Active Calibration of Reachable Sets Using Approximate Pick-to-Learn
Reachability computations that rely on learned or estimated models require calibration in order to uphold confidence about their guarantees. Calibration generally involves sampling scenarios inside the reachable set. However, producing reasonable pro…
Authors: Sampada Deglurkar, Ebonye Smith, Jingqi Li
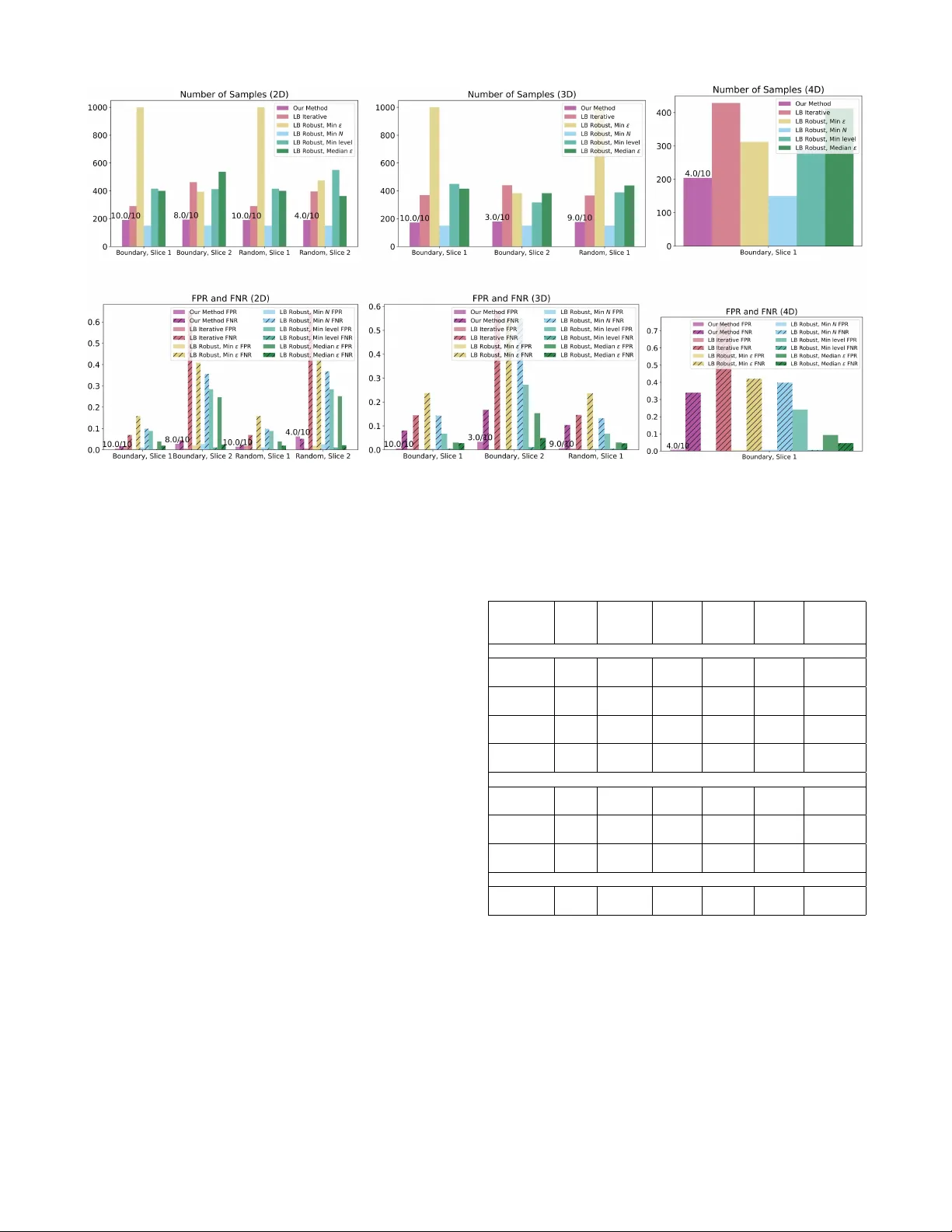
Activ e Calibration of Reachable Sets Using A ppr oximate Pick-to-Lear n* Sampada Deglurkar 1 , Ebonye Smith 1 , Jingqi Li 2 , and Claire J. T omlin 1 Abstract — Reachability computations that rely on lear ned or estimated models r equire calibration in order to uphold confidence about their guarantees. Calibration generally in- volves sampling scenarios inside the reachable set. However , producing reasonable probabilistic guarantees may requir e many samples, which can be costly . T o remedy this, we propose that calibration of reachable sets be perf ormed using active lear ning strategies. In order to pr oduce a probabilistic guarantee on the active learning, we adapt the Pick-to-Learn algorithm, which produces generalization bounds for standard supervised learning, to the active learning setting. Our method, Appr oximate Pick-to-Learn, treats the process of choosing data samples as maximizing an approximate error function. W e can then use conformal prediction to ensure that the approximate error is close to the true model error . W e demonstrate our technique for a simulated drone racing example in which learning is used to provide an initial guess of the reachable tube. Our method requir es fewer samples to calibrate the model and provides more accurate sets than the baselines. W e simultaneously pro vide tight generalization bounds. I . I N T RO D U C T I O N In many safety-critical applications, reachability analysis [1] is a valuable tool for providing safety guarantees for dynamical systems. T raditionally , reachability methods are computationally intensi ve, are performed offline, and re- quire pre-specified models of dynamics, objectiv es, and con- straints. Some of these limitations ha ve been addressed by the use of learning-based algorithms to solve for reachable sets [2], [3], [4]. Howe ver , not only can learning-enabled tech- niques be error-prone, but also system modeling assumptions may not match reality . For example, [5] provides e xamples of how incomplete training can cause a learned reachable set to misclassify unsafe points as safe near its boundary . In the absence of hard safety guarantees, one approach from prior literature is to turn to pr obabilistic guarantees, and to calibrate a reachable set using samples [5], [6]. Howe ver , producing a strong probabilistic guarantee may require taking a large amount of potentially costly samples. Also, as the calibration procedure adapts the reachable set to the en vironment, the set updates in response to each sample that is taken. This iterative learning and sampling breaks *This work was supported by NSF Safe Learning Enabled Systems, the D ARP A Assured Autonomy , ANSR, and TIAMA T programs, and the N ASA ULI on Safe A viation Autonomy . E.S. was supported by NSF GRFP , and J.L. by an Oden Institute Fello wship. 1 Sampada Deglurkar (corresponding author), Ebonye Smith, and Claire J. T omlin are with the Department of Electrical Engineering and Com- puter Sciences, University of California Berkeley , Berkeley , CA 94720, USA, tel:510-643-6610, sampada deglurkar@berkeley.edu, ebonyesmith@berkeley.edu, tomlin@berkeley.edu 2 Jingqi Li is with the Oden Institute of Computational Engineering and Sciences, Univ ersity of T exas at Austin, Austin, TX 78712, USA, tel: 765- 337-0678 jingqi.li@austin.utexas.edu Fig. 1: (a) Our frame work provides a probabilistic generalization bound for the iterative process of learning and activ ely sampling the next data point. The novelty of our method lies in the realization that if we conformally calibrate our activ e sampling strategy so that it approximates maximizing the true model error, we can achieve a desired probabilistic guarantee. (b) W e demonstrate our method on a drone racing example in which the ego drone (green) overtakes another drone (yellow). W e display the reach-av oid set learned by our method, with the lighter colors indicative of the set at previous iterations and the darker colors for later iterations. The orange points are samples taken by our calibrated active learning strategy . assumptions made by many prior works that the samples be exchangeable or IID. Finally , there is the question of how to define calibration in the first place. Understanding how to update a reachable set is a learning problem in itself, which prior w orks often simplify by making the calibrated reachable set a simple function of the original set. W e address these issues by framing calibration as an activ e learning problem, through which we can choose only the necessary samples. At the same time, we pro vide strong guarantees and high-accuracy reachable sets. For this, our key insight lies in lev eraging the Pick-to-Learn algorithm, introduced by Paccagnan et al. [7]. This is a meta-algorithm that turns any supervised learning procedure into a compression scheme, which yields a generalization bound. W e adapt this algorithm for active learning, resulting in our Appr oximate Pick-to-Learn method. W e ov ervie w our method in Figure 1. In summary , our contrib utions are: • W e frame reachable set calibration as an acti ve learning problem and provide a novel method to produce a probabilistic guarantee. • W e introduce an extension to the Pick-to-Learn algo- rithm for active learning in the form of Approximate Pick-to-Learn and theoretically establish its probabilis- tic guarantees. • W e demonstrate our methodology in simulation and show how it balances tradeof fs between sample com- plexity , guarantee strength, and reachable set accuracy better than the baselines. In this paper , we first give an overvie w of related work in Section II. W e then describe the problem setup in Section III, e xplain our method in Section IV, sho w our simulation experiments in Section V, and conclude in Section VI. I I . R E L A T E D W O R K A. Calibrating Learned Reachability Computations The works [5] and [6], which serve as our baselines, study the calibration of learned reachable sets using sampled trajectories. The iterativ e method [5] ev aluates ground-truth reachability values at IID samples and adjusts the level set of the value function to obtain zero safety violations, while the robust method [6] instead counts violations and incorporates them into a relaxed probabilistic guarantee. Both rely on scenario optimization [8], trading off the strength of the guarantee with the sample comple xity . Our work builds on these ideas with a more sample-efficient, activ e learning- based calibration approach. There are also prior works on adapting reachable sets online, such as in response to ne w sensed information [9], with respect to changing dynamics or environmental parameters [10], [11], [12], or in accordance with human feedback about constraints [13], [14]. Ho wev er, these works constrain the amount of adaptation that can happen and do not provide probabilistic guarantees on the final reachable set. B. Guarantees for Active and Online Learning Settings Many works in the multi-armed bandits or Bayesian opti- mization literature make regret-related theoretical statements [15], [16], [17], [18], which describe the optimality of the activ e learning process but not how the final model performs on unseen data. They may otherwise assume that the learned model belongs to a particular hypothesis class [19], [20]. For example, some Bayesian optimization works produce probabilistic statements on the accuracy of level set estimates, but with the assumption that the underlying function is drawn from a Gaussian process (GP) [21], [22]. In contrast, we work with arbitrary and potentially black-box models of the reachability value function. Another line of related work applies conformal prediction [23] to produce probabilistic safety guarantees in dynamic settings. For example, [24], [25] use a form of Adaptiv e Conformal Inference [26], whose guarantee is similar to a regret bound. Our method uses conformal prediction, but to calibrate the estimate of where it is important to sample next rather than to calibrate the reachable set itself. I I I . R E A C H A B I L I T Y L E A R N I N G A N D C A L I B R A T I O N Let x ∈ X denote a state in the bounded state space, and let x t +1 = f ( x t , u t ) describe the system dynamics, where x t ∈ X and u t ∈ U denote the state and control at time step t , respecti vely . W e are giv en a policy ˜ π ( x ) and a value function ˜ V ( x, t ) . For example, if ˜ π and ˜ V are learned using the method in [4], the v alue function induced by ˜ π is V ˜ π ( x, t ) := sup t ′ =0 ,...,t min { γ t ′ r ( ξ ˜ π x ( t ′ )) , min τ =0 ,...,t ′ γ τ c ( ξ ˜ π x ( τ )) } (1) for discount factor γ ∈ (0 , 1) , where ξ ˜ π x : [0 , t ] → X represents the trajectory under ˜ π starting at x . Here, r : X → R and c : X → R are functions such that r ( x ) > 0 indicates that x lies in the target set, and c ( x ) > 0 indicates that x satisfies constraints. The super -zero le vel set of V ˜ π ( x, t ) recov ers the r each-avoid set , which consists of all states from which the policy ˜ π guides the system to the target set within t stages while satisfying the constraints. Since the learned value function may be subject to error , we use it to initialize our active learning calibration process. Let the hypothesis h : X → R , with initial hypothesis h 0 , refer to the v alue function induced by the policy for a particular time horizon. During the acti ve learning procedure, we obtain samples z := ( x, V ˜ π ( x, T )) . Let z x denote the state portion of z . W e also assume access to a learning algorithm L , which maps a list of samples to a hypothesis. When we produce a probabilistic guarantee, we will want to do so with respect to the err or of the hypothesis at z , e h ( z ) . In our setting, this error is binary-valued: e h ( z ) = 1 { h ( x ) × V ˜ π ( x, T ) ≤ 0 ∧ h ( x ) = V ˜ π ( x, T ) } , so it is 0 when h correctly predicts the sign of the value and 1 otherwise. W e iteratively choose x ’ s and observ e V ˜ π ( x, T ) at those locations by rolling out ˜ π for time horizon T and applying Equation (1). W e continue to collect samples until the value function’ s error is lo w e verywhere with high probability . I V . A P P RO X I M A T E P I C K - T O - L E A R N In this section, we describe our adaptation of the Pick-to- Learn algorithm for acti ve learning. Section IV -A pro vides an overvie w of Pick-to-Learn. W e then describe in Section IV -B the key ingredients that should be adapted for our algorithm: Pick-to-Learn’ s dataset and hypothesis-dependent total order . Finally , Section IV -C describes how we use conformal prediction to produce a calibrated appr oximate total order and obtain our final guarantee 1 . A. The Pick-to-Learn Algorithm In the standard supervised learning setting, the Pick-to- Learn algorithm [7] produces a generalization bound by turning an y learning algorithm into a compression scheme . For a dataset D := { z 1 , ..., z n D } with IID z i ’ s in Z , the method aims to iteratively build the compressed set Q ⊆ D . At each iteration, the data point in D \ Q on which the current hypothesis performs the worst is added to Q . This is the point that maximizes a hypothesis-dependent total or der ≤ h defined over Z : z i ≤ h z j ⇐ ⇒ e h ( z i ) ≤ e h ( z j ) , ∀ z i , z j ∈ Z . Then, L is applied to obtain a new h . The algorithm terminates when e h ( z ) ≤ ω ∀ z ∈ D for the threshold ω . B. Adapting Pick-to-Learn for Active Learning As Pick-to-Learn is designed for of fline supervised learn- ing, se veral aspects need to be changed to apply the technique to activ e learning. Firstly , in active learning, a labeled dataset D does not exist. Because of this, we also do not have access 1 Code for this project can be found at h ttps:// github .com/sd e glurkar/bayes_opt_calibration . to e h ( z ) for all z ∈ D , and so secondly , we do not know the hypothesis-dependent total order . Our response to these dilemmas is to redefine D as an unlabeled dataset of n D IID samples of x from a uniform distribution over the state space; D := { x 1 , ...x n D } . Though now D ⊆ X , we will allo w Q to hav e labels: Q ⊆ Z . In this way , we think of D as a representation of the world in which we are performing acti ve learning; we can choose which elements of D we would like to learn on. In the Pick- to-Learn algorithm, this choice is precisely adversarial in that it is the point for which e h ( z ) is maximized. Howe ver , in the absence of knowing e h ( z ) exactly , one can imagine designing an active learning strategy that chooses points that reduce uncertainty , optimize an objecti ve, or follow a heuristic [27]. Generally speaking, an acti ve learning strate gy can be modeled as maximizing some function a h,η ( x ) , where η is an instantiation of any random v ariable. This notation makes e xplicit the fact that the strategy may be stochastic and depend on factors other than h . C. Calibrating the Active Learning Strate gy with Conformal Pr ediction In Pick-to-Learn, the authors produce an upper bound on the risk of the hypothesis, which is defined as P z ( e h ( z ) ≥ ω | D ) . Howe ver , if the termination condition of our algorithm were a h,η ( x ) ≤ ω ∀ x ∈ D , we would only obtain an upper bound on P x ( a h,η ( x ) ≥ ω | D ) . T o address this issue, we lev erage conformal prediction to produce a value ˆ e h,η ( x ) that adjusts a h,η ( x ) so that with high probability , e h ( z ) ≥ ω implies that ˆ e h,η ( z x ) ≥ ω for any z x , h , and η . W e detail our method in Algorithm 1. Follo wing one technique giv en in [23], we construct an interval around a h,η ( x ) . Giv en a heuristic v alue µ h,η ( x ) , conformal predic- tion calculates λ ∈ R so that: P C ( e h ( z ) ∈ [ a h,η ( z x ) − λµ h,η ( z x ) , a h,η ( z x ) + λµ h,η ( z x )]) ≥ 1 − α (2) for calibration set C := { z C 1 , ..., z C n C } containing IID sam- ples separate from D . Specifically , λ is the ⌈ (1 − α )( n C + 1) ⌉ /n C quantile of { s ( z C 1 ) , ..., s ( z C n C ) } for score function s ( z ) := | e h ( z ) − a h,η ( z x ) | /µ h,η ( z x ) (Line 7 in Algorithm 1). Now , we write ˆ e h,η ( x ) := a h,η ( x ) + λµ h,η ( x ) (Line 8). This is essentially a total order 2 ˆ ≤ h,η that appr oximates ≤ h ov er z x : x i ˆ ≤ h,η x j ⇐ ⇒ ˆ e h,η ( x i ) ≤ ˆ e h,η ( x j ) , ∀ x i , x j ∈ X . The Pick-to-Learn algorithm can now be performed as is except by maximizing ˆ e h,η ( x ) at ev ery step (Line 9) and with the termination condition ˆ e h,η ( x ) ≤ ω ∀ x ∈ D (Line 1). W e present our final guarantee with the follo wing theorem: Theorem 1. Let A be Algorithm 1, such that A ( D ) = ( h, Q ) . Then, P C h P D h P z ( e h ( z ) ≥ ω | D ) ≤ ¯ ϵ ( | Q | , δ ) i ≥ 1 − δ i ≥ 1 − α 2 If there are ties, where ˆ e h,η ( x i ) = ˆ e h,η ( x j ) for x i = x j , we create a tie-breaking criterion using a small amount of random noise: ˆ e h,η ( x ) := a h,η ( x ) + λµ h,η ( x ) + σ ( x ) for positive-v alued σ ( x ) such that ˆ e h,η ( x ) ≥ a h,η ( x ) + λµ h,η ( x ) ∀ x ∈ X still holds. Algorithm 1: A ( D ) - Approximate Pick-to-Learn for Calibrating Reachable Sets Initialize: Q = ∅ , h = h 0 , η = η 0 , ¯ x = arg max x ∈ D ˆ e h 0 ,η 0 ( x ) , C = { z C 1 , ..., z C n C } , i = 0 1: while ˆ e h,η ( ¯ x ) ≥ ω do 2: i ← i + 1 3: Obtain V ˜ π ( ¯ x, T ) and define ¯ z := ( ¯ x, V ˜ π ( ¯ x, T )) 4: Q ← Q ∪ { ¯ z } 5: h ← L ( Q ) 6: η ← η i 7: λ ← Quantil e ⌈ (1 − α )( n +1) ⌉ /n n | e h ( z C 1 ) − a h,η ( z C 1 ,x ) | µ h,η ( z C 1 ,x ) , ..., | e h ( z C n C ) − a h,η ( z C n C ,x ) | µ h,η ( z C n C ,x ) o 8: ˆ e h,η ← a h,η + λµ h,η 9: ¯ x ← arg max x ∈ D \ Q ˆ e h,η ( x ) 10: end while 11: retur n h, Q for any δ ∈ (0 , 1) and α ∈ (0 , 1) . ¯ ϵ ( | Q | , δ ) is calculated as in Pick-to-Learn. Pr oof. The first component of our proof is to show that our algorithm serves as a preferent compression scheme. Since ˆ e h,η characterizes a total order over X , our proof of this fact is the same as that of Lemma A.6 in [7]. Now , let us define κ as our compression function, so that κ ( D ) := Q . W e also define ϕ as the pr obability of c hange of compr ession ; ϕ κ ( D ) := P z ( κ ( κ ( D ) ∪ { z } ) = κ ( D ) | D ) . By Lemma 1 (see Appendix), with probability at least 1 − α over C , if e h ( z ) ≥ ω then κ ( κ ( D ) ∪ { z } ) = κ ( D ) . It now remains to state that with probability at least 1 − α ov er C , e h ( z ) ≥ ω is a sub-event of κ ( κ ( D ) ∪ { z } ) = κ ( D ) giv en D . Thus, P C h P z ( e h ( z ) ≥ ω | D ) ≤ P z ( κ ( κ ( D ) ∪ { z } ) = κ ( D )) i ≥ 1 − α , which means P C h P z ( e h ( z ) ≥ ω | D ) ≤ ϕ κ ( D ) i ≥ 1 − α . Using Lemma 1 and Theorem 7 in Campi and Garatti 2023 [28], P D h ϕ κ ( D ) ≤ ¯ ϵ ( | κ ( D ) | , δ ) i ≥ 1 − δ . P C h P D h P z ( e h ( z ) ≥ ω | D ) ≤ ¯ ϵ ( | κ ( D ) | , δ ) i ≥ 1 − δ i ≥ 1 − α . Theorem 1 suggests that, with high probability , the learned value function achiev es low error on unseen states ev en though the samples used for verification came from an adaptiv e process. The size of C is dictated by how closely we would like the empirical guarantee for the outer probability in Theorem 1 to match the theoretical guarantee of 1 − α . From [23], this empirical guarantee follows a Beta distribution. For some constant β , the size of C is calculated such that 1 − β probability mass of the distribution remains within 1 − α − ϵ α and 1 − α + ϵ α for some tolerance ϵ α . V . S I M U L A T I O N E X P E R I M E N T S A. Experimental Setup In our simulation experiments, we consider the example in [4] of an ego drone competing with another drone to reach a gate. For this reachability problem, the state is 12 - dimensional, consisting of the two agents’ 6 -dimensional dynamics that are described by double integrators in the three spatial dimensions. The rew ard function r ( x ) incentivizes the ego drone to remain ahead of the other drone, move faster than the other drone, and approach the gate within a corridor . The constraint function c ( x ) imposes that the ego drone approach the gate within a certain angle, maintain an altitude limit, and stay away from the other agent and its approximate region of downw ash. W e produce V ˜ π ( x, T ) values by applying ˜ π for the e go drone and applying a PID controller for the other drone for T = 30 steps. In order to av oid retraining a neural network at ev ery iteration, we model h 0 ( x ) as a GP that uses ˜ V ( x, t ) as part of its prior . Thus, the total sample complexity of our method for these experiments is | Q | + | C | plus 40 initial samples for fitting h 0 ( x ) . W e opt for a heuristic acti ve learning strate gy in which we prioritize points near the boundary of the reachable set, where it is most likely that the model is incorrect. Since the zero-lev el set of the value function defines the boundary , a h,η ( x ) simply uses the absolute v alue of the value function and is normalized so that a h,η ( x ) ∈ [0 , 1] ∀ x ∈ D . Note that our algorithm terminates when ˆ e h,η ≤ ω ∀ x ∈ D , and since ˆ e h,η ( x ) ≥ a h,η ( x ) , if a h,η ( x ) is never belo w ω ∀ x ∈ D during the course of the algorithm then neither is ˆ e h,η ( x ) . T o remedy this, a h,η ( x ) is decayed at ev ery iteration of the while loop in Algorithm 1 using a multiplicative exponential factor ζ ∈ [0 , 1] . Also, we heuristically define µ h,η ( x ) as 0 . 1 × a h,η ( x ) . The value of ˆ e h,η ( x ) at every iteration depends on the values of the score functions in the calibration dataset. If for some z C i ∈ C a h,η ( z C i,x ) is small but e h ( z C i ) = 1 , ˆ e h,η ( x ) may remain above ω for some x ∈ D . It is only when discrepancies between a h,η and e h lessen, usually by v alues of e h in C going to zero, that the algorithm is allo wed to terminate. In these experiments, ω = 0 . 3 , ζ = 0 . 95 , and δ = 1 e − 4 . B. Baselines and Metrics W e compare our method with the two baselines described in Section II-A: [5], which we call LB Iterative after the names of the authors, and [6], which we denote as LB Robust. Both provide the guarantee P x ∈ ˆ S ( V ( x, T ) ≤ 0) ≤ ϵ LB with probability at least 1 − β over sampled data, where ˆ S is the calibrated set. W e set β = 0 . 1 for all methods. Notably , our probabilistic guarantee is with respect to a general notion of error , whereas the baselines’ guarantee only constrains the false inclusion of unsafe states. W e implement the LB Robust method to highlight the trade-offs inv olved in calibration. W e vary the number of samples over ( [50 , 200 , 250 , 300 , 350 , 500 , 750 , 1000] ) and the levels of the learned value function ( [0 . 0 , 0 . 05 , 0 . 1 , 0 . 15 , 0 . 2 , 0 . 3 , 0 . 5 , 0 . 75 , 0 . 9 , 1 . 0] ). For each combination of these, we implement the method to obtain the ϵ LB value. Then, ov er all combinations we take the one with the minimal ϵ LB (“LB Robust, Minimal ϵ ”), the minimal ϵ LB for the smallest number of samples (“LB Robust, Minimal N ”), the minimal Fig. 2: (a) In this 2-dimensional “Slice 1”, the ego drone’ s 3D velocity is set to [0 . 0 , 0 . 7 , 0 . 0] and its altitude is 0 . 0 . The other drone’s 3D spatial coordinates are [0 . 4 , − 2 . 2 , 0 . 0] and its 3D velocity is [0 . 0 , 0 . 3 , 0 . 0] . (b) In this 2-dimensional “Slice 2”, the other drone’ s state is the same, but the ego drone’ s velocity is [0 . 0 , 0 . 0 , − 0 . 5] and its altitude is 0 . 05 . The baselines’ calibration technique is to simply choose an appropriate lev el of the learned value function. For the more commonly seen scenario (a), the level sets hav e more regular shapes, better justifying this calibration technique. Howe ver , for the less commonly seen scenario (b), this is not the case, and it is more reasonable to be unconstrained by learned set geometries, as in our method. In both figures, orange points are the samples that our method took. ϵ LB for the smallest level (“LB Robust, Minimal level”), and finally the median ϵ LB (“LB Robust, Median ϵ ”). For all methods, we compare the total number of samples required, ϵ LB and ¯ ϵ ( | Q | , δ ) , and the f alse positiv e rate and false ne gati ve rate (FPR and FNR) of the final sets. Here, FPR and FNR are calculated by gridding the state space, computing the ground truth values at the grid points, and checking whether the calibrated set includes (a “positiv e”) and excludes (a “negati ve”) the correct points. C. Results and Discussion W e vary the type of active learning technique we use, the dimension and slice of the state space that we operate in, and the values of α and ϵ α . Figure 2 visualizes the impact of some of these v ariations in 2-dimensional slices of the 12-dimensional system. Compared to Figure 2(a), the states in the slice in Figure 2(b) are less likely to hav e been seen during the learning of ˜ V ( x, t ) . Since the baseline methods can only choose among the levels of the learned value function, they struggle more when the learned function is less accurate. Our method, meanwhile, is not constrained by the geometries of the learned le vel sets. Fig. 3: Plots comparing the number of samples and FPR/FNR across methods. “Boundary” denotes our boundary sampling activ e learning technique, while “Random” refers to setting a h,η ( x ) to random values. In 3D experiments, the slice of the dynamics is the same as that for the 2D Slice 1 except the ego drone’ s altitude is also allowed to vary . In 4D experiments, we additionally allow the ego agent’ s velocity in the x-direction to vary . The numbers above the bars indicate how many seeds out of 10 were successful for our method. Here, failure is defined as more than 70 iterations of our algorithm, since the method is then no longer adaptiv e with minimal samples. Comparisons are only made for successful seeds. Our method balances the competing objectives of minimizing the number of samples and FPR and FNR well compared with the baselines. As we expect, performance for all methods is worse for Slice 2 compared with Slice 1. Figure 3 pro vides comparisons of the methods for different variable combinations. Our method uses the least number of samples except for the “LB Robust, Minimal N ” method, which has a worse FNR. As seen in T able I, the smallest ϵ is achiev ed by the “LB Robust, Minimal ϵ ” method, but it also uses the most samples. Our method also effecti vely trades off between FNR and FPR compared with the baselines, which may minimize one at the e xpense of the other . Across our method variants, boundary and random ac- tiv e learning require a similar number of samples. Though seemingly counterintuitiv e, this reflects a ke y property of probabilistic guarantees. The required number of iterations depends on the particular calibration set C and how well the model learns per sample. Especially if α and ϵ α are larger values, the ˆ e h,η ( x ) ≤ ω condition may not be as dif ficult to satisfy within a set number of iterations. Ho wever , e ven if the Boundary and Random experiments yield a similar probabilistic guarantee due to using a similar number of samples, the final reachable set learned via the boundary sampling strategy tends to hav e a better FPR and FNR. Finally , we study how our method’ s performance scales with increasing state dimension, where model learning be- comes more difficult and reducing errors in C becomes harder . In these cases, relaxing α and ϵ α reduces the required number of samples, at the cost of higher FPR and FNR. W e use ( α, ϵ α ) = (0 . 05 , 0 . 03) for the 2D experiments, (0 . 1 , 0 . 05) for the 3D experiments, and (0 . 15 , 0 . 05) for the 4D experiments. In this way , by uniting the processes of learning and probabilistic assurance, our framework allo ws Setting Ours LB LB LB LB LB Iterativ e Robust Robust Rob ust Robust Min ϵ Min N Min α Median ϵ 2D Boundary , 0.019 0.05 0.003 0.016 0.035 0.024 Slice 1 Boundary , 0.02 0.05 0.01 0.021 0.093 0.094 Slice 2 Random, 0.019 0.05 0.003 0.016 0.035 0.024 Slice 1 Random, 0.019 0.05 0.009 0.019 0.096 0.095 Slice 2 3D Boundary , 0.019 0.05 0.003 0.016 0.040 0.028 Slice 1 Boundary , 0.022 0.05 0.007 0.016 0.160 0.118 Slice 2 Random, 0.021 0.05 0.003 0.016 0.039 0.028 Slice 1 4D Boundary , 0.012 0.05 0.015 0.026 0.203 0.111 Slice 1 T ABLE I: Comparing ¯ ϵ ( | Q | , δ ) and ϵ LB values to understand the tightness of the probabilistic bounds - lower values generate stronger statements. “LB Robust, Min ϵ ” always has the lowest ϵ , but it falls short in other metrics. Again, these values are averaged over successful seeds. for a formal examination of how they interact and trade off. V I . C O N C L U S I O N S In this work, we (1) introduce a method to use activ e learning to both use fe wer samples and gain more accuracy when calibrating reachable sets and (2) produce an extension to the Pick-to-Learn algorithm that allo ws us to pro vide a probabilistic guarantee for acti ve learning. In this way , our work allows for an adaptiv e notion of safety . W e believe that our method can be used not only for calibration but also for reachable set synthesis more generally . In our next steps, we would like to apply these principles in hardware experiments. From our analyses, we additionally see that our intuitiv e understanding of risk in dynamical systems does not always align with the probabilistic statements made by statistical techniques. For example, the probabilistic guar- antee may not necessarily weaken as the dimension of the state space increases. Also, the relationships between the probabilistic guarantees and how conservati ve the sets are or ho w difficult they were to learn can be further explored. These are interesting points for future work. A P P E N D I X Lemma 1. W ith probability at least 1 − α over C , if e h ( z ) ≥ ω , then κ ( κ ( D ) ∪ { z } ) = κ ( D ) . Pr oof. For all h, η present during the e xecution of A , our methodology guarantees that the inequality in (2) holds via conformal prediction (Lemma 1 in [29]). Gi ven D and η , we hav e P C ( a h,η ( z x ) − λµ h,η ( z x ) ≤ e h ( z ) ≤ a h,η ( z x ) + λµ h,η ( z x )) ≥ 1 − α = ⇒ P C ( a h,η ( z x ) − λµ h,η ( z x ) ≤ e h ( z ) ≤ ˆ e h,η ( z x )) ≥ 1 − α . Since a h,η ( z x ) − λµ h,η ( z x ) ≤ e h ( z ) ≤ ˆ e h,η ( z x ) = ⇒ e h ( z ) ≤ ˆ e h,η ( z x ) , P C ( e h ( z ) ≤ ˆ e h,η ( z x )) ≥ P C ( a h,η ( z x ) − λµ h,η ( z x ) ≤ e h ( z ) ≤ ˆ e h,η ( z x )) ≥ 1 − α . So, P C ( e h ( z ) ≤ ˆ e h,η ( z x )) ≥ 1 − α . Since e h ( z ) ≥ ω and e h ( z ) ≤ ˆ e h,η ( z x ) imply ˆ e h,η ( z x ) ≥ ω , P C ( ˆ e h,η ( z x ) ≥ ω ) ≥ P C ( e h ( z ) ≤ ˆ e h,η ( z x )) ≥ 1 − α and so P C ( ˆ e h,η ( z x ) ≥ ω ) ≥ 1 − α . Now we show that if ˆ e h,η ( z x ) ≥ ω , the compression changes. W e sho w the contrapositiv e, similar to the proof of Lemma A.8 in Pick-to-Learn. If z is such that κ ( κ ( D ) ∪ { z } ) = κ ( D ) , or κ ( Q ∪ { z } ) = Q , then A ( Q ∪ { z } ) must select all of the same points as A ( D ) , choosing the same points at every iteration. It must terminate having produced Q and h . This must mean that in its last itera- tion, arg max ˜ z ∈ Q ∪{ z }\ Q ˆ e h,η ( ˜ z x ) ≤ ω , which implies that arg max ˜ z ∈{ z } ˆ e h,η ( ˜ z x ) ≤ ω . Then, ˆ e h,η ( z x ) ≤ ω . R E F E R E N C E S [1] S. Bansal, M. Chen, S. L. Herbert, and C. J. T omlin, “Hamilton–jacobi reachability: A brief overvie w and recent advances, ” in 2017 IEEE 56th Annual Conference on Decision and Control (CDC) , pp. 2242– 2253, IEEE, 2017. [2] S. Bansal and C. J. T omlin, “Deepreach: A deep learning approach to high-dimensional reachability , ” in IEEE International Conference on Robotics and Automation (ICRA) , pp. 1817–1824, IEEE, 2021. [3] K.-C. Hsu, V . Rubies-Royo, C. J. T omlin, and J. F . Fisac, “Safety and liv eness guarantees through reach-avoid reinforcement learning, ” arXiv preprint arXiv:2112.12288 , 2021. [4] J. Li, D. Lee, J. Lee, K. S. Dong, S. Sojoudi, and C. T omlin, “Certifiable reachability learning using a new lipschitz continuous value function, ” IEEE Robotics and Automation Letters , vol. 10, no. 4, pp. 3582–3589, 2025. [5] A. Lin and S. Bansal, “Generating formal safety assurances for high-dimensional reachability , ” in IEEE International Conference on Robotics and Automation (ICRA) , pp. 10525–10531, IEEE, 2023. [6] A. Lin and S. Bansal, “V erification of neural reachable tubes via sce- nario optimization and conformal prediction, ” in 6th Annual Learning for Dynamics & Contr ol Conference , pp. 719–731, PMLR, 2024. [7] D. Paccagnan, M. C. Campi, and S. Garatti, “The pick-to-learn algorithm: Empo wering compression for tight generalization bounds and improved post-training performance, ” in Advances in Neural Information Processing Systems (NeurIPS) , 2023. [8] M. C. Campi and S. Garatti, Intr oduction to the scenario appr oach . SIAM, 2018. [9] A. Bajcsy , S. Bansal, E. Bronstein, V . T olani, and C. J. T omlin, “ An efficient reachability-based frame work for prov ably safe autonomous navigation in unknown en vironments, ” in Pr oceedings of the IEEE Confer ence on Decision and Contr ol (CDC) , pp. 1758–1765, IEEE, 2019. [10] K. Nakamura and S. Bansal, “Online update of safety assurances using confidence-based predictions, ” CoRR , vol. abs/2210.01199, 2022. [11] J. Borquez, K. Nakamura, and S. Bansal, “Parameter-conditioned reachable sets for updating safety assurances online, ” in Proceedings of the IEEE International Conference on Robotics and Automation (ICRA) , 2023. [12] H. J. Jeong, Z. Gong, S. Bansal, and S. L. Herbert, “Parameterized fast and safe tracking (fastrack) using deepreach, ” in Proceedings of the 6th Annual Learning for Dynamics and Control Confer ence (L4DC) , vol. 242 of Pr oceedings of Machine Learning Research , pp. 1006– 1017, PMLR, 2024. [13] L. Santos, Z. Li, L. Peters, S. Bansal, and A. Bajcsy , “Updating robot safety representations online from natural language feedback, ” in Proceedings of the IEEE International Conference on Robotics and Automation (ICRA) , pp. 7778–7785, IEEE, 2025. [14] S. Agrawal, J. Seo, K. Nakamura, R. Tian, and A. Bajcsy , “ Anysafe: Adapting latent safety filters at runtime via safety constraint parame- terization in the latent space, ” CoRR , vol. abs/2509.19555, 2025. [15] S. T akeno, Y . Inatsu, M. Karasuyama, and I. T akeuchi, “Regret anal- ysis of posterior sampling-based e xpected improvement for bayesian optimization, ” T ransactions on Machine Learning Resear ch , 2025. [16] C. X. Cheng, R. Astudillo, T . Desautels, and Y . Y ue, “Practical bayesian algorithm execution via posterior sampling, ” in Pr oceedings of the Thirty-Seventh Confer ence on Neural Information Pr ocessing Systems (NeurIPS 2024) , Neural Information Processing Systems Foundation, Inc., 2024. [17] F . Zhang and Y . Chen, “Direct re gret optimization in bayesian opti- mization, ” CoRR , vol. abs/2507.06529, 2025. [18] S. Bubeck and N. Cesa-Bianchi, Re gret Analysis of Stochastic and Nonstochastic Multi-armed Bandit Problems , vol. 5. Foundations and T rends in Machine Learning, 2012. [19] B. Mason, R. Camilleri, S. Mukherjee, K. Jamieson, R. Nowak, and L. Jain, “Nearly optimal algorithms for le vel set estimation, ” in Proceedings of the 40th International Confer ence on Machine Learning (ICML) , v ol. 2023 of Pr oceedings of Machine Learning Resear ch , pp. 12345–12356, PMLR, 2023. [20] H. Flynn, D. Reeb, M. Kandemir , and J. Peters, “P ac-bayes bounds for bandit problems: A surv ey and experimental comparison, ” IEEE T ransactions on P attern Analysis and Machine Intelligence , v ol. 45, no. 12, pp. 15308–15327, 2023. [21] H. Ishibashi, K. Matsui, K. Kutsukak e, and H. Hino, “ An ( ϵ , δ )- accurate level set estimation with a stopping criterion, ” in Pr oceedings of the 41st International Conference on Machine Learning (ICML) , Proceedings of Machine Learning Research, PMLR, 2024. [22] Y . Inatsu, S. Iwazaki, and I. T akeuchi, “ Active learning for distri- butionally rob ust level-set estimation, ” CoRR , v ol. abs/2402.XXXX, 2024. [23] A. N. Angelopoulos and S. Bates, “Conformal prediction: A gentle introduction, ” F oundations and T rends in Machine Learning , vol. 16, no. 4, pp. 494–591, 2023. [24] A. Muthali, H. Shen, S. Deglurkar , M. H. Lim, R. Roelofs, A. Faust, and C. J. T omlin, “Multi-agent reachability calibration with conformal prediction, ” in 2023 IEEE 62nd Conference on Decision and Control (CDC) , pp. 6596–6603, IEEE, 2023. [25] A. Dixit, L. Lindemann, S. X. W ei, M. Cleaveland, G. J. Pappas, and J. W . Burdick, “ Adaptive conformal prediction for motion planning among dynamic agents, ” in Pr oceedings of the Learning for Dynamics and Control Conference (L4DC) , vol. 211 of Proceedings of Machine Learning Researc h , pp. 300–314, PMLR, 2023. [26] I. Gibbs and E. J. Cand ` es, “Conformal inference for online prediction with arbitrary distribution shifts, ” 2022. [27] R. Garnett, Bayesian Optimization . Cambridge University Press, 2023. [28] M. C. Campi and S. Garatti, “Compression, generalization and learn- ing, ” Journal of Machine Learning Research , vol. 24, no. 339, pp. 1– 74, 2023. [29] L. Lindemann, Y . Zhao, X. Y u, G. J. Pappas, and J. V . Deshmukh, F ormal V erification and Control with Conformal Prediction: Practical Safety Guarantees for Autonomous Systems . F oundations and Trends in Systems and Control, Now Publishers, 2023.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment