Internalizing Agency from Reflective Experience
Large language models are increasingly deployed as autonomous agents that must plan, act, and recover from mistakes through long-horizon interaction with environments that provide rich feedback. However, prevailing outcome-driven post-training method…
Authors: Rui Ge, Yichao Fu, Yuyang Qian
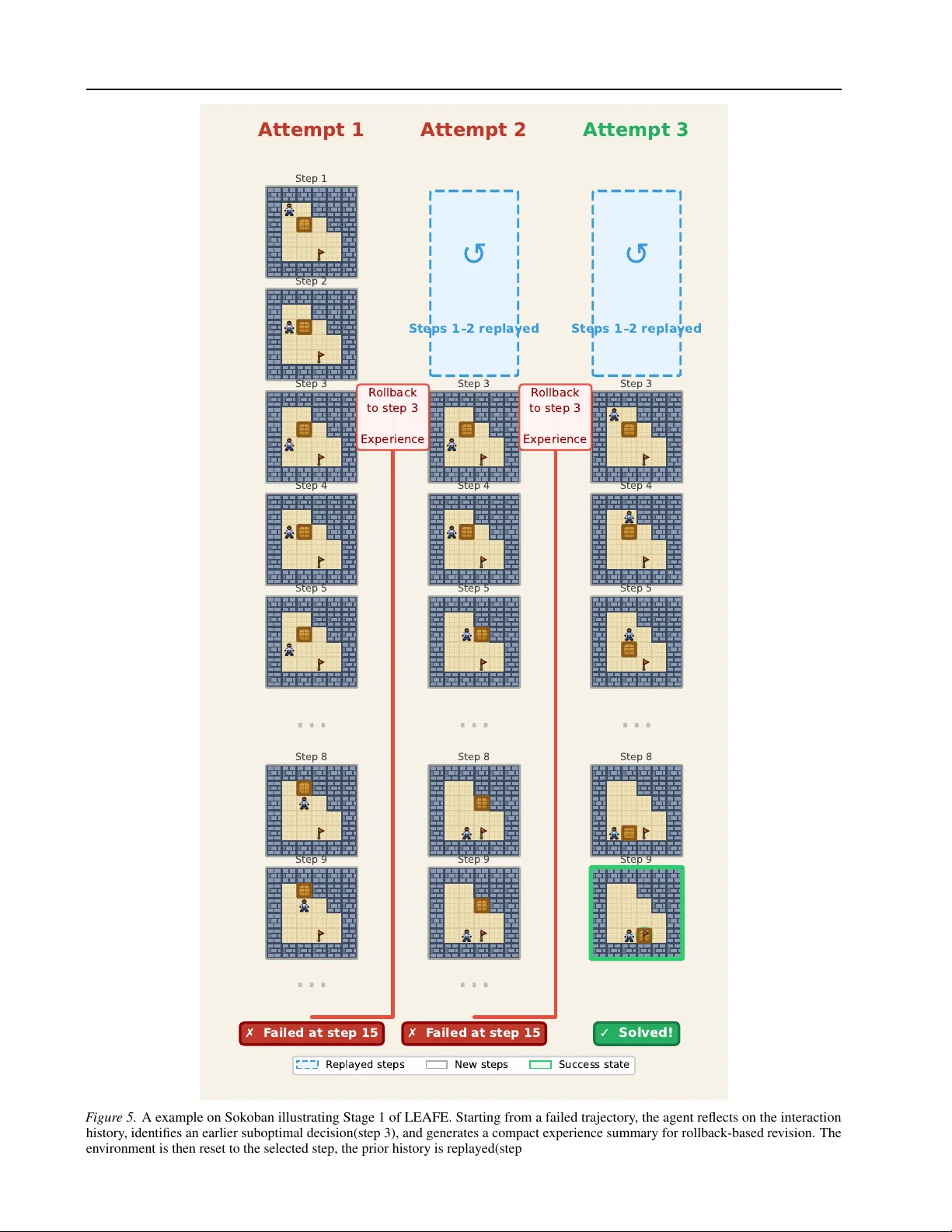
Internalizing Agency fr om Reflectiv e Experience Rui Ge 1 2 * Y ichao Fu 1 Y u-Y ang Qian 3 Junda Su 1 Y iming Zhao 1 Peng Zhao 3 Hao Zhang 1 Abstract Large language models are increasingly deployed as autonomous agents that must plan, act, and re- cov er from mistakes through long-horizon interac- tion with en vironments that provide rich feedback. Ho wever , prev ailing outcome-dri ven post-training methods (e.g., RL with verifiable rewards) primar- ily optimize final success signals, leaving rich en- vironment feedback underutilized. Consequently , they often lead to distribution sharpening : the policy becomes better at reproducing a narro w set of already-successful beha viors, while failing to improv e the feedback-grounded agency needed to expand problem-solving capacity (e.g., P ass@ k ) in long-horizon settings. T o address this, we propose LEAFE ( Learning F eedback-Gr ounded Agency from Reflective Ex- perience ), a framew ork that internalizes recovery agency from reflecti ve experience. Specifically , during e xploration, the agent summarizes en viron- ment feedback into actionable e xperience, back- tracks to earlier decision points, and explores alter- nati ve branches with revised actions. W e then dis- till these experience-guided corrections into the model through supervised fine-tuning, enabling the policy to recov er more ef fectiv ely in future in- teractions. Across a div erse set of interactive cod- ing and agentic tasks under fixed interaction b ud- gets, LEAFE consistently improv es Pass@1 ov er the base model and achiev es higher Pass@ k than outcome-dri ven baselines(GRPO) and experience- based methods such as Early Experience, with gains of up to 14% on Pass@128. 1. Introduction Large Language Models (LLMs) are rapidly shifting from passiv e r esponders to autonomous actors that plan, act, and adapt in complex en vironments. In interacti ve domains such * W ork done during an internship at UCSD. 1 Univ ersity of Cali- fornia San Diego 2 Shanghai Jiao T ong Univsersity 3 Nanjing Uni- versity . Correspondence to: Hao Zhang < haozhang@ucsd.edu > . Pr eprint. Mar ch 18, 2026. 1 2 4 8 16 32 64 128 256 512 1024 N u m b e r o f S a m p l e s ( k ) 0.0 0.1 0.2 0.3 0.4 0.5 0.6 Success R ate (pass@k) CodeContests Base GRPO Ours Ours+GRPO F igure 1. Internalizing feedback-grounded agency improves model capability (i.e., Pass@K) in long-horizon interaction, while outcome-only training (e.g., GRPO) yields limited gains beyond the base model. as web na vigation, program synthesis with ex ecution feed- back, and long-horizon task completion, an agent’ s success relies on agentic behavior : making a sequence of decisions, observing their consequences, and recovering from mistakes ov er time ( Y ao et al. , 2022b ; Nakano et al. , 2021 ), rather than solely producing a single-round response. Crucially , such en vironments provide rich and structured feedback (e.g., in valid actions, state transitions, and compiler errors) that goes beyond simple failure signals, often pinpointing why a trajectory becomes unproductive and ho w it can be corrected ( Y ang et al. , 2024 ; Shinn et al. , 2023 ). Thus, the central promise of agentic LLMs is not one-shot correctness, but rob ust decision-making under feedback: detecting when a trajectory is failing and updating actions accordingly . A common practice for post-training agentic LLM is outcome-based reinforcement learning with verifiable re- wards (RL VR): the agent samples multiple trajectories, re- ceiv es a single scalar rew ard for final task success (e.g., completion or pass/fail), and uses policy gradient to in- crease the likelihood of rewarded trajectories ( Guo et al. , 2025 ; Zeng et al. , 2025b ; Shao et al. , 2024 ). In long-horizon interacti ve settings, a single terminal scalar rew ard provides limited guidance: across many rollouts, only a small fraction is rewarded, so updates are dominated by a few rewarded (often already-competent) trajectories, and most partially- correct failures contribute little direct signal. As a result, RL VR often behav es like distribution sharpening : it con- 1 Internalizing Agency fr om Reflective Experience centrates probability mass on a small set of already-solv ed behaviors latent in long tail area of the base model, boosting Pass@1 b ut yielding limited or even ne gativ e gains at large k (e.g., Pass@1024) that more closely reflect coverage of the model capability ( Y ue et al. , 2025 ; Zhao et al. , 2025b ). This biases learning tow ard exploiting existing capabilities, rather than exploring beha viors outside the current support of the model’ s trajectory distrib ution. Consequently , practi- tioners hav e to rely on the expensiv e test-time computation (e.g., multiple retries, sampling-and-voting, or e xplicit tree search) to escape early mistak es, increasing both the latenc y and the deployment complexity ( W ang et al. , 2022b ; Y ao et al. , 2023 ; Fu et al. , 2025b ). This disconnect highlights a missing link in current agent training: the distinction between distrib ution sharpening and agency internalization . By agency internalization, we mean training the model to acquire an agentic capabil- ity(agency) of interacting with the en vironment, interpreting structured feedback, reflecting on what went wrong, and revising subsequent decisions accordingly . Outcome-driv en methods such as GRPO can upweight trajectories that end in success, but the y typically reduce interaction feedback (e.g., in valid actions, error messages, failed tests) to an episode- lev el scalar signal, providing weak supervision on where a trajectory went off course and what decision should change. In contrast, rob ust agency requires internalizing the recovery procedure itself: identifying the critical decision points that induced failure and revising them in a feedback-conditioned, targeted manner , rather than relying on blind retries or e xter- nal branching (e.g., T ree of Thoughts). Our goal is to make such feedback-grounded recov ery an intrinsic capability of the model, reducing reliance on heavy test-time sampling. As a pre view , Figure 1 shows that this form of internaliza- tion expands the model’ s effecti ve capability in long-horizon interaction, while RL VR exhibits little improv ement beyond the base model. In this work, we propose LEAFE ( Lea rning F eedbac k- Gr ounded Agency fr om Reflective E xperience ), a two-stage framew ork that explicitly teaches LLMs agents to acquire feedback-grounded agency from r eflective e xperience (i.e., the ability to use en vironment feedback to detect when a tra- jectory is failing and re vise decisions to recover). At a high lev el, outcome-driv en post-training methods such as GRPO, when trained with a scalar success re ward, tend to sharpen the policy within the model’ s existing capability support, fa voring exploitation o ver expanding exploration, whereas LEAFE trains the agent to repair trajectories that start to fail: instead of only reinforcing end-to-end successes, we explic- itly expose the model to f ailure cases, identify where they went wrong, and supervise the corrective re visions that turn them back into productive progress. T o be more specific, in stage 1 (§ 3.1 T r ee-Based Experience Generation with Rollback ), the agent periodically performs reflection and produces a rollback point τ and an experience summary (a brief diagnosis-and-fix instruction). W e then backtr ack to τ and branch with e xperience-guided revised actions, gen- erating trajectories that exhibit failur e → r ollback → fix → success (see T able 3 ). In Stage 2 (§ 3.2 Experience Distil- lation ), we internalize these improvements via e xperience- to-policy distillation , training the model to reproduce the post-rollback correctiv e decisions without providing experi- ence at test time (see T able 4 ). W e ev aluate LEAFE across a di verse set of agentic bench- marks that demand long-horizon interaction and error recov- ery , including CodeContests ( Li et al. , 2022 ), W ebShop ( Y ao et al. , 2022a ), ALFW orld ( Shridhar et al. , 2020 ), Science- W orld ( W ang et al. , 2022a ), and Sokoban( Schrader , 2018 ). Across tasks and fixed interaction budgets, LEAFE consis- tently improv es success rates and achieves stronger lar ge- k performance, substantially outperforming outcome-dri ven RL VR baselines such as GRPO in P ass@k efficienc y . These results highlight a central takeaw ay: by enabling back- track during exploration and learning from the resulting reflectiv e experience turns en vironment feedback into ac- tionable supervision, shifting the burden of competence from heavy test-time sampling to internalized, experience- driven agency . Our contributions are listed as follo ws: • Structur ed exploration via feedbac k-to-experience . W e propose reflecti ve backtracking that turns scalar sig- nals into e xperience-guided branches (rollback + cor- rection), enabling targeted e xploration beyond simple exploitation of base polic y’ s dominant modes. • Richer supervision than scalar r ewar ds. Our experi- ence trajectories provide decision-lev el reflect → r evise supervision, explicitly specifying where a rollout errs and how to fix it, rather than treating each rollout as an independent sample scored by a terminal rew ard. • Internalized r ecovery impr oves P ass@k. By fine- tuning on post-backtrack actions, we internalize feedback-grounded agency into the model weights, ex- panding behavioral cov erage and improving Pass@k in long-horizon interaction (up to 14% for Pass@128). 2. Background 2.1. LLMs as Interacting Agents Single-Agent Interaction. Follo wing the previous ReAct paradigm ( Y ao et al. , 2022b ), we view an interacti ve episode as an interlea ved sequence of textual observ ations and agent actions. Gi ven an instruction q ∈ Q , at step t the en viron- ment returns a textual observ ation o t , and the LLM-based 2 Internalizing Agency fr om Reflective Experience agent ( π θ ) outputs an ex ecutable action a t ∼ π θ ( · | h t , q ) , h t = ( o 0 , a 0 , . . . , o t − 1 , a t − 1 , o t ) . (1) A rollout (trajectory) is denoted by τ = ( q , o 0 , a 0 , . . . , o T ) , whose outcome can be ev aluated by a task-specific veri- fier/en vironment to produce a success or failure signal. 2.2. Reinfor cement Learning with V erifiable Rewards A common post-training paradigm for agentic LLMs is outcome-based RL with verifiable re wards (RL VR), where a programmatic verifier or en vironment signal assigns a scalar rew ard to a completed trajectory (e.g., success/failure or the number of passing tests). Representativ e algorithms include PPO ( Schulman et al. , 2017 ) and its variants, as well as group-based methods such as GRPO ( Guo et al. , 2025 ; Zeng et al. , 2025b ; Shao et al. , 2024 ). More concretely , giv en a group of sampled traces for the same problem, GRPO computes a normalized rew ard (or advanta ge) within the group to stabilize learning and encour - age relati ve improv ement among samples. The trace-le vel rew ard used by GRPO is computed as follows: ℓ i ( θ ) = min r i ( θ ) A i , clip( r i ( θ ) , 1 − ϵ, 1 + ϵ ) A i − β · KL , and J GRPO ( θ ) = E q , { o i } " 1 G G X i =1 ℓ i ( θ ) # , where KL ≜ D KL π θ ∥ π ref . Despite their success, outcome- based RL VR provides supervision only at the trajectory lev el, which makes credit assignment difficult for long- horizon generation and tool use. Moreover , because op- timization is driv en by rewards on sampled rollouts under a fixed training-time sampling procedure, such updates often r eweight or sharpen the model’ s behavior within its existing solution space, rather than reliably disco vering qualitativ ely new solutions. This moti vates a separate ev aluation of the model’ s capability under increased sampling b udgets. 2.3. LLM’ s Capability Boundary T o quantify a model’ s capability boundary (i.e., whether cor - rect solutions exist within its rollout distribution gi ven suf fi- cient sampling budget), we ev aluate Pass@ K , follo wing the capability-oriented e valuation protocol in prior w ork ( Y ue et al. , 2025 ). For each problem instance, we generate K rollouts from the agentic LLM. Each instance receiv es a bi- nary score: it is counted as 1 if at least one of the K rollouts successfully solves the problem under the task-specific veri- fier/en vironment, and 0 otherwise. W e then report Pass@ K as the av erage of these binary outcomes over the dataset. Importantly , P ass@ 1 corresponds to the single-rollout set- ting that is most relev ant for deployment, while Pass@ K (for large K ) estimates the model’ s best-of- K potential un- der large enough sampling b udget. In our e xperiments, we use a sufficiently large K (i.e., 128 ) to characterize the em- pirical boundary of the model’ s capability under the gi ven en vironment and interaction protocol, and we additionally use Pass@ 1 when assessing single-attempt ef fectiv eness. 3. Learning Fr om Reflective Experience This section introduces LEAFE, a two-stage framework for learning from reflective experience (see Figure 2 ). In Stage 1, we collect experience discov ered during exploration and use it as additional context to induce an experience- conditioned policy that revises decisions after rollback. The pseudo-code of the algorithm is sho wn in Algo 1 . In Stage 2, we distill these experience-conditioned policies into model parameters, so the resulting model internalizes the improve- ments without relying on explicit e xperience at test time. 3.1. T ree-Based Experience Generation with Rollback Setup and Notation. W e consider an episodic interacti ve en vironment E with a maximum horizon T . For a gi ven instruction q ∈ Q , an episode is characterized by a sequence of en vironment states { E t } T t =0 . At each time step t , the agent recei ves a textual observation o t and generates an ex ecutable action a t . A language-model polic y π θ induces a distribution o ver actions conditioned on the instruction and history as in Eq. 1 . The environment’ s transition dynamics are defined by a function Step( · ) : E t +1 , o t +1 ← Step( E t , a t ) , where ex ecuting a t in state E t transitions the en vironment to E t +1 and yields the subsequent observation o t +1 . An episode stops upon reaching the step limit T or encountering a terminal condition (e.g., success or irrev ersible failure). A r ollout is a complete attempt that executes the polic y from an initial state until termination. During rollout, the agent repeatedly produces actions, receiv es feedback from E , and appends the interaction to the history . Periodic Reflection. A fundamental challenge in le ver- aging experience is that linguistic feedback is inherently qualitativ e and unstructured, making it dif ficult to directly internalize into model weights via standard optimization. W e address this by treating experience as a contextual in- tervention that induces a policy shift via the input context. Inspired by rollback mechanisms ( Li et al. , 2025 ; W ang & Choudhury ), we allow the model to identify a suboptimal decision point and initiate a new ex ecution branch based on synthesized insights. Formally , ev ery K steps or upon failure, the agent in vokes a 3 Internalizing Agency fr om Reflective Experience Traje c t o r y Ass is t ant Obs 1 Ac t 1 Obs ? - 1 Ac t ? - 1 Obs ? Ac t ? ... ... R e f l ec t i on : Su b o p t im al ro u n d : ? R e as o n :.. . E x p er i en c e- au g m en te d p ro m pt ( Prompt + ( h ? , e) ) Ac t ? ' Prev io us His to r y ( h t ) E x p er i en c e( e ) Obs ? + 1 ' ... R ol lb ac k Tree ... Suc c e ss f u l Traje c t o r ies (i ) Beh av io r R eh e r s a l (i i ) E x p e r i e n c e- t o - Pol i c y Di s t i l l at io n (x t , a t ) p ai rs R a n d om Sam p l e R eh er sa l Dat ase t D reh : ( Promp t( h t ), a t ) R ef lec t io n + Bran c h in g E v en t s (x ? , a ? ' ) p ai rs Co un te r f ac t u al Dat as et D cf : ( Prompt ( h ? ), a ? ' ) St ag e 1 : Tre e - Bas e d Ex p er i e n c e G e n er a t i o n w it h R o l l b a c k St ag e 2 : E x p e r ie n c e Di s t i l l at i o n : R o llb a c k + Br anc hou t R ef lec t e ve r y K ro u nd s o r u p o n f ail F igure 2. Illustration of the LEAFE framework. Stage 1 : During experience collection, the assistant periodically revie ws the current trajectory and identifies a suboptimal round (denoted as red-colored τ ). It then produces the actionable e xperience e , which is concatenated with the restored history to facilitate subsequent attempts. Stage 2 : During experience distillation, the model optimizes a joint loss using two datasets: randomly sampled rehearsal pairs to maintain capabilities, and counterfactual pairs (original prompts paired with e xperience- improv ed actions) to internalize diverse e xploration. For simplicity , we depict one branching e vent from the rollback exploration tree. reflection procedure. Gi ven the interaction history h t and a reflection prompt p refl , the policy π θ generates a rollback target τ and an experience summary e : ( τ , e ) ∼ π θ ( · | h t , p refl ) , τ ∈ { 1 , . . . , t } . Here, τ indicates the time step where the trajectory de viated from the desired path, while e provides a natural-language diagnostic with actionable suggestions to guide the subse- quent attempt for the agent. Branching via Rollback. T o initiate a new execution branch from a rollback target ( τ , e ) , we first reconstruct the en vironment state E τ and its corresponding interaction history h τ . This is achiev ed by resetting the en vironment and replaying the original action sequence a 1: τ − 1 to reach the decision point τ . Under the guidance of the synthesized experience e , the polic y generates a revised action: a ′ τ ∼ π θ ( · | h τ , q , e ) . Executing a ′ τ transitions the environment to a ne w successor state E ′ τ +1 ← Step( E τ , a ′ τ ) , ef fectively branching the tra- jectory aw ay from the original suboptimal path. The agent then continues the rollout from E ′ τ +1 until the next periodic reflection or episode termination. W e manage branching requests using a queue-based Breadth- First Search (BFS) strategy . By iterativ ely selecting targets from the queue and generating new trajectories, the system constructs an implicit r ollbac k tree of experiences. Expan- sion continues until the e xploration reaches a maximum tree depth or exhausts the allocated attempt b udget. Figure 5 provides a concrete example from Sokoban to illustrate how Stage 1 performs reflection, rollback, and branch exploration in practice. 3.2. Experience Distillation Stage 2 distills the experience-induced policy improvements from Stage 1 into model parameters. W e construct two types of supervised data and perform standard next-token likelihood training. (i) Beha vior Rehearsal. T o mitigate catastrophic forget- ting and preserve the agent’ s fundamental task-solving ca- pabilities, we incorporate a rehearsal set D reh sampled from successful episodes. Inspired by rejection sampling ( Ahn et al. , 2024 ), we treat successful rollouts—including those generated through branching—as high-quality demonstra- tions. Specifically , for each successful trajectory , we extract state-action pairs ( h t , a t ) and optimize the rehearsal loss: L reh ( θ ′ ) = − E ( h,a ) ∼D reh [log π θ ′ ( a | h, q )] . By maximizing the likelihood of actions that led to terminal success state, this objecti ve ensures the polic y maintains a stable performance baseline while adapting to new insights. (ii) Experience-to-Policy Distillation. Our core supervi- sion is deri ved from the branching points identified during 4 Internalizing Agency fr om Reflective Experience reflection. When an experience e is injected at round τ to yield an improved action a ′ τ , we treat this action as a counter- factual tar get for the original history without the experience. The objecti ve is to internalize the policy shift—distilling the model’ s ability to correct its own mistakes into the model weights, e ven when the explicit natural-language guidance e is absent at test time. Specifically , for each branching e vent in D refl , we maximize the likelihood of the corrected action a ′ τ conditioned only on the original history h τ and instruction q : L cf ( θ ′ ) = − E ( h τ ,a ′ τ ) ∼D refl [log π θ ′ ( a ′ τ | h τ , q )] . By mapping the experience-augmented decision back to the experience-free conte xt, we effecti vely expand the model’ s policy space. This allows the agent to recov er from sub- optimal states by making corrected actions more probable under its intrinsic policy , thereby increasing success rate (e.g., pass@ k ) without requiring additional reflection steps during inference. T raining Objective. The final objective jointly optimizes counterfactual distillation and beha vior rehearsal: L ( θ ′ ) = L cf ( θ ′ ) + β L reh ( θ ′ ) , where β is a hyperparameter scaling the rehearsal strength. This multi-task formulation yields a distilled policy π θ ′ that preserves foundational task competence while inter - nalizing correcti ve strategies deri ved from experience. By enriching the polic y’ s intrinsic action distribution with these experience-induced alternativ es, we enhance exploration div ersity and significantly improve success metrics such as pass@ k under limited test-time sampling. 4. Experiment W e ev aluate our proposed frame work across a diverse range of agentic tasks, spanning from competitive programming to multi-step interactiv e reasoning in simulated physical and digital en vironments. Models. W e e valuate LEAFE using the Qwen2.5 (7B/72B) ( T eam et al. , 2024 ) and Llama-3/3.1 (8B/70B) ( Grattafiori et al. , 2024 ) series. These models are selected for their competiti ve performance and widespread adoption as standardized benchmarks in recent RL VR ( Zeng et al. , 2025b ; Shao et al. , 2025 ) and agentic reasoning ( Da et al. , 2025 ; Feng et al. , 2025 ) research. Their robust reasoning and instruction-follo wing capabilities provide a rigorous baseline to demonstrate that LEAFE enhances the fundamental agency of even the most capable and leading open-source models. Datasets. W e ev aluate LEAFE on four benchmarks that demand strategic interaction, long-horizon decision mak- ing, and mistake recov ery . (1) W ebShop ( Y ao et al. , 2022a ) requires agents to navigate over one million of products via multi-hop search and attribute matching; (2) ALFW orld ( Shridhar et al. , 2020 ) challenges the model’ s grounded common-sense reasoning in a te xt-based interacti ve en viron- ment aligned with embodied household tasks; (3) Science- W orld ( W ang et al. , 2022a ) presents a text-based scientific experimentation environment in which agents must solve multi-step tasks by interacting with objects, manipulating materials, and following procedural constraints; and (4) Sokoban ( Schrader , 2018 ) is a planning-intensive puzzle en vironment that requires precise sequential manipulation and effecti ve correction of earlier mistakes. In addition, we ev aluate on CodeContests ( Li et al. , 2022 ), a competitive programming benchmark with execution-based test-case verification. T ogether, these benchmarks assess an agent’ s broad ability to incorporate environmental feedback and recov er from errors across web navigation, embodied inter- action, scientific experimentation, and program synthesis. Baselines & Metrics. W e compare LEAFE against four baselines: Base (instruct model with no task-specific fine- tuning), GRPO-RL VR (outcome-supervised RL with v erifi- able final re wards using GRPO ( Guo et al. , 2025 )), EarlyExp (rew ard-free agent learning that con verts early interaction experience into supervision ( Zhang et al. , 2025a )), and A CE (a training-free, prompt-based method that improves agents by constructing e volving playbooks from execution feed- back ( Zhang et al. , 2025b )). W e report Pass@1 and Pass@128 (Sec. 2.3 ); Specifically , Pass@1 quantifies single-try pass rate as a measure of ex- ploitation ability . In contrast, Pass@128 estimates the best- of- k performance under a much larger sampling b udget, serving as a proxy for the model’ s exploration capacity and fundamental performance boundary . All our reported Pass@128 is computed from independent inference-time samples from the trained policy (i.e., without Stage 1 roll- backing or experience-guided branching). Implementation Details. For the interacti ve agentic bench- marks, we use verl-ag ent ( Feng et al. , 2025 ) as a unified framew ork for both training and ev aluation. For ALFW orld , W ebShop , and Sokoban , we directly adopt the settings and en vironment interfaces provided by the frame work. For Sci- enceW orld , which is not nati vely supported, we implement a compatible wrapper that follo ws the same verl-ag ent inter- face and training format. For CodeContests , we train with verl ( Sheng et al. , 2025 ) and follo w CTRL ( Xie et al. , 2025 ) for ex ecution-based ev aluation. For the baselines, GRPO-RL VR is obtained by directly train- ing the base model with GRPO. Since EarlyExp does not provide an of ficial codebase, we re-implement its core com- ponent, Implicit W orld Modeling (IWM), and use the verl SFT module for all supervised training stages; specifically , EarlyExp first performs IWM training on the base model 5 Internalizing Agency fr om Reflective Experience T able 1. Main results on four agent benchmarks. W e report Pass@1(%) and Pass@128(%) for two models per dataset. LEAFE consistently outperforms baselines across all tasks in terms of Pass@128. W E B S H O P A L F W O R L D Q W E N 2 . 5 - 7 B L L A M A 3 . 1 - 8 B Q W E N 2 . 5 - 7 B L L A M A 3 . 1 - 8 B M E T H O D P A S S @ 1 P A S S @ 1 2 8 P AS S @ 1 P A S S @ 1 2 8 P A S S @ 1 P A S S @ 1 2 8 P AS S @ 1 P A S S @ 1 2 8 B A S E ( N O F T ) 0 . 0 5 5 . 2 0 0 . 0 0 1 . 8 0 2 6 . 0 7 7 8 . 5 7 2 9 . 8 2 7 4 . 2 9 E A R LY E X P 6 1 . 5 5 8 4 . 6 0 5 1 . 1 3 7 7 . 8 0 7 2 . 2 3 9 2 . 8 6 7 4 . 1 5 9 5 . 7 1 G R P O - R L V R 6 7 . 4 5 8 5 . 4 0 5 4 . 9 5 7 9 . 4 0 6 9 . 4 6 9 1 . 4 3 7 2 . 5 0 9 4 . 2 9 AC E 6 8 . 6 5 8 6 . 8 0 5 4 . 3 5 7 9 . 8 0 6 6 . 3 4 8 9 . 6 3 7 0 . 3 2 9 2 . 5 0 L E A F E 6 6 . 5 0 8 7 . 8 0 5 6 . 2 5 8 1 . 0 0 6 7 . 5 0 9 4 . 2 9 7 1 . 7 9 9 6 . 4 3 S C I W O R L D S O KO BA N Q W E N 2 . 5 - 7 B L L A M A 3 . 1 - 8 B Q W E N 2 . 5 - 7 B L L A M A 3 . 1 - 8 B M E T H O D P A S S @ 1 P A S S @ 1 2 8 P AS S @ 1 P A S S @ 1 2 8 P A S S @ 1 P A S S @ 1 2 8 P AS S @ 1 P A S S @ 1 2 8 B A S E ( N O F T ) 7 . 0 0 4 7 . 3 3 7 . 1 7 4 8 . 6 7 6 . 9 0 4 3 . 8 0 1 7 . 7 0 6 1 . 4 0 E A R LY - E X P 2 6 . 1 7 5 4 . 6 7 2 4 . 0 4 5 6 . 0 0 6 0 . 1 5 7 1 . 6 0 5 7 . 3 2 6 8 . 2 0 G R P O - R L V R 2 7 . 1 7 5 7 . 3 3 2 4 . 2 5 5 6 . 0 0 5 8 . 1 5 6 8 . 0 0 6 0 . 4 3 7 3 . 4 0 AC E 2 9 . 4 5 5 9 . 6 7 2 5 . 2 8 5 7 . 3 3 6 1 . 3 0 7 0 . 8 0 6 0 . 7 9 7 3 . 2 0 L E A F E 2 7 . 8 8 6 2 . 0 0 2 2 . 7 0 5 9 . 3 3 6 4 . 6 0 7 8 . 4 0 6 2 . 0 0 7 7 . 2 0 and then further applies GRPO optimization. For A CE , we follo w the official repository’ s implementation on AppW orld for interacti ve tasks and extend the same playbook-based prompting strategy to our other benchmarks; A CE is ap- plied on top of the GRPO-trained model, while keeping the prompts and task ex ecution protocol consistent with verl- agent . Finally , our method, LEAFE, is also initialized from the GRPO-trained model and further optimized to enhance reasoning and exploration capabilities. 4.1. Main Results T able 1 summarizes our main results on four interactiv e agent benchmarks(W ebShop, ALFW orld, ScienceW orld, and Sokoban), across multiple backbone models from the Qwen2.5 and Llama3.1 families. T able 2 further presents results on CodeContests using larger backbone models. W e report both Pass@1 and P ass@128 to distinguish single-try accuracy from an agent’ s broader capability under increased sampling. Across benchmarks, LEAFE ’ s advantage is most pro- nounced at lar ge k . While GRPO can match or even ex- ceed LEAFE at Pass@1 in some settings, these gains often plateau as k increases. In contrast, LEAFE not only im- prov es Pass@1 ov er the base model, but also continues to yield larger impro vements at higher sampling b udgets. For example, on W ebShop with Qwen2.5-7B, GRPO achiev es a higher Pass@1, whereas LEAFE consistently attains a higher Pass@128. This behavior is consistent with distribu- tion sharpening in GRPO: it boosts the probability of sam- pling a small set of already-successful trajectories, boosting Pass@1 b ut offering limited additional coverage as k grows. The contrast is clearest on CodeContests, where LEAFE T able 2. Main results on CodeContests with larger backbone mod- els. LEAFE yields substantial improvements in Pass@128 com- pared with the GRPO-RL VR baseline. Note: EarlyExp and A CE are not reported on CodeContests because it is designed for inter - activ e environments and does not directly apply to code execution feedback without a different implementation. Q W E N 2 . 5 - 7 2 B L L A M A 3 - 7 0 B M E T H O D P A S S @ 1 P A S S @ 1 2 8 P A S S @ 1 P A S S @ 1 2 8 B A S E ( N O F T ) 1 0 . 0 0 3 3 . 9 4 7 . 3 5 2 4 . 8 5 G R P O - R L V R 2 0 . 4 5 3 6 . 9 7 1 3 . 6 4 2 7 . 8 8 L E A F E 1 7 . 1 2 4 7 . 8 8 1 4 . 0 9 33 . 9 4 T able 3. CodeContests Pass@128 under dif ferent sampling strate- gies with Independent Sampling (IS), Iterativ e Refinement (IR), and our stage 1. Model IS IR Ours (Stage 1) Qwen2.5-32B 48.92 51.48 55.52 Qwen2.5-72B 48.65 49.52 54.30 Llama3-70B 30.20 38.10 42.50 improv es Pass@128 by up to +14% over the base model, highlighting the benefit of internalizing feedback-grounded agency in domains that require iterativ e correction. Overall, the stronger large- k scaling indicates expanded beha vioral cov erage, i.e., the desired agency is trained into the model to better reflect and progress in long-horizon interaction. 4.2. Capability Scaling: Pass@k Analysis Figure 3 studies Pass@ k scaling as the sampling budget k increases. Giv en the different interaction costs and task characteristics, we cap the budget at k =256 for ALFW orld, k =512 for ScienceW orld, and k =1024 for CodeContests. 6 Internalizing Agency fr om Reflective Experience T able 4. Experience-to-Policy distillation impro ves Pass@128. Model pass@1 pass@128 L reh L cf + L reh L reh L cf + L reh Qwen2.5-7B 27.67 27.88 59.33 62.00 Llama3.1-8B 22.54 22.70 57.33 59.33 Qwen2.5-14B 37.17 36.50 67.33 72.00 Higher upper bound. Across all three benchmarks, our method consistently achieves the best performance in the large- k regime, indicating a genuine improvement in the model’ s capability ceiling. The gain is particularly pro- nounced on CodeContests, where the mar gin remains sub- stantial ev en at the largest b udget. Better sample efficiency . As illustrated in Figure 3 , our approach reaches the same accuracy threshold with fewer samples, and after a moderate budget, it maintains a higher success rate than the baselines at the same k , i.e., it dom- inates the scaling curve beyond a certain point. Overall, these results show that our method improves both the attain- able performance ceiling and the efficienc y of con verting additional samples into higher success rates. 4.3. Effectiveness Analysis T ree-Based Experience Generation with Rollback. T a- ble 3 compares three ways of spending the same e xecution budget on CodeContests, where each attempt can be ex e- cuted and returns compiler/runtime outputs and test feed- back. Independent Sampling draws independent solutions; Iterativ e Refinement updates the next attempt based on the previous ex ecution result; our Stage 1 sampling performs tree-based experience-guided rollback branching to explore alternativ e fixes at critical failure points. Across all models, our sampling strate gy yields the highest Pass@128, showing that structured, feedback-driv en branching is more effecti ve than either independent sampling or linear refinement for discov ering successful programs under a fixed budget. Experience-to-Policy Distillation. T able 4 compares train- ing with rehearsal alone ( L reh ) vs. rehearsal plus counter- factual distillation ( L cf + L reh ) on ScienceW orld. L reh follo ws a reject-sampling style scheme ( Ahn et al. , 2024 ): it filters out failed trajectories and imitates decisions from successful rollouts, which helps preserve competent be- haviors b ut of fers limited guidance on how to revise a tra- jectory once it starts to fail. Adding L cf , which is the key that distills experience-guided corrections, lar gely im- prov es Pass@128 across model sizes while k eeping Pass@1 comparable (e.g., 59 . 33% → 62 . 00% on Qwen2.5-7B and 67 . 33% → 72 . 00% on Qwen2.5-14B). This suggests that experience-to-polic y distillation L cf is crucial for internal- izing correctiv e revisions, while L reh mainly stabilizes and T able 5. OOD Generalization on MBPP (trained on CodeContests). V alues are Pass@128 (%). Red superscripts indicate the absolute drop relati ve to the corresponding base model, while blue super - scripts indicate the absolute gain. GRPO suffers clear degradation under distribution shift, whereas LEAFE better preserves OOD performance and can ev en surpass the base model. Method Qwen2.5-32B Qwen2.5-72B Llama3-70B Base (No-train) 85.45 83.33 78.31 GRPO 81.22 − 4 . 2 81.22 − 2 . 1 74.07 − 4 . 2 Ours 85.45 +0 . 0 85.13 +1 . 8 79.63 +1 . 3 T able 6. Ablation study on the impact of auxiliary training tar- get (i.e., EarlyExp(EE) and GRPO(RL)). Results are reported as Pass@ 1 / Pass@ 128 (%). While additional training tar get consis- tently enhances greedy precision (P ass@ 1 ), it may occasionally constrain the exploration ceiling (P ass@ 128 ). T ask Model Ours Ours + Enhancement ALFW orld Qwen2.5-7B 67.50 / 94.29 67.86 / 95.71 (w/ EE) Llama3.1-8B 71.79 / 96.43 74.46 / 93.57 (w/ EE) CodeContests Qwen2.5-32B 9.34 / 34.35 14.09 / 33.94 (w/ RL) Qwen2.5-72B 11.15 / 40.00 17.12 / 47.88 (w/ RL) Llama3-70B 9.33 / 30.30 14.09 / 33.94 (w/ RL) retains base behaviors. 4.4. Ablation Study Scaling Behavior Acr oss Model Sizes. As illustrated in Figure 4 , we observ e a consistent scaling trend in Pass@128 performance across all benchmarks. Specifically , increasing the model size from Qwen2.5-7B to 14B yields gains of +0.6% on W ebShop and +10.0% on ScienceW orld. Simi- larly , on CodeContests, the transition from Qwen2.5-32B to 72B results in a +13.9% improvement. Throughout these scales, our method consistently outperforms all baselines. The robustness of these gains across both Qwen and Llama architectures demonstrates that LEAFE ef fectively lev erages increased model capacity to raise the performance ceiling. Out-of-Distribution Generalization. T o ev aluate the Out- of-Distribution (OOD) generalization of our approach, we tested models trained on CodeContests on the held-out MBPP benchmark. As shown in T able 5 , our method shows superior rob ustness to distribution shift compared to the GRPO baseline. Notably , while GRPO leads to se vere per - formance drop on OOD tasks (e.g., -4.2% on Llama3-70B), our method not only mitigates this degradation but still keep- ing surpass the original base model’ s performance. This result suggests that LEAFE helps the model to learn funda- mental reflectiv e agency rather than simply ov er-fitting to dataset-specific shortcuts. Synergy and T rade-offs with A uxiliary T raining T ar - get. W e in vestigated into the synergy of LEAFE with EarlyExp and GRPO. As presented in T able 6 , integrat- ing these techniques consistently improves Pass@ 1 success 7 Internalizing Agency fr om Reflective Experience 1 2 4 8 16 32 64 128 256 512 1024 N u m b e r o f S a m p l e s ( k ) 0.0 0.1 0.2 0.3 0.4 0.5 0.6 Success R ate (pass@k) CodeContests 1 2 4 8 16 32 64 128 256 N u m b e r o f S a m p l e s ( k ) 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 ScienceW orld 1 2 4 8 16 32 64 128 256 512 N u m b e r o f S a m p l e s ( k ) 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 ALFW orld Base GRPO Ours+GRPO F igure 3. Scaling results on different benchmarks. W e plot the Pass@ k success rate as a function of the number of samples k . Our method (red) consistently achiev es higher efficiency and performance ceilings across all tasks compared to the baseline s. Qwen-7B Qwen-14B 60 80 SR (%) W ebShop W ebShop Qwen-7B Qwen-14B 0 50 SR (%) SciW orld SciW orld Qwen-32B Qwen-72B 0 20 40 60 SR (%) CodeContests CodeContests EarlyExp GRPO Ours P@1 P@128 F igur e 4. Main results on W ebShop and SciW orld. Bars represent Pass@1 (solid) and Pass@k (hatched) (%). Ours consistently outperforms GRPO and other baselines across different model architectures and scales. rates across all e valuated benchmarks: For instance, add EarlyExp to Llama3.1-8B on ALFW orld increases accuracy from 71.79% to 74.4%, while GRPO boosts Qwen2.5-7B on CodeContests from 11.15% to 17.12%. Howe ver , these gains in exploitation do not always translate to enhanced model capability at higher sampling budget. W e observe that Pass@ 128 performance can sometimes decline under auxiliary training target, notably for Llama3.1-8B (96.43% → 93.57%) and Qwen2.5-32B (34.35% → 33.94%), sug- gesting that while EarlyExp and GRPO ef fectiv ely align the primary training target, they may narro w the exploration space. In contrast, LEAFE consistently impro ves model’ s capacity as analyzed in § 4.1 . 4.5. Discussion and Limitation Beyond Distribution Sharpening: Internalizing Agency from Experience. Across tasks, LEAFE’ s gains are most pronounced at large k (e.g., Pass@128), where outcome- driv en training such as GRPO often plateaus despite oc- casional Pass@1 improvements. This is consistent with terminal scalar re wards mainly upweighting a small set of already-successful trajectories, while long-horizon suc- cess depends on tar geted, feedback-conditioned revisions. By generating repair-oriented rollback branches in Stage 1 and distilling the resulting correcti ve decisions in Stage 2, LEAFE internalizes feedback-grounded recovery into the model, improving both the Pass@ k ceiling and sample effi- ciency . Overall, our results suggest LEAFE expands beha v- ioral coverage by training agents to fix failing trajectories rather than relying on blind retries or external search. Limitation. LEAFE has the following limitations: For example, LEAFE is most effecti ve when the en vironment provides clear , diagnostic feedback; its benefits may dimin- ish when feedback is weak, delayed, or hard to attribute. Besides, LEAFE assumes the en vironment can be reliably reset to a rollback point, which can be difficult in non- deterministic or stateful real-world settings. 5. Related W ork LLM-based Agents. Large Language Models (LLMs) have ev olved from passiv e generators into autonomous agents capable of tool-use and multi-step reasoning. Early work largely relies on prompting to elicit agent beha viors without weight updates, including ReAct ( Y ao et al. , 2022b ), Refle x- ion ( Shinn et al. , 2023 ), and Tree of Thoughts ( Y ao et al. , 2023 ). Recently , reinforcement-learning (often RL VR) has become a major route to improv e reasoning robust- ness and long-horizon decision making, exemplified by DeepSeek-R1 ( Guo et al. , 2025 ) and OpenAI o1 ( Jaech et al. , 2024 ). Building on this direction, systems such as verl-agent/GiGPO ( Feng et al. , 2025 ), rLLM ( T an et al. , 2025 ), and Agent-R1 ( Cheng et al. , 2025 ) scale multi-turn RL for tool-using agents, while open-weight releases (e.g., Kimi K2 ( T eam et al. , 2025 ), GLM-4.5/4.7 ( Zeng et al. , 2025a ; Z.ai , 2025 ), MiniMax-M2 ( MiniMax , 2025 )) further accelerate reproducible agent research. 8 Internalizing Agency fr om Reflective Experience Reinfor cement Learning with V erifiable Rewards (RL VR). RL VR post-trains LLMs with automatically ver - ifiable signals (e.g., exact-match answers, unit tests, the- orem provers, or en vironment states), and has become a widely adopted recipe for improving reasoning on mathe- matics and programming-style tasks ( Guo et al. , 2025 ; Y u et al. , 2025 ). PPO ( Schulman et al. , 2017 ) is a standard baseline, while critic-free group-based optimizers such as GRPO ( Shao et al. , 2024 ; Guo et al. , 2025 ) and step-aw are variants like GiGPO ( Feng et al. , 2025 ) improve stability and credit assignment; these recipes hav e been reproduced and scaled in open settings (e.g., SimpleRL-Zoo ( Zeng et al. , 2025b ), ORZ ( Hu et al. , 2025 ), and Skywork-OR1 ( He et al. , 2025a )). Beyond sparse outcome re wards, recent work e x- plores denser step-wise supervision via process re ward mod- eling and automated process verifiers ( Setlur et al. , 2024 ) as well as implicit/dense re ward construction ( Cui et al. , 2025 ). RL VR is also being scaled and extended through ef ficient small-model RL scaling ( Luo et al. , 2025 ), budget-a ware optimization ( Qi et al. , 2025 ), and system-level accelera- tion (e.g., asynchronous rollouts) ( Fu et al. , 2025a ), and has expanded to ne w verifiable domains such as V erilog genera- tion ( Zhu et al. , 2025 ) and Lean-based theorem pro ving ( Ji et al. , 2025 ; Shang et al. , 2025 ). Self-Evolving LLM Agents. A growing body of w ork stud- ies how LLM agents can impro ve themselves through in- teraction, reflection, and accumulated experience. One line externalizes learning into prompts, memories, or reusable ex- perience libraries without directly updating model weights, as in ReasoningBank ( Ouyang et al. , 2025 ), FLEX ( Cai et al. , 2025 ), and A CE ( Zhang et al. , 2025b ). Another line per- forms tr aining-based self-ev olution by iterati vely turning in- teraction data into better policies, skills, or strategic abstrac- tions: SKILLRL ( Xia et al. , 2026 ) and EvolveR ( W u et al. , 2025 ) distill trajectories into reusable skills or principles, while Agent0 ( Xia et al. , 2025 ), Absolute Zero ( Zhao et al. , 2025a ), and CodeIt ( Butt et al. , 2024 ) further couple self- improv ement with automatic task generation, self-play style curricula, or hindsight relabeling. A third line focuses on test-time self-improv ement, either through lightweight test- time fine-tuning on synthesized data ( Acikgoz et al. , 2025 ) or through repeated e volution of prompts, memory , and tool-use configurations across attempts ( He et al. , 2025b ). Unlike these, our w ork emphasizes internalizing feedback- grounded exploratory experience into the policy itself for more effecti ve long-horizon agenc y . Learning From Experience. Learning from Experience is a long-standing goal in agentic systems. Before LLMs, model-based RL such as W orld Models ( Ha & Schmidhu- ber , 2018 ) and Dreamer ( Hafner et al. , 2023 ; 2020 ; 2023 ) learned latent dynamics to imagine future outcomes for planning. For LLM agents, recent work either internalizes experience into weights or stores distilled e xperience for retrie val: Early Experience (EarlyExp) ( Zhang et al. , 2025a ) learns from self-generated traces via implicit world mod- eling and self-reflection; Agent Q ( Putta et al. , 2024 ) com- bines guided MCTS and self-critique with of f-policy DPO to learn from both successes and f ailures; HOPE ( W ang & Choudhury ) uses hindsight counterfactual actions to driv e multi-turn RL exploration; and SP A ( Chen et al. , 2025 ) in- ternalizes world models via self-play finetuning. Closest to our setting, GA-Rollback ( Li et al. , 2025 ) triggers stepwise rollback to pre vent error propagation, while Ev olveR ( W u et al. , 2025 ) distills trajectories into reusable strategic prin- ciples. In contrast, our proposed LEAFE explicitly localizes critical failure points and internalizes corrective rollback experiences into a single-rollout polic y . 6. Conclusion In this paper , we introduce LEAFE, a frame work for train- ing LLM agents to internalize feedback-grounded agency through rollback and reflectiv e experience. Unlike outcome- based RL VR methods that rely on terminal scalar rew ards, LEAFE le verages structured exploration and en vironment feedback to identify where a trajectory fails and how it should be re vised, providing informativ e, step-le vel learning signals. Across long-horizon agentic benchmarks, LEAFE consistently improv es Pass@k efficiency ov er outcome- driv en baselines such as GRPO, particularly at lar ge k , re- flecting broader beha vioral coverage rather than increased concentration on e xisting successful modes. These re- sults demonstrate that internalizing reflectiv e experience improv es an agent’ s ability to interact with the en vironment and adapt under feedback, positioning LEAFE as a practical approach for developing agents that continue to improve through deployment-time interaction. Impact Statement This work aims to advance research on training agentic language models for interaction in complex en vironments. Improv ements in agent capability and deployment ef ficiency may support more practical use of learning-based agents in a range of applications. At the same time, as agents be- come more capable of sustained interaction and autonomous decision-making, careful consideration of reliability , secu- rity , and safety remains important. Beyond these general considerations, we do not identify specific societal impacts that require separate discussion. 9 Internalizing Agency fr om Reflective Experience References Acikgoz, E. C., Qian, C., Ji, H., Hakkani-T ¨ ur , D., and T ur , G. Self-improving llm agents at test-time. arXiv pr eprint arXiv:2510.07841 , 2025. Ahn, J., V erma, R., Lou, R., Liu, D., Zhang, R., and Y in, W . Large language models for mathematical reasoning: Pro- gresses and challenges. arXiv pr eprint arXiv:2402.00157 , 2024. Butt, N., Manczak, B., W iggers, A., Rainone, C., Zhang, D. W ., Def ferrard, M., and Cohen, T . Codeit: Self- improving language models with prioritized hindsight replay . arXiv preprint , 2024. Cai, Z., Guo, X., Pei, Y ., Feng, J., Su, J., Chen, J., Zhang, Y .- Q., Ma, W .-Y ., W ang, M., and Zhou, H. Flex: Continuous agent ev olution via forward learning from experience. arXiv pr eprint arXiv:2511.06449 , 2025. Chen, S., Zhu, T ., W ang, Z., Zhang, J., W ang, K., Gao, S., Xiao, T ., T eh, Y . W ., He, J., and Li, M. Internalizing world models via self-play finetuning for agentic rl. arXiv pr eprint arXiv:2510.15047 , 2025. Cheng, M., Ouyang, J., Y u, S., Y an, R., Luo, Y ., Liu, Z., W ang, D., Liu, Q., and Chen, E. Agent-r1: T raining pow- erful llm agents with end-to-end reinforcement learning. arXiv pr eprint arXiv:2511.14460 , 2025. Cui, G., Y uan, L., W ang, Z., W ang, H., Zhang, Y ., Chen, J., Li, W ., He, B., F an, Y ., Y u, T ., et al. Process re- inforcement through implicit rew ards. arXiv pr eprint arXiv:2502.01456 , 2025. Da, J., W ang, C., Deng, X., Ma, Y ., Barhate, N., and Hendryx, S. Agent-rlvr: Training software engineer- ing agents via guidance and en vironment rewards. arXiv pr eprint arXiv:2506.11425 , 2025. Feng, L., Xue, Z., Liu, T ., and An, B. Group-in-group policy optimization for llm agent training. arXiv preprint arXiv:2505.10978 , 2025. Fu, W ., Gao, J., Shen, X., Zhu, C., Mei, Z., He, C., Xu, S., W ei, G., Mei, J., W ang, J., et al. Areal: A large-scale asynchronous reinforcement learning system for language reasoning. arXiv pr eprint arXiv:2505.24298 , 2025a. Fu, Y ., W ang, X., T ian, Y ., and Zhao, J. Deep think with confidence. arXiv pr eprint arXiv:2508.15260 , 2025b. Grattafiori, A., Dubey , A., Jauhri, A., P andey , A., Kadian, A., Al-Dahle, A., Letman, A., Mathur , A., Schelten, A., V aughan, A., et al. The llama 3 herd of models. arXiv pr eprint arXiv:2407.21783 , 2024. Guo, D., Y ang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., W ang, P ., Bi, X., et al. Deepseek-r1: In- centi vizing reasoning capability in llms via reinforcement learning. arXiv pr eprint arXiv:2501.12948 , 2025. Ha, D. and Schmidhuber , J. W orld models. arXiv preprint arXiv:1803.10122 , 2(3), 2018. Hafner , D., Lillicrap, T ., Norouzi, M., and Ba, J. Mas- tering atari with discrete world models. arXiv pr eprint arXiv:2010.02193 , 2020. Hafner , D., Pasukonis, J., Ba, J., and Lillicrap, T . Mastering div erse domains through world models. arXiv preprint arXiv:2301.04104 , 2023. He, J., Liu, J., Liu, C. Y ., Y an, R., W ang, C., Cheng, P ., Zhang, X., Zhang, F ., Xu, J., Shen, W ., Li, S., Zeng, L., W ei, T ., Cheng, C., An, B., Liu, Y ., and Zhou, Y . Skyw ork open reasoner 1 technical report. arXiv preprint arXiv:2505.22312 , 2025a. He, Y ., Liu, J., Liu, Y ., Li, Y ., Cao, T ., Hu, Z., Xu, X., and Hooi, B. Evotest: Ev olutionary test-time learn- ing for self-improving agentic systems. arXiv preprint arXiv:2510.13220 , 2025b. Hu, J., Zhang, Y ., Han, Q., Jiang, D., Zhang, X., and Shum, H.-Y . Open-reasoner -zero: An open source approach to scaling up reinforcement learning on the base model. arXiv pr eprint arXiv:2503.24290 , 2025. Jaech, A., Kalai, A., Lerer , A., Richardson, A., El-Kishky , A., Low , A., Helyar , A., Madry , A., Beutel, A., Car- ney , A., et al. Openai o1 system card. arXiv preprint arXiv:2412.16720 , 2024. Ji, X., Liu, Y ., W ang, Q., Zhang, J., Y ue, Y ., Shi, R., Sun, C., Zhang, F ., Zhou, G., and Gai, K. Leanabell- prov er-v2: V erifier-inte grated reasoning for formal theo- rem proving via reinforcement learning. arXiv pr eprint arXiv:2507.08649 , 2025. Li, X., Chen, K., Long, Y ., Bai, X., Xu, Y ., and Zhang, M. Generator-assistant stepwise rollback framew ork for large language model agent. arXiv pr eprint arXiv:2503.02519 , 2025. Li, Y ., Choi, D., Chung, J., Kushman, N., Schrittwieser , J., Leblond, R., Eccles, T ., Keeling, J., Gimeno, F ., Lago, A. D., Hubert, T ., Choy , P ., de Masson d’Autume, C., Babuschkin, I., Chen, X., Huang, P .-S., W elbl, J., Gow al, S., Cherepanov , A., Molloy , J., Manko witz, D. J., Robson, E. S., Kohli, P ., de Freitas, N., Kavukcuoglu, K., and V in yals, O. Competition-lev el code genera- tion with alphacode. Science , 378(6624):1092–1097, 2022. doi: 10 . 1 1 2 6 /s c i e n c e . ab q 1 1 5 8. URL h t t p s : / / w w w . s c i e n c e . o r g / d o i / a b s / 1 0 . 1 1 2 6 / s c ience.abq1158 . 10 Internalizing Agency fr om Reflective Experience Luo, M., T an, S., W ong, J., Shi, X., T ang, W . Y ., Roongta, M., Cai, C., Luo, J., Li, L. E., Popa, R. A., and Stoica, I. Deepscaler: Surpassing o1-pre view with a 1.5b model by scaling rl. https://pretty- radio- b75.notio n.site/ DeepSc a leR- Surpassin g- O1- Pre vi ew - wi t h- a- 1 - 5B- Mo de l- b y- Sc al in g- R L- 1 9 6 8 19 0 2 c 1 46 8 0 0 5 be d 8 c a 30 3 0 1 3 a4 e 2 , 2025. Notion Blog. MiniMax. Minimax m2 & agent: Ingenious in simplicity . http s:// w ww.m inim ax.i o/ne ws/mi nima x- m 2 , October 2025. Accessed: 2026-01-28. Nakano, R., Hilton, J., Balaji, S., W u, J., Ouyang, L., Kim, C., Hesse, C., Jain, S., Kosaraju, V ., Saunders, W ., et al. W ebgpt: Browser -assisted question-answering with hu- man feedback. arXiv pr eprint arXiv:2112.09332 , 2021. Ouyang, S., Y an, J., Hsu, I., Chen, Y ., Jiang, K., W ang, Z., Han, R., Le, L. T ., Daruki, S., T ang, X., et al. Rea- soningbank: Scaling agent self-ev olving with reasoning memory . arXiv preprint , 2025. Putta, P ., Mills, E., Garg, N., Motwani, S., Finn, C., Garg, D., and Rafailov , R. Agent q: Adv anced reasoning and learning for autonomous ai agents. arXiv preprint arXiv:2408.07199 , 2024. Qi, P ., Liu, Z., Pang, T ., Du, C., Lee, W . S., and Lin, M. Optimizing anytime reasoning via b udget relative polic y optimization. arXiv pr eprint arXiv:2505.13438 , 2025. Schrader , M.-P . B. gym-sokoban. https://github.c om/mpSchrader/gym- sokoban , 2018. Schulman, J., W olski, F ., Dhariwal, P ., Radford, A., and Klimov , O. Proximal policy optimization algorithms. arXiv pr eprint arXiv:1707.06347 , 2017. Setlur , A., Nagpal, C., Fisch, A., Geng, X., Eisenstein, J., Agarwal, R., Agarw al, A., Berant, J., and Kumar , A. Re- warding progress: Scaling automated process verifiers for llm reasoning. arXiv pr eprint arXiv:2410.08146 , 2024. Shang, S., W an, R., Peng, Y ., W u, Y ., Chen, X.-h., Y an, J., and Zhang, X. Stepfun-prover pre view: Let’ s think and verify step by step. arXiv preprint , 2025. Shao, R., Li, S. S., Xin, R., Geng, S., W ang, Y ., Oh, S., Du, S. S., Lambert, N., Min, S., Krishna, R., et al. Spu- rious re wards: Rethinking training signals in rlvr . arXiv pr eprint arXiv:2506.10947 , 2025. Shao, Z., W ang, P ., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y ., W u, Y ., et al. Deepseekmath: Push- ing the limits of mathematical reasoning in open language models. arXiv pr eprint arXiv:2402.03300 , 2024. Sheng, G., Zhang, C., Y e, Z., W u, X., Zhang, W ., Zhang, R., Peng, Y ., Lin, H., and W u, C. Hybridflow: A flexible and efficient rlhf frame work. In Pr oceedings of the T wentieth Eur opean Conference on Computer Systems , pp. 1279– 1297, 2025. Shinn, N., Cassano, F ., Gopinath, A., Narasimhan, K., and Y ao, S. Refle xion: Language agents with verbal rein- forcement learning. Advances in Neural Information Pr ocessing Systems , 36:8634–8652, 2023. Shridhar , M., Y uan, X., C ˆ ot ´ e, M.-A., Bisk, Y ., Trischler , A., and Hausknecht, M. Alfworld: Aligning text and embodied en vironments for interacti ve learning. arXiv pr eprint arXiv:2010.03768 , 2020. T an, S., Luo, M., Cai, C., V enkat, T ., Montgomery , K., Hao, A., W u, T ., Balyan, A., Roongta, M., W ang, C., Li, L. E., Popa, R. A., and Stoica, I. rllm: A framework for post- training language agents, 2025. URL h t t ps : / / p r etty- radio- b75.notion.site/ rLLM- A- Fra mework- for- Post- Training- Language- Age nt s- 2 1 b 81 9 0 2c 1 4 6 81 9 d b 6 3 c d 98 a 5 4b a 5 f 31 . Notion Blog. T eam, K., Bai, Y ., Bao, Y ., Chen, G., Chen, J., Chen, N., Chen, R., Chen, Y ., Chen, Y ., Chen, Y ., et al. Kimi k2: Open agentic intelligence. arXiv preprint arXiv:2507.20534 , 2025. T eam, Q. et al. Qwen2 technical report. arXiv pr eprint arXiv:2407.10671 , 2(3), 2024. W ang, H. and Choudhury , S. The road not taken: Hindsight exploration for llms in multi-turn rl. In ES-F oMo III: 3rd W orkshop on Efficient Systems for F oundation Models . W ang, R., Jansen, P ., C ˆ ot ´ e, M.-A., and Ammanabrolu, P . Sciencew orld: Is your agent smarter than a 5th grader? arXiv pr eprint arXiv:2203.07540 , 2022a. W ang, X., W ei, J., Schuurmans, D., Le, Q., Chi, E., Narang, S., Chowdhery , A., and Zhou, D. Self-consistency im- prov es chain of thought reasoning in language models. arXiv pr eprint arXiv:2203.11171 , 2022b. W u, R., W ang, X., Mei, J., Cai, P ., Fu, D., Y ang, C., W en, L., Y ang, X., Shen, Y ., W ang, Y ., et al. Evolver: Self-ev olving llm agents through an experience-dri ven lifecycle. arXiv pr eprint arXiv:2510.16079 , 2025. Xia, P ., Zeng, K., Liu, J., Qin, C., W u, F ., Zhou, Y ., Xiong, C., and Y ao, H. Agent0: Unleashing self-ev olving agents from zero data via tool-inte grated reasoning. arXiv pr eprint arXiv:2511.16043 , 2025. 11 Internalizing Agency fr om Reflective Experience Xia, P ., Chen, J., W ang, H., Liu, J., Zeng, K., W ang, Y ., Han, S., Zhou, Y ., Zhao, X., Chen, H., et al. Skillrl: Evolv- ing agents via recursiv e skill-augmented reinforcement learning. arXiv pr eprint arXiv:2602.08234 , 2026. Xie, Z., Chen, J., Chen, L., Mao, W ., Xu, J., and Kong, L. T eaching language models to critique via reinforcement learning. arXiv pr eprint arXiv:2502.03492 , 2025. Y ang, J., Jimenez, C. E., W ettig, A., Lieret, K., Y ao, S., Narasimhan, K., and Press, O. Swe-agent: Agent- computer interfaces enable automated software engineer - ing. Advances in Neural Information Pr ocessing Systems , 37:50528–50652, 2024. Y ao, S., Chen, H., Y ang, J., and Narasimhan, K. W eb- shop: T o wards scalable real-world web interaction with grounded language agents. Advances in Neural Informa- tion Pr ocessing Systems , 35:20744–20757, 2022a. Y ao, S., Zhao, J., Y u, D., Du, N., Shafran, I., Narasimhan, K. R., and Cao, Y . React: Synergizing reasoning and acting in language models. In The eleventh international confer ence on learning r epresentations , 2022b. Y ao, S., Y u, D., Zhao, J., Shafran, I., Griffiths, T ., Cao, Y ., and Narasimhan, K. Tree of thoughts: Deliberate problem solving with large language models. Advances in neural information pr ocessing systems , 36:11809–11822, 2023. Y u, Q., Zhang, Z., Zhu, R., Y uan, Y ., Zuo, X., Y ue, Y ., Dai, W ., Fan, T ., Liu, G., Liu, L., et al. Dapo: An open-source llm reinforcement learning system at scale. arXiv pr eprint arXiv:2503.14476 , 2025. Y ue, Y ., Chen, Z., Lu, R., Zhao, A., W ang, Z., Song, S., and Huang, G. Does reinforcement learning really incenti vize reasoning capacity in llms be yond the base model? arXiv pr eprint arXiv:2504.13837 , 2025. Z.ai. Glm-4.7: Advancing the coding capability , 2025. URL https://z.ai/blog/glm- 4.7 . Zeng, A., Lv , X., Zheng, Q., Hou, Z., Chen, B., Xie, C., W ang, C., Y in, D., Zeng, H., Zhang, J., et al. Glm-4.5: Agentic, reasoning, and coding (arc) foundation models. arXiv pr eprint arXiv:2508.06471 , 2025a. Zeng, W ., Huang, Y ., Liu, Q., Liu, W ., He, K., Ma, Z., and He, J. Simplerl-zoo: In vestigating and taming zero reinforcement learning for open base models in the wild. arXiv pr eprint arXiv:2503.18892 , 2025b. Zhang, K., Chen, X., Liu, B., Xue, T ., Liao, Z., Liu, Z., W ang, X., Ning, Y ., Chen, Z., Fu, X., et al. Agent learning via early experience. arXiv preprint , 2025a. Zhang, Q., Hu, C., Upasani, S., Ma, B., Hong, F ., Kamanuru, V ., Rainton, J., W u, C., Ji, M., Li, H., et al. Agentic con- text engineering: Evolving contexts for self-improving language models. arXiv pr eprint arXiv:2510.04618 , 2025b. Zhao, A., W u, Y ., Y ue, Y ., W u, T ., Xu, Q., Lin, M., W ang, S., W u, Q., Zheng, Z., and Huang, G. Absolute zero: Reinforced self-play reasoning with zero data. arXiv pr eprint arXiv:2505.03335 , 2025a. Zhao, R., Meterez, A., Kakade, S., Pehlevan, C., Jelassi, S., and Malach, E. Echo chamber: Rl post-training am- plifies behaviors learned in pretraining. arXiv pr eprint arXiv:2504.07912 , 2025b. Zhu, Y ., Huang, D., L yu, H., Zhang, X., Li, C., Shi, W ., W u, Y ., Mu, J., W ang, J., Jin, P ., et al. Qimeng-codev-r1: Reasoning-enhanced verilog generation. In The Thirty- ninth Annual Confer ence on Neural Information Pr ocess- ing Systems , 2025. 12 Internalizing Agency fr om Reflective Experience A. Algorithm Detail Algorithm 1 L E A F E Stage 1: T ree-Based Experience Generation 1: Input: environment E , policy π θ , instruction q , period K , max steps T , budget B 2: Initialize W ← { (1 , ∅ , ∅ ) } ; D traj ← ∅ ; D refl ← ∅ 3: count ← 0 4: while W = ∅ and count < B do 5: Dequeue ( τ , e, a 1: τ − 1 ) from W ; count ← count + 1 6: Reset( E ) ; Repla y ( E , a 1: τ − 1 ) { Restore E τ and h τ } 7: t ← τ 8: while t ≤ T and E not terminal do 9: if t = τ and e = ∅ then 10: a t ∼ π θ ( · | h t , q , e ) { Generate improved action a ′ τ } 11: D refl ← D refl ∪ { ( h t , e, a t ) } { Collect experience-guided sample } 12: else 13: a t ∼ π θ ( · | h t , q ) 14: end if 15: E t +1 , o t +1 ← Step( E t , a t ) ; h t +1 ← h t ∪ ( a t , o t +1 ) 16: if t mod K = 0 or E fails then 17: ( ˆ τ , ˆ e ) ∼ π θ ( · | h t +1 , p refl ) { Identify failure and provide guidance } 18: Enqueue ( ˆ τ , ˆ e, a 1: ˆ τ − 1 ) into W 19: end if 20: if E succeeds then 21: D traj ← D traj ∪ { h t +1 } 22: end if 23: t ← t + 1 24: end while 25: end while B. Implementation Details B.1. Summary T able 7 summarizes the data scale used across all benchmarks. For each dataset, we report the exact number of instances in the task split (training set and test set). In addition, we list the average amount of auxiliary SFT data (EarlyExp and our LEAFE) distilled from rollouts; these values are approximate and meant to indicate the typical order of magnitude (in thousands) rather than an exact count, since the final number can v ary slightly across runs. T able 7. Dataset statistics and approximate numbers of training samples used by auxiliary supervision. Training/test set sizes are e xact instance counts, while EarlyExp and LEAFE refer to the average scale (order of magnitude) of distilled samples used for SFT across runs. Dataset #T raining Set #T est Set #EarlyExp samples #LEAFE samples ALFW orld 3553 140 10k 12k ScienceW orld 2000 150 6k 12k W ebShop 5000 500 15k 10k Sokoban 5000 500 10k 10k CodeContests 5000 165 N/A 10k B.2. Implementation of En vironment ALFW orld. ALFW orld is a household embodied task suite b uilt on te xt-based environments. At each step, the en vironment ex ecutes the agent’ s action and returns a textual observ ation describing the execution result and the updated scene state. In addition, ALFW orld provides a list of admissible actions for the next step, which we expose to the model as action 13 Internalizing Agency fr om Reflective Experience F ailed at step 15 Steps 1 2 repla yed F ailed at step 15 Steps 1 2 repla yed Solved! Attempt 1 Attempt 2 Attempt 3 Step 1 Step 2 Step 3 Step 4 Step 5 Step 8 Step 9 Step 3 Step 4 Step 5 Step 8 Step 9 Step 3 Step 4 Step 5 Step 8 Step 9 R eplayed steps New steps Success state R ollback to step 3 Experience R ollback to step 3 Experience F igure 5. A example on Sokoban illustrating Stage 1 of LEAFE. Starting from a failed trajectory , the agent reflects on the interaction history , identifies an earlier suboptimal decision(step 3), and generates a compact experience summary for rollback-based re vision. The en vironment is then reset to the selected step, the prior history is replayed(step 1-2), and a new branch is explored under the guidance of the reflected experience. Repeating this failure → reflection → rollback → correction process enables the agent to reco ver from early mistakes and e ventually reach a successful solution. 14 Internalizing Agency fr om Reflective Experience candidates. ScienceW orld. ScienceW orld is an interactive scientific reasoning en vironment in which the agent solves multi-step tasks by manipulating objects and instruments. After ex ecuting an action, the en vironment returns a te xtual observation describing the action outcome and the resulting world state. Unlike ALFW orld, ScienceW orld exposes a set of currently available objects . The agent must compose valid actions by selecting an action template and instantiating it with objects from this list (e.g., use [object] on [object] ), following the en vironment’ s action syntax. W ebShop. W ebShop simulates goal-directed online shopping as a browser -like interaction loop. At each step, the en vironment renders the current webpage content (including product lists, descriptions, and navigation elements). The agent can either issue a sear ch action by providing a k eyword query , or perform a click action by selecting a clickable element (e.g., a product entry , cate gory link, or a back button) to navig ate across pages toward the tar get purchase. Sokoban. Sokoban is a grid-based puzzle en vironment in which the agent must push boxes onto designated tar get locations through sequential mov ement decisions. At each step, the en vironment ex ecutes one of four directional actions ( up , down , left , right ) and returns the updated grid state. In our setup, we use a text-mode representation of the en vironment, where each grid cell is rendered as a symbolic token: walls, floor tiles, targets, boxes, the player are represented by symbols such as # , , O , X , P . This textual grid is exposed to the model as the observation, and the agent must infer spatial structure, object interactions, and long-horizon box-pushing plans directly from these symbolic layouts. CodeContests. CodeContests is a competitiv e programming benchmark where each episode corresponds to a single coding problem. In our setup, at ev ery round, the model produces a complete candidate solution (full code) for the problem. The environment compiles and ex ecutes the submitted code against test cases and returns execution feedback. On the public test set, the en vironment provides concrete runtime outputs (e.g., failing case outputs, errors, or mismatched results), whereas on the priv ate set it reports only an aggregate correctness score. The model uses this feedback to generate a revised full-program submission in the next round. B.3. Implementation of Our Method LEAFE Stage 1: T r ee-Based Experience Generation with Rollback. During rollout, we trigger rollbac k reflection either (i) ev ery fixed interv al of K interaction rounds, or (ii) immediately when an episode terminates in failure. At each reflection, we provide the model with the full interaction history up to the current step and prompt it to (a) select a specific suboptimal r ound τ to roll back to, and (b) summarize a concise experience e (diagnosis-and-fix instruction) grounded in the observed feedback. The chosen τ is intended to correspond to the decision that caused the trajectory to enter an incorrect branch or become unproductiv e. A concrete prompt example is shown in Appendix B.5 . In our implementation, we set K =10 for ALFW orld and ScienceW orld, K =5 for W ebShop and Sokoban, and K =4 for CodeContests. Notably , CodeContests has a maximum horizon of 4 , so rollback is only in voked when the attempt b udget is exhausted. Stage 2: Experience Distillation. W e construct two types of supervised data for standard next-token lik elihood training. First, Behavior Rehearsal samples successful trajectories to preserve the agent’ s base competence. W e randomly select 20% of successful rollouts to form the rehearsal set D reh . Second, Experience-to-P olicy Distillation builds a counterfactual dataset D cf from branching points: when an experience e injected at round τ yields an improv ed action a ′ τ , we treat a ′ τ as the counterfactual tar get for the original history without providing e at training time. In practice, we sample 3 counterfactual (branching) instances per task to populate D cf . W e then perform SFT on the union of D reh and D cf with batch size 128 and learning rate 1 × 10 − 6 for 2 – 3 epochs, depending on the dataset and model scale. B.4. Implementation of Baselines B . 4 . 1 . G R P O - R L V R Interactive agentic benchmarks (ALFW orld, ScienceW orld, W ebShop, Sokoban). For ALFW orld, ScienceW orld, W ebShop and Sokoban, we train the GRPO-RL VR baseline using the V E R L - A G E N T framework. ALFW orld, W ebShop and Sokoban are of ficially supported in the repository , and we directly follo w the provided en vironment setup, default training configurations, and reward definitions. ScienceW orld is not officially implemented in V E R L - A G E N T ; we therefore implement a compatible en vironment wrapper follo wing the official interf aces and guidelines, while keeping the observ ation/action 15 Internalizing Agency fr om Reflective Experience formatting and data structures consistent with e xisting tasks in the frame work. Unless stated otherwise, we use the same default training setup and reward scheme as in V E R L - A G E N T . The only ScienceW orld-specific modification is in the memory module: we keep at most the most recent 10 interaction turns in the context. Competitive pr ogramming benchmark (CodeContests). For CodeContests, we train GRPO-RL VR using the V E R L framew ork. W e follow the en vironment setup and e valuation protocol of CTRL: a solution recei ves re ward 1 if and only if the generated program passes all test cases, including both public and pri vate tests; otherwise the re ward is 0 . W e set the GRPO learning rate to 1 × 10 − 6 , the training batch size to 128 , and use n = 8 rollouts per prompt. W e train for 3 epochs on the CodeContests training set. B . 4 . 2 . E A R LY E X P E R I E N C E In this section, we describe our reproduction of the Early Experience baseline, with a focus on its key component, Implicit W orld Modeling (IWM). In short, IWM trains the agent to predict the ne xt en vir onment observation conditioned on the current interaction context and a candidate action, thereby implicitly capturing en vironment dynamics via supervised next-token prediction. EarlyExp constructs IWM supervision using expert demonstrations. In our setting, we focus on interaction-driv en learning: both our method and the GRPO-RL VR baseline obtain supervision from en vironment feedback rather than ground-truth trajectories. Therefore, for a fair comparison, we implement IWM supervision purely from model-generated rollouts.: we rollout the base model on the training set and collect action–observation pairs, using the en vironment-returned observation as the prediction target. For each task instance, we perform 4 independent rollouts, select the highest-scoring attempt, and uniformly sample 3 action–observ ation pairs from that attempt to form the IWM supervision set. W e then perform SFT on it with batch size 64 and learning rate 1 × 10 − 6 for 1 epoch. An example prompt is shown in B.5 . B . 4 . 3 . AC E A CE proposes a prompt-based self-ev olving agent framework in which e xperience is accumulated in an external playbook rather than internalized through parameter updates. The playbook is a structured context memory that stores reusable task-solving strategies, heuristics, and reflecti ve insights e xtracted from past interactions. Its implementation is or ganized around three main roles: a Generator that interacts with the environment to solve tasks, a Reflector that analyzes trajectories and summarizes useful takeaw ays, and a Curator that updates the playbook by incorporating new entries. The open-source implementation of A CE is b uilt on AppW orld, which serves as a representati ve interacti ve agent benchmark. In our experiments, we e xtend the of ficial implementation to ALFW orld, W ebShop, ScienceW orld, and Sokoban by following the same ov erall A CE pipeline. Specifically , we reuse the official prompts for the Generator , Reflector , and Curator roles, while keeping the task ex ecution en vironments and interaction formatting consistent with the V E R L - A G E N T setup used in our other interactiv e benchmarks. Since the current ACE implementation only appends ne w playbook entries and does not perform effecti ve pruning or consolidation, the playbook can grow quickly and lead to excessi ve context length. T o control context size, we cap the number of playbook entries during training at 100 . At test time, we use the playbook obtained after training as part of the model context for do wnstream ev aluation. 16 Internalizing Agency fr om Reflective Experience B.5. Example Prompts EarlyExp Example Prompt User: Y ou are an expert age nt operating in the ALFRED Embodied En vironment. Y our task is to: put two cellphone in bed. Prior to this step, you have already taken 7 step(s). Below are the most recent 5 observations and the corresponding actions you took: [Observation 3: ’Y ou arriv e at desk 1... ’, Action 3: ’take cellphone 2 from desk 1’] [Observation 4: ’Y ou pick up the cellphone 2 from the desk 1. ’, Action 4: ’go to bed 1’] [Observation 5: ’Y ou arriv e at bed 1. On the bed 1, you see ... ’, Action 5: ’go to desk 1’] [Observation 6: ’Y ou arriv e at desk 1. On the desk 1, you see ... ’, Action 6: ’take cellphone 1 from desk 1’] [Observation 7: ’Nothing happens. ’, Action 7: ’move cellphone 2 to bed 1’] Y ou are now at step 8 and your current observation is: Nothing happens. Y our admissible actions of the current situation are: [’examine cellphone 2’, ’examine desk 1’, ’go to bed 1’, ’go to drawer 1’, ’go to drawer 2’, ’go to garbagecan 1’, ’go to shelf 1’, ’go to shelf 2’, ’go to shelf 3’, ’go to shelf 4’, ’go to shelf 5’, ’go to shelf 6’, ’go to shelf 7’, ’go to shelf 8’, ’go to sidetable 1’, ’in ventory’, ’look’, ’mo ve cellphone 2 to desk 1’]. The next action is **move cellphone 2 to desk 1**. Y our task is to predict the en vironment observation after ex ecuting this action. Output only the observation. Assistant: Y ou move the cellphone 2 to the desk 1... LEAFE Example Prompt User: [STEP 1] Observation: This room is called the bathroom. In it, you see... Action: go kitchen [STEP 2] Observation: Y ou move to the kitchen... Action: pick up apple [STEP 3] Observation: Y ou move the apple to the in v entory ... Action: go to the counter [STEP 4] Observation: It’ s not clear ho w to go to/through a counter ... Action: go stove [STEP 5] Observation: It’ s not clear ho w to go to/through a stove... Action: go counter [STEP 6] Observation: It’ s not clear ho w to go to/through a counter ... Action: focus on apple ... Y ou are an expert agent playing ScienceW orld, a text-based science simulation game. Y our task is to boil apple juice. For compounds without a boiling point, comb usting the substance is also acceptable. Y ou have already tak en 6 step(s), but the task failed without completing the objecti ve. F AILURE REASON: The environment closed early , but the task was not properly completed. IMPOR T ANT : Analyze your failed attempt and identify where things went wrong. Y ou have a chance to go back to a specific step and try a different approach, with the benefit of your current e xperience. First, carefully analyze the trajectory within tags. Then, provide your final decision in the following format: ... ... Assistant: The trajectory initially seemed promising as I picked up the apple and moved to wards the counter , but I became confused about how to proceed... 2 Plan the full procedure before acting: focus on the target substance, use valid appli- ances/containers, and av oid actions that the en vironment rejects (e.g., going “to/through” non-locations). 17
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment