AdaLTM: Adaptive Layer-wise Task Vector Merging for Categorical Speech Emotion Recognition with ASR Knowledge Integration
Integrating Automatic Speech Recognition (ASR) into Speech Emotion Recognition (SER) enhances modeling by providing linguistic context. However, conventional feature fusion faces performance bottlenecks, and multi-task learning often suffers from opt…
Authors: Chia-Yu Lee, Huang-Cheng Chou, Tzu-Quan Lin
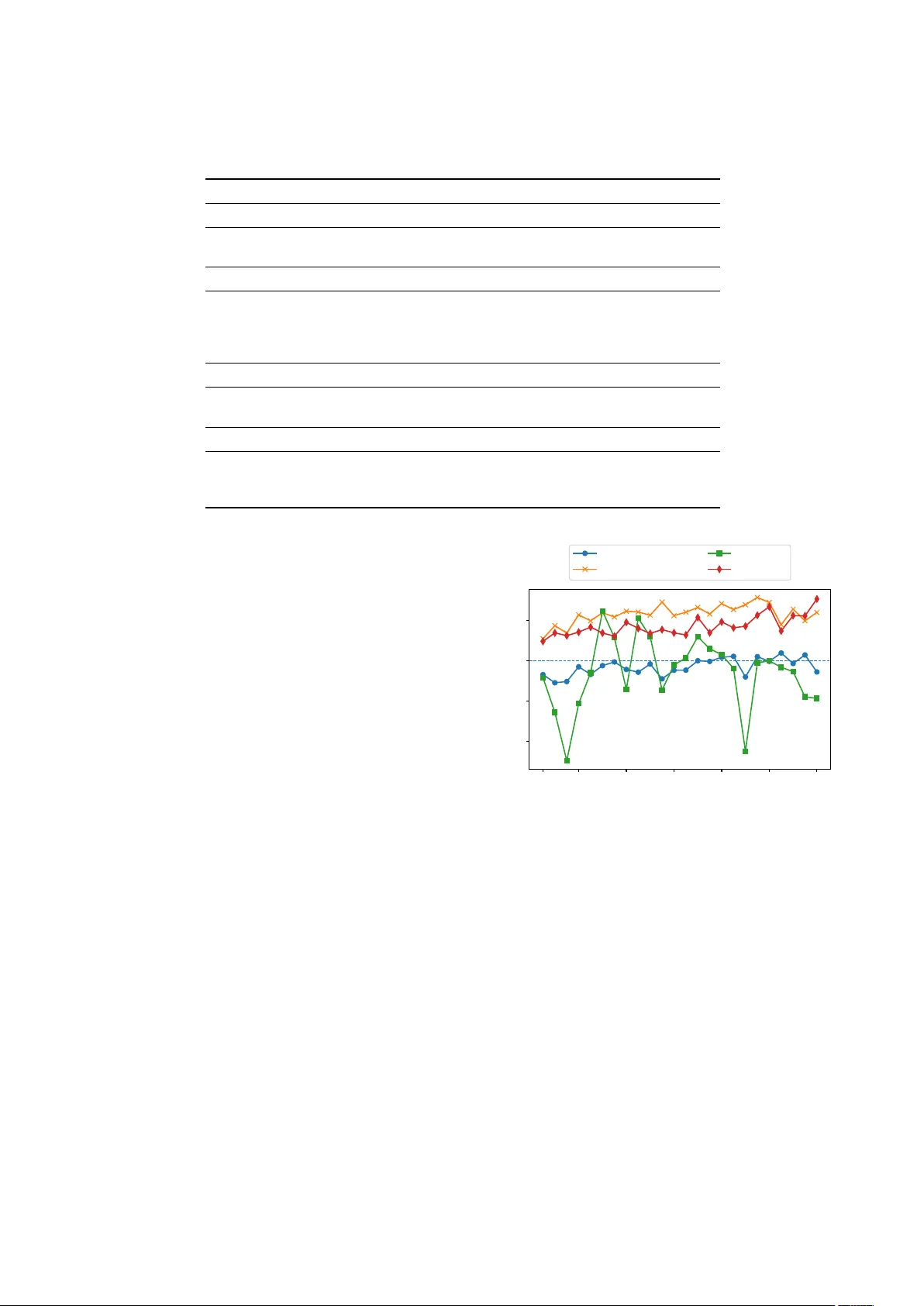
AdaL TM: Adaptiv e Layer -wise T ask V ector Mer ging f or Categorical Speech Emotion Recognition with ASR Knowledge Integration Chia-Y u Lee 1 , Huang-Cheng Chou ID 2 , ∗ , Tzu-Quan Lin ID 3 , ∗ , Y uanchao Li ID 4 , ∗ , Y a-Tse W u 1 , Shrikanth Narayanan ID 2 , Chi-Chun Lee ID 1 , ∗∗ 1 Behavioral Informatics & Interaction Computation (BIIC) Lab, Department of Electrical Engineering, National Tsing Hua Uni versity , Hsinchu 30013, T aiwan 2 Signal Analysis and Interpretation Laboratory (SAIL), Ming Hsieh Department of Electrical and Computer Engineering, Uni versity of Southern California, Los Angeles, CA 90089, USA 3 Graduate Institute of Communication Engineering, National T aiwan Uni v ersity , T aipei, T aiwan 4 Uni versity of Edinb urgh, Edinbur gh, UK aqz7793@gmail.com, cclee@ee.nthu.edu.tw Abstract Integrating Automatic Speech Recognition (ASR) into Speech Emotion Recognition (SER) enhances modeling by providing linguistic context. Howe ver , conv entional feature fusion faces performance bottlenecks, and multi-task learning often suffers from optimization conflicts. While task vectors and model merging have addressed such conflicts in NLP and CV , their potential in speech tasks remains largely une xplored. In this work, we propose an Adaptiv e Layer-wise T ask V ector Merg- ing (AdaL TM) frame work based on W avLM-Lar ge. Instead of joint optimization, we e xtract task v ectors from in-domain ASR and SER models fine-tuned on emotion datasets. These vectors are integrated into a frozen base model using layer -wise learn- able coefficients. This strategy enables depth-aware balancing of linguistic and paralinguistic kno wledge across transformer layers without gradient interference. Experiments on the MSP- Podcast demonstrate that the proposed approach effecti vely mit- igates conflicts between ASR and SER. Index T erms : speech emotion recognition, adaptive learning, task vector 1. Introduction and Related W ork Speech Emotion Recognition (SER) is intrinsically multimodal, relying hea vily on both acoustic cues and linguistic content [1, 2]. Consequently , integrating knowledge from Automatic Speech Recognition (ASR) has become a standard paradigm to enhance SER performance [3, 4]. Early approaches focused on output-lev el fusion, where textual representations from ASR are combined with acoustic features [5, 6]. Howev er , this strategy is limited by its sensitivity to ASR transcription errors, particu- larly on expressiv e speech [4], and it fails to foster deep, inter- mediate interactions between modalities [7]. T o enable deeper fusion, many ha ve resorted to Multi-T ask Learning (MTL), jointly optimizing ASR and SER objectiv es within a shared acoustic encoder [8, 3]. Y et, this introduces a sev ere optimization conflict, as the tasks’ objecti ves are funda- mentally misaligned. ASR seeks emotion-in variant repr esenta- tions by suppr essing paralinguistic variability , wher eas SER r e- lies pr ecisely on such variability to infer emotional states [9, 4]. The resulting gradient interference often degrades the model’ s * These authors contributed equally . ** indicates the corresponding author . Figure 1: The proposed Adaptive Layer -wise T ask V ector Mer g- ing (AdaLTM) framework. The pr e-trained bac kbone and task vectors ( W base , ∆ W AS R , ∆ W S E R ) remain fr ozen, while only the layer-wise merging coefficients ( λ ) and the downstr eam pr e- diction head ar e updated. ability to learn robust emotional cues, motiv ating a paradigm shift away from gradient-based joint optimization. Recently , operating directly in the weight space via task vectors has emer ged as a promising, optimization-free alterna- tiv e [10]. By defining a task vector τ as the difference between fine-tuned parameters ( θ ft ) and pre-trained parameters ( θ pre ), one can algebraically add a task’ s capability to a base model: τ = θ ft − θ pre . While task vectors have been successfully ap- plied across various speech domains [11, 12, 13], their use in SER remains largely une xplored. Furthermore, we identify a critical, previously overlooked bottleneck in applying this paradigm to ASR-enhanced SER: domain mismatch . W e find that simply merging a task vector from a standard, out-of-domain ASR model (e.g., fine-tuned on Librispeech [14]) yields sub-optimal results. Such models are trained to be emotion-agnostic, actively discarding the rich par- alinguistic cues (e.g., laughter , pitch contours) that are vital for SER. This aligns with recent findings that highlight the impor - tance of domain consistency and careful integration strategies when lev eraging ASR kno wledge [7, 9, 15]. T o resolve both the optimization conflict and the domain mismatch, we propose the Adaptive Layer-wise T ask V ector Merging (AdaL TM) framework (sho wn in Figure 1). Instead of joint training, we first e xtract separate task vectors from ASR and SER models that ha ve been independently fine-tuned on the target emotional domain (MSP-Podcast [16, 17]). Building on recent advances in adaptive merging [18], we introduce learn- able layer-wise coef ficients that dynamically balance and inject these in-domain task v ectors into a frozen W avLM-Lar ge back- bone [19]. W e employ W avLM-Large as our backbone, mo- tiv ated by its leading performance on the SUPERB [20] and EMO-SUPERB [21] SER benchmarks. For each layer l , the merged weights θ ( l ) merged are computed as: θ ( l ) merged = θ ( l ) pre + α ( l ) τ ( l ) ASR + β ( l ) τ ( l ) SER , (1) where α ( l ) and β ( l ) are learnable parameters. Our main contri- butions are threefold: • W e introduce a nov el adaptive layer-wise model-merging framew ork ( AdaL TM ) that integrates ASR knowledge into SER, effecti vely resolving the optimization conflicts inherent to traditional MTL. 1 • W e establish the critical role of domain consistency in task vector merging, demonstrating that in-domain ASR knowl- edge significantly outperforms out-of-domain alternativ es. • W e analyze layer-wise merging dynamics and achie ve a com- petitiv e Unweighted A verage Recall of 38.94% (Macro-F1 scroe of 35.20%) on the MSP-Podcast dataset. 2. Methodology W e propose Adaptiv e Layer-wise T ask V ector Merging (AdaL TM), shown in Figure 1, a framework that enhances SER by extracting task-specific kno wledge into task vectors and adaptiv ely integrating them into a pre-trained backbone. W e employ two distinct layer-wise mechanisms: λ for weight-space task vector mer ging, and α for downstream feature aggre gation. 2.1. T ask V ector Formulation W e employ the W avLM-Large model as our foundational back- bone, denoted by its pre-trained weights W base . T o cap- ture domain-specific and task-specific knowledge, we fine-tune W base on distinct target tasks using Differential Learning Rates (DLR). Specifically , we fine-tune the base model on the MSP- Podcast dataset to deri ve both an SER-specific model ( W S E R ) and an in-domain ASR model ( W AS R ). A task vector repre- sents the direction and magnitude in the weight space required to adapt the base model to a specific task. W e define the ASR and SER task vectors as the element-wise weight residuals: ∆ W AS R = W AS R − W base . (2) ∆ W S E R = W S E R − W base . (3) By isolating these vectors, we capture the transition from generalized acoustic representations to specialized knowledge (i.e., textual mapping for ASR and paralinguistic extraction for SER) without modifying the original backbone. 2.2. Adaptive Lay er -wise Merging Strategy Model merging normally applies a single scaling factor across all layers, which fails to account for the varying levels of ab- straction learned at different depths of the transformer . T o ad- dress this, we propose an adaptive Layer-wise merging strat- egy . W e partition the W avLM-Large model into 25 distinct lay- ers: one non-encoder layer (comprising the CNN feature ex- tractor and positional embeddings), denoted as index l = 0 , and the subsequent 24 transformer encoder layers, index ed as l ∈ { 1 , 2 , . . . , 24 } . For each layer l , we introduce layer-wise, 1 https://anonymous.4open.science/r/AdaL TM-62A2/ continuous learnable parameters λ ( l ) AS R and λ ( l ) S E R to dynam- ically scale the respectiv e task vectors. The merged weight W ( l ) merg ed for the l -th layer is formulated as: W ( l ) merg ed = W ( l ) base + λ ( l ) AS R ∆ W ( l ) AS R + λ ( l ) S E R ∆ W ( l ) S E R . (4) Both λ ( l ) AS R and λ ( l ) S E R are initialized to 0 . 5 , a v alue empiri- cally found to provide a stable starting point for the optimization process, ensuring the generalized capabilities of the base model are preserved initially . 2.3. T ask-Specific Optimization During the final phase of emotion training, we utilize the model parameterized by dynamically composed weights W merg ed as a feature extractor . T o effecti vely aggregate the hierarchical fea- tures, we extract the hidden states H ( l ) from all 24 transformer layers and apply a learnable weighted sum mechanism to form the final representation H out : H out = 24 X l =1 α l H ( l ) , (5) where α l are the normalized, trainable layer weights. H out is then fed into a SER Prediction Head for the final classifica- tion. Crucially , to prevent catastrophic forgetting, the backbone weights ( W base , ∆ W AS R , and ∆ W S E R ) are strictly frozen during this phase. The only trainable parameters are the layer- wise merging coefficients { λ ( l ) AS R , λ ( l ) S E R } 24 l =0 , the weighted sum weights { α l } 24 l =1 , and the parameters of the Emotion Pre- diction Head. This architecture enforces the model to learn how to integrate ASR kno wledge for enhancing SER performance. 3. Experimental Setup 3.1. Dataset and Backbone Models All experiments are conducted on the MSP-Podcast (v1.12) cor- pus [16, 17] to ensure domain consistency for both primary SER and auxiliary ASR tasks. The SER task is an 8-class classi- fication problem (Anger, Contempt, Disgust, Fear , Happiness, Neutral, Sadness, Surprise). T o ensure high-quality ASR super- vision, we use only samples with human-annotated transcripts, resulting in 89,752 training, 25,232 v alidation, and 46,366 test samples. Our frame work is built upon the pre-trained W avLM-Lar ge foundation model ( W base ). T o extract the necessary task vec- tors, we employ three fine-tuned model v ariants: • Primary SER Model ( W S E R ): A W avLM-Lar ge model fine-tuned on MSP-Podcast for SER [22] 2 , establishing our acoustic baseline with a MaF1 of 35.56%. • In-domain ASR Model ( W AS R in ): A W avLM-Lar ge model fine-tuned on MSP-Podcast transcripts, achieving a robust WER of 23.09% on the test set and providing domain-aligned linguistic knowledge. • Out-of-domain ASR Model ( W AS R out ): A standard W avLM-Lar ge model fine-tuned on LibriSpeech 100h 3 , used as a baseline to demonstrate the importance of domain con- sistency . It yields a much higher WER of 37.86%. 2 https://huggingface.co/tiantiaf/wa vlm-large-categorical-emotion 3 https://huggingface.co/patrickvonplaten/w avlm-libri-clean-100h-lar ge T able 1: P erformance comparison of differ ent ASR inte gration str ate gies and merging configurations on the MSP-P odcast dataset. All metrics ar e r eported in (%). Best results for our pr oposed paradigm ar e in bold . Pre. : Pr ecision; MaF1 : Macr o-F1. W e r eport the 95% confidence interval (CI) for each SER r esult using the toolkit [23]. Method/Setup U AR Pre. MaF1 WER P art 1: Multi-T ask Learning (MTL) Baselines W avLM-Lar ge (Fully T rainable) 29.54 ± 0 . 38 33.35 ± 1 . 47 28.40 ± 0 . 51 99.12 MTL w/ static init. ( W base + 0 . 5∆ W ) 29.21 ± 0 . 38 38.30 ± 2 . 46 29.06 ± 0 . 50 66.37 P art 2: Ablation Study of Our Merging Paradigm (AdaLTM) Setup 1: Baseline (Frozen Backbone) 37.05 ± 0 . 67 34.46 ± 0 . 42 34.46 ± 0 . 47 - Setup 2: ASR-Only V ector 37.57 ± 0 . 67 34.43 ± 0 . 38 33.56 ± 0 . 42 - Setup 3: SER-Only V ector 39.09 ± 0 . 60 34.80 ± 0 . 39 35.41 ± 0 . 44 - Setup 4: Proposed Dual-V ector 38.94 ± 0 . 61 34.26 ± 0 . 42 35.20 ± 0 . 48 - P art 3: Importance of Domain (Dual-V ector Merging) Out-of-Domain Dual-V ectors 38.68 ± 0 . 63 34.20 ± 0 . 43 34.84 ± 0 . 48 - In-Domain Dual-V ectors (Ours) 38.94 ± 0 . 61 34.26 ± 0 . 42 35.20 ± 0 . 48 - P art 4: Importance of Granularity (Merging Strategy) Static Global Merging ( λ = 0 . 5 ) 38.30 ± 0 . 61 34.71 ± 0 . 46 35.73 ± 0 . 51 - Adaptiv e Global Merging 38.93 ± 0 . 60 34.02 ± 0 . 43 34.85 ± 0 . 47 - Adaptiv e Layer -wise Merging (Ours) 38.94 ± 0 . 61 34.26 ± 0 . 42 35.20 ± 0 . 48 - 3.2. Comparison Setups W e design two sets of experiments to validate our approach. First, to demonstrate the synergy of our dual-vector merging, we conduct a comprehensi ve ablation study , with results presented in Part 2 of T able 1. The setups include: (1) Baseline , a frozen W avLM backbone without merging; (2) ASR-Only , merging only the in-domain ASR vector; (3) SER-Only , merging only the SER vector; and (4) Proposed Dual-V ector , our complete framew ork integrating both. Second, to justify the necessity of layer-wise granular- ity , we compare our proposed Adaptive Layer -wise strategy against two global baselines (Part 4 of T able 1): a Static Global merge with a fixed λ = 0 . 5 for all layers, and an Adaptive Global merge that learns a single shared λ across all layers. 3.3. Implementation Details and Metrics T o prevent catastrophic forgetting, the pre-trained backbone ( W base ) and task vectors ( ∆ W ) are frozen during all do wn- stream experiments. T raining is restricted to the layer-wise merging coef ficients λ (initialized to 0.5), the weighted sum weights α l , and the emotion prediction head. These param- eters are optimized using the AdamW optimizer [24] with a learning rate of 1 . 0 × 10 − 4 and a batch size of 32. T o ad- dress class imbalance in the MSP-Podcast dataset, we employ a class-balanced soft cross-entropy loss [25, 26]. For each e xperi- ment, the model checkpoint with the lowest validation loss from 100 training epochs is selected for evaluation. Performance is primarily ev aluated using Unweighted A verage Recall (UAR), supplemented by Precision and Macro-F1 (MaF1) for a com- prehensiv e analysis. All experiments were conducted using the PyT orch frame work [27] on two NVIDIA V100 GPU (64GB). 1 4 8 12 16 20 24 Layer index 0.40 0.45 0.50 0.55 λ value Dual-ASR-V ector Dual-Emo-V ector Only ASR Only Emo Figure 2: Layer-wise Dynamics: Dual vs. Single T ask V ectors. Blue line : Pr oposed dual-vector ASR. Orange line : Dual-vector SER. Gr een line : Only-ASR setup. Red line : Only-SER setup. 4. Results and Analyses 4.1. Baseline Comparison: Overcoming Conflicts T o ev aluate the limitations of conv entional MTL, we compare our frame work against two fully trainable baselines updating via joint ASR and SER losses. T o mitigate initialization bias, the second baseline initializes with statically merged task vec- tors ( W base + 0 . 5∆ W AS R + 0 . 5∆ W S E R ). As shown in Part 1 of T able 1, conv entional MTL ap- proaches exhibit sev ere gradient interference, or the “seesa w ef- fect. ” Although static initialization constrains auxiliary WER to 66.37% (vs. 99.12% for the vanilla backbone), t he primary SER performance inevitably collapses to a U AR of 29.62%. This confirms that jointly optimizing a single backbone for diamet- rically opposed tasks: emotion-in variant ASR versus emotion- 1 4 8 12 16 20 24 Layer index 0.48 0.50 0.52 0.54 0.56 0.58 λ value In Domain Model ASR In Domain Model Emo Out Domain Model ASR Out Domain Model Emo Figure 3: Impact of Domain Consistency on T ask V ector Mer g- ing. Blue line : In-domain ASR vector . Or ange line : In-domain SER vector . Gr een line : Out-domain ASR vector . Red line : Out- domain SER vector . rich SER, degrades acoustic representations. In contrast, AdaL TM eliminates these conflicts by strictly freezing the backbone during adaptiv e layer-wise merging. This strategy achieves a UAR of 38.62% and Precision of 34.55%, an absolute improvement of over 8.4% compared to the best MTL epoch, substantiating that multi-task kno wledge is most effecti vely unified via weight-space merging rather than joint backpropagation. Furthermore, compared to the fully trainable MTL baseline updating ov er 300M parameters, our AdaL TM approach achieves this superior performance while updating less than 1% of the total parameters, demonstrating significant computational efficienc y during the adaptation phase. 4.2. The Synergy of Complementary T ask V ectors Part 2 of T able 1 presents a comprehensiv e ablation study vali- dating the necessity of our dual-v ector approach. The progres- sion of these results clearly illustrates the additiv e and synergis- tic value of merging complementary task vectors. The progres- sion of these results clearly illustrates the additiv e and synergis- tic value of mer ging complementary task vectors. The experiment begins with Setup 1 (Baseline) , which uses the frozen W avLM backbone as a static feature e xtractor . This yields a U AR of 37.05%, reflecting the performance ceiling of relying solely on generalized, pre-trained acoustic representa- tions for this task. Next, Setup 2 (ASR-Only) introduces linguistic knowl- edge by merging exclusiv ely with the in-domain ASR task vec- tor , raising the UAR to 37.57%. This demonstrates that con- versational linguistic conte xt provides a fundamental le vel of emotional discriminability , but the marginal impro vement sug- gests it lacks the explicit paralinguistic fine-tuning required for robust SER. Con versely , Setup 3 (SER-Only) captures these crucial paralinguistic nuances by merging only with the SER task vec- tor . This achiev es a much stronger UAR of 39.09%, establishing a rigorous single-vector merging baseline. The absolute gain of 2.04% UAR ov er the baseline proves that adaptively scaling a frozen, task-specific residual v ector is a vastly superior strate gy to using the base model’ s raw features. Finally , Setup 4 (Proposed Dual-V ector) inte grates both ASR and SER vectors simultaneously , achieving a highly com- petitiv e peak UAR of 38.94%. This result demonstrates a defini- tiv e synergistic effect. By independently scaling the ASR and SER vectors, our adaptiv e mechanism seamlessly interlocks textual semantics (“what is being said, ” from Setup 2) with acoustic prosody (“how it is spok en, ” from Setup 3). The marginal 0.15% U AR reduction compared to the SER- Only setup reflects the physical constraints of representational crowding: accommodating both emotion-in variant le xical map- pings and emotion-rich prosody within a fixed-capacity model introduces slight parameter competition. This observation is highly consistent with recent findings in adapti ve model merg- ing [18], which demonstrate that individual task-specific e xpert models inherently establish a performance upper bound, mak- ing minor degradations during multi-task weight fusion an ex- pected theoretical outcome. Howe ver , the critical takeaway is the framew ork’ s robust- ness. Unlike joint-training approaches that suffer from catas- trophic interference, our layer-wise mechanism successfully navigates this crowding, preserving the expert-le vel capability of the SER vector while safely inte grating te xtual semantics. This combined integration definiti vely outperforms the standard static baseline (Setup 1) by a 1.89% absolute margin in U AR. 4.3. Impact of Domain and Layer -wise Knowledge Our experiments also underscore the critical importance of both domain alignment and mer ging granularity , with results detailed in Part 3 and 4 of T able 1. Domain Consistency is Key: When replacing the in- domain ASR vector with an out-of-domain (LibriSpeech-tuned) one, the UAR drops from 38.94% to 38.68%. While this per- formance is still strong, the de gradation confirms that domain- aligned linguistic features provide a more effecti ve semantic an- chor , as visually supported by our layer-wise analysis in Sec- tion 4.4. Layer -wise Granularity Matters: W e compared our pro- posed adaptiv e layer-wise merging against two global strate- gies. A static global merge with a fixed λ = 0 . 5 yields a U AR of 38.30%. An adaptiv e global strate gy , which learns a sin- gle shared λ for all layers, improv es this to 38.93%. Howev er , our adaptiv e layer-wise approach achieves the highest U AR of 38.94%, demonstrating that providing the model with the fle xi- bility to balance ASR and SER knowledge differently across the network’ s depth is crucial for resolving representational con- flicts and achieving optimal performance. 4.4. Layer -wise Dynamics: Unv eiling Multi-T ask Synergy and Domain Mismatch T o physically interpret our merging results, Figure 2 visualizes the learned layer-wise λ trajectories across the 24 transformer layers. These distributions re veal exactly how the model man- ages representational crowding and domain interference. In-Domain Synergy: Linguistic Anchoring and Prosodic Dominance. In our proposed dual-vector setup, the in-domain ASR weights ( λ AS R in , blue line) stabilize remarkably near the 0.5 baseline, sharply contrasting the sev ere v olatility seen when the ASR vector is used alone (green line). This proves that when acoustic prosody is av ailable, the ASR vector no longer strug- gles to predict emotions; instead, it functions as a stable linguis- tic anchor . Supported by this semantic foundation, the SER vec- tor achiev es absolute prosodic dominance. Across the middle- to-deep layers, the dual-setup SER weights (orange) track con- sistently higher than the single-setup SER weights (red). The adaptiv e mechanism confidently amplifies paralinguistic fea- tures, physicalizing the 1 + 1 > 1 synergy observed in our U AR metrics. Out-Domain Mismatch: Feature Suppression and Opti- mization Chaos. Conv ersely , introducing an out-of-domain task vector severely disrupts this balance. First, the in-domain SER weights ( λ E mo out ) are acti vely suppressed across the middle and deep layers, demonstrating that emotion-agnostic textual features directly hinder the extraction of paralinguistic cues. Furthermore, the out-domain ASR weights ( λ AS R out ) exhibit violent fluctuations, culminating in an unnatural, chaotic spike in the final semantic blocks (layers 20–24). This optimization chaos occurs because the model erratically up-scales conflict- ing, rigid textual mappings in a failed attempt to minimize the loss. This visually confirms that without strict domain align- ment, adapti ve merging degrades into gradient instability and representational interference. 5. Discussion and Conclusion This work demonstrates that operating in the weight space via Adapti ve Layer -wise T ask V ector Merging (AdaL TM) pro- vides an effecti ve alternative to con ventional multi-task learn- ing for integrating auxiliary ASR knowledge into SER. By av oiding joint backpropagation, the proposed framew ork elimi- nates gradient interference between ASR and SER objectives, which commonly limits traditional joint training paradigms. Our layer-wise analysis further suggests that deeper transformer blocks benefit more from domain-aligned linguistic representa- tions, supporting the importance of both domain consistency and layer-wise granularity in multi-task model mer ging. Extensiv e experiments confirm that domain alignment plays a critical role in successful task vector integration. In- corporating an in-domain ASR task vector (MSP-Podcast) con- sistently improv es performance, particularly for high-arousal emotions characterized by strong acoustic variability , whereas merging an out-of-domain vector (LibriSpeech) leads to per- formance degradation. These findings highlight that auxiliary linguistic kno wledge must be both structurally and distribution- ally compatible with the tar get emotional domain. Overall, the proposed approach achieves a U AR of 38.62%, demonstrating that task vector mer ging is viable for ASR-enhanced SER. Despite these promising results, sev eral limitations remain. First, the ef fectiv eness of AdaL TM depends on the availabil- ity of in-domain transcriptions to fine-tune the auxiliary ASR model. For under-resourced emotional datasets lacking reliable transcripts, extracting a highly compatible ASR task vector re- mains challenging. Second, although the do wnstream adapta- tion stage is parameter-efficient (updating only the layer-wise coefficients ( λ ) and the prediction head), the initial extraction of task vectors requires fine-tuning separate foundation models, introducing additional computational overhead. Future work will focus on resolving these limitations toward more general- izable and zero-shot SER scenarios. 6. Acknowledgments This work was supported in part by the National Science and T echnology Council (NSTC), T aiwan, under Grant No. 114- 2917-I-564-030 (to H.-C. Chou). The successful completion of this research was made possible by the academic resources and advanced research infrastructure provided by the National Center for High-Performance Computing, National Institutes of Applied Research (NIAR), T aiwan. W e gratefully acknowl- edge their in v aluable support. W e also thank T iantian Feng and Hung-yi Lee for insightful discussions and feedback. 7. Generative AI Use Disclosur e Generativ e AI tools were used only for minor improvements in language and presentation. No AI system w as used to generate, modify , or interpret the scientific content of this manuscript. All authors are fully accountable for the originality and v alidity of the research. 8. References [1] C. M. Lee and S. S. Narayanan, “T o ward detecting emotions in spoken dialogs, ” IEEE Tr ansactions on Speech and Audio Pr o- cessing , vol. 13, no. 2, pp. 293–303, mar 2005. [2] C.-C. Lee, T . Chaspari, E. M. Provost, and S. S. Narayanan, “ An engineering view on emotions and speech: From analysis and pre- dictiv e models to responsible human-centered applications, ” Pr o- ceedings of the IEEE , pp. 1–17, 2023. [3] Y . Li, P . Bell, and C. Lai, “Fusing ASR outputs in joint training for speech emotion recognition, ” in ICASSP 2022-2022 IEEE Inter - national Conference on Acoustics, Speech and Signal Processing (ICASSP) . IEEE, 2022, pp. 7362–7366. [4] Y . Li, Z. Zhao, O. Klejch, P . Bell, and C. Lai, “ASR and emotional speech: A w ord-lev el inv estigation of the mutual impact of speech and emotion recognition, ” in Proc. Interspeech 2023 , 2023, pp. 1449–1453. [5] S. Y oon, S. Byun, and K. Jung, “Multimodal speech emotion recognition using audio and text, ” in 2018 IEEE spoken language technology workshop (SL T) . IEEE, 2018, pp. 112–118. [6] S. Sahu, V . Mitra, N. Seneviratne, and C. Y . Esp y-W ilson, “Multi- modal learning for speech emotion recognition: An analysis and comparison of asr outputs with ground truth transcription. ” in In- terspeech , 2019, pp. 3302–3306. [7] Y . Li, P . Bell, and C. Lai, “Speech Emotion Recognition With ASR Transcripts: a Comprehensive Study on W ord Error Rate and Fusion T echniques, ” in 2024 IEEE Spoken Language T echnology W orkshop (SLT) , 2024, pp. 518–525. [8] X. Cai, J. Y uan, R. Zheng, L. Huang, and K. Church, “Speech Emotion Recognition with Multi-T ask Learning, ” in Interspeech 2021 , 2021, pp. 4508–4512. [9] H.-C. Chou, “A Tiny Whisper-SER: Unifying Automatic Speech Recognition and Multi-label Speech Emotion Recognition T asks, ” in 2024 Asia P acific Signal and Information Processing Associ- ation Annual Summit and Confer ence (APSIP A ASC) , 2024, pp. 1–6. [10] G. Ilharco et al. , “Editing Models with T ask Arithmetic, ” in The Eleventh International Confer ence on Learning Repr esentations , 2023, pp. 1–17. [11] G. Ramesh and K. Audhkhasi, “T ask V ector Algebra for ASR Models, ” in ICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Pr ocessing (ICASSP) . IEEE, 2024, pp. 12 256–12 260. [12] P . Plantinga, J. Y oo, A. Girma, and C. Dhir, “Parameter A veraging Is All Y ou Need T o Prev ent Forgetting, ” in 2024 IEEE Spoken Language T echnology W orkshop (SLT) . IEEE, 2024, pp. 271– 278. [13] T .-Q. Lin, W .-P . Huang, H. T ang, and H.-y . Lee, “Speech-FT : Merging pre-trained and fine-tuned speech representation mod- els for cross-task generalization, ” IEEE T ransactions on Audio, Speech and Languag e Pr ocessing , vol. 34, pp. 70–83, 2025. [14] V . Panayotov , G. Chen, D. Povey , and S. Khudanpur , “Lib- rispeech: An ASR corpus based on public domain audio books, ” in 2015 IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) , 2015, pp. 5206–5210. [15] Y . Li, Y . Gong, C.-H. H. Y ang, P . Bell, and C. Lai, “Revise, Reason, and Recognize: LLM-Based Emotion Recognition via Emotion-Specific Prompts and ASR Error Correction, ” in ICASSP 2025 - 2025 IEEE International Confer ence on Acoustics, Speec h and Signal Pr ocessing (ICASSP) , 2025, pp. 1–5. [16] R. Lotfian and C. Busso, “Building naturalistic emotionally bal- anced speech corpus by retrieving emotional speech from e xisting podcast recordings, ” IEEE T ransactions on Af fective Computing , vol. 10, no. 4, pp. 471–483, 2019. [17] C. Busso, R. Lotfian, K. Sridhar, A. N. Salman, W .-C. Lin, L. Goncalves, S. Parthasarathy , A. R. Naini, S.-G. Leem, L. Martinez-Lucas, H.-C. Chou, and P . Mote, “The MSP-Podcast Corpus, ” 2025. [Online]. A vailable: https: //arxiv .org/abs/2509.09791 [18] E. Y ang, Z. W ang, L. Shen, S. Liu, G. Guo, X. W ang, and D. T ao, “ AdaMerging: Adaptiv e Model Merging for Multi-T ask Learn- ing, ” in The T welve International Confer ence on Learning Repr e- sentations , 2024, pp. 1–21. [19] S. Chen, C. W ang, Z. Chen, Y . W u, S. Liu, Z. Chen, J. Li, N. Kanda, T . Y oshioka, X. Xiao et al. , “W avlm: Large-scale self- supervised pre-training for full stack speech processing, ” IEEE Journal of Selected T opics in Signal Processing , vol. 16, no. 6, pp. 1505–1518, 2022. [20] S. wen Y ang, P .-H. Chi, Y .-S. Chuang, C.-I. J. Lai, K. Lakhotia, Y . Y . Lin, A. T . Liu, J. Shi, X. Chang, G.-T . Lin, T .-H. Huang, W .-C. Tseng, K. tik Lee, D.-R. Liu, Z. Huang, S. Dong, S.-W . Li, S. W atanabe, A. Mohamed, and H. yi Lee, “SUPERB: Speech Processing Univ ersal PERformance Benchmark, ” in Interspeech 2021 , 2021, pp. 1194–1198. [21] H. W u, H.-C. Chou, K.-W . Chang, L. Goncalves, J. Du, J.-S. R. Jang, C.-C. Lee, and H.-Y . Lee, “Open-Emotion: A Reproducible EMO-Superb For Speech Emotion Recognition Systems, ” in 2024 IEEE Spoken Language T echnology W orkshop (SLT) , 2024, pp. 510–517. [22] T . Feng, J. Lee, A. Xu, Y . Lee, T . Lertpetchpun, X. Shi, H. W ang, T . Thebaud, L. Moro-V elazquez, D. Byrd, N. Dehak, and S. Narayanan, “V ox-profile: A speech foundation model benchmark for characterizing div erse speaker and speech traits, ” 2025. [Online]. A vailable: https://arxiv .org/abs/2505.14648 [23] L. Ferrer and P . Riera, “Confidence Intervals for evaluation in machine learning. ” [Online]. A vailable: https://github.com/ luferrer/ConfidenceIntervals [24] I. Loshchilov and F . Hutter , “Decoupled W eight Decay Regu- larization, ” in International Confer ence on Learning Repr esenta- tions , 2019. [25] Y . Cui, M. Jia, T .-Y . Lin, Y . Song, and S. Belongie, “Class- Balanced Loss Based on Ef fecti ve Number of Samples, ” in Pr o- ceedings of the IEEE/CVF Conference on Computer V ision and P attern Recognition (CVPR) , June 2019. [26] H.-C. Chou, L. Goncalves, S.-G. Leem, C.-C. Lee, and C. Busso, “The Importance of Calibration: Rethinking Confidence and Per- formance of Speech Multi-label Emotion Classifiers, ” in Inter- speech 2023 , 2023, pp. 641–645. [27] A. Paszk e et al. , “PyT orch: An Imperative Style, High- Performance Deep Learning Library , ” in Advances in Neural Information Pr ocessing Systems , H. W allach, H. Larochelle, A. Beygelzimer , F . d'Alch ´ e-Buc, E. Fox, and R. Garnett, Eds., vol. 32. Curran Associates, Inc., 2019.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment