Robust Nasality Representation Learning for Cleft Palate-Related Velopharyngeal Dysfunction Screening in Real-World Settings
Velopharyngeal dysfunction (VPD) is characterized by inadequate velopharyngeal closure during speech and often causes hypernasality and reduced intelligibility. Although speech-based machine learning models can perform well under standardized clinica…
Authors: Weixin Liu, Bowen Qu, Amy Stone
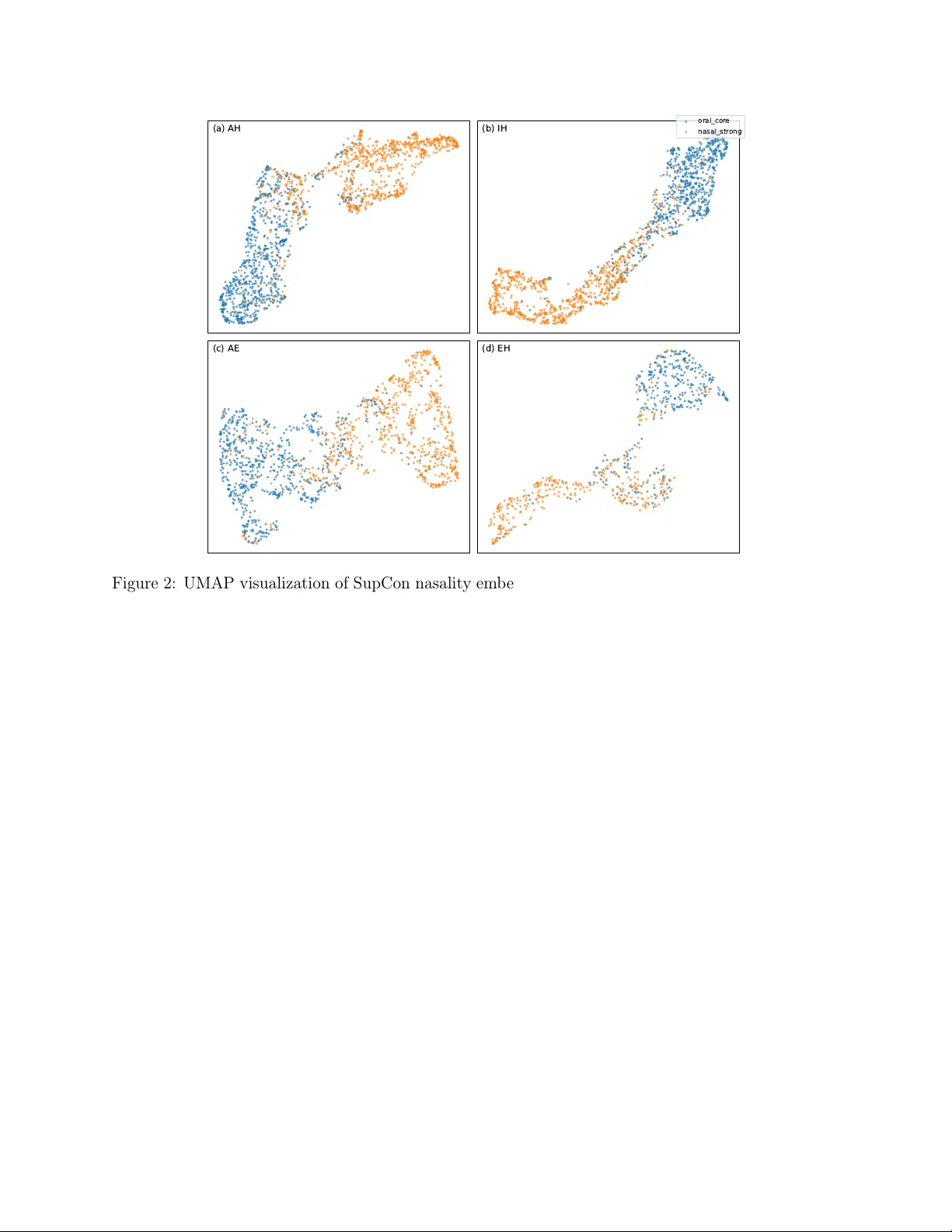
Robust Nasalit y Represen tation Learning for Cleft P alate-Related V elopharyngeal Dysfunction Screening in Real-W orld Settings W eixin Liu 1 , Bo wen Qu 2 , Am y Stone 3 , Maria E. P ow ell 3 , Shama Dufresne 4 , Stephane Braun 5,6 , Izab ela Galdyn 5,6 , Mic hael Golinko 5,6 , Bradley Malin 1,2,7,8 , Zhijun Yin * ∗ 1,2,7 , and Matthew E. P ontell * 5,6 1 Departmen t of Electrical and Computer Engineering, V anderbilt Univ ersity , Nashville, TN, United States 2 Departmen t of Computer Science, V anderbilt Univ ersity , Nash ville, TN, United States 3 Departmen t of Otolaryngology—Head and Neck Surgery , V anderbilt Universit y Medical Cen ter, Nashville, TN, United States 4 Sc ho ol of Medicine, V anderbilt Universit y , Nash ville, TN, United States 5 Departmen t of Plastic Surgery , V anderbilt Univ ersity Medical Center, Nash ville, TN, United States 6 Division of Pediatric Plastic Surgery , Monro e Carell Jr. Children’s Hospital, Nashville, TN, United States 7 Departmen t of Biomedical Informatics, V anderbilt Universit y Medical Cen ter, Nashville, TN, United States 8 Departmen t of Biostatistics, V anderbilt Universit y Medical Cen ter, Nashville, TN, United States Abstract Bac kground: V elopharyngeal dysfunction (VPD) is an impaired ability to ac hieve adequate v elopharyngeal closure during sp eech, often resulting in h yp ernasality and reduced intelligibilit y . VPD screening and diagnosis require sp ecialized exp ertise and controlled recording conditions, limiting scalable access outside high-income coun tries. Key challenge: Speech-based mac hine learning models can perform extremely w ell under standardized clinical recording conditions. Ho wev er, p erformance often deteriorates when deplo yed on consumer devices (e.g., phones or tablets) and in uncontrolled acoustic en vironments. This degradation is largely driven b y domain shift arising from differences in recording conditions (e.g., device and c hannel characteristics, background noise, and ro om acoustics), which can cause mo dels to rely on spurious recording artifacts rather than pathology-relev ant cues. Metho ds: This study introduces a t wo-stage framew ork to improv e robustness under realistic recording scenarios. Nasality r epr esentation pr e-tr aining employs a nasality-focused represen- tation via supervised contrastiv e learning (SupCon) using an auxiliary dataset with phoneme alignmen ts to form oral-con text versus nasal-context sup ervision. During F r ozen-enc o der VPD scr e ening , the encoder is frozen to perform VPD screening using ligh t weigh t classifiers on 0.5 second c h unks with probability aggregation to pro duce recording-level decisions using a fixed decision threshold. Here, in-domain refers to standardized clinical recordings used for model de- v elopment, and out-of-domain refers to heterogeneous public In ternet recordings collected under uncon trolled conditions and ev aluated without any adaptation. Data is then compared against prior-study baselines, including MF CC features and large pretrained speech representations, using the same ev aluation proto col. Results: On an in-domain clinical cohort of 82 sub jects (60 train / 22 test; 345 training recordings; 131 test recordings; m ultiple recordings p er sub ject), the proposed approach ac hieves p erfect recording-lev el screening p erformance (macro-F1 = 1.000, accuracy = 1.000). On a separate ∗ Corresp on dence: zhijun.yin@vumc.org; matthew.e.p ontell@vumc.org 1 out-of-domain set of 131 public Internet recordings, large pretrained sp eech representations degrade substantially , and MFCC is the strongest baseline (macro-F1 = 0.612, accuracy = 0.641). The proposed method ac hieves the b est ov erall out-of-domain p erformance (macro-F1 = 0.679, accuracy = 0.695), impro ving ov er the strongest baseline by +0.067 macro-F1 and +0.054 accuracy (p oint-estimate improv ements) under the same ev aluation proto col and fixed threshold. Conclusion: Learning a nasalit y-fo cused representation prior to clinical classification can reduce sensitivit y to recording artifacts and improv e robustness when moving from the lab oratory to real-w orld audio recording scenarios. This design supp orts practical deplo yment of VPD screening and motiv ates domain-robust ev aluation protocols for deplo yable sp eec h-based digital health to ols. Keyw ords: velopharyngeal dysfunction, v elopharyngeal insufficiency , cleft palate, cleft lip, h yp ernasality , nasalit y representation, sup ervised contrastiv e learning, domain shift, mobile health, digital screening, sp eech analysis, global health INTRODUCTION V elopharyngeal dysfunction (VPD) arises from inadequate function of the velopharyngeal p ort during sp eech, which allo ws for abnormal air coupling b etw een the oral and nasal cavities. VPD frequen tly presents with hypernasality and impaired sp eech in telligibility , b oth of which negatively impact comm unication, feeding, and psychosocial function (Guyton et al., 2018). The most common manifestation of VPD is velopharyngeal insufficiency (VPI), whic h often results from velopharyngeal dysfunction in the setting of a cleft palate (Lucas et al., 2025). In patien ts with cleft palate, VPI rates can exceed 30% and are likely m uch higher w orldwide (Alter et al., 2025b). Diagnosis and managemen t of VPD requires specialized sp eec h-language pathologists (SLPs) that are often members of m ultidisciplinary cleft care teams, and ev aluations are often conducted in standardized acoustic recording conditions. These resources are often not a v ailable in lo w- and middle-income countries (LMICs), thereb y creating a barrier to timely diagnosis and management (Alter et al., 2025a). In an attempt to augment the reach of existing SLPs, teams hav e b egun to explore the use of mac hine learning mo dels to automatically detect the presence of VPD from acoustic samples (Lucas et al., 2025; Shirk et al., 2025; Alter et al., 2025a; Liu et al., 2025b). T o ensure that mo dels are clinically translatable, a scalable VPD screening to ol must b e deplo yable in the field and op erate on consumer devices in everyda y acoustic en vironments. How ever, clinical deploymen t in tro duces significan t v ariation in acoustic setting, microphone frequency response, channel compression, bac kground noise, rev erb eration, and sp eaking style, amongst man y other factors. Such factors induce domain shift b et ween standardized clinical recordings used for model developmen t and real- w orld audio encoun tered during deploymen t (Liu et al., 2025b; Ganin et al., 2016; Sun and Saenk o, 2016). A cen tral c hallenge is that mo dels trained in-domain can inadv ertently fo cus on spurious correlations tied to recording conditions (e.g., device-sp ecific sp ectral coloration or background noise patterns), achieving near-ceiling performance in con trolled tests y et failing to generalize under realistic v ariabilit y . This phenomenon is widely recognized as “shortcut learning” in medical AI, where mo dels latch onto non-pathological artifacts rather than actual biological signals (Geirhos et al., 2020; DeGra ve et al., 2021). Prior work on VPD sp eech analysis has explored b oth classical acoustic features and mo dern deep learning approac hes, including ob jective assessment of hypernasality and nasality-related measures (Lucas et al., 2025; Alter et al., 2025a; Shirk et al., 2025; Liu et al., 2025b; Mathad et al., 2021; Lozano et al., 2024; Zhang et al., 2023). More recently , large self-sup ervised sp eec h representations (e.g., W a v2V ec2, HuBER T, data2v ec, Whisper enco ders) ha ve enabled strong p erformance on small clinical datasets b y lev eraging broad pretraining (Baevski et al., 2020; Hsu et al., 2021; Baevski et al., 2022; 2 Radford et al., 2023). Despite these adv ances, high in-domain accuracy do es not guarantee deploy able robustness. Rather, many approaches are ev aluated primarily within a single recording domain or under mild condition changes, leaving a gap in understanding and addressing generalization failures under substan tial domain shift, for example, mo ving from the clinic to consumer devices (Liu et al., 2025b). Figure 1: Ov erview of the prop osed t wo-stage framework. Stage 1: nasalit y represen tation pre- training using sup ervised con trastive learning (SupCon) with positive pairs sampled from the same sp eak er, same vo w el, and same auxiliary class (oral-context vs. nasal-context), while restricting con trastive comparisons to within-vo w el pairs to reduce phonetic-con tent leak age. A W av2V ec2.0 bac kb one with trainable lay er fusion and a pro jection head outputs 256-dimensional ℓ 2 -normalized em b eddings. Stage 2: robust VPD screening under domain shift (lab → wild) using the frozen enco der as a feature extractor on 0.5 s c hunks, follow ed b y a light w eight classifier (LR/SVM/MLP/XGBoost) and mean aggregation of c hunk-lev el probabilities to pro duce recording-lev el screening decisions (in-domain and out-of-domain) using a fixed decision threshold. This study aims to address this gap b y learning a represen tation that targets the underlying pro duction-related attribute, namely nasalit y , b efore training the clinical screening classifier, with the goal of reducing reliance on domain-dep endent recording artifacts under cross-device and cross-en vironment v ariability (Liu et al., 2025b; Ganin et al., 2016; Sun and Saenk o, 2016). Such nasalit y-related cues could b e more stable across devices than man y c hannel- or en vironment-specific artifacts, and thus a representation encouraged to enco de nasality distinctions can improv e robustness when the recording domain changes (Liu et al., 2025b). T o ac hieve this goal, w e aim to use a tw o-stage framew ork ( Figure 1 ) to model nasality-related cues. With nasality representation pre-training, sup ervised con trastive learning (SupCon) is p erformed on an auxiliary sp eech corpus with phoneme alignmen ts (Khosla et al., 2020; Pana yoto v et al., 2015; Lugosch, 2019; McAuliffe et al., 2017; Gilk ey, 2026). The prop osed sc hema inv olves constructing an oral-con text versus nasal-context sup ervision signal and applying a sampling strategy that suppresses sp eaker and phonetic confounds b y creating p ositive pairing on the same v ow el from the same sp eak er and vo wel-restricted contrastiv e comparisons. With frozen-enco der VPD screening, the learned enco der is frozen and used as a feature extractor for VPD screening with light w eight classifiers, aggregating c hunk-lev el probabilities to yield recording-level screening decisions (in-domain and out-of-domain) using a fixed decision 3 threshold. This design separates representation learning from clinical classification, aiming to impro v e cross-domain robustness without adaptation to the target domain (Liu et al., 2025b). MA TERIALS AND METHODS Datasets and Prepro cessing Clinic al In-Domain Cohort The in-domain cohort of 82 patients was collected under standardized acoustic conditions in a clinical setting. Clinical lab els were assigned based on human sp ecialist sp eech-language pathology (SLP) p erceptual speech ev aluation as part of routine clinical assessment, supp orted by instrumental assessmen ts such as videonasoendoscopy (VNE) and/or nasometry when indicated. The VPD case cohort comprised 44 patien ts with clinically significant VPD as determined b y the treating SLP , whereas 38 control patients w ere identified as ha ving adequate v elopharyngeal function based on human SLP ev aluation. Cohort definition and cohort partitioning follow ed our established proto col for automated VPD detection and out-of-domain (OOD) v alidation (Alter et al., 2025a; Liu et al., 2025b). All recordings were resampled to 16,000 Hz and conv erted to mono. Eac h audio file w as segmented into multiple non-ov erlapping 0.5-second c hunks. F or files shorter than 0.5 s (and residual segments shorter than 0.5 s), we applied rep eating padding b y tiling the a v ailable audio con tent until reaching the 0.5-second target length (instead of zero-padding) to b etter preserve short-utterance acoustic c haracteristics. Eac h 0.5-second segmen t was treated as a modeling unit for feature extraction and c hunk-lev el inference. Out-of-Domain Cohort T o sim ulate real-w orld deplo ymen t under domain shift, w e relied up on an OOD test set constructed from publicly av ailable Internet sources. OOD con trol-group recordings were sourced from the Cen ters for Disease Control and Preven tion and the Eastern Ontario Health Unit, and OOD case/control lab eling and dataset curation follow ed the same proto col describ ed in a prior OOD v alidation study (Liu et al., 2025b). The resulting OOD set contains 131 recordings (70 con trols, 61 VPD cases). These public sources do not provide reliable sp eak er identifiers or comprehensiv e metadata, so eac h recording is treated as an indep endent ev aluation unit and r e c or ding-level p erformance is rep orted on the OOD set. Mo dels trained on the in-domain cohort wer e ev aluated directly on the OOD recordings without any r etr aining, fine-tuning, or c alibr ation to quantify robustness under domain shift, consisten t with prior practice in this clinical context (Liu et al., 2025b). The same pro cedure used in the clinical in-domain dataset to sample and segment recordings w as used for the OOD dataset. Nasality Pr e-T r aining Corpus T o learn a device- and con tent-robust representation of nasality prior to clinical classification, auxiliary pre-training on the Librisp e e ch Alignments dataset was p erformed (Gilkey, 2026; Lugosch, 2019). This dataset is derived from the LibriSp eech corpus (Pana y otov et al., 2015) and pro vides 16 kHz read English sp eech with word- and phoneme-lev el alignments generated b y the Montreal F orced Aligner (MF A) (McAuliffe et al., 2017). This publicly av ailable alignment resource w as introduced in prior w ork on sp eec h mo del pre-training for end-to-end sp oken language understanding (Lugosch et al., 2019). The alignments include phoneme b oundaries, enabling time-lo calized extraction of v ow el-centered segments. Using the phoneme-lev el alignmen t, we extracted short, vo wel-cen tered 4 acoustic segmen ts from each utterance. Each segment is indexed by a (vowel, sp e aker) key inferred from the filename and metadata. This key is relied up on to construct within-sp eaker and within-v ow el comparisons to minimize confounds from sp eak er identit y and vo w el conten t. An auxiliary binary sup ervision signal w as constructed for contrastiv e learning using a rule-based lab eling pro cedure deriv ed from phoneme alignments. Using the MF A-provided ARP Ab et phoneme b oundaries in the LibriSp eech Alignments dataset, each vo wel segment was extracted and assigned a con text-based lab el using its immediate left and right neighboring consonan ts. V ow els flank ed by t wo oral consonan ts (C–V–C, where C denotes a non-nasal consonant) were assigned to the oral core set, while vo wels flanked by tw o nasal consonan ts (N–V–N; N ∈ { M, N, NG } ) w ere assigned to the nasal strong set. Mixed con texts (C–V–N or N–V–C) w ere treated as nasal weak and excluded from SupCon training to reduce lab el noise from partial coarticulation. As basic qualit y con trol, we skipp ed utterances with missing audio bytes, required a 16 kHz sampling rate, and ignored v ow els at utterance b oundaries where a full left/righ t context is una v ailable. The sp eak er iden tity relied up on for same-sp eaker sampling was inferred from the utterance ID prefix (e.g., 6415 in 6415-116629-0034 ). These auxiliary lab els are used only for represen tation pre-training and are nev er used as clinical VPD diagnosis labels. All extracted segmen ts were resampled to 16 kHz, con verted to mono, and standardized to a fixed duration of 0.20 s (3200 samples) via center cropping (if longer) or zero padding (if shorter). Sup ervised Contrastiv e Learning for Nasality Represen tation Pair Construction and V owel-R estricte d Sup ervise d Contr astive Obje ctive A nasality enco der was pre-trained using a supervised con trastive learning (SupCon) pro cess (Khosla et al., 2020). This pro cess extends the foundational self-sup ervised SimCLR framework (Chen et al., 2020) by lev eraging lab el information to pull same-class samples together while pushing a wa y opp osite-class samples. A sampling strategy w as emplo yed sp ecifically designed to suppress sp eaker and phonetic confounds. Each training item pro duces t wo “views” ( x 1 , x 2 ) sampled from tw o differ ent segmen ts b elonging to the same class ( y ∈ { 0 , 1 } ), the same v ow el, and the same sp eak er. A vo wel ‘ v ’ is sampled from the set of vo w els that ha ve at least tw o oral segments and at least t wo nasal segmen ts. The class lab el ‘ y ’ is then sampled with equal probability . Finally , w e sample tw o distinct files from the corresp onding buc ket indexed by k ey ( v , sp eaker ) : ( x 1 , x 2 ) ∼ D y ,v , speaker , x 1 = x 2 . T o further reduce phonetic con tent leak age, the contrastiv e ob jectiv e is restricted to compare em b eddings within the same v ow el only . Cross-vo wel pairs are excluded from the denominator in the con trastive softmax. In each training step, we sample a mini-batch of B paired views, and the enco der outputs em b eddings { z (1) i , z (2) i } B i =1 , whic h we concatenate in to a set of 2 B ℓ 2 -normalized v ectors. Let y i denote the oral/nasal label and v i the v ow el ID. Because the em b eddings are ℓ 2 -normalized, their dot pro duct corresponds to cosine similarity , providing a scale-inv ariant measure of similarity commonly used in contrastiv e learning. Pairwise cosine similarities are computed and scaled b y a temp erature parameter τ to control the sharpness of the contrastiv e softmax distribution: s ij = z ⊤ i z j τ , τ = 0 . 07 . Self-similarities are mask ed ( i = j ) and comparisons are restricted to samples with the same vo wel ( v i = v j ). The p ositive set for anchor i consists of all samples j = i suc h that y j = y i and v j = v i . 5 The v ow el-restricted SupCon loss is: L = − 1 2 B 2 B X i =1 1 |P ( i ) | X p ∈P ( i ) log exp( s ip ) P a ∈A ( i ) exp( s ia ) , where A ( i ) = { j = i : v j = v i } and P ( i ) ⊂ A ( i ) . Enc o der Ar chite ctur e: W av2V e c2 with L ayer F usion and Partial Unfr e ezing A W av2V ec2-style transformer enco der is used as the bac kb one feature extractor (Baevski et al., 2020). The bac kb one is initialized from a W a v2V ec2-Large-960h pretrained chec kp oint that is stored lo cally (“wa v2vec2-large-960h-local”). The final K = 4 hidden lay ers are then fused with learnable weigh ts, and the p o oled represen tation is pro jected to a 256-dimensional embedding, where H ( ℓ ) ∈ R B × S × d denotes the hidden states from la yer ℓ . A weigh ted sum of the final four la yers is then computed: H fused = K X i =1 α i H ( L − K + i ) , α i = exp( w i ) P K j =1 exp( w j ) , where { w i } are learnable parameters and L is the total num b er of transformer la yers. Mean p o oling is then applied o ver the sequence dimension: h = MeanPool ( H fused ) ∈ R B × d , follo wed b y a tw o-la yer MLP pro jection head to pro duce a 256-dimensional embedding: z = Normalize BN ( MLP ( h )) ∈ R B × 256 . Em b eddings are ℓ 2 -normalized. Batch normalization is applied during training when the batch size is greater than 1. T o balance adaptation and stability , the backbone is frozen except for the last N = 4 transformer lay ers (and the enco der lay er normalization), while alw ays training the la y er-fusion w eights and the pro jection head. In summary , the first L − 4 transformer la yers are k ept fixed and only the last four la yers are fine-tuned during SupCon pre-training. T r aining Details The mo del is then trained using Adam W with weigh t decay 0.01 and tw o parameter groups to implemen t la yer-wise learning rates: (i) fusion/pro jection head parameters at 3 × 10 − 4 , and (ii) unfrozen bac kb one lay ers at 3 × 10 − 5 . Gradients were clipp ed to a maxim um norm of 5.0, mixed precision training used bfloat16, and training ran up to 20 ep o c hs with early stopping (patience = 6) based on the v alidation monitor b elow. A random 10% split of the auxiliary dataset w as used as v alidation (seed = 42). Batch size was auto-selected from {2048, 4096, 6144, 8192} to maximize throughput under GPU memory . Unless otherwise sp ecified, all W a v2V ec2 backbone weigh ts were initialized from the same W av2V ec2-Large-960h pretrained chec kp oint and loaded from a lo cally cac hed copy for training efficiency . R epr esentation Quality Monitor The em b edding space was ev aluated using a pairwise distance discrimination task on the v alidation split. Under matched v ow el and matched sp eaker, p ositive pairs are same-class (oral–oral or nasal– nasal) and negative pairs are cross-class (oral–nasal). Given em b eddings z 1 , z 2 , the Euclidean 6 T able 1: Key hyperparameters for nasality sup ervised contrastiv e (SupCon) pre-training. Comp onen t Setting Bac kb one W a v2V ec2-Large-960h (lo cal chec kp oint), last-lay er fusion Input sampling rate 16 kHz Segmen t duration 0.20 s (3200 samples), cen ter crop / zero pad Em b edding dimension 256 La yer fusion last K = 4 la yers, learnable softmax weigh ts Unfreezing last N = 4 transformer la yers + enco der lay er norm Loss v ow el-restricted sup ervised contrastiv e loss T emp erature τ = 0 . 07 Optimizer A dam W Learning rates head: 3 × 10 − 4 ; bac kb one: 3 × 10 − 5 W eigh t decay 0.01 Gradien t clipping max norm 5.0 Precision AMP bfloat16 Ep o c hs / early stop up to 20; patience 6 (monitor: v alidation pairwise accuracy; SupCon only) V alidation split 10% random split; seed = 42 Batc h size auto-selected from {2048,4096,6144,8192} distance w as computed: d = ∥ z 1 − z 2 ∥ 2 . Represen tation qualit y w as ev aluated using a distance-based pairwise discrimination task under matc hed sp eaker and matc hed vo w el. F or early stopping, v alidation pairwise accuracy is computed b y selecting a fixed distance threshold on the v alidation split and applying it consisten tly across v ow els. This monitor is used only to trac k representation learning during SupCon pre-training; it is not used for the downstream VPD screening classifier, whic h uses a fixed decision threshold on predicted probabilities. Ligh tw eigh t VPD Classification After pre-training, the enco der is frozen and 256-dimensional embeddings are extracted for eac h 0.5-second ch unk in the clinical datasets. Several light w eight classifiers are trained on top of these em b eddings using only the in-domain training data: logistic regression (LR), supp ort v ector mac hine (SVM), multila y er p erceptron (MLP), and XGBoost (Chen, 2016). These mo dels are computationally efficient and represent complemen tary decision functions (linear, margin-based, shallo w nonlinear, and gradient-bo osted trees), allowing a well-performing yet deploymen t-friendly classifier to b e selected via cross-v alidation without changing the underlying represen tation. F or all classifiers, a standardization step (z-score normalization) fit was applied on the training fold only . The h yp erparameters were selected via group-wise cross-v alidation on the in-domain training split using GroupKFold to prev ent sub ject leak age, where all recordings (and their constituent ch unks) from the same sub ject were kept in the same fold. The selection criterion was chosen to b e recording-level macro-F1 a veraged across folds, where c hunk-lev el probabilities w ere first aggregated within each recording. The searched grids were: • LR: C ∈ { 0 . 01 , 0 . 1 , 1 , 10 } (class-weigh t balanced). • SVM: w e tuned the kernel type and asso ciated hyperparameters (e.g., C for linear; C and γ 7 for RBF) using cross-v alidation (class-weigh t balanced; probability outputs enabled). • MLP: hidden sizes ∈ { (64) , (128 , 64) } , activ ation ∈ { relu , tanh } , and α ∈ { 10 − 4 , 10 − 3 } with early stopping. • X GBo ost: w e tuned standard gradient-bo osted tree hyperparameters (e.g., max depth, num b er of estimators, and learning rate) via cross-v alidation. F or brevity , the SVM results are rep orted without sp ecifying the kernel in the tables. The b est p erforming SVM configuration w as selected by cross-v alidation. After setting the hyperparameters, eac h classifier was refit on the full in-domain training split and ev aluated on the held-out test split. VPD Classification Baseline Mo dels T o ensure a fair and direct comparison with prior work, commonly used baseline feature extractors and classical classifiers are ev aluated under the same prepro cessing and ev aluation proto col. Fiv e feature extraction pip elines are implemen ted for each 0.5-second ch unk: • MF CC (baseline) (Da vis and Mermelstein, 1980): 40 MF CC co efficien ts p er c hunk, mean-p o oled o ver frames (40-d). • W av2V ec2-Large-960h (frozen) (Baevski et al., 2020): final-lay er hidden states mean- p o oled o ver time (1024-d). • HuBER T-Large (frozen) (Hsu et al., 2021): final-la yer hidden states mean-po oled (1024-d). • Data2V ec-Audio-Large (frozen) (Baevski et al., 2022): final-lay er hidden states mean- p o oled (1024-d). • Whisp er-Large-v2 enco der (frozen) (Radford et al., 2023): enco der hidden states mean-p o oled (1280-d). F our classifiers were ev aluated for eac h feature t yp e: SVM, logistic regression, MLP , and XGBoost (Chen, 2016) (20 feature-classifier pip elines). F or SVM, the kernel and asso ciated hyperparameters w ere selected through cross-v alidation. F or brevit y , SVM results are rep orted without kernel sp ecification. Mo del Ev aluation Recording-lev el screening p erformance is reported for b oth the in-domain clinical cohort and the OOD In ternet recordings. Each recording is segmen ted into non-ov erlapping 0.5-second ch unks and the classifier outputs a c hunk-lev el probability ˆ p i for eac h ch unk. F or a recording with N c hunks, a recording-lev el probability is computed by mean aggregation: ˆ p rec = 1 N N X i =1 ˆ p i . (1) A fixed decision threshold t = 0 . 5 is then applied to obtain the binary screening decision. F or the OOD In ternet recordings, each recording is treated as an indep endent ev aluation unit and the same aggregation and thresholding pro cedure is applied. 8 T o prev ent sub ject leak age (i.e., recordings from the same individual app earing in b oth the training and test sets), train/test splits are defined at the sub ject lev el suc h that no sub ject w as included in b oth the training and testing sets. Hyp erparameter selection was p erformed with group-wise cross-v alidation ( GroupKFold ), where all recordings (and their constituen t c hunks) from the same sub ject were assigned to the same fold. This design prev ents the mo del from exploiting rep eated recordings from the same individual across training and ev aluation. It should b e noted that this retrospective clinical cohort may exhibit demographic differences betw een cases and con trols (e.g., age and sex distributions), which can act as p otential confounders. F or the OOD dataset, sp eak er identities are not provided and cannot b e reliably inferred from the public sources. Therefore, sp eak er-disjoint ev aluation cannot b e enforced and instead, ev aluation is p erformed directly at the recording lev el without any retraining, fine-tuning, or calibration. All metrics are computed at the recording lev el, and accuracy , macro-precision, macro-recall, and macro-F1 are rep orted. F or eac h class c ∈ { 0 , 1 } (either con trol or VPD), precision, recall, and F1 are: Prec c = TP c TP c + FP c , Rec c = TP c TP c + FN c , F1 c = 2 Prec c Rec c Prec c + Rec c . (2) And macro-precision, macro-recall, and macro-F1 are computed as the un w eighted mean across classes: MacroPrec = 1 2 X c Prec c , MacroRec = 1 2 X c Rec c , MacroF1 = 1 2 X c F1 c . (3) A ccuracy is computed as the fraction of correctly classified recordings. RESUL TS Dataset Summary The in-domain cohort consists of 82 sub jects and was partitioned in to an in-domain 60-sub ject training set and a 22-sub ject held-out test set using a sub ject-disjoint split to preven t sub ject leak age. The training set comprised 28 con trols and 32 VPD cases with 345 recordings, while the held-out test set comprised 10 con trols and 12 VPD cases with 131 recordings. In the 60-sub ject training cohort, the con trols were 71.4% female with a mean age of 29 . 6 ± 11 . 8 y ears, while the VPD cases w ere 46.9% female with a mean age of 10 . 0 ± 3 . 8 y ears. In the 22-sub ject held-out test cohort, the controls w ere 70.0% female with a mean age of 30 . 8 ± 10 . 2 y ears, while the VPD cases w ere 41.7% female with a mean age of 9 . 1 ± 3 . 6 y ears. Each sub ject contribute d one or more recordings; therefore, although the split is defined at the sub ject level, model p erformance is rep orted at the recording level. The OOD set contains 131 recordings (70 controls, 61 VPD cases), collected under largely undo cumen ted recording conditions (device, environmen t, and channel c haracteristics), thereby in tro ducing substantial heterogeneit y . Because these public sources do not pro vide reliable sp eaker iden tifiers or comprehensiv e metadata, we treat each recording as an indep endent ev aluation unit and rep ort recording-lev el p erformance on the OOD set. The dataset for nasalit y SupCon pre-training includes 778,110 oral_core segments and 42,670 nasal_strong segments, with 406,473 nasal_w eak segmen ts set aside to reduce lab el noise. 9 (a) AH (b) IH (c) AE (d) EH oral_cor e nasal_str ong Figure 2: UMAP visualization of SupCon nasality embeddings on the auxiliary v alidation split. Each panel sho ws a single vo wel with a class-balanced subset of v ow el-cen tered segments (0.20 s). Poin ts are colored by the auxiliary nasalit y context lab el (oral_core vs. nasal_strong). V ow el lab els follow ARP Ab et notation from the forced-alignmen t annotations. Nasalit y Represen tation Pre-T raining V alidation Ev aluation is p erformed to determine whether the SupCon pre-training ob jective yields a meaningful nasalit y-fo cused embedding space under con trolled comparisons (matc hed sp eak er and matc hed v ow el). On the v alidation split, the nasality enco der achiev ed the highest v alidation pairwise accuracy at ep o ch 19. Using a fixed distance-based decision rule on the v alidation split to discriminate matched- sp eak er, matched-v ow el p ositiv e vs. negative pairs, the pairwise v alidation accuracy reached 0.724. This v alidation monitor is used only for SupCon pre-training early stopping and is separate from do wnstream VPD screening ev aluation. T o qualitativ ely assess separation in the learned embedding space, v alidation embeddings are visualized using UMAP for multiple represen tativ e vo wels (ARP Ab et lab els; e.g., AH, AE, IH, EH) with class-balanced subsets ( Fig. 2 ). Examination is performed to determine whether oral core and nasal strong segments form distinguishable clusters (or a consistent separation trend) within eac h vo wel, indicating that the embedding captures nasality-related structure b eyond vo wel iden tity . Across the examined v ow els, oral core and nasal strong segmen ts show partial separation, consisten t with the pairwise discrimination results. Screening Performance Under In-Domain and Out-of-Domain Ev aluation VPD screening p erformance is ev aluated using (i) baseline feature+classifier pip elines from the prior study ev aluation proto col (Alter et al., 2025a; Liu et al., 2025b) and (ii) the prop osed SupCon nasality 10 represen tation with ligh tw eigh t classifiers. T o streamline comparison and emphasize robustness, w e rep ort merged tables for in-domain and OOD ev aluation ( T ables 2 and 3 ). F or the in-domain held-out recordings, several pip elines achiev ed near-ceiling p erformance, i.e. mean p erformance at or near the upp er b ound observed on this standardized clinical dataset under the current ev aluation proto col. Multiple large pretrained sp eech representations reac hed 100% accuracy and macro-F1 of 1.000 (e.g., Whisp er and HuBER T with MLP/XGBoost), indicating that under con trolled recording conditions the screening task is highly separable for these data ( T able 2 ). Using frozen 256-d SupCon nasalit y embeddings, all ev aluated ligh tw eight classifiers (LR/SVM/MLP/X GBo ost) also achiev ed p erfect recording-lev el screening p erformance (accuracy = 100%, macro-F1 = 1.000). It should b e noted that such p erfect p erformance is sp ecific to this in-domain cohort and proto col; it is observ ed across m ultiple strong baselines and is consistent with the high separability of the standardized clinical recordings and the recording-lev el aggregation used in ev aluation, rather than implying uniformly p erfect p erformance in more heterogeneous settings. On the OOD dataset, p erformance drops substan tially across most baseline pipelines, consistent with a strong domain shift b etw een standardized clinical recordings and uncon trolled Internet audio ( T able 3 ). Among the baselines, MFCC+SVM is the strongest (macro-F1 = 0.612; accuracy = 64.1%), while large pretrained sp eech representations degrade mark edly (b est macro-F1 among them = 0.432). The prop osed SupCon nasalit y representation achiev es the b est o verall OOD performance, with macro-F1 = 0.679 and accuracy = 69.5% (MLP), improving ov er the strongest baseline by +0.067 macro-F1 and +5.4 accuracy p oints under the same ev aluation proto col and fixed threshold. T able 2: Recording-lev el p erformance on the in-domain held-out recordings (standardized clinical recordings; 131 recordings from 22 held-out sub jects). This table merges (i) all baseline pip elines under the prior study proto col with (ii) the new SupCon nasalit y representation with ligh tw eight classifiers. Bold highlights the prop osed metho d for ease of comparison. F eature / Metho d Classifier Accuracy Macro Prec. Macro Rec. Macro F1 Baselines (prior study pr oto c ol) Whisper MLP 1.000 1.000 1.000 1.000 Whisper XGBoost 1.000 1.000 1.000 1.000 Whisper SVM 1.000 1.000 1.000 1.000 Whisper Logistic Regression 1.000 1.000 1.000 1.000 HuBER T MLP 1.000 1.000 1.000 1.000 HuBER T XGBoost 1.000 1.000 1.000 1.000 HuBER T SVM 0.992 0.929 0.996 0.960 Data2V ec XGBoost 0.992 0.929 0.996 0.960 MFCC SVM 0.992 0.996 0.917 0.953 MFCC MLP 0.992 0.996 0.917 0.953 MFCC Logistic Regression 0.992 0.996 0.917 0.953 Data2V ec Logistic Regression 0.985 0.875 0.992 0.925 HuBER T Logistic Regression 0.985 0.875 0.992 0.925 MFCC XGBoost 0.985 0.913 0.913 0.913 Data2V ec SVM 0.969 0.800 0.984 0.867 Data2V ec MLP 0.954 0.750 0.976 0.821 W av2V ec2 XGBoost 0.946 0.731 0.972 0.801 W av2V ec2 SVM 0.946 0.731 0.972 0.801 W av2V ec2 MLP 0.930 0.700 0.963 0.767 W av2V ec2 Logistic Regression 0.907 0.667 0.951 0.724 Pr op ose d (SupCon nasality repr esentation; 256-d emb e ddings fr om 0.5 s chunks) SupCon Nasality (256-d) Logistic Regression 1.000 1.000 1.000 1.000 SupCon Nasality (256-d) SVM 1.000 1.000 1.000 1.000 SupCon Nasality (256-d) MLP 1.000 1.000 1.000 1.000 SupCon Nasality (256-d) XGBoost 1.000 1.000 1.000 1.000 11 T able 3: Recording-lev el p erformance on the out-of-domain test set (heterogeneous public In ternet recordings). The table merges (i) all baseline pip elines under the prior study proto col and (ii) the prop osed SupCon nasalit y representation with light w eight classifiers. All metrics use a fixed decision threshold of t = 0 . 5 . F eature / Metho d Classifier Accuracy Macro Prec. Macro Rec. Macro F1 Baselines (prior study pr oto c ol) MFCC SVM 0.641 0.763 0.663 0.612 MFCC Logistic Regression 0.603 0.745 0.628 0.560 MFCC XGBoost 0.550 0.754 0.579 0.473 MFCC MLP 0.512 0.619 0.540 0.432 W av2V ec2 MLP 0.512 0.619 0.540 0.432 W av2V ec2 Logistic Regression 0.504 0.588 0.532 0.427 Data2V ec SVM 0.504 0.605 0.533 0.419 Data2V ec MLP 0.489 0.537 0.515 0.417 Data2V ec Logistic Regression 0.473 0.495 0.498 0.413 W av2V ec2 SVM 0.504 0.671 0.535 0.402 Data2V ec XGBoost 0.481 0.527 0.509 0.397 W av2V ec2 XGBoost 0.489 0.571 0.518 0.393 HuBER T MLP 0.504 0.742 0.536 0.393 HuBER T Logistic Regression 0.489 0.738 0.521 0.364 HuBER T SVM 0.481 0.736 0.514 0.349 HuBER T XGBoost 0.481 0.736 0.514 0.349 Whisper Logistic Regression 0.473 0.735 0.507 0.334 Whisper XGBoost 0.473 0.735 0.507 0.334 Whisper MLP 0.473 0.735 0.507 0.334 Whisper SVM 0.466 0.233 0.500 0.318 Pr op ose d (SupCon nasality repr esentation; 256-d emb e ddings; r e c ording-level aggr egation) SupCon Nasality (256-d) MLP 0.695 0.712 0.683 0.679 SupCon Nasality (256-d) SVM 0.672 0.680 0.661 0.658 SupCon Nasality (256-d) Logistic Regression 0.664 0.662 0.662 0.662 SupCon Nasality (256-d) XGBoost 0.655 0.659 0.661 0.658 DISCUSSION This in v estigation addresses a practical question in sp eech-based digital health: how can we maintain the p erformance of a mo del used to screen for sp eec h pathology when moving from a regulated clinical setting in to an unregulated field-testing environmen t? Motiv ated by the h yp othesis that nasality- related cues may b e more stable across recording conditions than man y device- and en vironment- dep enden t artifacts, this study tested whether learning a nasality-focused representation prior to clinical classification improv es robustness under recording domain shift. This hypothesis was ev aluated by training mo dels on the in-domain clinical cohort and assessing p erformance on a separate OOD Internet set without any target-domain retraining, fine-tuning, or calibration under a fixed screening threshold. Under this proto col, the prop osed SupCon nasality representation ac hiev ed the b est OOD performance (macro-F1 = 0.679, accuracy = 0.695), improving o v er the strongest retained baseline (MF CC+SVM: macro-F1 = 0.612, accuracy = 0.641). In con trast, in-domain p erformance w as near-ceiling across multiple strong pip elines, underscoring that high in-domain accuracy do es not guaran tee deploy able robustness and motiv ating domain-robust ev aluation for VPD screening (Liu et al., 2025b). F our sp ecific con tributions should b e noted. First, this wor kflo w specifically studies VPD screening under substan tial domain shift, from standardized clinical recordings to heterogeneous real- w orld/Internet recordings, using a unified ev aluation proto col and a fixed screening threshold. Second, a supervised contrastiv e pre-training strategy is in tro duced that learns nasality-sensitiv e em b eddings using oral-con text v ersus nasal-context sup ervision deriv ed from phoneme alignmen ts, with sampling 12 constrain ts to reduce sp eak er and phonetic-con tent leak age. Third, a t wo-stage, deploymen t-friendly pip eline w as developed, with a frozen enco der feature extractor, light weigh t classifiers, and simple probabilit y aggregation. F ourth, this study provides con trolled comparisons against MF CC features and large pretrained sp eech represen tations under the same proto col, demonstrating improv ed robustness in OOD testing. Collectiv ely , these con tributions provide evidence consisten t with the h yp othesis that nasality-focused represen tation learning can impro ve robustness under recording- domain shift, and they suggest a practical path wa y to ward scalable VPD screening on consumer devices where recording conditions are inheren tly v ariable and uncontrolled. Represen tation Learning Under Domain Shift A p ossible explanation for domain shift is that models trained and tested only on standardized clinical recordings can lev erage recording-condition cues that are stable within a given setting (e.g., c hannel resp onse, compression c haracteristics, background noise profiles, or ro om acoustics) but do not reflect pathology . As a result, p erformance can app ear near-ceiling in-domain yet degrade sharply when those recording conditions change in real-world audio (Liu et al., 2025b; Ganin et al., 2016). In our in-domain cohort, several strong feature+classifier pip elines ac hieve p erfect recording-level p erformance under the current proto col, suggesting that the standardized clinical recordings are highly separable for this dataset and that recording-level aggregation further amplifies separability . P erfect in-domain testing results can therefore b e in terpreted as the upp er b ound for this sp ecific cohort and ev aluation setting; how ever, this p erformance cannot b e implied across non-standardized acoustic settings. SupCon pre-training pro vides a more direct mechanism to emphasize nasality-related structure. The oral-con text v ersus nasal-context sup ervision, together with same-speaker/same-v ow el p ositiv e pairing and v ow el-restricted contrastiv e comparisons, encourages embeddings to group according to nasalit y context while suppressing sp eak er iden tity and phonetic-conten t confounds (Khosla et al., 2020). This focus on nasality-related distinctions is consisten t with the improv ed out-of- domain screening p erformance observ ed without any target-domain adaptation (Liu et al., 2025b). F uture w ork will aim to mitigate p oten tial recording-condition shortcuts in the in-domain cohort b y quantifying recording qualit y and c hannel artifacts (e.g., SNR/noise level, rev erb eration proxies, co dec/compression indicators). A dditionally , p erforming sensitivit y analyses via stratification or exclusion of lo w-quality recordings ma y provide a clearer estimate of in-domain p erformance under v arying acoustic conditions. Implications for Digital Health Deplo yment The pip eline presented in this study is referred to as the “nasality pretrained screening (NPS)” pip eline, which is deplo yment friendly giv en the frozen enco der and light weigh t downstream classifier. This design supp orts real-w orld screening w orkflows, where recordings ma y be captured using diverse consumer devices and acoustic en vironments (e.g., home or w eb-sourced recordings), and inference can b e p erformed either on device or in a serv er-assisted manner dep ending on resource constrain ts. In addition, recording-level aggregation by a veraging ch unk probabilities provides a simple and in terpretable decision mechanism that can b e used consistently across settings, supp orting a screening w orkflow where repeated measurements ma y b e collected longitudinally . This deploymen t-orien ted framing is aligned with broader efforts in voice-based digital biomarkers and scalable screening pip elines b ey ond VPD (Liu et al., 2025a). 13 Limitations This study has sev eral limitations that should b e ac knowledged. First, the nasality pre-training sup ervision is deriv ed from phoneme-alignmen t context rules (oral vs. nasal neigh b oring consonants). Because this rule-based lab eling pro vides only an appro ximate proxy for nasalit y and may b e noisy or incomplete, the resulting pretrained representation ma y not capture all clinically relev an t v ariabilit y in co-articulation, sp eaking style, and severit y-dep endent acoustic patterns. Second, the OOD dataset may con tain uncontrolled confounders (device, en vironment, demographics, compression, and recording protocols), and the heterogeneous public In ternet sources pro vide limited metadata, whic h limits our abilit y to derive causal attribution of the p erformance changes to an y single factor (Liu et al., 2025b). How ever, the extreme v ariability of the OOD cohort likely exaggerates what w ould b e encountered in the field, which ma y under-estimate mo del p erformance. A dditionally , since reliable sp eaker identifiers are una v ailable in the public sources, we treat eac h recording as an indep enden t ev aluation unit. Y et this recording-lev el assumption may b e violated if some recordings are correlated (e.g., multiple clips from the same sp eaker). As such, future inv estigations should v alidate robustness under sp eaker-disjoin t OOD designs when identifiers are av ailable. Third, the in-domain clinical cohort is relatively small (only 22 sub jects in the held-out test split) and the near-p erfect performance under standardized conditions lik ely ov erestimate robustness in broader p opulations, different elicitation prompts, or alternativ e clinical w orkflows. Moreov er, the in-domain case and con trol groups may differ in demographic characteristics (e.g., age distributions), which could b e a significant confounding factor and should b e addressed in larger matc hed cohorts. Finally , a fixed screening threshold ( t = 0 . 5 ) w as used for simplicity and comparability across metho ds. In practice, the op erating p oint ma y need to be tuned to clinical priorities (e.g., prioritizing sensitivity for screening) and probabilit y calibration may b e required across deploymen t settings. F uture Directions Next steps include collecting multi-device datasets with standardized clinical metadata to b etter c haracterize which recording-condition factors (microphone response, ro om acoustics, noise, and compression) driv e generalization failures, and to supp ort principled robustness ev aluations under con trolled p erturbations. Additionally , the screening task will b e extended b ey ond binary detection to ward severit y grading and longitudinal monitoring of treatment resp onse. Metho dologically , exploring domain-robust ob jectiv es (e.g., domain-adv ersarial learning or correlation-alignmen t style regularization) may further reduce sensitivity to recording artifacts (Ganin et al., 2016; Sun and Saenk o, 2016). Finally , motiv ated b y deplo yment in resource-limited and multilingual settings, we aim to study cross-lingual generalization and multilingual VPD screening, with the goal of developing mo dels that main tain strong diagnostic p erformance across languages such as English and Spanish without requiring extensiv e language-sp ecific re-collection or re-training. CONCLUSION This study presen ts a nasalit y-fo cused representation learning framework to improv e the robustness of mo del-based VPD screening under substan tial recording-domain shift. Using sup ervised con trastive pre-training with oral-context versus nasal-context sup ervision, the proposed enco der learns nasalit y- relev an t cues while suppressing sp eaker- and phonetic-con tent confounds, enabling a frozen feature extractor with light w eight downstream classifiers for recording-level screening. Under standardized in- domain clinical recording conditions, p erformance w as near ceiling on the sub ject-disjoin t held-out test set. More importantly for deploymen t, the prop osed approac h improv ed OOD screening p erformance 14 on heterogeneous public Internet recordings without retraining or calibration, outp erforming the strongest retained baseline under the same ev aluation proto col and fixed threshold. Overall, these results suggest that explicitly targeting ph ysiologically meaningful attributes at the represen tation lev el can reduce reliance on recording artifacts and supp ort deploy able sp eech-based screening in real-w orld settings. F uture work will prioritize prosp ectiv e multi-devi ce data collection with standardized metadata and deploymen t-a ware calibration to establish clinically robust op erating p oin ts. CONFLICT OF INTEREST The authors declare that the researc h was conducted in the absence of any commercial or financial relationships that could b e construed as a p oten tial conflict of interest. FUNDING This w ork was supp orted by the Departmen t of Plastic Surgery at V anderbilt Univ ersity Medical Cen ter. A UTHOR CONTRIBUTIONS Author Contributions (CRediT): Conceptualization: W.L., B.M., Z.Y., M.E.P .; Metho dology: W.L., B.Q., B.M., Z.Y., M.E.P .; Softw are: W.L., B.Q.; Data curation: W.L., A.S., M.P ., S.D., S.B., I.G., M.G.; Data prepro cessing: W.L., A.S., M.P ., S.D., S.B., I.G., M.G.; F ormal analysis: W.L.; V alidation: W.L., A.S., M.P ., S.D., S.B., I.G., M.G.; Inv estigation (clinical data supp ort): A.S., M.P ., S.D., S.B., I.G., M.G., M.E.P .; Resources: M.E.P .; Visualization: W.L., B.Q.; W riting—original draft: W.L.; W riting—review & editing: all authors; Sup ervision: B.M., Z.Y., M.E.P .; Pro ject administration: W.L., M.E.P .; F unding acquisition: M.E.P . All authors read and appro ved the final manuscript. A CKNO WLEDGMENTS W e thank the Departmen t of Plastic Surgery at V anderbilt Universit y Medical Cent er for supp ort in clinical data collection and curation. D A T A A V AILABILITY The in-domain clinical recordings w ere collected and curated through the Department of Plastic Surgery at V anderbilt Universit y Medical Center. Due to priv acy and ethical restrictions, these clinical data are not publicly av ailable. Requests for access may be considered up on reasonable request to the corresp onding author and sub ject to applicable institutional appro v als and data use requiremen ts. The out-of-domain test audio samples were obtained from publicly a v ailable Internet sources; con trol samples w ere obtained from the Cen ters for Disease Control and Prev ention and the Eastern On tario Health Unit. 15 ETHICS ST A TEMENT This study was conducted after institutional review board approv al (IRB No. 212135) at Monro e Carell Jr. Children’s Hospital at V anderbilt. A retrosp ective review of data from the V anderbilt V oice Cen ter was performed. REFERENCES Noah Alter, Claib orne Lucas, R icardo T orres-Guzman, Andrew James, Amy Stone, Maria E Po w ell, Scott Corlew, W eixin Liu, Bow en Qu, Zhijun Yin, et al. F rom supp ort v ector mac hines to neural net works: adv ancing automated velopharyngeal dysfunction detection in patien ts with cleft palate. A nnals of Plastic Sur gery , 95(3S):S55–S59, 2025a. Noah Alter, Amy Stone, Maria P ow ell, Elisa J Gordon, Beyhan Anan, Usama Hamdan, Zhijun Yin, and Matthew E Pon tell. It’s time to define the global burden of velopharyngeal insufficiency . The Cleft Palate Cr aniofacial Journal , page 10556656251316084, 2025b. Alexei Baevski, Y uhao Zhou, Ab delrahman Mohamed, and Michael Auli. wa v2vec 2.0: A framework for self-sup ervised learning of sp eec h representations. A dvanc es in neur al information pr o c essing systems , 33:12449–12460, 2020. Alexei Baevski, W ei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, and Michael Auli. Data2v ec: A general framew ork for self-sup ervised learning in sp eech, vision and language. In International c onfer enc e on machine le arning , pages 1298–1312. PMLR, 2022. Tianqi Chen. Xgb o ost: A scalable tree b o osting system. Cornel l University , 2016. Ting Chen, Simon Korn blith, Mohammad Norouzi, and Geoffrey Hinton. A simple framew ork for con trastive learning of visual represen tations. In International c onfer enc e on machine le arning , pages 1597–1607. PmLR, 2020. Stev en Da vis and P aul Mermelstein. Comparison of parametric representations for monosyllabic w ord recognition in contin uously sp oken sentences. IEEE tr ansactions on ac oustics, sp e e ch, and signal pr o c essing , 28(4):357–366, 1980. Alex J DeGrav e, Joseph D Janizek, and Su-In Lee. Ai for radiographic co vid-19 detection selects shortcuts o ver signal. Natur e Machine Intel ligenc e , 3(7):610–619, 2021. Y arosla v Ganin, Evgeniya Ustinov a, Hana Ajak an, Pascal Germain, Hugo Laro chelle, F rançois La violette, Mario March, and Victor Lempitsky . Domain-adversarial training of neural net works. Journal of machine le arning r ese ar ch , 17(59):1–35, 2016. Rob ert Geirhos, Jörn-Henrik Jacobsen, Claudio Michaelis, Richard Zemel, Wieland Brendel, Matthias Bethge, and F elix A Wic hmann. Shortcut learning in deep neural netw orks. Natur e Machine Intel ligenc e , 2(11):665–673, 2020. Kim Gilk ey . gilk eyio/librisp eech-alignmen ts. Hugging F ace Datasets, 2026. URL https: //huggingface.co/datasets/gilkeyio/librispeech- alignments . Accessed 2026-02-02. Kelsey B Guyton, Mary J Sandage, Dallin Bailey , Nancy Haak, Lawrence Molt, and Allison Plum b. A cquired velopharyngeal dysfunction: survey , literature review, and clinical recommendations. A meric an journal of sp e e ch-language p atholo gy , 27(4):1572–1597, 2018. 16 W ei-Ning Hsu, Benjamin Bolte, Y ao-Hung Hub ert T sai, Kushal Lakhotia, Ruslan Salakh utdinov, and Ab delrahman Mohamed. Hub ert: Self-sup ervised sp eech representation learning b y masked prediction of hidden units. IEEE/ACM tr ansactions on audio, sp e e ch, and language pr o c essing , 29:3451–3460, 2021. Pranna y Khosla, Piotr T eterwak, Chen W ang, Aaron Sarna, Y onglong Tian, Phillip Isola, Aaron Masc hinot, Ce Liu, and Dilip Krishnan. Sup ervised contrastiv e learning. A dvanc es in neur al information pr o c essing systems , 33:18661–18673, 2020. W eixin Liu, Bow en Qu, Matthew E P ontell, Maria E Po well, Bradley A Malin, and Zhijun Yin. F rom v oice to diagnosis: A hybrid approach to m ulti-lab el disease classification with uncertaint y a wareness. In 2025 IEEE International Confer enc e on Bioinformatics and Biome dicine (BIBM) , pages 4776–4783. IEEE, 2025a. W eixin Liu, Bow en Qu, Amy Stone, Maria P ow ell, Shama Dufresne, Stephane Braun, Izab ela Galdyn, Mic hael Golinko, Zhijun Yin, and Matthew E Pon tell. Out of the lab oratory and into the clinic: Out-of-domain v alidation of machine learning mo dels for v elopharyngeal dysfunction detection. A nnals of Plastic Sur gery , pages 10–1097, 2025b. Andrés Lozano, Enrique Nav a, María Dolores García Méndez, and Ignacio Moreno-T orres. Computing nasalance with mfccs and con volutional neural netw orks. PloS one , 19(12):e0315452, 2024. Claib orne Lucas, Ricardo T orres-Guzman, Andrew J James, Scott Corlew, Am y Stone, Maria E P ow ell, Michael Golinko, and Matthew E Pon tell. Mac hine learning for automatic detection of v elopharyngeal dysfunction: a preliminary rep ort. Journal of Cr aniofacial Sur gery , 36(3):816–819, 2025. Loren Lugosc h. Librisp eech alignments, 2019. URL https://doi.org/10.5281/zenodo.2619474 . Loren Lugosc h, Mirco Ra v anelli, P atrick Ignoto, Vikran t Singh T omar, and Y oshua Bengio. Sp eech mo del pre-training for end-to-end spoken language understanding. arXiv pr eprint arXiv:1904.03670 , 2019. Vikram C Mathad, Nancy Sc herer, Kathy Chapman, Julie M Liss, and Visar Berisha. A deep learning algorithm for ob jective assessment of hypernasality in children with cleft palate. IEEE T r ansactions on Biome dic al Engine ering , 68(10):2986–2996, 2021. Mic hael McAuliffe, Mic haela So colof, Sarah Mih uc, Michael W agner, and Morgan Sonderegger. Mon treal forced aligner: T rainable text-sp eech alignmen t using k aldi. In Intersp e e ch , volume 2017, pages 498–502, 2017. V assil P anay otov, Guoguo Chen, Daniel P ov ey , and Sanjeev Khudanpur. Librisp eech: an asr corpus based on public domain audio b o oks. In 2015 IEEE international c onfer enc e on ac oustics, sp e e ch and signal pr o c essing (ICASSP) , pages 5206–5210. IEEE, 2015. Alec Radford, Jong W o ok Kim, T ao Xu, Greg Bro c kman, Christine McLeav ey , and Ily a Sutsk ever. Robust sp eech recognition via large-scale w eak sup ervision. In International c onfer enc e on machine le arning , pages 28492–28518. PMLR, 2023. Myranda Uselton Shirk, Catherine Dang, Jaew o o Cho, Hanlin Chen, Lily Hofstetter, Jack Bijur, Claib orne Lucas, Andrew James, Ricardo-T orres Guzman, Andrea Hiller, et al. Leveraging large language mo dels for automated detection of velopharyngeal dysfunction in patien ts with cleft palate. F r ontiers in Digital He alth , 7:1552746, 2025. 17 Bao c hen Sun and Kate Saenko. Deep coral: Correlation alignmen t for deep domain adaptation. In Eur op e an c onfer enc e on c omputer vision , pages 443–450. Springer, 2016. Y u Zhang, Jing Zhang, W en Li, Heng Yin, and Ling He. Automatic detection system for velopha- ryngeal insufficiency based on acoustic signals from nasal and oral channels. Diagnostics , 13(16): 2714, 2023. 18
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment