DeepStage: Learning Autonomous Defense Policies Against Multi-Stage APT Campaigns
This paper presents DeepStage, a deep reinforcement learning (DRL) framework for adaptive, stage-aware defense against Advanced Persistent Threats (APTs). The enterprise environment is modeled as a partially observable Markov decision process (POMDP)…
Authors: Trung V. Phan, Tri Gia Nguyen, Thomas Bauschert
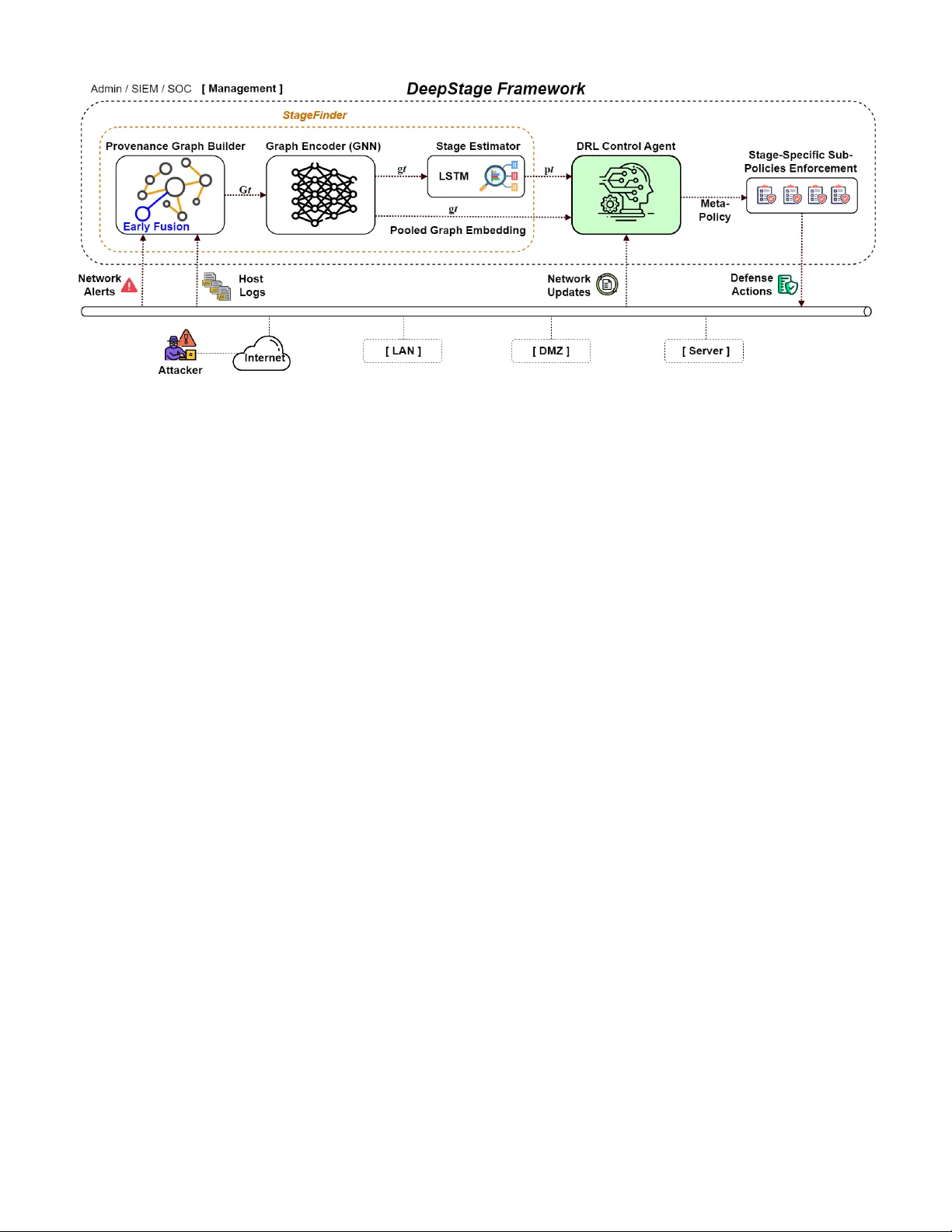
DeepStage: Learning Autonomous Defense Policies Against Multi-Stage APT Campaigns T rung V . Phan † , T ri Gia Nguyen § and Thomas Bauschert † † Chair of Communication Networks, T echnische Univ ersit ¨ at Chemnitz, 09126 Chemnitz, Germany § Faculty of Information T echnology , FPT Univ ersity , Da Nang 50509, V ietnam This paper is currently under revie w for IEEE CSR 2026. Abstract —This paper presents DeepStage , a deep r einfor cement learning (DRL) framework for adaptive, stage-aware defense against Advanced P ersistent Threats (APTs). The enterprise en vironment is modeled as a partially observable Markov de- cision process (POMDP), where host prov enance and network telemetry ar e fused into unified pro venance graphs. Building on our prior work [1], a graph neural encoder and an LSTM- based stage estimator infer pr obabilistic attacker stages aligned with the MITRE A TT&CK framework. These stage beliefs, combined with graph embeddings, guide a hierarchical Pr oximal Policy Optimization (PPO) agent that selects defense actions across monitoring, access contr ol, containment, and remediation. Evaluated in a realistic enterprise testbed using CALDERA- driven APT playbooks, DeepStage achieves a stage-weighted F1- score of 0.89, outperforming a risk-aware DRL baseline by 21.9%. The results demonstrate effective stage-aware and cost- efficient autonomous cyber defense. Index T erms —Advanced Persistent Threat (APT), Deep Rein- for cement Learning (DRL), A utonomous Cyber Defense, Prove- nance Graph Embedding. I . I N T RO D U C T I O N In recent years, Advanced Persistent Threats (APTs) [2] hav e emerged as a major security concern for enterprise, gov ernmental, and critical infrastructure networks. Unlike op- portunistic or commodity malware, APTs are characterized by stealthy operations, prolonged dwell times, and multi-stage at- tack progressions aimed at achie ving long-term objecti ves such as data exfiltration, cyber espionage, or operational sabotage. As reflected in the MITRE A TT&CK Enterprise matrix [3], an APT campaign typically e volv es through multiple stages, be- ginning with reconnaissance and initial compromise, followed by privile ge escalation, lateral mov ement, and ultimately data exfiltration or system disruption. Each stage often generates only subtle indicators that are interleav ed with benign system activity , making reliable detection particularly challenging [4]. T raditional signature-based intrusion detection and prevention systems (IDS/IPS) remain effecti ve against known threats but struggle to identify novel or ev olving T actics, T echniques, and Procedures (TTPs) [5]. Anomaly-based detection approaches provide broader co verage; howe ver , they often suf fer from high false-positiv e rates and limited ability to contextualize sequences of activities across time and hosts [6]. T o address these challenges, our prior work introduced StageF inder [1], a framew ork designed to estimate the current attack stage during an APT campaign. StageFinder continu- ously collects host-level system logs and transforms them into prov enance graphs that capture causal and temporal depen- dencies among system entities such as processes, files, users, and sockets. T o incorporate broader situational context, an early fusion mechanism integrates network-layer alerts—such as those generated by IDS or fire wall systems—directly into the prov enance graph. Each alert is modeled as a first-class node connected to relevant host entities, preserving semantic relationships between network anomalies and local acti vities. The resulting fused pro venance graph captures b oth intra- host and inter-netw ork dependencies within a unified causal representation. A graph neural network encoder is then ap- plied to extract low-dimensional embeddings that represent structural and contextual patterns within the graph. Finally , these embeddings are processed by a long short-term memory model to capture temporal dynamics and infer the attacker’ s probabilistic stage in the kill chain. As a continuation of our efforts to defend against APT attacks, this work proposes DeepStage , a unified and stage- aware APT defense framework that integrates pro venance graph embeddings with deep reinforcement learning (DRL). DeepStage builds upon our prior framework, StageF inder [1], by inheriting its network and system data processing pipeline as well as its output of probabilistic attack-stage estimates. Specifically , the inferred attack-stage probabilities, together with prov enance graph embeddings, are used to condition a hierarchical DRL agent. The agent operates under a partially observable Markov decision process (POMDP) formulation, enabling adaptiv e and stage-specific defense decisions in the presence of uncertainty and incomplete system visibility . Fur- thermore, the DRL agent has direct access to both system- lev el prov enance signals and network-lev el alerts, allowing it to make timely and context-aw are defensive responses. Experiments conducted in a realistic enterprise testbed us- ing CALDERA-driv en APT playbooks [7] demonstrate that DeepStage achiev es a stage-weighted F1-score of 0.89, out- performing a risk-aware DRL baseline by 21.9% in ov erall APT defense effecti v eness. I I . R E L A T E D W O R K A. DRL-based Autonomous Cyber Defense Deep Reinforcement Learning (DRL) has recently been explored for automated cyber-defense, where an agent learns response policies through interaction with a simulated secu- rity environment [8]. These systems typically model network defense as a sequential decision problem and train agents to select mitigation actions that balance detection ef fectiv eness, response latency , and operational cost. Sev eral DRL-based network intrusion response systems (NIRS) have been proposed to automate incident response [9]. In these frame works, the en vironment is represented by net- work alerts or host status indicators, and the DRL agent learns to deploy countermeasures such as traffic filtering or service isolation. Howe ver , most existing NIRS framew orks are designed for single-phase attacks (e.g., denial-of-service or network scanning) and operate primarily at the network perimeter . Consequently , they lack visibility into host-lev el behavior and cannot capture the sequential progression of Advanced Persistent Threats (APTs). As a result, their learned policies are lar gely reactiv e and respond to indi vidual alerts rather than anticipating the ev olution of multi-stage attacks. B. Risk-A war e DRL and Attack-Graph-Based Defense T o improv e situational awareness, several studies integrate attack-graph analysis with reinforcement learning to model the security state of enterprise networks [10]. In these approaches, nodes represent vulnerabilities or privile ge states, and edges encode potential attack paths. The DRL agent selects defensi ve actions that minimize the e xpected cumulativ e attack risk, often formulated as Δ ( total risk ) − 𝜆𝐶 ( 𝑎 ) , where 𝐶 ( 𝑎 ) denotes the operational cost of action 𝑎 . While attack-graph-based methods provide structured rea- soning about attacker movement, the y rely on static, pre- computed graphs generated by tools such as MulV AL. These representations do not capture temporal dependencies among system events and cannot reflect the dynamic and adaptive behaviors characteristic of real-world APT campaigns. Recent proactiv e DRL approaches attempt to predict attacker mov e- ment along possible attack paths [11]. Howe ver , these methods typically rely on coarse abstractions of network topology or host connecti vity and therefore lack the fine-grained behavioral context required to distinguish concurrent attack stages. C. Hierar chical and Constrained Reinforcement Learning Hierarchical DRL architectures hav e been proposed to ad- dress the complexity of large action spaces in cyber defense. DeepShield [12], for example, models reconnaissance-phase defense as a hierarchical control problem. A meta-agent de- tects suspicious scanning behavior and selects among se veral mitigation strategies executed by a lower-le vel agent, such as IP shuffling, software diversity , or component redundancy . Although hierarchical control impro ves scalability , DeepShield focuses primarily on early reconnaissance attacks and does not extend to later APT stages such as privilege escalation, lateral mov ement, or data exfiltration. Other approaches explore offline or constrained reinforce- ment learning for cyber defense [13]. These methods aim to learn safe policies from historical security logs while enforc- ing operational constraints. Howe ver , they generally do not incorporate explicit modeling of attack stages, limiting both interpretability and the ability to adapt defensiv e strategies across different phases of an attack campaign. D. Limitations of Existing DRL-based Defense Systems A key limitation of most DRL-based defense frame- works [9]–[13] is their reliance on flat feature-based state representations. T ypically , the system state is represented using aggregated indicators such as alert counts, vulnerability scores, or host states. These representations ignore the causal relation- ships among processes, files, users, and network connections. As a result, the learned policies cannot reason about ho w malicious activities propagate through system dependencies or ev olve across multiple hosts during an APT campaign. Prov enance graphs provide a richer representation for mod- eling system behavior . By capturing causal dependencies and temporal relationships among system entities, prov enance graphs enable fine-grained reasoning about attack progression and system compromise. Embedding such graphs into com- pact vector representations allows learning-based models to incorporate both structural and temporal context. E. Summary and Researc h Gap Although prior DRL-based cyber -defense systems demon- strate the potential for automated mitigation, the y remain limited in handling multi-stage APT campaigns. Attack-graph- based methods rely on static abstractions, hierarchical DRL framew orks focus on early-stage attacks, and feature-based models fail to capture causal dependencies in system activity . T o address these limitations, this paper proposes Deep- Stage , a stage-aware defense framework that integrates fused host–network prov enance graph embeddings with an LSTM- based stage estimator . Combined with a hierarchical Proximal Policy Optimization (PPO) agent, DeepStage enables adaptive, stage-aware defense policies that respond to the e volving tactics of advanced persistent threats. I I I . D E S I G N O F T H E D E E P S TAG E F R A M E W O R K A. Network En vir onment W e consider a representativ e enterprise network en viron- ment for data collection and analysis. The infrastructure is logically segmented into four zones—local area network (LAN), demilitarized zone (DMZ), server zone, and manage- ment zone—as illustrated in Fig. 1. The LAN hosts employee workstations and internal services, which often serv e as ini- tial entry points for attacks. The DMZ contains externally accessible services (e.g., web, email, and VPN) and acts as a buf fer between external and internal networks. The server zone stores critical assets such as database and authentication servers, frequently targeted in later stages of APT campaigns. The management zone hosts centralized monitoring and or- chestration components, where the DeepStage framew ork is deployed to collect telemetry from all zones while remaining isolated from external access. Network traffic is regulated by perimeter firew alls and analyzed by IDS/IPS sensors (e.g., Zeek), enabling the collection of both host- and network-le vel telemetry for subsequent data fusion. Fig. 1. Data and control flow of the proposed DeepStage framew ork. B. Operation of the DeepStage F r amework The proposed DeepStag e frame work operates as a closed- loop APT defense architecture that continuously collects sys- tem telemetry , models system behavior , and enables adaptive defensiv e actions. Figure 1 illustrates the data and control flow across the system components. 1) Data Acquisition: T wo primary data streams are col- lected across the enterprise network: ( i ) host-level logs from endpoint monitoring tools such as Auditd (Linux) and Sysmon (W indo ws), capturing e vents including process creation and file access; and ( ii ) network alerts generated by security sensors such as Snort or Zeek [14]. All ev ents are securely transmitted to the Management Zone for analysis. 2) Pr ovenance Graph Construction: The collected logs and alerts are parsed and correlated to construct a fused pr ovenance graph . Nodes represent system entities (e.g., processes, files, sockets, or alerts), while edges encode causal or data-flow re- lationships. Network alerts are incorporated through an early- fusion mechanism, linking network ev ents with host activities to form a unified causal representation. 3) Graph Embedding and Stag e Estimation: A graph neural network (GNN) encoder transforms the fused graph into a fixed-length embedding 𝑔 𝑡 , representing the system state at time 𝑡 . A sequence of embeddings { 𝑔 1 , . . . , 𝑔 𝑡 } is then processed by an LSTM-based stage estimator [1] that outputs a probability distribution 𝑝 𝑡 ov er APT stages defined by the MITRE A TT&CK framework. 4) Hierar chical DRL Defense: The combined state 𝑠 𝑡 = [ 𝑔 𝑡 , 𝑝 𝑡 ] is provided to a hierarchical DRL agent. The meta- policy interprets the estimated stage and selects a correspond- ing sub-policy to execute defensive actions such as host iso- lation, IP blocking, honeypot deployment, or alert escalation. 5) F eedback and Learning: Following each action, the en- vironment pro vides a re ward reflecting mitigation ef fecti veness and system stability . This feedback updates the DRL policy , enabling continuous adaptation to ev olving APT behaviors. I V . S T A G E - A W A R E D R L - B A S E D A P T D E F E N S E A. POMDP-Based System Model Advanced Persistent Threats are stealthy and multi-stage attacks whose activities are only partially observable through system logs and network alerts. Since the defender cannot directly observe the true system security state, the defense problem violates the full observability assumption of standard Markov Decision Processes (MDPs). Therefore, we model the defense en vironment as a P artially Observable Markov Decision Pr ocess (POMDP) [15]. Formally , the en vironment is defined as M = ( S , A , O , 𝑃, Ω , 𝑅 , 𝛾 ) , where S denotes latent system states, A the defense action space, and O the observation space. 𝑃 ( 𝑠 ′ | 𝑠 , 𝑎 ) represents state transitions, Ω ( 𝑜 | 𝑠 , 𝑎 ) the observation model, 𝑅 ( 𝑠 , 𝑎 ) the reward function, and 𝛾 the discount factor . This formulation enables the agent to reason over uncertain system states using belief representations deri ved from observable evidence. B. State Representation The hidden system state 𝑠 𝑡 reflects the underlying security posture of the enterprise network, including host compromise lev els and the attacker’ s progression stage. Because 𝑠 𝑡 cannot be directly observed, the agent maintains a belief state derived from observable telemetry . At each time step, host logs and netw ork alerts are fused into a prov enance graph 𝐺 𝑡 . A graph neural net- work (GNN) encoder produces a structural embedding 𝑔 𝑡 = 𝑓 GNN ( 𝐺 𝑡 ) , which summarizes system activity . Meanwhile, the Stage Estimator generates a probabilistic stage vector 𝑝 𝑡 = [ 𝑝 ( 0 ) 𝑡 , 𝑝 ( 1 ) 𝑡 , . . . , 𝑝 ( 𝐾 ) 𝑡 ] , where 𝑝 ( 𝑘 ) 𝑡 denotes the likelihood of APT stage 𝑘 and 𝑘 = 0 represents benign activity . The observation at time 𝑡 is defined as 𝑜 𝑡 = [ 𝑔 𝑡 , 𝑝 𝑡 , 𝑎 𝑡 − 1 ] , and a recurrent encoder updates the belief representation 𝑏 𝑡 = 𝑓 LSTM ( 𝑏 𝑡 − 1 , 𝑜 𝑡 ) . The belief embedding 𝑏 𝑡 integrates struc- tural system context and stage inference, forming the state representation used by the DRL agent. C. Defense Action Space The action space A consists of practical countermeasures used in enterprise incident response: A = A 𝑚𝑜 𝑛 ∪ A 𝑎 𝑐𝑐 ∪ A 𝑐 𝑜𝑛𝑡 ∪ A 𝑟 𝑒𝑚 . Monitoring ( A 𝑚𝑜 𝑛 ) : Passi ve actions that increase situational awareness without disrupting operations, such as increasing log verbosity , triggering malware scans, or correlating alerts. Access Contr ol ( A 𝑎 𝑐𝑐 ) : Defensiv e actions that restrict privile ges or authentication, including disabling suspicious accounts, rev oking session tokens, or enforcing multi-factor authentication. Containment ( A 𝑐 𝑜𝑛𝑡 ) : Acti ve interventions that limit at- tacker movement, such as isolating compromised hosts, block- ing malicious IPs, or terminating suspicious processes. Remediation ( A 𝑟 𝑒𝑚 ) : Recovery actions that restore system integrity , including patching vulnerabilities, restoring configu- rations, and resetting security policies. This structured action space enables a hierarchical DRL agent to activ ate stage-specific sub-policies aligned with en- terprise defense workflo ws. D. Rewar d Design The re ward function balances two objecti ves: maximizing attack mitigation ef fectiv eness and minimizing operational disruption. The rew ard at time 𝑡 is defined as 𝑅 ( 𝑏 𝑡 , 𝑎 𝑡 ) = 𝑅 security ( 𝑡 ) − 𝜆𝐶 ( 𝑎 𝑡 ) , (1) where 𝑅 security measures the effecti veness of the chosen action in blocking or containing malicious activity , 𝐶 ( 𝑎 𝑡 ) represents the operational cost of executing action 𝑎 𝑡 , and 𝜆 is a global trade-off coefficient controlling the ov erall penalty strength. Because different APT stages pose different levels of risk, we introduce stage-aware weighting: 𝑅 ( 𝑏 𝑡 , 𝑎 𝑡 ) = 𝛼 𝑘 𝑅 security ( 𝑡 ) − 𝛽 𝑘 𝜆𝐶 ( 𝑎 𝑡 ) , (2) where 𝛼 𝑘 and 𝛽 𝑘 adjust the relativ e importance of security and operational cost at stage 𝑘 . T ypically , 𝛼 𝑘 increases for later stages (e.g., exfiltration), allowing more aggressive responses, while 𝛽 𝑘 decreases to reduce the penalty for disrupti ve con- tainment actions. E. Optimization Objective The goal of the defense agent is to learn a policy that maximizes the expected cumulativ e discounted rew ard: 𝐽 ( 𝜃 ) = E 𝜋 𝜃 " 𝑇 𝑡 = 0 𝛾 𝑡 𝑅 ( 𝑏 𝑡 , 𝑎 𝑡 ) # , (3) where 𝜋 𝜃 ( 𝑎 𝑡 | 𝑏 𝑡 ) is the policy parameterized by neural network weights 𝜃 . F . Hierar chical P olicy Structure T o reflect the multi-stage nature of APTs, we employ a hierarchical policy composed of a meta-policy and stage- specific sub-policies: 𝜋 𝜃 ( 𝑎 𝑡 | 𝑏 𝑡 ) = 𝜋 𝜃 meta ( 𝑘 𝑡 | 𝑏 𝑡 ) 𝜋 𝜃 𝑘 ( 𝑎 𝑡 | 𝑏 𝑡 ) , (4) where the meta-policy selects the current stage 𝑘 𝑡 , and the corresponding sub-policy determines the defense action. G. P olicy Learning via PPO T o optimize the hierarchical policy , we adopt Proximal Policy Optimization (PPO) [16], a stable policy-gradient algo- rithm suitable for high-dimensional and partially observable en vironments. PPO updates the policy parameters using the gradient ∇ 𝜃 𝐽 ( 𝜃 ) = E 𝜋 𝜃 [ ∇ 𝜃 log 𝜋 𝜃 ( 𝑎 𝑡 | 𝑏 𝑡 ) 𝐴 𝑡 ] , (5) where 𝐴 𝑡 = 𝑄 ( 𝑏 𝑡 , 𝑎 𝑡 ) − 𝑉 ( 𝑏 𝑡 ) denotes the advantage function. PPO enables stable policy updates while improving sample efficienc y in complex cyber -defense en vironments. V . P E R F O R M A N C E E V A L UA T I O N A. Contr olled T estbed Experiments are conducted in a controlled enterprise testbed consisting of 6 Ub untu (20.04 L TS) virtual machines (VMs) acting as enterprise hosts and one Kali Linux VM acting as the attacker . Each VM is provisioned with 4 vCPU and 8 GB RAM. A dedicated GPU workstation (i.e., NVIDIA R TX 3060, 32 GB RAM) hosts DRL training and hea vy computation. Network services (HTTP , SSH) are deployed across the host VMs; a Zeek sensor [14] is placed at the network edge to generate network alerts. B. Data collection and pr ovenance Host telemetry is captured via auditd and osquery ; kernel- lev el provenance is collected using CamFlow [17]. Zeek produces network ev ents, which are con verted into Alert nodes and fused into the provenance graph (early fusion). Snapshots are constructed every Δ 𝑡 = 300 seconds to form 𝐺 𝑡 , and a GNN graph encoder produces embeddings 𝑔 𝑡 ∈ R 128 . C. Attack generation W e use MITRE Caldera [7] to generate realistic, A TT&CK-aligned adversary beha viors for DRL training and ev aluation. Caldera’ s modular “ability” and “adver - sary” playbook model lets us script end-to-end multi-stage campaigns (reconnaissance → initial compromise → privilege escalation → lateral mo vement → C2 → exfiltration) and vary timing, techniques, and targets programmatically , which is ideal for producing large numbers of labeled episodes. In our pipeline, Caldera driv es attacker actions against the enterprise VMs while host telemetry and network sensors collect the prov enance. Each playbook execution is annotated by a con- troller that records ground-truth stage labels and timestamps, enabling per-snapshot labeling for stage-estimator training and rew ard shaping for the DRL agent. Specifically , we le verage 10 T ABLE I S E T O F P R AC TI C A L S U B - P O L IC I E S D E PL OYAB L E . C O S T 𝐶 ( 𝑎 ) D E N OT ES T HE NO R M A LI Z E D O P ER ATI O NA L I M PAC T . Meta- policy Sub-policy Deployment in T estbed Cost 𝐶 ( 𝑎 ) A mon 𝑎 0 : Maintain baseline monitoring Keep auditd.conf , CamFlow , and Zeek agent in baseline mode 0.01 𝑎 1 : Increase host logging level Modify auditd.conf , CamFlow , and Zeek agent policies to capture process and socket events 0.05 𝑎 2 : Activ ate Deep Packet Inspection T emporarily enable Zeek full packet capture on target subnets 0.10 𝑎 3 : Memory/process snapshot Use volatility or psrecor d via management API to collect runtime memory dump 0.20 𝑎 4 : Deploy honeypot redirect Deploy Cowrie SSH honeypot or redirect via iptables DNA T 0.25 𝑎 5 : Log enrichment with threat intel Query local MISP feed and annotate alerts with TTP tags in prov e- nance database 0.10 𝑎 6 : Trigger system audit scan Run osqueryi snapshot to collect running processes, loaded modules, and sockets 0.15 𝑎 7 : Initiate cross-host correlation scan Run graph-matching between host provenance graphs to detect coor- dinated anomalies 0.20 A acc 𝑎 8 : Disable risky services Stop insecure services ( telnetd , ftp ) via systemctl 0.20 𝑎 9 : Rotate user credentials Force password reset or SSH key rotation through LD AP/AD 0.30 𝑎 10 : Enforce 2F A/MF A on pri vileged ac- counts Integrate P AM-based OTP for sudo/SSH login attempts 0.40 𝑎 11 : Revok e active sessions T erminate processes with ele vated privile ges or kill suspicious user sessions 0.25 𝑎 12 : Privilege escalation blocklist Apply AppArmor/Seccomp policy limiting setuid/setcap operations 0.20 𝑎 13 : Enable strict sudo logging Configure /etc/sudoers for detailed audit logs and restricted group access 0.15 𝑎 14 : Lock compromised accounts Disable login for suspicious users ( usermod -L ) 0.30 A cont 𝑎 15 : Block malicious IP or domain Apply iptables or Zeek blacklist rule; block known C2 endpoints 0.20 𝑎 16 : Throttle suspicious network flows Use tc qdisc or SDN API to rate-limit outgoing traffic 0.25 𝑎 17 : Micro-segmentation Apply dynamic bridge or Open vSwitch rules to limit host-to-host communication 0.35 𝑎 18 : Kill malicious process Send SIGKILL / SIGSTOP to identified malicious PID 0.20 𝑎 19 : Network interface isolation T emporarily down network interface ( ifdown eth0 ) for suspect host 0.80 𝑎 20 : Contain file I/O access Apply read-only permissions to sensitive directories via chattr +i 0.40 𝑎 21 : Block USB/external device usage Disable usb-storage kernel module 0.50 A rem 𝑎 22 : Emergency patching Run apt-get upgrade –only-upgrade to patch known CVEs 0.40 𝑎 23 : Remove persistence artifacts Delete malicious autoruns, crontab, rc scripts, or binary replacements 0.30 𝑎 24 : Rollback system to snapshot Use OpenStack/QEMU snapshot restore for infected VM 0.90 𝑎 25 : Clean DNS and FW rules Remove temporary defense rules after validation 0.15 𝑎 26 : Restore from backup Recover critical files or configurations from safe backups 0.80 𝑎 27 : Permanent hardening of policies Persist firewall, auditd, and sudo settings to prev ent recurrence 0.20 𝑎 28 : Re-enable normal operation Reconnect host to main VLAN after verification 0.20 base Caldera playbooks [7], and generate randomized variants from each to increase variety and prev ent overfitting. D. Meta-policy and sub-policies T o enable realistic and fine-grained defense decisions within the emulated enterprise network, each meta-policy in the DeepStage frame work is decomposed into multiple sub- policies that correspond to concrete, automatable defensive actions. These sub-policies are carefully selected to align with the system components av ailable in the testbed, and can be e xecuted safely through the management controller via REST automation on the target host. T able I summarizes all practical sub-policies and their normalized operational costs 𝐶 ( 𝑎 ) , which are later incorporated into the DRL reward formulation. It is noted that the action 𝑎 0 , representing the baseline monitoring mode , is ex ecuted under normal system conditions when no attack is detected ( 𝑘 =0). E. Rewar d computation The DRL agent receiv es a scalar reward, 𝑅 ( 𝑏 𝑡 , 𝑎 𝑡 ) = 𝛼 𝑘 𝑅 security − 𝛽 𝑘 𝜆𝐶 ( 𝑎 𝑡 ) , at each time step 𝑡 . In particular , 𝑅 security ( 𝑡 ) ∈ [ 0 , 1 ] quantifies the normalized security impr ove- ment observed between time steps. Let 𝑘 𝑡 and 𝑘 𝑡 + 1 denote the ground-truth APT stages at time 𝑡 and 𝑡 + 1 , respectiv ely . Then, 𝑅 security ( 𝑡 ) is defined as 𝑅 security ( 𝑡 ) = 1 , if 𝑘 𝑡 + 1 < 𝑘 𝑡 , 0 . 5 , if 𝑘 𝑡 + 1 = 𝑘 𝑡 , 0 , if 𝑘 𝑡 + 1 > 𝑘 𝑡 . (6) This piecewise formulation provides an intuitiv e and discrete rew ard signal: actions that successfully driv e the adversary to an earlier or less critical stage yield the highest rew ard ( 𝑅 security = 1 ), while actions that merely stabilize the system provide partial credit ( 𝑅 security = 0 . 5 ). Conv ersely , if the at- tacker advances to a more se vere stage, the rew ard drops to T ABLE II P P O T R A I NI N G PA RA M E T ER S F O R T H E D E E P S TAG E D R L - B A SE D A P T D E F E NS E . Parameter V alue / Range Description Actor network 3-layer MLP Input: fused graph embedding ( 𝑔 𝑡 ) + stage belief ( 𝑝 𝑡 ); Output: probability over meta/sub-policy actions. Critic network 3-layer MLP Estimates value 𝑉 ( 𝑜 𝑡 ) for baseline; shared first layer with actor . Optimizer Adam ( 𝛽 1 = 0 . 9 , 𝛽 2 = 0 . 999 ) Adaptiv e optimization for actor and critic updates. Learning rate ( 𝜂 ) 3 × 10 − 4 (decay 0.99 per epoch) Stable step size for PPO gradient updates. Discount factor ( 𝛾 ) 0 . 99 Long-term credit assignment for delayed APT mitigation rewards. GAE parameter ( 𝜆 GAE ) 0 . 95 Balances bias and variance in advantage estimation. Clipping threshold ( 𝜖 ) 0 . 2 Controls update size to maintain stable policy improvement. Entropy coefficient ( 𝑐 ent ) 0 . 01 – 0 . 05 Encourages exploration over meta/sub-policy choices. V alue loss coefficient ( 𝑐 𝑣 ) 0 . 5 Balances critic loss contribution. Batch size 4096 transitions Number of samples per PPO update. Mini-batch size 512 Size for each gradient step in PPO optimization. Epochs per update 5 PPO passes per batch; stabilizes on-policy learning. Episode length 50–100 time steps Corresponds to one APT campaign (Caldera playbook). T raining episodes 2,000 T raining and fine-tuning in the enterprise testbed. Rew ard scaling Normalize to [ − 1 , 1 ] Ensures numerical stability for PPO. zero, signaling policy f ailure at time 𝑡 . 𝐶 ( 𝑎 𝑡 ) ∈ [ 0 , 1 ] repre- sents the normalized operational cost of the selected action 𝑎 𝑡 , defined according to T able I. The stage-specific coefficients 𝛼 𝑘 and 𝛽 𝑘 are chosen to emphasize later-stage mitigation, where decisive defense actions are critical, while encouraging conservati v e low-cost monitoring during early stages. T ypical settings are: 𝛼 𝑘 = [ 0 . 3 , 0 . 5 , 0 . 8 , 1 . 0 , 1 . 3 , 1 . 5 , 2 . 0 ] and 𝛽 𝑘 = [ 0 . 0 , 0 . 5 , 0 . 7 , 1 . 0 , 1 . 3 , 1 . 6 , 2 . 0 ] for 𝑘 = 0 , 1 , . . . , 6 , correspond- ing respectiv ely to the Normal, Reconnaissance, Initial Com- promise, Privilege Escalation, Lateral Movement, Command- and-Control, and Exfiltration stages. A typical cost scaling factor is set to 𝜆 = 0 . 1 . F . DRL parameter settings T able II summarizes the hyperparameter settings and net- work configurations used to train the PPO-based reinforcement learning agent in the DeepStage framework. These parameters are selected to ensure stable policy con ver gence and effecti ve learning under the partially observable and stage-specific APT defense [18], [19]. G. Benchmarking Baselines T o assess the performance of the proposed DeepStage framew ork, we benchmark it against the Risk-A war e DRL- based APT Defense approach [10]. This baseline integrates reinforcement learning with MulV AL-deri ved attack-graph modeling, where each state encodes the risk lev els associated with graph nodes and edges, and the action space comprises elev en predefined mitigation operations (e.g., patching, access restriction, or service isolation). The re ward function is defined as the net reduction in aggregate network risk minus the operational cost of the selected mitigation, thereby optimizing risk minimization under constrained defensi ve b udgets. This formulation represents a risk-centric defense paradigm that lev erages symbolic attack-graph reasoning rather than data- driv en behavioral modeling. Furthermore, we include a stage-unaw are v ariant of our framew ork, denoted DeepStage-Unawar e , to quantify the con- Fig. 2. Per-stage defense ef fectiv eness measured by Stage-weighted F1-score across the six APT phases. tribution of stage conditioning to overall performance. In this variant, the stage-specific weighting factors in the reward function are neutralized by setting 𝛼 𝑘 = 𝛽 𝑘 = 1 . 0 , resulting in a uniform reward across all APT phases. Consequently , DeepStage-Unaware learns a defense policy without explicit awareness of the attacker’ s progression along the kill chain, allowing direct ev aluation of the benefit provided by the proposed stage-aware reinforcement structure. H. Result Analysis a) Stage-weighted attack defense performance: Figure 2 illustrates the per-stage defense effecti veness in terms of stage-weighted F1-scores across the APT lifecycle. DeepStage achiev es the highest macro-average F1-score of 0.89, com- pared with 0.80 for DeepStage-Unaware and 0.73 for the Risk- A ware DRL baseline, corresponding to relativ e improvements of approximately 11.3% and 21.9%, respecti vely . The im- prov ement is most pronounced during the Lateral Mov ement and Command-and-Control stages, where DeepStage attains F1-scores of 0.87 and 0.92, representing relative gains of up to 15–20% over the baselines. These results confirm that the Fig. 3. Cost–effecti veness frontiers illustrating normalized security gain versus cumulativ e action cost. hierarchical PPO agent, when guided by stage-conditioned rew ards ( 𝛼 𝑘 , 𝛽 𝑘 ) , can adaptively allocate mitigation resources and sustain detection precision across ev olving APT stages. In contrast, the stage-unaware variant performs redundant actions during early stages, reducing its F1-scores by up to 10%, while the Risk-A ware DRL baseline lags across all stages due to its coarse, static attack-graph abstraction. b) Cost–Effectiveness Analysis: The cost–ef fectiv eness frontier in Figure 3 demonstrates that DeepStage achiev es consistently higher security gain for comparable operational cost levels. At the mid-range cost ratio ( 𝐶 ( 𝑎 ) / 𝐶 max = 0 . 5 ), DeepStage attains a normalized security gain of 0.65, outper- forming DeepStage-Unaware (0.54) and the Risk-A ware DRL baseline (0.43). This represents an average improv ement of approximately 23% and 51%, respectiv ely . Even under full budget allocation, DeepStage maintains a 15–25% margin in cumulativ e reward, indicating that the hierarchical PPO agent effecti v ely balances mitigation cost and defensiv e v alue. The stage-aware re ward shaping ( 𝛼 𝑘 , 𝛽 𝑘 ) enables strategic resource allocation—fa voring lightweight monitoring during early APT stages and escalating to containment or remediation only when high-confidence late-stage indicators emer ge. In contrast, the stage-unaw are variant triggers redundant actions in lo w- risk stages, while the Risk-A ware baseline remains ov erly conservati v e due to its coarse attack-graph abstraction. c) Learning Stability and Con ver gence: Figure 4 shows the PPO learning curves for the three ev aluated methods. DeepStage con ver ges approximately 1.7 × faster than both baselines, reaching a stable policy after about 900 episodes, while DeepStage-Unaware and the Risk-A ware DRL baseline require around 1600 and 1800 episodes, respectively . At con- ver gence, DeepStage achieves a normalized episodic reward of 0.91, compared with 0.84 for DeepStage-Unaware and 0.79 for the Risk-A ware model, yielding an average improvement of roughly 12%. This acceleration and stability arise from DeepStage’ s hierarchical PPO design, which decomposes the defense policy into four structured meta-policies, reducing the Fig. 4. Training con ver gence of hierarchical PPO across methods. Fig. 5. Defense responsiveness ov er APT stage transitions. effecti v e action-space complexity and enabling faster , more stable updates. The stage-conditioned rew ard shaping further enhances learning efficiency by providing phase-specific rein- forcement aligned with the attacker’ s progression. By contrast, the Risk-A ware baseline exhibits a flatter and slower con ver - gence curve due to its static, low-dimensional attack-graph state representation, which limits gradient feedback and delays policy stabilization. d) Stage-T ransition Responsiveness: Figure 5 shows the defense responsiveness of the three methods over successiv e time steps, where each step corresponds to a 300-second obser - vation window . DeepStage exhibits the most agile and timely adaptation, reaching a responsiv eness level of 0.90 by the fourth time step (approximately 20 minutes of emulated time) and stabilizing near 0.97 thereafter . In contrast, DeepStage- Unaware attains a maximum responsi veness of 0.86, while the Risk-A ware DRL baseline saturates around 0.71. This demonstrates that the stage-aware reinforcement mechanism in DeepStage enables rapid escalation of mitigation actions as the attack progresses through successiv e APT stages. The integra- tion of the LSTM-based stage estimator with the hierarchical PPO agent ensures that higher-confidence stage transitions trigger more assertiv e defensive policies, allowing the system to contain or remediate intrusions early . By comparison, the stage-unaware v ariant exhibits delayed responses during early- and mid-stage transitions, and the Risk-A ware baseline re- sponds conservati vely due to its static attack-graph abstraction and limited temporal sensitivity . V I . C O N C L U S I O N This paper introduced DeepStage , a unified deep rein- forcement learning framework for adaptiv e and stage-aware defense against Adv anced Persistent Threat (APT) attacks. DeepStage fuses multi-modal host and network provenance data into graph-based representations that capture structural and behavioral dependencies across enterprise systems. These fused graphs are encoded into low-dimensional embeddings and processed by an LSTM-based stage estimator to infer probabilistic beliefs of the attacker’ s current phase along the kill chain. The resulting stage probabilities, combined with graph embeddings, define the state representation for a hierar- chical PPO agent that organizes the defense policy into four interpretable layers: monitoring, access control, containment, and remediation. Through this design, DeepStage enables coordinated and context-a ware defense actions that adapt to the ev olving stages of sophisticated multi-stage attacks. Experimental re- sults demonstrate the effecti veness of the proposed framework in accurately estimating attack stages and improving the ov er- all effecti veness of autonomous mitigation strategies. Overall, DeepStage provides a principled and extensible foundation for autonomous APT defense by integrating situational awareness, temporal reasoning, and resource-aware decision-making in enterprise security en vironments. V I I . F U T U R E R E S E A R C H D I R E C T I O N S As future work, we plan to extend the DeepStage frame work in sev eral directions to further enhance the transparency and operational usability of autonomous cyber defense. First, we aim to incorporate explainable artificial intelligence (XAI) techniques into the DeepStage pipeline to provide interpretable insights into both attack-stage estimation and defense policy decisions. By identifying critical provenance subgraphs, in- fluential system ev ents, and ke y state features dri ving miti- gation actions, XAI-guided mechanisms can improve analyst trust and enable evidence-dri ven verification of automated responses. Moreov er , explanation signals can be lev eraged to guide reinforcement learning optimization, allo wing the defense policy to align more closely with interpretable at- tack e vidence. Second, we plan to explore the integration of large language model (LLM)-based security operations center (SOC) assistants that translate the structured outputs of DeepStage into human-readable incident reports, attack timelines, and mitigation rationales. Such LLM-assisted SOC capabilities can facilitate more effecti ve human–AI collabo- ration by helping analysts rapidly understand system alerts and defense recommendations. T ogether , these directions aim to bridge the gap between autonomous cyber defense and practical security operations, enabling more trustworthy and interpretable protection against multi-stage APT campaigns. A C K N O W L E D G M E N T This work has been performed in the framework of the SUST AINET -Advance project, funded by the German BMFTR (ID:16KIS2280). R E F E R E N C E S [1] T . V . Phan et al. , “Learning the apt kill chain: T emporal reasoning over provenance data for attack stage estimation, ” in IEEE International Confer ence on Communications (ICC) , 2026. Accepted for publication. A vailable on http://arxiv .org/abs/2603.07560. [2] A. Alshamrani et al. , “ A survey on advanced persistent threats: T ech- niques, solutions, challenges, and research opportunities, ” IEEE Com- munications Surveys & T utorials , vol. 21, no. 2, pp. 1851–1877, 2019. [3] T . M. Corporation, “Mitre att&ck®: A knowledge base of adversary tactics, techniques, and common kno wledge. ” https://attack.mitre.or g, 2023. Accessed: 2026-03-08. [4] B. Zhang et al. , “ A survey on advanced persistent threat detection: A unified framework, challenges, and countermeasures, ” A CM Comput. Surv . , vol. 57, Nov . 2024. [5] N. H. A. Mutalib et al. , “Explainable deep learning approach for advanced persistent threats (apts) detection in cybersecurity: A re view , ” Artificial Intelligence Review , v ol. 57, no. 11, p. 297, 2024. [6] R. A. Bridges et al. , “ A survey of intrusion detection systems leveraging host data, ” A CM Comput. Surv . , vol. 52, Nov . 2019. [7] T . M. Corporation, “MITRE Caldera: Automated Adversary Emulation Platform, ” 2024. Open-source adversary-emulation system used for breach-and-attack simulation of APT playbooks. [8] T . T . Nguyen et al. , “Deep reinforcement learning for cyber security , ” IEEE T ransactions on Neural Networks and Learning Systems , v ol. 34, no. 8, pp. 3779–3795, 2021. [9] M. Reaney et al. , “Network intrusion response using deep reinforcement learning in an aircraft it-ot scenario, ” in Pr oceedings of the 19th International Conference on A vailability, Reliability and Security , ARES ’24, Association for Computing Machinery , 2024. [10] A. T . Le et al. , “ Automated apt defense using reinforcement learning and attack graph risk-based situation awareness, ” in Pr oceedings of the W orkshop on Autonomous Cyber security , AutonomousCyber ’24, (New Y ork, NY , USA), p. 23–33, Association for Computing Machinery , 2024. [11] F . T erranova et al. , “Le veraging deep reinforcement learning for c yber- attack paths prediction: Formulation, generalization, and evaluation, ” in Pr oceedings of the 27th International Symposium on Researc h in Attacks, Intrusions and Defenses , RAID ’24, (New Y ork, NY , USA), p. 1–16, Association for Computing Machinery , 2024. [12] Y . Cao et al. , “Deep-shield: Multiphase mitigation of apt via hierarchical deep reinforcement learning, ” IEEE Internet of Things Journal , v ol. 12, no. 15, pp. 30970–30982, 2025. [13] A. W ei et al. , “Of fline reinforcement learning for autonomous cyber de- fense agents, ” in 2024 W inter Simulation Confer ence (WSC) , pp. 1978– 1989, 2024. [14] V . Paxson and T . Z. Project, “Zeek: The Network Security Monitor (for- merly Bro). ” https://zeek.org/, 2019. Open-source network monitoring framew ork. Accessed: 2026-03-08. [15] L. P . Kaelbling, M. L. Littman, and A. R. Cassandra, “Planning and others, ” Artificial Intelligence , vol. 101, no. 1–2, pp. 99–134, 1998. [16] J. Schulman, F . W olski, P . Dhariwal, et al. , “Proximal policy optimiza- tion algorithms, ” arXiv pr eprint arXiv:1707.06347 , 2017. [17] T . Pasquier et al. , “Practical whole-system provenance capture, ” in Symposium on Cloud Computing (SoCC’17) , ACM, 2017. [18] J. Baptista, “Ppo hyperparameter optimization, ” PhD W eekly Report , 2024. Discusses hyperparameter ranges and effects specifically for Proximal Policy Optimization. [19] A. Filali et al. , “Dynamic SDN-based radio access network slicing with deep reinforcement learning for URLLC and eMBB services, ” IEEE T ransactions on Network Science and Engineering , vol. 9, no. 4, pp. 2174–2187, 2022.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment