Amortized Inference for Correlated Discrete Choice Models via Equivariant Neural Networks
Discrete choice models are fundamental tools in management science, economics, and marketing for understanding and predicting decision-making. Logit-based models are dominant in applied work, largely due to their convenient closed-form expressions fo…
Authors: Easton Huch, Michael Keane
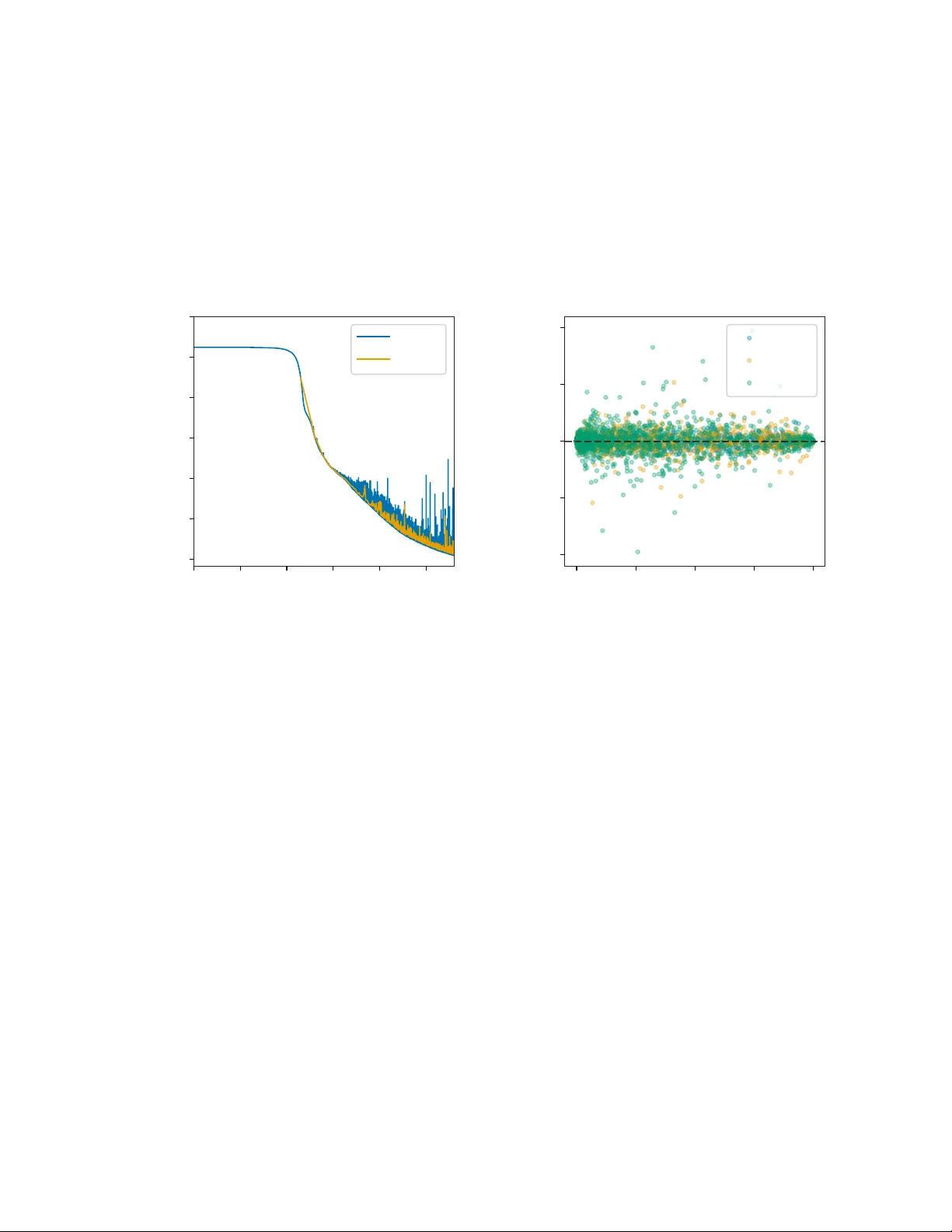
Amortized Inference for Correlated Discrete Choice Mo dels via Equiv arian t Neural Net w orks Easton Huc h ∗ Mic hael Keane † Marc h 2026 Abstract Discrete c hoice mo dels are fundamen tal to ols in managemen t science, economics, and mark eting for understanding and predicting decision-making. Logit-based mo dels are dominant in applied w ork, largely due to their conv enien t closed-form expressions for c hoice probabilities. Ho wev er, these mo dels en tail restrictive assumptions on the sto c hastic utilit y comp onen t, constraining our abilit y to capture realistic and theoreti- cally grounded choice b ehavior—most notably , substitution patterns. In this work, we prop ose an am ortized inference approach using a neural net w ork emulator to approxi- mate c hoice probabilities for general error distributions, including those with correlated errors. Our proposal includes a sp ecialized neural net work arc hitecture and accompany- ing training pro cedures designed to resp ect the inv ariance prop erties of discrete choice mo dels. W e pro vide group-theoretic foundations for the arc hitecture, including a pro of of universal approximation given a minimal set of inv arian t features. Once trained, the emulator enables rapid likelihoo d ev aluation and gradient computation. W e use Sob olev training, augmenting the lik eliho o d loss with a gradient-matc hing p enalty so that the emulator learns b oth choice probabilities and their deriv atives. W e show that em ulator-based maximum likelihoo d estimators are consistent and asymptotically nor- mal under mild approximation conditions, and we pro vide sandwich standard errors that remain v alid ev en with imp erfect lik e liho o d approximation. Sim ulations sho w significan t gains o ver the GHK simulator in accuracy and sp eed. Keyw ords: amortized inference; DeepSet; discrete choice; inv arian t theory; m ultino- mial probit; neural netw ork emulator; p ermutation equiv ariance; Sob olev training ∗ P ostdo ctoral F ellow, Johns Hopkins Carey Business Sc ho ol, ehuc h@jhu.edu. † Carey Distinguished Professor, Johns Hopkins Carey Business Sc ho ol, mkeane14@jh u.edu. 1 1 In tro duction Discrete choice mo dels are a widely used to ol in management science, economics, marketing, and other fields for understanding how individuals and organizations make decisions among finite sets of alternatives ( McF adden , 1974 ). These models provide a structural framew ork that deliv ers in terpretable parameters—suc h as willingness-to-pay and demand elasticities— and that also enables predictions ab out the effects of hypothetical in terven tions, including pricing c hanges, pro duct introductions, and p olicy mo difications. The dominan t discrete c hoice mo del in applied w ork is the multinomial logit (MNL), whic h assumes that the utility consumer i obtains from alternativ e j takes the form U j = v j + ϵ j where v j is the deterministic comp onen t of utilit y , t ypically written as a linear function x ⊤ j β of alternative j ’s attributes x j , and ϵ j is a Type I extreme v alue (Gumbel) error that is independent and identically distributed (iid) across alternativ es j = 1 , . . . , K . This setup yields simple closed-form choice probabilities: the probabilit y of choosing alternativ e j is giv en by the “softmax” function exp( v j ) / P K k =1 exp( v k ). The resulting computational con venience has made MNL the default choice in countless applications. Ho wev er, this conv enience comes at a w ell-known cost. The iid Gum b el error assumption implies the restrictive indep endence of irrelev an t alternativ es (I IA) property: the o dds ratio b et w een an y tw o alternativ es is unaffected b y the presence or attributes of other alternativ es, whic h can lead to unrealistic substitution patterns. A p opular generalization of MNL is the mixed logit mo del (mixed-MNL), in which the utility weigh t β is allo wed to be heterogeneous across consumers. Estimation is straigh tforw ard via simulation metho ds ( T rain , 2009 ). The mixed-MNL relaxes IIA at the aggregate lev el, but I IA still holds at the lev el of consumer i ’s individual c hoices given the corresp onding random utility weigh t, β i . The multinomial probit (MNP) is a well-kno wn alternative to MNL that relaxes I IA and allo ws for flexible substitution patterns b y assuming ϵ 1 , . . . , ϵ K come from a m ultiv ariate nor- mal distribution with cross-alternative correlations. Despite this adv an tage, MNP has seen relativ ely limited adoption, largely due to its computational demands. MNP c hoice probabil- ities hav e no closed form and require ev aluating multiv ariate normal rectangle probabilities. Estimation relies on more sophisticated simulation metho ds than needed for mixed-MNL: the GHK simulator in a classical setting ( Gewek e , 1989 ; Ha jiv assiliou and McF adden , 1998 ; Keane , 1994 ) or MCMC in a Bay esian setting ( McCullo ch and Rossi , 1994 ). W e prop ose a fundamentally differen t approach: Rather than sim ulating c hoice probabilities anew for eac h likelihoo d ev aluation, we train a neural netw ork emulator to directly approx- 2 imate the c hoice probabilit y function. This strategy—known as amortized inference—shifts the computational burden from inference time to a one-time training phase. Once trained, the emulator provides rapid deterministic approximations to c hoice probabilities via simple function calls. The amortized inference framew ork has prov en highly successful in multiple scien tific domains for appro ximating computationally in tensive sim ulation mo dels ( Lueck- mann et al. , 2019 ; Cranmer et al. , 2020 ). Here, we adapt it to discrete c hoice mo dels, extending b ey ond MNL and MNP to general correlated error distributions. In the econometrics literature, Norets ( 2012 ) emplo ys a related strategy , appro ximating the exp ected v alue function in dynamic discrete c hoice mo dels via a neural netw ork. He applies this strategy in the context of a sp ecific parametric mo del, so changes in the dynamic mo del require mo difying and retraining the neural net work. In con trast, our emulator op erates on the generic c hoice problem given only the deterministic utilities and the parameters of the error distribution, enabling mo difications to the parametric mo del (e.g., the functional form of the deterministic utilities) without altering or retraining the emulator. Our metho dology relies on sev eral new contributions. First, w e dev elop a neural net work arc hitecture sp ecifically designed for choice mo dels. It resp ects their fundamen tal inv ariance prop erties, which w e formalize as symmetries (group actions) of the c hoice-probabilit y map. 1 Choice probabilities are inv ariant to lo cation shifts (adding a constant to all utilities) and scale transformations (m ultiplying utilities b y a p ositive constant), and equiv ariant with resp ect to p ermutations of c hoice alternativ es. Our architecture incorp orates a preprocessing transformation that reduces the size of the feature space b y enforcing lo cation and scale in v ariance. The pro cessed features are then passed to a per-alternative enco der mo dule based on the DeepSet architecture ( Zaheer et al. , 2017 ). The output is then concatenated across alternativ es and pro cessed through equiv ariant la y ers that imp ose a sum-to-one constraint on the output probabilities while resp ecting the p erm utation equiv ariance prop erty . Second, we establish the theoretical foundations of our architecture. W e prov e that it can univ ersally appro ximate choice probabilities on compact subsets of the parameter space, outside a measure-zero exceptional set. This result connects our architecture to the theory of orbit separation under group actions, extending the universal appro ximation results of Blum- Smith et al. ( 2025 ) on symmetric matrices to the joint space of utility vectors and cen tered co v ariance matrices. Blum-Smith et al. ( 2025 ) emplo y Galois theory to pro ve generic orbit separation, while w e provide a direct pro of based on an inv ariant reconstruction argument. 1 If these prop erties are not embedded in the architecture, the NN must learn them during training. As a con tin uum of mo dels generate equiv alent c hoice probabilities, this would slo w learning considerably . 3 Third, w e establish the statistical prop erties of maximum lik eliho o d estimators (MLEs) formed using an em ulator approximation of the true discrete c hoice probabilities. W e sho w that if the em ulator approximates the true log lik eliho o d sufficien tly well—specifically , if the av erage appro ximation error is o p ( n − 1 )—then the em ulator-based estimator inherits the consistency and asymptotic normalit y of the exact MLE. When this condition is not met, w e show that v alid inference can still b e obtained via sandwich standard errors, treating the em ulator as a working mo del in the quasi-maximum likelihoo d framework. By careful design, our prepro cessing transformations and architecture enforce smo othness of c hoice probabilities with resp ect to the inputs: the deterministic utilities and corresp onding scale (co v ariance) matrix. W e use Sob olev training ( Czarnec ki et al. , 2017 ) to match em ulator gradien ts to those of the log c hoice probabilities. T ogether, these design c hoices enable reliable use of automatic differen tiation for downstream mo del-fitting and inference tasks. With a pretrained emulator, generalizing from logit to probit (or an y other error distribution) requires only the replacemen t of closed-form softmax probabilities with em ulator ev aluations of c hoice probabilities when forming the lik eliho o d. In the probit case, given a fixed compu- tational budget, we sho w via simulations that an ML estimator using our amortized inference pro cedure matc hes or exceeds the p erformance of one using the GHK algorithm in terms of estimation error and cov erage rates. F urthermore, our approac h can easily handle mo dels other than MNP where an efficien t simulation algorithm like GHK is una v ailable. F or concreteness, muc h of our exp osition fo cuses on MNP mo dels. Ho wev er, the emulator approac h and supp orting theory are largely agnostic to the assumed parametric form of the errors. Generalizing to other error distributions (e.g., correlated Gumbel) is straightforw ard, requiring only mo dest c hanges to the training data generation and emulator inputs. The remainder of this pap er is organized as follo ws. Section 2 summarizes related literature on choice modeling. Section 3 describ es the MNP mo del and our inferential goals. Sec- tion 4 presents the em ulator arc hitecture and training pro cedure. Section 5 establishes the theoretical prop erties of the arc hitecture and em ulator-based estimators. Section 6 presen ts sim ulation results, and Section 7 concludes. 2 Related Literature The literature on applying mac hine learning metho ds to discrete choice can b e divided into t wo broad streams. The first stream maintains the classic random utilit y mo del (RUM) of c hoice, in whic h choice probabilities are generated by a p opulation of rational consumer 4 t yp es with different (but stable) preference orderings ov er the univ erse of choice ob jects, as explained by Blo ch and Marschak ( 1960 ) and McF adden and Rich ter ( 1990 ). 2 MNL, MNP , and mixed-MNL are all mem b ers of the RUM class pro vided one main tains the RUM assumption that the utility of an option dep ends only on its own c haracteristics. Key pap ers in this strand start from this basic MNL structure and use neural net w orks to generalize the functional form of utilit y: Ben tz and Merunk a ( 2000 ), Sifringer et al. ( 2020 ), W ang et al. ( 2020 ), Han et al. ( 2022 ), and Singh et al. ( 2023 ). Tw o imp ortan t recen t pap ers extend this w ork: Aouad and Desir ( 2025 ) develop an architecture that implements the mixed logit mo del with a flexible distribution of taste heterogeneit y (R UMnet), and Bagheri et al. ( 2025 ) dev elop another architecture that generalizes the Gumbel error assumption (RUM-NN). Both pap ers use softmax-smo othed sample a v erages to approximate c hoice probabilities within the loss function, resulting in increased computation time relative to pure logit-based mo dels. Aouad and Desir ( 2025 ) build on the generic appro ximation prop erty of mixed-MNL mo dels sho wn in McF adden and T rain ( 2000 ). This result relies on a flexible basis expansion of the utility function and a p oten tially nonparametric mixing distribution. In practice, these mo del attributes are unkno wn to analysts. As emphasized in b oth Aouad and Desir ( 2025 ) and McF adden and T rain ( 2000 ), this appro ximation prop ert y is not unique to Gum b el errors. Rather, it holds more generally for a larger class of hierarchical discrete choice mo dels, including mixed-MNP mo dels. McF adden and T rain ( 2000 ) use this appro ximation prop ert y to justify adoption of mixed-MNL as a computationally conv enient alternative to other mo dels lacking closed-form c hoice probabilities, suc h as MNP . But this justification of mixed-MNL becomes less compelling giv en a practical, general-purpose alternativ e lik e the em ulators we prop ose here. The second stream dispenses with the R UM structure, often motiv ated by a desire to relax restrictiv e MNL assumptions like I IA and to allow more flexible substitution patterns. Some pap ers in this stream view discrete c hoice as a general classification problem that is amenable to machine learning metho ds. This is exemplified by W ang and Ross ( 2018 ), Lh ´ eritier et al. ( 2019 ), Rosenfeld et al. ( 2020 ), Chen and Mi ˇ si´ c ( 2022 ), and Chen et al. ( 2025 ). Others main tain an MNL structure at the top lev el—that is, choice probabilities are determined b y a vector of alternativ e-sp ecific utilities that enter a softmax function—but a neural net is used to construct the alternative-specific utility functions in flexible wa ys that deviate from RUM assumptions. F or instance, the utility of alternative j is allow ed to dep end on 2 Supp ose there are ¯ K ob jects in the univ erse and a consumer is presented with a choice set (or “assort- men t”) that contains K ≤ ¯ K elemen ts. A k ey implication of RUM is that the utilit y a consumer derives from pro duct k is inv arian t to the c hoice set, ruling out context or assortmen t effects. 5 attributes of other alternativ es to generate con text effects. This is exemplified by W ang et al. ( 2021 ), W ong and F aro o q ( 2021 ), Cai et al. ( 2022 ), Pfannsc hmidt et al. ( 2022 ), and Berb eglia and V enk ataraman ( 2025 ). Bet ween these tw o streams, a fundamental tension emerges: While RUM mo dels are fa v ored for their interpretabilit y and grounding in economic theory , the dominant R UM mo dels in empirical w ork (linear MNL and mixed-MNL) enforce constraints on deterministic utilities and substitution patterns that may b e to o restrictiv e in some applications; in particular, they assume I IA at the level of individual c hoices. The first stream aims to address this c hallenge by adding additional flexibilit y to R UM mo dels. How ev er, many of these prop osals main tain the assumption of indep enden t logit errors, constraining substitution patterns and p oten tially biasing utility estimates. The exceptions—namely , RUMnet and RUM-NN— address substitution, but they do so at the exp ense of interpretabilit y and/or computational efficiency due to their (a) (p otentially) nonlinear utility functions and (b) exp ensive sample- a verage appro ximations of the lik eliho o d function. The second stream abandons the R UM structure altogether, making it difficult or imp ossible to obtain reliable inferences for man y economically meaningful quantities, suc h as consumer w elfare, willingness-to-pay measures, demand elasticities, and substitution effects. In summary , this tension results in a tradeoff b et w een mo deling flexibility and interpretation, ranging from rigid interpretable mo dels like MNL on one hand to flexible atheoretic classification metho ds on the other. MNP mo dels constitute a notable exception to the ab ov e tradeoff as they allo w for flexi- ble substitution patterns via interpr etable cov ariance relationships. Moreov er, if additional flexibilit y is desired, they can b e extended to allow the deterministic utilities to follow the functional form of a neural netw ork ( Hrusc hk a , 2007 ). Conv ersely , if researchers desire a more parsimonious or interpretable mo del, analysts can constrain the cov ariance structure via p enalization metho ds as in Jiang et al. ( 2025 ) or via factor structures as we illustrate in Section 6 . Despite these virtues, empirical applications of MNP are relativ ely sparse in the literature due, in large part, to the difficulty of ev aluating MNP c hoice probabilities. More broadly , MNP mo dels are just one mem b er of a larger class of R UM mo dels featuring correlated error terms. Analogous to MNP , other mem b ers can b e generated by assuming errors of the form ϵ = Σ 1 / 2 ϵ ∗ , where Σ 1 / 2 is a square-ro ot scale matrix and ϵ ∗ is a vector of exc hangeable errors. F or example, ϵ ∗ j iid ∼ Gumbel(0 , 1) results in a correlated Gum b el distribu- tion with scale matrix Σ . As another example, we could assume ϵ ∗ ∼ Multiv ariate- t ( 0 , I , ν ) to capture hea vy tail behavior via the degrees-of-freedom parameter ν > 0 ( I denotes an iden tity matrix). Bagheri et al. ( 2025 ) consider correlated error distributions formed in this 6 manner, resorting to exp ensiv e sim ulation metho ds to appro ximate the choice probabilities b ecause an efficien t algorithm (GHK) is av ailable only in the Gaussian case. The primary contribution of this w ork is an amortized inference framew ork that pro duces accurate, reusable, and computationally efficient estimates of c hoice probabilities for RUM mo dels with general error distributions, including those featuring non trivial correlation struc- tures. The framew ork presents a p oten tial resolution to the flexibility–in terpretabilit y trade- off highligh ted abov e, enabling practical estimation of flexible choice mo dels without sacri- ficing the economically meaningful insigh ts and parsimony of RUM mo dels. The framew ork is supp orted b y strong theoretical justification, including a universal approximation guaran- tee and asymptotic inference results under mild approximation conditions (see Section 5 ). Moreo ver, the framew ork is largely complementary to recent adv ances in mac hine learning metho ds, including the tw o streams discussed ab ov e. In many cases, these metho ds could b e enhanced with emulator-based likelihoo d ev aluations, resulting in flexible mo dels with in terpretable substitution patterns and manageable computational demands. 3 Problem Setup This section summarizes the problem setup, including the in v ariance prop erties of discrete c hoice mo dels and our inferen tial goals. 3.1 Discrete Choice Mo dels W e consider a decision-mak er choosing among K mutually exclusive alternatives. The decision-mak er assigns a latent utility U j to each alternative j ∈ { 1 , . . . , K } and selects the alternativ e with the highest utility: Y = arg max j ∈{ 1 ,...,K } U j . (1) The laten t utilities decomp ose into deterministic and sto chastic comp onen ts: U j = v j + ϵ j , j = 1 , . . . , K, (2) where v j is the deterministic (or systematic) utility that dep ends on observ able c haracteris- tics, and ϵ j is a cen tered random error capturing unobserv ed factors. As explained in Section 1 , the deterministic utility t ypically takes a linear form v j = x ⊤ j β , where x j is a v ector of alternativ e-sp ecific attributes and β is a parameter vector to b e estimated. 7 Differen t distributional assumptions on the error v ector ϵ = ( ϵ 1 , . . . , ϵ K ) ⊤ yield different c hoice models. The MNL mo del assumes that the ϵ j are indep endent and identically dis- tributed with the Gum b el(0 , 1) distribution. In contrast, the MNP mo del assumes that ϵ follo ws a m ultiv ariate normal distribution with mean zero and co v ariance matrix Σ . Belo w, w e consider correlated mo dels in which ϵ = Σ 1 / 2 ϵ ∗ , where Σ 1 / 2 is a square-ro ot scale matrix as describ ed in Section 2 . W e imp ose the follo wing assumption on ϵ ∗ . Assumption 1. The error v ector ϵ ∗ admits a density , f ϵ ∗ : R K → [0 , ∞ ), with resp ect to Leb esgue measure. Moreov er, the elemen ts of ϵ ∗ are exc hangeable so that f ϵ ∗ ( P π ϵ ′ ) = f ϵ ∗ ( ϵ ′ ) for all ϵ ′ ∈ R K and an y p erm utation matrix, P π . This setup and assumption include the MNP as a leading example with f ϵ ∗ equal to the PDF of the N ( 0 K , I K ) distribution. Ho wev er, the setup is general enough to include many other p ossibilities, such as the correlated Gum b el and m ultiv ariate- t distributions describ ed in Section 2 . W e defer treatmen t of additional regularity conditions until Section 5 when we dev elop the theoretical prop erties of our framework in the con text of an assumed parametric mo del with parameter v ector θ ∈ Θ ⊂ R p . W e denote the c hoice probabilit y for alternative j as P j ( v , Σ ) = Pr( U j ≥ U k for all k = j ) = Pr( ϵ k − ϵ j ≤ v j − v k for all k = j ) , (3) where v = ( v 1 , . . . , v K ) ⊤ . In practice, we ma y also c ho ose to include additional parameters go verning the distribution of ϵ ∗ , such as the degrees-of-freedom parameter, ν , describ ed in Section 2 , but these parameters are suppressed in the notation for simplicity . The c hoice probabilit y can b e expressed as the following integral: P j ( v , Σ ) = Z R j f ϵ ∗ ( ϵ ∗ ) d ϵ ∗ , (4) R j = ϵ ∗ ∈ R K : v j + Σ 1 / 2 j • ϵ ∗ ≥ v k + Σ 1 / 2 k • ϵ ∗ for all k = j , (5) where R j is the region of the error space where alternative j is chosen and Σ 1 / 2 j • denotes the j th row of Σ 1 / 2 so that Σ 1 / 2 j • ϵ ∗ = ϵ j . In general, this in tegral is not analytically tractable. In MNP mo dels, in particular, it do es not hav e a closed-form solution for K ≥ 3, necessitating n umerical metho ds, such as the GHK algorithm, whic h simulates these probabilities via recursiv e conditioning. F or each ev aluation, GHK requires R sim ulation dra ws, with the appro ximation error decreasing at rate O ( R − 1 / 2 ). 8 3.2 In v ariance Prop erties Choice probabilities satisfy three fundamen tal inv ariance prop erties. Lo cation in v ariance. Adding a constant to all utilities do es not c hange choice probabilities: P j ( v + C 1 K , Σ ) = P j ( v , Σ ) (6) where 1 K is the K -vector of ones and C ∈ R may b e random. This follo ws b ecause choices dep end only on utilit y differences. Scale in v ariance. Scaling all utilities and the scale matrix preserves choice probabilities: P j ( α v , α 2 Σ ) = P j ( v , Σ ) for all α > 0 . (7) This follo ws b ecause the scaled mo del is equiv alent to the original mo del with v and ϵ replaced b y α v and α ϵ , resp ectively . P ermutation equiv ariance. Relab eling alternatives permutes the choice probabilities cor- resp ondingly . F or an y p erm utation π of { 1 , . . . , K } with asso ciated p ermutation matrix P π : P j ( v , Σ ) = P π − 1 ( j ) ( P π v , P π ΣP ⊤ π ) . (8) A naive attempt at constructing an emulator may not resp ect these prop erties. T ranslating, rescaling, or p ermuting the alternatives could pro duce different emulator predictions, result- ing in slo w learning and p o or generalization b ecause the emulator would need to learn these prop erties manually . In Section 4 , we propose a solution that automatically satisfies these prop erties based on tw o design comp onen ts: a prepro cessing step that fixes the lo cation and scale, and an equiv ariant arc hitecture that ensures p erm utation equiv ariance without sacrificing expressivit y . The ab ov e in v ariance prop erties imply that the choice mo del is not identified without normal- ization. W e assume throughout that the mo del has b een appropriately normalized s o that the parameter v ector θ is identified. This is t ypically ac hiev ed in practice b y setting the utility of one alternativ e to zero deterministically and fixing one of the nonzero diagonal elemen ts in Σ (see Keane ( 1992 )). Similarly , we assume that the data exhibit sufficient v ariation to iden tify the remaining parameters, whic h t ypically requires v ariation in alternativ e-sp ecific co v ariates, such as prices. 9 3.3 Inferen tial Goals Giv en observ ations { ( y i , X i ) } n i =1 , where y i ∈ { 1 , . . . , K } is the observ ed c hoice and X i rep- resen ts the co v ariates, w e seek to estimate the parameter vector, θ . This parameter vector includes b oth the co efficients affecting deterministic utilities and additional parameters gov- erning the scale matrix. The (a veraged) log-likelihoo d function is ℓ n ( θ ) = 1 n n X i =1 log P y i { v i ( X i , θ ) , Σ i ( X i , θ ) } , (9) where v i ( X i , θ ) and Σ i ( X i , θ ) denote the utilit y vector and scale matrix for observ ation i as functions of the co v ariates and parameters. Maxim um likelihoo d estimation requires maximizing ℓ n ( θ ) o v er Θ, which in turn requires rep eated ev aluation of ℓ n ( θ ) and its gradien t ∇ θ log P j ( v , Σ ). Similarly , Bay esian metho ds such as Hamiltonian Monte Carlo require rep eated ev aluations of b oth ℓ n ( θ ) and ∇ θ log P j ( v , Σ ), often thousands of times throughout the estimation pro cess. Our goal is to construct a neural net w ork em ulator ˆ P j ( v , Σ ; ϕ ) that provides fast, accurate appro ximations of the true c hoice probabilities, along with analytic gradients via automatic differen tiation. The em ulator is trained once on sim ulated data spanning the relev ant input space, after whic h it can b e used for rapid inference on many datasets and mo dels. 4 Em ulator Design This section outlines the emulator preprocessing transformations, neural netw ork architec- ture, training pro cedure, and inference pro cess. 4.1 Design Goals The em ulator must satisfy four desiderata: 1. Resp ect in v ariance prop erties. The em ulator should resp ect the in v ariance prop- erties describ ed in Section 3.2 : in v ariance with resp ect to lo cation shifts and scale transformations, and equiv ariance with resp ect to p ermutations. 2. Provide smo oth appro ximations. The em ulator should b e differen tiable with re- sp ect to its inputs, enabling gradient-based optimization and automatic differen tiation. 10 3. Generalize across sp ecifications. A single trained emulator should w ork for div erse utilit y and cov ariance structures. 4. Be computationally efficient. Emulator ev aluation should b e fast enough to enable routine use in estimation. W e ac hiev e these goals through a com bination of prepro cessing transformations and a care- fully designed neural net work architecture. 4.2 Prepro cessing: Centering and Scaling W e address lo cation and scale in v ariance through prepro cessing transformations that pro ject the inputs on to a canonical subspace. Cen tering. Define the cen tering matrix M = I K − 1 K 1 K 1 ⊤ K , (10) whic h w e emplo y to pro ject the vector of utilities, U ∈ R K , onto the subspace orthogo- nal to 1 K , resulting in transformed utilities ˜ U = M ( v + ϵ ) = v + ϵ − 1 K ( ¯ v + ¯ ϵ ), where ¯ v = 1 K P K j =1 v j and ¯ ϵ = 1 K P K j =1 ϵ j . These transformed utilities sum to zero within each realization: P K j =1 ˜ U j = 0. In effect, this transformation results in mo dified em ulator inputs: ˜ v = M v = v − 1 K ¯ v, ˜ Σ = MΣM ⊤ . (11) Scaling. W e normalize by the trace of the cen tered scale matrix, pro ducing transformed utilities U ∗ = q K/ tr ˜ Σ ˜ U . The final transformed parameters are then v ∗ = s K tr( ˜ Σ ) ˜ v , Σ ∗ = K tr( ˜ Σ ) ˜ Σ . (12) W e can omit the case tr( ˜ Σ ) = 0 as this results in kno wn, deterministic c hoices. The complete transformation pro duces normalized inputs ( v ∗ , Σ ∗ ) satisfying: 1. P K j =1 v ∗ j = 0 (cen tered deterministic utilities), 2. Σ ∗ 1 K = 0 (centered scale matrix), 11 3. tr( Σ ∗ ) = K (scale-normalized), 4. Σ ∗ is p ositiv e semidefinite with rank at most K − 1. This normalization reduces the size of the emulator’s input space, accelerating learning and impro ving generalization. Imp ortantly , this transformation commutes with p erm utation ma- trices: for any permutation matrix P π , applying the transformation to ( P π v , P π ΣP ⊤ π ) yields ( P π v ∗ , P π Σ ∗ P ⊤ π ). This ensures that the prepro cessing preserves p ermutation equiv ariance. 4.3 Neural Net w ork Arc hitecture After preprocessing, we construct a neural net work that maps ( v ∗ , Σ ∗ ) to choice probabilities while mainta ining p ermutation equiv ariance. The architecture consists of three comp onents: a p er-alternative enco der, p erm utation-equiv ariant la yers, and an output la y er. Belo w, we in terpret Σ as a co v ariance matrix to simplify the exposition, referring to its diagonal and off- diagonal elemen ts as v ariances and cov ariances, resp ectively . This interpretation is correct for MNP mo dels. F or other mo dels, it is only illustrativ e as these parameters may not exactly coincide with the v ariances and co v ariances. P er-alternative enco der. F or each alternative j ∈ { 1 , . . . , K } , we construct a repre- sen tation z j ∈ R d z that captures ho w alternativ e j relates to all other alternatives. This represen tation is built from t wo complementary DeepSet netw orks—a diagonal DeepSet and an off-diagonal DeepSet—whose outputs are combined with alternativ e j ’s own features. The diagonal DeepSet pro cesses pairwise relationships b etw een j and eac h other alterna- tiv e, while the off-diagonal DeepSet summarizes the co v ariance structure among alternatives other than j . In the descriptions b elow, the features lab eled as “base inputs” are sufficien t for universal approximation of c hoice probabilities (see Section 5.1 ). W e include additional features to improv e the expressivity of the emulator, as we find this improv es its predictions. Diagonal DeepSet. F or each pair ( j, k ) with k = j , we construct a feature v ector d j k con taining differen tiable functions of the utilities and co v ariances asso ciated with alternatives j and k . The base inputs are the utilities v ∗ j and v ∗ k , the v ariances Σ ∗ j j and Σ ∗ kk , and the co v ariance Σ ∗ j k . F rom these, we derive additional feature transformations that facilitate learning, including standard deviations σ j = p Σ ∗ j j and σ k = p Σ ∗ kk , the correlation ρ j k = Σ ∗ j k / ( σ j σ k ), and the standardized utilit y difference (z-score): z j k = v ∗ j − v ∗ k p Σ ∗ j j + Σ ∗ kk − 2Σ ∗ j k . (13) 12 The diagonal DeepSet pro cesses these features using the architecture of Zaheer et al. ( 2017 ): h diag j = ρ diag X k = j ϕ diag ( d j k ) ! , (14) where ϕ diag is a multi-la y er p erceptron (MLP) applied to eac h pair, the sum aggregates ov er all k = j , and ρ diag is another MLP that pro duces a learned nonlinear representation of the sum. W e use the notation ϕ diag and ρ diag follo wing Zaheer et al. ( 2017 ); the MLPs ρ diag and ρ off (defined b elo w) can b e distinguished from the correlation ρ j k b y their subscripts. Singh et al. ( 2023 ) also emplo y a v ariant of the DeepSet arc hitecture. Ho wev er, their metho d assumes iid errors and operates on problem-sp ecific features, which requires their neural net work to b e mo dified and retrained to accommo date new data structures. In contrast, our arc hitecture relies on generic RUM mo del inputs, such as deterministic utilities. Off-diagonal DeepSet. F or each pair ( k , l ) with k < l and k , l = j , w e construct a feature v ector o kl con taining differen tiable, symmetric functions comparing alternatives k and l ; we require symmetry b ecause the pairs do not p ossess a natural ordering. The base input is Σ ∗ kl , and we include other deriv ed features, suc h as the correlation ρ kl , squared utility difference ( v ∗ k − v ∗ l ) 2 , the squared z-score z 2 kl , and the v ariance sum Σ ∗ kk + Σ ∗ ll . The off-diagonal DeepSet has an analogous structure to that of the diagonal DeepSet: h off j = ρ off X k 0 con trols the weigh t of the gradien t-matching term. The cross-en tropy comp onen t is the multinomial negative log-likelihoo d (up to constants): L CE ( ϕ ) = − K X j =1 ˆ P sim j log ˆ P j ( v ∗ , Σ ∗ ; ϕ ) , (21) where ˆ P sim j = n j / P K k =1 n k is the sim ulated choice frequency for alternative j . F or the gradient-matc hing comp onent, we follo w the sto c hastic Sob olev training approach of Czarnec ki et al. ( 2017 ), whic h a voids computing full Jacobian matrices b y instead matc hing directional deriv atives along random directions. Let d = ( d v , vec h( D Σ )) denote a random direction in the joint space of utilities and cov ariances, where d v ∈ R K , D Σ ∈ R K × K is symmetric, and v ech( · ) denotes the half-vectorization (upp er triangular elemen ts including the diagonal). The gradient-matc hing loss is: L grad ( ϕ ) = K X j =1 ˆ P sim j ∇ d log ˆ P j − ∇ d log P target j 2 , (22) where ∇ d denotes the directional deriv ativ e along d . W eighting by the simulated c hoice frequencies ˆ P sim j fo cuses learning on alternatives that are frequently c hosen, whose gradients most influence parameter estimation in do wnstream inference tasks. Constrain t-resp ecting directions. The canonical inputs ( v ∗ , Σ ∗ ) lie on a constrained 17 manifold: X K = ( ( v ∗ , Σ ∗ ) : K X j =1 v ∗ j = 0 , Σ ∗ 1 K = 0 , tr( Σ ∗ ) = K , Σ ∗ ⪰ 0 ) . (23) Random directions must resp ect these constrain ts to remain in the tangent space of X K . W e construct v alid directions as follo ws: 1. Sample ˜ d v ∼ N ( 0 , I K ) and cen ter: d v = ˜ d v − ¯ d v 1 K , where ¯ d v = 1 K P j ˜ d v ,j . 2. Sample a symmetric matrix ˜ D Σ with iid standard normal entries on and ab ov e the diagonal, then double-cen ter: D ′ Σ = M ˜ D Σ M , (24) where M = I K − 1 K 1 K 1 ⊤ K is the cen tering matrix from Section 4 . 3. Remov e the trace comp onent to ensure tr( D Σ ) = 0: D Σ = D ′ Σ − tr( D ′ Σ ) K − 1 M . (25) 4. Set d = ( d v , vec h( D Σ )) and normalize: d ← d / ∥ d ∥ . Computing directional deriv atives. W e compute the emulator’s directional deriv atives via finite differences: ∇ d log ˆ P j ≈ log ˆ P j ( v ∗ + ϵ d v , Σ ∗ + ϵ d Σ ; ϕ ) − log ˆ P j ( v ∗ − ϵ d v , Σ ∗ − ϵ d Σ ; ϕ ) 2 ϵ , (26) where ϵ > 0 is a small step size (we use ϵ = 10 − 5 ). This approac h is computationally efficien t, requiring only tw o additional forw ard passes p er direction regardless of the input dimension. Alternativ ely , one could compute the directional deriv ativ e via automatic differentiation as in Czarnec ki et al. ( 2017 ). T arget directional deriv atives are computed from pre-stored Jacobians. During data gen- eration, we compute and store the full Jacobians ∇ θ log P target j with resp ect to v ∗ and Σ ∗ . During training, the target directional deriv ativ e is obtained via the inner pro duct: ∇ d log P target j = * ∂ log P target j ∂ v ∗ , d v + + * ∂ log P target j ∂ Σ ∗ , D Σ + F , (27) where ⟨· , ·⟩ F denotes the F rob enius inner pro duct. 18 T arget gradien t computation. Computing target gradients for Sob olev training requires differen tiating through the c hoice sim ulation pro cess. Since discrete c hoices are inherently non-differen tiable, w e emplo y a smo oth relaxation using a temperature-scaled softmax. F or eac h Mon te Carlo draw r with utilit y v ector U ( r ) = v ∗ + ϵ ( r ) , w e appro ximate the hard c hoice indicator with: ˜ Y ( r ) j = exp( τ U ( r ) j ) P K k =1 exp( τ U ( r ) k ) , (28) where τ > 0 is a temperature parameter. As τ → ∞ , this conv erges to the hard argmax; for finite τ , it pro vides a differentiable approximation. The target log-probability is then: log P target j = log 1 R R X r =1 ˜ Y ( r ) j ! , (29) and the target gradien ts ∂ log P target j /∂ v ∗ and ∂ log P target j /∂ Σ ∗ are obtained via automatic differen tiation through this expression. This approac h is closely related to the “Gum b el– softmax tric k” frequen tly used for gradien t estimation with neural netw orks ( Jang et al. , 2017 ; Maddison et al. , 2017 ). W e use τ = 3 in our exp erimen ts, which pro vides a balance b et w een gradient accuracy (low bias) and computational stability . T raining details. Our training pro cedure mak es use of t wo r eplay buffers , a common tec hnique in deep learning ( Mnih et al. , 2015 ). The first repla y buffer stores precomputed training examples including inputs ( v ∗ , Σ ∗ ), sim ulated choice frequencies, and target Jaco- bians. The second stores random directions for the gradient-matc hing loss. At eac h training step, we sample random pairs from the repla y buffers, compute the loss, and up date the net work parameters via sto chastic gradien t descent. The repla y buffer accelerates training b y allo wing reuse of expensive high-precision simulations and gradient computations. W e set the gradien t p enalty weigh t λ grad = 10 − 8 in our exp eriments; empirically , we find that this v alue provides sufficiently well-behav ed deriv atives. Multi- K training. Remark ably , none of the weigh t vectors and matrices has a dimension dep ending on K . The dimension K en ters the neural netw ork only through the input data dimension; thus, we can design a single emulator capable of pro cessing m ultiple v alues of K simultaneously . The training pro cedures describ ed abov e can then be adapted to iterate o ver a range of K v alues, sa y K ∈ { 3 , 4 , 5 } , and the resulting emulator can then learn to appro ximate choice probabilities for a v arying n umber of choices (see Section 6.3 ). Under this configuration, w e recommend including K as an element of s j . 19 4.5 Inference with the T rained Emulator Once trained, the em ulator enables rapid inference. Giv en a new dataset { ( y i , X i ) } n i =1 and candidate parameter v ector θ : 1. Compute the deterministic utilit y vector v i ( X i , θ ) and scale matrix Σ i ( X i , θ ) for eac h observ ation. 2. Apply the prepro cessing transformation to obtain ( v ∗ i , Σ ∗ i ). 3. Ev aluate the em ulator to obtain estimated c hoice probabilities ˆ P ij for all alternatives. 4. Compute the log likelihoo d ˆ ℓ n ( θ ) = 1 n P n i =1 log ˆ P i,y i . As the prepro cessing transformation and neural netw ork are b oth smo oth functions, the gra- dien ts of the emulator log lik eliho o d with resp ect to θ can b e computed exactly via automatic differen tiation. This enables the use of gradien t-based optimizers for maximum likelihoo d estimation, as well as gradien t-based sampling metho ds suc h as Hamiltonian Mon te Carlo for Ba yesian inference. The smo othness of the em ulator also facilitates computation of standard errors, whic h can b e estimated via outer pro ducts of gradients (see Section 5.2 ). 5 Theory This section establishes the theoretical foundations for the emulator architecture and the statistical prop erties of em ulator-based discrete choice estimators. 5.1 Univ ersal Appro ximation W e first show that the p er-alternative enco der arc hitecture can univ ersally appro ximate c hoice probabilities. The key insigh t is that the multisets pro cessed b y the enco der generically determine the input up to the relev ant symmetry group. F or eac h alternativ e j , define the in v ariant function g j : X K → (Multiset , Multiset) by: T j ( v ∗ , Σ ∗ ) = { { ( v ∗ k , Σ ∗ kk , Σ ∗ j k ) : k = j } } , (30) O j ( Σ ∗ ) = { { Σ ∗ kl : 1 ≤ k < l ≤ K , k = j, l = j } } , (31) g j ( v ∗ , Σ ∗ ) = ( T j ( v ∗ , Σ ∗ ) , O j ( Σ ∗ )) . (32) The m ultiset T j consists of K − 1 triples, eac h coupling an alternativ e k ’s utility and v ariance with its cov ariance with alternativ e j . The multiset O j consists of the off-diagonal co v ariances 20 among alternatives other than j . These are precisely the base inputs pro cessed by the p er- alternativ e enco der’s diagonal and off-diagonal DeepSets. Theorem 1 (Generic Separation) . F or e ach alternative j ∈ { 1 , . . . , K } , ther e exists a close d, me asur e-zer o set B j ⊂ X K such that for any ( v ∗ 1 , Σ ∗ 1 ) , ( v ∗ 2 , Σ ∗ 2 ) ∈ X K \ B j : g j ( v ∗ 1 , Σ ∗ 1 ) = g j ( v ∗ 2 , Σ ∗ 2 ) = ⇒ ( v ∗ 1 , Σ ∗ 1 ) and ( v ∗ 2 , Σ ∗ 2 ) ar e in the same S ( j ) K − 1 -orbit , (33) wher e S ( j ) K − 1 is the sub gr oup of p ermutations fixing alternative j . The pro of, giv en in App endix A.8 , pro ceeds in three steps: Step 1: Genericity conditions. W e define tw o genericit y conditions on ( v ∗ , Σ ∗ ): (a) the triples ( v ∗ k , Σ ∗ kk , Σ ∗ j k ) for k = j are pairwise distinct as elemen ts of R 3 ; and (b) for each k = j , there exists a unique subset of off-diagonal co v ariances that sums to − Σ ∗ kk − Σ ∗ j k . Condition (b) follo ws from the row-sum constrain t Σ ∗ 1 K = 0 : the off-diagonal entries in ro w k (excluding Σ ki ) sum to − Σ ∗ kk − Σ ∗ j k . Step 2: Reco v ery pro cedure. When b oth conditions hold, we can recov er ( v ∗ , Σ ∗ ) from g j up to relab eling of alternat iv es other than j . First, order the triples in T j lexicographically to assign lab els to alternativ es. Then, for eac h alternative k , iden tify its row of off-diagonal en tries as the unique subset in O j with the required sum. Finally , reco ver shared entries Σ ∗ kl as the singleton in tersection of the subsets for rows k and l . Step 3: Measure-zero exceptional set. The set B j where either condition fails is a finite union of zero sets of nontrivial analytic functions on the affine subspace X K . By the principle that prop er analytic sub v arieties hav e measure zero ( Mity agin , 2020 ), B j has measure zero. This separation result, com bined with the Stone–W eierstrass theorem, yields univ ersal ap- pro ximation: Theorem 2 (MLP Univ ersal Approximation) . Under Assumption 1 , for e ach alternative j , the choic e pr ob ability function P j c an b e uniformly appr oximate d on any c omp act subset of X K \ B j by a multi-layer p er c eptr on taking the c omp onents of g j as input. Pr o of sketch. W e apply the pro of strategy of Blum-Smith et al. ( 2025 ). The c hoice probabil- it y P j is con tin uous and S ( j ) K − 1 -in v ariant. By Theorem 1 , the functions encoding g j —sorted triples and sorted off-diagonal entries—separate p oin ts in the quotient space ( X K \ B j ) /S ( j ) K − 1 . Since S ( j ) K − 1 is finite (hence compact), standard results imply that the quotien t is Hausdorff 21 ( Bredon , 1972 ). By the Stone–W eierstrass theorem, the algebra generated by these functions is dense in contin uous functions on compact subsets of the quotient. Pulling bac k to X K and applying the univ ersal appro ximation theorem for MLPs ( Cyb enk o , 1989 ; Hornik et al. , 1989 ) yields the result. See App endix A.8 for details. Corollary 1 (Arc hitecture Universal Approximation) . L et B = ∪ K j =1 B j . Under Assumption 1 , for e ach alternative j , the choic e pr ob ability function P j c an b e uniformly appr oximate d on any c omp act subset of X K \ B j by the p er-alternative enc o der. F urther, the ve ctor of choic e pr ob abilities ( P 1 , . . . , P K ) c an b e uniformly appr oximate d on any c omp act subset of X K \ B by the neur al network ar chite ctur e of Se ction 4.3 . Pr o of. Apply the pro of of Theorem 2 in tandem with univ ersal approximation results for DeepSet ( Zaheer et al. , 2017 ) and equiv ariant architectures ( Segol and Lipman , 2020 ). The exceptional set B has measure zero, so it do es not affect appro ximation in practice: for an y probabilit y distribution o v er X K that is absolutely con tinuous with resp ect to Leb esgue measure, inputs lie in B with probability zero. Corollary 1 guaran tees that the p er-alternative enco der alone is sufficien t for universal ap- pro ximation. The inclusion of the final equiv ariant lay ers ensures that the estimated proba- bilities sum to one and impro ves the expressivity of the neural net w ork. F or large choice sets, w e ma y opt for a simpler arc hitecture that applies the p er-alternativ e enco der to only the c hosen alternative with no equiv ariant la yers, resulting in a single output, P j . This mo dification maintains the univ ersal approximation property; how ever, it relaxes the sum-to-one constrain t in return for computational efficiency . Corollary 1 could also b e extended to hold simultaneously for a finite set of K v alues under a suitable extension of the space X K and its exceptional sets. Section 6.3 presen ts n umeri- cal results showing that the prop osed architecture can pro vide accurate appro ximations for m ultiple v alues of K simultaneously . 5.2 Consistency and Asymptotic Normalit y W e now establish that em ulator-based estimators inherit the asymptotic prop erties of exact maxim um likelihoo d estimators under appropriate conditions. Let { ( y i , X i ) } n i =1 b e iid observ ations from the true mo del with parameter θ 0 ∈ Θ. Define the 22 true and em ulator log-likelihoo d contributions as m ( y , X ; θ ) = log P y { v ∗ ( X , θ ) , Σ ∗ ( X , θ ) } , (34) ˆ m n ( y , X ; θ ) = log ˆ P y { v ∗ ( X , θ ) , Σ ∗ ( X , θ ); ϕ n } , (35) with corresp onding score functions ψ ( y , X ; θ ) = ∇ θ m ( y , X ; θ ) , ˆ ψ n ( y , X ; θ ) = ∇ θ ˆ m n ( y , X ; θ ) . (36) The true and em ulator (a veraged) log lik eliho o ds are ℓ n ( θ ) = 1 n P n i =1 m ( y i , X i ; θ ) and ˆ ℓ n ( θ ) = 1 n P n i =1 ˆ m n ( y i , X i ; θ ). Define the MLE and emulator-based estimator as ˜ θ n = arg max θ ∈ Θ ℓ n ( θ ) , ˆ θ n = arg max θ ∈ Θ ˆ ℓ n ( θ ) . (37) W e require that the em ulator log likelihoo d con verges to the true log likelihoo d. Assumption 2 (Emulator Approximation Qualit y) . F or some α ≥ 0, the em ulator satisfies sup θ ∈ Θ ˆ ℓ n ( θ ) − ℓ n ( θ ) = o p ( n − α ) . (38) The n referenced in Assumption 2 is the sample size of the observed data. Consequen tly , this assumption in v olv es an asymptotic regime in which the emulator becomes increasingly accurate as n → ∞ , which is achiev able b y progressiv ely (a) increasing the num b er of simu- lated training examples and (b) increasing the neural net work complexit y (i.e., the num b er of lay ers and hidden units). App endix B.1 provides more primitive sufficien t conditions for Assumption 2 with references to closel y related work on con v ergence rates of neural netw orks and their usage in econometric theory . Notably , for mo dels with analytic c hoice probabilities, w e exp ect this assumption to require only O ( n α + δ ) training examples for an y δ > 0. W e also require sufficien t regularit y of the true mo del. Assumption 3 (Regularity) . The mo del satisfies: (i) θ 0 is the unique maximizer of E { m ( y , X ; θ ) } in the compact set Θ with θ 0 ∈ int(Θ) and E {| m ( y , X ; θ 0 ) |} < ∞ ; (ii) m ( y , X ; θ ) is twice contin uously differen tiable in θ for all ( y , X ); (iii) E { sup θ ∈ Θ ∥ ψ ( y , X ; θ ) ∥ 2 } < ∞ ; 23 (iv) E { sup θ ∈ Θ ∥∇ 2 θ m ( y , X ; θ ) ∥} < ∞ ; (v) the Fisher information J ( θ 0 ) = E ψ ( y , X ; θ 0 ) ψ ( y , X ; θ 0 ) ⊤ is p ositiv e definite. Theorem 3 (Consistency) . Under Assumptions 2 and 3 , ˆ θ n p − → θ 0 as n → ∞ . Pr o of. By Assumption 2 with α ≥ 0, sup θ | ˆ ℓ n ( θ ) − ℓ n ( θ ) | p − → 0. F urther, the regularit y conditions of Assumption 3 are sufficient to apply the uniform la w of large num b ers (ULLN) so that sup θ | ℓ n ( θ ) − E { m ( y , X ; θ ) } | p − → 0. The triangle inequalit y giv es uniform conv ergence of ˆ ℓ n to E { m ( y , X ; θ ) } , whic h is uniquely maximized at θ 0 b y Assumption 3 (i). By the consistency theorem for extrem um estimators ( New ey and McF adden , 1994 , Theorem 2.1), ˆ θ n p − → θ 0 . Under the stronger condition α ≥ 1, the emulator-based estimator is asymptotically normal. Theorem 4 (Asymptotic Normality) . Under Assumptions 2 and 3 with α ≥ 1 , √ n ( ˆ θ n − θ 0 ) d − → N 0 , J ( θ 0 ) − 1 . (39) The pro of, giv en in App endix B.2 , sho ws that ˆ θ n is asymptotically equiv alent to ˜ θ n . R emark 1 (Approximate Maximizers) . If a maxim um is not uniquely attained, one can work with appro ximate maximizers satisfying ˆ ℓ n ( ˆ θ n ) ≥ sup θ ˆ ℓ n ( θ ) − o p ( n − α ). The consistency and asymptotic normality results contin ue to hold; see Newey and McF adden ( 1994 , Theorem 2.1) and App endix B.2 . T o estimate the Fisher information, define the true and emulator outer-pro duct-of-scores estimators: J n ( θ ) = 1 n n X i =1 ψ ( y i , X i ; θ ) ψ ( y i , X i ; θ ) ⊤ , (40) ˆ J n ( θ ) = 1 n n X i =1 ˆ ψ n ( y i , X i ; θ ) ˆ ψ n ( y i , X i ; θ ) ⊤ . (41) Assumption 4 (Gradient Approximation Quality) . The emulator satisfies sup θ ∈ Θ ˆ J n ( θ ) − J n ( θ ) p − → 0 as n → ∞ . (42) Assumption 4 is justified by Sobolev training, which penalizes discrepancies b et ween em u- lator and target gradients. The p enalization is required b ecause training on log-likelihoo d 24 v alues alone do es not guaran tee con vergence of gradients. As with Assumption 2 , see Ap- p endix B.1 for more primitiv e sufficient conditions and additional discussion. Prop osition 1 (Consisten t Estimation of Fisher Information) . Under Assumptions 2 , 3 , and 4 , ˆ J n ( ˆ θ n ) p − → J ( θ 0 ) . Pr o of. By the triangle inequality , ∥ ˆ J n ( ˆ θ n ) − J ( θ 0 ) ∥ ≤ ∥ ˆ J n ( ˆ θ n ) − J n ( ˆ θ n ) ∥ + ∥ J n ( ˆ θ n ) − J ( ˆ θ n ) ∥ + ∥ J ( ˆ θ n ) − J ( θ 0 ) ∥ . The first term v anishes by Assumption 4 . F or the second term, the regularity conditions of Assumption 3 are sufficient to apply the ULLN to J n ; thus, this term also con verges in probability to zero. Finally , the third term v anishes b y contin uity of J and consistency of ˆ θ n . The emulator score ˆ ψ n ( y i , X i ; θ ) is computable via automatic differentiation through the smo oth neural net w ork. Standard errors for ˆ θ n are obtained as the square ro ots of the diagonal elemen ts of ˆ J n ( ˆ θ n ) − 1 /n . An alternativ e estimator based on the Hessian, ˜ J n = − 1 n P n i =1 ∇ 2 θ ˆ m n ( y i , X i ; ˆ θ n ), requires second-deriv ative accuracy not directly targeted b y first-order Sob olev training. The score- based estimator ˆ J n ( ˆ θ n ) is therefore preferred. 5.3 Inference Under Missp ecification When the em ulator do es not p erfectly approximate the true likelihoo d, w e can still obtain v alid inference b y treating the em ulator as a working mo del, follo wing the quasi-maximum lik eliho o d framework ( White , 1982 ). In this section, we treat the neural net work as fixed with n , dropping the n subscript from the observ ation log lik eliho o d, ˆ m ( y , X ; θ ), and score function, ˆ ψ ( y , X ; θ ). Define the pseudo-true parameter as the population maximizer of the em ulator log likelihoo d: θ † 0 = arg max θ ∈ Θ E { ˆ m ( y , X ; θ ) } . (43) When the em ulator closely appro ximates the true likelihoo d, θ † 0 ≈ θ 0 . The asymptotic distribution dep ends on t wo matrices: A ( θ ) = − E ∇ 2 θ ˆ m ( y , X ; θ ) , B ( θ ) = E n ˆ ψ ( y , X ; θ ) ˆ ψ ( y , X ; θ ) ⊤ o . (44) Under correct sp ecification (i.e., a p erfect em ulator), the information matrix equalit y giv es A ( θ 0 ) = B ( θ 0 ) = J ( θ 0 ). Under missp ecification, these matrices differ, necessitating the sandwic h co v ariance form. Under regularit y conditions stated in App endix B.3 , we obtain 25 the follo wing results. Theorem 5 (Consistency Under Missp ecification) . Under Assumptions 5 and 6 , ˆ θ n p − → θ † 0 . Theorem 6 (Asymptotic Normality Under Missp ecification) . Under Assumptions 5 and 6 , √ n ( ˆ θ n − θ † 0 ) d − → N n 0 , A ( θ † 0 ) − 1 B ( θ † 0 ) A ( θ † 0 ) −⊤ o . (45) The pro ofs follow standard M-estimator argumen ts; see App endix B.4 . The sandwich co- v ariance V = A ( θ † 0 ) − 1 B ( θ † 0 ) A ( θ † 0 ) −⊤ can b e consisten tly estimated by ˆ V n = ˆ A − 1 n ˆ B n ˆ A −⊤ n , where ˆ A n = − 1 n n X i =1 ∇ 2 θ ˆ m ( y i , X i ; ˆ θ n ) , ˆ B n = 1 n n X i =1 ˆ ψ ( y i , X i ; ˆ θ n ) ˆ ψ ( y i , X i ; ˆ θ n ) ⊤ . (46) Both quan tities are computable via automatic differentiation. Note that ˆ B n corresp onds to ˆ J n ( ˆ θ n ) from the previous section under an asymptotic regime with a fixed emulator. Theorem 6 pro vides v alid inference for θ † 0 , not necessarily θ 0 . If w e emplo y an asymptotic regime where the em ulator v aries with n , then the pseudo-true parameter also v aries with n , so we denote it as θ † n . When α ∈ [0 , 1) in Assumption 2 , we ha ve θ † n p − → θ 0 as n → ∞ , but this conv ergence ma y b e to o slo w relativ e to √ n sampling v ariabilit y . The sandwich standard errors remain v alid for θ † n , but confidence interv als should not b e interpreted as targeting θ 0 . Even if A ( θ † 0 ) and B ( θ † 0 ) b oth approximate J ( θ 0 ), the centering at θ † n = θ 0 in tro duces asymptotic bias. V alid inference for θ 0 requires α ≥ 1 (Theorem 4 ). Similarly , Prop osition 1 pro vides conditions under which ˆ B n p − → J ( θ 0 ). Ho wev er, our first- order Sobolev training pro cedure pro vides no guarantee that the emulator Hessian will ap- pro ximate the Hessian of the true mo del; thus, ˆ A n need not conv erge to an y quantit y from the true mo del. How ever, Theorem 6 requires only that A ( θ † 0 ) b e nonsingular, not that it matc h the true model. When the emulator additionally pro vides accurate second deriv atives, the sandwic h cov ariance matrix reduces to J ( θ 0 ) − 1 . 6 Sim ulation Study W e ev aluate the p erformance of em ulator-based MNP estimators across a range of sam- ple sizes, num b ers of alternatives, and mo del sp ecifications. W e compare their statistical p erformance and computational requiremen ts to estimators based on the GHK simulator. 26 6.1 Sim ulation Design Mo del sp ecification. W e consider MNP mo dels with K ∈ { 3 , 5 , 10 } alternatives and p = 2 cov ariates. Alternativ e K serv es as the reference with utilit y normalized to zero, represen ting an outside option. F or each non-reference alternativ e j ∈ { 1 , . . . , K − 1 } , the deterministic utilit y is v j = x ⊤ j β , where x j ∈ R p is a vector of alternativ e-sp ecific attributes and β = (0 , 1) ⊤ is the true co efficient v ector. W e consider tw o sp ecifications for Σ , denoting them as Dense and F actor. The Dense sp ecification assumes a dense structure for Σ 1:( K − 1) , 1:( K − 1) , the upp er ( K − 1) × ( K − 1) submatrix of Σ . F or iden tification, we set Σ 11 = 1 and Σ • K = Σ ⊤ K • = 0 K ; the latter equation sets the v ariance and co v ariances of the zero-utility option to zero. The F actor sp ecification assumes a one-factor structure for Σ 1:( K − 1) , 1:( K − 1) of the form Σ 1:( K − 1) , 1:( K − 1) = Ψ + γ γ ⊤ , where γ ∈ R K − 1 and Ψ ∈ R ( K − 1) × ( K − 1) is a diagonal ma- trix of uniquenesses. F or identification, w e imp ose an anc hored normalization that fixes the first uniqueness and first factor loading: Ψ 11 = 0 , γ 1 = 1 . (47) As with the Dense sp ecification, w e set Σ • K = Σ ⊤ K • = 0 K . These constrain ts imply Σ 11 = 1, fixing the scale of the mo del, and Σ 1 j = γ j for j ≥ 2, so that the factor loadings directly enco de co v ariances with the first alternativ e. Giv en these constrain ts, w e parameterize the mo del in terms of K − 2 free uniquenesses (Ψ 22 , . . . , Ψ K − 1 ,K − 1 ) and K − 2 free loadings ( γ 2 , . . . , γ K − 1 ). This anchored normalization is designed to eliminate flat directions in the lik eliho o d surface. T able 1 sho ws the num b er of nonredundan t parameters by t yp e for the Dense and F actor sp ecifications. With the anc hored normalization, the F actor sp ecification is exactly iden tified for K = 3 and o veriden tified for K ≥ 4. F or K = 10, the F actor sp ecification results in fewer than half as man y parameters as the Dense sp ecification (18 vs. 46). Data generation. F or each replication, w e generate cov ariates x ij iid ∼ N ( 0 , I p ) for obser- v ations i = 1 , . . . , n and alternativ es j = 1 , . . . , K − 1, with x iK = 0 for the reference alternativ e. F or the Dense sp ecification, w e dra w the co v ariance matrix according to a Wishart( I K − 1 , K + 10) distribution and then normalize it so that Σ 11 = 1, resulting in a probability densit y 27 Co v ariance ( Σ ) Sp ecification K Co efficien ts V ariances (Uniquenesses) Co v ariances (Loadings) T otal Dense 3 2 1 1 4 5 2 3 6 11 10 2 8 36 46 F actor 3 2 1 1 4 5 2 3 3 8 10 2 8 8 18 T able 1: Parameter counts by Σ sp ecification (Dense or F actor) and K . function (PDF) giv en by Γ( s ) · | Σ 1:( K − 1) , 1:( K − 1) | 5 2 s Γ K − 1 K +10 2 · 1 2 tr( Σ 1:( K − 1) , 1:( K − 1) ) s , (48) where s = ( K + 10)( K − 1) / 2 and Γ K − 1 ( · ) denotes the ( K − 1)-dimensional m ultiv ariate gamma function (see App endix C.2 ). F or the F actor sp ecification, w e sample the free uniquenesses on the log scale, drawing log(Ψ j j ) iid ∼ N (0 , 0 . 1 2 ) for j = 2 , . . . , K − 1, and exp onen tiate to obtain Ψ j j > 0. F or the factor loadings, we draw γ j iid ∼ N (0 , 0 . 2 2 ) for j = 2 , . . . , K − 1. The fixed v alues Ψ 11 = 0 and γ 1 = 1 complete the parameterization. Giv en the co v ariates and true parameters, we compute deterministic utilities and sim ulate c hoices y i ∈ { 1 , . . . , K } according to one of t w o data-generating pro cesses (DGPs): Probit or Em ulator. The Probit RUM generates c hoices from the exact MNP mo del, drawing errors ϵ i ∼ N ( 0 , Σ ) and selecting the utility-maximizing alternative. The Emulator RUM generates c hoices b y sampling directly from the categorical distribution defined by the em ulator’s predicted choice probabilities. When coupled with the Emulator R UM, the em ulator-based estimation metho d is correctly specified, enabling a comparison of em ulator-based estimators under both correct sp ecification (Em ulator RUM) and approximate inference (Probit R UM). Estimation. T o ensure p ositive definiteness of Σ , we estimate the Dense sp ecification on the scale of the Cholesky factor, with the diagonal elements optimized on the log scale to enforce p ositivit y . Similarly , we estimate the F actor sp ecification with the free uniquenesses on the log scale, optimizing log(Ψ j j ) for j = 2 , . . . , K − 1. 28 W e form estimators using t wo metho ds, Em ulator and GHK, corresp onding to whether w e appro ximate the log-likelihoo d function using a pretrained emulator or the GHK sim ulator. W e fit b oth metho ds to data generated by the Probit R UM; we also fit the Em ulator metho d to data generated by the Emulator R UM to analyze its p erformance under correct sp ecifica- tion. W e apply the GHK metho d with R ∈ { 10 , 50 , 250 } dra ws, representing low, mo derate, and high computational effort. Both metho ds, Emulator and GHK, p erform regularized maximum likelihoo d estimation. The regularization consists of t wo comp onen ts: a barrier p enalty and a pseudo-prior. The barrier p enalt y is applied to log(Ψ j j ) for the F actor sp ecification and to the log-diagonal Cholesky parameters for the Dense sp ecification. F or a latent parameter η , the barrier p enalt y is λ reg · log( η + 8) /n . The pseudo-prior terms take the form λ reg · log { p ( θ ) } /n , where p ( θ ) is the density function of θ under the data-generating pro cess. W e add these p enalties together to form a com bined penalty of the form λ reg · r ( θ ) /n , where r ( θ ) sums the barrier and log-prior p enalties and λ reg is a regularization h yp erparameter. W e then estimate θ as the maximizer of the sum of the (appro ximate) log lik eliho o d and λ reg · r ( θ ) /n . W e tak e λ reg = 0 . 1 so that the p enalty is small and asymptotically negligible. In practice, we find that these penalties lead to more reliable con vergence of the mo del-fitting algorithm and help address w eak iden tification of the cov ariance parameters that arises when K is large and n is small. W e accoun t for these p enalties in the standard error computation by estimating Co v( ˆ θ n ) as n · ˆ J n ( ˆ θ n ) − λ reg · ∇ 2 θ r ( ˆ θ n ) − 1 . Again, the impact of the p enalization is asymptotically negligible b ecause the term n · ˆ J n ( ˆ θ n ) dominates asymptotically . F or all metho ds, w e maximize the (approximate) regularized log likelihoo d using L-BFGS optimization ( Liu and Nocedal , 1989 ). In practice, w e found it necessary to limit the mini- m um step size (we used 10 − 6 ) and allo w small decreases in the ob jectiv e function to enable the optimizer to escap e lo cal minima. Exp erimen tal design. W e consider sample sizes n ∈ { 1 , 000 , 10 , 000 , 100 , 000 } and con- duct 100 replications for eac h configuration. W e compute p erformance metrics aggregated across all parameter types. W e compute Mon te Carlo standard errors for the cov erage and a verage timings using scaled empirical standard deviations. F or the remaining metrics, w e apply b o otstrap resampling (across rep etitions) with 1,000 b o otstrap samples to estimate the Mon te Carlo standard errors. Computational en vironmen t. All sim ulations were implemented in PyT orc h ( P aszk e et al. , 2019 ) and executed on a p ersonal laptop with 48 GB RAM and an Apple M4 Pro 29 pro cessor. W e fit the emulators using the Apple Metal P erformance Shaders (MPS). T o obtain comparable estimation timings, how ever, we p erformed the rest of the sim ulation on CPU. 6.2 Sim ulation Results W e fit the em ulators for 400 , 000 training episo des using 400 , 000 pregenerated training ex- amples, each consisting of 10 6 c hoices. Details on the optimizer, learning rate sc hedule, and net work arc hitecture are provided in App endix C.1 . This mo del-fitting pro cedure completed in 2.1, 4.6, and 16.6 hours for K = 3 , 5 , and 10, respectively , represen ting a mo dest level of computational effort. 10 0 10 1 10 2 10 3 10 4 10 5 Episode Number 10 − 6 10 − 5 10 − 4 10 − 3 10 − 2 10 − 1 10 0 Cross-Entrop y Loss T rain Ev al (a) K = 3 10 0 10 1 10 2 10 3 10 4 10 5 Episode Number 10 − 6 10 − 5 10 − 4 10 − 3 10 − 2 10 − 1 10 0 Cross-Entrop y Loss T rain Ev al (b) K = 5 10 0 10 1 10 2 10 3 10 4 10 5 Episode Number 10 − 6 10 − 5 10 − 4 10 − 3 10 − 2 10 − 1 10 0 Cross-Entrop y Loss T rain Ev al (c) K = 10 Figure 2: T raining and ev aluation loss o v er 400 , 000 training episodes for em ulators with K ∈ { 3 , 5 , 10 } alternativ es. The training loss (blue) decreases consistently throughout training, and the ev aluation loss (orange) closely trac ks the training loss, indicating that the emulators do not o verfit the simulated training data. Figure 2 displays the training and ev aluation loss for the emulators ov er time. A t eac h v alue of K ∈ { 3 , 5 , 10 } , the training loss decreases consisten tly ov er time even at the end of training, indicating that further training w ould lik ely lead to additional improv ements. The ev aluation loss closely tracks the training loss, implying that the emulator generalizes w ell with minimal ov erfitting to the simulated training probabilities. W e compute the ev aluation loss ev ery 200 episo des; these p erio dic calculations pro duce significan tly less visible v ariation in the ev aluation loss compared to the training loss. T able 2 displays p erformance metrics for K = 3 comparing the p erformance of the emulator and GHK estimation metho ds. The p erformance metrics are the ro ot mean squared error (RMSE), ro ot mean squared bias (RMS Bias), ratio of estimated to empirical standard errors (SE Ratio), 95% confidence in terv al cov erage rates (Cov erage), and elapsed mo del-fitting time in seconds (Time (s)). The emulator metho ds p erform w ell across all sample sizes, 30 n DGP Metho d RMSE RMS Bias SE Ratio Co v erage Time (s) 1,000 Em ulator Em ulator 0.159 (0.016) 0.010 (0.009) 1.00 (0.05) 0.94 (0.01) 0.11 (0.00) Probit Emulator 0.206 (0.032) 0.049 (0.018) 0.95 (0.08) 0.95 (0.01) 0.10 (0.00) Probit GHK(10) 0.202 (0.031) 0.047 (0.019) 0.96 (0.08) 0.94 (0.02) 0.08 (0.00) Probit GHK(50) 0.203 (0.032) 0.048 (0.018) 0.96 (0.09) 0.95 (0.01) 0.14 (0.00) Probit GHK(250) 0.207 (0.033) 0.049 (0.019) 0.95 (0.08) 0.95 (0.01) 0.41 (0.01) 10,000 Em ulator Em ulator 0.052 (0.006) 0.007 (0.004) 0.94 (0.07) 0.94 (0.01) 0.36 (0.00) Probit Emulator 0.053 (0.009) 0.008 (0.004) 0.99 (0.11) 0.94 (0.01) 0.36 (0.00) Probit GHK(10) 0.052 (0.008) 0.010 (0.003) 1.00 (0.09) 0.94 (0.01) 0.30 (0.00) Probit GHK(50) 0.052 (0.009) 0.007 (0.004) 1.00 (0.10) 0.95 (0.01) 0.44 (0.01) Probit GHK(250) 0.053 (0.009) 0.008 (0.005) 0.99 (0.11) 0.94 (0.01) 0.93 (0.01) 100,000 Em ulator Em ulator 0.015 (0.002) 0.001 (0.001) 0.97 (0.08) 0.94 (0.01) 1.80 (0.01) Probit Emulator 0.016 (0.002) 0.001 (0.001) 1.06 (0.07) 0.98 (0.01) 1.82 (0.02) Probit GHK(10) 0.020 (0.002) 0.007 (0.001) 0.83 (0.06) 0.83 (0.02) 0.90 (0.01) Probit GHK(50) 0.016 (0.002) 0.002 (0.001) 1.03 (0.08) 0.97 (0.01) 1.90 (0.02) Probit GHK(250) 0.016 (0.002) 0.001 (0.001) 1.06 (0.07) 0.98 (0.01) 7.22 (0.09) T able 2: Comparison of Emulat or and GHK estimation metho ds for m ultinomial probit mo dels with K = 3. The em ulator p erforms comp etitiv ely with GHK(50) and GHK(250) and requires computation time b etw een that of GHK(10) and GHK(50). Performance metrics are a v eraged across all parameters (co efficients, v ariances, and cov ariances) with Monte Carlo standard errors sho wn in parentheses. matc hing the p erformance of GHK(50) and GHK(250) in terms of statistical p erformance but at a low er computational cost. GHK(10) significantly undercov ers at n = 100 , 000, exhibiting substan tially higher RMS Bias than the other methods. This p o or p erformance is likely an artifact of the GHK sim ulator pro viding biased estimates on the log scale due to Jensen’s inequality; for sufficiently large n , this bias is even tually nonnegligible relativ e to 1 / √ n sampling error. T able 3 displays similar results for K = 5. The em ulator is comp etitiv e with GHK(50) and GHK(250) at all sample sizes. Compared to GHK(50), the compute time for the Emulator metho d is sligh tly lo wer for n = 1 , 000, approximately equal for n = 10 , 000, and slightly higher for n = 100 , 000. T able 4 displa ys p erformance results for K = 10. The em ulator performs comparably to GHK(250) with m uch low er computational requiremen ts. At n = 1 , 000, the emulator fits the mo del in less than 3 seconds on av erage, outpacing even GHK(10). The computation time of the em ulator falls betw een that of GHK(10) and GHK(50) at n = 10 , 000 and b etw een GHK(50) and GHK(250) at n = 100 , 000. Compared to T ables 2 and 3 , the standard error estimates are less reliable for the smaller sample sizes, presumably due to weak iden tification; the problem is amplified when we omit the p enalt y on Σ . The standard errors improv e 31 n DGP Metho d RMSE RMS Bias SE Ratio Co v erage Time (s) 1,000 Em ulator Em ulator 0.243 (0.017) 0.032 (0.012) 1.11 (0.06) 0.94 (0.01) 0.41 (0.01) Probit Emulator 0.281 (0.020) 0.045 (0.016) 1.04 (0.04) 0.93 (0.01) 0.42 (0.00) Probit GHK(10) 0.278 (0.015) 0.074 (0.017) 0.95 (0.03) 0.89 (0.01) 0.29 (0.00) Probit GHK(50) 0.280 (0.017) 0.051 (0.017) 1.02 (0.04) 0.92 (0.01) 0.62 (0.01) Probit GHK(250) 0.284 (0.020) 0.046 (0.017) 1.03 (0.04) 0.93 (0.01) 2.02 (0.03) 10,000 Em ulator Em ulator 0.086 (0.006) 0.010 (0.004) 0.99 (0.05) 0.95 (0.01) 2.27 (0.02) Probit Emulator 0.084 (0.005) 0.009 (0.004) 1.06 (0.04) 0.96 (0.01) 2.26 (0.02) Probit GHK(10) 0.095 (0.006) 0.032 (0.006) 0.88 (0.03) 0.89 (0.01) 0.89 (0.01) Probit GHK(50) 0.086 (0.006) 0.013 (0.005) 1.02 (0.04) 0.95 (0.01) 2.27 (0.03) Probit GHK(250) 0.084 (0.005) 0.009 (0.004) 1.06 (0.04) 0.96 (0.01) 4.95 (0.05) 100,000 Em ulator Em ulator 0.028 (0.004) 0.003 (0.001) 0.97 (0.09) 0.95 (0.01) 18.09 (0.15) Probit Emulator 0.028 (0.002) 0.002 (0.001) 1.00 (0.06) 0.95 (0.01) 18.30 (0.17) Probit GHK(10) 0.056 (0.004) 0.024 (0.003) 0.49 (0.02) 0.60 (0.02) 3.75 (0.03) Probit GHK(50) 0.030 (0.002) 0.004 (0.002) 0.93 (0.05) 0.92 (0.01) 9.45 (0.11) Probit GHK(250) 0.028 (0.002) 0.002 (0.001) 1.00 (0.06) 0.95 (0.01) 42.96 (0.49) T able 3: Comparison of Emulat or and GHK estimation metho ds for m ultinomial probit mo dels with K = 5. As in T able 2 , the emulator p erforms comp etitively with GHK(50) and GHK(250) at a comparable or lo wer computational cost. n DGP Metho d RMSE RMS Bias SE Ratio Co v erage Time (s) 1,000 Em ulator Em ulator 0.324 (0.014) 0.195 (0.011) 1.56 (0.14) 0.93 (0.01) 2.24 (0.02) Probit Emulator 0.343 (0.016) 0.207 (0.012) 1.71 (0.24) 0.93 (0.01) 2.21 (0.02) Probit GHK(10) 0.388 (0.017) 0.217 (0.013) 0.35 (0.07) 0.22 (0.02) 5.86 (0.30) Probit GHK(50) 0.363 (0.016) 0.215 (0.013) 0.70 (0.07) 0.54 (0.03) 14.16 (0.95) Probit GHK(250) 0.351 (0.017) 0.214 (0.012) 1.43 (0.11) 0.91 (0.01) 14.87 (0.41) 10,000 Em ulator Em ulator 0.172 (0.010) 0.073 (0.007) 1.74 (0.19) 0.96 (0.01) 19.28 (0.26) Probit Emulator 0.200 (0.011) 0.080 (0.010) 1.81 (0.20) 0.95 (0.01) 19.04 (0.19) Probit GHK(10) 0.236 (0.014) 0.123 (0.010) 1.57 (0.52) 0.79 (0.02) 8.95 (0.30) Probit GHK(50) 0.203 (0.010) 0.090 (0.010) 1.29 (0.07) 0.91 (0.01) 33.54 (0.83) Probit GHK(250) 0.198 (0.010) 0.079 (0.010) 1.41 (0.07) 0.95 (0.01) 50.22 (0.70) 100,000 Em ulator Em ulator 0.069 (0.004) 0.013 (0.003) 1.07 (0.05) 0.95 (0.01) 165.59 (1.15) Probit Emulator 0.082 (0.005) 0.020 (0.004) 0.92 (0.03) 0.93 (0.01) 164.88 (1.49) Probit GHK(10) 0.139 (0.009) 0.073 (0.006) 0.48 (0.02) 0.60 (0.01) 31.48 (0.35) Probit GHK(50) 0.085 (0.005) 0.027 (0.004) 0.89 (0.03) 0.90 (0.01) 93.23 (0.98) Probit GHK(250) 0.081 (0.005) 0.020 (0.004) 0.97 (0.03) 0.93 (0.01) 404.22 (5.59) T able 4: Comparison of Emulat or and GHK estimation metho ds for m ultinomial probit mo dels with K = 10. The emulator p erforms comparably to GHK(250) in terms of statistical p erformance but requires far less computation time. Compare to T ables 2 and 3 . 32 substan tially with the sample size (with or without p enalization), reaching SE Ratios of 0.92–1.07 for the Em ulator and GHK(250) metho ds at n = 100 , 000. n DGP Metho d RMSE RMS Bias SE Ratio Co v erage Time (s) 1,000 Em ulator Em ulator 0.089 (0.004) 0.022 (0.006) 1.18 (0.05) 0.95 (0.01) 0.11 (0.00) Probit Emulator 0.095 (0.004) 0.007 (0.005) 1.10 (0.04) 0.96 (0.01) 0.10 (0.00) Probit GHK(10) 0.096 (0.004) 0.011 (0.005) 1.08 (0.04) 0.96 (0.01) 0.08 (0.00) Probit GHK(50) 0.094 (0.004) 0.007 (0.005) 1.11 (0.04) 0.96 (0.01) 0.15 (0.00) Probit GHK(250) 0.095 (0.004) 0.007 (0.005) 1.10 (0.04) 0.96 (0.01) 0.42 (0.01) 10,000 Em ulator Em ulator 0.038 (0.002) 0.003 (0.002) 0.99 (0.04) 0.93 (0.01) 0.39 (0.01) Probit Emulator 0.038 (0.002) 0.007 (0.003) 1.00 (0.05) 0.96 (0.01) 0.38 (0.00) Probit GHK(10) 0.040 (0.002) 0.013 (0.002) 0.99 (0.05) 0.95 (0.01) 0.33 (0.00) Probit GHK(50) 0.038 (0.002) 0.008 (0.003) 1.00 (0.05) 0.96 (0.01) 0.48 (0.01) Probit GHK(250) 0.038 (0.002) 0.007 (0.003) 1.00 (0.05) 0.95 (0.01) 0.96 (0.01) 100,000 Em ulator Em ulator 0.011 (0.001) 0.001 (0.001) 1.08 (0.05) 0.96 (0.01) 1.97 (0.02) Probit Emulator 0.011 (0.001) 0.001 (0.001) 1.04 (0.04) 0.96 (0.01) 1.91 (0.01) Probit GHK(10) 0.016 (0.001) 0.009 (0.001) 0.88 (0.04) 0.82 (0.02) 0.98 (0.01) Probit GHK(50) 0.012 (0.001) 0.002 (0.001) 1.04 (0.04) 0.95 (0.01) 2.07 (0.03) Probit GHK(250) 0.011 (0.001) 0.001 (0.001) 1.04 (0.05) 0.96 (0.01) 7.52 (0.09) T able 5: Comparison of Emulator and GHK estimation metho ds for factor-structured multi- nomial probit mo dels with K = 3. P erformance metrics are a veraged ov er the factor param- eters (co efficients, uniquenesses, and factor loadings). The Em ulator’s performance mirrors that of GHK(250) at a m uch low er computational cost. T able 5 displa ys analogous results for the F actor sp ecification with K = 3. Performance metrics are av eraged o ver the nonredundan t elemen ts of β , Ψ , and γ . The Emulator’s p erformance mirrors that of GHK(250) but at a m uch low er computational cost. T ables 6 and 7 displa y analogous results for 5 and 10 alternatives, resp ectiv ely . In b oth cases, the Em ulator performs comparably to GHK(50) and GHK(250) despite not b eing trained sp ecifically for factor mo dels. The Emulator is faster than GHK(50) for n ∈ { 1 , 000 , 10 , 000 } . A t n = 100 , 000, the Emulator’s computation time falls b etw een that of GHK(50) and GHK(250). Across all scenarios, the Emulator metho d p erforms comp etitively with or significan tly b etter than GHK. W e exp ect that the relative p erformance of the emulator would increase with (a) additional training and (b) implemen tation on sp ecialized deep-learning hardware, such as GPUs. The latter is likely to b e esp ecially adv antageous for the em ulator b ecause its computations are trivially parallelizable and highly optimized on mo dern GPUs. 33 n DGP Metho d RMSE RMS Bias SE Ratio Co v erage Time (s) 1,000 Em ulator Em ulator 0.128 (0.004) 0.016 (0.005) 1.20 (0.04) 0.97 (0.01) 0.32 (0.01) Probit Emulator 0.131 (0.003) 0.012 (0.004) 1.19 (0.03) 0.97 (0.01) 0.32 (0.00) Probit GHK(10) 0.134 (0.004) 0.017 (0.005) 1.12 (0.03) 0.95 (0.01) 0.23 (0.00) Probit GHK(50) 0.131 (0.003) 0.012 (0.004) 1.19 (0.03) 0.98 (0.01) 0.49 (0.01) Probit GHK(250) 0.132 (0.003) 0.012 (0.004) 1.19 (0.03) 0.97 (0.01) 1.61 (0.02) 10,000 Em ulator Em ulator 0.059 (0.002) 0.007 (0.003) 1.01 (0.04) 0.95 (0.01) 1.92 (0.02) Probit Emulator 0.059 (0.003) 0.005 (0.002) 1.04 (0.04) 0.95 (0.01) 1.97 (0.02) Probit GHK(10) 0.062 (0.003) 0.011 (0.003) 0.93 (0.04) 0.93 (0.01) 0.77 (0.01) Probit GHK(50) 0.059 (0.003) 0.004 (0.003) 1.02 (0.04) 0.95 (0.01) 2.02 (0.03) Probit GHK(250) 0.059 (0.003) 0.007 (0.003) 1.04 (0.04) 0.95 (0.01) 4.67 (0.08) 100,000 Em ulator Em ulator 0.019 (0.001) 0.002 (0.001) 1.02 (0.03) 0.96 (0.01) 15.46 (0.18) Probit Emulator 0.020 (0.001) 0.006 (0.001) 1.04 (0.03) 0.94 (0.01) 15.58 (0.18) Probit GHK(10) 0.029 (0.001) 0.017 (0.001) 0.75 (0.03) 0.75 (0.02) 3.21 (0.04) Probit GHK(50) 0.019 (0.001) 0.004 (0.001) 1.02 (0.03) 0.95 (0.01) 8.47 (0.12) Probit GHK(250) 0.019 (0.001) 0.002 (0.001) 1.04 (0.03) 0.96 (0.01) 37.30 (0.59) T able 6: Comparison of Emulator and GHK estimation metho ds for factor-structured multi- nomial probit mo dels with K = 5. As in T able 5 , the emulator p erforms comp etitively with GHK(50) and GHK(250) at a comparable or low er computational cost. n DGP Metho d RMSE RMS Bias SE Ratio Co v erage Time (s) 1,000 Em ulator Em ulator 0.188 (0.004) 0.023 (0.004) 1.14 (0.02) 0.96 (0.00) 1.06 (0.01) Probit Emulator 0.198 (0.005) 0.030 (0.005) 1.10 (0.02) 0.96 (0.01) 1.01 (0.01) Probit GHK(10) 0.220 (0.005) 0.059 (0.006) 0.92 (0.02) 0.90 (0.01) 0.77 (0.01) Probit GHK(50) 0.205 (0.005) 0.039 (0.005) 1.06 (0.02) 0.95 (0.01) 2.44 (0.03) Probit GHK(250) 0.199 (0.005) 0.030 (0.005) 1.11 (0.02) 0.96 (0.01) 5.93 (0.08) 10,000 Em ulator Em ulator 0.080 (0.002) 0.011 (0.003) 1.24 (0.04) 0.98 (0.00) 7.58 (0.06) Probit Emulator 0.082 (0.002) 0.012 (0.003) 1.22 (0.04) 0.97 (0.01) 7.48 (0.06) Probit GHK(10) 0.103 (0.002) 0.049 (0.003) 0.95 (0.03) 0.88 (0.01) 4.03 (0.04) Probit GHK(50) 0.087 (0.002) 0.019 (0.003) 1.14 (0.04) 0.96 (0.01) 14.83 (0.16) Probit GHK(250) 0.084 (0.002) 0.012 (0.003) 1.20 (0.04) 0.97 (0.01) 24.85 (0.25) 100,000 Em ulator Em ulator 0.043 (0.002) 0.004 (0.002) 0.94 (0.04) 0.93 (0.01) 69.83 (0.57) Probit Emulator 0.036 (0.001) 0.004 (0.001) 1.11 (0.04) 0.97 (0.01) 69.05 (0.66) Probit GHK(10) 0.071 (0.002) 0.047 (0.002) 0.65 (0.02) 0.60 (0.02) 19.73 (0.20) Probit GHK(50) 0.039 (0.001) 0.012 (0.001) 1.04 (0.04) 0.93 (0.01) 55.94 (0.75) Probit GHK(250) 0.036 (0.001) 0.004 (0.001) 1.12 (0.05) 0.96 (0.01) 218.97 (2.94) T able 7: Comparison of Emulator and GHK estimation metho ds for factor-structured multi- nomial probit mo dels with K = 10. The emulator p erforms comparably to GHK(250) in terms of statistical p erformance but requires far less computation time. Compare to T ables 5 and 6 . 34 6.3 Multi- K T raining Accuracy W e conclude this section b y providing numerical results from training a neural net work em ulator to appro ximate c hoice probabilities for K ∈ { 3 , 4 , 5 } sim ultaneously . W e use the same neural net w ork as w e used in the previous section for K = 5. As ab ov e, we train for 400 , 000 episo des, but we lo op ov er training examples with K = 3, 4, and 5 alternatives within eac h episo de. The training pro cess completes in 13.0 hours. 10 0 10 1 10 2 10 3 10 4 10 5 Episo de Num b er 10 − 6 10 − 5 10 − 4 10 − 3 10 − 2 10 − 1 10 0 Cross-En tropy Loss T rain Ev al (a) T raining Loss 0 . 00 0 . 25 0 . 50 0 . 75 1 . 00 Estimated Probability ( ˆ P ) − 0 . 010 − 0 . 005 0 . 000 0 . 005 0 . 010 Estimation Error ( P − ˆ P ) K=3 K=4 K=5 (b) Estimation Accuracy Figure 3: (a) T raining and ev aluation loss ov er 400 , 000 training episo des for em ulators with K ∈ { 3 , 4 , 5 } alternatives. The training loss (blue) decreases consistently throughout training, and the ev aluation loss (orange) closely trac ks the training loss, indicating minimal o verfitting. (b) Em ulator probabilit y estimates compared to estimation errors. The emulator sim ultaneously learns the choice probabilities for K = 3 , 4 , 5 with small error. Figure 3a shows the training and ev aluation loss steadily decreasing throughout the training pro cedure, approac hing levels similar to those of Figure 2 . Figure 3b plots the estimated c hoice probabilities against estimation errors for K ∈ { 3 , 4 , 5 } with 400 simulated exam- ples each. The small errors indicate that the mo del accurately appro ximates the choice probabilities across all three v alues of K simultaneously . 7 Conclusion This pap er prop oses an amortized inference approach for discrete c hoice mo dels. The ap- proac h uses a nov el neural net work arc hitecture to appro ximate c hoice probabilities under general error distributions, including those featuring non trivial cross-alternativ e correlations, 35 suc h as MNP mo dels. This generalit y enables flexible mo deling of empirical choice behav- ior, including complex substitution patterns, without losing the theoretical grounding or in terpretability of RUM mo dels. Because the emulator op erates on the generic c hoice problem, it is agnostic to the assumed parametric form of the deterministic utilities or the accompanying scale (co v ariance) matrix. Giv en a pretrained em ulator, this generality enables drop-in adoption without the need for custom arc hitecture c hanges or additional training. In particular, generalizing from logit to probit requires only the replacement of closed-form softmax probabilities with emulator ev aluations. Other correlated error distributions are similarly straigh tforward. Our prop osed arc hitecture and training pro cess feature a prepro cessing transformation, DeepSet mo dules ( Zaheer et al. , 2017 ), equiv arian t lay ers, smo oth activ ation functions, and Sob olev training ( Czarnec ki et al. , 2017 ). T ogether, these design choices pro duce smo oth appro ximations of choice probabilities that resp ect their in v ariance prop erties and accelerate learning via parameter sharing. W e show that the arc hitecture p ossesses a universal appro x- imation property , extending recen t theoretical results for symmetric matrices ( Blum-Smith et al. , 2025 ) to the join t space of utility vectors and cen tered scale (co v ariance) matrices. In Monte Carlo sim ulations, w e find that em ulator-based estimators p erform as well or better than GHK-based estimators in terms of b oth statistical p erformance and computational requiremen ts when estimating MNP mo dels. These findings supp ort our theoretical results sho wing that emulator-based estimators inherit the prop erties of exact MLEs under mild appro ximation conditions. W e fo cus on MNP mo dels in the sim ulation study to enable comparison to the GHK simulator, whic h is directly applicable only to Gaussian errors. The computational b enefits of the amortized inference approac h are amplified by the fact that em ulator ev aluations are trivially parallelizable and highly optimized on mo dern deep learning hardw are, such as GPUs. Sev eral limitations merit discussion. Practitioners must ensure sufficien t o verlap b etw een the distribution of inputs in their application and the training distribution. Additionally , our asymptotic theory requires the emulator appro ximation error to v anish at an appropriate rate, meaning applications with very large samples may require more extensively trained em ulators. Lastly , mo dels with correlated errors require iden tifying restrictions not needed for indep endent logit-based mo dels. Although our approac h enables simple and efficient computation of choice probabilities for these mo dels, the data requirements and mo deling decisions to ensure prop er iden tification remain a separate challenge. 36 The framew ork also allo ws n umerous extensions. Our emulator architecture and training pro cedure could b e sp ecialized to sp ecific settings, such as factor-structured scale matrices or mixture distributions. W e exp ect these could b e handled b y reconfiguring the mo dules in our arc hitecture and, in some cases, generalizing the prepro cessing transformation. In particular, the t w o preceding examples would lik ely require an additional DeepSet op eration o ver factors or mixture comp onents. Our emulators could also b e used in tandem with other mo dern choice mo deling arc hitectures, suc h as those describ ed in Section 2 . Previous work has applied neural-net work-assisted estimation approaches to other econometric models with in tractable lik eliho o d functions, suc h as dynamic discrete choice ( Norets , 2012 ) and consumer searc h ( W ei and Jiang , 2025 ), in the context of specific parametric models. The amortized inference approac h presen ted here could likely b e generalized to man y of these settings, enabling efficien t amortized inference without mo difying or retraining the neural netw ork. Ac kno wle dgmen ts The authors ackno wledge the use of AI to ols to assist in the developmen t of this manuscript. All con tent has b een manually reviewed for accuracy . 37 References Aouad, A. and Desir, A. (2025). Represen ting random utilit y c hoice mo dels with n ueral net works. Management Scienc e , Articles in Adv ance. Bagheri, N., Ghasri, M., and Barlow, M. (2025). A neural estimation framework for discrete c hoice mo dels with arbitrary error distributions. Journal of Choic e Mo del ling , 57:100583. Ben tz, Y. and Merunk a, D. (2000). Neural netw orks and the m ultinomial logit for brand c hoice mo delling: a hybrid approach. Journal of F or e c asting , 19(3):177–200. Berb eglia, G. and V enk ataraman, A. (2025). The generalized stochastic preference c hoice mo del. arXiv pr eprint arXiv:1803.04244 . Blo c h, H. and Marsc hak, J. (1960). Sto c hastic rationality and revealed stochastic preference. In Contributions to pr ob ability and Statistics . Stanford Universit y Press. Blum-Smith, B., Huang, N. T., Cuturi, M., and Villar, S. (2025). F unctions on symmetric matrices and point clouds via ligh t weigh t in v ariant features from Galois theory . SIAM Journal on Applie d A lgebr a and Ge ometry , 9(4):902–938. Bredon, G. E. (1972). Intr o duction to Comp act T r ansformation Gr oups , volume 46. Academic Press, New Y ork. Cai, Z., W ang, H., T alluri, K., and Li, X. (2022). Deep learning for choice mo deling. arXiv pr eprint arXiv:2208.09325 . Chen, N., Gallego, G., and T ang, Z. (2025). The use of binary choice forests to mo del and estimate discrete c hoices. arXiv pr eprint arXiv:1908.01109 . Chen, Y.-C. and Mi ˇ si´ c, V. V. (2022). Decision forest: A nonparametric approach to mo deling irrational c hoice. Management Scienc e (INF ORMS) , 68(10):7090–7111. Co cola, J. and Hand, P . (2020). Global conv ergence of Sob olev training for ov erparameterized neural net works. In International Confer enc e on Machine L e arning, Optimization, and Data Scienc e , pages 574–586. Springer. Cranmer, K., Brehmer, J., and Loupp e, G. (2020). The frontier of simulation-based inference. Pr o c e e dings of the National A c ademy of Scienc es , 117(48):30055–30062. Cyb enk o, G. (1989). Appro ximation by sup erp ositions of a sigmoidal function. Mathematics of Contr ol, Signals and Systems , 2(4):303–314. 38 Czarnec ki, W. M., Osindero, S., Jaderb erg, M., Swirszcz, G., and P ascan u, R. (2017). Sob olev training for neural netw orks. In A dvanc es in Neur al Information Pr o c essing Sys- tems , v olume 30, pages 4278–4287. De Ryck, T., Lanthaler, S., and Mishra, S. (2021). On the approximation of functions b y tanh neural net works. Neur al Networks , 143:732–750. Dugas, C., Bengio, Y., B´ elisle, F., Nadeau, C., and Garcia, R. (2000). Incorp orating second- order functional kno wledge for b etter option pricing. In Leen, T., Dietterich, T., and T resp, V., editors, A dvanc es in Neur al Information Pr o c essing Systems , v olume 13. MIT Press. E, W. and W ang, Q. (2018). Exp onential con vergence of the deep neural netw ork approxi- mation for analytic functions. Scienc e China Mathematics , 61(10):1733–1740. F arrell, M. H., Liang, T., and Misra, S. (2021). Deep neural netw orks for estimation and inference. Ec onometric a , 89(1):181–213. Gew eke, J. (1989). Bay esian inference in econometric mo dels using Monte Carlo in tegration. Ec onometric a , 57(6):1317–1339. Ha jiv assiliou, V. A. and McF adden, D. L. (1998). The metho d of sim ulated scores for the estimation of LD V mo dels. Ec onometric a , 66(4):863–896. Han, Y., Pereira, F. C., Ben-Akiv a, M., and Zegras, C. (2022). A neural-embedded choice mo del: Learning taste representation with strengthened. T r ansp ortation R ese ar ch B , 163:166–186. Hornik, K., Stinchcom b e, M., and White, H. (1989). Multilay er feedforw ard netw orks are univ ersal approximators. Neur al Networks , 2(5):359–366. Hrusc hk a, H. (2007). Using a heterogeneous m ultinomial probit model with a neural net extension to mo del brand c hoice. Journal of F or e c asting , 26(2):113–127. Jang, E., Gu, S., and Poole, B. (2017). Categorical reparameterization with Gum b el– softmax. In International Confer enc e on L e arning R epr esentations . Jiang, Z., Li, J., and Zhang, D. (2025). A high-dimensional c hoice mo del for online retailing. Management Scienc e (INF ORMS) , 71(4):3320–3339. Keane, M. P . (1992). A note on iden tification in the m ultinomial probit mo del. Journal of Business & Ec onomic Statistics , 10(2):193–200. 39 Keane, M. P . (1994). A computationally practical sim ulation estimator for panel data. Ec onometric a , 62(1):95–116. Kingma, D. P . and Ba, J. L. (2015). Adam: A metho d for sto chastic optimization. In International Confer enc e on L e arning R epr esentations . Lh ´ eritier, A., Bo camazo, M., Delaha ye, T., and Acuna-Agost, R. (2019). Airline itinerary c hoice mo deling using mac hine learning. Journal of Choic e Mo del ling , 31:198–209. Liu, D. C. and Nocedal, J. (1989). On the limited memory BFGS metho d for large scale optimization. Mathematic al Pr o gr amming , 45(1):503–528. Loshc hilov, I. and Hutter, F. (2019). Decoupled w eight deca y regularization. In International Confer enc e on L e arning R epr esentations . Luec kmann, J.-M., Bassetto, G., Karaletsos, T., and Mac ke, J. H. (2019). Lik eliho o d-free inference with emulator netw orks. In Ruiz, F., Zhang, C., Liang, D., and Bui, T., edi- tors, Pr o c e e dings of The 1st Symp osium on A dvanc es in Appr oximate Bayesian Infer enc e , v olume 96 of Pr o c e e dings of Machine L e arning R ese ar ch , pages 32–53. PMLR. Maddison, C. J., Mnih, A., and T eh, Y. W. (2017). The concrete distribution: A con tin- uous relaxation of discrete random v ariables. In International Confer enc e on L e arning R epr esentations . McCullo c h, R. and Rossi, P . E. (1994). An exact likelihoo d analysis of the m ultinomial probit mo del. Journal of Ec onometrics , 64(1):207–240. McF adden, D. (1974). Conditional logit analysis of qualitative choice b ehavior. In Zarem bk a, P ., editor, F r ontiers in Ec onometrics , pages 105–142. Academic Press, New Y ork. McF adden, D. and Rich ter, M. (1990). Sto chastic rationalit y and rev ealed sto c hastic pref- erence. In Pr efer enc es, Unc ertainty, and Optimality: Essays in Honor of L e o Hurwicz . W estview Press. McF adden, D. and T rain, K. (2000). Mixed mnl mo dels for discrete resp onse. Journal of Applie d Ec onometrics , 15(5):447–470. Mit yagin, B. S. (2020). The zero set of a real analytic function. Mathematic al Notes , 107(3):529–530. 40 Mnih, V., Kavuk cuoglu, K., Silver, D., Rusu, A. A., V eness, J., Bellemare, M. G., Grav es, A., Riedmiller, M., Fidjeland, A. K., Ostrovski, G., Petersen, S., Beattie, C., Sadik, A., An tonoglou, I., King, H., Kumaran, D., Wierstra, D., Legg, S., and Hassabis, D. (2015). Human-lev el control through deep reinforcement learning. Natur e , 518(7540):529–533. New ey , W. K. and McF adden, D. (1994). Large sample estimation and hypothesis testing. In Engle, R. F. and McF adden, D. L., editors, Handb o ok of Ec onometrics , v olume 4, pages 2111–2245. Elsevier. Norets, A. (2012). Estimation of dynamic discrete choice models using artificial neural net work approximations. Ec onometric R eviews , 31(1):84–106. P aszke, A., Gross, S., Massa, F., Lerer, A., Bradbury , J., Chanan, G., Killeen, T., Lin, Z., Gimelshein, N., An tiga, L., et al. (2019). PyT orch: An imp erative st yle, high-p erformance deep learning library . A dvanc es in Neur al Information Pr o c essing Systems , 32. Pfannsc hmidt, K., Gupta, P ., Haddenhorst, B., and H ¨ ullermeier, E. (2022). Learning con text-dep enden t choice functions. International Journal of Appr oximate R e asoning , 140:116–155. Ramac handran, P ., Zoph, B., and Le, Q. V. (2018). Searching for activ ation functions. In International Confer enc e on L e arning R epr esentations . Rosenfeld, N., Oshiba, K., and Singer, Y. (2020). Predicting choice with set-dep enden t aggregation. In I I I, H. D. and Singh, A., editors, Pr o c e e dings of the 37th International Confer enc e on Machine L e arning , v olume 119 of Pr o c e e dings of Machine L e arning R e- se ar ch , pages 8220–8229. PMLR. Sc hmidt-Hieb er, J. (2020). Nonparametric regression using deep neural net w orks with ReLU activ ation function. The A nnals of Statistics , 48(4):1875–1897. Segol, N. and Lipman, Y. (2020). On univ ersal equiv arian t set net w orks. In International Confer enc e on L e arning R epr esentations . Shen, X., Jiang, C., Sakhanenko, L., and Lu, Q. (2023). Asymptotic prop erties of neural net work sieve estimators. Journal of Nonp ar ametric Statistics , 35(4):839–868. PMID: 38169985. Sifringer, B., Lurkin, V., and Alahi, A. (2020). Enhancing discrete choice mo dels with represen tation learning. T r ansp ortation R ese ar ch Part B: Metho dolo gic al , 140:236–261. 41 Singh, A., Liu, Y., and Y oganarasimhan, H. (2023). Choice mo dels and p erm utation in v ariance: Demand estimation in differen tiated products mark ets. arXiv pr eprint arXiv:2307.07090 . T rain, K. E. (2009). Discr ete Choic e Metho ds with Simulation . Cambridge Universit y Press, Cam bridge, 2nd edition. v an der V aart, A. W. (1998). Asymptotic Statistics . Cam bridge Series in Statistical and Probabilistic Mathematics. Cam bridge Universit y Press, Cam bridge, UK. W ang, F. and Ross, C. L. (2018). Mac hine learning trav el mo de c hoices: Comparing the p erformance of an extreme gradient b o osting mo del with a multinomial logit model. T r ans- p ortation R ese ar ch R e c or d , 2672(47):35–45. W ang, S., Mo, B., and Zhao, J. (2020). Deep neural netw orks for choice analysis: Arc hi- tecture design with alternative-specific utilit y functions. T r ansp ortation R ese ar ch Part C: Emer ging T e chnolo gies , 112:234–251. W ang, S., Mo, B., and Zhao, J. (2021). Theory-based residual neural net works: A synergy of discrete choice mo dels and deep neural netw orks. T r ansp ortation R ese ar ch Part B: Metho dolo gic al , 146:333–358. W ei, Y. M. and Jiang, Z. (2025). Estimating parameters of structural models using neural net works. Marketing Scienc e , 44(1):102–128. White, H. (1982). Maximum lik eliho o d estimation of missp ecified mo dels. Ec onometric a , 50(1):1–25. W ong, M. and F aro o q, B. (2021). Reslogit: A residual neural netw ork logit mo del for data-driv en choice mo delling. T r ansp ortation R ese ar ch Part C: Emer ging T e chnolo gies , 126:103050. Zaheer, M., Kottur, S., Rav an bakhsh, S., Poczos, B., Salakh utdinov, R. R., and Smola, A. J. (2017). Deep sets. In A dvanc es in Neur al Information Pr o c essing Systems , volume 30. 42 Supplemen tary Materials for “Amortized Inference for Correlated Discrete Choice Mo dels via Equiv arian t Neural Net w orks” Easton Huc h P ostdo ctoral F ellow, Johns Hopkins Carey Business Sc ho ol Mic hael Keane Carey Distinguished Professor, Johns Hopkins Carey Business School App endix A presen ts results and pro ofs regarding generic separation and universal approxi- mation. Section A.8 prov es the results giv en in Section 5.1 . App endix B provides pro ofs of the estimation theory results in Section 5.2 . App endix C pro vides details on the sim ulation study . A Generic Separation and Univ ersal Appro ximation This app endix develops the group-theoretic foundations underlying the p er-alternative en- co der arc hitecture presented in the main text. W e establish that certain in v ariants generically separate orbits under p erm utation groups, yielding univ ersal appro ximation results via the Stone–W eierstrass theorem. Let S K denote the space of symmetric real-v alued K × K matrices. W e consider an extended group G K acting on S K b y p erm utation, scaling, and translation by matrices in the n ull space of double-cen tering. Section A.1 in tro duces the necessary notation and establishes basic prop erties of the cen tering matrix and the normalized double-centering function f . Sections A.2 – A.4 establish that the comp osition h = g ◦ f , which first applies normalized double-cen tering and then extracts m ultisets of diagonal and off-diagonal elements, generi- cally separates G K -orbits. The exceptional set where separation fails is closed, G K -in v ariant, and has measure zero. Section A.5 considers the restriction to the cen tered, trace-normalized subspace S ∗ K = Im( f ), where g generically separates S K -orbits and the Stone–W eierstrass theorem yields universal A-1 appro ximation. Section A.6 develops a v arian t for a distinguished index j , showing that an inv arian t g j generically separates orbits under S ( j ) K − 1 , the subgroup fixing j . Sections A.7 – A.8 extend the theory to incorp orate deterministic utilities, culminating in pro ofs of Theorem 1 and Theorem 2 from the main text. Throughout, X and Y represent scale matrices. As in Section 4.3 , we sometimes refer to these mat rices as co v ariance matrices although this in terpretation is not strictly correct outside of MNP mo dels. A.1 Preliminaries Throughout, let K ≥ 2 b e the n umber of alternativ es. Let I K denote the K × K identit y matrix and 1 K ∈ R K the v ector of all ones. Definition 1 (Cen tering Matrix) . The c entering matrix M ∈ R K × K is defined as M = I K − 1 K 1 K 1 ⊤ K . Prop osition 2 (Prop erties of the Centering Matrix) . The c entering matrix M is symmetric ( M ⊤ = M ), idemp otent ( M 2 = M ), and annihilates c onstant ve ctors ( M1 K = 0 ). Pr o of. Symmetry is immediate. F or idemp otency , M 2 = I K − 2 K 1 K 1 ⊤ K + 1 K 2 1 K ( 1 ⊤ K 1 K ) 1 ⊤ K = I K − 2 K 1 K 1 ⊤ K + 1 K 1 K 1 ⊤ K = M . Finally , M1 K = 1 K − 1 K 1 K ( 1 ⊤ K 1 K ) = 1 K − 1 K = 0 . Definition 2 (Double-Cen tering F unction) . Define the domain U = { X ∈ S K : tr( MXM ) = 0 } and the function f : U → S K b y f ( X ) = K · MXM tr( MXM ) . Prop osition 3 (Explicit F orm ula) . F or X ∈ S K , let ¯ X i • = 1 K P K k =1 X ik , ¯ X • j = 1 K P K k =1 X kj , and ¯ X •• = 1 K 2 P i,j X ij . Then: (i) [ MXM ] ij = X ij − ¯ X i • − ¯ X • j + ¯ X •• . (ii) tr( MXM ) = tr( X ) − K ¯ X •• . Pr o of. P art (i) follo ws b y direct expansion. F or part (ii), use idemp otency and the cyclic prop ert y of trace: tr( MXM ) = tr( M 2 X ) = tr( MX ) = tr( X ) − 1 K 1 ⊤ K X1 K = tr( X ) − K ¯ X •• . A-2 Prop osition 4 (Domain Prop erties) . The set S K \ U = { X ∈ S K : tr( MXM ) = 0 } is a hyp erplane in S K with L eb esgue me asur e zer o. The domain U is op en and G K -invariant. Pr o of. By Prop osition 3 (ii), tr( MXM ) is a nontrivial linear function, so its zero set is a measure-zero h yp erplane. Op enness follows from contin uit y . F or G K -in v ariance: scaling b y c = 0 gives tr( M ( c X ) M ) = c tr( MXM ) = 0; null-space translation by N = u 1 ⊤ K + 1 K u ⊤ satisfies MNM = 0 since M1 K = 0 ; p ermutation preserv es the trace b y the cyclic prop ert y . Definition 3 (Extended Group Action) . Let S K denote the symmetric group on K elements with asso ciated p erm utation matrices P π , and let R ∗ = R \ { 0 } . Define the extended group G K = R K ⋊ ( R ∗ × S K ), whic h acts on S K b y: ( c, u , π ) · X = c P π XP ⊤ π + u 1 ⊤ K + 1 K u ⊤ . Prop osition 5 ( f and G K ) . The function f satisfies: (i) Equivarianc e under p ermutation: f ( P π XP ⊤ π ) = P π f ( X ) P ⊤ π . (ii) Invarianc e under sc aling: f ( c X ) = f ( X ) for c = 0 . (iii) Invarianc e under nul l-sp ac e tr anslation: f ( X + u 1 ⊤ K + 1 K u ⊤ ) = f ( X ) . Pr o of. F or (i), since P π 1 K = 1 K , we ha ve P π M = MP π , so M ( P π XP ⊤ π ) M = P π MXMP ⊤ π , and the trace is preserved. P art (ii) follows from f ( c X ) = cK MXM c · tr( MXM ) = f ( X ). F or (iii), M ( u 1 ⊤ K + 1 K u ⊤ ) M = 0 since M1 K = 0 . Lemma 1 (Preimage Characterization) . If f ( X ) = f ( Y ) for X , Y ∈ U , then ther e exist c ∈ R ∗ and w ∈ R K such that X = c Y + w 1 ⊤ K + 1 K w ⊤ . Pr o of. Let t X = tr( MXM ) and t Y = tr( MY M ). The assumption f ( X ) = f ( Y ) implies MXM = c MY M where c = t X /t Y ∈ R ∗ . F or symmetric Z , let µ Z = Z1 K /K (ro w av erages) and m Z = 1 ⊤ K Z1 K /K 2 (grand mean). Expanding MZM = Z − µ Z 1 ⊤ K − 1 K µ ⊤ Z + m Z 1 K 1 ⊤ K and applying to b oth sides: X = c Y + ( µ X − c µ Y ) 1 ⊤ K + 1 K ( µ X − c µ Y ) ⊤ − ( m X − cm Y ) 1 K 1 ⊤ K . Setting w = µ X − c µ Y − m X − cm Y 2 1 K giv es the result. A-3 Definition 4 (Centered, T race-Normalized Subspace) . Define S ∗ K = { Y ∈ S K : Y 1 K = 0 , tr( Y ) = K } . Definition 5 (In v ariant F unction g ) . F or Y ∈ S ∗ K , define g ( Y ) = ( D K ( Y ) , O K ( Y )) where D K ( Y ) = { { Y ii : i = 1 , . . . , K } } is the m ultiset of diagonal en tries and O K ( Y ) = { { Y ij : 1 ≤ i < j ≤ K } } is the multiset of off-diagonal entries. A.2 Generic Injectivit y W e now define the genericit y conditions under whic h g separates orbits. Definition 6 (Genericity Conditions) . Let Y ∈ S K . W e sa y Y satisfies: (a) Condition (a) if all en tries are distinct: Y ij = Y kl for ( i, j ) = ( k , l ) with i ≤ j , k ≤ l . (b) Condition (b) if for eac h i , there exists exactly one ( K − 1)-subset S of off-diagonal p ositions suc h that P ( k,l ) ∈S Y kl = − Y ii . Condition (b) exploits the ro w-sum constrain t Y 1 K = 0 : the off-diagonal en tries in ro w i sum to − Y ii , so the canonical subset S ∗ i = { ( i, j ) : j = i } alw ays satisfies the equation. Condition (b) requires this subset to b e unique among the K ( K − 1) / 2 K − 1 p ossible ( K − 1)-subsets. Lemma 2 (Reco very Lemma) . If Y ∈ S ∗ K satisfies c onditions (a) and (b), then g ( Y ) deter- mines Y up to S K -orbit. Pr o of. Giv en m ultisets D K and O K , w e reconstruct Y up to relab eling: Step 1: Order the distinct diagonal elemen ts as Y (1)(1) > · · · > Y ( K )( K ) , assigning canonical lab els to alternativ es. Step 2: F or eac h ( i ), identify R ( i ) ⊂ O K as the unique ( K − 1)-subset summing to − Y ( i )( i ) (exists b y condition (b)). Step 3: F or i = j , recov er Y ( i )( j ) as the unique elemen t in R ( i ) ∩ R ( j ) (singleton by condition (a)). An y Y ′ with g ( Y ′ ) = g ( Y ) satisfying (a) and (b) yields the same reconstruction up to relab eling. A.3 The Exceptional Set Definition 7 (Exceptional Set) . Define E = U C ∪ { X ∈ U : f ( X ) violates (a) or (b) } . A-4 Lemma 3 (Non-T rivialit y of Constraints) . The fol lowing hold: (i) F or distinct p ositions ( i, j ) = ( k , l ) , the function f ( X ) ij − f ( X ) kl is not identic al ly zer o on U . (ii) F or e ach index i and ( K − 1) -subset S = S ∗ i , the function P ( k,l ) ∈S f ( X ) kl + f ( X ) ii is not identic al ly zer o on U . Pr o of. Consider diagonal X = diag ( λ 1 , . . . , λ K ) with distinct λ j and P j λ j = 0. Then [ MXM ] ii = λ i (1 − 2 /K ) + ¯ λ/K and [ MXM ] ij = ( ¯ λ − λ i − λ j ) /K for i = j . F or generic λ j , all entries of f ( X ) are distinct, proving (i). F or (ii), the linear com bination for S = S ∗ i has nonzero co efficien t on λ i , so it is non trivial. Prop osition 6 (Prop erties of E ) . The set E is close d, G K -invariant, and has L eb esgue me asur e zer o. Pr o of. Closed: Conditions (a) and (b) are op en (strict inequalities and unique subset-sums are preserv ed under small p erturbations), so E C is op en. G K -in v ariant: By Prop osition 5 , scaling and n ull-space translation leav e f ( X ) unchanged. P ermutation conjugates f ( X ), preserving distinctness and subset-sum structure. Measure zero: Eac h entry f ( X ) ij is a rational (hence analytic) function on U b y Prop osi- tion 3 . By Lemma 3 , the constraints defining violations of (a) and (b) are nontrivial analytic functions. Their zero sets hav e measure zero by Mit yagin ( 2020 ), and E is a finite union of suc h sets. A.4 Basic Result for the F ull Space Theorem 7 (Main Theorem) . F or any X , Y ∈ S K \ E : g { f ( X ) } = g { f ( Y ) } implies X and Y ar e in the same G K -orbit. Pr o of. By Lemma 2 , g { f ( X ) } = g { f ( Y ) } implies f ( Y ) = P π f ( X ) P ⊤ π for some π ∈ S K . By Prop osition 5 (i), f ( P π XP ⊤ π ) = f ( Y ). By Lemma 1 , Y = c P π XP ⊤ π + w 1 ⊤ K + 1 K w ⊤ for some c ∈ R ∗ , w ∈ R K . A-5 A.5 Restriction to Cen tered, T race-Normalized Matrices Prop osition 7 (Prop erties of S ∗ K ) . The subsp ac e S ∗ K is a nonempty, close d affine subsp ac e of dimension ( K + 1)( K − 2) / 2 , satisfies S ∗ K = Im( f ) , and is S K -invariant. Pr o of. The dimension follo ws from dim( S K ) − ( K + 1) = K ( K + 1) / 2 − K − 1 = ( K + 1)( K − 2) / 2. F or S ∗ K = Im( f ): if X ∈ U , then f ( X ) 1 K = 0 and tr( f ( X )) = K , so Im( f ) ⊆ S ∗ K ; conv ersely , if Y ∈ S ∗ K , then MY M = Y and f ( Y ) = Y . F or S K -in v ariance: ( P π Y P ⊤ π ) 1 K = P π Y 1 K = 0 and the trace is preserved. Definition 8 (Restricted Exceptional Set) . Define E ∗ = { Y ∈ S ∗ K : Y violates (a) or (b) } . Theorem 8 (Generic Separation on S ∗ K ) . The set E ∗ is close d, S K -invariant, and has me a- sur e zer o in S ∗ K . F or any Y 1 , Y 2 ∈ S ∗ K \ E ∗ : g ( Y 1 ) = g ( Y 2 ) implies Y 1 and Y 2 ar e in the same S K -orbit. Pr o of. The prop erties of E ∗ follo w from Prop osition 6 restricted to S ∗ K , using Lemma 3 (which pro vides nontrivial constraints via S ∗ K = Im( f )). Separation follows from Lemma 2 . Corollary 2 (Universal Approximation on S ∗ K ) . Any c ontinuous, S K -invariant function on S ∗ K \ E ∗ c an b e uniformly appr oximate d on c omp act subsets by an MLP taking the sorte d diagonal and off-diagonal entries as input. Pr o of. F ollowing Blum-Smith et al. ( 2025 ), enco de g via con tinuous functions: g d k ( Y ) = the k th largest diagonal entry , and g o ℓ ( Y ) = the ℓ th largest off-diagonal en try . These are S K -in v ariant and separate p oints in ( S ∗ K \ E ∗ ) /S K b y Theorem 8 . Since S K is finite (hence compact), the quotient is Hausdorff ( Bredon , 1972 ). By Stone–W eierstrass, the algebra generated b y these functions is dense. By the univ ersal appro ximation theorem ( Cyb enko , 1989 ; Hornik et al. , 1989 ), MLPs can approximate an y con tin uous function of these inputs. A.6 Restriction to Submatrices F or a distinguished index j , we develop an inv ariant separating S ( j ) K − 1 -orbits, where S ( j ) K − 1 = { π ∈ S K : π ( j ) = j } . Definition 9 (Submatrix In v ariant g j ) . F or Y ∈ S ∗ K and index j , defin e g j ( Y ) = ( P j ( Y ) , O j ( Y )) A-6 where: P j ( Y ) = { { ( Y kk , Y j k ) : k = j } } , O j ( Y ) = { { Y kl : 1 ≤ k < l ≤ K , k = j, l = j } } . The m ultiset P j couples eac h diagonal entry Y kk (for k = j ) with the cov ariance Y j k . The m ultiset O j con tains off-diagonal en tries of Y − j, − j . Note that Y j j = K − P k = j Y kk is implicitly reco verable. Definition 10 (Genericity Conditions for Submatrices) . W e say Y ∈ S ∗ K satisfies (a j ) if all entries except p ossibly Y j j are distinct, and (b j ) if for eac h k = j , there is a unique ( K − 2)-subset S of off-diagonal p ositions in Y − j, − j with P ( k,m ) ∈S Y km = − Y kk − Y j k . The target sum − Y kk − Y j k arises from the row-sum constraint: Y kk + Y kj + P l = k ,l = j Y kl = 0. Theorem 9 (Generic Separation via g j ) . Define E j = { Y ∈ S ∗ K : Y violates ( a j ) or ( b j ) } . Then E j is close d, S ( j ) K − 1 -invariant, and has me asur e zer o. F or Y 1 , Y 2 ∈ S ∗ K \ E j : g j ( Y 1 ) = g j ( Y 2 ) implies Y 1 , Y 2 ar e in the same S ( j ) K − 1 -orbit. Pr o of. The pro of follows Theorem 8 . F or separation, the recov ery pro cedure parallels Lemma 2 : order pairs in P i lexicographically , identify eac h row’s off-diagonal en tries via the unique subset-sum, and reco ver shared entries as singleton intersections. Corollary 3 (Univ ersal Approximation via g j ) . Any c ontinuous, S ( j ) K − 1 -invariant function on S ∗ K \ E j c an b e uniformly appr oximate d on c omp act subsets by an MLP taking the sorte d p airs fr om P j and sorte d entries fr om O j as input. Pr o of. The pro of is analogous to Corollary 2 , with pairs replacing diagonal en tries. A.7 Extension to Utilit y-Co v ariance P airs: Global In v arian ts W e extend the theory to pairs ( v , Y ) consisting of a utilit y v ector and cov ariance matrix. Definition 11 (Centered Utilit y-Cov ariance Space) . Define X K = { ( v , Y ) ∈ R K × S K : P K i =1 v i = 0 , Y 1 K = 0 , tr( Y ) = K } . This space has dimension ( K − 1) + ( K + 1)( K − 2) / 2 = ( K 2 + K − 4) / 2. It is closed, Hausdorff, and S K -in v ariant under π · ( v , Y ) = ( P π v , P π Y P ⊤ π ). Definition 12 (Global Joint Inv arian t) . F or ( v , Y ) ∈ X K , define ˜ g ( v , Y ) = ( P ( v , Y ) , O ( Y )) where P ( v , Y ) = { { ( v i , Y ii ) : i = 1 , . . . , K } } and O ( Y ) = { { Y ij : 1 ≤ i < j ≤ K } } . A-7 The k ey extension is that P con tains p airs ( v i , Y ii ) coupling utilities with v ariances. Definition 13 (Genericit y Conditions) . W e sa y ( v , Y ) ∈ X K satisfies (˜ a) if the pairs ( v i , Y ii ) are pairwise distinct and the off-diagonal entries are pairwise distinct, and ( ˜ b) if condition (b) holds for Y . Theorem 10 (Generic Separation on X K ) . Define ˜ B = { ( v , Y ) ∈ X K : (˜ a ) or ( ˜ b ) fails } . Then ˜ B is close d, S K -invariant, and has me asur e zer o. F or ( v 1 , Y 1 ) , ( v 2 , Y 2 ) ∈ X K \ ˜ B : ˜ g ( v 1 , Y 1 ) = ˜ g ( v 2 , Y 2 ) implies the p airs ar e in the same S K -orbit. Pr o of. The pro of follows Theorem 8 . The reco v ery procedure orders pairs lexicographically to assign lab els, then recov ers off-diagonal entries via subset-sum intersections. The measure- zero argumen t extends since v i − v j is non trivial on X K . A.8 Extension to Utilit y-Co v ariance P airs: P er-Alternativ e In- v arian ts This section establishes Theorem 1 (Generic Separation) and Theorem 2 (MLP Univ ersal Appro ximation) from the main text. Definition 14 (Per-Alternativ e Inv arian t g j ) . F or ( v , Y ) ∈ X K and index j , defin e g j ( v , Y ) = ( T j ( v , Y ) , O j ( Y )) where: T j ( v , Y ) = { { ( v k , Y kk , Y j k ) : k = j } } , O j ( Y ) = { { Y kl : 1 ≤ k < l ≤ K , k = j, l = j } } . This com bines extensions from Sections A.6 and A.7 : T j con tains triples ( v k , Y kk , Y j k ) cou- pling each alternativ e k ’s utility and v ariance with its cov ariance with j , while O j con tains off-diagonal entries of Y − j, − j . The v alues v j = − P k = j v k and Y j j = K − P k = j Y kk are implicitly reco verable. Definition 15 (Genericity Conditions) . W e sa y ( v , Y ) ∈ X K satisfies (˜ a j ) if the triples ( v k , Y kk , Y j k ) for k = j are pairwise distinct and the off-diagonal en tries of Y − j, − j are pairw ise distinct, and ( ˜ b j ) if condition (b j ) holds. Definition 16 (Exceptional Set) . Define B j = { ( v , Y ) ∈ X K : (˜ a j ) or ( ˜ b j ) fails } . Prop osition 8 (Prop erties of B j ) . The set B j is close d, S ( j ) K − 1 -invariant, and has me asur e zer o in X K . Pr o of. The pro of follo ws Prop osition 6 . Closedness holds b ecause (˜ a j ) and ( ˜ b j ) are op en conditions. In v ariance under S ( j ) K − 1 holds b ecause p erm utations fixing j preserv e distinctness A-8 and subset-sum structure. F or measure zero: coincidence of tw o triples defines the inter- section of three hyperplanes { v k = v l } ∩ { Y kk = Y ll } ∩ { Y j k = Y j l } , each non trivial; the subset-sum constraints are similarly nontrivial by arguments analogous to Lemma 3 (ii). Lemma 4 (Recov ery Lemma) . If ( v , Y ) ∈ X K satisfies ( ˜ a j ) and ( ˜ b j ), then g j ( v , Y ) deter- mines ( v , Y ) up to S ( j ) K − 1 -orbit. Pr o of. The pro of extends Lemma 2 to triples. Order triples in T j lexicographically to assign lab els (1) , . . . , ( K − 1). F or eac h ( k ), identify R ( k ) ⊂ O j as the unique ( K − 2)-subset summing to − Y ( k )( k ) − Y j ( k ) . Recov er Y ( k )( l ) as the singleton R ( k ) ∩ R ( l ) . Recov er v j and Y j j from the constrain ts. W e now prov e the main results from Section 5 . Pr o of of The or em 1 . By Proposition 8 , B j is closed, S ( j ) K − 1 -in v ariant, and has measure zero. F or ( v 1 , Y 1 ) , ( v 2 , Y 2 ) ∈ X K \ B j with g j ( v 1 , Y 1 ) = g j ( v 2 , Y 2 ), Lemma 4 implies b oth pairs are determined up to S ( j ) K − 1 -orbit b y this common v alue. Pr o of of The or em 2 . Enco de g j via contin uous functions: sort triples lexicographically to obtain 3( K − 1) functions g t k, 1 = v ( k ) , g t k, 2 = Y ( k )( k ) , g t k, 3 = Y j ( k ) ; sort off-diagonal entries to obtain ( K − 1)( K − 2) / 2 functions g o ℓ . These are con tinuous and S ( j ) K − 1 -in v ariant, and separate p oin ts on ( X K \ B j ) /S ( j ) K − 1 b y Theorem 1 . Since S ( j ) K − 1 is finite, X K /S ( j ) K − 1 is Hausdorff ( Bredon , 1972 ). By Stone–W eierstrass, the algebra generated by these functions is dense on compact subsets. By the universal appro xi- mation theorem ( Cyb enk o , 1989 ; Hornik et al. , 1989 ), MLPs can approximate an y con tinuous function of these inputs. Because the choice probabilities are defined according to the integral giv en in ( 4 ) under Assumption 1 , they are contin uous functions; thus, the result holds. B Estimation Theory This appendix con tains additional information on the estimation theory results in Sections 5.2 and 5.3 . Section B.1 pro vides additional discussion of the appro ximation conditions: Assumptions 2 and 4 . Section B.2 pro vides a pro of of Theorem 4 . Section B.3 contains the regularit y conditions for Section 5.3 . Section B.4 pro vides a pro of of Theorem 6 . A-9 B.1 Em ulator Appro ximation Assumptions This section provides additional discussion of Assumptions 2 and 4 , sho wing ho w they can b e derived from more primitiv e conditions on the em ulator and justifying these conditions through related theoretical results. Primitiv e assumptions. W e consider a sieve regime in which a sequence of em ulators ˆ P n is trained with increasing precision as the sample size n grows. This is achiev ed b y progressiv ely (a) increasing the n umber of sim ulated training examples s = s n and (b) increasing the neural netw ork complexit y c = c n (e.g., the n umber of lay ers or hidden units). W e imp ose the following primitive conditions: (P1) Comp act c ovariate supp ort : The co v ariate space C is compact. (P2) Smo oth utility and c ovarianc e mappings : The mappings θ 7→ v ∗ i ( X i , θ ) and θ 7→ Σ ∗ ( X i , θ ) are con tinuously differentiable for all X i ∈ C . (P3) Interior pr ob ability c ondition : There exist a compact set ¯ X K ⊂ X K and p > 0 suc h that inf ( v ∗ , Σ ∗ ) ∈ ¯ X K min j P j ( v ∗ , Σ ∗ ) ≥ p and the image of C × Θ under the mapping ( X , θ ) 7→ ( v ∗ ( X , θ ) , Σ ∗ ( X , θ )) is con tained in ¯ X K . (P4) Pr ob ability-sc ale appr oximation : F or some α ≥ 0, the em ulator satisfies sup ( v ∗ , Σ ∗ ) ∈ ¯ X K max j =1 ,...,K | ˆ P n,j ( v ∗ , Σ ∗ ) − P j ( v ∗ , Σ ∗ ) | = o p ( n − α/ 2 ) . (49) (P5) Gr adient appr oximation : The emula tor gradien ts satisfy sup ( v ∗ , Σ ∗ ) ∈ ¯ X K max j =1 ,...,K ∇ ( v ∗ , Σ ∗ ) log ˆ P n,j ( v ∗ , Σ ∗ ) − ∇ ( v ∗ , Σ ∗ ) log P j ( v ∗ , Σ ∗ ) = o p (1) . (50) W e next show ho w these assumptions imply Assumptions 2 and 4 . W e then provide justifi- cation of assumptions (P4) and (P5) using related results in approximation theory . F rom probability-scale errors to log-lik eliho o d errors. W e now sho w that conditions (P1)–(P4) imply Assumption 2 . W rite the log-likelihoo d error as ˆ ℓ n ( θ ) − ℓ n ( θ ) = 1 n n X i =1 ξ i , where ξ i = log ˆ P n,y i ( θ ) − log P y i ( θ ) , (51) A-10 and y i ∈ { 1 , . . . , K } denotes the observ ed c hoice. Conditional on co v ariates and the trained em ulator, the ξ i are indep enden t. W e decomp ose in to bias and centered comp onents: ˆ ℓ n ( θ ) − ℓ n ( θ ) = 1 n n X i =1 E ( ξ i | X i ) | {z } bias + 1 n n X i =1 { ξ i − E ( ξ i | X i ) } | {z } centered term . (52) Let δ n = sup ( v ∗ , Σ ∗ ) ∈ ¯ X K max j | ˆ P n,j − P j | = o p ( n − α/ 2 ) denote the probabilit y-scale error from (P4). T a ylor expanding log ˆ P n,j around P j giv es log ˆ P n,j − log P j = ˆ P n,j − P j P j − ( ˆ P n,j − P j ) 2 2 P 2 j + O δ 3 n p 3 . (53) The conditional exp ectation of ξ i is E ( ξ i | X i ) = K X j =1 P j (log ˆ P n,j − log P j ) . (54) The first-order con tribution is P j P j · ( ˆ P n,j − P j ) /P j = P j ( ˆ P n,j − P j ) = 0, since b oth probabilit y vectors sum to one. Therefore, E ( ξ i | X i ) = − K X j =1 ( ˆ P n,j − P j ) 2 2 P j + O δ 3 n p 3 = O δ 2 n p . (55) F or the cen tered term, the mean v alue theorem giv es | log ˆ P n,j − log P j | ≤ | ˆ P n,j − P j | /p ≤ δ n /p , and hence | ξ i | ≤ δ n /p . The conditional v ariance satisfies V ar( ξ i | X i ) ≤ E ( ξ 2 i | X i ) ≤ δ 2 n /p 2 . Since the cen tered terms ξ i − E ( ξ i | X i ) are conditionally independent with mean zero, the v ariance of their sample av erage is V ar " 1 n n X i =1 { ξ i − E ( ξ i | X i ) } X 1 , . . . , X n # = 1 n 2 n X i =1 V ar( ξ i | X i ) ≤ δ 2 n np 2 . (56) By Cheb yshev’s inequality , the centered term is O p δ n p √ n . Com bining via the triangle inequality: | ˆ ℓ n ( θ ) − ℓ n ( θ ) | = O δ 2 n p + O p δ n √ np ! . (57) A-11 F or α ∈ [0 , 1], the bias term O ( δ 2 n /p ) = o ( n − α ) dominates the centered term O p δ n p √ n = o p n − ( α +1) / 2 . Since conditions (P1) and (P2) ensure that the mapping from ( X , θ ) to ( v ∗ , Σ ∗ ) is con tinuous on the compact set C × Θ, the b ound holds uniformly o ver θ ∈ Θ: sup θ ∈ Θ | ˆ ℓ n ( θ ) − ℓ n ( θ ) | = o p ( n − α ) , (58) whic h is Assumption 2 . F rom gradien t appro ximation to Fisher information consistency . W e now sho w that conditions (P1), (P2), (P3), and (P5) imply Assumption 4 . By the c hain rule, ∇ θ log ˆ P n,j ( θ ) = {∇ θ ( v ∗ , Σ ∗ ) } ⊤ ∇ ( v ∗ , Σ ∗ ) log ˆ P n,j , (59) and similarly for ∇ θ log P j ( θ ). By condition (P2), the Jacobian ∇ θ ( v ∗ , Σ ∗ ) is con tinuous on the compact set C × Θ and hence uniformly b ounded: sup ( X , θ ) ∈C × Θ ∥∇ θ ( v ∗ , Σ ∗ ) ∥ ≤ C for some constan t C < ∞ . Let ε n = sup ( v ∗ , Σ ∗ ) ∈ ¯ X K max j ∇ ( v ∗ , Σ ∗ ) log ˆ P n,j − ∇ ( v ∗ , Σ ∗ ) log P j = o p (1) (60) denote the gradien t approximation error from (P5). Then sup θ ∈ Θ ∇ θ log ˆ P n,j ( θ ) − ∇ θ log P j ( θ ) ≤ C ε n = o p (1) . (61) Recall the em ulator and true outer-pro duct-of-scores estimators are ˆ J n ( θ ) = 1 n n X i =1 ∇ θ log ˆ P n,y i ( θ ) ∇ θ log ˆ P n,y i ( θ ) ⊤ , (62) J n ( θ ) = 1 n n X i =1 ∇ θ log P y i ( θ ) ∇ θ log P y i ( θ ) ⊤ . (63) Let ˆ s i = ∇ θ log ˆ P n,y i ( θ ) and s i = ∇ θ log P y i ( θ ). The iden tity ˆ s i ˆ s ⊤ i − s i s ⊤ i = ( ˆ s i − s i ) ˆ s ⊤ i + s i ( ˆ s i − s i ) ⊤ (64) implies ∥ ˆ s i ˆ s ⊤ i − s i s ⊤ i ∥ ≤ ∥ ˆ s i − s i ∥ · ( ∥ ˆ s i ∥ + ∥ s i ∥ ) . (65) A-12 The true scores s i are uniformly b ounded: (P3) ensures that all relev ant inputs ( v ∗ , Σ ∗ ) lie in ¯ X K where P j ≥ p > 0, guaran teeing b ounded gradien ts ∇ ( v ∗ , Σ ∗ ) log P j , and (P2) ensures the Jacobian ∇ θ ( v ∗ , Σ ∗ ) is contin uous and hence b ounded on C × Θ. Let M = sup θ ∈ Θ max j ∥∇ θ log P j ( θ ) ∥ < ∞ , so that ∥ s i ∥ ≤ M for all i . Since ∥ ˆ s i − s i ∥ ≤ C ε n = o p (1), the em ulator scores satisfy ∥ ˆ s i ∥ ≤ ∥ s i ∥ + C ε n ≤ M + o p (1). Therefore, sup θ ∈ Θ ∥ ˆ J n ( θ ) − J n ( θ ) ∥ ≤ 1 n n X i =1 ∥ ˆ s i − s i ∥ · ( ∥ ˆ s i ∥ + ∥ s i ∥ ) ≤ 1 n n X i =1 C ε n · { 2 M + o p (1) } = o p (1) , (66) whic h is Assumption 4 . Justification from appro ximation theory . The primitiv e conditions (P4) and (P5) are supp orted by related theoretical results on neural net work approximation and estimation, though a complete theory tailored to our sp ecific setting remains an area for future work. The total emulator error can b e decomp osed in to appro ximation error and estimation error: sup ( v ∗ , Σ ∗ ) ∈ ¯ X K max j =1 ,...,K | ˆ P n,j ( v ∗ , Σ ∗ ) − P j ( v ∗ , Σ ∗ ) | ≤ a ( c n ) | {z } approximation + e ( s n , c n ) | {z } estimation , (67) where a ( c ) is the distance from the true c hoice probabilit y function to the b est appro ximator in the net work class of complexity c , and e ( s, c ) is the deviation of the trained netw ork from this b est-in-class appro ximator due to training on s simulated examples. F or the approximation error, pro vided the choice probabilities are real-analytic functions of ( v ∗ , Σ ∗ ) on the in terior of the parameter space, neural net works with smo oth activ a- tions can approximate them with exp onen tially small error. De Ryck et al. ( 2021 ) es- tablish that tanh netw orks with t wo hidden lay ers achiev e approximation error decaying as O N k/ ( d +1) exp( − C · N 1 / ( d +1) log N ) in Sob olev norms W k, ∞ , where N is the net work width, d is the input dimension, and C > 0 dep ends on the analyticit y parameters of the tar- get function. Earlier w ork established similar exp onential rates for deep ReLU net works ( E and W ang , 2018 ), though under the stronger assumption that the target function admits an absolutely conv ergen t pow er series expansion. Given these exp onential con vergence results, ac hieving approximation error ε requires net work complexity scaling only p olylogarithmically in 1 /ε . A-13 F or the estimation error, standard results from empirical pro cess theory yield b ounds of order O n p c log ( sc ) /s o in L 2 norms, where c is a complexity parameter ( Sc hmidt-Hieb er , 2020 ; F arrell et al. , 2021 ; Shen et al. , 2023 ). F or our setting, ho wev er, we require an L ∞ b ound. The results below assume minimally that e ( s, c ) = O c k p olylog( s ) / √ s for some k < ∞ . Then, with netw ork complexit y growing p olylogarithmically in the target accuracy , the dep endence on c is negligible, and the estimation error is effectively of order O (1 / √ s ) up to logarithmic factors. Ac hieving the rate giv en in (P4) requires that b oth a ( c n ) = o ( n − α/ 2 ) and e ( s n , c n ) = o p ( n − α/ 2 ); note that the approximation error is nonsto c hastic b ecause it concerns pure func- tion appro ximation. The exp onen tial appro ximation rates for analytic functions imply that the first condition is satisfied with p olylogarithmic gro wth in c n . The second condition re- quires s n to grow faster than n α up to logarithmic factors. In practice, since sim ulation from the MNP mo del is computationally inexp ensiv e, generating a training set with s n ≫ n is feasible. The cases α = 0 and α = 1 corresp ond to differen t inferen tial goals. When α = 0, As- sumption 2 requires only that the log-lik eliho o d error v anish in probability , which suffices for consistency of the em ulator-based estimator (Theorem 3 ). When α = 1, the stronger requiremen t that the error v anish faster than n − 1 ensures that the emulator-based estimator is asymptotically equiv alent to the true MLE, inheriting its √ n -consistency and asymptotic normalit y (Theorem 4 ). The latter requires a larger training set: s n gro wing faster than n v ersus s n gro wing faster than n 0 = 1. F or the gradient appro ximation in (P5), Czarnec ki et al. ( 2017 ) show that neural netw orks are universal appro ximators in Sob olev norms, and the b ounds of De Ryck et al. ( 2021 ) hold in W k, ∞ norms, establishing that smo oth netw orks can simultaneously appro ximate b oth function v alues and deriv ativ es. Additionally , Co cola and Hand ( 2020 ) pro ve global con vergence of gradien t flo w for Sob olev training with o verparameterized tw o-la y er net works, ensuring that the trained net work achiev es small Sob olev loss under appropriate conditions. These results supp ort the plausibility of (P5), though the precise rates and conditions for our setting merit further in vestigation. B.2 Pro of of Theorem 4 Pr o of. W e pro ve the result for appro ximate maximizers satisfying ˆ ℓ n ( ˆ θ n ) ≥ sup θ ∈ Θ ˆ ℓ n ( θ ) − η n where η n = o p ( n − 1 ). Exact maximizers corresp ond to η n = 0. W e proceed in three A-14 steps: first b ounding the difference in log likelihoo ds, then sho wing that the estimators are asymptotically equiv alen t, and finally app ealing to the asymptotic normalit y of the exact MLE. Step 1: Bounding the difference in log lik eliho o ds. Define δ n = sup θ ∈ Θ | ˆ ℓ n ( θ ) − ℓ n ( θ ) | = o p ( n − 1 ) by Assumption 2 with α ≥ 1. By the triangle inequalit y , | ℓ n ( ˆ θ n ) − ℓ n ( ˜ θ n ) | ≤ | ℓ n ( ˆ θ n ) − ˆ ℓ n ( ˆ θ n ) | + | ˆ ℓ n ( ˆ θ n ) − ℓ n ( ˜ θ n ) | . (68) By Assumption 2 , the first term is b ounded b y δ n . F or the second term, w e establish upp er and lo wer b ounds on ˆ ℓ n ( ˆ θ n ). Since ˜ θ n maximizes ℓ n : ˆ ℓ n ( ˆ θ n ) ≤ ℓ n ( ˆ θ n ) + δ n ≤ ℓ n ( ˜ θ n ) + δ n . (69) F or the lo w er b ound, b y the approximate maximizer prop erty and the fact that ˜ θ n ∈ Θ: ˆ ℓ n ( ˆ θ n ) ≥ sup θ ∈ Θ ˆ ℓ n ( θ ) − η n ≥ ˆ ℓ n ( ˜ θ n ) − η n ≥ ℓ n ( ˜ θ n ) − δ n − η n . (70) Com bining these b ounds, | ˆ ℓ n ( ˆ θ n ) − ℓ n ( ˜ θ n ) | ≤ δ n + η n . Therefore, | ℓ n ( ˆ θ n ) − ℓ n ( ˜ θ n ) | ≤ 2 δ n + η n = o p ( n − 1 ) , (71) whic h implies n | ℓ n ( ˆ θ n ) − ℓ n ( ˜ θ n ) | = o p (1). Step 2: Asymptotic equiv alence of the estimators. W e show that √ n ( ˆ θ n − ˜ θ n ) p − → 0 . Fix ϵ > 0 and define the neigh b orho o d B n,ϵ = n θ ∈ Θ : √ n ∥ θ − ˜ θ n ∥ ≤ ϵ o . (72) W e show that ˆ θ n ∈ B n,ϵ with probabilit y approaching one. F or an y θ / ∈ B n,ϵ , we hav e ∥ θ − ˜ θ n ∥ > ϵ/ √ n . Since ˜ θ n maximizes ℓ n , the score v anishes: 1 n P n i =1 ψ ( y i , X i ; ˜ θ n ) = 0 . By T aylor expansion around ˜ θ n , ℓ n ( θ ) = ℓ n ( ˜ θ n ) + 1 2 ( θ − ˜ θ n ) ⊤ ∇ 2 θ ℓ n ( ¯ θ )( θ − ˜ θ n ) , (73) where ¯ θ lies on the segment b etw een θ and ˜ θ n . By consistency , b oth ˆ θ n p − → θ 0 and ˜ θ n p − → θ 0 , A-15 so ¯ θ p − → θ 0 . By the uniform law of large num b ers and Assumption 3 (ii) and (iv), ∇ 2 θ ℓ n ( ¯ θ ) p − → − J ( θ 0 ) . (74) Let λ min > 0 denote the minim um eigenv alue of J ( θ 0 ), which is positive by Assumption 3 (v). F or sufficiently large n , with probability approac hing one, the Hessian ∇ 2 θ ℓ n ( ¯ θ ) has all eigen- v alues b ounded ab ov e by − λ min / 2. Thus, for θ / ∈ B n,ϵ , n n ℓ n ( ˜ θ n ) − ℓ n ( θ ) o ≥ λ min 4 n ∥ θ − ˜ θ n ∥ 2 > λ min 4 · ϵ 2 = κ > 0 (75) with probabilit y approaching one as n → ∞ . No w suppose Pr( ˆ θ n / ∈ B n,ϵ ) → 0. On the even t that both ˆ θ n / ∈ B n,ϵ and the Hessian b ound holds, we ha ve n ( ℓ n ( ˜ θ n ) − ℓ n ( ˆ θ n )) > κ . Since the Hessian b ound holds with probability approac hing one, this ev en t has probability bounded aw ay from zero, whic h implies that Pr hn n ( ℓ n ( ˜ θ n ) − ℓ n ( ˆ θ n ) o > κ i → 0. But this contradicts n | ℓ n ( ˆ θ n ) − ℓ n ( ˜ θ n ) | = o p (1) from Step 1. Therefore, Pr( ˆ θ n ∈ B n,ϵ ) → 1. Since ϵ > 0 w as arbitrary , w e conclude that √ n ( ˆ θ n − ˜ θ n ) p − → 0 . Step 3: Asymptotic normalit y . By standard maxim um likelihoo d theory (Theorem 5.39 and Lemma 7.6 of v an der V aart ( 1998 )), the regularit y conditions in Assumption 3 ensure that the mo del is differentiable in quadratic mean at θ 0 with nonsingular Fisher information. Since ˜ θ n is consistent, √ n ( ˜ θ n − θ 0 ) d − → N { 0 , J ( θ 0 ) − 1 } . Since √ n ( ˆ θ n − ˜ θ n ) p − → 0 , Slutsky’s theorem giv es √ n ( ˆ θ n − θ 0 ) = √ n ( ˆ θ n − ˜ θ n ) + √ n ( ˜ θ n − θ 0 ) d − → N 0 , J ( θ 0 ) − 1 . (76) B.3 Regularit y Conditions for Inference Under Missp ecification This app endix states the regularit y conditions required for the results in Section 5.3 . These conditions parallel standard assumptions for M-estimators ( v an der V aart , 1998 , Chapter 5) and are mild for neural net work emulators with smo oth activ ation functions. Recall that in Section 5.3 , w e treat the neural netw ork as fixed (not v arying with n ), so w e use ˆ m and ˆ ψ without n subscripts. Assumption 5 (Identification and Uniform Conv ergence) . The follo wing conditions hold: A-16 (i) The parameter space Θ is compact. (ii) The pseudo-true parameter θ † 0 = arg max θ ∈ Θ E { ˆ m ( y , X ; θ ) } exists uniquely and lies in the in terior of Θ. (iii) The pseudo-true parameter is well-separated: for ev ery ϵ > 0, sup θ : ∥ θ − θ † 0 ∥≥ ϵ E { ˆ m ( y , X ; θ ) } < E n ˆ m ( y , X ; θ † 0 ) o . (77) (iv) The sample criterion function conv erges uniformly to its exp ectation: sup θ ∈ Θ 1 n n X i =1 ˆ m ( y i , X i ; θ ) − E [ ˆ m ( y , X ; θ )] p − → 0 . (78) (v) The estimator ˆ θ n is an appro ximate maximizer of the sample criterion function: 1 n n X i =1 ˆ m ( y i , X i ; ˆ θ n ) ≥ sup θ ∈ Θ 1 n n X i =1 ˆ m ( y i , X i ; θ ) − o p ( n − 1 ) . (79) Assumption 6 (Regularity for Asymptotic Normality) . The following conditions hold: (i) (Differentiabilit y) F or eac h ( y , X ), the map θ 7→ ˆ m ( y , X ; θ ) is differen tiable on Θ with gradien t ˆ ψ ( y , X ; θ ) = ∇ θ ˆ m ( y , X ; θ ). (ii) (Lo cal dominance) There exists δ > 0 and a measurable function ˙ m ( y , X ) ha ving E [ ˙ m ( y , X ) 2 ] < ∞ suc h that sup θ : ∥ θ − θ † 0 ∥≤ δ ∥ ˆ ψ ( y , X ; θ ) ∥ ≤ ˙ m ( y , X ) . (80) (iii) (Second-order expansion) The map θ 7→ E { ˆ m ( y , X ; θ ) } admits a second-order T a ylor expansion at θ † 0 : E { ˆ m ( y , X ; θ ) } = E n ˆ m ( y , X ; θ † 0 ) o − 1 2 ( θ − θ † 0 ) ⊤ A ( θ † 0 )( θ − θ † 0 ) + o ( ∥ θ − θ † 0 ∥ 2 ) , (81) where A ( θ † 0 ) = − E n ∇ 2 θ ˆ m ( y , X ; θ † 0 ) o is p ositiv e definite. A-17 B.4 Pro of of Theorems 5 and 6 Pr o of of The or em 5 . Define the sample and p opulation criterion functions M n ( θ ) = 1 n n X i =1 ˆ m ( y i , X i ; θ ) , M ( θ ) = E { ˆ m ( y , X ; θ ) } . (82) By Assumption 5 (iv), sup θ ∈ Θ | M n ( θ ) − M ( θ ) | p − → 0. By Assumption 5 (ii)–(iii), θ † 0 is the unique maximizer of M ( θ ) and is well-separated in the sense that sup θ : ∥ θ − θ † 0 ∥≥ ϵ M ( θ ) < M ( θ † 0 ) for ev ery ϵ > 0. By Assumption 5 (v), M n ( ˆ θ n ) ≥ sup θ ∈ Θ M n ( θ ) − o p ( n − 1 ), whic h implies M n ( ˆ θ n ) ≥ sup θ ∈ Θ M n ( θ ) − o p (1). The result ˆ θ n p − → θ † 0 no w follows from Theorem 5.7 of v an der V aart ( 1998 ). Pr o of of The or em 6 . W e verify the conditions of Theorem 5.23 of v an der V aart ( 1998 ) and apply it to obtain the result. By Assumption 6 (i), the map θ 7→ ˆ m ( y , X ; θ ) is differen tiable at θ † 0 for ev ery ( y , X ), with deriv ative ˆ ψ ( y , X ; θ † 0 ). By Assumption 6 (ii), the score is lo cally dominated by a square- in tegrable function, which implies the Lipschitz condition | ˆ m ( y , X ; θ 1 ) − ˆ m ( y , X ; θ 2 ) | ≤ ˙ m ( y , X ) ∥ θ 1 − θ 2 ∥ (83) for θ 1 , θ 2 in a neighborho o d of θ † 0 via the mean v alue theorem. Assumption 6 (iii) provides the required second-order T aylor expansion of θ 7→ E { ˆ m ( y , X ; θ ) } at the p oint of maximum θ † 0 , with nonsingular second deriv ative matrix − A ( θ † 0 ). By Theorem 5 , ˆ θ n p − → θ † 0 . By Assumption 5 (v), the near-maximization condition M n ( ˆ θ n ) ≥ sup θ ∈ Θ M n ( θ ) − o p ( n − 1 ) is satisfied. Applying Theorem 5.23 of v an der V aart ( 1998 ): √ n ( ˆ θ n − θ † 0 ) = A ( θ † 0 ) − 1 1 √ n n X i =1 ˆ ψ ( y i , X i ; θ † 0 ) + o p (1) . (84) By Assumption 6 (ii), E n ∥ ˆ ψ ( y , X ; θ † 0 ) ∥ 2 o ≤ E { ˙ m ( y , X ) 2 } < ∞ . The cen tral limit theorem and Slutsky’s lemma yield √ n ( ˆ θ n − θ † 0 ) d − → N n 0 , A ( θ † 0 ) − 1 B ( θ † 0 ) A ( θ † 0 ) −⊤ o , (85) A-18 where B ( θ † 0 ) = E n ˆ ψ ( y , X ; θ † 0 ) ˆ ψ ( y , X ; θ † 0 ) ⊤ o . C Sim ulation Study Details This app endix provides additional details on the factor model parameterization, emulator training pro cedure, and the scaled Wishart distribution used in the simulation study . C.1 Em ulator T raining W e train the em ulator using the Adam optimizer ( Kingma and Ba , 2015 ) with the AdamW w eight decay v arian t ( Loshc hilov and Hutter , 2019 ). The base learning rate is 0 . 003 with momen tum parameters β 1 = 0 . 9 and β 2 = 0 . 999, numerical stability constant ϵ = 10 − 8 , and w eight decay 3 × 10 − 6 . Learning rate sc hedule. W e use a learning rate sc hedule with linear warm up follo wed b y in verse-square-root deca y . During the first 5 , 000 steps, the learning rate increases linearly from zero to the base rate. After w armup, the learning rate decays as p t warm up /t , where t is the curren t step and t warm up = 5 , 000. Drop out sc hedule. W e apply drop out during training to encourage div ersit y among learned represen tations. W e set the drop out rate to 1 / (10 t ), where t indexes the training episo des from 1 to 400 , 000. T raining procedure. W e pregenerate 400 , 000 training examples, eac h consisting of a canonicalized input ( v ∗ , Σ ∗ ), sim ulated c hoice frequencies based on 10 6 Mon te Carlo dra ws, and target gradien ts computed using the soft relaxation describ ed in Section 4 . During training, w e randomly pair these examples with pre-computed tangent space directions for the directional deriv ativ e loss. Gradients are clipp ed to a maximum norm of 0 . 01. W e train for 400 , 000 optimizer steps with a batch size of 10 , 000. Net work arc hitecture. T able 8 summarizes the neural netw ork arc hitecture for each v alue of K . All netw orks use the Swish activ ation function. Larger v alues of K require larger net works to maintain approximation accuracy . C.2 Deriv ation of Scaled Wishart PDF This section derives the PDF of a scaled Wishart random matrix as describ ed in Section 6.1 . A-19 Let W ∼ W d ( V , n ) denote a d × d Wishart random matrix with scale matrix V and n ≥ d degrees of freedom. W e derive the distribution of Σ = W /W j j , where W j j is the ( j, j ) elemen t of W for some j ∈ { 1 , . . . , d } . The Wishart densit y is f W ( W ) = | W | ( n − d − 1) / 2 exp − 1 2 tr( V − 1 W ) 2 nd/ 2 | V | n/ 2 Γ d ( n/ 2) (86) where Γ d ( · ) is the m ultiv ariate gamma function. The in verse transformation is W = W j j Σ . Note that Σ is p ositiv e definite with Σ j j = 1, so it has d ( d + 1) / 2 − 1 free parameters. T ogether with W j j , this matc hes the d ( d + 1) / 2 unique elemen ts of W . The Jacobian determinant of this transformation is w d ( d +1) / 2 − 1 j j , where w j j denotes the v alue of W j j . Substituting W = W j j Σ into the Wishart densit y and applying the Jacobian yields the joint densit y f W j j , Σ ( w j j , Σ ) = | Σ | ( n − d − 1) / 2 2 nd/ 2 | V | n/ 2 Γ d ( n/ 2) · w nd/ 2 − 1 j j exp n − w j j 2 tr( V − 1 Σ ) o . (87) In tegrating ov er w j j > 0 using the gamma in tegral gives the marginal density of Σ : f Σ ( Σ ) = Γ( nd/ 2) 2 nd/ 2 | V | n/ 2 Γ d ( n/ 2) · | Σ | ( n − d − 1) / 2 1 2 tr( V − 1 Σ ) nd/ 2 (88) for symmetric, p ositiv e definite Σ with Σ j j = 1 for some fixed j ∈ { 1 , . . . , d } . In the simulation study , w e use d = K − 1, n = K + 10, V = I K − 1 , and j = 1. Substituting these v alues and simplifying yields the densit y giv en in Section 6.1 . A-20 Comp onen t K = 3 K = 5 K = 10 Diagonal De epSet ϕ output dim 8 24 32 ϕ hidden la yers 0 1 1 ϕ hidden dim N/A 24 32 ρ output dim 8 24 32 ρ hidden la yers 0 0 0 P arameters 152 1,440 2,432 Off-diagonal De epSet ϕ output dim 8 24 32 ϕ hidden la yers 0 1 1 ϕ hidden dim N/A 24 32 ρ output dim 8 24 32 ρ hidden la yers 0 0 0 P arameters 128 1,368 2,336 Combining MLP Output dim 8 24 32 Hidden dim 12 48 64 Hidden la yers 2 2 2 P arameters 572 6,312 10,976 Equivariant layers Hidden dim 4 12 16 Hidden la yers 1 1 1 P arameters 76 612 1,072 T otal p ar ameters 928 9,732 16,816 T able 8: Neural net work arc hitecture b y n umber of alternatives K . All configurations use an initial drop out rate of 0 . 1 and Swish activ ations. When the num b er of hidden lay ers is 0, the hidden dimension is not applicable (N/A). A-21
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment