SOMP: Scalable Gradient Inversion for Large Language Models via Subspace-Guided Orthogonal Matching Pursuit
Gradient inversion attacks reveal that private training text can be reconstructed from shared gradients, posing a privacy risk to large language models (LLMs). While prior methods perform well in small-batch settings, scaling to larger batch sizes an…
Authors: Yibo Li, Qiongxiu Li
SOMP: Scalable Gradient In version f or Large Language Models via Subspace-Guided Orthogonal Matching Pursuit Y ibo Li Politecnico di Milano / Italy yibo2.li@mail.polimi.it Qiongxiu Li Aalborg Uni versity qili@es.aau.dk Abstract Gradient in version attacks rev eal that priv ate training text can be reconstructed from shared gradients, posing a priv acy risk to large lan- guage models (LLMs). While prior methods perform well in small-batch settings, scaling to larger batch sizes and longer sequences remains challenging due to se vere signal mixing, high computational cost, and de graded fidelity . W e present SOMP (Subspace-Guided Orthogonal Matching Pursuit), a scalable gradient in ver - sion framework that casts text recov ery from aggregated gradients as a sparse signal recov- ery problem. Our ke y insight is that aggregated transformer gradients retain exploitable head- wise geometric structure together with sample- le vel sparsity . SOMP leverages these properties to progressively narrow the search space and disentangle mixed signals without exhaustiv e search. Experiments across multiple LLM fami- lies, model scales, and fi ve languages show that SOMP consistently outperforms prior methods in the aggregated-gradient re gime.For long se- quences at batch size B = 16 , SOMP achiev es substantially higher reconstruction fidelity than strong baselines, while remaining computation- ally competitiv e. Even under e xtreme aggre- gation (up to B = 128 ), SOMP still recov ers meaningful text, suggesting that priv acy leak- age can persist in re gimes where prior attacks become much less effecti ve. 1 Introduction The reliance of LLMs on massive, often sensi- ti ve datasets raises critical priv acy concerns, par - ticularly in collaborati ve training scenarios across multiple institutions. T o address these pri v acy concerns across sensitiv e domains (e.g., health- care ( T eo et al. , 2024 ), la w ( Zhang et al. , 2023 ), and finance ( Shi et al. , 2023 )), Federated Learning (FL) protects raw data by sharing only aggregated gradi- ent updates ( Zhang et al. , 2024 ; Y ao et al. , 2025 ). Consequently , relying on large local batch sizes is typically deployed to obfuscate individual samples, creating a strong expectation of data pri vac y . Despite its appeal, federated learning does not provide inherent priv acy guarantees ( Li et al. , 2024 ). Early gradient in version attacks sho wed that an honest-but-curious server can reconstruct pri v ate training data directly from shared gradi- ents ( Zhu et al. , 2019 ). Although these attacks were first studied in continuous image domains ( Li et al. , 2022 ), the y no w pose a direct threat to LLMs, where discrete textual inputs can also be recovered. In particular , methods such as D AGER demonstrate that entire text batches can be exactly reconstructed from aggregated transformer updates. These results directly challenge the common assumption ( McMa- han et al. , 2023 ) that gradient aggreg ation alone is suf ficient to obfuscate indi vidual samples. Ho we ver , existing text-based gradient in version methods face serious scalability challenges. Early approaches rely heavily on e xternal language mod- els and are therefore limited to short sequences or lightly aggregated settings. More recent meth- ods extend to lar ger setups, but introduce new bot- tlenecks: hybrid optimization methods such as GRAB ( Feng et al. , 2024 ) suffer from cross-sample interference, while exact recovery methods such as D AGER ( Petro v et al. , 2024 ) incur prohibiti ve costs under longer sequences and large batchsize. As a result, prior methods become brittle precisely in the long-sequence, multi-sample regimes that are most rele v ant in practice. T o address this gap, we propose SOMP , a struc- tured frame work for multi-sample text gradient in- version under aggregated gradients. W e study the standard honest-b ut-curious server setting, where the attacker observes an aggregated gradient update. Our ke y insight is that aggregated transformer gra- dients are not arbitrary mixtures: they retain useful head-wise geometric structure induced by multi- head attention, together with sample-lev el sparsity . Building on this observ ation, SOMP reformulates in version as a structured reconstruction problem in gradient space, enabling more effecti ve disen- tanglement without exhaustiv e token-le vel verifi- cation. Our goal is not to claim uniform gains in e very regime, b ut to improve reconstruction quality and scaling behavior precisely where prior attacks degrade most: long-sequence, large batchsize set- tings. • Head-aware geometric guidance f or text gra- dient in version. W e show that aggregated trans- former gradients retain useful head-wise geometric structure, and exploit this structure to guide candi- date filtering and decoding under mixed gradients. • A sparse r econstruction f ormulation for multi- sample in version. W e reformulate e xact recovery from exhausti ve token-le vel search as sparse signal recov ery in gradient space, substantially mitigating the scalability bottlenecks of prior methods and enabling ef fectiv e disentanglement of cross-sample interference. • Robust and scalable inv ersion under gradi- ent aggregation. Across multiple transformer families and aggre gated-gradient re gimes, SOMP yields stronger reconstruction quality than prior text-based attacks, with its lar gest gains appearing in long-sequence and larger -batch settings. 2 Related W ork Gradient inv ersion and data leakage attacks. The problem of reconstructing pri vate data from shared gradients, often termed gr adient in version or gradient leakage , w as first explored ( Zhu et al. , 2019 ) and has since drawn extensi ve attention in the context of federated learning. Early ap- proaches mainly tar geted image data and formu- lated the recov ery as a continuous optimization problem ( Zhu et al. , 2019 ; Chen and Liu , 2025 ; Huang et al. , 2021 ). More recent works such as SPEAR ( Dimitrov et al. , 2024 ) further improv ed ef ficiency by e xploiting the inherent low-rank and sparsity structures of neural gradients, enabling ex- act reconstruction of large image batches. Ho wev er , these methods rely on continuous optimization and cannot be directly transferred to text, where in- puts are discrete and tokenizati on introduces non- dif ferentiable constraints. ( Geng et al. , 2022 ) Gradient in version for textual data. Recon- structing text from gradients is substantially more challenging than recovering images due to the discrete token space and the combinatorial struc- ture of language. Early approaches such as LAMP ( Balunovi ´ c et al. , 2022 ) and GRAB ( Feng et al. , 2024 ) incorporate language priors or hy- brid continuous–discrete optimization, but remain limited in scalability under aggregated or long- sequence settings due to the exponentially gro wing search space and sev ere cross-token interference. D A GER ( Petrov et al. , 2024 ) exploits the lo w-rank structure of self-attention gradients to enable exact reconstruction in transformer architectures. How- e ver , D AGER suffers from high computational cost due to layer-wise exhausti ve search and becomes unstable in high-token regimes, where aggregat- ing multiple inputs or long sequences causes the attention-gradient matrix to approach full rank, de- grading reconstruction accuracy . 3 Background In this section, we introduce the problem setup and summarize the structural properties of gradients in transformer-based models that serv e as fundamen- tals of our method. 3.1 Problem Setup W e consider LLMs parameterized by θ and trained under the F edSGD protocol. Each client holds a lo- cal mini-batch of B training samples { ( x j , y j ) } B j =1 and transmits only the aggreg ated gradient to the server . Gi ven a loss function L , the server observes g mix = 1 B B X j =1 ∇ θ L f θ ( x j ) , y j , (1) without access to individual samples or per-sample gradients. W e consider a transformer with context length p , hidden dimension d , and H attention heads. Gi ven an input sequence x = [ x 1 , . . . , x p ] , the corresponding token embeddings form the input representation Z 0 ∈ R p × d . 3.2 Structural Properties Gradients in transformer-based models exhibit se veral structural properties that are useful for multi-sample inv ersion. First, as noted in prior work ( Petro v et al. , 2024 ), gradients of linear lay- ers inherit a matrix-product form. For a linear layer Y = X W + ( b | · · · | b ) ⊤ , the weight gradient satis- fies ∇ W L = X ⊤ ∇ Y L , (2) which induces a low-rank structure in the resulting gradient matrix. Second, multi-head attention induces a natural head-wise decomposition in gradient space. Let ( · ) l denote the l -th transformer layer , ( · ) Q,K,V de- note the query , ke y , and value projections, and ( · ) ( h ) index the h -th attention head. In particular, W ( h ) 1 ,Q denotes the query projection matrix of head h in the first transformer layer . For the first-layer query projection, the gradient of head h can be written as ∇ W ( h ) 1 ,Q = Z ⊤ 0 G ( h ) Q ∈ R d × d h , (3) where G ( h ) Q ∈ R p × d h denotes the backpropagated signal for head h , and d = P H h =1 d h . The full query gradient is obtained by concatenating these head-wise slices. Finally , these gradients exhibit informativ e spar- sity patterns at the token lev el ( Dimitrov et al. , 2024 ). In particular, head-aligned sparsity pro- vides useful cues for filtering and scoring candi- date tokens under aggre gated gradients. A formal discussion is provided in Appendix A . T ogether , these properties suggest that aggre- gated gradients retain useful structure that can be exploited for multi-sample reconstruction. 4 Methodology W e no w proceed to introduce the proposed SOMP , a three-stage frame work for reconstructing te xtual inputs from the aggregated gradient g mix . Un- like prior search-based methods, SOMP treats multi-sample in version as a structured reconstruc- tion problem and progressiv ely narrows the search space from tokens to sentences and finally to sam- ple gradients. Stage I uses head-wise gradient slices to construct a compact tok en pool. Stage II decodes candidate sentences from this pool using geometry-guided beam search with an LM prior . Stage III then treats the decoded candidates as gra- dient atoms and selects a sparse subset whose gradi- ents best reconstruct g mix . This progressi ve design separates coarse candidate filtering from final sam- ple selection, making reconstruction more scalable under long sequences and large-batch aggre gation. The ov erall pipeline is illustrated in Figure 1 . Unless otherwise specified, hyperparameters are fixed across experiments. A full list of hyperparam- eters is provided in Appendix C . 4.1 Stage I: Head-Structured T ok en Pooling Follo wing Eq. ( 3 ), we decompose the first- layer query gradient into head-specific slices { ∇ W ( h ) 1 ,Q } H h =1 . Each slice induces a head-specific subspace, which we use to e v aluate token plausi- bility under the observed aggreg ated gradient. The goal of Stage I is not to reconstruct complete se- quences, but to build a compact, high-recall token pool that constrains the search space in Stage II. T o rank candidate tokens, we combine three com- plementary signals: geometric alignment to the head-wise query subspaces, consistency across in- formati ve heads, and head-a ware sparsity patterns in the FFN gradient. Detailed pseudocode is giv en in Appendix D (Algorithm 1 ). Subspace-alignment score. For a candidate em- bedding e ( v , pos ) ∈ R d , we first project it into the query space of head h : q ( h ) ( v , pos ) = e ( v , pos ) W ( h ) 1 ,Q ∈ R d h . Let P R ( h ) Q denote the orthogonal projector onto the subspace induced by ∇ W ( h ) 1 ,Q . W e define the head- wise alignment score as s ( h ) sub ( v , pos ) = ( I − P R ( h ) Q ) q ( h ) ( v , pos ) 2 , (4) where smaller values indicate stronger geomet- ric compatibility . W e then aggregate these scores across the informati ve heads H act : s sub ( v , pos ) = 1 |H act | X h ∈H act s ( h ) sub ( v , pos ) . (5) Cross-head consistency scor e. Plausible tokens should align consistently across informativ e heads rather than match only a single head by chance ( Li et al. , 2019 ; V oita et al. , 2019 ). W e therefore com- pute s cons ( v , pos ) = Std h ∈H act s ( h ) sub ( v , pos ) , (6) where smaller v alues indicate more stable cross- head alignment. Head-aware sparsity score. In addition to geo- metric alignment, we exploit token-le vel sparsity signals using head-aligned FFN blocks. For each block h , we compute u ( h ) ( v , pos ) = e ( v , pos ) ⊤ W ( h ) FFN ∈ R d h , (7) where W ( h ) FFN ∈ R d × d h denotes the FFN gradient slice associated with block h . The corresponding Figure 1: Overvie w of SOMP . It consists of Stage I head-structured token pooling, Stage II geometry-driv en div erse decoding, and Stage III gradient-space sparse reconstruction. block-wise sparsity score is s ( h ) ( v , pos ) = 1 d h d h X m =1 1 | u ( h ) m ( v , pos ) | ≤ τ ( h ) m , (8) where τ ( h ) m is a per-dimension threshold estimated from the candidate set. Let H top denote the top- k blocks ranked by sparsity . W e aggre gate them as s sparse ( v , pos ) = 1 k X h ∈H top s ( h ) ( v , pos ) . (9) T oken ranking. W e then combine the three scores into a single cost: s total ( v , pos ) = λ 1 s sub ( v , pos ) + λ 2 s cons ( v , pos ) − λ 3 s sparse ( v , pos ) . (10) where lower v alues indicate higher token plausibil- ity . T okens are ranked by minimizing s total , and the top candidates are retained to form the token pool used in Stage II. 4.2 Stage II: Geometry-Driven Div erse Beam Decoding Stage II generates candidate sentences from the to- ken pool produced by Stage I. T o guide decoding, we construct head-wise query-gradient subspaces {R ( h ) 2 ,Q } from the second transformer layer , follo w- ing prior observations that lower and middle lay- ers provide more stable geometric directions for in version.See Algorithm 2 for the full decoding procedure. At decoding step t , let h ( h ) t denote the head-wise hidden representation for head h . W e measure its mismatch to the recov ered geometry by d ( h ) t = ( I − P R ( h ) 2 ,Q ) h ( h ) t 2 . W e then aggreg ate these distances across informa- ti ve heads: d geo t = 1 |H act | X h ∈H act d ( h ) t . T o improve fluency , we combine the geomet- ric score with an LM prior ( De vlin et al. , 2019 ; Dathathri et al. , 2020 ). Let ˜ h t denote the final-layer hidden state and let v x t denote the embedding of candidate token x t . W e define s LM = ⟨ ˜ h t , v x t ⟩ , (11) and combine it with geometry as d t = d geo t − β LM ˆ s LM , (12) where ˆ s LM denotes the standardized fluency score. Beam scores are accumulated across decoding steps: sum t = sum t − 1 + d t . (13) The base beam score is then defined as score base t = ( sum t /t, with length normalization , sum t , otherwise . (14) T o encourage di versity , we add repetition-aware penalties: score t = score base t + λ div 1 ( x t ∈ S t )+ λ ng 1 ( g t ∈ G t ) , (15) where S t is the set of pre viously selected tokens, G t is the set of observ ed n -grams, and g t denotes the ne wly formed n -gram at step t . W e retain the top- W /G hypotheses per group, yielding a candidate set X for the final reconstruction stage. 4.3 Stage III: Gradient-Space Sparse Reconstruction Gi ven the candidate sentences X = { x (1) , . . . , x ( M ) } from Stage II, we compute a gradient atom for each candidate: g i := ∇ θ L ( f θ ( x i ) , y i ) . While this definition depends on the candidate label y i , the true labels are unav ailable at reconstruction time. W e therefore compute candidate gradients using a fix ed surrogate label. Empirically , this ap- proximation has negligible impact on candidate ranking in Stage III (see Appendix B for details). T o reduce redundancy , we cluster beam outputs by R OUGE-L similarity and retain one representa- ti ve per cluster . W e then model the observed gradient as a sparse combination ov er the candidate set: g mix ≈ X i ∈S α i g i , (16) where S ⊆ { 1 , . . . , M } is an unknown support set with |S | = B . Intuiti vely , although Stage II may generate many plausible candidates, only a small subset should contribute to the true aggregated gra- dient. W e reco ver this support using Orthogonal Matching Pursuit (OMP). At iteration t , given the current residual r t , OMP selects the most aligned candidate: i t = arg max i |⟨ g i , r t ⟩| ∥ g i ∥ 2 . (17) The activ e coefficients are then updated by ridge- regularized least squares: α S = arg min α g mix − X j ∈S α j g j 2 2 + λ ∥ α ∥ 2 2 . (18) The residual is updated as r t +1 = g mix − X j ∈S α j g j . (19) The procedure terminates when ∥ r t ∥ 2 < ε or |S | = B . The resulting support identifies the can- didate sentences whose gradients best explain the observed mixture.The full algorithm is provided in Algorithm 3 . 4.4 Summary SOMP combines geometric candidate filtering with sparse residual fitting. In Stages I and II, head-wise structure is used as a soft constraint to prune im- plausible h ypotheses while preserving a high-recall candidate set. Stage III then resolv es the remaining ambiguity by selecting a sparse subset of candi- date gradients that best reconstructs g mix . Over- all, SOMP is best understood as a structured re- construction frame work rather than a method with worst-case reco very guarantees. 5 Experimental Evaluation W e ev aluate SOMP across multiple models, datasets, and training protocols along four com- plementary dimensions. First, we compare against prior text-based in version methods to assess o ver - all reconstruction quality under aggregated gradi- ents. Second, we v ary batch size to test whether SOMP remains effecti ve as sample mixing be- comes stronger . Third, we extend the ev alua- tion beyond the standard English FedSGD setting, including a multilingual test on other languages and FedA vg experiments, to e xamine whether the method relies on English-specific tokenization pat- terns or on the single-step optimization structure of FedSGD. Finally , we perform ablation studies to identify which stages of the pipeline are most responsible for the gains. 5.1 Experimental Setup. W e study the standard honest-but-curious server set- ting under FedSGD. The attack er observ es only the aggregated gradient g mix computed ov er a batch of size B , and does not ha ve access to indi vidual e x- amples or per-sample gradients. Unless otherwise stated, gradients are e xtracted from the first-layer query projections. Models and datasets. W e ev aluate SOMP on three autoregressi ve LLMs: GPT-2 ( Radford et al. , 2019 ), GPT-J-6B ( W ang and K omatsuzaki , 2021 ), and Qwen3-8B ( Y ang et al. , 2025 ). Reconstruc- tion experiments are conducted on CoLA ( W arstadt et al. , 2019 ), SST-2 ( Socher et al. , 2013 ), and stanfordNLP/imdb ( Maas et al. , 2011 ). Inputs are truncated to 512 tokens. Baselines and metrics. W e compare against rep- resentati ve prior text-based in version methods: D A GER, LAMP , and GRAB. All baselines are B Reference Inputs D A GER Reconstruction SOMP Reconstruction If JognThaw had ne ver ... is abso- lute must include. If JognThaw had ne ver ... is abso- lute must include. If JognThaw had ne ver ... is abso- lute must include. This sequel is quite ... lack of choreography . This sequel is quite ... movie is lack of money . This sequel is quite ... lack of choreography . . 4 I saw this movie when ... in an- other movie. I saw this movie when ... in an- other movie. I saw this movie when ... in an- other movie. I won’ t ask you ... giv e her any money . I saw this movie when ... in another movie . I won’ t ask you ... giv e her any money . Jill Dunne (played by Mitzi Kap- ture), is an ...
3 stars. Jill Dunne (played by Mitzi Kap- ture),is an ... nothing happens! Jill Dunne (played by Mitzi Kap- ture), is an ... Jill.
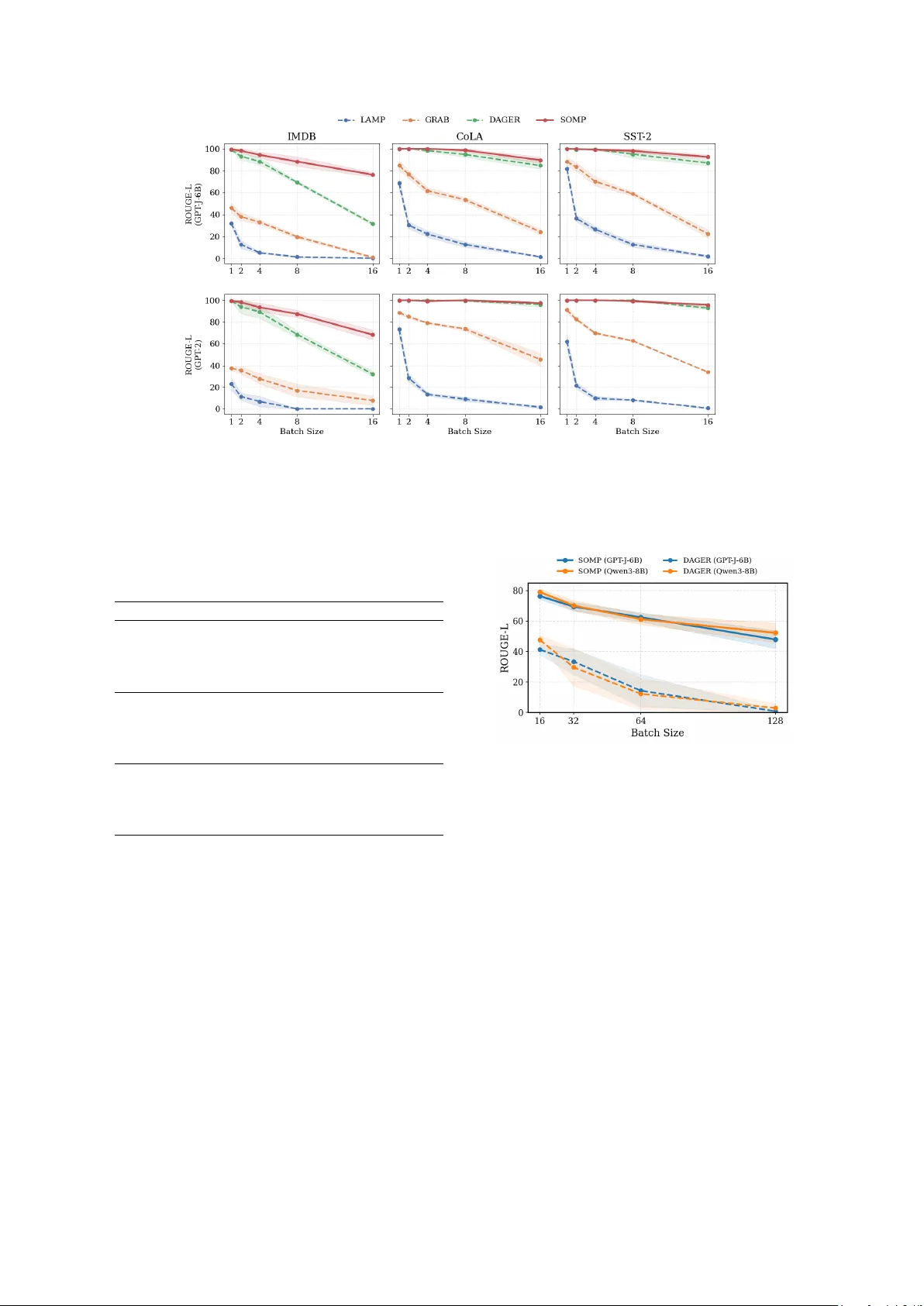
3 stars. ... ... ... 8 If the term itself were not geo- graphically ... different accents. If the term itself were not ... Ned Kelly geographic Ned K elly If the term itself were not geo- graphically ... different accents. SWING! It’ s an important film because ... it’ s really , really bad! SWING! It’ s an important film be- cause ... it’ s real real real real SWING! It’ s an important film because ...it’ s really bad!!! T able 1: Reconstruction examples under aggregated gradients at B = 2 , 4 , 8 . Highlighted spans mark incorrect tokens. As B increases, D A GER degrades faster , while SOMP remains more faithful to the reference inputs. reimplemented under the same aggregation pro- tocol and ev aluation pipeline. Reconstruction qual- ity is measured using sequence-lev el ROUGE-1 , R OUGE-2 , and ROUGE-L ( Lin , 2004 ), av eraged ov er 50 random batches and reported as mean ± standard deviation. For readability , the main text reports R OUGE-L ; full ROUGE-1/2/L results are provided in Appendix E and follo w the same over - all setting. Our main experiments focus on standard aggregated-gradient training rather than formal DP mechanisms such as DP-SGD. W e include an ex- ploratory Gaussian-noise study in Appendix H , while a full DP-SGD e valuation with clipping and pri v acy accounting is left for future w ork. 5.2 Reconstruction Perf ormance and Comparisons Figure 2 and T able 2 summarize the main com- parison against prior text-based gradient in version methods. The ov erall pattern is clear: SOMP achie ves the strongest reconstruction quality once gradients are mixed across multiple samples, and its adv antage becomes more pronounced as batch size increases. The largest gains appear on IMDB , where long inputs make cross-sample interfer- ence especially severe. T able 1 provides repre- sentati ve qualitati ve examples comparing D A GER and SOMP . Under mixed gradients, D A GER of- ten merges samples with similar prefix es, repeats locally plausible tokens, or drifts tow ard nearby embedding-space neighbors. The resulting out- puts can remain superficially fluent while failing to separate the underlying samples correctly . In con- trast, SOMP more reliably disentangles the mix ed signals and reconstructs the original inputs. Addi- tional qualitati ve e xamples comparing all methods are provided in Appendix E.1 . The main difficulty comes from increasing batch size, not from sequence length alone. IMDB is the most challenging benchmark in our study because it combines long inputs with cross-sample mixing. As sho wn in T able 2 , reconstruction quality gener- ally degrades as B increases, but prior approaches degrade much more sharply . For e xample, on GPT - J-6B, D A GER drops from 58 . 4 at B = 4 to 39 . 2 at B = 8 , whereas SOMP still reaches 73 . 5 at B = 8 . This gap widens further at B = 16 . Importantly , the full results in Appendix E show that D A GER remains highly effecti ve at B = 1 on IMDB . This indicates that long sequences alone are not the main bottleneck for search-based in ver - sion. The real challenge emerges when multiple long documents are mixed into a single observed gradient, which is exactly the re gime where SOMP provides its largest gains. On shorter-sequence benchmarks such as CoLA and SST-2 , inv ersion remains comparati vely easier, and both D A GER and SOMP perform strongly at small and moderate batch sizes. Ev en in these easier settings, ho we ver , SOMP degrades more gracefully as B gro ws. This sho ws that SOMP is not mainly designed to max- imize gains in easy cases, but to remain ef fective where prior attacks become brittle. SOMP remains effecti ve at substantially larger batch sizes. Figure 3 e xtends the comparison to Figure 2: Reconstruction performance (R OUGE-L) under aggregated gradients at batch sizes B = 1, 2, 4, 8, and 16 on IMDB, CoLA, and SST -2 using GPT -J-6B (top) and GPT -2 (bottom). SOMP shows the largest gains on IMDB, whose longer inputs make multi-sample in version harder than on shorter datasets such as CoLA and SST -2. T able 2: Reconstruction performance (R OUGE-L) un- der aggregated gradients at B = 4 , 8 , 16 on GPT -J-6B. Dataset Method B = 4 B = 8 B = 16 LAMP 1 . 2 ± 0 . 8 0 . 3 ± 0 . 3 0 . 1 ± 0 . 1 GRAB 8 . 6 ± 2 . 4 2 . 0 ± 0 . 6 0 . 9 ± 0 . 9 IMDB D AGER 58 . 4 ± 2 . 4 39 . 2 ± 0 . 8 31 . 6 ± 1 . 5 SOMP 89.3 ± 1.9 73.5 ± 5.1 76.4 ± 2.1 LAMP 10 . 6 ± 1 . 8 6 . 3 ± 0 . 7 1 . 4 ± 0 . 3 GRAB 42 . 6 ± 2 . 4 35 . 1 ± 2 . 1 24 . 3 ± 2 . 6 CoLA D A GER 92 . 9 ± 3 . 1 87 . 8 ± 4 . 5 84 . 8 ± 3 . 2 SOMP 96.3 ± 3.7 94.5 ± 3.3 89.7 ± 2.9 LAMP 12 . 9 ± 1 . 2 7 . 2 ± 0 . 7 1 . 8 ± 0 . 8 GRAB 43 . 3 ± 2 . 3 36 . 4 ± 2 . 5 22 . 3 ± 3 . 7 SST -2 DA GER 100 . 0 ± 0 . 0 92 . 9 ± 1 . 6 87 . 1 ± 2 . 4 SOMP 100.0 ± 0.0 95.8 ± 1.5 92.6 ± 1.9 much larger batch sizes on IMDB . W e can see that D A GER degrades rapidly as B increases. In con- trast, SOMP continues to reco ver meaningful text e ven at batch sizes far be yond the range where ear- lier methods begin to collapse. The same trend appears for both GPT-J-6B and Qwen3-8B , suggest- ing that the advantage of SOMP is not specific to a single architecture family . 5.3 Efficiency and Scalability SOMP impro ves efficienc y by filtering and scor- ing candidates in informativ e head-wise subspaces, rather than repeatedly verifying them in the full di- mensional space. This matters most when the can- didate set grows lar ge, since full-space verification becomes the main cost for search-based baselines Figure 3: Reconstruction performance (R OUGE-L) on GPT -J-6B and Qwen3-8B o ver larger batch sizes on IMDB . SOMP remains effecti ve substantially beyond the regime where prior methods de grade sharply . such as D A GER. T able 3 reports measured per- batch runtime under se veral beam widths. On short- sequence benchmarks such as CoLA and SST-2 , SOMP may incur some ov erhead from Stage III sparse reconstruction. On IMDB , howe ver , where sequences are longer and the search space is much larger , SOMP shows a clearly more f av orable run- time profile. W e note that SOMP is not designed to be uniformly faster in e very setting. In easier regimes, the added OMP stage can make it compa- rable to or slightly slower than simpler baselines. In long-sequence, lar ger-batch settings, ho wev er , SOMP becomes increasingly competitiv e and is of- ten faster , while also achieving substantially better reconstruction quality . Figure 4: Ablation at batch sizes ( B = 2 , 4 , 8 ). V ariants remove LM prior (SOMP1), OMP (SOMP2), sparsity scoring (SOMP3), cross-head consistency (SOMP4), and subspace-distance scoring (SOMP5). T able 3: A verage per -batch runtime in seconds. Bw denotes beam width. Dataset Method B=1 B=2 B=4 B=8 B=16 GPT -2 (runtime measured on R TX 5060) D AGER 3 6 10 19 36 CoLA SOMP(Bw=4) 7 10 13 21 26 SOMP(Bw=8) 7 10 14 24 31 SOMP(Bw=16) 8 13 21 33 41 D AGER 3 4 9 18 31 SST -2 SOMP(Bw=4) 6 9 13 22 30 SOMP(Bw=8) 7 11 14 26 37 SOMP(Bw=16) 8 12 30 40 52 D AGER 61 118 248 467 1127 IMDB SOMP(Bw=4) 48 96 191 359 672 SOMP(Bw=8) 58 117 231 448 968 SOMP(Bw=16) 75 143 289 572 1308 5.4 Multilingual Evaluation W e ne xt test whether SOMP generalizes be yond English. Across fiv e languages, SOMP maintains strong reconstruction quality without language- specific tuning, suggesting that its effecti veness does not depend on English-specific tokenization patterns. As sho wn in T able 8 of Appendix F , per - formance remains strongest on English, German, and Chinese, while French and Italian degrade more noticeably as batch size increases. A likely reason is heavier subword fragmentation, which leads to longer tokenized sequences and a lar ger decoding search space. Even so, SOMP remains ef fecti ve across all e valuated languages, indicating that it e xploits structural properties of aggre gated transformer gradients that persist across languages. 5.5 Reconstruction under FedA vg W e also e v aluate SOMP under FedA vg , where clients perform multiple local updates before aggre- gation. This setting is more realistic than one-step FedSGD and more challenging for in version, as the attacker observes only the final model update after local training (see Appendix G ). The results sho w that FedA vg does not eliminate leakage: across local epochs, learning rates, and mini-batch sizes, SOMP still reco vers substantial information from the observed update. Overall, these experiments indicate that the leakage exploited by SOMP is not specific to single-step FedSGD, but can persist under practical federated optimization. 5.6 Ablation Study W e ablate the main components of SOMP in Fig- ure 4 , including the LM prior , OMP-based sparse reconstruction, sparsity scoring, cross-head consis- tency , and subspace-distance scoring. Removing OMP causes the largest drop, especially at larger batch sizes and longer sequence lengths, showing that sparse reconstruction is the ke y step for resolv- ing cross-sample ambiguity in the highly mixed regime. The other components also contribute con- sistently: the LM prior and cross-head consistency matter more as batch size increases, while sparsity scoring and subspace-based filtering help suppress noisy candidates earlier in the pipeline. Overall, the gains of SOMP come from the interaction of its stages rather than from any single heuristic. 6 Conclusion W e presented SOMP , a subspace-guided and sparsity-dri ven frame work for reconstructing tex- tual inputs from aggreg ated gradients of large lan- guage models. By exploiting the multi-head struc- ture of transformer gradients, SOMP combines ge- ometric filtering, language-model–guided decod- ing, and sparse gradient-space reconstruction. Ex- perimental results sho w that SOMP enables accu- rate and stable multi-sample reconstruction under aggregated-gradient settings, particularly for long sequences and large batch sizes. Overall, SOMP provides a principled and scalable approach to gra- dient in version in practical training scenarios. 7 Limitations SOMP relies on structural regularities in first-layer query gradients and uses head-wise decomposition to reduce the search space. Although modern trans- formers may adopt alternati ve attention designs such as grouped-query attention (GQA), our exper- iments on Qwen3-8B show that performance re- mains comparable under this architecture. A more challenging setting would be architectures where head-le vel gradient patterns are substantially less separable. In addition, Stage I requires maintaining a high- recall token pool. Under sev erely distorted, com- pressed, or noisy gradients, relev ant tokens may be pruned too early during candidate filtering, af fect- ing do wnstream reconstruction. From an ef ficiency perspecti ve, while head-wise factorization reduces the cost of candidate v erification, the OMP-based sparse reconstruction in Stage III introduces addi- tional ov erhead. As a result, SOMP may be slower on short sequences and small batch sizes, but be- comes increasingly competitiv e as sequence length and aggregation le vel increase. Finally , our main e v aluation does not study for - mal dif ferential pri v acy mechanisms such as DP- SGD. While we include initial experiments with additi ve Gaussian noise in the Appendix H , these results do not constitute a systematic ev aluation of dif ferential pri v acy , since they do not incorporate the full DP-SGD pipeline with gradient clipping and priv acy accounting. A more complete study un- der noisy , clipped, or DP-SGD-perturbed gradients remains future work. 8 Ethical Considerations This work inv estigates the feasibility of reconstruct- ing textual inputs from aggre gated gradients, high- lighting potential priv acy risks in federated and distributed training of lar ge language models. Our goal is to better understand the conditions under which gradient leakage may occur , in order to in- form the design of safer and more priv acy-a ware training protocols. W e do not advocate the misuse of gradient in ver- sion techniques. Instead, our findings emphasize the importance of established pri v acy safe guards, such as secure aggregation and dif ferential priv acy . References Mislav Balunovi ´ c, Dimitar I. Dimitrov , Nikola Jo- vano vi ´ c, and Martin V echev . 2022. Lamp: Extract- ing text from gradients with language model priors . Pr eprint , Xinping Chen and Chen Liu. 2025. Gradient inv er- sion transcript: Leveraging rob ust generativ e priors to reconstruct training data from gradient leakage . Pr eprint , Sumanth Dathathri, Andrea Madotto, Janice Lan, Jane Hung, Eric Frank, Piero Molino, Jason Y osinski, and Rosanne Liu. 2020. Plug and play language mod- els: A simple approach to controlled text generation . Pr eprint , Jacob Devlin, Ming-W ei Chang, Kenton Lee, and Kristina T outanov a. 2019. BER T: Pre-training of deep bidirectional transformers for language under - standing . In Pr oceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language T ech- nologies, V olume 1 (Long and Short P apers) , pages 4171–4186, Minneapolis, Minnesota. Association for Computational Linguistics. Dimitar I. Dimitro v , Maximilian Baader , Mark Niklas Müller , and Martin V echev . 2024. Spear:exact gra- dient in version of batches in federated learning . Pr eprint , Xinguo Feng, Zhongkui Ma, Zihan W ang, Eu Joe Chegne, Mengyao Ma, Alsharif Abuadbba, and Guangdong Bai. 2024. Uncov ering gradient in ver- sion risks in practical language model training . In Pr oceedings of the 2024 on ACM SIGSAC Confer- ence on Computer and Communications Security , CCS ’24, page 3525–3539, New Y ork, NY , USA. Association for Computing Machinery . Jiahui Geng, Y ongli Mou, Feifei Li, Qing Li, Oya Beyan, Stefan Decker , and Chunming Rong. 2022. T ow ards general deep leakage in federated learning . Pr eprint , Y angsibo Huang, Samyak Gupta, Zhao Song, Kai Li, and Sanjee v Arora. 2021. Evaluating gradient in- version attacks and defenses in federated learning . Pr eprint , Jian Li, Baosong Y ang, Zi-Y i Dou, Xing W ang, Michael R. L yu, and Zhaopeng T u. 2019. Infor- mation aggregation for multi-head attention with routing-by-agreement . Pr eprint , Qiongxiu Li, Lixia Luo, Agnese Gini, Changlong Ji, Zhanhao Hu, Xiao Li, Chengfang Fang, Jie Shi, and Xiaolin Hu. 2024. Perfect gradient in version in fed- erated learning: A ne w paradigm from the hidden subset sum problem . Pr eprint , Zhuohang Li, Jiaxin Zhang, Luyang Liu, and Jian Liu. 2022. Auditing priv acy defenses in federated learning via generativ e gradient leakage . Pr eprint , Chin-Y ew Lin. 2004. ROUGE: A package for auto- matic e v aluation of summaries . In T ext Summariza- tion Branc hes Out , pages 74–81, Barcelona, Spain. Association for Computational Linguistics. Andrew L. Maas, Raymond E. Daly , Peter T . Pham, Dan Huang, Andrew Y . Ng, and Christopher Potts. 2011. Learning word v ectors for sentiment analysis . In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language T echnologies , pages 142–150, Portland, Oregon, USA. Association for Computational Lin- guistics. H. Brendan McMahan, Eider Moore, Daniel Ram- age, Seth Hampson, and Blaise Agüera y Ar- cas. 2023. Communication-ef ficient learning of deep networks from decentralized data . Pr eprint , Ivo Petrov , Dimitar I. Dimitrov , Maximilian Baader , Mark Niklas Müller , and Martin V echev . 2024. Dager: Exact gradient in version for large language models . Pr eprint , Alec Radford, Jef f W u, Rew on Child, David Luan, Dario Amodei, and Ilya Sutske ver . 2019. Language models are unsupervised multitask learners . Y ueyue Shi, Hengjie Song, and Jun Xu. 2023. Re- sponsible and effecti ve federated learning in financial services: A comprehensi ve survey . In 2023 62nd IEEE Confer ence on Decision and Control (CDC) , pages 4229–4236. Richard Socher , Alex Perelygin, Jean W u, Jason Chuang, Christopher D. Manning, Andre w Ng, and Christopher Potts. 2013. Recursiv e deep models for semantic compositionality over a sentiment treebank . In Proceedings of the 2013 Confer ence on Empiri- cal Methods in Natural Language Pr ocessing , pages 1631–1642, Seattle, W ashington, USA. Association for Computational Linguistics. Zhen Ling T eo, Liyuan Jin, Nan Liu, Siqi Li, Di Miao, Xiaoman Zhang, W ei Y an Ng, T ing F ang T an, Deb- orah Meixuan Lee, Kai Jie Chua, John Heng, Y ong Liu, Rick Siow Mong Goh, and Daniel Shu W ei T ing. 2024. Federated machine learning in health- care: A systematic re vie w on clinical applications and technical architecture . Cell Reports Medicine , 5(2):101419. Elena V oita, David T albot, Fedor Moisee v , Rico Sen- nrich, and Ivan T itov . 2019. Analyzing multi-head self-attention: Specialized heads do the heavy lift- ing, the rest can be pruned . In Pr oceedings of the 57th Annual Meeting of the Association for Computa- tional Linguistics , pages 5797–5808, Florence, Italy . Association for Computational Linguistics. Ben W ang and Aran Komatsuzaki. 2021. GPT -J- 6B: A 6 Billion Parameter Autoregressiv e Lan- guage Model. https://github.com/kingoflolz/ mesh- transformer- jax . Alex W arstadt, Amanpreet Singh, and Samuel R. Bow- man. 2019. Neural network acceptability judgments . T ransactions of the Association for Computational Linguistics , 7:625–641. An Y ang, Anfeng Li, Baosong Y ang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Y u, Chang Gao, Chengen Huang, Chenxu Lv , Chujie Zheng, Day- iheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran W ei, Huan Lin, Jialong T ang, and 41 others. 2025. Qwen3 technical report . Pr eprint , Y uhang Y ao, Jianyi Zhang, Junda W u, Chengkai Huang, Y u Xia, T ong Y u, Ruiyi Zhang, Sungchul Kim, Ryan Rossi, Ang Li, Lina Y ao, Julian McAuley , Y iran Chen, and Carlee Joe-W ong. 2025. Federated large language models: Current progress and future direc- tions . Pr eprint , Jianyi Zhang, Saeed V ahidian, Martin Kuo, Chun yuan Li, Ruiyi Zhang, T ong Y u, Y ufan Zhou, Guoyin W ang, and Y iran Chen. 2024. T ow ards b uilding the federated gpt: Federated instruction tuning . Preprint , Zhuo Zhang, Xiangjing Hu, Jingyuan Zhang, Y ating Zhang, Hui W ang, Lizhen Qu, and Zenglin Xu. 2023. FEDLEGAL: The first real-world federated learning benchmark for legal NLP . In Pr oceedings of the 61st Annual Meeting of the Association for Compu- tational Linguistics (V olume 1: Long P apers) , pages 3492–3507, T oronto, Canada. Association for Com- putational Linguistics. Ligeng Zhu, Zhijian Liu, and Song Han. 2019. Deep leakage from gradients . Pr eprint , arXi v:1906.08935. A Head-wise Sparsity Decomposition In this appendix, we provide a formal justification sho wing that measuring sparsity globally or in a head-wise manner is equi valent under a block-wise decomposition of feed-forward network (FFN) pa- rameters. A.1 Additivity of Head-wise Sparsity Proposition A.1 (Additivity of Head-wise Spar - sity). Let G ∈ R d × D be a gradient-related matrix associated with a feed-forward netw ork layer . As- sume that G is partitioned column-wise into H disjoint blocks: G = [ G (1) , G (2) , . . . , G ( H ) ] , (20) where G ( h ) ∈ R d × D h and P H h =1 D h = D . For a token embedding e ∈ R d , define its pro- jected response g = G ⊤ e ∈ R D , (21) and correspondingly the head-wise responses g ( h ) = ( G ( h ) ) ⊤ e ∈ R D h . (22) Then the global sparsity of g , measured by the number of non-zero entries, satisfies ∥ g ∥ 0 = H X h =1 ∥ g ( h ) ∥ 0 . (23) An analogous decomposition holds for threshold- based sparsity measures where entries with magni- tude belo w a fixed threshold are treated as zero. Proof . By construction, the blocks G ( h ) corre- spond to disjoint column subsets of G . Conse- quently , the v ectors g ( h ) occupy disjoint coordinate subsets of g . Since sparsity measures such as the ℓ 0 count (or thresholded variants) operate indepen- dently on each coordinate, the total number of non- zero entries in g is exactly the sum of the non-zero entries across all head-wise components: ∥ g ∥ 0 = H X h =1 ∥ g ( h ) ∥ 0 . (24) A.2 Discussion Proposition A.1 shows that e valuating sparsity in a head-wise manner is mathematically equi v alent to e v aluating sparsity on the full projected response under a block-wise decomposition of FFN param- eters. Therefore, adopting a head-a ware sparsity formulation does not introduce additional assump- tions, nor does it alter the underlying sparsity-based filtering objectiv e. Instead, it provides a structured reformulation aligned with the architectural organi- zation of modern transformer FFNs and facilitates more interpretable and numerically stable sparsity estimation. B Effect of Surrogate Labels in Stage III The Stage III gradient atom is defined as g i = ∇ θ L ( f θ ( x i ) , y i ) . Since the true labels of candidate sentences are unkno wn at reconstruction time, we compute can- didate gradients using a fixed surrogate label. Gradient decomposition. For a softmax classi- fier with cross-entropy loss, ∇ θ L ( x, y ) = J θ ( x ) ⊤ ( p − y ) , where J θ ( x ) = ∂ z ∂ θ is the Jacobian of the logits and p = softmax( z ) . Thus the gradient consists of an input-dependent Jacobian J θ ( x ) and a label- dependent coef ficient vector ( p − y ) . If the true label y is replaced by a surrogate label ˜ y , the gradient becomes ˜ g ( x ) = J θ ( x ) ⊤ ( p − ˜ y ) . Both g ( x, y ) and ˜ g ( x ) therefore lie in the same subspace colspan( J θ ( x ) ⊤ ) , meaning that replacing the label preserves the input- dependent gradient structure and only changes the coef ficient vector . Implication f or Stage III. Stage III ranks candi- dates using gradient alignment scores ⟨ g , r t ⟩ . Replacing the true label only modifies the coeffi- cient vector in g r while leaving the Jacobian in- teraction structure unchanged. Consequently , the dominant input-dependent gradient structure is pre- served, and in practice the resulting candidate rank- ing is only weakly af fected by the choice of label. C Hyperparameters This appendix summarizes the hyperparameters used in SOMP . W e distinguish between batch- size-independent hyperparameters, which are fixed across all experiments, and batch-size-dependent hyperparameters, which v ary with the aggregation le vel B . The batch-size-dependent parameters reflect the increased ambiguity and sparsity requirements in- duced by larger gradient mixtures. Importantly , these parameters follow a fixed strategy shared across datasets, languages, and models, rather than being tuned per task or per instance. Discussion. As the batch size increases, the ag- gregated gradient represents a mixture of a larger number of samples, increasing both combinatorial ambiguity and sparsity requirements. Accordingly , SOMP increases the size of the candidate token pool and the breadth of sentence-le vel search while maintaining fixed geometric and sparsity weighting. This strategy enables stable reconstruction across a wide range of aggre gation lev els without per-task hyperparameter tuning. Algorithm 1 Stage I: Head-Structured T oken Pool- ing Require: Aggregated gradient g mix , vocab ulary V Ensure: Filtered token pool P 1: function T O K E N P O O L I N G ( g mix , V ) 2: Decompose g mix into { G ( h ) } H h =1 3: Compute R ( h ) Q ← Span( G ( h ) ) 4: P ← ∅ 5: for v ∈ V do 6: Compute s sub ( v ) , s cons ( v ) , s sparse ( v ) 7: s total ← λ 1 s sub + λ 2 s cons − λ 3 s sparse 8: if v ∈ T op - k then 9: P ← P ∪ { v } 10: end if 11: end for 12: return P 13: end function Algorithm 2 Stage II: Di verse Beam Decoding Require: Global pool P , subspaces R , groups G Ensure: Candidate set X 1: function D I V E R S E B E A M S E A R CH ( P , R ) 2: Detect candidate lengths L ← { L 1 , . . . } 3: X raw ← ∅ 4: for L ∈ L do 5: for t ← 1 T oL do 6: P t ← { v ∈ P | s sub ( v , t ) < τ pos } 7: end for 8: Initialize beam groups B 1 , . . . , B G 9: for t ← 1 T oL do 10: for g ∈ 1 . . . G do 11: Expand B g using P t 12: S ← score base t + λ div 1 ( x t ∈ S t ) + λ ng 1 ( g t ∈ G t ) 13: Prune to top- W /G 14: end for 15: end for 16: X raw ← X raw ∪ S B g 17: end for 18: C ← Cluster ( X raw ) 19: retur n X ← { Rep ( c ) | c ∈ C } 20: end function Category Hyperparameter V alue Stage I λ 1 0 . 8 λ 2 0 . 5 λ 3 0 . 5 τ ( h ) m 0 . 5 × head-wise median Stage II β LM 0 . 33 λ div 0 . 15 λ ng 0 . 2 Stage III λ 1 e − 3 ϵ 1 e − 4 · ∥ g mix ∥ 2 τ cluster 0 . 8 × Rouge-L Model / Exp. H model-specific P 512 T able 4: Batch-size-independent hyperparameters used in SOMP . Hyperparameter B =1 B =4 B =8 B =16+ T oken pool size k 960 1600 2400 3200 Informativ e heads | H act | H/ 4 H/ 4 H / 3 H/ 3 Sparsity heads | H top | H/ 6 H/ 6 H / 4 H / 4 Beam width W 2 4 6 12 Number of beam groups G 1 4 8 16 OMP iterations (max) B B B B T able 5: Batch-size-dependent hyperparameters as a function of aggregation le vel B . C.1 Hyperparameter Sensitivity Analysis W e analyze the sensitivity of SOMP to se veral ke y hyperparameters used in the three-stage reconstruc- tion pipeline. In particular , we examine the influ- ence of parameters controlling token pooling, beam search, and sparse reconstruction. Unless otherwise stated, experiments are con- ducted on the IMDB dataset using GPT -J with batch size B = 8 . For each experiment, we vary one hyperparameter while keeping all others fix ed according to the hyperparameter settings above. Reconstruction quality is measured using R OUGE- L. Overall, SOMP behaves as expected under hy- perparameter variation, b ut remains stable under moderate changes. Small to moderate de viations in parameter values do not lead to abrupt degradation in reconstruction performance, indicating that the method does not rely on fragile tuning. Discussion. The results show that SOMP is in- fluenced by hyperparameter choices, as larger to- ken pools or beam widths generally improve candi- date cov erage at the cost of increased computation. Ho we ver , performance v aries smoothly across a reasonable range of parameter values. In particu- lar , moderate changes in k , W , or λ do not cause catastrophic degradation in reconstruction quality . T able 6: Hyperparameter sensitivity analysis of SOMP . Each parameter is v aried while keeping the others fix ed. Parameter V alue ROUGE-L Stage I: T oken P ooling T oken pool size k 800 59.7 1200 71.5 1600 73.4 2000 74.5 2400 73.3 λ 1 0.6 74.7 0.8 67.3 1.0 53.4 λ 2 0.3 68.4 0.5 74.5 0.7 61.7 Stage II: Beam Decoding Beam width W 2 37.1 4 59.9 6 66.4 8 72.7 12 79.3 λ div 0.1 62.2 0.15 74.7 0.2 69.5 λ ng 0.1 64.8 0.2 74.8 0.3 71.5 Stage III: Sparse Reconstruction λ 5 × 10 − 4 69.8 1 × 10 − 3 74.2 5 × 10 − 3 71.6 1 × 10 − 2 73.7 ϵ 5 × 10 − 5 76.5 1 × 10 − 4 73.9 5 × 10 − 4 68.4 τ cluster 0.6 67.0 0.8 73.5 1.0 81.4 These observ ations suggest that SOMP does not de- pend on fragile hyperparameter tuning and remains robust under typical parameter v ariations. D Algorithmic Details This appendix provides pseudocode for the three stages of SOMP , complementing the high-lev el de- scriptions in Section 4 . Algorithm 1 details head- structured token pooling, Algorithm 2 presents geometry-dri ven di verse beam decoding, and Algo- rithm 3 describes gradient-space sparse reconstruc- tion via Orthogonal Matching Pursuit (OMP). The pseudocode is intended to improve clarity and reproducibility and does not introduce addi- tional assumptions beyond those already discussed in the main text. Algorithm 3 Stage III: OMP Reconstruction Require: g mix , candidates X , batch size B Ensure: Reconstructed batch S ∗ 1: function O M P ( g mix , X ) 2: Dictionary D ← {∇L ( x ) | x ∈ X } 3: r 0 ← g mix , Λ 0 ← ∅ 4: for k = 1 → B do 5: j ∗ ← arg max j |⟨ g j ,r k − 1 ⟩| ∥ g j ∥ 2 6: Λ k ← Λ k − 1 ∪ { j ∗ } 7: α ∗ ← arg min α g mix − P i ∈ Λ k α i g i 2 2 + λ ∥ α ∥ 2 2 8: r k ← g mix − P i ∈ Λ k α ∗ i g i 9: if ∥ r k ∥ < ϵ then 10: break 11: end if 12: end for 13: retur n S ∗ ← { x j | j ∈ Λ k } 14: end function E Full Main Results This appendix reports the full reconstruction results in T able 7 corresponding to the main e xperiments in Section 5 . W e include R OUGE-1 and ROUGE-2 across batch sizes B ∈ { 1 , 2 , 4 , 8 } for all compared methods under the same setup as the main text. E.1 Qualitative Reconstruction Example T o complement the quantitativ e results, we present a qualitati ve reconstruction example under aggre- gated gradients with batch size B = 2 , 4 , 8 . T a- bles 11 , 12 , and 13 compare the outputs generated by SOMP and se veral baselines on the same gra- dient batch. While prior methods such as LAMP , GRAB, and D A GER often produce mismatched or mixed sentences due to cross-sample token interfer- ence, SOMP is able to recov er the original inputs more accurately . F Multilingual Experiment This appendix provides additional multilingual re- construction results in T able 8 corresponding to Section 5.4 . W e report SOMP’ s performance across fi ve languages and analyze the effect of tokeniza- tion dif ferences on reconstruction quality . Across all fiv e ev aluated languages, SOMP remains ef fecti ve without language-specific tun- ing, indicating robustness to dif ferent tokenization schemes. Performance is strongest on English, German, and Chinese, while Italian and French sho w some what lar ger de gradation as batch size increases. This pattern is consistent with heavier subword fragmentation in languages that produce longer tok enized sequences and lar ger candidate branching during decoding. Dataset Method R-1 R-2 R-1 R-2 R-1 R-2 R-1 R-2 B = 1 B = 2 B = 4 B = 8 GPT -J LAMP 31.9 ± 2.4 16.5 ± 3.1 12.7 ± 3.7 7.6 ± 2.0 5.1 ± 0.7 1.4 ± 0.3 1.3 ± 0.4 0.3 ± 0.3 IMDB GRAB 46.1 ± 4.4 33.4 ± 1.4 38.1 ± 3.7 21.7 ± 0.9 33.1 ± 2.1 9.2 ± 1.3 19.7 ± 1.7 2.0 ± 0.6 D AGER 99.2 ± 0.8 94.3 ± 3.2 93.2 ± 3.4 72.0 ± 2.8 88.5 ± 3.1 58.4 ± 2.4 69.3 ± 1.3 39.2 ± 0.8 SOMP 99.5 ± 0.5 96.5 ± 2.1 98.3 ± 1.7 93.6 ± 3.8 94.4 ± 2.7 89.3 ± 1.9 88.4 ± 4.3 73.5 ± 5.1 LAMP 68.6 ± 4.5 42.6 ± 4.7 30.4 ± 3.1 17.8 ± 1.6 22.2 ± 2.9 10.4 ± 1.5 12.6 ± 2.4 6.3 ± 0.7 CoLA GRAB 84.7 ± 4.4 62.5 ± 2.7 76.7 ± 3.6 57.2 ± 3.8 61.8 ± 2.9 42.6 ± 2.4 53.5 ± 2.2 35.1 ± 2.1 D AGER 100.0 ± 0.0 100.0 ± 0.0 100.0 ± 0.0 100.0 ± 0.0 98.5 ± 1.5 92.9 ± 3.1 94.8 ± 2.3 87.8 ± 4.5 SOMP 100.0 ± 0.0 100.0 ± 0.0 100.0 ± 0.0 100.0 ± 0.0 100.0 ± 0.0 96.3 ± 3.7 98.7 ± 1.3 94.5 ± 3.3 LAMP 81.8 ± 3.0 57.8 ± 6.9 36.5 ± 3.2 23.6 ± 3.8 26.5 ± 2.5 12.9 ± 1.2 12.6 ± 2.4 7.2 ± 0.7 SST -2 GRAB 88.3 ± 4.4 66.3 ± 1.2 83.6 ± 3.7 56.5 ± 4.5 70.3 ± 4.2 43.3 ± 2.3 58.9 ± 1.7 36.4 ± 2.5 D AGER 100.0 ± 0.0 100.0 ± 0.0 99.3 ± 0.7 92.0 ± 1.8 99.6 ± 0.4 90.4 ± 3.3 95.1 ± 3.6 86.8 ± 2.9 SOMP 100.0 ± 0.0 100.0 ± 0.0 100.0 ± 0.0 99.8 ± 0.2 99.2 ± 0.8 97.6 ± 2.4 98.2 ± 1.8 95.9 ± 2.5 Dataset Method R-1 R-2 R-1 R-2 R-1 R-2 R-1 R-2 B = 1 B = 2 B = 4 B = 8 GPT -2 LAMP 23.2 ± 5.8 18.8 ± 8.4 11.4 ± 3.2 7.4 ± 1.6 6.8 ± 4.7 2.7 ± 2.4 0.1 ± 0.1 0.1 ± 0.1 IMDB GRAB 37.3 ± 1.8 29.1 ± 1.0 35.5 ± 3.2 21.1 ± 4.5 27.7 ± 4.8 12.8 ± 3.2 16.9 ± 5.8 7.7 ± 4.3 D AGER 99.5 ± 0.5 94.0 ± 4.6 87.2 ± 6.4 78.8 ± 4.7 86.4 ± 5.8 71.6 ± 4.1 68.2 ± 3.2 42.5 ± 2.4 SOMP 99.6 ± 0.4 94.4 ± 3.6 98.3 ± 1.7 94.6 ± 2.3 93.6 ± 3.9 86.3 ± 5.5 87.4 ± 3.4 68.5 ± 4.5 LAMP 73.3 ± 4.5 43.3 ± 7.0 28.6 ± 3.7 11.0 ± 3.8 13.4 ± 1.4 3.9 ± 1.2 8.9 ± 1.6 1.6 ± 0.8 CoLA GRAB 88.6 ± 1.6 65.7 ± 1.4 84.9 ± 1.2 56.8 ± 1.2 79.2 ± 0.7 52.8 ± 3.0 73.6 ± 1.7 45.6 ± 5.9 D AGER 100.0 ± 0.0 100.0 ± 0.0 100.0 ± 0.0 100.0 ± 0.0 100.0 ± 0.0 95.6 ± 1.8 99.6 ± 0.4 96.2 ± 2.1 SOMP 100.0 ± 0.0 100.0 ± 0.0 100.0 ± 0.0 98.2 ± 0.0 99.2 ± 0.8 94.0 ± 2.9 100.0 ± 0.0 97.5 ± 0.5 LAMP 62.2 ± 6.2 31.8 ± 8.4 21.4 ± 3.2 9.5 ± 3.6 9.8 ± 1.9 2.6 ± 1.4 8.1 ± 0.7 0.7 ± 0.4 SST -2 GRAB 91.2 ± 0.5 63.4 ± 0.0 82.6 ± 1.7 53.7 ± 0.4 69.8 ± 1.2 38.1 ± 0.6 62.7 ± 0.6 33.8 ± 0.1 D AGER 100.0 ± 0.0 96.0 ± 3.0 100.0 ± 0.0 89.5 ± 1.4 100.0 ± 0.0 92.8 ± 2.4 100 ± 0.0 92.9 ± 1.6 SOMP 100.0 ± 0.0 98.8 ± 0.8 100.0 ± 0.0 97.5 ± 0.9 100.0 ± 0.0 98.4 ± 0.4 99.3 ± 0.7 95.8 ± 1.5 T able 7: Full reconstruction results for the main e xperiments, reporting ROUGE-1 and R OUGE-2 across datasets and batch sizes for GPT -J and GPT -2. Language B=1 B=4 B=8 B=16 English 99.7 ± 0.3 94.3 ± 1.4 88.2 ± 1.7 83.5 ± 2.1 German 99.6 ± 0.4 94.6 ± 0.8 89.7 ± 2.1 82.3 ± 2.6 Chinese 99.8 ± 0.2 93.1 ± 1.2 88.1 ± 1.4 84.4 ± 3.4 Italian 99.7 ± 0.3 90.2 ± 1.5 83.3 ± 1.8 78.1 ± 1.8 French 95.7 ± 2.1 86.3 ± 3.3 80.5 ± 3.6 72.8 ± 3.7 T able 8: Multilingual reconstruction perfor- mance of SOMP on Qwen3 across batch sizes on stanfordNLP/imdb . G Reconstruction under F edA vg This appendix reports additional results under the FedA vg training protocol, complementing the sum- mary in Section 5.5 . W e e v aluate whether multiple local updates before aggreg ation mitigate gradient leakage. Experimental Setup. W e conduct experiments on GPT-2 using the Rotten T omatoes dataset. Un- less otherwise specified, we use E = 10 local epochs, learning rate η = 10 − 4 , and mini-batch size B mini = 4 . Reconstruction quality is measured using R OUGE-1 and R OUGE-2. E η B mini R-1 R-2 2 10 − 4 4 99.1 ± 0.9 98.2 ± 1.1 5 10 − 4 4 97.5 ± 1.3 95.8 ± 1.3 10 10 − 4 4 95.3 ± 1.8 93.9 ± 1.6 20 10 − 4 4 95.7 ± 0.9 94.4 ± 1.4 10 10 − 5 4 99.8 ± 0.2 99.1 ± 0.9 10 5 × 10 − 5 4 98.7 ± 0.9 97.9 ± 1.2 10 10 − 4 4 94.5 ± 1.4 93.6 ± 1.7 10 10 − 4 2 93.3 ± 1.9 91.4 ± 2.2 10 10 − 4 8 97.7 ± 1.3 96.1 ± 1.6 10 10 − 4 16 99.5 ± 0.5 98.6 ± 0.8 T able 9: Reconstruction performance of SOMP under FedA vg on GPT -2 (Rotten T omatoes). E denotes the number of local epochs, η the learning rate, and B mini the mini-batch size. Results. As sho wn in T able 9 , FedA vg does not eliminate gradient leakage across a range of rea- sonable training configurations. SOMP remains capable of recovering sensitive information e ven when multiple local epochs are performed before aggregation. Noise Level σ ROUGE-1 R OUGE-2 10 − 5 78.1 ± 3.3 72.8 ± 4.1 5 × 10 − 5 55.9 ± 4.2 34.5 ± 3.9 10 − 4 26.7 ± 4.0 16.6 ± 3.6 5 × 10 − 4 9.6 ± 3.5 1.9 ± 1.9 T able 10: Exploratory reconstruction performance of SOMP under additiv e Gaussian noise on GPT -2 (Rotten T omatoes, B = 1 ). Higher noise lev els correspond to stronger perturbation of the aggregated gradient. H Exploratory Results with Differential-Pri vacy-Inspired Noise This appendix provides an exploratory analysis of SOMP under differential pri vacy–inspired de- fenses. In particular , we in vestigate the effect of additi ve Gaussian noise applied to aggre gated gra- dients. These experiments are preliminary and do not provide formal dif ferential priv acy guarantees; they are intended only to assess the qualitativ e be- havior of gradient in version under noisy training signals. Experimental Setup. Follo wing prior work, we apply zero-mean Gaussian noise with v ariance σ 2 to the aggreg ated gradient g mix before reconstruc- tion. W e ev aluate SOMP on GPT-2 using the Rotten T omatoes dataset with batch size B = 1 . Recon- struction quality is measured using R OUGE-1 and R OUGE-2. Results and Discussion. As shown in T able 10 , reconstruction quality degrades rapidly as the noise magnitude increases. At sufficiently lar ge noise le vels, SOMP fails to recover meaningful inputs. A systematic e valuation under formal dif ferential pri v acy mechanisms, such as DP-SGD with per- sample clipping and priv acy accounting, remains an important direction for future work. Reference Inputs LAMP GRAB D A GER SOMP I received this movie as a gift, I knew from ... movies, don’ t watch this movie. I camcorder movie" D VD sucks filmmaker knew w ane bee ... movies,
Sgt this movie. town w atched it pro- duce movie, Ben Draper ... ries HORR OR revenge woman absolute. I received this mo vie as a gift, I knew from ... movies, don’t watch this movie. I received this mo vie as a gift, I knew from ... movies, don’t watch this movie. I very much looked for- ward to this movie. ... a good lov e story . I very Michael place W illie generally to they ... Chris capt.
’ s con- text ’ re romantic. Its Jr . ’ s editing to much is be T oo. better care ... love W illie and Missy;series. I very much looked for- ward to Michael ... a good lov e Michael. I very much looked for- ward to this movie. ... a good lov e story . Protocol is an implausi- ble movie whose only ... way to see this film. Protocol Lov e’ s implausi- ble Missy very much ... because see Plus. Jr . ’ s is But, implausible romantic always only ... always enjo y role film. Protocol is an implausible movie whose only ... way to see this movie. Protocol is an implausible movie whose only ... way to see this film. I was excited to vie w a Cataluña ´ s film in ... to go to see this film. I was excited Berlin ´ s a Cataluña ´ s film in ... , was horrible. competition . Cataluña, too horr to view a Cataluña ´ s see film ... to Molina this film. I was excited to view a Cataluña ´ s film in ... to go to see this film. I was excited to view a Cataluña ´ s film in ... to go ´ s to see Cataluña ´ s film. T able 11: Qualitativ e reconstruction examples under aggregated gradients with batch size B = 2 . Highlighted spans indicate incorrect tokens caused by cross-sample mixing. Reference Inputs LAMP GRAB D A GER SOMP A model named Laura is working in South America when ... jun- gle. It would probably be more fun.
3/10 A Laura named iv e fake Laura in Amer - ica America ... vision. far). Franco happening. probab be film fun.
3/10 primitiv es Hunter named Devil.
films working drags ity in (25 ...laugh. hilariously killed real fun more fun.
.
A model named Laura is working in hotel when Devil Hunter is film film her hotel ... It would probably be more fun.
3/10 A model named Laura is work in South America when ...jungle. It would probably be more fun.3/10 .3/10.3/10. Devil Hunter gained notoriety for the fact that ... no reason to bother with this one. Devil Hunter film no- toriety for the ’V ideo Nasty’ that’ s films the DPP ... with this one devil blood horror . DPP Hunter gained notori- ety for films kid- napped that title). the the ... She Kills in Ec- stasy Nasty list but it re- ally needn’t ha ve been Devil Hunter gained notoriety for the fact that ... basic V enus film films Devil this one. Devil Hunter gained notoriety for the fact that ... no reason to bother with this one one This film seemed way too long ev en ... proba- bly didn’t see an uncut version. This film version too uncut probably way ... scene blood camera long didn’t see . 75 zombie too long seemed ev en ... dub- bing didn’t rock y dubbing way clif f version. This film seemed way too long ev en ... film films’t zombie / flick film films... This film seemed way too long ev en ... proba- bly didn’t see an uncut version. I cannot stay indiffer - ent to Lars van Trier’ s films. I ... to the view- ers to decide this alone. I films alone T rier’ s viewers ... cannot decide horror camera devil Lars stay . Dancer cannot to consider different v an van Lars’ s masterpiece ... pre- ambiguous
decide this Europa Europa . I cannot stay indiffer - ent to Lars van Trier’ s films. I ... differ - ent filmmaker v an Lars van demonstrati ve this alone. ’ s.. I cannot stay different to Lars v an T rier’s films. I ... to the viewers to decide this alone ... Ah, Channel 5 of local Mexican t.v . Everyday , at 2:00 ... film-making.
Y ou have been warned. Ah, warned Mexican 2:00 Channel ... film- making blood devil street local been Every- day . Ah, Mexican Ah, Ah, Mexican t.v . Ah,... Ev- eryday at 2:00 been film-making. Y ou have warned. Ah, Channel 5 of local Mexican Ah, Mexican, at 2:00... film-film film.
later fil ms, cinematography warned. Ah, Channel 5 of local Mexican Ah, Every- day , at 2:00 ... film- making.Ah,Ah, Y ou hav e been warned. T able 12: Qualitativ e reconstruction examples under aggregated gradients with batch size B = 4 . Highlighted spans indicate incorrect tokens caused by cross-sample mixing. Reference Inputs LAMP GRAB D A GER SOMP Sloppily directed, wit- less comedy that sup- posedly ... be be g- ging for some peace and quiet. (*1/2) peace quiet comedy begging sloppily * ... hotel blood ’t camera witless scene . quiet comedy peace ... witless directed ’ s begging some film street . Sloppily directed, wit- less comedy that sup- posedly ... doomed James James 50s Royale Royale Ro yale Royale..*(*2(. Sloppily directed, witless comedy that comedy spoofs ... be be g- ging some Royale and Ro yale..(*1/2)... I was disgusted by this movie. No it wasn’t ... movie, b ut find out the true story of Artemisia. movie disgusted Artemisia true ... story Beav er devil blood find out . Artemisia movie disgusted ... Beav er Beav er find scene film . I was disgusted by this movie. No it wasn’t ...
movie, but mo vie movie the Artemisia Gentileschi. I was disgusted by this movie. No it it ’t ... movie, but find out the true Artemisia of Artemi- sia.... I didn’t think the French could make a bad mo vie, but ... pornography . So the French can fail, after all! French pornography bad movie ... after fail camera street horror French . pornography think French ... bad movie fail after film camera . I was disgusted by this movie. No it wasn’t ...
movie, but mo vie movie the Artemisia Gentileschi. I didn’t think the French could make a bad mo vie, but ... pornography . So the French can fail, after all! , after all!, after all!!!!! I read somewhere that when Kay Francis re- fused to ... and you’ll be doing yourself a fa- vor . fa vor somewhere yourself doing ... Kay Francis camera jungle blood . fa vor Francis somewhere ... doing yourself Kay film scene . I read somewhere that when Kay Francis refused to ... and Francis’ll movie
Also, a fa vor . And her hair!!! I read somewhere that when Kay Francis refused to ... and you’ll be yourself a fa vor f a- vor a a a a... A stale "misfits-in-the- army" saga, which ... Me", has only two or three brief scenes. What a waste! (*1/2) saga brief scenes ... waste army devil hotel camera three . brief films ... scenes to waste army film . A stale "misfits-in-the- army" saga, which ... Me", saga only two misfits misfits brief scenes. What a waste! (*1/2) A stale "misfits-in-the- army" saga, which ... Me", has only two three scenes. What a waste! (*1/2)! (*1/2)) When I was at the movie store the other day , I passed up ... and Blonder is a huge blonde BOMB- shell.
1/10 When I movie store ... Michelle Romy Anderson blood street scene day . Blonder store ... huge blonde stupid movie Michelle film . When I was at the movie store the other day , I passed up ... and Blonder is a huge BOMB.
1/10
1/10 When I was at the movie store the other day , I passed up ... and Blonder is a blonde Blonder .
1/10 ..... D T able 13: Qualitativ e reconstruction examples under aggregated gradients with batch size B = 8 . Highlighted spans indicate incorrect tokens caused by cross-sample mixing.
3 stars. Jill Dunne (played by Mitzi Kap- ture),is an ... nothing happens! Jill Dunne (played by Mitzi Kap- ture), is an ... Jill.
3 stars. ... ... ... 8 If the term itself were not geo- graphically ... different accents. If the term itself were not ... Ned Kelly geographic Ned K elly If the term itself were not geo- graphically ... different accents. SWING! It’ s an important film because ... it’ s really , really bad! SWING! It’ s an important film be- cause ... it’ s real real real real SWING! It’ s an important film because ...it’ s really bad!!! T able 1: Reconstruction examples under aggregated gradients at B = 2 , 4 , 8 . Highlighted spans mark incorrect tokens. As B increases, D A GER degrades faster , while SOMP remains more faithful to the reference inputs. reimplemented under the same aggregation pro- tocol and ev aluation pipeline. Reconstruction qual- ity is measured using sequence-lev el ROUGE-1 , R OUGE-2 , and ROUGE-L ( Lin , 2004 ), av eraged ov er 50 random batches and reported as mean ± standard deviation. For readability , the main text reports R OUGE-L ; full ROUGE-1/2/L results are provided in Appendix E and follo w the same over - all setting. Our main experiments focus on standard aggregated-gradient training rather than formal DP mechanisms such as DP-SGD. W e include an ex- ploratory Gaussian-noise study in Appendix H , while a full DP-SGD e valuation with clipping and pri v acy accounting is left for future w ork. 5.2 Reconstruction Perf ormance and Comparisons Figure 2 and T able 2 summarize the main com- parison against prior text-based gradient in version methods. The ov erall pattern is clear: SOMP achie ves the strongest reconstruction quality once gradients are mixed across multiple samples, and its adv antage becomes more pronounced as batch size increases. The largest gains appear on IMDB , where long inputs make cross-sample interfer- ence especially severe. T able 1 provides repre- sentati ve qualitati ve examples comparing D A GER and SOMP . Under mixed gradients, D A GER of- ten merges samples with similar prefix es, repeats locally plausible tokens, or drifts tow ard nearby embedding-space neighbors. The resulting out- puts can remain superficially fluent while failing to separate the underlying samples correctly . In con- trast, SOMP more reliably disentangles the mix ed signals and reconstructs the original inputs. Addi- tional qualitati ve e xamples comparing all methods are provided in Appendix E.1 . The main difficulty comes from increasing batch size, not from sequence length alone. IMDB is the most challenging benchmark in our study because it combines long inputs with cross-sample mixing. As sho wn in T able 2 , reconstruction quality gener- ally degrades as B increases, but prior approaches degrade much more sharply . For e xample, on GPT - J-6B, D A GER drops from 58 . 4 at B = 4 to 39 . 2 at B = 8 , whereas SOMP still reaches 73 . 5 at B = 8 . This gap widens further at B = 16 . Importantly , the full results in Appendix E show that D A GER remains highly effecti ve at B = 1 on IMDB . This indicates that long sequences alone are not the main bottleneck for search-based in ver - sion. The real challenge emerges when multiple long documents are mixed into a single observed gradient, which is exactly the re gime where SOMP provides its largest gains. On shorter-sequence benchmarks such as CoLA and SST-2 , inv ersion remains comparati vely easier, and both D A GER and SOMP perform strongly at small and moderate batch sizes. Ev en in these easier settings, ho we ver , SOMP degrades more gracefully as B gro ws. This sho ws that SOMP is not mainly designed to max- imize gains in easy cases, but to remain ef fective where prior attacks become brittle. SOMP remains effecti ve at substantially larger batch sizes. Figure 3 e xtends the comparison to Figure 2: Reconstruction performance (R OUGE-L) under aggregated gradients at batch sizes B = 1, 2, 4, 8, and 16 on IMDB, CoLA, and SST -2 using GPT -J-6B (top) and GPT -2 (bottom). SOMP shows the largest gains on IMDB, whose longer inputs make multi-sample in version harder than on shorter datasets such as CoLA and SST -2. T able 2: Reconstruction performance (R OUGE-L) un- der aggregated gradients at B = 4 , 8 , 16 on GPT -J-6B. Dataset Method B = 4 B = 8 B = 16 LAMP 1 . 2 ± 0 . 8 0 . 3 ± 0 . 3 0 . 1 ± 0 . 1 GRAB 8 . 6 ± 2 . 4 2 . 0 ± 0 . 6 0 . 9 ± 0 . 9 IMDB D AGER 58 . 4 ± 2 . 4 39 . 2 ± 0 . 8 31 . 6 ± 1 . 5 SOMP 89.3 ± 1.9 73.5 ± 5.1 76.4 ± 2.1 LAMP 10 . 6 ± 1 . 8 6 . 3 ± 0 . 7 1 . 4 ± 0 . 3 GRAB 42 . 6 ± 2 . 4 35 . 1 ± 2 . 1 24 . 3 ± 2 . 6 CoLA D A GER 92 . 9 ± 3 . 1 87 . 8 ± 4 . 5 84 . 8 ± 3 . 2 SOMP 96.3 ± 3.7 94.5 ± 3.3 89.7 ± 2.9 LAMP 12 . 9 ± 1 . 2 7 . 2 ± 0 . 7 1 . 8 ± 0 . 8 GRAB 43 . 3 ± 2 . 3 36 . 4 ± 2 . 5 22 . 3 ± 3 . 7 SST -2 DA GER 100 . 0 ± 0 . 0 92 . 9 ± 1 . 6 87 . 1 ± 2 . 4 SOMP 100.0 ± 0.0 95.8 ± 1.5 92.6 ± 1.9 much larger batch sizes on IMDB . W e can see that D A GER degrades rapidly as B increases. In con- trast, SOMP continues to reco ver meaningful text e ven at batch sizes far be yond the range where ear- lier methods begin to collapse. The same trend appears for both GPT-J-6B and Qwen3-8B , suggest- ing that the advantage of SOMP is not specific to a single architecture family . 5.3 Efficiency and Scalability SOMP impro ves efficienc y by filtering and scor- ing candidates in informativ e head-wise subspaces, rather than repeatedly verifying them in the full di- mensional space. This matters most when the can- didate set grows lar ge, since full-space verification becomes the main cost for search-based baselines Figure 3: Reconstruction performance (R OUGE-L) on GPT -J-6B and Qwen3-8B o ver larger batch sizes on IMDB . SOMP remains effecti ve substantially beyond the regime where prior methods de grade sharply . such as D A GER. T able 3 reports measured per- batch runtime under se veral beam widths. On short- sequence benchmarks such as CoLA and SST-2 , SOMP may incur some ov erhead from Stage III sparse reconstruction. On IMDB , howe ver , where sequences are longer and the search space is much larger , SOMP shows a clearly more f av orable run- time profile. W e note that SOMP is not designed to be uniformly faster in e very setting. In easier regimes, the added OMP stage can make it compa- rable to or slightly slower than simpler baselines. In long-sequence, lar ger-batch settings, ho wev er , SOMP becomes increasingly competitiv e and is of- ten faster , while also achieving substantially better reconstruction quality . Figure 4: Ablation at batch sizes ( B = 2 , 4 , 8 ). V ariants remove LM prior (SOMP1), OMP (SOMP2), sparsity scoring (SOMP3), cross-head consistency (SOMP4), and subspace-distance scoring (SOMP5). T able 3: A verage per -batch runtime in seconds. Bw denotes beam width. Dataset Method B=1 B=2 B=4 B=8 B=16 GPT -2 (runtime measured on R TX 5060) D AGER 3 6 10 19 36 CoLA SOMP(Bw=4) 7 10 13 21 26 SOMP(Bw=8) 7 10 14 24 31 SOMP(Bw=16) 8 13 21 33 41 D AGER 3 4 9 18 31 SST -2 SOMP(Bw=4) 6 9 13 22 30 SOMP(Bw=8) 7 11 14 26 37 SOMP(Bw=16) 8 12 30 40 52 D AGER 61 118 248 467 1127 IMDB SOMP(Bw=4) 48 96 191 359 672 SOMP(Bw=8) 58 117 231 448 968 SOMP(Bw=16) 75 143 289 572 1308 5.4 Multilingual Evaluation W e ne xt test whether SOMP generalizes be yond English. Across fiv e languages, SOMP maintains strong reconstruction quality without language- specific tuning, suggesting that its effecti veness does not depend on English-specific tokenization patterns. As sho wn in T able 8 of Appendix F , per - formance remains strongest on English, German, and Chinese, while French and Italian degrade more noticeably as batch size increases. A likely reason is heavier subword fragmentation, which leads to longer tokenized sequences and a lar ger decoding search space. Even so, SOMP remains ef fecti ve across all e valuated languages, indicating that it e xploits structural properties of aggre gated transformer gradients that persist across languages. 5.5 Reconstruction under FedA vg W e also e v aluate SOMP under FedA vg , where clients perform multiple local updates before aggre- gation. This setting is more realistic than one-step FedSGD and more challenging for in version, as the attacker observes only the final model update after local training (see Appendix G ). The results sho w that FedA vg does not eliminate leakage: across local epochs, learning rates, and mini-batch sizes, SOMP still reco vers substantial information from the observed update. Overall, these experiments indicate that the leakage exploited by SOMP is not specific to single-step FedSGD, but can persist under practical federated optimization. 5.6 Ablation Study W e ablate the main components of SOMP in Fig- ure 4 , including the LM prior , OMP-based sparse reconstruction, sparsity scoring, cross-head consis- tency , and subspace-distance scoring. Removing OMP causes the largest drop, especially at larger batch sizes and longer sequence lengths, showing that sparse reconstruction is the ke y step for resolv- ing cross-sample ambiguity in the highly mixed regime. The other components also contribute con- sistently: the LM prior and cross-head consistency matter more as batch size increases, while sparsity scoring and subspace-based filtering help suppress noisy candidates earlier in the pipeline. Overall, the gains of SOMP come from the interaction of its stages rather than from any single heuristic. 6 Conclusion W e presented SOMP , a subspace-guided and sparsity-dri ven frame work for reconstructing tex- tual inputs from aggreg ated gradients of large lan- guage models. By exploiting the multi-head struc- ture of transformer gradients, SOMP combines ge- ometric filtering, language-model–guided decod- ing, and sparse gradient-space reconstruction. Ex- perimental results sho w that SOMP enables accu- rate and stable multi-sample reconstruction under aggregated-gradient settings, particularly for long sequences and large batch sizes. Overall, SOMP provides a principled and scalable approach to gra- dient in version in practical training scenarios. 7 Limitations SOMP relies on structural regularities in first-layer query gradients and uses head-wise decomposition to reduce the search space. Although modern trans- formers may adopt alternati ve attention designs such as grouped-query attention (GQA), our exper- iments on Qwen3-8B show that performance re- mains comparable under this architecture. A more challenging setting would be architectures where head-le vel gradient patterns are substantially less separable. In addition, Stage I requires maintaining a high- recall token pool. Under sev erely distorted, com- pressed, or noisy gradients, relev ant tokens may be pruned too early during candidate filtering, af fect- ing do wnstream reconstruction. From an ef ficiency perspecti ve, while head-wise factorization reduces the cost of candidate v erification, the OMP-based sparse reconstruction in Stage III introduces addi- tional ov erhead. As a result, SOMP may be slower on short sequences and small batch sizes, but be- comes increasingly competitiv e as sequence length and aggregation le vel increase. Finally , our main e v aluation does not study for - mal dif ferential pri v acy mechanisms such as DP- SGD. While we include initial experiments with additi ve Gaussian noise in the Appendix H , these results do not constitute a systematic ev aluation of dif ferential pri v acy , since they do not incorporate the full DP-SGD pipeline with gradient clipping and priv acy accounting. A more complete study un- der noisy , clipped, or DP-SGD-perturbed gradients remains future work. 8 Ethical Considerations This work inv estigates the feasibility of reconstruct- ing textual inputs from aggre gated gradients, high- lighting potential priv acy risks in federated and distributed training of lar ge language models. Our goal is to better understand the conditions under which gradient leakage may occur , in order to in- form the design of safer and more priv acy-a ware training protocols. W e do not advocate the misuse of gradient in ver- sion techniques. Instead, our findings emphasize the importance of established pri v acy safe guards, such as secure aggregation and dif ferential priv acy . References Mislav Balunovi ´ c, Dimitar I. Dimitrov , Nikola Jo- vano vi ´ c, and Martin V echev . 2022. Lamp: Extract- ing text from gradients with language model priors . Pr eprint , Xinping Chen and Chen Liu. 2025. Gradient inv er- sion transcript: Leveraging rob ust generativ e priors to reconstruct training data from gradient leakage . Pr eprint , Sumanth Dathathri, Andrea Madotto, Janice Lan, Jane Hung, Eric Frank, Piero Molino, Jason Y osinski, and Rosanne Liu. 2020. Plug and play language mod- els: A simple approach to controlled text generation . Pr eprint , Jacob Devlin, Ming-W ei Chang, Kenton Lee, and Kristina T outanov a. 2019. BER T: Pre-training of deep bidirectional transformers for language under - standing . In Pr oceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language T ech- nologies, V olume 1 (Long and Short P apers) , pages 4171–4186, Minneapolis, Minnesota. Association for Computational Linguistics. Dimitar I. Dimitro v , Maximilian Baader , Mark Niklas Müller , and Martin V echev . 2024. Spear:exact gra- dient in version of batches in federated learning . Pr eprint , Xinguo Feng, Zhongkui Ma, Zihan W ang, Eu Joe Chegne, Mengyao Ma, Alsharif Abuadbba, and Guangdong Bai. 2024. Uncov ering gradient in ver- sion risks in practical language model training . In Pr oceedings of the 2024 on ACM SIGSAC Confer- ence on Computer and Communications Security , CCS ’24, page 3525–3539, New Y ork, NY , USA. Association for Computing Machinery . Jiahui Geng, Y ongli Mou, Feifei Li, Qing Li, Oya Beyan, Stefan Decker , and Chunming Rong. 2022. T ow ards general deep leakage in federated learning . Pr eprint , Y angsibo Huang, Samyak Gupta, Zhao Song, Kai Li, and Sanjee v Arora. 2021. Evaluating gradient in- version attacks and defenses in federated learning . Pr eprint , Jian Li, Baosong Y ang, Zi-Y i Dou, Xing W ang, Michael R. L yu, and Zhaopeng T u. 2019. Infor- mation aggregation for multi-head attention with routing-by-agreement . Pr eprint , Qiongxiu Li, Lixia Luo, Agnese Gini, Changlong Ji, Zhanhao Hu, Xiao Li, Chengfang Fang, Jie Shi, and Xiaolin Hu. 2024. Perfect gradient in version in fed- erated learning: A ne w paradigm from the hidden subset sum problem . Pr eprint , Zhuohang Li, Jiaxin Zhang, Luyang Liu, and Jian Liu. 2022. Auditing priv acy defenses in federated learning via generativ e gradient leakage . Pr eprint , Chin-Y ew Lin. 2004. ROUGE: A package for auto- matic e v aluation of summaries . In T ext Summariza- tion Branc hes Out , pages 74–81, Barcelona, Spain. Association for Computational Linguistics. Andrew L. Maas, Raymond E. Daly , Peter T . Pham, Dan Huang, Andrew Y . Ng, and Christopher Potts. 2011. Learning word v ectors for sentiment analysis . In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language T echnologies , pages 142–150, Portland, Oregon, USA. Association for Computational Lin- guistics. H. Brendan McMahan, Eider Moore, Daniel Ram- age, Seth Hampson, and Blaise Agüera y Ar- cas. 2023. Communication-ef ficient learning of deep networks from decentralized data . Pr eprint , Ivo Petrov , Dimitar I. Dimitrov , Maximilian Baader , Mark Niklas Müller , and Martin V echev . 2024. Dager: Exact gradient in version for large language models . Pr eprint , Alec Radford, Jef f W u, Rew on Child, David Luan, Dario Amodei, and Ilya Sutske ver . 2019. Language models are unsupervised multitask learners . Y ueyue Shi, Hengjie Song, and Jun Xu. 2023. Re- sponsible and effecti ve federated learning in financial services: A comprehensi ve survey . In 2023 62nd IEEE Confer ence on Decision and Control (CDC) , pages 4229–4236. Richard Socher , Alex Perelygin, Jean W u, Jason Chuang, Christopher D. Manning, Andre w Ng, and Christopher Potts. 2013. Recursiv e deep models for semantic compositionality over a sentiment treebank . In Proceedings of the 2013 Confer ence on Empiri- cal Methods in Natural Language Pr ocessing , pages 1631–1642, Seattle, W ashington, USA. Association for Computational Linguistics. Zhen Ling T eo, Liyuan Jin, Nan Liu, Siqi Li, Di Miao, Xiaoman Zhang, W ei Y an Ng, T ing F ang T an, Deb- orah Meixuan Lee, Kai Jie Chua, John Heng, Y ong Liu, Rick Siow Mong Goh, and Daniel Shu W ei T ing. 2024. Federated machine learning in health- care: A systematic re vie w on clinical applications and technical architecture . Cell Reports Medicine , 5(2):101419. Elena V oita, David T albot, Fedor Moisee v , Rico Sen- nrich, and Ivan T itov . 2019. Analyzing multi-head self-attention: Specialized heads do the heavy lift- ing, the rest can be pruned . In Pr oceedings of the 57th Annual Meeting of the Association for Computa- tional Linguistics , pages 5797–5808, Florence, Italy . Association for Computational Linguistics. Ben W ang and Aran Komatsuzaki. 2021. GPT -J- 6B: A 6 Billion Parameter Autoregressiv e Lan- guage Model. https://github.com/kingoflolz/ mesh- transformer- jax . Alex W arstadt, Amanpreet Singh, and Samuel R. Bow- man. 2019. Neural network acceptability judgments . T ransactions of the Association for Computational Linguistics , 7:625–641. An Y ang, Anfeng Li, Baosong Y ang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Y u, Chang Gao, Chengen Huang, Chenxu Lv , Chujie Zheng, Day- iheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran W ei, Huan Lin, Jialong T ang, and 41 others. 2025. Qwen3 technical report . Pr eprint , Y uhang Y ao, Jianyi Zhang, Junda W u, Chengkai Huang, Y u Xia, T ong Y u, Ruiyi Zhang, Sungchul Kim, Ryan Rossi, Ang Li, Lina Y ao, Julian McAuley , Y iran Chen, and Carlee Joe-W ong. 2025. Federated large language models: Current progress and future direc- tions . Pr eprint , Jianyi Zhang, Saeed V ahidian, Martin Kuo, Chun yuan Li, Ruiyi Zhang, T ong Y u, Y ufan Zhou, Guoyin W ang, and Y iran Chen. 2024. T ow ards b uilding the federated gpt: Federated instruction tuning . Preprint , Zhuo Zhang, Xiangjing Hu, Jingyuan Zhang, Y ating Zhang, Hui W ang, Lizhen Qu, and Zenglin Xu. 2023. FEDLEGAL: The first real-world federated learning benchmark for legal NLP . In Pr oceedings of the 61st Annual Meeting of the Association for Compu- tational Linguistics (V olume 1: Long P apers) , pages 3492–3507, T oronto, Canada. Association for Com- putational Linguistics. Ligeng Zhu, Zhijian Liu, and Song Han. 2019. Deep leakage from gradients . Pr eprint , arXi v:1906.08935. A Head-wise Sparsity Decomposition In this appendix, we provide a formal justification sho wing that measuring sparsity globally or in a head-wise manner is equi valent under a block-wise decomposition of feed-forward network (FFN) pa- rameters. A.1 Additivity of Head-wise Sparsity Proposition A.1 (Additivity of Head-wise Spar - sity). Let G ∈ R d × D be a gradient-related matrix associated with a feed-forward netw ork layer . As- sume that G is partitioned column-wise into H disjoint blocks: G = [ G (1) , G (2) , . . . , G ( H ) ] , (20) where G ( h ) ∈ R d × D h and P H h =1 D h = D . For a token embedding e ∈ R d , define its pro- jected response g = G ⊤ e ∈ R D , (21) and correspondingly the head-wise responses g ( h ) = ( G ( h ) ) ⊤ e ∈ R D h . (22) Then the global sparsity of g , measured by the number of non-zero entries, satisfies ∥ g ∥ 0 = H X h =1 ∥ g ( h ) ∥ 0 . (23) An analogous decomposition holds for threshold- based sparsity measures where entries with magni- tude belo w a fixed threshold are treated as zero. Proof . By construction, the blocks G ( h ) corre- spond to disjoint column subsets of G . Conse- quently , the v ectors g ( h ) occupy disjoint coordinate subsets of g . Since sparsity measures such as the ℓ 0 count (or thresholded variants) operate indepen- dently on each coordinate, the total number of non- zero entries in g is exactly the sum of the non-zero entries across all head-wise components: ∥ g ∥ 0 = H X h =1 ∥ g ( h ) ∥ 0 . (24) A.2 Discussion Proposition A.1 shows that e valuating sparsity in a head-wise manner is mathematically equi v alent to e v aluating sparsity on the full projected response under a block-wise decomposition of FFN param- eters. Therefore, adopting a head-a ware sparsity formulation does not introduce additional assump- tions, nor does it alter the underlying sparsity-based filtering objectiv e. Instead, it provides a structured reformulation aligned with the architectural organi- zation of modern transformer FFNs and facilitates more interpretable and numerically stable sparsity estimation. B Effect of Surrogate Labels in Stage III The Stage III gradient atom is defined as g i = ∇ θ L ( f θ ( x i ) , y i ) . Since the true labels of candidate sentences are unkno wn at reconstruction time, we compute can- didate gradients using a fixed surrogate label. Gradient decomposition. For a softmax classi- fier with cross-entropy loss, ∇ θ L ( x, y ) = J θ ( x ) ⊤ ( p − y ) , where J θ ( x ) = ∂ z ∂ θ is the Jacobian of the logits and p = softmax( z ) . Thus the gradient consists of an input-dependent Jacobian J θ ( x ) and a label- dependent coef ficient vector ( p − y ) . If the true label y is replaced by a surrogate label ˜ y , the gradient becomes ˜ g ( x ) = J θ ( x ) ⊤ ( p − ˜ y ) . Both g ( x, y ) and ˜ g ( x ) therefore lie in the same subspace colspan( J θ ( x ) ⊤ ) , meaning that replacing the label preserves the input- dependent gradient structure and only changes the coef ficient vector . Implication f or Stage III. Stage III ranks candi- dates using gradient alignment scores ⟨ g , r t ⟩ . Replacing the true label only modifies the coeffi- cient vector in g r while leaving the Jacobian in- teraction structure unchanged. Consequently , the dominant input-dependent gradient structure is pre- served, and in practice the resulting candidate rank- ing is only weakly af fected by the choice of label. C Hyperparameters This appendix summarizes the hyperparameters used in SOMP . W e distinguish between batch- size-independent hyperparameters, which are fixed across all experiments, and batch-size-dependent hyperparameters, which v ary with the aggregation le vel B . The batch-size-dependent parameters reflect the increased ambiguity and sparsity requirements in- duced by larger gradient mixtures. Importantly , these parameters follow a fixed strategy shared across datasets, languages, and models, rather than being tuned per task or per instance. Discussion. As the batch size increases, the ag- gregated gradient represents a mixture of a larger number of samples, increasing both combinatorial ambiguity and sparsity requirements. Accordingly , SOMP increases the size of the candidate token pool and the breadth of sentence-le vel search while maintaining fixed geometric and sparsity weighting. This strategy enables stable reconstruction across a wide range of aggre gation lev els without per-task hyperparameter tuning. Algorithm 1 Stage I: Head-Structured T oken Pool- ing Require: Aggregated gradient g mix , vocab ulary V Ensure: Filtered token pool P 1: function T O K E N P O O L I N G ( g mix , V ) 2: Decompose g mix into { G ( h ) } H h =1 3: Compute R ( h ) Q ← Span( G ( h ) ) 4: P ← ∅ 5: for v ∈ V do 6: Compute s sub ( v ) , s cons ( v ) , s sparse ( v ) 7: s total ← λ 1 s sub + λ 2 s cons − λ 3 s sparse 8: if v ∈ T op - k then 9: P ← P ∪ { v } 10: end if 11: end for 12: return P 13: end function Algorithm 2 Stage II: Di verse Beam Decoding Require: Global pool P , subspaces R , groups G Ensure: Candidate set X 1: function D I V E R S E B E A M S E A R CH ( P , R ) 2: Detect candidate lengths L ← { L 1 , . . . } 3: X raw ← ∅ 4: for L ∈ L do 5: for t ← 1 T oL do 6: P t ← { v ∈ P | s sub ( v , t ) < τ pos } 7: end for 8: Initialize beam groups B 1 , . . . , B G 9: for t ← 1 T oL do 10: for g ∈ 1 . . . G do 11: Expand B g using P t 12: S ← score base t + λ div 1 ( x t ∈ S t ) + λ ng 1 ( g t ∈ G t ) 13: Prune to top- W /G 14: end for 15: end for 16: X raw ← X raw ∪ S B g 17: end for 18: C ← Cluster ( X raw ) 19: retur n X ← { Rep ( c ) | c ∈ C } 20: end function Category Hyperparameter V alue Stage I λ 1 0 . 8 λ 2 0 . 5 λ 3 0 . 5 τ ( h ) m 0 . 5 × head-wise median Stage II β LM 0 . 33 λ div 0 . 15 λ ng 0 . 2 Stage III λ 1 e − 3 ϵ 1 e − 4 · ∥ g mix ∥ 2 τ cluster 0 . 8 × Rouge-L Model / Exp. H model-specific P 512 T able 4: Batch-size-independent hyperparameters used in SOMP . Hyperparameter B =1 B =4 B =8 B =16+ T oken pool size k 960 1600 2400 3200 Informativ e heads | H act | H/ 4 H/ 4 H / 3 H/ 3 Sparsity heads | H top | H/ 6 H/ 6 H / 4 H / 4 Beam width W 2 4 6 12 Number of beam groups G 1 4 8 16 OMP iterations (max) B B B B T able 5: Batch-size-dependent hyperparameters as a function of aggregation le vel B . C.1 Hyperparameter Sensitivity Analysis W e analyze the sensitivity of SOMP to se veral ke y hyperparameters used in the three-stage reconstruc- tion pipeline. In particular , we examine the influ- ence of parameters controlling token pooling, beam search, and sparse reconstruction. Unless otherwise stated, experiments are con- ducted on the IMDB dataset using GPT -J with batch size B = 8 . For each experiment, we vary one hyperparameter while keeping all others fix ed according to the hyperparameter settings above. Reconstruction quality is measured using R OUGE- L. Overall, SOMP behaves as expected under hy- perparameter variation, b ut remains stable under moderate changes. Small to moderate de viations in parameter values do not lead to abrupt degradation in reconstruction performance, indicating that the method does not rely on fragile tuning. Discussion. The results show that SOMP is in- fluenced by hyperparameter choices, as larger to- ken pools or beam widths generally improve candi- date cov erage at the cost of increased computation. Ho we ver , performance v aries smoothly across a reasonable range of parameter values. In particu- lar , moderate changes in k , W , or λ do not cause catastrophic degradation in reconstruction quality . T able 6: Hyperparameter sensitivity analysis of SOMP . Each parameter is v aried while keeping the others fix ed. Parameter V alue ROUGE-L Stage I: T oken P ooling T oken pool size k 800 59.7 1200 71.5 1600 73.4 2000 74.5 2400 73.3 λ 1 0.6 74.7 0.8 67.3 1.0 53.4 λ 2 0.3 68.4 0.5 74.5 0.7 61.7 Stage II: Beam Decoding Beam width W 2 37.1 4 59.9 6 66.4 8 72.7 12 79.3 λ div 0.1 62.2 0.15 74.7 0.2 69.5 λ ng 0.1 64.8 0.2 74.8 0.3 71.5 Stage III: Sparse Reconstruction λ 5 × 10 − 4 69.8 1 × 10 − 3 74.2 5 × 10 − 3 71.6 1 × 10 − 2 73.7 ϵ 5 × 10 − 5 76.5 1 × 10 − 4 73.9 5 × 10 − 4 68.4 τ cluster 0.6 67.0 0.8 73.5 1.0 81.4 These observ ations suggest that SOMP does not de- pend on fragile hyperparameter tuning and remains robust under typical parameter v ariations. D Algorithmic Details This appendix provides pseudocode for the three stages of SOMP , complementing the high-lev el de- scriptions in Section 4 . Algorithm 1 details head- structured token pooling, Algorithm 2 presents geometry-dri ven di verse beam decoding, and Algo- rithm 3 describes gradient-space sparse reconstruc- tion via Orthogonal Matching Pursuit (OMP). The pseudocode is intended to improve clarity and reproducibility and does not introduce addi- tional assumptions beyond those already discussed in the main text. Algorithm 3 Stage III: OMP Reconstruction Require: g mix , candidates X , batch size B Ensure: Reconstructed batch S ∗ 1: function O M P ( g mix , X ) 2: Dictionary D ← {∇L ( x ) | x ∈ X } 3: r 0 ← g mix , Λ 0 ← ∅ 4: for k = 1 → B do 5: j ∗ ← arg max j |⟨ g j ,r k − 1 ⟩| ∥ g j ∥ 2 6: Λ k ← Λ k − 1 ∪ { j ∗ } 7: α ∗ ← arg min α g mix − P i ∈ Λ k α i g i 2 2 + λ ∥ α ∥ 2 2 8: r k ← g mix − P i ∈ Λ k α ∗ i g i 9: if ∥ r k ∥ < ϵ then 10: break 11: end if 12: end for 13: retur n S ∗ ← { x j | j ∈ Λ k } 14: end function E Full Main Results This appendix reports the full reconstruction results in T able 7 corresponding to the main e xperiments in Section 5 . W e include R OUGE-1 and ROUGE-2 across batch sizes B ∈ { 1 , 2 , 4 , 8 } for all compared methods under the same setup as the main text. E.1 Qualitative Reconstruction Example T o complement the quantitativ e results, we present a qualitati ve reconstruction example under aggre- gated gradients with batch size B = 2 , 4 , 8 . T a- bles 11 , 12 , and 13 compare the outputs generated by SOMP and se veral baselines on the same gra- dient batch. While prior methods such as LAMP , GRAB, and D A GER often produce mismatched or mixed sentences due to cross-sample token interfer- ence, SOMP is able to recov er the original inputs more accurately . F Multilingual Experiment This appendix provides additional multilingual re- construction results in T able 8 corresponding to Section 5.4 . W e report SOMP’ s performance across fi ve languages and analyze the effect of tokeniza- tion dif ferences on reconstruction quality . Across all fiv e ev aluated languages, SOMP remains ef fecti ve without language-specific tun- ing, indicating robustness to dif ferent tokenization schemes. Performance is strongest on English, German, and Chinese, while Italian and French sho w some what lar ger de gradation as batch size increases. This pattern is consistent with heavier subword fragmentation in languages that produce longer tok enized sequences and lar ger candidate branching during decoding. Dataset Method R-1 R-2 R-1 R-2 R-1 R-2 R-1 R-2 B = 1 B = 2 B = 4 B = 8 GPT -J LAMP 31.9 ± 2.4 16.5 ± 3.1 12.7 ± 3.7 7.6 ± 2.0 5.1 ± 0.7 1.4 ± 0.3 1.3 ± 0.4 0.3 ± 0.3 IMDB GRAB 46.1 ± 4.4 33.4 ± 1.4 38.1 ± 3.7 21.7 ± 0.9 33.1 ± 2.1 9.2 ± 1.3 19.7 ± 1.7 2.0 ± 0.6 D AGER 99.2 ± 0.8 94.3 ± 3.2 93.2 ± 3.4 72.0 ± 2.8 88.5 ± 3.1 58.4 ± 2.4 69.3 ± 1.3 39.2 ± 0.8 SOMP 99.5 ± 0.5 96.5 ± 2.1 98.3 ± 1.7 93.6 ± 3.8 94.4 ± 2.7 89.3 ± 1.9 88.4 ± 4.3 73.5 ± 5.1 LAMP 68.6 ± 4.5 42.6 ± 4.7 30.4 ± 3.1 17.8 ± 1.6 22.2 ± 2.9 10.4 ± 1.5 12.6 ± 2.4 6.3 ± 0.7 CoLA GRAB 84.7 ± 4.4 62.5 ± 2.7 76.7 ± 3.6 57.2 ± 3.8 61.8 ± 2.9 42.6 ± 2.4 53.5 ± 2.2 35.1 ± 2.1 D AGER 100.0 ± 0.0 100.0 ± 0.0 100.0 ± 0.0 100.0 ± 0.0 98.5 ± 1.5 92.9 ± 3.1 94.8 ± 2.3 87.8 ± 4.5 SOMP 100.0 ± 0.0 100.0 ± 0.0 100.0 ± 0.0 100.0 ± 0.0 100.0 ± 0.0 96.3 ± 3.7 98.7 ± 1.3 94.5 ± 3.3 LAMP 81.8 ± 3.0 57.8 ± 6.9 36.5 ± 3.2 23.6 ± 3.8 26.5 ± 2.5 12.9 ± 1.2 12.6 ± 2.4 7.2 ± 0.7 SST -2 GRAB 88.3 ± 4.4 66.3 ± 1.2 83.6 ± 3.7 56.5 ± 4.5 70.3 ± 4.2 43.3 ± 2.3 58.9 ± 1.7 36.4 ± 2.5 D AGER 100.0 ± 0.0 100.0 ± 0.0 99.3 ± 0.7 92.0 ± 1.8 99.6 ± 0.4 90.4 ± 3.3 95.1 ± 3.6 86.8 ± 2.9 SOMP 100.0 ± 0.0 100.0 ± 0.0 100.0 ± 0.0 99.8 ± 0.2 99.2 ± 0.8 97.6 ± 2.4 98.2 ± 1.8 95.9 ± 2.5 Dataset Method R-1 R-2 R-1 R-2 R-1 R-2 R-1 R-2 B = 1 B = 2 B = 4 B = 8 GPT -2 LAMP 23.2 ± 5.8 18.8 ± 8.4 11.4 ± 3.2 7.4 ± 1.6 6.8 ± 4.7 2.7 ± 2.4 0.1 ± 0.1 0.1 ± 0.1 IMDB GRAB 37.3 ± 1.8 29.1 ± 1.0 35.5 ± 3.2 21.1 ± 4.5 27.7 ± 4.8 12.8 ± 3.2 16.9 ± 5.8 7.7 ± 4.3 D AGER 99.5 ± 0.5 94.0 ± 4.6 87.2 ± 6.4 78.8 ± 4.7 86.4 ± 5.8 71.6 ± 4.1 68.2 ± 3.2 42.5 ± 2.4 SOMP 99.6 ± 0.4 94.4 ± 3.6 98.3 ± 1.7 94.6 ± 2.3 93.6 ± 3.9 86.3 ± 5.5 87.4 ± 3.4 68.5 ± 4.5 LAMP 73.3 ± 4.5 43.3 ± 7.0 28.6 ± 3.7 11.0 ± 3.8 13.4 ± 1.4 3.9 ± 1.2 8.9 ± 1.6 1.6 ± 0.8 CoLA GRAB 88.6 ± 1.6 65.7 ± 1.4 84.9 ± 1.2 56.8 ± 1.2 79.2 ± 0.7 52.8 ± 3.0 73.6 ± 1.7 45.6 ± 5.9 D AGER 100.0 ± 0.0 100.0 ± 0.0 100.0 ± 0.0 100.0 ± 0.0 100.0 ± 0.0 95.6 ± 1.8 99.6 ± 0.4 96.2 ± 2.1 SOMP 100.0 ± 0.0 100.0 ± 0.0 100.0 ± 0.0 98.2 ± 0.0 99.2 ± 0.8 94.0 ± 2.9 100.0 ± 0.0 97.5 ± 0.5 LAMP 62.2 ± 6.2 31.8 ± 8.4 21.4 ± 3.2 9.5 ± 3.6 9.8 ± 1.9 2.6 ± 1.4 8.1 ± 0.7 0.7 ± 0.4 SST -2 GRAB 91.2 ± 0.5 63.4 ± 0.0 82.6 ± 1.7 53.7 ± 0.4 69.8 ± 1.2 38.1 ± 0.6 62.7 ± 0.6 33.8 ± 0.1 D AGER 100.0 ± 0.0 96.0 ± 3.0 100.0 ± 0.0 89.5 ± 1.4 100.0 ± 0.0 92.8 ± 2.4 100 ± 0.0 92.9 ± 1.6 SOMP 100.0 ± 0.0 98.8 ± 0.8 100.0 ± 0.0 97.5 ± 0.9 100.0 ± 0.0 98.4 ± 0.4 99.3 ± 0.7 95.8 ± 1.5 T able 7: Full reconstruction results for the main e xperiments, reporting ROUGE-1 and R OUGE-2 across datasets and batch sizes for GPT -J and GPT -2. Language B=1 B=4 B=8 B=16 English 99.7 ± 0.3 94.3 ± 1.4 88.2 ± 1.7 83.5 ± 2.1 German 99.6 ± 0.4 94.6 ± 0.8 89.7 ± 2.1 82.3 ± 2.6 Chinese 99.8 ± 0.2 93.1 ± 1.2 88.1 ± 1.4 84.4 ± 3.4 Italian 99.7 ± 0.3 90.2 ± 1.5 83.3 ± 1.8 78.1 ± 1.8 French 95.7 ± 2.1 86.3 ± 3.3 80.5 ± 3.6 72.8 ± 3.7 T able 8: Multilingual reconstruction perfor- mance of SOMP on Qwen3 across batch sizes on stanfordNLP/imdb . G Reconstruction under F edA vg This appendix reports additional results under the FedA vg training protocol, complementing the sum- mary in Section 5.5 . W e e v aluate whether multiple local updates before aggreg ation mitigate gradient leakage. Experimental Setup. W e conduct experiments on GPT-2 using the Rotten T omatoes dataset. Un- less otherwise specified, we use E = 10 local epochs, learning rate η = 10 − 4 , and mini-batch size B mini = 4 . Reconstruction quality is measured using R OUGE-1 and R OUGE-2. E η B mini R-1 R-2 2 10 − 4 4 99.1 ± 0.9 98.2 ± 1.1 5 10 − 4 4 97.5 ± 1.3 95.8 ± 1.3 10 10 − 4 4 95.3 ± 1.8 93.9 ± 1.6 20 10 − 4 4 95.7 ± 0.9 94.4 ± 1.4 10 10 − 5 4 99.8 ± 0.2 99.1 ± 0.9 10 5 × 10 − 5 4 98.7 ± 0.9 97.9 ± 1.2 10 10 − 4 4 94.5 ± 1.4 93.6 ± 1.7 10 10 − 4 2 93.3 ± 1.9 91.4 ± 2.2 10 10 − 4 8 97.7 ± 1.3 96.1 ± 1.6 10 10 − 4 16 99.5 ± 0.5 98.6 ± 0.8 T able 9: Reconstruction performance of SOMP under FedA vg on GPT -2 (Rotten T omatoes). E denotes the number of local epochs, η the learning rate, and B mini the mini-batch size. Results. As sho wn in T able 9 , FedA vg does not eliminate gradient leakage across a range of rea- sonable training configurations. SOMP remains capable of recovering sensitive information e ven when multiple local epochs are performed before aggregation. Noise Level σ ROUGE-1 R OUGE-2 10 − 5 78.1 ± 3.3 72.8 ± 4.1 5 × 10 − 5 55.9 ± 4.2 34.5 ± 3.9 10 − 4 26.7 ± 4.0 16.6 ± 3.6 5 × 10 − 4 9.6 ± 3.5 1.9 ± 1.9 T able 10: Exploratory reconstruction performance of SOMP under additiv e Gaussian noise on GPT -2 (Rotten T omatoes, B = 1 ). Higher noise lev els correspond to stronger perturbation of the aggregated gradient. H Exploratory Results with Differential-Pri vacy-Inspired Noise This appendix provides an exploratory analysis of SOMP under differential pri vacy–inspired de- fenses. In particular , we in vestigate the effect of additi ve Gaussian noise applied to aggre gated gra- dients. These experiments are preliminary and do not provide formal dif ferential priv acy guarantees; they are intended only to assess the qualitativ e be- havior of gradient in version under noisy training signals. Experimental Setup. Follo wing prior work, we apply zero-mean Gaussian noise with v ariance σ 2 to the aggreg ated gradient g mix before reconstruc- tion. W e ev aluate SOMP on GPT-2 using the Rotten T omatoes dataset with batch size B = 1 . Recon- struction quality is measured using R OUGE-1 and R OUGE-2. Results and Discussion. As shown in T able 10 , reconstruction quality degrades rapidly as the noise magnitude increases. At sufficiently lar ge noise le vels, SOMP fails to recover meaningful inputs. A systematic e valuation under formal dif ferential pri v acy mechanisms, such as DP-SGD with per- sample clipping and priv acy accounting, remains an important direction for future work. Reference Inputs LAMP GRAB D A GER SOMP I received this movie as a gift, I knew from ... movies, don’ t watch this movie. I camcorder movie" D VD sucks filmmaker knew w ane bee ... movies,
Sgt this movie. town w atched it pro- duce movie, Ben Draper ... ries HORR OR revenge woman absolute. I received this mo vie as a gift, I knew from ... movies, don’t watch this movie. I received this mo vie as a gift, I knew from ... movies, don’t watch this movie. I very much looked for- ward to this movie. ... a good lov e story . I very Michael place W illie generally to they ... Chris capt.
’ s con- text ’ re romantic. Its Jr . ’ s editing to much is be T oo. better care ... love W illie and Missy;series. I very much looked for- ward to Michael ... a good lov e Michael. I very much looked for- ward to this movie. ... a good lov e story . Protocol is an implausi- ble movie whose only ... way to see this film. Protocol Lov e’ s implausi- ble Missy very much ... because see Plus. Jr . ’ s is But, implausible romantic always only ... always enjo y role film. Protocol is an implausible movie whose only ... way to see this movie. Protocol is an implausible movie whose only ... way to see this film. I was excited to vie w a Cataluña ´ s film in ... to go to see this film. I was excited Berlin ´ s a Cataluña ´ s film in ... , was horrible. competition . Cataluña, too horr to view a Cataluña ´ s see film ... to Molina this film. I was excited to view a Cataluña ´ s film in ... to go to see this film. I was excited to view a Cataluña ´ s film in ... to go ´ s to see Cataluña ´ s film. T able 11: Qualitativ e reconstruction examples under aggregated gradients with batch size B = 2 . Highlighted spans indicate incorrect tokens caused by cross-sample mixing. Reference Inputs LAMP GRAB D A GER SOMP A model named Laura is working in South America when ... jun- gle. It would probably be more fun.
3/10 A Laura named iv e fake Laura in Amer - ica America ... vision. far). Franco happening. probab be film fun.
3/10 primitiv es Hunter named Devil.
films working drags ity in (25 ...laugh. hilariously killed real fun more fun.
.
A model named Laura is working in hotel when Devil Hunter is film film her hotel ... It would probably be more fun.
3/10 A model named Laura is work in South America when ...jungle. It would probably be more fun.3/10 .3/10.3/10. Devil Hunter gained notoriety for the fact that ... no reason to bother with this one. Devil Hunter film no- toriety for the ’V ideo Nasty’ that’ s films the DPP ... with this one devil blood horror . DPP Hunter gained notori- ety for films kid- napped that title). the the ... She Kills in Ec- stasy Nasty list but it re- ally needn’t ha ve been Devil Hunter gained notoriety for the fact that ... basic V enus film films Devil this one. Devil Hunter gained notoriety for the fact that ... no reason to bother with this one one This film seemed way too long ev en ... proba- bly didn’t see an uncut version. This film version too uncut probably way ... scene blood camera long didn’t see . 75 zombie too long seemed ev en ... dub- bing didn’t rock y dubbing way clif f version. This film seemed way too long ev en ... film films’t zombie / flick film films... This film seemed way too long ev en ... proba- bly didn’t see an uncut version. I cannot stay indiffer - ent to Lars van Trier’ s films. I ... to the view- ers to decide this alone. I films alone T rier’ s viewers ... cannot decide horror camera devil Lars stay . Dancer cannot to consider different v an van Lars’ s masterpiece ... pre- ambiguous
decide this Europa Europa . I cannot stay indiffer - ent to Lars van Trier’ s films. I ... differ - ent filmmaker v an Lars van demonstrati ve this alone. ’ s.. I cannot stay different to Lars v an T rier’s films. I ... to the viewers to decide this alone ... Ah, Channel 5 of local Mexican t.v . Everyday , at 2:00 ... film-making.
Y ou have been warned. Ah, warned Mexican 2:00 Channel ... film- making blood devil street local been Every- day . Ah, Mexican Ah, Ah, Mexican t.v . Ah,... Ev- eryday at 2:00 been film-making. Y ou have warned. Ah, Channel 5 of local Mexican Ah, Mexican, at 2:00... film-film film.
later fil ms, cinematography warned. Ah, Channel 5 of local Mexican Ah, Every- day , at 2:00 ... film- making.Ah,Ah, Y ou hav e been warned. T able 12: Qualitativ e reconstruction examples under aggregated gradients with batch size B = 4 . Highlighted spans indicate incorrect tokens caused by cross-sample mixing. Reference Inputs LAMP GRAB D A GER SOMP Sloppily directed, wit- less comedy that sup- posedly ... be be g- ging for some peace and quiet. (*1/2) peace quiet comedy begging sloppily * ... hotel blood ’t camera witless scene . quiet comedy peace ... witless directed ’ s begging some film street . Sloppily directed, wit- less comedy that sup- posedly ... doomed James James 50s Royale Royale Ro yale Royale..*(*2(. Sloppily directed, witless comedy that comedy spoofs ... be be g- ging some Royale and Ro yale..(*1/2)... I was disgusted by this movie. No it wasn’t ... movie, b ut find out the true story of Artemisia. movie disgusted Artemisia true ... story Beav er devil blood find out . Artemisia movie disgusted ... Beav er Beav er find scene film . I was disgusted by this movie. No it wasn’t ...
movie, but mo vie movie the Artemisia Gentileschi. I was disgusted by this movie. No it it ’t ... movie, but find out the true Artemisia of Artemi- sia.... I didn’t think the French could make a bad mo vie, but ... pornography . So the French can fail, after all! French pornography bad movie ... after fail camera street horror French . pornography think French ... bad movie fail after film camera . I was disgusted by this movie. No it wasn’t ...
movie, but mo vie movie the Artemisia Gentileschi. I didn’t think the French could make a bad mo vie, but ... pornography . So the French can fail, after all! , after all!, after all!!!!! I read somewhere that when Kay Francis re- fused to ... and you’ll be doing yourself a fa- vor . fa vor somewhere yourself doing ... Kay Francis camera jungle blood . fa vor Francis somewhere ... doing yourself Kay film scene . I read somewhere that when Kay Francis refused to ... and Francis’ll movie
Also, a fa vor . And her hair!!! I read somewhere that when Kay Francis refused to ... and you’ll be yourself a fa vor f a- vor a a a a... A stale "misfits-in-the- army" saga, which ... Me", has only two or three brief scenes. What a waste! (*1/2) saga brief scenes ... waste army devil hotel camera three . brief films ... scenes to waste army film . A stale "misfits-in-the- army" saga, which ... Me", saga only two misfits misfits brief scenes. What a waste! (*1/2) A stale "misfits-in-the- army" saga, which ... Me", has only two three scenes. What a waste! (*1/2)! (*1/2)) When I was at the movie store the other day , I passed up ... and Blonder is a huge blonde BOMB- shell.
1/10 When I movie store ... Michelle Romy Anderson blood street scene day . Blonder store ... huge blonde stupid movie Michelle film . When I was at the movie store the other day , I passed up ... and Blonder is a huge BOMB.
1/10
1/10 When I was at the movie store the other day , I passed up ... and Blonder is a blonde Blonder .
1/10 ..... D T able 13: Qualitativ e reconstruction examples under aggregated gradients with batch size B = 8 . Highlighted spans indicate incorrect tokens caused by cross-sample mixing.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment