Bayesian factorization via $L_{1/2}$ shrinkage
Factor models are widely used for dimension reduction. Bayesian approaches to these models often place a prior on the factor loadings that allows for infinitely many factors, with loadings increasingly shrunk toward zero as the column index increases…
Authors: Shicheng Liu, Qingping Zhou, Yanan Fan
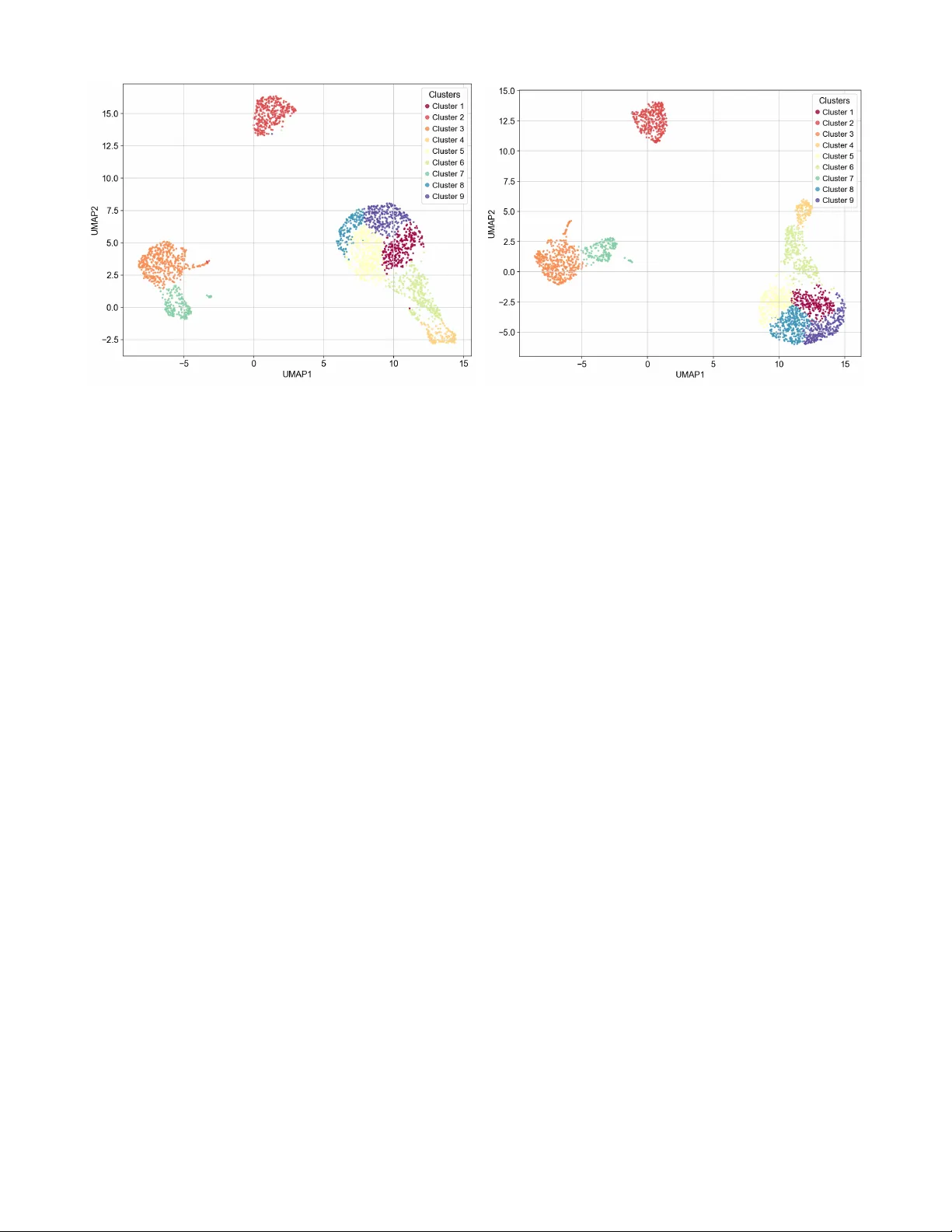
Ba y esian factorization via shrinkage Shic heng Liu, Qingping Zhou, Y anan F an, and Xiongw en Ke ∗ Sc ho ol of Mathematics and Statistics, Cen tral South Univ ersit y Data61, CSIR O, Sydney , A ustralia Marc h 31, 2026 Abstract F actor mo dels are widely used for dimension reduction. Ba yesian approac hes to these mo dels often place a prior on the factor loadings that allows for innitely many factors, with loadings increasingly shrunk to ward zero as the column index increases. Ho wev er, existing increasing shrinkage priors often p ossess complex hierarchical structures that complicate p os- terior inference. T o address this issue, we prop ose using an shrinkage prior. W e demon- strate that b y carefully setting the parameters in the hyper prior of its global shrinkage parameters, the increasing shrinkage prop erty is preserv ed. Our prior sp ecication is simple, facilitating the construction of an ecient Gibbs sampler for exact p osterior inference. F or faster computation, w e also prop ose a v ariational approximation algorithm. Through numer- ical studies, we compare our approac hes with current p opular Bay esian metho ds for factor mo dels, demonstrating their merits in terms of accuracy and computational eciency . K eywor ds: F actor analysis, shrinkage, Gibbs sampler, V ariational inference ∗ Corresp onding author: k exiongwen@csu.edu.cn 1 1 In tro duction The factor mo del can represent high-dimensional data through latent factors b y p erforming a low- rank factorization of the cov ariance matrix. It has b een applied in v arious elds, including so cial sciences ( Samartsidis et al. 2020 ), genomics studies ( Carv alho et al. 2008 ), economics ( Korobilis & Schröder 2025 ), and computer vision ( Lee et al. 2005 ). Ho w ever, additional structural assump- tions are often necessary to address the challenges associated with this mo del. F or instance, the dimension of the laten t factors is typically unkno wn, and it is natural to exp ect that the additional dimensions of the latent factor will play a progressively less imp ortant role in c haracterizing the structure of the data. Therefore, the asso ciated factor should receiv e a stronger p enalt y . F urther- more, a series of works ( Baik & Silverstein 2006 , Johnstone & Lu 2009 , Jung & Marron 2009 , Nadler 2008 , Birnbaum et al. 2013 ) ha v e shown that the traditional principal comp onent analysis (PCA) approac h can lead to inconsistent estimation of the principal eigenv ectors in the high-dimensional setting. The most popular approach to address this issue is to assume that the leading eigen v ectors exhibit a certain type of sparsit y , commonly referred to as sparse PCA in the literature ( Zou et al. 2006 , d’Aspremont et al. 2008 , CAI et al. 2013 ). On the Ba yesian front, numerous priors hav e b een developed in recent years to resolve these chal- lenges in factor mo dels. The main idea is to induce the group sparsity among the columns in the loading factor matrix, which leads to an automatic selection of the factor dimension and shrink- ing elements of the loading matrix to w ard zero. The seminal work b y Bhattac harya & Dunson ( 2011 ) introduced the m ultiplicativ e gamma pro cess (MGP) shrinkage prior, which allo ws for in- nitely many factors in the mo del, with elements of the factor loading matrix increasingly shrunk to w ard zero as the column index increases. Consequen tly , p osterior sampling adopts an adaptive approac h to automatically select the latent dimension, facilitating the identication of the opti- mal dimensionality . Building on this idea, the spike-and-slab type prior, whic h assigns sucient probabilit y mass to zero, has b een widely used to infer the factor dimensionality . Researc hers ha ve 2 com bined the spik e-and-slab prior with the P oisson pro cess ( PILLAI & DUNSON 2014 ), the Indian buet pro cess ( Knowles & Ghahramani 2011 , Rov ck ov a & George 2016 , Ohn & Kim 2022 ), and the stic k-breaking pro cess ( Legramanti et al. 2020 ) to construct the prior with increasing shrink- age prop erties. Another spike-and-slab prior pro vided by GAO & ZHOU ( 2015 ) oers promising theoretical results but is computationally intractable; they successfully implemen ted a p osterior sampler only for factor mo dels with a one-dimensional factor. Ba y esian inference on the p osterior often relies on Marko v-Chain Mon te Carlo (MCMC) algorithms. Recen tly , alternatives to MCMC as fast inference approac hes ha v e b een proposed, including the ex- p ectation maximization algorithms for p osterior mo de search with the spike-and-slab Lasso-Indian buet pro cess prior (SSL-IBP) ( Rov ck ov a & George 2016 ) and m ulti-scale generalized double Pareto prior ( Sriv astav a et al. 2017 ), as well as the v ariational inference (VI) for p osterior appro ximation with multiplicativ e gamma pro cess shrinkage prior ( Hansen et al. 2025 ), and the spike-and-slab prior ( Ning & Ning 2024 ). W e see that most of the recen t dev elopmen t of the prior for the Ba yesian factor mo del used spik e-and-slab type priors as a basic building blo c k. F ew follow-up w orks based on the global lo cal shrinkage prior ( P olson & Scott 2010 ) ha v e emerged since the in tro duction of the MGP shrinkage prior by Bhattac hary a & Dunson ( 2011 ). Sriv astav a et al. ( 2017 ) prop osed using the generalized double Pareto for factor mo dels but fo cused solely on p osterior mo de search. In this pap er, we consider using shrinkage prior from Ke & F an ( 2025 ) for the Ba yesian factor mo del. By carefully setting the parameters in the prior of global shrinkage parameters, w e ensure that the elemen ts of the factor loading matrix are increasingly shrunk to w ard zero as the column index increases, ac hieving a stronger sense of shrinkage than the MGP prior. Additionally , this prior has a simple structure, easing the p osterior inference. W e construct a Gibbs sampler as an exact inference approac h. Since MCMC metho ds are generally computationally intensiv e and memory-demanding, w e also propose a no v el collapsed v ariational inference method that in tegrates out b oth global and lo cal shrinkage parameters for fast p osterior approximation. In our numerical studies, we demonstrate the p erformance of our approach on b oth sim ulated and real datasets. 3 The rest of the pap er is organized as follo ws. Section 2 in tro duces the prior setting and discusses its prop erties. Section 3 details the Gibbs sampler. Section 4 presents the v ariational inference algorithm. Section 5 ev aluates the prop osed algorithms through numerical studies. Section 6 concludes with discussion. 2 Mo del and priors This section in tro duces the laten t factor mo del, follo w ed by the sp ecication of the shrinkage prior and its prop erties. 2.1 Laten t factor mo del The setup for factor analysis consists of an matrix of indep enden t observ ations with dimension . The latent factor mo del is of the form i.i.d. i.i.d. (1) where is the factor loading matrix that w eights the contributions of the - dimensional laten t factor and is an idiosyncratic error with cov ariance diag . Marginalizing out the latent factor , we hav e . 2.2 Prior Sp ecication Motiv ated by the Bay esian innite factor mo del ( Bhattachary a & Dunson 2011 , Legramanti et al. 2020 ), our approac h b egins b y assigning shrinkage prior ( Ke & F an 2025 ) on the individual elemen ts in with and and making the global shrinkage parameter sto c hastically increase with the column index of the factor loading matrix. Since the dimension of the latent factor is usually unkno wn, this setting allows the p osterior parameter 4 space to con tain all p ossible num b ers of latent factors. More formally , exp Gamma (2) where is a global shrinkage parameter for t he th column and , , . F or the shrinkage prior, it has the Gaussian mixture represen tation as shown by Ke & F an ( 2025 ): Exp Gamma (3) Finally , an inv erse-gamma prior is placed on the diagonal en tries of : IG for . 2.3 Prop erties of the shrinkage prior W e start with a prior for a loading matrix ha ving innitely many columns. It w as sho wn by Bhattachary a & Dunson ( 2011 ) that the set of loading matrix that leads to well-dened co v ariance matrices is max The factor loading matrix in the set guaran tees that has nite entries and is p ositiv e semi-denite. The next lemma pro vides the condition that the prior measure has full supp ort on . Lemma 2.1 If and , then . The proof is giv en in the Appendix A supplemen tary , along with the other pro ofs in this section. In practice, the loading matrix is truncated to a nite num b er of columns for tractable computation, as in Bhattac hary a & Dunson ( 2011 ). The truncated loading matrix is obtained b y deleting the columns of with index . The next theorem guaran tees that the c hoice of can make the co v ariance matrix arbitrarily close to , where distance b etw een and is measured using the sup-norm. 5 Theorem 2.2 If and , then for any , (4) for , wher e . The ab o v e theorem states that the prior probabilit y of b eing arbitrarily close to with inv erse p o w er fast rate as . Durante ( 2017 ) sho wed that the increasing shrinkage prop erties of the MGP shrinkage prior only hold in exp ectation but not in probabilit y . With this motiv ation, the cum ulativ e shrinkage pro cess (CSP) prior ( Legraman ti et al. 2020 ) w as prop osed. The next lemma states that this stronger sense of increasing shrinkage property also holds under the prior setting ( 2 ). Lemma 2.3 for any and . Finally , we show that our prior assigns p ositive probability to arbitrarily small neigh b orho o ds around any cov ariance matrix. Theorem 2.4 L et for al l and b e an - neighb orho o d of with r adius of under the sup-norm. If is any c ovarianc e matrix, then if and , for any . Then by using Theorem 2 of Bhattachary a & Dunson ( 2011 ), we obtain the weak consistency of the p osterior for . 3 Gibbs Sampling In this section, we denote as the row v ector and as the column vector from the matrix . W e further denote as the column v ector from the matrix . Suc h notations will b e used in the remaining sections. Then w e propose a Gibbs sampler for the posterior computation: 6 1. Sample for indep endently from InvGamma 2. Sample for indep endently from diag diag 3. Sample from whic h is done by the following step: • Sample for indep endently from • Sample sequentially from – Sample for indep enden tly from Gamma – Sample for and indep enden tly from , which is done by sampling : ∗ Sample InvGaussian ∗ Sample InvGaussian W e observ e that for dieren t latent dimensions , the conditional posteriors of global and lo cal shrinkage parameters are independent. In con trast, this prop ert y do es not hold for the p osteriors deriv ed from the MGP and CSP priors. 4 V ariational inference Although the Gibbs sampler can provide an exact p osterior inference, it is computationally intensiv e and memory-demanding. In this section, we use the v ariational inference to approximate the join t 7 p osterior . 4.1 Collapsed v ariational inference W e consider the follo wing mean-eld assumption: (5) where the second equality is follow ed by the fact that if the conditional p osterior of and hav e an indep enden t structure, then the indep enden t structure also holds for their v ariational p osterior ( Bishop & Nasrabadi 2006 ). Our approach relates to the collapsed v ariational inference ( T eh et al. 2007 ), whic h aims to improv e the accuracy of the appro ximation by marginalizing out the global and lo cal shrinkage parameters. The evidence low er b ound (ELBO) is then: log log log log log log log (6) F rom section 3 , we see that b oth , and belong to the exp onential family . Therefore, maximizing the ELBO of ( 6 ) leads to the and belong to the same distribution as their conditional p osterior ( Bishop & Nasrabadi 2006 ). Thus, w e ha v e: InvGamma Trc Cov (7) where , , diag , Cov and Cov . T o maximize the ELBO in ( 6 ), we p erform co ordinate-ascent optimization, iteratively up dating the v ariational parameters in each v ariational factor while keeping others xed. 8 4.2 Optimizing the ELBO with resp ect to Since the conditional p osterior do es not b elong to any simple distribution family , neither does . Th us additional eort is required to make computation tractable. W e further assume that and consider the v ariational p osterior MF where is the -dimensional m ultiv ariate t-distribution with lo cation parameter , scale matrix and degrees of freedom. When , the m ultiv ariate t-distribution con verges to the Gaussian distribution. W e set as v ariational parameters with for optimization. W e further restrict to guarantee the existence of the mean and cov ariance of the multiv ariate t-distribution. Before deriving our algorithm, we state some useful results: • The multiv ariate t-distribution has a scale-mixture of Gaussian hierarchical represen tation: Gamma (8) • The entrop y of -dimensional multiv ariate t-distribution is log ln (9) where log log log and is the digamma function. • Simple extension of Bonnet’s and Price’s Gradients ( Opp er & Archam b eau 2009 ): Consider the gradients with respect to the and of a Gaussian distribution , then for some suitable smo oth function , w e hav e z z z z z z (10) Our strategy is to learn and separately , rather than jointly learning the v ari- ational parameters . That is when up dating one of them, the other should b e xed. 9 4.2.1 Learning and No w w e write do wn the ELBO in ( 6 ) that dep ends only on and : log ln (11) where , and Cov with . It seems that w e can obtain the Mon te Carlo gradient of the ELBO with resp ect to the v ariational parameters by using Bonnet’s and Price’s theorem in equation ( 10 ). Then, the gradien t descen t t yp e algorithm can b e used. Ho w ev er, since log is non-dierentiable and non-Lipsc hitz at zero ( Ke & F an 2025 ), this theorem can not b e applied directly . The next Lemma helps us to nd a tractable lo wer bound of ( 11 ) as a surrogate function for optimization at eac h iteration. Lemma 4.1 F or any , we have log log (12) wher e is the c onstant term that do es not dep end on the variational p ar ameters and . In addition, if , (13) If , then the lower b ound in ( 12 ) b e c omes trivial as its right hand side attains . The proof is given in the supplemen tary App endix B, along with the other pro ofs in this section. By Lemma 4.1 , we hav e ln (14) The lo wer b ound we obtain in Lemma 4.1 is closely related to the lo cal quadratic approximation ( F an & Li 2001 ), whic h is one of the minorize-maximize (MM) algorithms ( Hunter & Li 2005 ). T o 10 a v oid the trivial lo wer b ound, Hunter & Li ( 2005 ) suggested b ounding the denominator aw ay from zero by adding a small p ositive tolerance num b er to mak e a slightly p erturb ed version of the low er b ound. In equation ( 13 ), w e lo calize the low er b ound ( 14 ) by setting and mo dify the term in the denominator to max at iteration . In practice, w e found that this strategy works v ery well. No w, the gradien t of v ariational parameters with resp ect to the surrogate function can b e obtained by Bonnet’s and Price’s theorem shown in ( 10 ): (15) where , , Cov and diag . Another c hallenge is that the precision matrix should b e constrained within the space of p ositiv e denite matrix and the traditional gradient descen t may violate this constrain t. In addition, it is w ell-known that the gradient descent on the Euclidean space do es not adequately capture the geometry of the probability distribution( Amari 1998 ). A small Euclidean distance b etw een and is not equiv alent to a small Kullbac k-Leibler div ergence b etw een and , and thus Homan et al. ( 2013 ) suggested using the natural gradien t for up dating the v ariational parameters. The natural gradient descent can b e view ed as a second-order optimization metho d where the Fisher information of the v ariational p osterior tak es the role of the Hessian matrix ( Martens 2020 ), resulting in faster conv ergence. Unfortunately , the Fisher information matrix of the v ariational parameter from has no closed-form expression. How ever, if we x and using the fact that the Multiv ariate t-distribution has a Gaussian-Gamma mixture representation shown in ( 8 ), then the Fisher infor- mation matrix of has a closed-form expression in the join t distribution , suc h that 11 where is the Kronec ker pro duct. That’s the reason wh y we up date separately . The next theorem provides a data augmentation p ersp ectiv e that justies the ab o ve argumen t. Theorem 4.2 With the me an le d assumption and , then for any xe d for , minimizing KL is e quivalent to minimizing KL In other wor ds, the dier enc e of their c orr esp onding ELBO is only a c onstant. Then we hav e the natural gradien t (16) A t eac h iteration , we up date the v ariational parameters by natural gradient descen t where is a step size parameter such that and ( Robbins & Monro 1951 ). W e see that with natural gradien t descen t, the p ositiv e deniteness of can b e guaran teed as long as its initialization is p ositiv e denite. 4.2.2 Learning Since we require to guaran tee that the mean and cov ariance of the multiv ariate t-distribution exist, for ease of optimization, we set with . Then the gradient of ELBO with resp ect to can b e written as Trc log (17) 12 where is the trigamma function. Since standard gradient descen t is inherently ”Euclidean”, whose up date rule has no mechanism to resp ect constrain ts , we use mirror descen t ( Beck & T eboulle 2003 , Raskutti & Mukherjee 2015 ), which rein terprets the up date in the ”dual space” with no constraint and uses the mirror map to pull the p oin t back in to the primal space. F or parameter space with p ositiv e constraint, we consider a mirror map that log , which is the generalized Shannon en tropy . Its gradien t function and the in v erse of gradien t function are log and exp , resp ectiv ely . At each iteration, we will • Compute gradien t . • Up date in the dual space : . • Map bac k from the dual space to the primal space: exp . The ab ov e steps can b e com bined into a very clean and simple form, whic h gives us the exp onen- tiated gradient up date rule: exp (18) W e see that the second term in ( 17 ) has no closed form. W e can use the REINF ORCE tric k or the Reparameterization T ric k to calculate the Monte Carlo gradient. In practice, gradients estimated from the reparameterization tric k often hav e smaller v ariance than the REINFOR CE trick, so they are preferred as long as such reparameterization exists. Unfortunately , the parameter w e wan t to optimize is in the Gamma distribution Gamma , whic h is not amenable to standard reparameterization. Naesseth et al. ( 2017 ) prop osed generalized reparameterization gra- dien ts for the shap e parameter in the Gamma distribution and show ed their sup erior p erformance o v er the REINFOR CE trick. Here w e follow their approac h with small mo dications adapted to our problem. By equation ( 8 ), w e write with 13 where is standard normal distribution and with Gamma . If there exists an inv ertible transform , then there exists , such that log log Then we can compute its gradien t with resp ect to log log pathwise gradient log log score-function gradien t (19) By nding an appropriate inv ertible transform , the score-function term will b e very small. In this case, the generalized reparameterization gradients will b e close to the reparameterization gradien ts. Naesseth et al. ( 2017 ) consider the inv ertible transform (20) By accept-reject sampling, we can generate a random v ariable with density (21) Then Gamma . The details of b oth accept-reject sampling and the deriv ation of the gradien t are given in the supplemen tary material. The pseudo co de for our v ariational inference algorithm is provided in Algorithm 1 . 14 Algorithm 1: V ariational Inference Inputs: , , , while do . IG Trc Cov . Up dating via natural gradient descent: for to do E end Set and calculate the MC gradient . for to do exp end Set end Result: , and 5 Numerical studies W e demonstrate the p erformance of the prop osed algorithms for the Ba y esian factor mo del with shrinkage using tw o syn thetic examples and tw o gene datasets. W e compared our algorithms with other comp eting metho ds, including the Gibbs sampler(GS) and v ariational inference(VI) for MGP shrinkage prior ( Bhattac harya & Dunson 2011 , Hansen et al. 2025 ), the Gibbs Sampler for CSP prior ( Legramanti et al. 2020 ) and the parameter expanded likelihoo d exp ectation maximiza- tion (PXL-EM) for SSL-IBP ( Ro v c ko v a & George 2016 ). Throughout the n umerical studies, w e set , and for our shrinkage prior. All the h yp erparameters in v olv ed in 15 the comp etitors are set as suggested by their reference. All the Gibbs samplers are run for 10,000 iterations with the rst 5,000 iterations discarded as a burn-in p erio d. In addition, we alwa ys set for all the metho ds in this section except for the v ariational inference for MGP ( Hansen et al. 2025 ). W e encoun tered numerical instabilit y issues with this algorithm when setting . Th us, we set for this algorithm. The increasing shrinkage priors will allo w us to estimate the eective dimension of the laten t factor , which is often muc h smaller. 5.1 Sim ulation studies W e consider tw o synthetic examples that ha ve b een studied b y Rov ck o v a & George ( 2016 ) and Hansen et al. ( 2025 ) resp ectively . These t wo examples incorp orate sparsit y and sp ecic structural patterns in the loading matrix, leading to sparsity structures in the non-diagonal elemen ts of the co v ariance matrix. In these tw o examples, we will rep eat the exp erimen ts for times and rep ort the mean and the standard deviation of the following metrics: • The F robenius norm b et ween and . • The false disco very rate (FDR) and the false negative rate (FNR) of the nonzero elemen ts in the cov ariance matrix. • The estimated eective factor cardinalit y . It should p oin t out that, except for the SSL-IBP , w e can not obtain the sparsit y of the factor loading matrix directly from the other metho ds as the con tinuous shrinkage priors assign zero probabilit y to the p oin t zero. Th us, some p ost selection inference pro cedures are required. T o estimate the eective laten t dimension, w e rst estimate the sparsit y of the factor loading matrix b y c hec king for zero in marginal credible interv als ( v an der P as et al. 2017 ). If is not in the marginal credible interv al, we declare it a signal, and otherwise we declare it as zero. If all the elemen ts in the column v ector are iden tied as zero, then the laten t dimension is not coun ted as eective. W e will use credible interv als in our n umerical studies. T o estimate the sparsit y 16 structure of the cov ariance, we use the simple thresholding rule: the element in the co v ariance matrix will b e identied as zero if the absolute v alue of its p osterior mean is smaller than . 5.1.1 Syn thetic example 1 F or the rst synthetic example, the data is generated by dra wing independent samples from the m ultiv ariate normal distribution with . Assuming latent factors, the factor loading matrix follo ws a blo c k-diagonal structure with ov erlapping nonzero elemen ts allocation. Sp ecically , eac h factor is associated with nonzero resp onses, suc h that , while the ov erlap b etw een successive factors is . The v alue of all the nonzero elemen ts in the factor loading matrix are set to b e 1. The blo c k-diagonal structure of leads to a true co v ariance matrix that is also blo c k-diagonal, as seen in Figure 1 (a). Figure 1 (b) and Figure 1 (c) show that b oth our tw o inference approac hes provide accurate esti- mation for the co v ariance matrix. The GS p erformed b etter than the VI as Figure 1 (c) is slightly blurred in the true sparsit y area, while Figure 1 (b) is quite clean. T able 1 conrms this observ ation as the F rob enius norm from VI is larger than the GS. Comparing with the comp etitors, b oth infer- ence approaches for shrinkage consistently outp erform the MGP and CSP but are b eaten by the SSL-IBP from Rov ck ov a & George ( 2016 ), which achiev ed smaller FDR and F robenius norm. Figure 2 provides the heatmap of the p osterior mean from the GS for the loading matrix with three dierent shrinkage priors. W e see that for all three metho ds, the v alue of the p osterior mean are close to zero for elemen ts in the factor loading matrix with column index larger than ve. Within the rst ve laten t dimensions, b oth shrinkage and MGP shrinkage pro vide a more structured sparsity estimation than CSP . But due to the iden tiable issue, none of them recov er the exact factor loading matrix. W e also compare the conv ergence sp eed of GS in this example. This is done by calculating the 17 (a) T rue (b) Gibbs Sampler (c) V ariational Inference Figure 1: (a) The true structure of the co v ariance matrix, (b) the p osterior mean of the co v ariance matrix from Gibbs sampler with shrinkage, (c) the p osterior mean of the cov ariance matrix from v ariational inference with shrinkage. FDR FNR F rob enius norm GS 69.28% (0.00) 0.00% (0.00) 5.00 (0.00) 344.79 (39.11) VI 69.28% (0.00) 0.00% (0.00) 5.00 (0.00) 416.12 (42.42) MGP GS 69.28% (0.00) 0.00% (0.00) 5.00 (0.00) 442.42 (41.52) VI 68.50% (0.00) 0.01% (0.00) 5.00 (0.00) 597.03 (31.47) CSP GS 69.29% (0.00) 0.00% (0.00) 5.00 (0.00) 487.70 (53.59) SSL-IBP PXL-EM 7.10% (0.09) 0.08% (0.00) 5.04 (0.20) 248.52 (44.55) T able 1: Comparison of inference algorithms for dieren t priors. 18 (a) (b) MGP (c) CSP Figure 2: The heatmap of the p osterior mean from the Gibbs samplers for the loading matrix with three dierent shrinkage priors. eectiv e sample size (ESS) for after the burn-in p erio d using arviz pac kage ( Kumar et al. 2019 ) and plotting their heatmaps in Figure 3 . In terms of ESS, the GS for shrinkage has the b est p erformance. Interestingly , the heatmap of the ESS for are someho w consistent with the heatmap of its p osterior mean, particularly for the shrinkage. The ESS are large for elements in that b elong to the non-eectiv e latent dimensions. F or shrinkage, the auto correlation of the samples in these elemen ts is almost zero. On the other hand, the ESS is v ery small for elemen ts iden tied as nonzero. 5.1.2 Syn thetic example 2 F or the second syn thetic example, the data is generated from with three com binations, namely , and . With the num b er of latent factors , each en try of the loading matrix w as set to zero with a probabilit y , or drawn from distribution with a probabilit y of . The elemen ts in the diagonal matrix w ere sampled indep endently from . T able 2 summarizes the numerical results from three scenarios. F or Scenario 2 and Scenario 3, b oth inference approac hes from shrinkage alw ays outp erformed all comp etitors. F or Scenario 19 (a) (b) MGP (c) CSP Figure 3: The heatmap of the eective sample size from the Gibbs samplers for the loading matrix with three dieren t shrinkage priors. 1, the shrinkage still outp erformed the MGP shrinkage prior and CSP prior but had a larger F rob enius norm than SSL-IBP . SSL-IBP had a smaller FDR but a muc h larger FNR than the other metho ds, indicating that SSL-IBP o v erestimates the sparsit y level of the co v ariance matrix. A dditionally , for Scenarios 3, the SSL-IBP failed to estimate the eectiv e latent dimension as it alw a ys had nonzero elements in eac h column vector of . F or all the scenarios, shrinkage can target the right num b er of the eective latent dimension exactly . Finally , w e made a run time comparison of dieren t Bay esian approaches across v arying data di- mensions and hardware congurations in T able 3 . Apart from our methods, the Pytorc h imple- men tations for the GS hav e also b een provided for both MGP and CSP , which allowing them to b e compared b oth in CPU and GPU. F or the VI for MGP and PXL-EM for SSL-IBP , we only ran the R co de they provided on CPU. On the Macb ook Air M5, the GS for MGP had the least computation cost; it w as signicantly faster than the GS for b oth shrinkage and CSP . While on the GPU, the GS for shrinkage b ecame the fastest, CSP sat in the middle, and the GS for MGP seemed to scale less eciently than the other t w o on GPU. Additionally , the only dierence among the three GS are the conditional 20 FDR FNR F rob enius norm Scenario 1: GS 55.20% (0.01) 0.07% (0.00) 5.00 (0.00) 93.59 (8.17) VI 54.35% (0.02) 0.42% (0.00) 5.00 (0.00) 101.53 (10.98) MGP GS 55.37% (0.01) 0.00% (0.00) 5.00 (0.00) 134.26 (11.52) VI 50.20% (0.01) 3.20% (0.01) 5.58 (0.50) 123.81 (8.06) CSP GS 55.47% (0.01) 0.02% (0.00) 4.94 (0.24) 129.40 (10.48) SSL-IBP PXL-EM 16.10% (0.04) 31.70% (0.02) 6.72 (1.23) 88.21 (9.34) Scenario 2: GS 55.32% (0.01) 0.06% (0.00) 5.00 (0.00) 38.21 (3.84) VI 54.98% (0.01) 0.05% (0.00) 5.00 (0.00) 52.24 (5.73) MGP GS 55.49% (0.01) 0.05% (0.00) 5.10 (0.30) 65.70 (4.81) VI 50.20% (0.01) 3.20% (0.01) 7.00 (0.00) 64.39 (5.83) CSP GS 55.31% (0.01) 0.03% (0.00) 5.00 (0.00) 64.35 (5.11) SSL-IBP PXL-EM 54.00% (0.01) 0.50% (0.00) 42.16 (6.28) 93.61 (8.28) Scenario 3: GS 55.13% (0.01) 0.06% (0.00) 5.00 (0.00) 195.46 (20.67) VI 54.98% (0.01) 0.06% (0.00) 5.00 (0.00) 262.62 (17.94) MGP GS 55.25% (0.01) 0.05% (0.00) 5.06 (0.24) 374.56 (17.56) VI 45.60% (0.01) 3.20% (0.00) 7.26 (0.44) 348.97 (23.49) CSP GS 55.49% (0.01) 0.03% (0.00) 5.00 (0.00) 373.67 (19.11) SSL-IBP PXL-EM 55.40% (0.01) 0.01% (0.00) 50.00 (0.00) 310.27 (39.80) T able 2: Comparison of inference algorithms for dieren t priors 21 p osterior of global and lo cal shrinkage parameters, suggesting that the GS for shrinkage has the b est parallelization strategies when sampling these conditional p osteriors. The VI for shrinkage is consistently m uch faster than the GS across all platforms and data sizes. The VI for MGP shrinkage is faster than our VI approach. How ever, due to numerical instabilit y issues, their approach could only b e implemen ted with , whereas for the other metho ds we set . The PXL-EM for SSL-IBP , whic h is a p osterior mo de searc h algorithm, is extremely fast even without GPU acceleration. The n umerical studies in tw o synthetic examples underscore the imp ortance of b oth algorithmic eciency (MCMC vs. VI) and hardw are selection (CPU vs. GPU) in scalable computation for Ba y esian factor mo dels. The GPU acceleration provides order-of-magnitude speedups for the GS. Our VI algorithm also b enets from GPU acceleration, though less dramatically . F or large scale problems, our VI algorithm oers a fa vorable sp eed-accuracy trade-o. 5.2 Real data application W e now presen t t wo gene datasets to illustrate our metho ds. 5.2.1 Lung cancer dataset W e study the gene expression dataset for lung cancer, which comprises expression lev els of 5000 genes and 56 sub jects, previously analyzed by Lee et al. ( 2010 ) and T an & Witten ( 2014 ) for the biclustering task. Its sub jects encompass 20 pulmonary carcinoid subjects (carcinoid), 13 colon cancer metastasis subjects (colon), 17 normal lung sub jects (normal), and 6 small cell lung subjects (small cell). Due to and is v ery small, such problem is often v ery challenge. Our goal here is to iden tify statistically signican t genes correlated with lung cancer and distinguish the four dieren t tumor types. As b efore, w e use the p osterior mean as the estimator for all the metho ds except for SSL-IBP , which uses the p osterior mo de. 22 Data Dimensions (100, 1956) (100, 1000) (500, 1000) (500, 5000) Macb o ok Air M5 32GB RAM GS VI MGP GS VI CSP GS SSL-IBP PXL-EM NVIDIA V100 32GB GS VI MGP GS CSP GS NVIDIA A100 40GB GS VI MGP GS CSP GS T able 3: A v erage computation cost in seconds across 10 sim ulation replications for Macb ook Air M5 and 50 simulation replications for NVIDIA GPUs. 23 T o prepro cess the data for analysis, we cen ter and scale it b efore running eac h algorithm. F rom Figure 4 we observ e that, although some uctuations exist, all the metho ds except the GS for MGP shrinkage show a strong trend of decreasing norm of as the column index increases. F or the shrinkage, the b ehavior of from GS and VI are very similar. Figure 5 presen ts the p osterior estimation of the latent factor scores. W e see that the rst tw o latent factors capture biologically meaningful v ariation that separates the four t yp es of tumors reasonably well for our tw o algorithms. Similar plots from the other methods hav e also b een giv en in supplemen tary App endix C. All of them separates the four t yp es of tumors. T o nd the relev an t genes correlated with lung cancer, w e select the nonzero elements in the loading factor matrix by chec king for zero in the credible in terv als with lev el for shrinkage, MGP shrinkage and CSP shrinkage. Since the PXL-EM for SSL-IBP produces the exact sparsity for the loading matrix , selecting the relev ant genes can b e done directly . T able 4 lists the p ercentage of nonzero elemen ts in the rst six column vectors in the loading factor matrix. W e observe that all metho ds, except GS for MGP , generally sho w a trend where the p ercentage of nonzero loadings decreases as increases from to . This indicates that the early factors capture the main signal, while later factors are increasingly shrunk. In addition, the GS pro duced more sparsity than VI for shrinkage. This could b e t w o reasons: • When and n is small, the p osterior is complex and multi-modal(zero mo de and nonzero mode). VI tries to appro ximate it with a uni-mo dal distribution (i.e. multiv ariate- t), the optimization often faces a trade-o. T o av oid the p enalt y for missing the probability region around nonzero mo de, it ma y shift its p osterior mean sligh tly a w ay from zero. F rom Figure 5 (a), we see that VI pro vided the larger norm of than GS. • The mean-eld assumption ma y lead to a narro w credible in terv als as it often underestimates the uncertaint y . Th us, for problems with small sample size, w e recommend using GS for shrinkage. 24 (a) shrinkage (b) MGP shrinkage (c) CSP and SSL-IBP shrinkage Figure 4: norm of the p osterior estimation . (a) Gibbs Sampler (b) V ariational Inference Figure 5: Scatter plot for the p osterior mean of from shrinkage 5.2.2 P eripheral blo o d monon uclear cells (PBMC) dataset W e analyze a single cell RNA-sequencing (scRNA-seq) dataset generated on 2.7k h uman p eripheral blo o d monon uclear (PBMC) cells, a v ailable in the Python pac kage scanp y ( W olf et al. 2018 ). This data consists of single cells that were sequenced on the Illumina NextSeq 500 with genes, which giv es us a count matrix. The v alues in this matrix represen t the n umber of molecules for eac h gene (i.e. ) that are detected in each cell (i.e. ). W e follo w ed the standard pre-pro cessing data approach from Stuart et al. 25 MGP CSP SSL-IBP GS VI GS VI GS PXL-EM 1 43.14% 80.36% 17.78% 68.78% 69.88% 51.52% 2 35.40% 71.24% 19.60% 46.98% 61.06% 34.60% 3 22.00% 52.12% 1.58% 29.06% 34.88% 32.98% 4 18.44% 42.24% 5.02% 21.60% 37.12% 27.62% 5 20.88% 42.76% 15.28% 16.28% 33.26% 20.38% 6 17.56% 35.62% 10.02% 10.66% 6.54% 33.28% T able 4: P ercen tage of nonzero elements in the rst six column vectors for . ( 2019 ), Hao et al. ( 2021 ), widely used in scRNA-seq analysis. Its steps include the selection and ltration of cells based on quality con trol criteria, log-normalization and scaling, and the detection of highly v ariable features. Sp ecically , for quality control, we ltered out the cells based on three criteria: • Cells that hav e unique feature counts o ver or less than . • Genes that are detected in fewer than cells. • Cells with the p ercentage of coun ts in mito c hondrial genes less than . These lters reduced the size of the coun t matrix to . Then, we normalized the feature expression measurements for each cell by the total expression of each feature, multiplied this b y a scale factor ( as a default setting), and log-transformed the result. Next, w e found genes that are highly expressed in some cells and lo wly expressed in others. F o cusing on these genes in do wnstream analysis helps highligh t biological signals in single-cell datasets ( Brenneck e et al. 2013 ). This further reduced the size of the matrix to . Finally , we standardized the data. The Ba y esian factor mo del was used to reduce the data dimension, helping us cluster the cells and iden tify gene markers. Results from PXL-EM for SSL-IBP are not sho wn for this dataset 26 as we failed to make it work. Figure 6 shows that b oth the GS and VI for shrinkage can shrink the column of the factor loading matrix v ariable to w ard zero as its index increases, which is a desirable result in terms of dimension reduction. It allows us to use the lo w-dimensional latent factor scores to cluster the cell. While for its comp etitors, only the VI for MGP shrinkage achiev es this target. The other metho ds only shrink the column of the factor loading matrix to a small num b er but not close to zero. (a) shrinkage (b) MGP and CSP shrinkage Figure 6: The norm of the column of the p osterior mean of the loading factor matrix . With the latent factor scores, w e cluster the cell with the worko w from Stuart et al. ( 2019 ): • Using p osterior mean of the eectiv e latent factor scores to compute the K-nearest neigh b or (KNN) graph, with edges in the graph dra wn betw een cells with similar score of laten t factors. • Clustering the neighborho o d graph with the Leiden graph-clustering metho d ( T raag et al. 2019 ). • Em b edding the graph in t wo dimensions with the UMAP algorithm ( McInnes et al. 2018 ) for visualization. F rom Figure 7 , w e see that the p osterior mean of laten t factor scores from the t wo metho ds for shrinkage yields 9 clusters, and the shap e of the clusters visualized by their UMAP plots agrees 27 quite well. (a) Gibbs Sampler (b) V ariational Inference Figure 7: Cell clusters from shrinkage visualized b y pro jecting to tw o dimensions with the UMAP algorithm. Finally , w e found mark er genes within each cluster, which can identify sp ecic cell types. As suggested by Ntranos et al. ( 2019 ), the Mann–Whitney U test ( Mann & Whitney 1947 ) can b e used to rank the marker genes in each cluster. More sp ecically , the test will compare the data in the cluster with the data from the rest. The rank of gene signicance in the test can be obtained. T able 5 lists the top three marker genes in each cluster and their inferred cell type obtained b y shrinkage. W e see that the t wo metho ds give almost the same top three mark er genes in eac h cluster. The small dierence exists in cluster and cluster . F rom Figure 7 (a) and (b), w e see that these tw o clusters are neigh b ors. Additionally , T able 5 sho ws that L TB and IL32 are the top three mark er genes in cluster and cluster . Thus, we can com bine these tw o clusters together with inferred cell t yp e CD4 T cells ( Hao et al. 2021 ). W e also see that the cluster and cluster are neighbor and their top three marker genes are rib osomal protein rich, which are constitutiv ely expressed in all the cell types. So we will not sp ecify their cell t yp e. Again, these tw o clusters can b e com bined together. With these renements, we will ha ve 7 clusters in total. UMAP plots 28 and the marker genes for the results from MGP shrinkage and CSP shrinkage will b e giv en in the supplementary App endix C. Both the results from GS and VI for MGP shrinkage prior are consisten t with us. The result from GS for CSP prior only has small dierence with us. Cluster Gibbs Sampler V ariational Inference T op Markers Inferred Cell Type T op Mark ers Inferred Cell T yp e 1 L TB, IL7R, LDHB Memory T cells L TB, IL7R, IL32 Activ ated T cells 2 CD74, HLA-DRA, CD79A B cells CD74, CD79A, HLA-DRA B cells 3 L YZ, S100A9, S100A8 Monocytes L YZ, S100A9, S100A8 Mono cytes 4 GZMB, NK G7, GNL Y NK cells GZMB, NK G7, PRF1 NK cells 5 IL32, LDHB, L TB Activ ated T cells IL32, CD3D, L TB Activ ated / Memory T cells 6 CCL5, NK G7, CST7 CD8 T cells NK G7, CCL5, CST7 CD8 T cells 7 COTL1, LST1, FCER1G Dendritic COTL1, LST1, F CER1G Dendritic 8 MALA T1, RPL32, RPS27 Not-sp ecic RPS27, RPL32, RPS12 Not-specic 9 RPS6, RPS3A, RPS12 Not-specic RPS12, RPS6, RPS3A Not-specic T able 5: T op three marker genes in eac h cluster and the inferred cell t yp e obtained b y shrinkage. 6 Conclusion and discussion W e hav e presen ted a new increasing shrinkage prior for disco vering the n um b er of laten t factors and studied its prop erties. F or p osterior inference, w e proposed the Gibbs sampler as an exact approac h and v ariational inference as an approximation approach. W e demonstrated that b oth our algorithms ha v e comparable or even b etter p erformance than other algorithms discussed in the pap er, show casing their sup eriority . While our VI algorithm is faster than the Gibbs sampler and scalable to large problems, it has 29 t w o limitations. First, the conv ergence sp eed can b e sensitive to the learning rate. Second, w e can only guaran tee the con vergence of the ELBO, and by using a decreasing learning rate, we can also guarantee the conv ergence of the v ariational parameters. Ho wev er, it is dicult to show that the conv ergence p oin t is a lo cal optimum. This is common to v ariational inference algorithms. F uture studies should fo cus on understanding its con vergence prop erties and trying to generalize our results to other mo dels. Lastly , an in teresting research direction in v olv es applying our increasing shrinkage prior to innite- width neural net works. Similar to the innite factor mo del, our prior would help select the width. In this context, curren t inference approaches cannot b e applied directly due to the lack of conjugacy b et w een the prior and likelihoo d. A new inference algorithm should b e dev elop ed. Disclosure statemen t No p otential conict of in terest w as rep orted b y the author(s). 7 Data A v ailabilit y Statemen t De-iden tied data hav e b een made av ailable at the following URL: • Lung Cancer datas et: https://doi.org/10.5281/zenodo.19255485 • PBMC dataset: https://doi.org/10.5281/zenodo.19255485 SUPPLEMENT AR Y MA TERIAL Supplemen tary Material: This supp orting information contains: • App endix A. Pro of of 2.1 - 2.4. • App endix B. Pro of of 4.1 and 4.2. • App endix C. Some extra results in the numerical studies. 30 Supp orting co de: The Python co de is av ailable at htt ps:/ /git hub. com /kex iong wen /Bay es_F a ctor_Model References Amari, S.-I. (1998), ‘Natural gradien t w orks ecien tly in learning’, Neur al c omputation 10 (2), 251– 276. Baik, J. & Silv erstein, J. W. (2006), ‘Eigenv alues of large sample cov ariance matrices of spik ed p opulation mo dels’, Journal of multivariate analysis 97 (6), 1382–1408. Bec k, A. & T eb oulle, M. (2003), ‘Mirror descent and nonlinear pro jected subgradien t metho ds for con v ex optimization’, Op er ations R ese ar ch L etters 31 (3), 167–175. Bhattac hary a, A. & Dunson, D. B. (2011), ‘Sparse ba yesian innite factor mo dels’, Biometrika 98 (2), 291–306. Birn baum, A., Johnstone, I. M., Nadler, B. & Paul, D. (2013), ‘Minimax b ounds for sparse p ca with noisy high-dimensional data’, A nnals of statistics 41 (3), 1055. Bishop, C. M. & Nasrabadi, N. M. (2006), Pattern r e c o gnition and machine le arning , V ol. 4, Springer. Brennec k e, P ., Anders, S., Kim, J. K., Kołodziejczyk, A. A., Zhang, X., Proserpio, V., Baying, B., Benes, V., T eic hmann, S. A., Marioni, J. C. et al. (2013), ‘Accoun ting for tec hnical noise in single-cell rna-seq exp eriments’, Natur e metho ds 10 (11), 1093–1095. CAI, T. T., MA, Z. & WU, Y. (2013), ‘Sparse p ca: Optimal rates and adaptiv e estimation’, The A nnals of Statistics 41 (6), 3074–3110. Carv alho, C. M., Chang, J., Lucas, J. E., Nevins, J. R., W ang, Q. & W est, M. (2008), ‘High- 31 dimensional sparse factor mo deling: applications in gene expression genomics’, Journal of the A meric an Statistic al A sso ciation 103 (484), 1438–1456. d’Aspremon t, A., Bach, F. & El Ghaoui, L. (2008), ‘Optimal solutions for sparse principal comp o- nen t analysis. ’, Journal of Machine L e arning R ese ar ch 9 (7). Duran te, D. (2017), ‘A note on the m ultiplicativ e gamma pro cess’, Statistics & Pr ob ability L etters 122 , 198–204. F an, J. & Li, R. (2001), ‘V ariable selection via nonconcav e p enalized lik eliho o d and its oracle prop erties’, Journal of the A meric an statistic al A sso ciation 96 (456), 1348–1360. GA O, C. & ZHOU, H. H. (2015), ‘Rate-optimal p osterior con traction for sparse p ca’, The A nnals of Statistics 43 (2), 785–818. Hansen, B., A v alos-P acheco, A., Russo, M. & De Vito, R. (2025), ‘F ast v ariational inference for ba y esian factor analysis in single and multi-study settings’, Journal of Computational and Gr aph- ic al Statistics 34 (1), 96–108. Hao, Y., Hao, S., Andersen-Nissen, E., Mauc k, W. M., Zheng, S., Butler, A., Lee, M. J., Wilk, A. J., Darby , C., Zager, M. et al. (2021), ‘Integrated analysis of multimodal single-cell data’, Cel l 184 (13), 3573–3587. Homan, M. D., Blei, D. M., W ang, C. & P aisley , J. (2013), ‘Sto c hastic v ariational inference’, the Journal of machine L e arning r ese ar ch 14 (1), 1303–1347. Hun ter, D. R. & Li, R. (2005), ‘V ariable selection using mm algorithms’, A nnals of statistics 33 (4), 1617. Johnstone, I. M. & Lu, A. Y. (2009), ‘On consistency and sparsit y for principal components analysis in high dimensions’, Journal of the A meric an Statistic al A sso ciation 104 (486), 682–693. 32 Jung, S. & Marron, J. (2009), ‘Pca consistency in high dimension, lo w sample size con text’, The A nnals of Statistics 37 (6B), 4104–4130. Ke, X. & F an, Y. (2025), ‘Bay esian regression’, Journal of Computational and Gr aphic al Statistics 34 (1), 199–210. Kno wles, D. & Ghahramani, Z. (2011), ‘Nonparametric ba y esian sparse factor mo dels with appli- cation to gene expression mo deling’, The A nnals of A pplie d Statistics 5 (2B), 1534. K orobilis, D. & Sc hrö der, M. (2025), ‘Probabilistic quan tile factor analysis’, Journal of Business & Ec onomic Statistics 43 (3), 530–543. Kumar, R., Carroll, C., Hartikainen, A. & Martín, O. A. (2019), ‘Arviz a unied library for exploratory analysis of bay esian mo dels in p ython’ . Lee, K.-C., Ho, J. & Kriegman, D. J. (2005), ‘Acquiring linear subspaces for face recognition under v ariable ligh ting’, IEEE T r ansactions on p attern analysis and machine intel ligenc e 27 (5), 684– 698. Lee, M., Shen, H., Huang, J. Z. & Marron, J. S. (2010), ‘Biclustering via sparse singular v alue decomp osition’, Biometrics 66 (4), 1087–1095. Legraman ti, S., Duran te, D. & Dunson, D. B. (2020), ‘Ba y esian cum ulativ e shrinkage for innite factorizations’, Biometrika 107 (3), 745–752. Mann, H. B. & Whitney , D. R. (1947), ‘On a test of whether one of tw o random v ariables is sto c hastically larger than the other’, The annals of mathematic al statistics pp. 50–60. Martens, J. (2020), ‘New insigh ts and p ersp ectives on the natural gradien t metho d’, Journal of Machine L e arning R ese ar ch 21 (146), 1–76. McInnes, L., Healy , J. & Melville, J. (2018), ‘Umap: Uniform manifold appro ximation and pro jec- tion for dimension reduction’, arXiv pr eprint arXiv:1802.03426 . 33 Nadler, B. (2008), ‘Finite sample appro ximation results for principal comp onent analysis: A matrix p erturbation approach’, A nnals of Statistics 36 (6), 2791–2817. Naesseth, C., Ruiz, F., Linderman, S. & Blei, D. (2017), Reparameterization gradien ts through acceptance-rejection sampling algorithms, in ‘Articial Intelligence and Statistics’, PMLR, pp. 489–498. Ning, Y.-C. B. & Ning, N. (2024), ‘Spik e and slab ba y esian sparse principal comp onen t analysis’, Statistics and Computing 34 (3), 118. Ntranos, V., Yi, L., Melsted, P . & Pac hter, L. (2019), ‘A discriminativ e learning approach to dieren tial expression analysis for single-cell rna-seq’, Natur e metho ds 16 (2), 163–166. Ohn, I. & Kim, Y. (2022), ‘P osterior consistency of factor dimensionalit y in high-dimensional sparse factor mo dels’, Bayesian A nalysis 17 (2), 491–514. Opp er, M. & Arc ham b eau, C. (2009), ‘The v ariational gaussian approximation revisited’, Neur al c omputation 21 (3), 786–792. PILLAI, N. S. & DUNSON, D. (2014), ‘P osterior con traction in sparse bay esian factor mo dels for massiv e co v ariance matrices b y deb deep pati, anirban bhattachary a’, The A nnals of Statistics 42 (3), 1102–1130. P olson, N. G. & Scott, J. G. (2010), ‘Shrink globally , act lo cally: Sparse ba y esian regularization and prediction’, Bayesian statistics 9 (501-538), 105. Raskutti, G. & Mukherjee, S. (2015), ‘The information geometry of mirror descen t’, IEEE T r ans- actions on Information The ory 61 (3), 1451–1457. Robbins, H. & Monro, S. (1951), ‘A sto c hastic appro ximation method’, The annals of mathematic al statistics pp. 400–407. 34 Ro v ck ov a, V. & George, E. I. (2016), ‘F ast bay esian factor analysis via automatic rotations to sparsit y’, Journal of the A meric an Statistic al A sso ciation 111 (516), 1608–1622. Samartsidis, P ., Seaman, S. R., Mon tagna, S., Charlett, A., Hic kman, M. & Angelis, D. D. (2020), ‘A ba yesian multiv ariate factor analysis mo del for ev aluating an interv ention by using observ a- tional time series data on m ultiple outcomes’, Journal of the R oyal Statistic al So ciety Series A: Statistics in So ciety 183 (4), 1437–1459. Sriv asta v a, S., Engelhardt, B. E. & Dunson, D. B. (2017), ‘Expandable factor analysis’, Biometrika 104 (3), 649–663. Stuart, T., Butler, A., Homan, P ., Hafemeister, C., Papalexi, E., Mauck, W. M., Hao, Y., Sto ec k- ius, M., Smib ert, P . & Satija, R. (2019), ‘Comprehensive in tegration of single-cell data’, c el l 177 (7), 1888–1902. T an, K. M. & Witten, D. M. (2014), ‘Sparse biclustering of transp osable data’, Journal of Compu- tational and Gr aphic al Statistics 23 (4), 985–1008. T eh, Y., Kurihara, K. & W elling, M. (2007), ‘Collapsed v ariational inference for hdp’, A dvanc es in neur al information pr o c essing systems 20 . T raag, V. A., W altman, L. & V an Ec k, N. J. (2019), ‘F rom louv ain to leiden: guaranteeing w ell- connected communities’, Scientic r ep orts 9 (1), 1–12. v an der P as, S., Szabó, B. & v an der V aart, A. (2017), ‘Uncertain t y quan tication for the horsesho e (with discussion). ’, Bayesian A nalysis 12 (4). W olf, F. A., Angerer, P . & Theis, F. J. (2018), ‘Scanpy: large-scale single-cell gene expression data analysis’, Genome biolo gy 19 (1), 15. Zou, H., Hastie, T. & Tibshirani, R. (2006), ‘Sparse principal comp onent analysis’, Journal of c omputational and gr aphic al statistics 15 (2), 265–286. 35
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment