ ϵ m ∥ ≤ 1 2 ∥ s m ∥ , then ∥ s m + ˜ ϵ m ∥ ≥ ∥ s m ∥ − ∥ ˜ ϵ m ∥ ≥ 1 2 ∥ s m ∥ and θ m ≤ π 2 sin( θ m ) = ∥ ( I − Pro j z )( s m + ϵ m ) ∥ ∥ s m + ˜ ϵ m ∥ ≤ ∥ ˜ ϵ m ∥ ∥ s m + ˜ ϵ m ∥ ≤ 2 ∥ ˜ ϵ m ∥ ∥ s m ∥ . Now , let us define a truncation τ : = λ min c d 4 α ( α > 0 ), B : = { m | ∥ s m ∥ ≤ τ } and G : = { m | ∥ s m ∥ ≥ τ } . Particularly , for m ∈ G , ∥ ˜ ϵ m ∥ / ∥ s m ∥ ≤ ∥ ˜ ϵ m ∥ /τ = 4 α ∥ ˜ ϵ m ∥ / ( λ min c d ) . Under the condition, max m ∥ ˜ ϵ m ∥ ≤ τ / 2 , we hav e E w [ ∥ Π ∗ R 2 ( w ) ∥ j ] 1 /j = η D 1 M 1 X m ∥ s m ∥ P(∆ m = 0) 1 /j = η D 1 M 1 X m ∈B ∥ s m ∥ P(∆ m = 0) 1 /j + η D 1 M 1 X m ∈G ∥ s m ∥ P(∆ m = 0) 1 /j ≲ η D 1 M 1 X m ∈B ∥ s m ∥ + η D 1 M 1 X m ∈G ∥ s m ∥ ( ∥ ˜ ϵ m ∥ / ∥ s m ∥ ) 1 /j ≲ η D 1 τ + η D 1 M 1 X m ∈G ∥ s m ∥ 4 α max m ∥ ˜ ϵ m ∥ λ min c d 1 /j . 56 Dataset Distillation Efficiently Encodes Lo w-Dimensional Representations A P R E P RI NT For ∥ H ˜ x m ∥ , we hav e P( ∥ H ˜ x m ∥ /λ max ≥ √ r + t ) ≤ e − t 2 / 2 . As a result, with probability 1 − δ ′ , 1 M 1 X m ∥ H ˜ x m ∥ ≲ √ r + s log(1 /δ ′ ) M 1 λ max . Combining these result with Corollary D.10 , we obtain with probability 1 − δ , E w [ ∥ Π ∗ R 2 ( w ) ∥ j ] 1 /j ≲ η D 1 c d λ min 4 α + η D 1 c d λ 2 max √ r + s log(2 /δ ′ ) M 1 4 α ( r d − 3 2 p log(2 M 1 /δ ) + dN − 1 2 + dJ ∗ − 1 2 ) λ min c d ! 1 /j . max m ∥ ϵ m ∥ ≤ τ / 2 leads to d ≥ 144 α 2 r 2 log(2 M /δ ) λ 2 min , N ≥ 144 α 2 d 4 λ 2 min and J ∗ ≥ 144 α 2 d 4 λ 2 min . Finally , E w [ ∥ Π ∗ R 3 ( w ) ∥ j ] 1 /j is bounded by η D 1 · ˜ O ( rd − 3 2 + dN − 1 2 + dJ ∗ − 1 2 ) since σ ′ ≤ 1 and max ∥ ˜ ϵ m ∥ = ˜ O ( rd − 3 2 + dN − 1 2 + dJ ∗ − 1 2 ) . Corollary D .16. W ith pr obability 1 − e − ι , if M 1 ≳ λ max η D 1 c d √ ι δ 2 r , α = η D 1 c d λ min δ and ϵ ≲ η D 1 c d λ 2 max ( √ r + p ι/ M 1 ) /δ − j c d λ min /α ∧ δ /η D 1 , then E w [ ∥ Π ∗ r ( w ) ∥ j ] 1 /j ≲ δ. W e can now state the analogue of Lemma 21 ( Damian et al. , 2022 ). Lemma D.17 (Analogue of Lemma 21 ( Damian et al. , 2022 )) . F or any k ≤ p , if η D 1 = Θ( √ d ) , M ≥ ˜ Ω( ˆ κ 2 p λ 2 min λ 2 max r 2 ) , d ≥ ˜ Ω( ˆ r 2 p r 2 ∨ r 3 λ 2 min ˆ κ 2 p ) , N ≥ ˜ Ω( ˆ r 2 p d 4 ∨ r λ 2 min ˆ κ 2 p d 4 ) , J ∗ ≥ ˜ Ω( ˆ r 2 p d 4 ∨ r λ 2 min ˆ κ 2 p d 4 ) , where ˆ r p = r 4 p +1 / 2 ˆ κ 4 p +1 p λ 4 p +1 min λ 8 p +1 max , ˆ κ p = max 1 ≤ i ≤ 4 k, 1 ≤ k ≤ p κ k/i and κ = λ max /λ min then, with high pr obability Mat E w (Π ∗ g M ( w )) ⊗ 2 k ⪰ ( α − 2 d r κ 2 ) − k Π Sym k ( S ∗ ) , wher e Π Sym k ( S ∗ ) is the orthogonal pr ojection onto symmetric k tensors r estricted to S ∗ , and α − 2 d = ˜ Θ(( η D 1 c d ) − 2 ) = ˜ Θ( d ) . Pr oof. Following Damian et al. ( 2022 ), it suf fices to prov e for all symmetric k tensor T with ∥ T ∥ 2 F = 1 that E w [ ⟨ T , (Π ∗ g M ( w )) ⊗ k ⟩ 2 ] ≳ ( α − 2 d r κ 2 ) − k . Since g M ( w ) = g ( w ) + r ( w ) , the binomial theorem leads to E w [ ⟨ T , (Π ∗ g M ( w )) ⊗ k ⟩ 2 ] ≥ 1 2 E w [ ⟨ T , ( g ( w )) ⊗ k ⟩ 2 ] − E w [ δ ( w ) 2 ] , where we used Y oung’ s inequality , Π ∗ g ( w ) = g ( w ) and δ ≲ P k i =1 ∥ T ( g ( w ) ⊗ k − i ) ∥ F ∥ Π ∗ r ( w ) ∥ i . From Lemma D.13 , E w [ δ ( w ) 2 ] ≲ E w [ ⟨ T , ( g ( w )) ⊗ k ⟩ 2 ] k X i =1 ( α − 2 d r λ 2 min κ 2 k/i E w [ ∥ Π ∗ r ( w ) ∥ 4 i ] 1 / 2 i ) i . Therefore, if E w [ ∥ Π ∗ r ( w ) ∥ j ] 1 /j ≤ 1 4 α d / ( √ r λ min ˆ κ p ) ≤ 1 4 α d / ( √ r λ min κ k/i ) , ∀ j ≤ 4 k , where ˆ κ p = max 1 ≤ i ≤ 4 k, 1 ≤ k ≤ p κ k/i , we obtain our result. This is satisfied by substituting δ = 1 4 α d / ( √ r λ min ˆ κ p ) in Corollary D.16 . This notably implies M 1 ≳ ˆ κ 2 p λ 2 min λ 2 max r 2 , 57 Dataset Distillation Efficiently Encodes Lo w-Dimensional Representations A P R E P RI NT and ϵ ≲ 1 ˆ r p d ∧ c d √ r λ min ˆ κ p , where ˆ r p : = r 4 p +1 / 2 ˆ κ 4 p +1 p λ 4 p +1 min λ 8 p +1 max . 9 The last inequality is satisfied when d ≳ ˆ r 2 p r 2 ι, N ≳ ˆ r 2 p d 4 , J ∗ ≳ ˆ r 2 p d 4 . As a result, E w [ δ ( w ) 2 ] ≲ 1 4 E w [ ⟨ T , ( g ( w )) ⊗ k ⟩ 2 ] , and this leads to Mat E w (Π ∗ g M ( w )) ⊗ 2 k ⪰ ( α − 2 d r κ 2 ) − k Π Sym k ( S ∗ ) . Since α d = ˜ Θ( η D 1 c d ) and c d = Θ(1 /d ) , we can set η D 1 = Θ( √ d ) so that α − 2 d = Θ( d ) , which leads to the desired result. The following corollary immediately follo ws from Corollary 22 of Damian et al. ( 2022 ). Corollary D.18 (Analogue of Corollary 22 ( Damian et al. , 2022 )) . If M ≥ ˜ Ω( ˆ κ 2 p λ 2 min λ 2 max r 2 ) , d ≥ ˜ Ω( ˆ r 2 p r 2 ∨ r 3 λ 2 min ˆ κ 2 p ) , N ≥ ˜ Ω( ˆ r 2 p d 4 ∨ r λ 2 min ˆ κ 2 p d 4 ) , J ∗ ≥ ˜ Ω( ˆ r 2 p d 4 ∨ r λ 2 min ˆ κ 2 p d 4 ) , where ˆ r p = r 4 p +1 / 2 ˆ κ 4 p +1 p λ 4 p +1 min λ 8 p +1 max and ˆ κ p = max 1 ≤ i ≤ 4 k, 1 ≤ k ≤ p κ k/i , then for any k ≤ p and any symmetric k tensor T supported on S ∗ , ther e exists z T ( w ) such that E w [ z T ( w )( ⟨ g M ( w ) , x ⟩ p ] = ⟨ T , x ⊗ k ⟩ , with E w [ z T ( w ) 2 ] ≲ ( dr κ 2 ) k ∥ T ∥ 2 F and | z T ( w ) | ≲ ( dr κ 2 ) k ∥ T ∥ 2 F ∥ g M ( w ) ∥ k . Next, in order to pro vide the analogue of Lemma 23 ( Damian et al. , 2022 ), we observe the follo wing statement. Lemma D.19. If η R 1 = ˜ Θ( √ d/r ) , N ≥ ˜ Ω( d 4 ) and J ∗ ≥ ˜ Ω( d 4 ) , with high pr obability , we have η R 1 ∥ g M ( w ) ∥ ≤ 1 , 2 η R 1 ⟨ g M ( w ) , x i ⟩ ≤ 1 . Pr oof. First of all, ∥ g M ( w ) ∥ ≤ η D 1 1 M X m ( c d H ˜ x (0) m + ϵ m ) σ ′ ( ⟨ w , c d H ˜ x (0) m + ϵ m ⟩ ) ≤ η D 1 1 M X m ( c d H ˜ x (0) m + ϵ m ) ≤ η D 1 c d 1 M X m H ˜ x (0) m + η D 1 1 M X m ∥ ϵ m ∥ = ˜ Θ p r ι/ ( M d ) + √ d max m ∥ ϵ m ∥ . From Corollary D.10 , the second term is sufficiently small for lar ge d , N and J ∗ . The first term can be made small by multiplying with a factor η R 1 = ˜ Θ( √ d/ √ r ) with sufficiently small constant. Note that g M ( w ) depends on the training data x i , through { ˜ x (1) m } . ⟨ g M ( w ) , x i ⟩ = * η D 1 1 M X m c d H ˜ x (0) m σ ′ ( ⟨ w , c d H ˜ x (0) m + ϵ m ⟩ ) , x i + + * η D 1 1 M X m ϵ ( i ) m σ ′ ( ⟨ w , c d H ˜ x (0) m + ϵ ( i ) m ⟩ ) , x i + = * η D 1 1 M X m c d H ˜ x (0) m σ ′ ( ⟨ w , c d H ˜ x (0) m + ϵ m ⟩ ) , Π ∗ x i + * η D 1 1 M X m ϵ ( i ) m σ ′ ( ⟨ w , c d H ˜ x (0) m + ϵ ( i ) m ⟩ ) , x i + ≤ 2 ∥ Π ∗ x i ∥ η D 1 c d 1 M X m ∥ H ˜ x (0) m ∥ + ∥ x i ∥ η D 1 1 M X m ∥ ϵ ( i ) m ∥ . 9 Here, we assumed λ max λ min ≥ 1 . 58 Dataset Distillation Efficiently Encodes Lo w-Dimensional Representations A P R E P RI NT Now , since ∥ x i ∥ = √ dι , ∥ Π ∗ x i ∥ = √ r ι , 1 M P m ∥ H ˜ x (0) m ∥ = ( √ r + p ι/ M ) λ max and 1 M P m ∥ ϵ ( i ) m ∥ = ˜ O ( d − 1 p r log(2 M /δ ) + dN − 1 2 + dJ ∗− 1 2 ) with high probability , as long as N ≥ ˜ Ω( d 4 ) , J ∗ ≥ ˜ Ω( d 4 ) , η R 1 = ˜ Θ( r − 1 √ d ) is sufficient to assure 2 η R 1 ⟨ g M ( w ) , x i ⟩ ≤ 1 . Let us now state the analogue of Lemma 23 ( Damian et al. , 2022 ). Lemma D.20 (Analogue of Lemma 23 ( Damian et al. , 2022 )) . If η D 1 = ˜ Θ( √ d ) , η R 1 = ˜ Θ( r − 1 √ d ) , M ≥ ˜ Ω( ˆ κ 2 p λ 2 min λ 2 max r 2 ) , d ≥ ˜ Ω( ˆ r 2 p r 2 ∨ r 3 λ 2 min ˆ κ 2 p ) , N ≥ ˜ Ω( ˆ r 2 p d 4 ∨ rλ 2 min ˆ κ 2 p d 4 ∨ d 4 ) , J ∗ ≥ ˜ Ω( ˆ r 2 p d 4 ∨ rλ 2 min ˆ κ 2 p d 4 ∨ d 4 ) , wher e ˆ r p = r 4 p +1 / 2 ˆ κ 4 p +1 p λ 4 p +1 min λ 8 p +1 max and ˆ κ p = max 1 ≤ i ≤ 4 k, 1 ≤ k ≤ p κ k/i , then for any k ≤ p and any symmetric k tensor T supported on S ∗ , ther e exists h T ( a, w , b ) such that if f h T ( x ) : = E a,w,b [ h T ( a, w , b ) σ ( ⟨ w (1) , x ⟩ + b )] , we have 1 N P n ( f h T ( x n ) − ⟨ T , x ⊗ p n ⟩ ) 2 ≲ 1 /n with E a,w,b [ h T ( a, w , b ) 2 ] ≲ r 3 k κ 2 k ι 3 k ∥ T ∥ 2 F , sup w | h T ( a, w , b ) | ≲ r 3 k κ 2 k ι 6 k ∥ T ∥ 2 F . Remark D.21. Note that the coefficient of r in the bounds of E a,w,b [ h T ( a, w , b ) 2 ] and sup w | h T ( a, w , b ) | is 3 k , while in Damian et al. ( 2022 ) it was k . T o conclude, we obtain the following theorem for the teacher training. Theorem D.22. Under the assumptions of Theor em D.9 , with parameters η D 1 = ˜ Θ( √ d ) , η R 1 = ˜ Θ( r − 1 √ d ) , λ R 1 = 1 /η R 1 , λ D 1 = 1 /η D 1 , M ≥ ˜ Ω( ˆ κ 2 p λ 2 min λ 2 max r 2 ) , d ≥ ˜ Ω( ˆ r 2 p r 2 ∨ r 3 λ 2 min ˆ κ 2 p ) , N ≥ ˜ Ω( ˆ r 2 p d 4 ∨ r λ 2 min ˆ κ 2 p d 4 ∨ d 4 ) , J ∗ ≥ ˜ Ω( ˆ r 2 p d 4 ∨ r λ 2 min ˆ κ 2 p d 4 ∨ d 4 ) , wher e ˆ r p = r 4 p +1 / 2 ˆ κ 4 p +1 p λ 4 p +1 min λ 8 p +1 max and ˆ κ p = max 1 ≤ i ≤ 4 k, 1 ≤ k ≤ p κ k/i , ther e exists λ T r 2 such that if η T r 2 is sufficiently small and T = ˜ Θ( { η T r 2 λ T r 2 } − 1 ) so that the final iter ate of the teacher training at t = 2 output a parameter a ( ξ T r 2 ) that satisfies with pr obability at least 0.99, E x,y [ | f ( a ( ξ T r 2 ) ,W (1) ,b (1) ) ( x ) − y | ] − ζ ≤ ˜ O r dr 3 p κ 2 p N + r r 3 p κ 2 p L ∗ + 1 N 1 / 4 ! . D.5 t = 2 Distillation and Retraining Finally , the behavior of distillation and retraining at t = 2 is similar to the single index model case. Indeed, we prepare D S 2 = { ˆ x (0) m , ˆ y (0) m } M 2 m =1 so that it satisfies the regularity condition B.36 . Please see Appendix B.8 for further details. Theorem D.23. Under the assumptions of Theor em D.22 , if { ˆ x (0) m } satisfies the r egularity condition B.36 , η S 1 = M 1 η T r 1 , then for a sufficiently small η D 2 and ξ R 2 = ˜ Θ(( η D 2 σ min ) − 1 ) , wher e σ min > 0 is the smallest eigen value of ˜ K ⊤ ˜ K , the one-step gradient matc hing ( 17 ) finds M labels ˜ y (1) m so that E x,y [ | f (˜ a ( ξ S 1 ) ,W (1) ,b (0) ) ( x ) − y | ] − ζ ≤ ˜ O r dr 3 p κ 2 p N + r r 3 p κ 2 p L ∗ + 1 N 1 / 4 ! , The overall memory cost is ˜ Θ( r 2 d + L ) . Theorem D.24. Under the assumptions of Theor em D.22 , if { ˆ x (0) m } satisfies the r egularity condition B.36 , then one-step performance matching can find with high pr obability a distilled dataset at the second step of distillation so that E x,y [ | f (˜ a (1) ,W (1) ,b (0) ) ( x ) − y | ] − ζ ≤ ˜ O r dr 3 p κ 2 p N + r r 3 p κ 2 p L ∗ + 1 N 1 / 4 ! , wher e ˜ a (1) is the output of the r etraining algorithm at t = 2 with ˜ a (0) = 0 . The overall memory usage is only ˜ Θ( r 2 d + L ) . 59 Dataset Distillation Efficiently Encodes Lo w-Dimensional Representations A P R E P RI NT D.6 Summary of Algorithm W e first summarize the setting of each hyperparameter that was not pro vided in the assumptions. • η D 1 = ˜ Θ( √ d ) , λ D 1 = 1 /η D 1 , • η R 1 = ˜ Θ( d ) for single inde x models with M 1 = 1 , and else η R 1 = ˜ Θ( r − 1 √ d ) , λ R 1 = 1 /η R 1 , • ξ T r 2 = ˜ Θ(1 / ( η T r 2 λ T r 2 )) , sufficiently small η T r 2 , there exist a λ T r 2 , • η S 2 = η R 2 , λ S 2 = 0 , • for one-step PM, ξ D 2 = ˜ Θ(1 / ( η D 2 λ D 2 )) , sufficiently small η D 2 , there exist a λ D 2 , λ R 2 = 0 , • for one-step GM, η D 2 = M 2 η T r 2 , λ D 2 = 0 , ξ R 2 = ˜ Θ(1 /η R 2 ) , sufficiently small η R 2 , λ R 2 = 0 . In the following, Algorithm 2 pro vides the precise formulation of Algorithm 1 with Assumption 3.6 applied. 60 Dataset Distillation Efficiently Encodes Lo w-Dimensional Representations A P R E P RI NT Algorithm 2 Analyzed Dataset Distillation Algorithm Input: Training dataset D T r , model f θ , loss function L , fixed initial parameter θ (0) = a (0) , W (0) , b (0) . Output: Distilled data D S . Initialize distilled data D S 0 randomly , α = 1 N P N n =1 y n , γ = 1 N P N n =1 y n x n , preprocess: y n ← y n − α − ⟨ γ , x n ⟩ . for t = 1 do Sample a batch of initial states { θ (0) j } J j =1 , and initialize distilled data D S randomly . I. T r aining Phase for j = 0 to J do T eacher T raining : W (1) j = W (0) j − η T r 1 n ∇ W L ( θ (0) j , D T r ) + λ T r 1 W (0) j o , where λ T r 1 = 1 /η T r 1 . W ith teacher gradient : g T r i,j = ∇ w i L ( θ (0) j , D T r ) . w (0) i,j is the realization of the j -th initialization of w i . Student T raining : ˜ W (1) j = W (0) j − η S 1 n ∇ W L ( θ (0) j , D S ) + λ S 1 W (0) j o , where λ S 1 = 1 /η S 1 . W ith student gradient: g S i,j = ∇ w i L ( θ (0) j , D S ) . end for II. Distillation Phase D S 1 = D S − η D 1 1 J P j ∇ D S 1 − 1 L P L i =1 ⟨ g S i,j , g T r i,j ⟩ + λ D 1 D S , where λ D 1 = 1 /η D 1 . III. Retraining Phase W (1) = W (0) − η R 1 ∇ W L ( θ (0) , D S 1 ) + λ R 1 W (0) . end for Reinitialize b i ∼ N (0 , 1) for t = 2 do Sample a batch of initial states { θ (1) j } J j =1 where θ (1) 0 = ( a (0) , W (1) , b (0) ) , and a new distilled data D S . I. T r aining Phase for j = 1 to J do T eacher T raining : a ( τ ) j = a ( τ − 1) j − η T r 2 n ∇ a L (( a ( τ − 1) j , W (1) , b (0) ) , D T r ) + λ T r 2 a ( τ − 1) j o , from τ = 1 to τ = ξ T r 2 . W ith teacher gradient: G T r 2 ,j = { g T r τ ,j } ξ T r 2 − 1 τ =0 = n ∇ a L (( a ( τ − 1) j , W (1) , b (0) ) , D T r ) + λ T r 2 a ( τ − 1) j o ξ T r 2 − 1 τ =0 . Student T raining : ˜ a (1) j = a (0) j − η S 2 n ∇ a L (( a (0) j , W (1) , b (0) ) , D S ) o . W ith student gradient: { g S 0 ,j } = n ∇ a L (( a (0) j , W (1) , b (0) ) , D S ) o . end for if One-Step Gradient Matching then II. Distillation Phase D S 2 = D S − η S 2 1 J P J j =1 ∇ D S 1 − D P ξ D 2 − 1 τ =0 g T r τ ,j , g S 0 ,j E . III. Retraining Phase ˜ a ( τ ) = ˜ a ( τ − 1) − η R 2 ∇ a L ( a ( τ − 1) , W (1) , b (0) ) , D S 2 from τ = 1 to τ = ξ R 2 . end if if One-Step Performance Matching then II. Distillation Phase for τ = 1 to ξ R 2 do D S ← D S − η R 2 ∇ D S L (˜ a (1) 0 , W (1) , b (0) ) , D T r + λ R 2 D S , where ˜ a (1) 0 is a function of D S . end for D S 2 = D S . III. Retraining Phase ˜ a (1) = a (0) − η R 2 ∇ a L (( a (0) , W (1) , b (0) ) , D S 2 ) . end if end for retur n D S 1 ∪ D S 2 61
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment