Finding Common Ground in a Sea of Alternatives
We study the problem of selecting a statement that finds common ground across diverse population preferences. Generative AI is uniquely suited for this task because it can access a practically infinite set of statements, but AI systems like the Haber…
Authors: Jay Chooi, Paul Gölz, Ariel D. Procaccia
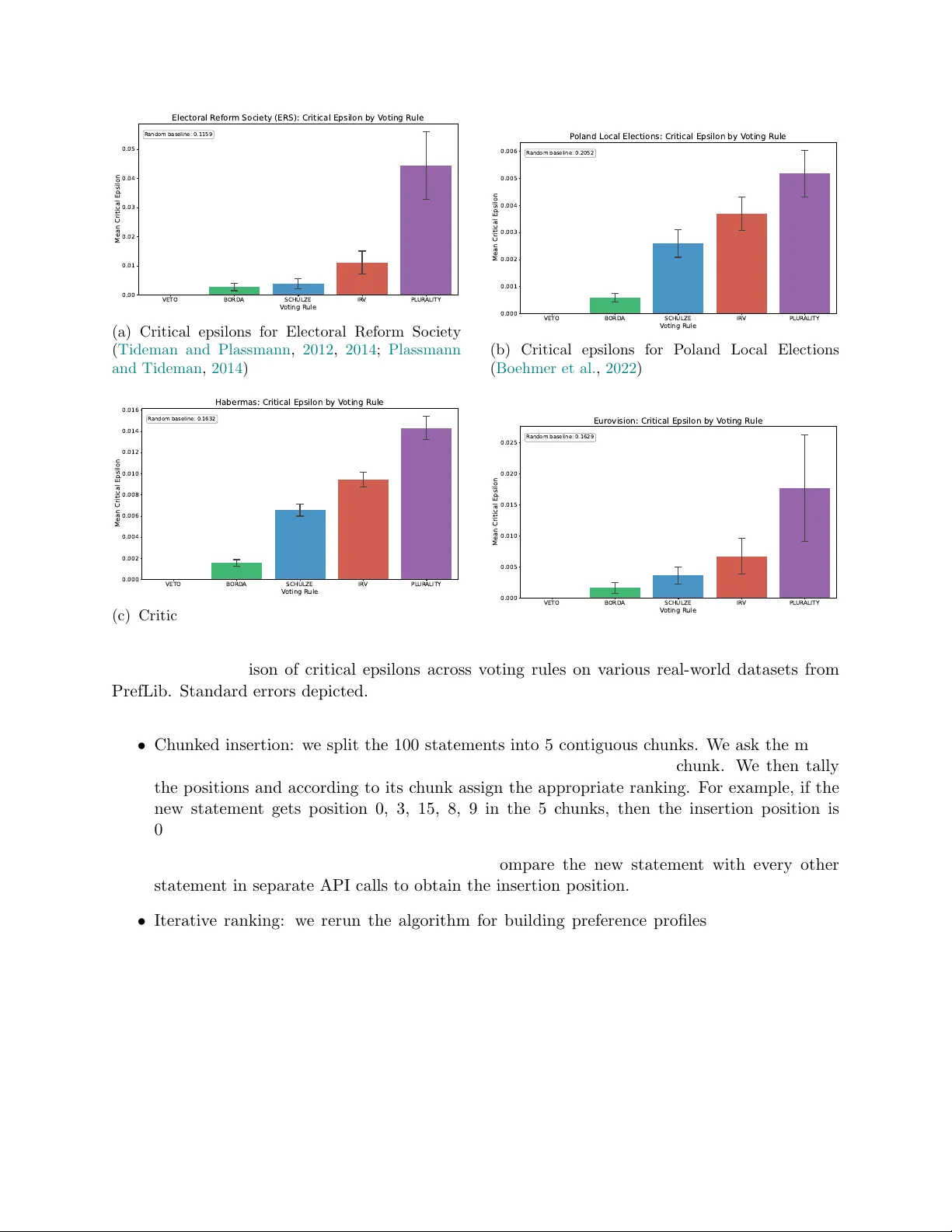
Finding Common Ground in a Sea of Alternativ es Ja y Cho oi 1 , P aul G¨ olz 2 , Ariel D. Pro caccia 1 , Benjamin Sc hiffer 3 , and Shirley Zhang 1 1 P aulson Sc ho ol of Engineering and Applied Sciences, Harv ard Universit y 2 Sc ho ol of Op erations Research and Information Engineering, Cornell Universit y 3 Departmen t of Statistics, Harv ard Universit y jeqin chooi@college.harvard.edu , paulgoelz@cornell.edu , arielpro@seas.harvard.edu , bschiffer1@g.harvard.edu , szhang2@g.harvard.edu Abstract W e study the problem of selecting a statemen t that finds common ground across diverse p opulation preferences. Generativ e AI is uniquely suited for this task b ecause it can access a practically infinite set of statemen ts, but AI systems lik e the Hab ermas machine ( T essler et al. , 2024 ) leav e the choice of generated statement to a v oting rule. What it means for this rule to find common ground, how ev er, is not w ell-defined. In this w ork, we propose a formal model for finding common ground in the infinite alternativ e setting based on the pr op ortional veto c or e from so cial c hoice. T o provide guaran tees relative to these infinitely man y alternatives and a large p opulation, w e wish to satisfy a notion of prop ortional v eto core using only query access to the unkno wn distribution of alternatives and v oters. W e design an efficien t sampling-based algorithm that returns an alternativ e in the (approx- imate) prop ortional veto core with high probabilit y and pro ve matching low er b ounds, which sho w that no algorithm can do the same using fewer queries. On a synthetic dataset of pref- erences ov er text, we confirm the effectiveness of our sampling-based algorithm and compare other social c hoice methods as w ell as LLM-based methods in terms of ho w reliably they produce statemen ts in the proportional veto core. 1 In tro duction In many countries, p olarization has reached unhealth y lev els ( Silv er , 2022 ), dividing p olitics in to “us” v ersus “them”. This division exacts a heavy toll: it reduces trust b etw een p eople, en tails p olitical gridlo c k and democratic erosion, and increases p olitical violence ( Lee , 2022 ; Piazza , 2023 ; McCo y et al. , 2018 ; Orhan , 2022 ). T o stem the tide of polarization, recent initiatives encourage peo- ple to discuss p olitics across divides and find points of agreemen t. The nonprofit Br aver Angels 1 , for example, brings groups of Demo crats and Republicans face to face, and citizens’ assemblies ( Dryzek et al. , 2019 ; OECD , 2020 ) con vene a represen tative sample of constituen ts to design common policy prop osals. Ma jor obstacles, ho w ever, stand in the wa y of scaling these efforts to a so ciety-wide level, including the cost of trained facilitators and cognitiv e limits that prev ent high-quality deliberation in large groups ( Fishkin , 2009 ). The recen t success of lar ge language mo dels (LLMs) in pro cessing natural language text shows promise in o vercoming these obstacles ( Landemore , 2024 ; McKinney and Chw alisz , 2025 ; Small et al. , 2023 ; Dem brane , 2023 ; Kon ya et al. , 2023 ). 1 https://braverangels.org/ 1 P erhaps the most prominent AI to ol with this goal is the Hab ermas machine , presented b y T essler et al. ( 2024 ) in Scienc e . T o help a group delib erate on a topic, the Hab ermas mac hine transforms opinion statements from the group members in to p ossible group statements, which are pieces of text represen ting the common ground of opinions. T essler et al. ( 2024 ) test the Hab ermas mac hine in the context of a citizens’ assembly and find that groups in teracting with the Hab ermas mac hine con verge in their b eliefs tow ards a common position, decreasing polarization. Besides LLM comp onen ts (for the generation of text and prediction of agreemen t), the Habermas mac hine also crucially relies on voting to select among generated proposals. V oting happ ens on tw o lev els: first, to generate alternativ e statements, 16 statements are sampled from a fine-tuned LLM, rank ed by a proxy mo del for eac h group mem b er, and only the winner according to the Sch ulze v oting rule ( Sc hulze , 2011 ) is kept; second, four alternative statements generated in this fashion are ranked by the actual group mem b ers, and the winning statemen t is again selected b y Sch ulze. F or finding common ground, Sch ulze may not b e the right to ol for selecting among statements b ecause this v oting rule is inheren tly ma joritarian: it readily o verrides the preferences of a minorit y to satisfy ev en a slight ma jorit y , as evidenced b y axioms such as Condorcet consistency and the m utual ma jorit y criterion. While T essler et al. ( 2024 ) find that minorit y opinions ha ve an influence on the winning statement, 2 this is an empirical finding and only holds on a verage across their exp erimen ts. T o robustly find common ground, we should aim for guarantees on the influence of minorities that hold for every p ossible group delib eration. What, then, can social c hoice offer as an axiom for finding common ground and as a voting rule to b e embedded inside the Hab ermas machine? W e argue that the pr op ortional veto c or e (PVC) of Moulin ( 1981 , 1982 ) is the right notion since it gives explicit outcome guaran tees to cohesive v oter coalitions of all sizes. Consider a coalition of, say , 30% of the participants and some alternative statemen t c . If the coalition can find a set with 100% − 30% = 70% of the alternatives that they all rank ab ov e c , the PV C guarantees that c will not be selected. In this w a y , minorit y groups are guaran teed an influence on the outcome, and they can av oid the statemen ts they disagree with the most, which is imp ortan t for a claim of common ground. T o pursue this guarantee, the Hab ermas mac hine could use a voting rule whose output alw ays lies in the PVC (like V ote by V eto ( Moulin , 1981 )), one could constrain any v oting rule to alternativ es in the PVC, or one could ev aluate voting rules (classical or LLM-based) in terms of how reliably their output lies in the PV C. One more challenge of using so cial choice in settings lik e the Hab ermas mac hine is that the space of alternativ es is tremendously large and often infinite. This leads to the natural question: Are the 16 statements sampled i.i.d. from the fine-tuned LLM enough to find common ground, and are the four statements resulting from indep endent runs of sampling and simulated v oting enough? Ho w can w e capture what “enough” is? In this pap er, w e define proportional v eto core guaran tees with respect to a very large set of statemen ts and design practical algorithms that satisfy them. Our pursuit of guarantees with resp ect to a large set of textual alternativ es is closely aligned with the gener ative so cial choic e framework b y Fish et al. ( 2026 ). Like them, we can only access this space of alternativ es indirectly through queries, whic h in our case means sampling from an unknown distribution ov er alternativ es. 2 Sp ecifically , T essler et al. ( 2024 ) embed the opinions by all group mem b ers using a text embedding model, and run a regression to predict the embedding of the winning statement as a mixture of these opinion statements. Group members are partitioned into a “ma jorit y” and “minority” group based on whether they answered “somewhat agree/agree/strongly agree” or “somewhat disagree/disagree/strongly disagree” in an initial question on the topic. T essler et al. ( 2024 ) find that minority agents tend to hav e non-negligible weigh t in this regression. 2 1.1 Our Contributions W e start by giving a formal mathematical mo del of what it means for a statemen t to find common ground when there are an infinite n umber of alternativ es. W e prop ose using the ϵ -pr op ortional veto c or e ( ϵ -PVC) , whic h extends the standard PVC to the setting with a distribution ov er alternatives. W e define the critic al ϵ of an alternativ e as the smallest ϵ for whic h that alternativ e is in the ϵ -PV C. Therefore, a smaller critical ϵ indicates that a statemen t b etter represen ts common ground. T o mo del information elicitation when there are infinite alternatives, we study a query-based information mo del with t wo types of queries. First, w e explore gener ative queries, which return alternativ es sampled from an unknown distribution of in terest ov er the alternative space, such as the output of an LLM with resp ect to a given prompt. Second, w e explore discriminative queries, whic h return user preferences ov er alternatives. W e fo cus on tw o t yp es of discriminative queries: min-queries that return a voter’s least fa vorite alternative among a given set and p airwise queries that return a v oter’s preference b etw een t wo giv en alternatives. Theoretical Results Our theoretical w ork fo cuses on pro viding upper and low er b ounds for how many queries are necessary to find an element in the ϵ -PVC. W e b egin by showing that the ϵ -PVC alwa ys has size at least ϵ . W e then present a query-based algorithm that with high probability finds an elemen t of the ϵ -PV C using ˜ O (1 /ϵ 2 ) generativ e queries and min-queries. W e prov e that no algorithm can alw ays find an elemen t of the ϵ -PV C using few er than Ω(1 /ϵ 2 ) generative queries and min-queries, whic h sho ws that our algorithm is w orst-case optimal for b oth types of queries. P airwise queries are perhaps the easiest information elicitation method from the v oters’ p ersp ec- tiv e. Therefore, we sho w that our algorithm can b e adapted to use pairwise queries while giving the same theoretical guarantees. The k ey mo dification is showing that with O ( nm ) pairwise queries, w e can find an elemen t of the PV C for finite sets of n voters and m alternatives. W e provide an efficien t metho d for doing this and further show that there is a matc hing lo wer b ound for this step; i.e., no algorithm can find an elemen t of the PV C with few er than Ω( nm ) pairwise queries for n v oters and m alternatives. Exp erimen tal Results W e conclude b y empirically ev aluating the critical ϵ achiev ed by different metho ds for selecting alternativ es on simulated preference data. W e obtain div erse preference data sets for a v ariet y of topics by using ChatGPT to generate b oth alternativ es and preference data for different p ersonas. T o mo del a query-based setting, the differen t voting rules are only given access to a small subset of voters and alternativ es and m ust select an alternativ e from this subset. Our first empirical result confirms that the sampling-based approach from the theory section finds alternativ es in the ϵ -PVC for small ϵ . W e then sho w that different so cial c hoice metho ds such as Sc hulze and pluralit y can select alternatives with large critical ϵ , indicating that these methods ma y not necessarily choose a goo d common-ground statemen t. Finally , we conclude our exp eriments by studying generative v oting rules that use LLMs to generate common-ground statemen ts. W e show that these generative voting rules do generate statements with small critical ϵ , whic h indicates that the notion of PVC aligns w ell with ho w an LLM tries to find common ground. W e also show that when the LLM is not prop erly tuned to the p opulation, the generative voting rules give statements with significantly higher critical ϵ compared to our algorithm. 3 1.2 Related W ork Man y recen t w orks ha ve studied ho w to use AI for finding consensus on a large scale ( Kahng et al. , 2019 ; Gudi ˜ no et al. , 2024 ; Landemore , 2024 ; Kony a et al. , 2023 ; T essler et al. , 2024 ; Bakker et al. , 2022 ; Blair and Larson , 2026 ). The most similar of these metho ds is the Habermas mac hine ( T essler et al. , 2024 ), whic h we already discussed at length. At the end of Section 2 , we further discuss the clone-pro ofness axiom satisfied by the Sc hulze rule, and why our approach to common ground do es not require it. Finding common-ground statements is an imp ortant goal of online delib eration platforms like Polis ( Small et al. , 2021 ) and R emesh 3 , on which users submit statemen ts and rate their agreemen t with the statements written b y others. Both platforms ( Computational Demo cracy Pro ject , 2025 ; Kon ya et al. , 2023 ) presen t user-submitted statements based on a “bridging-based ranking” ( Ov ady a and Thorburn , 2023 ), whic h measures if a statement has high approv al rates in all clusters of users. Our approac h is m uch more general b ecause we give guarantees to all subsets of voters rather than only some presp ecified groups. The idea of finding common-ground and bridging has also b een p opular in the con text of annotating so cial media p osts ( De et al. , 2025 ; W o jcik et al. , 2022 ). F or example, W o jcik et al. ( 2022 ) study a bridging-based algorithm for finding common-ground and selecting notes to app end to tw eets. F urthermore, Slaugh ter et al. ( 2025 ) sho w that this approac h to finding common ground successfully reduces engagemen t with and proliferation of misinformation on social media platforms. While these metho ds for finding common ground ha v e had practical success, they lac k formal theoretical guarantees. The PVC w as first studied b y Moulin ( 1981 , 1982 ) in the traditional so cial c hoice setting of p erfect information ab out a finite num b er of voters and alternatives. In the same setting, Iano vski and Kondratev ( 2023 ) giv e a p olynomial time algorithm for computing the PV C and a neutral and anon ymous algorithm for finding an element from the PV C. Ideas from these algorithms inspire some of our algorithmic pro cedures, as discussed in later sections. More recen tly , the PVC has b een studied in a v ariet y of contexts including approv al ballots ( Halp ern et al. , 2025 ), federated learning ( Chaudhury et al. , 2024 ), and p olicy aggregation ( Alamdari et al. , 2024 ). The settings studied b y Chaudhury et al. ( 2024 ) and ( Alamdari et al. , 2024 ) b oth can hav e an infinite n umber of alternatives, which lead these works to notions similar to the ϵ -PVC. Lik e us, the work on gener ative so cial choic e ( Fish et al. , 2026 ; Bo ehmer et al. , 2025 ) uses generativ e mo dels for so cial c hoice ov er an infinite space of textual alternatives. Similar to our setting, they study generative queries that generate alternativ es and discriminative queries that access voter preferences. A ma jor difference, how ev er, is that their goal is to find a set of sever al represen tative statements, whic h enables them to give guarantees to minority groups without finding common ground within eac h statemen t. A second ma jor difference is that their space of alternativ es lac ks our structure of a probability distribution. As a result, their generative queries (finding a statemen t maximizing a function of voter preferences) are muc h more complex and muc h harder to implement than our query of sampling from a fixed distribution. Bey ond the generative so cial choice mo del, there has also b een significan t work on applying so cial choice techniques to settings with man y or infinite alternatives and limited information in the setting of AI alignment ( Ge et al. , 2024 ; Pro caccia et al. , 2025b ; G¨ olz et al. , 2025 ; Conitzer et al. , 2024 ) and AI ev aluation ( Pro caccia et al. , 2025a ; Zhang and Hardt , 2024 ). Due to the size of the alternative space in these settings, these w orks also fo cus on choosing subsets of alternativ es and voters to giv e approximate or probabilistic generalization guaran tees. 3 https://www.remesh.ai/ 4 2 Mo del Let M b e a (p ossibly infinite) set of alternativ es and let N b e a finite (but potentially very large) set of voters. Each v oter i ∈ N has a ranking o ver all alternativ es in M . F or alternatives a, b ∈ M and v oter i ∈ N , we use a ≻ i b to mean that v oter i prefers alternativ e a to alternativ e b . Imp ortan tly , w e do not assume p erfect information ab out the preferences of the voters. Instead, w e assume that we can access information about the alternatives and v oters using tw o t yp es of queries: generative queries and discriminative queries . Generative queries allo w us to access the set of alternativ es M . Sp ecifically , let D b e a fixed distribution ov er M . F or a set of alternativ es M ⊆ M , define µ D ( M ) as the measure of the set M for distribution D . A generative query returns a random sample from the distribution D . Note that no information ab out the distribution D or the rankings of the voters is kno wn a priori. Discriminativ e queries allow us to gather information ab out voter preferences. W e study tw o t yp es of discriminativ e queries. The first t yp e of discriminativ e query we study is a min-query , whic h takes as input a voter i ∈ N and a set of alternatives X ⊆ M and returns voter i ’s least fa vorite alternative in X . The second type of discriminativ e query we study is a p airwise query , whic h takes as input a v oter i ∈ N and tw o alternativ es a, b ∈ M , and returns which alternativ e in { a, b } is ranked higher b y voter i . Our main goal is to use a combination of generative and discriminativ e queries to efficiently find an alternativ e in M that finds common ground for the en tire p opulation N . W e argue that the ϵ -Prop ortional V eto Core ( ϵ -PVC) is a mathematically principled wa y of finding common ground. Informally , an alternative a is blo c ked by a coalition of voters if all v oters in the coalition prefer a sufficiently large set of alternatives to a . The ϵ -PVC is simply the set of alternativ es that is not blo ck ed b y an y coalition of v oters. By ruling out alternatives for whic h some sizable minority ranks a large blo ck of options higher, the ϵ -PVC excludes p olarizing alternatives. Definition 2.1. An alternative a ∈ M is ϵ - blo ck ed b y a coalition T ⊆ N of v oters if there exists a blo cking set of alternatives S ⊆ M suc h that • Eac h voter i ∈ T prefers eac h alternativ e b ∈ S to a (i.e. b ≻ i a ), and • µ D ( S ) > 1 − | T | n + ϵ. The ϵ -Prop ortional V eto Core ( ϵ -PV C) is the set of all alternativ es that are not ϵ -blo ck ed by an y coalition of voters. When N and M are finite, the Prop ortional V eto Core (PVC) ( Moulin , 1981 ) refers to the sp ecial case when ϵ = 0 and D is the uniform distribution o ver all alternatives in M . See App endix A for more details. A higher ϵ > 0 makes it harder for coalitions to blo c k alternatives and therefore mak es the ϵ -PV C a less demanding notion. Hence, the ϵ -PVC naturally leads to a metric for how well an alternativ e a ∈ M do es at finding common ground for the voters N . Intuitiv ely , the critical ϵ for an alternativ e is the smallest fraction of v oters that must b e ignored in eac h coalition so that no coalition will veto that alternativ e. Therefore, a critical ϵ closer to 0 implies that an alternative is b etter for finding common ground while a larger critical ϵ implies that an alternative is worse at it. Definition 2.2. F or an y alternative a ∈ M , the critical ϵ for a is the smallest ϵ ≥ 0 such that a is in the ϵ -PV C. 5 Role of the Statement Distribution D plays a crucial role in our notion of common ground since it determines how many alternativ es a coalition T m ust agree on to blo c k an alternativ e a . F or example, let D b e defined by an LLM, whic h pro duces a neutral summary with 99% probability , but sometimes insults a minority instead. The ϵ -PV C allo ws the small minority to blo c k the insulting statements, whose small measure in the distribution reflects its fringe nature. This marks a ma jor difference in p ersp ective to T essler et al. ( 2024 ), who use the Sch ulze voting rule due to its clone-pro ofness. If the Hab ermas machine samples 99 neutral statemen ts and one insulting statemen t from the LLM and voters see the neutral statemen ts as interc hangeable, clone-pro ofness actually ensures that a slight ma jorit y preference for the insulting statemen t makes it the winner. In addition, clone-proofness is a brittle axiom that only applies to exact clones, so similar but not iden tically ranked alternatives can still hav e a large effect on the outcome. 4 As illustrated in the ab o ve example, having a distribution ov er alternativ es enables us to guar- an tee rights to coalitions b y forming a y ardstick for how m uch influence each of them deserv es. This do es mean, of course, that the distribution must be carefully c hosen to b e broadly acceptable to the voters. In many cases, the statemen t distribution generated by an LLM migh t b e a suffi- cien tly neutral ground — sa y , from a base mo del, which seem to b e more p olitically mo derate than p ost-trained mo dels ( Rozado , 2024 ), or a mo del sp ecifically fine-tuned for this purp ose. Another option could b e to define D in terms of the distribution of voters as w e do in our exp erimen ts: w e dra w characteristics of a random voter and ask the LLM to answ er from their p ersp ective. W e con tinue our discussion on the c hoice of distribution D in Section 6 . 3 Basic Prop erties T o b egin our in v estigation of the ϵ -PVC, w e start by b ounding its size and dev eloping a polynomial- time algorithm that can compute the critical ϵ and the ϵ -PVC if D is the uniform distribution ov er a given set of alternativ es. 3.1 Size of ϵ -PV C As a w arm-up, w e study the size of the ϵ -PV C, which will tell us ho w many generative queries are necessary to even see an elemen t of the ϵ -PV C. W e b egin by showing that, for an y ϵ > 0, the ϵ -PV C is not only non-empty but alwa ys has a size (with resp ect to the measure µ D ) of at least ϵ . Previous pap ers that hav e lo ok ed at v arian ts of the ϵ -PVC ( Alamdari et al. , 2024 ; Chaudhury et al. , 2024 ) giv e similar pro ofs of existence, but do not explicitly study the size of the ϵ -PVC. Prop osition 3.1. F or any instanc e of the pr oblem and any ϵ , the size of the ϵ -PVC (with r esp e ct to the me asur e µ D ) is at le ast ϵ . Pr o of sketch. The key idea of this pro of relies on an algorithm w e call vote by γ -v eto (Algorithm 3 in App endix B.1 ), whic h is guaranteed to return a set of alternatives C with mass at least ϵ such that all alternativ es in C are also in the ϵ -PV C. In this algorithm, the voters are ordered randomly , and then in this order each voter v eto es their least fav orite 1 − ϵ n mass of alternatives that has not 4 While the winner of Sc hulze on samples from D is indep endent of the m ultiplicities of identical samples, we wan t to caution that the precondition of clone-pro ofness, requiring alternatives to b e treated the same b y every voter, mak es it a brittle axiom. F or example, Pierczynski and Szufa ( 2024 ) give an election where Sch ulze do es not satisfy clone-pro ofness for alternativ es that are almost clones. In this wa y , multiplicities can still ha ve unpredictable effects under Sch ulze. 6 y et b een v eto ed. Clearly , once all n v oters ha ve vetoed 1 − ϵ n mass, the remaining alternativ es must ha ve mass at least ϵ . The pro of that the remaining alternatives are in the ϵ -PVC follows similarly to the pro of for the V ote by V eto rule of Moulin ( 1982 ). In tuitiv ely , any alternativ e a not in the ϵ -PV C must get remov ed b efore the algorithm ends, as the last voter to v eto from the blo cking set for this alternative a is guaranteed to v eto a if a has not y et b een vetoed. F or the full pro of, see App endix B.1 . A direct corollary of Theorem 3.1 is that, among sufficiently man y generativ e queries, there will with high probability b e an alternative in the ϵ -PVC: Corollary 3.2. F or any ϵ, δ > 0 , a set of m = log(1 /δ ) ϵ gener ative queries wil l with pr ob ability 1 − δ c ontain an element of the ϵ -PVC. Pr o of. Let M b e the result of m = log(1 /δ ) ϵ generativ e queries and let C ϵ b e the ϵ -PVC. Then Pr( M ∩ C ϵ = ∅ ) = (1 − µ D ( C ϵ )) m ≤ (1 − ϵ ) m ≤ e − ϵm = δ, where the first inequalit y is by Prop osition 3.1 . Therefore, the probability that at least one elemen t of M is in C ϵ is at least 1 − δ . While O (1 /ϵ ) generativ e queries con tain at least one elemen t of the ϵ -PV C with high probability , w e show in Section 5 that a larger n umber, sp ecifically Ω(1 /ϵ 2 ), of generativ e queries is needed to identify an elemen t of the ϵ -PVC. Therefore, identifying an element of the ϵ -PVC with generative queries is statistically harder than simply generating an elemen t of the ϵ -PVC. In contrast to the traditional PVC, the 0-PV C can, in general, be empty: Prop osition 3.3. F or an infinite numb er of alternatives, the 0 -PVC c an b e empty. Pr o of. Let M : = N ≥ 1 , and let each alternativ e i ≥ 1 ha ve mass 1 2 i . Supp ose that all v oters prefer alternativ es with larger n umbers. W e pro ve, b y con tradiction, that no alternative i is in the 0-PV C. Indeed, any such i is blo ck ed b y the grand coalition T = N and the alternative set S = { i + 1 } , since all voters prefer i + 1 o ver i and since µ D ( S ) = 1 2 i +1 > 0 = 1 − | T | n . 3.2 Computing Critical ϵ As mentioned in the previous section, the critical ϵ of an alternative measures ho w w ell a given alternativ e do es at finding common ground. In this section, w e give an algorithm for finding the critical ϵ of a given alternativ e in p olynomial time when the num b er of alternatives is finite and D is the uniform distribution ov er M . Our algorithm generalizes the algorithm of Ianovski and Kondratev ( 2023 ) for deciding if an alternativ e is in the traditional PVC. By running this algorithm for all alternatives, w e can construct the en tire ϵ -PV C in p olynomial time in the same setting. ALGORITHM 1: Computing the critical ϵ Input: Alternative a , |N | = n , |M| = m 1 Construct a flo w graph G as follows: 2 Connect a source no de to n voter no des, eac h edge with w eight m 3 Connect m − 1 no des (for all alternatives except a ) to a sink no de, eac h with edge w eight n 4 Connect v oter no de i to alternative no de j with infinite weigh t if v oter i prefers a to alternative j 5 Let K b e the size of the min-cut for graph G 6 return 2 nm − n − K nm − 1 7 Theorem 3.4. When M is finite, Algorithm 1 c omputes the critic al ϵ of a given alternative in p olynomial time. Pr o of Sketch. Our pro of generalizes the ideas of Ianovski and Kondratev ( 2023 ) for computing the PV C. Their algorithm chec ks whether an alternativ e a is in the PV C b y constructing a graph G a suc h that there exists a complete biclique in G a if and only if a is not in the PVC. W e show that for the same graph G a , the size of the maximum biclique is larger than (1 + ϵ ) nm if and only if that alternativ e is not in the ϵ -PVC. In order to efficiently compute the size of the maximum biclique, w e follo w the same metho d as Ianovski and Kondratev ( 2023 ) of constructing the flo w graph in Algorithm 1 such that the weigh t of the max flow K in this graph plus the size of the maximum biclique in G a equals 2 nm − n . In the last line of Algorithm 1 , w e use this fact to find the smallest ϵ for which the maximum biclique of G a is larger than (1 + ϵ ) nm . The runtime of the algorithm is p olynomial b ecause the min-cut can b e found in p olynomial time (App endix C.2.2 ). F or the detailed pro of, see Appendix C . 4 Algorithmic Results In this section, we present our main algorithmic results for efficiently finding an element of the ϵ - PV C. W e giv e a simple algorithm using generativ e queries and min-queries that finds an alternativ e in the ϵ -PVC, with high probabilit y , using ˜ O (1 /ϵ 2 ) queries of each t yp e. A k ey takea w ay from this result is that the num b er of generative and discriminative queries do es not dep end on the size of N (the n umber of voters) or the distribution o ver alternatives. This is imp ortant b ecause the p opulation may b e large and the generative distribution altogether unknown to the algorithm. Then, w e discuss how the same algorithm can b e mo dified to use pairwise discriminativ e queries instead of min-queries. 4.1 Min-Queries W e no w presen t and analyze Algorithm 2 , whic h finds an element of the ϵ -PVC using generativ e queries and min-queries. ALGORITHM 2: Finding an element of the ϵ -PV C 1 Input: N , M , δ, ϵ 2 Output: An alternative that is with probability 1 − δ an element of the ϵ -PVC 3 Set τ = 8 ϵ 2 log 32 ϵ 2 δ log 32 ϵ 2 δ . 4 Let M b e a set of alternatives that is the result of τ generative queries. 5 Initialize X = M . 6 while | X | > 1 do 7 Select a random voter i ∈ N . 8 Do one min-query to find v oter i ’s least fav orite alternative among X . 9 Remo ve that alternative from X . 10 end 11 return the r emaining element in X Theorem 4.1. Using O ϵ − 2 log 1 ϵδ gener ative and min-queries, Algorithm 2 r eturns an element of the ϵ -PV C with pr ob ability at le ast 1 − δ . 8 Pr o of. By construction, Algorithm 2 uses τ generative queries and τ − 1 min-queries, which giv es the desired b ound on the n umber of queries, observing that, for small enough ϵ, δ , τ = 8 ϵ 2 log 32 ϵ 2 δ log 32 ϵ 2 δ ≤ 8 ϵ 2 log 32 2 ϵ 4 δ 2 ≤ 8 ϵ 2 log 32 4 ϵ 4 δ 4 = 32 ϵ 2 log 32 ϵ δ = O ϵ − 2 log 1 ϵ δ . Let N b e the set of v oters that are selected in Lines 6 – 9 of Algorithm 2 . Note that a voter i ∈ N could be chosen in t wo differen t iterations of the while lo op, in which case w e view these as distinct copies of the voter in the set N . This means we m ust hav e that | N | = τ − 1. W e first show that any alternative in the PVC for voters N and alternatives M will, with probabilit y 1 − δ , b e in the ϵ -PV C for N , D . W e defer the pro of of this result to Lemma 4.2 b elo w. With this result, all w e need to show is that the alternative we return is in the PVC for N and M . In Lines 6 – 9 , w e are functionally applying the V ote by V eto rule from ( Moulin , 1982 ) to find an elemen t of the PVC for N and M using one min-query for each v oter in N . Let a b e the alternative returned by Algorithm 2 , and assume for con tradiction that a is not in the PV C for N and M , i.e., not in the 0-PVC for the uniform distribution ov er M . Hence, there exists a coalition of voters T and a set of alternatives S such that b ≻ i a for each i ∈ T and b ∈ S and such that | S | τ = | S | | M | > 1 − | T | | N | (1) Eac h v oter i ∈ N remov ed one alternative b i ∈ M from the set X . Since a was av ailable in X at the time and the voter chose to remov e b i , it must hold that a ≻ i b i . This means that the set W : = { b i | i ∈ T } of alternatives remov ed b y the voters in T is disjoin t from S . Moreov er, a is clearly not part of either set (b ecause it was not remov ed and cannot b e strictly preferred o ver itself ). This means that S ⊆ M \ W \ { a } and hence | S | ≤ τ − | T | − 1. It follows that | S | τ ≤ τ − | T | − 1 τ = 1 − | T | + 1 | N | + 1 ≤ 1 − | T | | N | , where the last inequality follo ws since | T | ≤ | N | . This contradicts Eq. ( 1 ), sho wing that a is indeed in the PV C for N and M . T ogether with the lemma, w e conclude that the returned statement is in the ϵ -PVC with probability at least 1 − δ . The key to concluding the pro of of the theorem is Theorem 4.2 , a quite technical result that connects the ϵ -PVC of the full instance with the PV C for the sampled voters and alternatives. At a high level, the pro of must argue that the randomly selected set of voters and alternativ es are sufficien tly represen tative of the p opulation and alternative distribution. But it is not immedi- ately obvious ho w to do so, given the exp onen tial n umber of coalitions, and infinite collection of alternativ e sets that could sho w that an alternative is ϵ -block ed. Instead, we apply concentration inequalities in a more subtle manner so that the n umber of generativ e queries needed dep ends only on ϵ and is indep endent of |N | (see Line 3 of Algorithm 2 ). Sp ecifically , we show that we do not need enough samples to sufficien tly appro ximate ev ery subset of v oters and alternativ es, but rather only need enough samples to sufficien tly approximate the voters and alternativ es for the blo cking coalitions of the generated alternativ es. Lemma 4.2. L et N b e the set of (not ne c essarily distinct voters) sele cte d in Lines 6 – 9 of A lgorithm 2 . F or any δ, ϵ > 0 , every element of the PV C for N and M fr om A lgorithm 2 wil l b e in the ϵ -PVC for N and D . 9 Pr o of. The key observ ation is that every alternative x ∈ M not in the ϵ -PVC for M , N , D must ha ve some blo c king coalition of voters T x ⊆ N and alternatives S x ⊆ M satisfying Definition 2.1 . Denote the i th alternative sampled on Line 4 as x i . If x i is not in the ϵ -PV C for M , N , D , then w e will show that with high probability , the corresp onding blo cking sets T x i and S x i are sufficiently accurately prop ortionally represented in the sampled sets M and N up to a factor of ϵ . If this is the case, then Definition 2.1 implies that x i will also not b e in the PVC for M and N . F or each x i , define the even t E i as the ev ent that the ab ov e holds if x i is not in the ϵ -PV C. If we show that E i holds with high probabilit y for every alternative x i ∈ M , then we can conclude that ev ery alternativ e in a ∈ M falls in one of t wo cases: Either a is in the ϵ -PVC for M , N , D or a is not in the PVC for N and M . This implies the desired result that any element of the PV C for N and M is in the ϵ -PVC for N , D . W e now pro ceed with the formal pro of: Let X b e a set of alternatives sampled as generative queries from D with size | X | = 8 log 32 ϵ 2 δ log 32 ϵ 2 δ ϵ 2 and let Y ⊆ N b e a random subset of N with size | Y | = 8 log 32 ϵ 2 δ log 32 ϵ 2 δ ϵ 2 . W e will show that with probabilit y 1 − δ , any alternative that is not in the ϵ -PV C for the full set of alternatives will not b e in the PVC for alternativ es X and v oters Y . This implies that any elemen t of the PV C for alter- nativ es X and v oters Y will with probabilit y 1 − δ b e in the ϵ -PV C for N , D . Define PV C ( X , Y ) as the PV C for alternatives X and voters Y . Define PV C ϵ ( N , D ) as the ϵ -PV C for N , D . F or an y elemen t x ∈ M suc h that x / ∈ PVC ϵ ( N , D ), there exists some T x ⊆ N and S x ⊆ M suc h that for all i ∈ T x and a ∈ S x , a ≻ i x and µ D ( S x ) + | T x | |N | > 1 + ϵ . Let X = { x 1 , ..., x | X | } b e the ordered set of generative queries. Now we define the even t E i := n x i ∈ PV C ϵ ( N , D ) o S n x i ∈ PV C ϵ ( N , D ) and | X ∩ S x i | | X | ≥ µ D ( S x i ) − ϵ/ 4 and | Y ∩ T x i | | Y | ≥ | T x i | |N | − ϵ/ 4 o First, note that if T | X | i =1 E i holds, then ev ery elemen t of X is either in PVC ϵ ( N , D ) or is not in PV C ( X , Y ). This implies that every element not in PVC ϵ ( N , D ) is not in PVC ( X , Y ). All that remains is to sho w that Pr T | X | i =1 E i ≥ 1 − δ . First, we will start with low er b ounding Pr( E i ) (which by symmetry is the same for all i ). W e ha ve: Pr( E i ) = Pr ( x i ∈ PV C ϵ ( N , D )) + Pr | X ∩ S x i | | X | ≥ µ D ( S x i ) − ϵ 4 and | Y ∩ T x i | | Y | ≥ | T x i | |N | − ϵ 4 x i / ∈ PVC ϵ ( N , D ) Pr( x i / ∈ PVC ϵ ( N , D )) . F o cusing on the middle probabilit y and using Ho effding’s inequalit y , w e ha ve that Pr | X ∩ S x i | | X | ≥ µ D ( S x i ) − ϵ 4 and | Y ∩ T x i | | Y | ≥ | T x i | |N | − ϵ 4 x i / ∈ PVC ϵ ( N , D ) ≥ 1 − Pr | X ∩ S x i | | X | < µ D ( S x i ) − ϵ 4 x i / ∈ PVC ϵ ( N , D ) − Pr | Y ∩ T x i | | Y | < | T x i | |N | − ϵ 4 x i / ∈ PVC ϵ ( N , D ) ≥ 1 − e − 2 | X | ϵ 2 / 16 − e − 2 | Y | ϵ 2 / 16 [Ho effding’s Ineq.] = 1 − 2 e − 2 | X | ϵ 2 / 16 [ | X | = | Y | ] = 1 − 2 e − 2 8 log ( 32 ϵ 2 δ log ( 32 ϵ 2 δ )) ϵ 2 ϵ 2 / 16 = 1 − δ 16 log 32 ϵ 2 δ ϵ 2 10 ≥ 1 − δ 8 log 32 ϵ 2 δ log 32 ϵ 2 δ ϵ 2 = 1 − δ | X | . Returning to b ounding Pr( E i ), we hav e that Pr( E i ) ≥ Pr ( x i ∈ PV C ϵ ( N , D )) + 1 − δ | X | Pr( x i / ∈ PVC ϵ ( N , D )) ≥ 1 − δ | X | . Finally , we can conclude that Pr T | X | i =1 E i ≥ 1 − P | X | i =1 Pr ( ¬ E i ) ≥ 1 − δ as desired. 4.2 P airwise Discriminativ e Queries While Algorithm 2 uses min-queries, it would be muc h more practically useful to hav e an algorithm based on pairwise discriminativ e queries, whic h are easier for v oters to resp ond to. F ortunately , w e can achiev e this with one simple change to Algorithm 2 . Sp ecifically , w e can simulate eac h min-query in Line 8 with a simple iterative algorithm to find the least-preferred alternativ e for a giv en voter in a linear n umber of pairwise comparisons: First, c ho ose an arbitrary ordering of the candidates in X and do a single pairwise query asking voter i to compare the first t wo alternativ es in the ordering. Then, ask v oter i to compare the least-preferred alternativ e from that first comparison to the next alternative in the ordering. Rep eat this process, alw ays k eeping the least-preferred alternative from each comparison. After iterating through all alternativ es in X , this is guaranteed to only use | X | − 1 pairwise queries to find voter i ’s least fa vorite alternative among X . 5 Lo w er Bounds In this section, we show that Algorithm 2 is tight in terms of b oth generativ e and discriminative queries. T o prov e this for eac h of generative and min-queries, we giv e a sp ecific hard instance of the problem that requires ˜ Ω(1 /ϵ 2 ) of that type of query in order to find an element of the ϵ -PV C. W e then sho w that the num b er of pairwise queries in the mo dification of Section 4.2 is also tight. 5.1 Generativ e and Min-Queries In Theorem 5.1 , we give a lo wer b ound on the n umber of generative queries needed in order to iden tify an elemen t of the ϵ -PVC. Imp ortantly , this result combined with Corollary 3.2 implies a fundamen tal gap b et ween the num b er of queries needed to generate v ersus identify an element of the ϵ -PV C. Sp ecifically , Corollary 3.2 says that ˜ O (1 /ϵ ) generativ e queries suffice to gener ate an elemen t of the ϵ -PVC with high probability , while Lemma 5.1 says that w e need at least ˜ Ω(1 /ϵ 2 ) generativ e queries to identify an element of ϵ -PV C. This highligh ts a surprising subtlety ab out generativ e queries, which is that it can b e easier to stumble across a statemen t in the ϵ -PVC than to certify which statemen t is in the ϵ -PV C. Theorem 5.1. F or any δ, ϵ > 0 , no algorithm c an use fewer than Ω(log(1 /δ ) /ϵ 2 ) gener ative queries and for every distribution D identify an element of the ϵ -PV C with pr ob ability gr e ater than 1 − δ . 11 Pr o of. Consider the following tw o discrete distributions with supp ort { a 1 , a 2 } . Distribution D 1 puts 0 . 5 + ϵ probabilit y mass on a 1 and 0 . 5 − ϵ probabilit y mass on a 2 . Distribution D 2 puts 0 . 5 − ϵ probabilit y mass on a 1 and 0 . 5 + ϵ probability mass on a 2 . Supp ose that half of the voters in N hav e preferences a 1 ≻ a 2 and the other half of the voters ha ve preference a 2 ≻ a 1 . With this v oter p opulation, the ϵ -PV C under distribution D 1 is { a 1 } while the ϵ -PVC under distribution D 2 is { a 2 } . Therefore, in order to find the ϵ -PV C, w e m ust ha ve sufficien t information to distinguish b et ween distributions D 1 and D 2 . Next, note that the KL distance b etw een these distributions satisfies K L ( D 1 ||D 2 ) ≤ O ( ϵ 2 ). Therefore, a standard information theory result (stated and prov en in Lemma 5.3 for completeness) giv es that with few er than Ω(log (1 /δ ) /ϵ 2 ) generative queries, it is imp ossible to distinguish b et ween these t w o distributions with probability greater than 1 − δ , whic h implies the desired result. A similar construction shows that in the worst case, we also need at least ˜ O (1 /ϵ 2 ) min-queries to distinguish betw een tw o p opulations that are b oth close to ambiv alent b et ween t wo alternativ es. The main difference b etw een this construction and the one in Theorem 5.1 is that it is difficult to distinguish b etw een t wo similar populations rather than tw o similar distributions. Theorem 5.2. F or any δ, ϵ > 0 , no algorithm c an use fewer than Ω(log(1 /δ ) /ϵ 2 ) discriminative queries and for every distribution D identify an element of the ϵ -PVC with pr ob ability gr e ater than 1 − δ . Pr o of. Consider the uniform distribution D with supp ort { a 1 , a 2 } . Consider the follo wing tw o sets of v oters. In N 1 , a (1 / 2 + ϵ ) fraction of v oters hav e preference a 1 ≻ a 2 and a (1 / 2 − ϵ ) fraction of v oters hav e preference a 2 ≻ a 1 . In N 2 , a (1 / 2 + ϵ ) fraction of voters ha ve preference a 2 ≻ a 1 and a (1 / 2 − ϵ ) fraction of v oters ha ve preference a 1 ≻ a 2 . The ϵ -PV C for v oters N 1 is just { a 1 } while the ϵ -PVC for the voters N 2 is { a 2 } . Distinguishing b et ween these tw o voter p opulations with discriminativ e queries is equiv alent to distinguishing b etw een a B ernoul li (1 / 2 + ϵ ) distribution and a B ernoul li (1 / 2 − ϵ ) distribution. W e can again app eal to Lemma 5.3 to get the desired result that no algorithm can use fewer than Ω(log (1 /δ ) /ϵ 2 ) queries to identify an element of the ϵ -PVC with probabilit y higher than 1 − δ for both of these settings. The pro ofs of Theorem 5.1 and Theorem 5.2 b oth rely on the following standard result from information theory , whic h w e state here formally and repro ve for completeness. Lemma 5.3. If two distributions D 1 and D 2 have Kul lb ack-L eibler distanc e satisfying K L ( D 1 ||D 2 ) ≤ cϵ 2 for some c onstant c , then no algorithm c an achieve minimax misclassific ation err or of less than δ for these two distributions using fewer than O (log (1 /δ ) /ϵ 2 ) samples. Pr o of. Let D n 1 and D n 2 b e the pro duct distributions for n samples from D 1 and D 2 resp ectiv ely . Then b y definition, K L ( D n 1 , D n 2 ) = ncϵ 2 . By the Bretagnolle-Hub er Inequality , this implies that the T V ( D n 1 , D n 2 ) ≤ 1 − 1 2 e − ncϵ 2 . By Le Cam’s metho d, the minimax misclassification error for any classifier distinguishing b et ween D n 1 , D n 2 m ust b e low er b ounded b y 1 2 (1 − T V ( D n 1 , D n 2 )) ≥ 1 4 e − ncϵ 2 . Plugging in n = log (1 / (4 δ )) / ( cϵ 2 ) gives a misclassification error of at least δ , whic h is the desired result. 5.2 P airwise Discriminativ e Queries Theorems 5.1 and 5.2 together imply that Algorithm 2 is tight in terms of the n umber of generative queries and min-queries needed. As discussed in Section 4 , Algorithm 2 works by finding an elemen t of the PVC for a set of voters N and alternatives M . W e also show ed that this algorithm can b e 12 mo dified to use O ( nm ) pairwise queries, where n = | N | and m = | M | . In Theorem 5.4 , we sho w that finding the PV C from a set of alternatives N and alternativ es M (with sizes n and m resp ectiv ely) cannot b e done in few er than Ω( nm ) pairwise discriminative queries, which implies that there is no b etter subroutine than this mo dification in the w orst case. Theorem 5.4 and its pro of ma y b e of indep endent interest to those studying the elicitation of v oter preferences using pairwise comparisons. The pro of b elo w establishes a low er b ound of nm/ 32; w e presen t a longer pro of of the same result that ac hieves a tighter low er b ound of nm/ 2 in App endix B.2 . Theorem 5.4. When the sets of alternatives M and voters N ar e finite, no algorithm c an always find an element in the PVC using fewer than Ω( mn ) p airwise discriminative queries. Pr o of. Let m = k n + 1 for any k ≥ 1. By definition, any alternativ e a in the PV C must not b e rank ed in the last k alternativ es by an y voter. W e will show that an y algorithm ALG needs at least nm/ 32 queries to find any alternative not ranked in the last k b y an y voter, which implies we need at least nm/ 32 queries to find an y alternativ e in the PVC. Consider the following adv ersary . The adversary answers pairwise queries by ALG arbitrarily (and consistently with previous queries), and for ev ery alternative a keeps trac k of a coun ter c a whic h counts the n umber of pairwise queries in v olving alternativ e a up to this point. The adv ersary also k eeps track of a set X of “active” voters which is initialized to b e N . As so on as the coun ter c a for an alternativ e a hits n/ 4, the adversary arbitrarily chooses one of the remaining “active” v oters i for whic h a can b e in the b ottom k , and assigns a to b e one of voter i ’s k w orst rank ed alternativ es. The adversary then truthfully tells ALG that a is ranked in one of the last k sp ots for v oter i . Similarly , if the queries answ ered so far force an alternative a to b e ranked in the last k of a v oter i , then a is also assigned to voter i . If voter i has k distinct alternatives assigned to v oter i ’s last k sp ots, then voter i is no longer activ e and is remo ved from the set of activ e v oters. No w supp ose that ALG has asked few er than nm/ 32 discriminative queries. P artition the full set of alternatives M in to M 1 and M 2 , suc h that M 1 con tains all alternatives that ha ve b een in volv ed in at least n/ 4 discriminativ e queries up un til this point, and M 2 con tains all alternativ es that ha ve b een inv olv ed in strictly less than n/ 4 discriminative queries. Note that for any alternative in M 1 , the adversary has already placed that alternative in the last k sp ots of at least one voter, and therefore no alternative in M 1 is in the PV C. T o conclude the pro of, w e m ust show that ALG cannot determine whether or not an y alternativ e in M 2 is in the PVC. Because ALG has ask ed fewer than nm/ 32 queries so far and each query in volv es exactly tw o alternatives, the n umber of alternatives inv olv ed in at least n/ 4 discriminativ e queries is at most m/ 4. This implies that | M 1 | ≤ m/ 4. An alternative a is only assigned to a v oter if either it is in M 1 or if the queries for a sp ecific v oter i force a to b e in i ’s b ottom k sp ots. F or the latter case, there m ust ha ve b een at least m − 1 k = n queries p er suc h assigned a . Therefore, there are at least nk − m/ 4 − nm/ 32 n ≥ 23 kn − 9 32 remaining sp ots left in the b ottom k p ositions of the active v oters, which implies there are at least 23 n/ 32 − 1 active voters remaining. F or any alternativ e a ∈ M 2 , w e know that strictly less than n/ 4 v oters ha ve b een queried ab out a . Therefore, since there are at least 23 n/ 32 − 1 active voters remaining, there m ust b e at least 23 n/ 32 − 1 − n/ 4 > 0 activ e voters (for sufficien tly large n ) who hav e not yet b een queried ab out alternativ e a . Imp ortantly , this means that a may b e in one of the last k sp ots of these v oters’ rankings, whic h further implies that ALG is unable to determine whether a is in the PVC. This is true for every alternative a ∈ M 2 , so we can conclude that ALG cannot find an y element of the PV C with few er than nm/ 32 queries. 13 6 In terpretation of D In this section, we further discuss the significance of the distribution D . One wa y to think ab out D is to view it as a w eighting sc heme that puts more weigh t on more “imp ortant” alternatives. T raditional v oting theory does not explicitly assume such a weigh ting sc heme, but do es commonly assume neutrality . A voting rule satisfies neutralit y if it is indifferent to the identit y of the alter- nativ es, in other words the outcome do es not change if the alternatives are p ermuted. Therefore, an y voting rule that satisfies neutrality must implicitly weigh t the alternatives equally , i.e. use a uniform w eighting. Similarly , when there is a compact space of infinite alternatives, an y voting rule satisfying neutrality must implicitly use a distribution D that is the uniform distribution ov er all alternativ es. All of our theoretical results (b oth p ositiv e and negative) apply when D is the uniform dis- tribution. Ho wev er, when there are infinite alternatives, the uniform distribution may not alwa ys b e the correct choice. As an example, consider the alternative space M = [0 , 1] with 100 voters. 99 of these voters only lik e alternativ e 0 and one v oter only lik es alternativ e 1. In this example, despite infinite alternatives existing in the in terv al [0 , 1], the only tw o alternatives that should b e relev ant are { 0 , 1 } , which hav e measure 0 under the uniform distribution. Unfortunately , the natural generalization of man y voting rules (e.g., Borda coun t) ignore sets of size 0, and therefore ma y ev en select an alternativ e not from { 0 , 1 } . Similarly , when computing the ϵ -PVC, b oth of the alternativ es in { 0 , 1 } with measure 0 could b e vetoed dep ending on tie-breaking. This is clearly an undesirable outcome, and can b e easily a voided b y c ho osing a more appropriate distribution D . Motiv ated by the example ab o ve, one w ay to c ho ose the distribution D is to put more w eight on alternativ es that are more “imp ortan t”. This means that the distribution D is implicitly capturing the cardinal preferences of the v oters b y putting higher w eight on alternativ es for whic h voters ha v e higher utilities. A common c hoice for suc h a distribution is the Bradley-T erry-Luce (BTL) model, where the probability of selecting an alternativ e is prop ortional to a score for that alternative. Supp ose eac h pla yer i has a utility function u i : M → [0 , 1] suc h that R M u i ( m ) dm = 1. Then we could let D b e the mixture of BTL mo dels ov er all v oters, i.e. µ D ( m ) = 1 |N | P i ∈N u i ( m ). This is equiv alent to a BTL mo del with scores equal to the sum of voter utilities. Happily , c ho osing D to b e this BTL mo del also gives us an intuitiv e in terpretation for the ϵ -PV C. If D is this BTL mo del, then the size of a coalition necessary to veto an alternative is prop ortional to the utilitarian so cial welfare (total p opulation utilit y) for that alternativ e. This means that a larger coalition of v oters is needed to v eto an alternativ e that has higher utilit y among the voters. W e formalize this idea b elow in the extreme case . Theorem 6.1. If D satisfies µ D ( m ) = 1 |N | P i ∈N u i ( m ) then the fol lowing holds for any subset S ∈ M . If at le ast an x + ϵ fr action of voters r ank every alternative in S ab ove every alternative not in S and the total utility of S is gr e ater than 1 − x fr action of the total utility of al l alternatives, then the ϵ -PV C must b e a subset of S . Pr o of. Let T b e the coalition of v oters that prefers S to ev ery alternativ e not in S and satisfies | T | n ≥ x + ϵ . W e will show that the coalition T with alternativ es S can veto ev ery alternative a ∈ M \ S . This follows directly from the fact that µ D ( S ) = 1 |N | P i ∈N u i ( m ) > 1 − x ≥ 1 − ( x + ϵ ) + ϵ ≥ 1 − | T | n + ϵ whic h satisfies Definition 2.1 . In the discrete setting, we hav e the following corollary: Corollary 6.2. If D satisfies µ D ( m ) = 1 |N | P i ∈N u i ( m ) then the fol lowing holds. If at le ast an x + ϵ fr action of the p opulation r anks alternative a ∈ M first and the utilitarian so cial welfar e of a 14 is gr e ater than x fr action of the total utility of al l alternatives, then a is the only alternative in the ϵ -PV C. F or intuition, suppose x = 1 / 2 and D is the BTL distribution (as abov e). In this case, Corollary 6.2 says that if there is any alternative a suc h that a ma jorit y of voters rank a first and a has m ore than half of the total p opulation utilit y , then a is the only alternativ e in the ϵ -PVC. Similarly , if at least a 1 / 2 + ϵ fraction of voters hav e utility 1 for a and utilit y 0 for every other alternative, then a is the only alternative in the ϵ -PVC. Examples suc h as these demonstrate how the ϵ -PVC com bines b oth ordinal and cardinal preferences when D is the utility-based BTL mo del. 7 Exp erimen tal Results W e no w analyze the ϵ -PVC of synthetically generated preference data, mo deling the preferences of individuals ov er opinion statements on v arious p olicy issues. Our first exp erimen tal goal is to v erify that our algorithm p erforms well in practical settings. This complements our asymptotic analysis in Section 4 , demonstrating that our algorithm also p erforms well at small sample sizes. Our second goal is to measure ho w often p opular v oting rules choose alternativ es that are in the ϵ -PV C. Our third goal is to understand ho w w ell LLMs can generate statemen ts in the ϵ -PV C given differen t generativ e capabilities and types of information. F or eac h exp eriment, w e first use the p ersona dataset of Castricato et al. ( 2024 ) to select the 100 distinct voters in N . W e then generate a different alternative for each voter for a total of 100 alternativ es. W e let D b e the uniform distribution ov er these alternatives, to capture a distribution defined by first choosing a random voter, and then generating a statemen t based on that user’s preferences, as discussed in Section 2 . As in our theoretical model, the voting rules in our exp eriments only hav e access to a random subset of alternatives and voters, sp ecifically 20 of each. Of course, practical situations may ha ve more than 100 voters and alternativ es, and one would wan t to sample as man y as p ossible, but this small-scale exp erimen t allo ws us to run man y exp erimen ts with LLMs at reasonable cost. W e compute the critical ϵ with resp ect to all 100 alternativ es and v oters to measure how well the alternativ e selected b y eac h voting rule do es at finding common ground for the ov erall p opulation. Recall that the critical ϵ (Definition 2.2 ) measures the smallest ϵ for which the alternative is in the ϵ -PV C. Therefore, a metho d that is b etter at finding common ground will c ho ose alternativ es with critical ϵ close to 0 while a method that is w orse at finding common ground will choose alternativ es with relatively large critical ϵ . 5 7.1 Metho dology Our exp eriment setup is illustrated in Figure 1 . F or each of six topics, w e p erform 10 replications, eac h with 100 v oters and 100 alternatives drawn from the p ersona dataset. W e then obtain a ranking of the generated alternatives for each v oter to form the ov erall preference profile. F rom there, we subsample to get 20 voters and 20 statemen ts yielding a 20 × 20 preference profile, whic h we do 4 times p er replication. Finally , v arious voting rules are run on this 20 × 20 preference profile, and w e compare the critical epsilons of the selected alternatives (with resp ect to the original 100 × 100 preference profile). W e elaborate on the details of eac h step of the experiment b elow. 5 W e op en source our implementation of v arious ϵ -PVC computations at PV C T o olb o x . The pip-installable li- brary is p erformance-optimized with a max-flo w algorithm compiled with C through SciPy ( Virtanen et al. , 2020 ). F urthermore, we release the co debase for our exp eriments at this GitHub rep ository . 15 Figure 1: Our exp eriment setup. W e generate statements conditioned on synthetic p ersona, and build preference profiles from voters conditioned on synthetic p ersona. W e then ev aluate v arious v oting rules, including those p o wered by LLMs, and compare their critical epsilons. T opics. W e originally form ulated 13 topics co vering contemporary p olitical issues (App endix D.1.1 ). T o study if certain v oting rules do better or w orse on p olarized or less p olarized questions, w e rate eac h topic by degree of p olarization. F or each topic, we generate 100 statements and sample 100 v oters indep enden tly to assign a Lik ert score from 0-10 to eac h statemen t indicating ho w m uch they agree with that stateme n t (Figure 4 ). W e then compute the mean Likert score and tak e its absolute difference from 5 to measure ho w strongly voters feel ab out differen t topics, i.e. ho w p olarizing topics are. Finally , w e selected the top three and b ottom three topics b y this metric. P ersonas. W e use the 1,000 synthetic p ersonas generated by Castricato et al. ( 2024 ). Their choice of p ersonas is informed b y the US census and in tended to b e ideologically and demographically div erse. Each p ersona contains comprehensive p ersonal characteristics, such as race, o ccupation, and how they sp end their p ersonal time. An example of a p ersona can b e found in App endix D.2 . W e filter the p ersonas to those ab ov e the age of 18, th us obtaining 815 adult p ersonas. Alternativ es. F or eac h p ersona and topic, we generate a representativ e statement from that p er- sona for that topic by querying an LLM (sp ecifically , gpt-5-mini ). W e explore other metho ds to generate alternatives in App endix D.3 . Preference Profiles. W e construct preference profiles by asking each voter (p o wered by gpt-5-mini and conditioned on a p ersona) to sequen tially rank their top 10 and b ottom 10 statements until all 100 statemen ts are rank ed. W e term this approac h iter ative r anking and discuss further details in App endix D.4 . Each preference profile consists of 100 voters and 100 statements. Calculating Critical Epsilons. W e compute the critical epsilons for each statemen t using Algo- rithm 1 (where the critical ϵ is with resp ect to the full 100 × 100 preference profile and the uniform distribution ov er these alternatives). 16 7.2 V oting Rules In this section, we compare the critical epsilon of the statemen ts selected by v arious voting rules. V eto-By-Consumption (VBC) ( Ianovski and Kondratev , 2023 ), like Algorithm 2 , finds an elemen t of the PV C for the subsampled preference profile. W e then compare VBC to other standard v oting rules, including Borda count, Sch ulze ( Sch ulze , 2011 ), Instan t Runoff V oting (IR V), and plurality . W e also include a baseline that is the critical ϵ of a uniform randomly chosen statement among the 100. Figure 2 shows the cumulativ e distribution function (CDF) of critical epsilons across all iterations for the three con trov ersial topics, and T able 1 shows the mean critical epsilons for all six topics. CDF graphs for the other topics and additional figures can b e found at App endix D.7 . Across topics there is a consistent pattern: the voting rules rank ed in increasing order of critical epsilons are: VBC < Borda < Sc hulze < IR V < Pluralit y . (2) As exp ected from our theoretical results, even with access to only a small num b er of v oters and alternatives, finding an element of the PV C for the subset giv es an alternativ e with very lo w critical ϵ for the full sets. The critical ϵ for VBC is almost alwa ys 0, with mean consistently less than 0 . 001 across topics. This supp orts using metho ds for finding elemen ts of the PV C in practical situations even without ha ving access to full information. Unsurprisingly , the other voting rules select alternativ es that hav e higher critical ϵ . F or example, Sc hulze (used b y the Hab ermas mac hine) selects alternativ es with an order of magnitude higher critical epsilon than VBC. Perhaps more surprisingly , pluralit y consistently selects alternatives with higher critical ϵ than just choosing a random alternative. The so cial c hoice function that consisten tly do es the b est after VBC is Borda count. In practice, Borda count could b e a go o d compromise as a scoring rule that is easily computable, interpretable, and also chooses alternatives with small critical ϵ . In addition to these syn thetic exp eriments for preferences o v er textual statements, w e also tested ho w w ell eac h of these v oting rules p erform on preference datasets from Preflib ( Mattei and W alsh , 2013 ), without subsampling, i.e., when the voting rule has full access to voters and alternatives. In these real-world scenarios, w e observe the same pattern of Equation ( 2 ), with Borda coun t consisten tly having the lo west critical ϵ among the standard voting rules and Pluralit y consisten tly ha ving the highest. See App endix D.5 for more details. 0.00 0.05 0.10 0.15 0.20 0.25 0.30 0.35 0.40 Epsilon 0.0 0.2 0.4 0.6 0.8 1.0 Cumulative P r obability Abortion VB C Bor da Schulze IR V Plurality R andom 0.00 0.05 0.10 0.15 0.20 0.25 0.30 0.35 0.40 Epsilon 0.0 0.2 0.4 0.6 0.8 1.0 Electoral College VB C Bor da Schulze IR V Plurality R andom 0.00 0.05 0.10 0.15 0.20 0.25 0.30 0.35 0.40 Epsilon 0.0 0.2 0.4 0.6 0.8 1.0 Healthcare VB C Bor da Schulze IR V Plurality R andom Critical Epsilons of V oting Methods for T opics: Abortion, Electoral College, Healthcare Figure 2: CDF of critical epsilons for the chosen alternativ es of v arious voting rules for the three p olarizing topics. The s maller the epsilons (the closer the line is to the top-left corner), the b etter at finding common ground the voting metho d is. 17 T able 1: Mean critical epsilons for v arious v oting rules across v arious topics. The smallest epsilon for each topic is bolded. Metho d Ab ortion Electoral College Healthcare Policing En vironmen t T rust in Institutions VBC 0.0008 0.0000 0.0003 0.0003 0.0000 0.0014 Borda 0.0075 0.0023 0.0005 0.0015 0.0014 0.0025 Sc hulze 0.0108 0.0040 0.0030 0.0040 0.0033 0.0033 IR V 0.0203 0.0233 0.0063 0.0133 0.0086 0.0050 Pluralit y 0.0865 0.0460 0.0158 0.0268 0.0142 0.0128 Random 0.0609 0.0108 0.0082 0.0103 0.0108 0.0072 7.3 Generativ e V oting Rules In this section we examine gener ative voting rules , whic h do not ha ve to select among the existing alternativ es and instead can use an LLM-generated new alternativ e. W e consider sev eral different generativ e voting rules that each use differen t amounts of information ab out the problem to generate common-ground statements: • GPT-Blind: the mo del is only giv en the topic and no information about v oters or alternatives • GPT-Syn thesize: the mo del is given the topic and the 20 alternatives. • GPT-Syn thesize+Rankings: the mo del is giv en the topic, the 20 alternatives, and the 20 × 20 preference profile. • GPT-Syn thesize+P ersonas: the mo del is given the topic and the p ersona descriptions of the 20 voters. T o keep the v alues comparable, w e do not compute the critical epsilon of a generated statemen t with resp ect to the uniform distribution o ver 101 statemen ts. Instead, we con tinue to consider the uniform distribution ov er the 100 original statements, and treat the generated statement as having zero probability mass in D . T able 2 sho ws the mean critical ϵ for these differen t generative v oting rules. F rom this table, we can see that the generative voting rules do generate alternatives with smaller critical ϵ than many standard v oting rules lik e Sch ulze, IR V, and Plurality . VBC and Borda b oth slightly outp erform the generativ e v oting rules despite the fact that the generative methods can pro duce their own alternativ es. Overall, the generative v oting rules choose alternativ es with relatively lo w critical ϵ , indicating that what an LLM b eliev es represen ts common ground is well aligned with the concept of the PVC. In addition to ge nerativ e LLM-based metho ds, we also ev aluate LLM-based metho ds that are still restricted to choosing one of the original 100 alternatives. W e discuss these metho ds and results in more detail in App endix D.8 . Clustered V oter P opulations. In the previous section, we show ed that the generative voting rules are able to generate alternativ es with v ery lo w critical ϵ , and the low n um b ers make it difficult to distinguish b etw een the generativ e and non-generativ e metho ds. As LLMs are p ost-trained to b e aligned to the general p opulation, we hypothesize that generative voting rules will struggle in elections where the v oter base is skew ed to a particular ideology . T o inv estigate this, w e partition the 815 adult p ersonas into 431 progressives and 255 conserv atives by k eyword filtering, with 129 18 T able 2: Mean critical epsilons for VBC, generative voting rules and random baselines across v arious topics. Smallest epsilon for each topic is b olded. Under “Random Insertion,” we sample a random statemen t from the 815 global statemen ts that are not in the 100 × 100 preference profile and use the same insertion program that we use for the generativ e metho ds. Metho d Abortion Electoral College Healthcare Policing Environmen t T rust in Institutions VBC 0.0008 0.0000 0.0003 0.0003 0.0000 0.0014 GPT-Blind 0.0103 0.0093 0.0080 0.0045 0.0085 0.0200 GPT-Syn thesize 0.0055 0.0108 0.0090 0.0128 0.0168 0.0238 GPT-Syn th+Rank. 0.0030 0.0053 0.0038 0.0025 0.0080 0.0095 GPT-Syn th.+Pers. 0.0030 0.0060 0.0040 0.0040 0.0058 0.0105 Random Insertion 0.0700 0.0100 0.0108 0.0100 0.0073 0.0110 Random 0.0609 0.0108 0.0082 0.0103 0.0108 0.0072 0.0 0.2 0.4 0.6 0.8 1.0 Epsilon 0.0 0.2 0.4 0.6 0.8 1.0 Cumulative P r obability Abortion VB C GPT - Blind GPT -Synthesize GPT -Synth+R ank GPT -Synth+P ers R andom Insertion R andom 0.0 0.2 0.4 0.6 0.8 1.0 Epsilon 0.0 0.2 0.4 0.6 0.8 1.0 Electoral College VB C GPT - Blind GPT -Synthesize GPT -Synth+R ank GPT -Synth+P ers R andom Insertion R andom 0.0 0.2 0.4 0.6 0.8 1.0 Epsilon 0.0 0.2 0.4 0.6 0.8 1.0 Healthcare VB C GPT - Blind GPT -Synthesize GPT -Synth+R ank GPT -Synth+P ers R andom Insertion R andom Critical Epsilons of Generative V oting Methods (Conservative V oters) for T opics: Abortion, Electoral College, Healthcare Figure 3: Critical epsilons for the winners of v arious generative voting rules on conserv ativ e voters for p olarizing topics. Generative voting rules consisten tly do worse than VBC and sometimes even the random baseline. unmatc hed p ersonas (see App endix D.9 for details). W e plot our results for conserv ative v oters in Figure 3 and rep ort the mean critical epsilon in T able 3 . W e find that generativ e voting rules degraded significantly compared to T able 2 and sometimes p erform w orse than the random baseline, while VBC maintains its performance of ha ving most critical epsilons close to 0. W e also find that providing more information to the generative v oting rules helps them signifi- can tly . In terestingly , providing p ersonas of the voters is the most helpful to the generativ e v oting rules, but with this information the mean critical epsilon is still 10 times larger than that of VBC. Due to space constrain ts, w e rep ort the results for progressiv e v oters in T able 12 in App endix D.9.3 . 8 Discussion One of the main theoretical contributions of this pap er is analyzing the sample complexity of finding alternatives in the ϵ -PVC using differen t t yp es of queries. While w e studied certain forms of generative and discriminativ e queries, there are many other wa ys to elicit information ab out b oth alternatives and v oters. A natural op en question is whether there are other reasonable query mo dels that are more effective at finding elemen ts of the ϵ -PVC. F or example, differen t forms of discriminativ e or generativ e queries ma y b e able to reduce the complexity of identifying an elemen t 19 T able 3: Mean critical epsilons for VBC, generative voting rules and random baselines across v arious topics for conserv ativ e v oters. Smallest epsilon for eac h topic is b olded. Metho d Abortion Electoral College Healthcare Policing Environmen t T rust in Institutions VBC 0.0013 0.0003 0.0003 0.0000 0.0003 0.0000 GPT-Blind 0.2775 0.0263 0.0050 0.0225 0.0843 0.0220 GPT-Syn thesize 0.2313 0.0263 0.0178 0.0393 0.0230 0.0305 GPT-Syn th+Rank. 0.1980 0.0295 0.0120 0.0215 0.0280 0.0048 GPT-Syn th.+Pers. 0.1065 0.0088 0.0048 0.0033 0.0065 0.0010 Random Insertion 0.1360 0.1013 0.0418 0.0640 0.0153 0.0135 Random 0.1751 0.0989 0.0428 0.0625 0.0382 0.0330 of the ϵ -PVC and close the 1 /ϵ to 1 /ϵ 2 gap we show ed in Section 5 . One of our key assumptions is that the num b er of alternativ es is large or infinite, a setting in whic h man y v oting rules are not w ell-defined. Therefore, another open question is how to generalize other v oting rules to the setting of infinite alternatives. F or example, despite the PVC technically requiring a num b er of constrain ts which is exp onential in |N | , Theorem 4.1 shows that the num b er of samples needed to find an element of the ϵ -PV C do es not dep end on the distribution or the n umber of voters. One could ask whether other voting rules also hav e such shortcuts in the infinite alternativ e setting, and whether similar sample complexity results hold. Finally , w e use the critical ϵ to measure the degree to whic h a given statement represents common ground for the p opulation. Ho wev er, there ma y b e man y alternatives with critical ϵ equal to 0, in whic h case it ma y not b e ob vious ho w to choose among them. One practical wa y to break ties would b e to c ho ose the alternative from the ϵ -PVC with the highest score according to some so cial c hoice scoring function. F or example, we could select the alternativ e with the highest Borda score among all alternatives in the ϵ -PVC. If we take the Borda score as a pro xy for maximizing w elfare, then the Borda winner in the ϵ -PV C can b e in terpreted as the common-ground alternativ e with the highest w elfare. One direction for future work is to further explore the b est wa y to com bine the ϵ -PVC with differen t scoring functions to select alternativ es with small critical ϵ and high welfare. Ac kno wledgemen ts This work w as partially supp orted by the National Science F oundation under grant I IS-2229881, b y the Office of Nav al Research under gran ts N00014-24-1-2704 and N00014-25-1-2153, and by gran ts from the Co op erative AI F oundation and the F oresigh t Institute. Schiffer and Zhang were supp orted b y an NSF Graduate Research F ellowship. W e thank T eddy Lee and Op enAI for the generous supp ort of API credits for running our exp erimen ts. References P arand A Alamdari, Soroush Ebadian, and Ariel D Pro caccia. P olicy aggregation. A dvanc es in Neur al Information Pr o c essing Systems , 37:68308–68329, 2024. M. Bakk er, M. Chadwic k, H. Sheahan, M. T essler, L. Campb ell-Gillingham, J. Balaguer, N. McAleese, A. Glaese, J. Aslanides, M. Botvinick, and C. Summerfield. Fine-tuning lan- 20 guage mo dels to find agreement among humans with div erse preferences. In Pr o c e e dings of the 36th Annual Confer enc e on Neur al Information Pr o c essing Systems (NeurIPS) , 2022. Carter Blair and Kate Larson. Generating fair consensus statements with so cial choice on tok en- lev el mdps. In Pr o c e e dings of the 25th International Confer enc e on Autonomous A gents and Multi-A gent Systems (AAMAS) , 2026. F orthcoming. Niclas Bo ehmer, Rob ert Brederec k, Piotr F aliszewski, and Rolf Niedermeier. A quantitativ e and qualitativ e analysis of the robustness of (real-w orld) election winners. In Pr o c e e dings of the 2nd A CM Confer enc e on Equity and A c c ess in A lgorithms, Me chanisms, and Optimization (EAAMO ’22) , pages 7:1–7:10. ACM, 2022. doi: 10.1145/3551624.3555292. URL https://doi.org/10. 1145/3551624.3555292 . Niclas Bo ehmer, Sara Fish, and Ariel D. Pro caccia. Generative so cial c hoice: The next generation. In Pr o c e e dings of the 42nd International Confer enc e on Machine L e arning , 2025. Niclas B¨ ohmer. Applic ation-oriente d Col le ctive De cision Making: Exp erimental T o olb ox and Dynamic Envir onments . PhD thesis, T echnisc he Universit¨ at Berlin, 2023. URL https: //depositonce.tu- berlin.de/items/ad71ac35- 162d- 4abb- 8bf5- bcbedbac1281 . Louis Castricato, Nathan Lile, Rafael Rafailov, Jan-Philipp F r¨ ank en, and Chelsea Finn. Persona: A repro ducible testb ed for pluralistic alignmen t, 2024. Bhask ar Ra y Chaudh ury , Aniket Murhek ar, Zh uow en Y uan, Bo Li, Ruta Meh ta, and Ariel D Pro caccia. F air federated learning via the prop ortional veto core. In F orty-first International Confer enc e on Machine L e arning , 2024. Computational Demo cracy Pro ject. Group informed consensus, 2025. URL https:// compdemocracy.org/group- informed- consensus/ . Accessed: 2026-02-08. Vincen t Conitzer, Rac hel F reedman, Jobst Heitzig, W esley H. Holliday , Bob M. Jacobs, Nathan Lam b ert, Milan Moss´ e, Eric Pacuit, Stuart Russell, Hailey Schoelkopf, Eman uel T ew olde, and William S. Zwick er. Position: so cial choice should guide ai alignment in dealing with diverse h uman feedbac k. In Pr o c e e dings of the 41st International Confer enc e on Machine L e arning (ICML) , 2024. Soham De, Mic hiel A Bakk er, Jay Baxter, and Martin Sa veski. Sup ernotes: Driving consensus in crowd-sourced fact-chec king. In Pr o c e e dings of the ACM on Web Confer enc e 2025 , pages 3751–3761, 2025. Dem brane. First rep ort: Demo cratic inputs to AI, Octob er 2023. URL https://www.dembrane. com/en- US/blog/report- openai- october- 2023 . Blog p ost describing the Common Ground application for hosting delib erations at scale. E. A. Dinitz. Algorithm for solution of a problem of maximum flow in net works with p o wer estimation. Doklady Akademii Nauk SSSR , 194(4):754–757, 1970. John S. Dryzek, Andr´ e B¨ ach tiger, Simone Chambers, Joshua Cohen, James N. Druckman, Andrea F elicetti, James S. Fishkin, David M. F arrell, Arc hon F ung, Am y Gutmann, H´ el ` ene Landemore, Jane Mansbridge, Sofie Marien, Mic hael A. Neblo, Simon Niemey er, Maija Set¨ al¨ a, Rune Slothuus, Jane Suiter, Dennis Thompson, and Mark E. W arren. The crisis of demo cracy and the science of delib eration. Scienc e , 363(6432):1144–1146, Marc h 2019. ISSN 0036-8075, 1095-9203. doi: 10/gfw5hq. 21 Sara Fish, Paul G¨ olz, Da vid C. P arkes, Ariel D. Pro caccia, Gili Rusak, Itai Shapira, and Manuel W ¨ uthrich. Generative So cial Choice. Journal of the A CM , 2026. T o App ear. James S. Fishkin. When the Pe ople Sp e ak: Delib er ative Demo cr acy and Public Consultation . Oxford Univ ersity Press, 2009. Mic hael R. Garey and David S. Johnson. Computers and Intr actability; A Guide to the The ory of NP-Completeness . W. H. F reeman & Co., USA, Octob er 1990. ISBN 978-0-7167-1045-5. Luise Ge, Daniel Halpern, Evi Micha, Ariel D Pro caccia, Itai Shapira, Y evgeniy V orob eychik, and Junlin W u. Axioms for ai alignmen t from human feedbac k. A dvanc es in Neur al Information Pr o c essing Systems , 37:80439–80465, 2024. P aul G¨ olz, Nik a Haghtalab, and Kunhe Y ang. Distortion of ai alignment: Do es preference opti- mization optimize for preferences? arXiv pr eprint arXiv:2505.23749 , 2025. Jairo F Gudi˜ no, Um b erto Grandi, and C ´ esar Hidalgo. Large language mo dels (llms) as agen ts for augmen ted demo cracy . Philosophic al T r ansactions A , 382(2285):20240100, 2024. Daniel Halp ern, Ariel D. Pro caccia, and W arut Suksomp ong. The prop ortional veto principle for approv al ballots. In Pr o c e e dings of the Thirty-F ourth International Joint Confer enc e on A rtificial Intel ligenc e , IJCAI ’25, 2025. ISBN 978-1-956792-06-5. doi: 10.24963/ijcai.2025/434. URL https://doi.org/10.24963/ijcai.2025/434 . Egor Iano vski and Aleksei Y. Kondratev. Computing the prop ortional v eto core, April 2023. URL http://arxiv.org/abs/2003.09153 . arXiv:2003.09153 [cs]. A. Kahng, M. K. Lee, R. Noothigattu, A. D. Pro caccia, and C.-A. Psomas. Statistical foundations of virtual demo cracy . In Pr o c e e dings of the 36th International Confer enc e on Machine L e arning (ICML) , pages 3173–3182, 2019. Andrew Kon y a, Lisa Schirc h, Colin Irwin, and Aviv Ov ady a. Demo cratic P olicy Dev elopmen t using Collectiv e Dialogues and AI, No vem b er 2023. H ´ el` ene Landemore. Can Artificial In telligence Bring Delib eration to the Masses? In Ruth Chang and Amia Sriniv asan, editors, Conversations in Philosophy, L aw, and Politics , pages 39–69. Oxford Universit y PressOxford, 1 edition, Marc h 2024. doi: 10.1093/oso/9780198864523.003. 0003. Am b er Hy e-Y on Lee. So cial T rust in Polarized Times: Ho w P erceptions of Political Polarization Affect Americans’ T rust in Eac h Other. Politic al Behavior , 44(3):1533–1554, September 2022. ISSN 0190-9320, 1573-6687. doi: 10.1007/s11109- 022- 09787- 1. N. Mattei and T. W alsh. Preflib: A library for preferences. In Pr o c e e dings of the 3r d International Confer enc e on Algorithmic De cision The ory (ADT) , pages 259––270, 2013. Jennifer McCo y , T ahmina Rahman, and Murat Somer. Polarization and the Global Crisis of Demo cracy: Common P atterns, Dynamics, and P ernicious Consequences for Demo cratic Polities. A meric an Behavior al Scientist , 62(1):16–42, Jan uary 2018. ISSN 0002-7642, 1552-3381. doi: 10/gdfg7m. Samm y McKinney and Claudia Chw alisz. Five dimensions of scaling demo cratic deliberation: With and b eyond AI. T ec hnical rep ort, Demo cracyNext, 2025. 22 Herv e Moulin. The Proportional V eto Principle. The R eview of Ec onomic Studies , 48(3):407, July 1981. ISSN 00346527. doi: 10.2307/2297154. Herv ´ e Moulin. V oting with prop ortional v eto p o wer. Ec onometric a: Journal of the Ec onometric So ciety , pages 145–162, 1982. OECD. Innovative Citizen Particip ation and New Demo cr atic Institutions: Catching the Delib- er ative Wave . Organisation for Economic Co-operation and Developmen t, June 2020. doi: 10.1787/339306da- en. Y unus Emre Orhan. The relationship b etw een affective p olarization and demo cratic backsliding: Comparativ e evidence. Demo cr atization , 29(4):714–735, Ma y 2022. ISSN 1351-0347, 1743-890X. doi: 10.1080/13510347.2021.2008912. Aviv Ov adya and Luk e Thorburn. Bridging systems: Op en problems for countering destruc- tiv e divisiv eness across ranking, recommenders, and gov ernance, Octob er 2023. URL https: //knightcolumbia.org/content/bridging- systems . Essays and Scholarship. James A. Piazza. P olitical Polarization and Political Violence. Se curity Studies , 32(3):476–504, Ma y 2023. ISSN 0963-6412, 1556-1852. doi: 10.1080/09636412.2023.2225780. Grzegorz Pierczynski and Stanisla w Szufa. Single-Winner V oting with Alliances: Avoiding the Sp oiler Effect. In Mehdi Dastani, Jaime Sim˜ ao Sic hman, Natasha Alechina, and Virginia Dign um, editors, Pr o c e e dings of the International Confer enc e on Autonomous A gents and Multi-A gent Systems (AAMAS) , pages 1567–1575, 2024. doi: 10.5555/3635637.3663017. Florenz Plassmann and T. Nicolaus Tideman. Ho w frequently do different v oting rules encounter v oting parado xes in three-candidate elections? So cial Choic e and Welfar e , 42(1):31–75, 2014. doi: 10.1007/s00355- 013- 0720- 8. Ariel Procaccia, Benjamin Schiffer, Serena W ang, and Shirley Zhang. Metrito cracy: Represen tative metrics for lite b enc hmarks. arXiv pr eprint arXiv:2506.09813 , 2025a. Ariel D. Pro caccia, Benjamin Schiffer, and Shirley Zhang. Clone-robust ai alignment. In Pr o c e e dings of the 42nd International Confer enc e on Machine L e arning , volume 267, pages 49903–49926, 2025b. Da vid Rozado. The p olitical preferences of LLMs. PLOS ONE , 19(7):e0306621, July 2024. ISSN 1932-6203. doi: 10.1371/journal.p one.0306621. Markus Sc hulze. A new monotonic, clone-indep endent, reversal symmetric, and condorcet- consisten t single-winner election metho d. So cial Choic e and Welfar e , 36(2):267–303, F ebruary 2011. ISSN 0176-1714, 1432-217X. doi: 10.1007/s00355- 010- 0475- 4. Laura Silver. Most across 19 coun tries see strong partisan conflicts in their so ci- et y , esp ecially in South Korea and the U.S. P ew Research Center, 2022. URL https://www.pewresearch.org/short- reads/2022/11/16/most- across- 19- countries- see- strong- partisan- conflicts- in- their- society- especially- in- south- korea- and- the- u- s/ . Accessed: 2026-01-31. Isaac Slaughter, Axel Peyta vin, Johan Ugander, and Martin Sav eski. Comm unity notes reduce engagemen t with and diffusion of false information online. Pr o c e e dings of the National A c ademy of Scienc es , 122(38):e2503413122, 2025. 23 C. Small, M. Bjorkegren, T. Erkkil¨ a, L. Shaw, and C. Megill. P olis: Scaling deliberation b y mapping high dimensional opinion spaces. R evista De Pensament I An` alisi , 26(2), 2021. Christopher T. Small, Iv an V endrov, Esin Durm us, Hadjar Homaei, Elizab eth Barry , Julien Cornebise, T ed Suzman, Deep Ganguli, and Colin Megill. Opp ortunities and Risks of LLMs for Scalable Delib eration with Polis, June 2023. Mic hael Henry T essler, Michiel A. Bakk er, Daniel Jarrett, Hannah Sheahan, Martin J. Chadwic k, Raphael Koster, Georgina Ev ans, Lucy Campb ell-Gillingham, T an tum Collins, Da vid C. Park es, Matthew Botvinick, and Christopher Summerfield. AI can help humans find common ground in demo cratic delib eration. Scienc e , 386(6719):eadq2852, October 2024. ISSN 0036-8075, 1095-9203. doi: 10.1126/science.adq2852. T. Nicolaus Tideman and Florenz Plassmann. Mo deling the outcomes of vote-casting in actual elections. In Dan S. F elsenthal and Mosh ´ e Macho v er, editors, Ele ctor al Systems: Par adoxes, Assumptions, and Pr o c e dur es , pages 217–251. Springer, Berlin, 2012. doi: 10.1007/978- 3- 642- 20441- 8 9. T. Nicolaus Tideman and Florenz Plassmann. Whic h voting rule is most lik ely to choose the “b est” candidate? Public Choic e , 158(3):331–357, 2014. doi: 10.1007/s11127- 012- 9935- y . P auli Virtanen, Ralf Gommers, T ravis E. Oliphan t, Matt Hab erland, T yler Reddy , David Cour- nap eau, Evgeni Buro vski, Pearu Peterson, W arren W ec kesser, Jonathan Bright, St ´ efan J. v an der W alt, Matthew Brett, Joshua Wilson, K. Jarro d Millman, Nik olay May oro v, Andrew R. J. Nelson, Eric Jones, Rob ert Kern, Eric Larson, C J Carey , ˙ Ilhan P olat, Y u F eng, Eric W. Mo ore, Jak e V anderPlas, Denis Laxalde, Josef Perktold, Rob ert Cimrman, Ian Henriksen, E. A. Quin- tero, Charles R. Harris, Anne M. Archibald, Antˆ onio H. Rib eiro, F abian P edregosa, Paul v an Mulbregt, and SciPy 1.0 Con tributors. SciPy 1.0: F undamental Algorithms for Scientific Com- puting in Python. Natur e Metho ds , 17:261–272, 2020. doi: 10.1038/s41592- 019- 0686- 2. Stefan W o jcik, Sophie Hilgard, Nic k Judd, Delia Mo can u, Stephen Ragain, MB Hunzak er, Keith Coleman, and Jay Baxter. Birdwatc h: Crowd wisdom and bridging algorithms can inform un- derstanding and reduce the spread of misinformation. arXiv pr eprint arXiv:2210.15723 , 2022. Guanh ua Zhang and Moritz Hardt. Inherent trade-offs betw een div ersit y and stabilit y in multi-task b enc hmarks. In Pr o c e e dings of the 41st International Confer enc e on Machine L e arning (ICML) , 2024. Jia yi Zhang, Simon Y u, Derek Chong, An thony Sicilia, Michael R. T omz, Christopher D. Manning, and W eiyan Shi. V erbalized sampling: How to mitigate mo de collapse and unlo ck llm diversit y , 2025. URL . 24 App endix A Reduction of ϵ -PV C to PV C The standard definition of PVC (as in ( Moulin , 1982 )) is the follo wing. Definition A.1. Let there b e a set of voters N with | N | = n , and a set of alternatives M with | M | = m . Eac h voter i has a ranking σ i o ver all alternativ es. Let the v eto function f ( x, n, m ) for some p ositive integer x ≤ n b e defined as follows: f ( x ) = l x n · m − 1 m . An alternative a is v eto ed if there exists some group of v oters T ∈ N such that there exists a set S of alternatives with | S | ≥ m − f ( | T | ) where every v oter i ∈ T prefers every alternative b ∈ S to a . The set of alternatives which are not vetoed is called the pr op ortional veto c or e . No w consider Definition 2.1 with N = N , M = M , ϵ = 0, and D as the uniform distribution o ver M . W e will sho w this is equiv alent to Definition A.1 Define n = | N | and m = | M | . In this c hoice of parameters for Definition 2.1 , an alternativ e a ∈ M is blo ck ed if there exists a T ⊆ N and S ⊆ M such that | S | m > 1 − | T | n . Defining y = m | T | n , this can b e rewritten as | S | > m − y . (3) Note that | S | > m − y if and only if | S | ≥ m − ⌈ y − 1 ⌉ . Therefore, Equation ( 3 ) is equiv alent to | S | ≥ m − ⌈ y − 1 ⌉ = m − f ( | T | ) . This is exactly the same definition of b eing blo ck ed as in Definition A.1 , and therefore we are done. B Deferred Pro ofs B.1 Pro of of Prop osition 3.1 Pr o of of Pr op osition 3.1 . A k ey technical tool w e use in the pro of of Prop osition 3.1 is a linear time algorithm that, giv en full access to D and the preferences of the v oters, can return a set of alternativ es that are in the ϵ -PV C. This algorithm is based on the V eto by V oting (VBV) algorithm in ( Moulin , 1982 ) for finding the PVC when M is finite. F or any instance of the problem with finite M , VBV alwa ys output an element of the PVC. Our modification allo ws these algorithms to generalize to the setting of ϵ -PVC with infinitely many alternativ es. Prop osition 3.1 follows directly from the follo wing lemma analyzing Algorithm 3 . Lemma B.1. Every alternative in the set C r eturne d by Algorithm 3 is in the ϵ -PVC. F urthermor e, µ D ( C ) ≥ ϵ . Pr o of. W e first will show that the set of alternativ es returned b y Algorithm 3 must all b e in the ϵ -PV C. Pro of b y con tradiction. Supp ose that a is returned b y Algorithm 3 and that a is not in the ϵ -PV C. By definition of ϵ -PVC, there m ust exist a coalition T and set of alternatives S suc h that 25 ALGORITHM 3: V ote by γ -V eto 1 Input: A set of v oters N and a set of alternatives M 2 Output: A set of alternativ es. 3 Let γ = 1 − ϵ n . 4 Assign each alternatives a ∈ M capacity c a = µ D ( a ). 5 Initialize C = M 6 for voter i ∈ N do 7 V oter i identifies the smallest set X ⊆ C with the follo wing prop erties. First, for every x ∈ X and y ∈ C , y ≻ i x . Second, defining X 0 = { x ∈ X : µ D ( x ) = 0 } , µ D ( X 0 ) + X x ∈ X \ X 0 c x ≥ γ . 8 Remo ve all alternatives in X from C except the one most highly ranked by voter i and call the most highly ranked alternative a . 9 If c a ≤ γ − µ D ( X \ { a } ), then remov e a from C . Otherwise, let c a = c a − ( γ − µ D ( x \ { a } )). 10 end 11 return C w ≻ i a for all i ∈ T and w ∈ S and µ D ( S ) > 1 − | T | n + ϵ. F or i ∈ T , let W i b e the set of alternatives that i ranks lo wer than a , and let W = { a } ∪ ( ∪ i ∈ T W i ). By construction, w e m ust ha ve that S and W are disjoint, so µ D ( W ) ≤ 1 − µ D ( S ) < | T | n − ϵ. Because a is in C when the algorithm terminates, every v oter in T m ust hav e remov ed or decreased the capacity of alternativ es they lik e less than or equal to a , so ev ery voter in T must ha ve remo v ed or decreased the capacity of alternatives in W . Each voter in S consumes γ mass, therefore the total amount of mass that is consumed from W m ust b e at least γ | T | = | T | (1 − ϵ ) n = | T | n − | T | n ϵ ≥ | T | n − ϵ > µ D ( W ) . Therefore, all alternatives in W must ha ve b een remov ed from C by the time that the algorithm terminated, and therefore a m ust hav e b een remo ved from C . This is a contradiction with the fact that a is returned by the algorithm, which completes the first part of the pro of. T o see that µ D ( C ) ≥ ϵ , define m ( C ) := µ D ( { x ∈ C : µ D ( x ) = 0 } ) + X x ∈ C : µ D ( x ) =0 c x . By construction, m ( C ) decreases b y exactly γ in each round of the for lo op. Since γ = 1 − ϵ n and there are n rounds of the for lo op, this implies that m ( C ) = ϵ when the algorithm terminates. F urthermore, by definition m ( C ) ≤ µ D ( C ), therefore m ( C ) = ϵ implies that µ D ( C ) ≥ ϵ as desired. B.2 Alternativ e Pro of of Theorem 5.4 In this section, w e presen t an alternativ e pro of for Theorem 5.4 that ac hieves a tigh ter lo wer bound of mn/ 2 (impro vemen t ov er mn/ 32 as sho wn in the pro of in Section 5 ). Note that our algorithm 26 using Median of Medians only uses ≈ 3 . 33 mn pairwise discriminativ e queries, and therefore this tigh ter lo wer b ound is only a factor of ≈ 6 . 66 from b eing fully tight. Se c ond Pr o of of The or em 5.4 . Let m = n + 1. First, assume that w e kno w w e are in one of t wo cases: • Alternativ e a is rank ed second to last in ev ery single ranking, and ev ery alternative in A \ { a } is ranked last in exactly one ranking • Alternativ e a is rank ed second to last b y n − 1 v oters and is ranked last in exactly one ranking, in which some alternativ e x is ranked second to last. Every alternative in A \ { a, x } is rank ed last in exactly one ranking. In the first option ab ov e, the PV C is just { a } . In the second option ab ov e, the PV C is just { x } . Therefore, in order to find the prop ortional veto core, the algorithm must b e able to distinguish b et ween these t wo cases. W e will sho w that no algorithm can distinguish b etw een these tw o cases with fewer than nm 2 = n ( n +1) 2 queries by giving an adversary that requires at least this many queries. Define X = A \ { a } . W e therefore will consider the easier problem of determining if ev ery elemen t of X is rank ed last exactly once in N . Note that an y queries not in volving a will not giv e an y information for this alternate problem, therefore w e will only consider queries inv olving a . W e will pro ve the desired result using induction. Let Q b e a set of queries of the form ( x, a, y ) for x ∈ X and y ∈ N where x ≻ y a . F or an y X , N , Q such that | X | = | N | , define f ( X , N , Q ) as the minimum num b er of queries in this adversarial setting necessary to determine whether or not ev ery element in X is ranked last in exactly one ranking in N assuming that we start by doing the queries in Q . Base case: If | X | = | N | = 1 then X and N are b oth singletons (i.e. X = { x } and N = { y } ). If | Q | ≥ 1, then clearly f ( X , N , Q ) ≥ | Q | ≥ 1. If Q = ∅ , then w e then need one query of ( x, a, y ) to determine whether or not x is ranked last b y y . Therefore, for any X, N such that | X | = | N | = 1 and any Q , w e hav e that f ( X , N , Q ) ≥ 1 = | N | ( | N | +1) 2 . Inductive Hyp othesis: Assume that f ( X , N , Q ) ≥ | N | ( | N | +1) 2 for all X , N , Q such that | X | = | N | < n . Consider any X , N , Q such that | X | = | N | = n . Case 1: There exists a set X 1 ⊂ X and Y 1 ⊂ N suc h that | X 1 | = | Y 1 | < n and suc h that the only p ossible wa y to assign every alternativ e in X to b e last in some ranking in N is to assign every alternativ e in X 1 to b e last in some ranking in Y 1 . Define Y 2 = N \ Y 1 and X 2 = X \ X 1 . Let Q 1 ⊂ Q b e the set of all queries in Q in volving alternatives in X 1 and voters in Y 1 and let Q 2 ⊂ Q b e the set of all queries in Q in volving alternatives in X 2 and voters in Y 2 . W e will show that f ( X, Y , Q ) ≥ f ( X 1 , Y 1 , Q 1 ) + f ( X 2 , Y 2 , Q 2 ) + | X 1 | · ( n − | X 1 | ) . (4) T o see this result, note that since X 1 alternativ es must be ranked last in some ranking in Y 1 and alternativ es in X 2 m ust b e ranked last in some ranking in Y 2 , from now on the play er only needs to ask queries in volving alternativ es in X 1 and voters in Y 1 or ask queries in volving alternativ es in X 2 and voters in Y 2 . This explains the first tw o recursive terms in the ab o ve equation. T o show the last additive term, we m ust show that the n umber of queries in Q \ Q 1 \ Q 2 ( or equiv alen tly the num b er of queries in volving alternativ es in X 1 and voters in Y 2 or inv olving alternatives in X 2 and voters in Y 1 ) is at least | X 1 | · ( n − | X 1 | ). This is b ecause in order for suc h an X 1 and Y a to exist, we m ust b e in one of the follo wing tw o situations: 27 • Ev ery alternative x 1 ∈ X 1 has b een compared to a in ev ery ranking y 2 ∈ Y 2 and x 1 ≻ y 2 a • Ev ery alternative x 2 ∈ X 2 has b een compared to a in ev ery ranking y 1 ∈ Y 1 and x 2 ≻ y 1 a Option 1 ab ov e requires | X 1 || Y 2 | comparisons in Q \ Q 1 \ Q 2 and option 2 requires | X 2 || Y 1 | comparisons in Q \ Q 1 \ Q 2 . In b oth cases, we must ha ve that | Q \ Q 1 \ Q 2 | ≥ | X 1 | · ( n − | X 1 | ) . Therefore, we hav e shown Equation ( 4 ). Using the inductive h yp othesis, Equation ( 4 ) implies that f ( X, N , Q ) ≥ | X 1 | ( | X 1 | + 1) 2 + | X 2 | ( | X 2 | + 1) 2 + | X 1 | ( n − | X 1 | ) = | X 1 | ( | X 1 | + 1) 2 + | X 2 | ( | X 2 | + 1) 2 + | X 1 | | X 2 | ( | X 2 | = n − | X 1 | ) = | X 1 | 2 + | X 1 | + | X 2 | 2 + | X 2 | + 2 | X 1 || X 2 | 2 = ( | X 1 | + | X 2 | ) 2 + ( | X 1 | + | X 2 | ) 2 = | N | 2 + | N | 2 = | N | ( | N | + 1) 2 . Case 2: If we are not in case 1, then for any query of the form q = ( x, a, y ), supp ose that the adv ersary resp onds that x ≻ y a . In this case, we hav e that (for Q ′ = Q + { q } ) f ( X, Y , Q ) = f ( X , Y , Q ′ ) . There are a finite num b er of p otential queries, so ev en tually w e will reach some Q ′ where Q ⊆ Q ′ and such that f ( X , Y , Q ) = f ( X , Y , Q ′ ) and such that X , Y , Q ′ falls in case 1. W e already show ed that in Case 1 we must hav e that f ( X, Y , Q ′ ) ≥ n ( n +1) 2 , so we can conclude that f ( X, Y , Q ) = f ( X , Y , Q ′ ) ≥ n ( n + 1) 2 . In order to sho w that the ab ov e adversary is v alid, we must main tain that at any p oin t given the query feedback from the adversary , a could either never ranked last or a could b e ranked last exactly once. Because the adversary alw ays resp onds that x ≻ y a for all queries, at any p oin t it is still p ossible that a could b e ranked last by every v oter. Therefore, we m ust sho w that for this adv ersary , we also could ha ve that a is not ranked last b y one v oter. This will follo w from the follo wing lemma. This lemma implies that an y time one query resp onse from the adv ersary would result in a query set Q for whic h a m ust b e rank ed last b y ev ery voter in N , w e m ust b e in the setting of case 1. This implies that the adversary never needs to answer a query in suc h a wa y that forces a to b e ranked last by every v oter until at least n ( n + 1) / 2 queries ha ve already been ask ed. Lemma B.2. F or a given ( X , N , Q ) , supp ose that ther e exists a matching of alternatives in X to voters in N such that every alternative in X c ould b e r anke d last by exactly one voter in N given the r esults of the queries in Q . F urther, assume that ther e exists a query ( a, x, y ) such that if x ≻ y a , then this is no longer the c ase. Then ther e must exist a set X 1 ⊂ X and Y 1 ⊂ Y such that | X 1 | = | Y 1 | < n and such that the only p ossible way to assign every alternative in X to b e last in some r anking in N is to assign every alternative in X 1 to b e last in some r anking in Y 1 . 28 Pr o of. Because there exists a matching of alternatives in X to v oters in N , c ho ose one suc h mapping and call it M : X → N . Create the follo wing directed graph with v ertices corresp onding to X . Add a directed edge from x 1 ∈ X to x 2 ∈ X if and only if the alternativ e x 1 could b e ranked last b y the v oter M ( x 2 ). If there exists an ( x, y ) as assumed in the lemma, then there cannot b e a directed cycle containing the vertex x . This is b ecause if there is a directed cycle C containing x , then there still exists a v alid matc hing M ′ that satisfies x ≻ y a , which violates the lemma assumption. T o construct M ′ , we could simply m odify M b y matc hing ever v ertex b in the cycle to M ( C ( b )). No w w e show that the lack of cycles con taining x implies that there exists some subset of v ertices X 1 ⊂ X such that there are no edges from X \ X 1 to X 1 and X 1 ⊂ X . The simplest wa y to do this is to reduce the graph into strongly connected comp onents. Because there is no cycle con taining x , x m ust b e alone in its component. The strongly connected comp onen t graph is a D AG so it m ust ha ve a source, which is a comp onent with no incoming edges. F urthermore, b ecause x is alone in its comp onen t there are at least t wo components. Therefore, taking X 1 to b e the source component giv es that there are no edges from X \ X 1 to X 1 . T aking Y 1 = M ( X 1 ) giv es that X 1 and Y 1 satisfy the desired prop erty that the only p ossible w ay to assign every alternative in X to b e last in some ranking in N is to assign ev ery alternativ e in X 1 to Y 1 , so we are done. C Deferred Pro ofs for Computing ϵ -PV C and Critical Epsilons C.1 Computing the ϵ − PV C and Critical Epsilons In this section, w e first discuss computing the ϵ -PV C efficiently when we hav e access to full infor- mation ab out v oters and alternatives when M is finite. Iano vski and Kondratev ( 2023 ) show ed that for the original definition of PVC, the problem of finding all statements in the PVC can b e reduced to a biclique problem, for whic h a p olynomial time algorithm is known. W e adapt the pro of to show that a similar reasoning applies to ϵ -PV C. Fix an alternative a ∈ M . As w e will use a graph reduction, w e first present the definition of a blo cking gr aph . Definition C.1 (Blocking graph) . [ Ianovski and Kondratev ( 2023 )] Given an election instance ( N , M , ≻ ) and an alternativ e a ∈ M . The blo cking gr aph of a is a bipartite graph where there are nm left vertices, where eac h vertex can be iden tified as one of the m copies of the n v oters, and there are n ( m − 1) righ t v ertices, where eac h vertex can b e identified as one of the n copies of the m − 1 alternativ es of M \ { a } . An edge exists from a left v ertex to a right vertex if and only if the left vertex corresp onds to a voter i ∈ N and the righ t vertex corresp onds to an alternative c ∈ M \ { a } suc h that i prefers c to a . W e now presen t t wo statements and sho w that they are equiv alent: Condition C.2 (Blo cking Set) . There exists a coalition T ⊆ N and a blo c king set S ⊆ M such that | T | /n > 1 − | S | /m + ϵ and every voter in T prefers ev ery alternativ e in S to a . Condition C.3 (Blo cking Graph) . The blo cking graph of a has a biclique with mk left vertices and nb right v ertices such that mk + nb > (1 + ϵ ) nm . T o bridge these tw o statements, we use | T | = k and | S | = b . By showing that Condition C.2 is equiv alen t to Condition C.3 , or in words, that the existence of the blo cking set is equiv alent to 29 the existence of a sufficiently large biclique in the blo cking graph, we can use a kno wn p olynomial time algorithm for Condition C.3 to chec k Condition C.2 , whic h in turn determines membership in ϵ − PV C. Prop osition C.4. Condition C.2 is e quivalent to Condition C.3 . Pr o of. (Condition C.2 = ⇒ Condition C.3 ) Note that b y m ultiplying the inequalit y in Condition C.3 b y nm , we get mk + nb > (1 + ϵ ) nm . By construction of the blo cking graph, the mk v ertices on the left that corresp ond to the m copies each of the k voters in T are all connected to the nb v ertices on the right that corresp ond to the n copies eac h of the b alternativ es in S . (Condition C.3 ⇐ = Condition C.2 ) T ake one left v ertex x in the biclique. Say x corresp onds to a cop y of voter i . Enlarge the biclique by including all left vertices that corresp ond to copies of v oter i . This is p ossible b ecause these v ertices ha ve the same set of neigh b ours b y construction of the blo cking graph. Do the same for every left v ertex in the biclique. Similarly , do a corresp onding enlargemen t for the right vertices in the biclique. Now, since there are at least mk left v ertices, of which we included all m copies of their corresponding voters, we m ust ha ve at least k v oters included in the biclique. Similarly , as we hav e at least nb righ t vertices, of whic h we included all n copies of their corresp onding alternativ es, we m ust ha ve at least b alternatives included in the biclique. Let these k v oters b e T and these b alternatives b e S . Then note that mk + nb > (1 + ϵ ) nm = ⇒ m | T | + b | S | > (1 + ϵ ) nm = ⇒ | T | /n > 1 − | S | /m + ϵ . By construction of the blo c king graph, these voters in T all prefers every alternative in S to a . Prior work has established that Condition C.3 can b e c heck ed in p olynomial time: Prop osition C.5. [ Gar ey and Johnson ( 1990 ), p g. 196, GT24] L et G b e a bip artite gr aph and k an inte ger. We c an, in p olynomial time, determine whether ther e exists a biclique K ⊆ G with x left vertic es and y right vertic es such that x + y = k . W e can thus determine whether a given alternative is in the ϵ − PV C by using the p olynomial time algorithm in Theorem C.5 and iterating k from (1 + ϵ ) nm to 2 mn − n , giving us Theorem C.6 . Corollary C.6. The ϵ − PVC c an b e c ompute d in p olynomial time. C.2 A F aster Algorithm through a Corresp ondence with Min-Cut With pro of of existence of a p olynomial time algorithm out of the wa y , here we pro ceed to present the pro of and runtime analysis for the faster algorithm that is used in our implementation (Algorithm 1 ). Man y ideas for this algorithm, including the max-flo w correspondence, are from Iano vski and Kondratev ( 2023 )’s O ( m max( n 3 , m 3 )) algorithm for computing the PVC. The core of the idea is that instead of copies of the same v ertex in a blo cking graph, we turn these copies into weigh ted edges in a flo w graph where the w eight is the num b er of copies. C.2.1 Correctness Pr o of. Consider the flo w graph after applying the min cut. The min cut could not cut the edges b et ween the voter no des and the alternative nodes as the edge w eights are infinite, so the only edges p ossibly cut are those b et ween the source no de and the voter no des, and those b etw een the alternativ e no des and the sink no de. Note that whenever an edge is cut, that no de contributes to the min-cut, while the remaining no des after the min-cut forms a biclique of the blo cking graph, whic h is in fact maximum. T o b e precise, all v oter no des and alternativ e no des are partitioned in to either contributing to the min-cut or the biclique. When an edge b etw een the source and a voter 30 no de is cut, that v oter no de contributes m to the min-cut. When an edge b etw een the sink and an alternativ e no de is cut, that alternative no de contributes n to the min-cut. The remaining no des after the min-cut will form a biclique in the corresp onding blo cking graph. T o see this, note that since the remaining voter no des are still connected to the source, and the remaining alternative no des are still connected to the sink, there must not b e an y edges left betw een any remaining v oter no des and alternative no des. Otherwise, a single edge b et ween a v oter no de and an alternative no de, whic h has infinite edge w eight, could transmit p ositive flo w. 6 Since no edges exist b etw een the remaining voter no des and alternativ e no des, by construction, all of these voters must appro ve all of these alternatives ov er the given alternative, which is precisely the blo c king set, or equiv alently , the maximum biclique in the blo c king graph. No w, the size of this biclique in the blo c king graph in volv es the n umber of copies, which is precisely the weigh ts of the edges leftov er from the min-cut. Since the min-cut minimizes the w eights cut, the constructed biclique is the biggest p ossible. T o b e precise, Q + K = 2 mn − n , where Q is the size of the biclique, K is the min-cut, and 2 mn − n is the total weigh t of the flow graph (excluding infinities), or equiv alen tly , the total num ber of vertices in the blo cking graph. With Q obtained, the correspondence in Theorem C.4 where Q = mk + nb allo ws us to chec k ϵ − PVC membership with Q ≤ (1 + ϵ ) nm as desired. C.2.2 Run time The runtime of the algorithm is c hiefly that of the construction of the flow graph, and finding the min-cut. The flow graph construction takes O ( nm ) time, since the flo w graph could b e fully connected. F or example, consider the case where the giv en alternative is ranked first by all v oters. The min-cut algorithm dep ends on implementation. By the max-flo w min-cut theorem, we could use standard max-flow algorithms. Dinic’s algorithm ( Dinitz , 1970 ) requires O ( | V | 2 | E | ), whic h in our case where | V | = O ( m + n ) and | E | = O ( mn ), the algorithm runs in O ( mn ( m + n ) 2 ). D Additional Exp erimen t Details W e present additional details for the exp eriments describ ed in Section 7 . D.1 Details on T opics Belo w w e present the long list of topics and their degree of polarization. D.1.1 Long List of T opics • Ho w should we increase the general public’s trust in US elections? • What are the b est p olicies to preven t littering in public spaces? • What are your thoughts on the wa y universit y campus administrators should approach the issue of Israel/Gaza demonstrations? • What should guide laws concerning ab ortion? 6 The careful reader will find that the infinite edge will not transmit flow if all voter no des are cut from the source, or all alternative no des are cut from the sink. Indeed this is the baseline case, which is to cut all alternative no des from the sink for a cut of ( m − 1) n (which is less than cutting v oter no des from the source for mn ), and will yield Q = mn = ⇒ Q ≤ (1 + ϵ ) nm ∀ ϵ ∈ [0 , 1] (here Q loses its meaning as the maximum biclique, but the algorithm is still v alid). By finding smaller cuts than mn , the algorithm will obtain a bigger corresp onding blo cking set, and raise ϵ . 31 • What balance should exist b et ween gun safet y la ws and Second Amendment rights? • What role should the go vernmen t pla y in ensuring univ ersal access to healthcare? • What balance should b e struck b etw een environmen tal protection and economic growth in climate p olicy? • What principles should guide immigration policy and the path to citizenship? • What limits, if any , should exist on free sp eech regarding hate sp eech? • What resp onsibilities should tech companies ha ve when collecting and monetizing user data? • What role should artificial in telligence pla y in so ciet y , and ho w should its risks b e gov erned? • What reforms, if any , should replace or modify the Electoral College? • What strategies should guide p olicing to address bias and use-of-force concerns while main- taining public safety? The Likert scores for each topic used to calculate degree of p olarization can b e found in Figure 4 . 32 1 2 3 4 5 6 7 8 9 10 0.0 0.1 0.2 0.3 0.4 0.5 Frequency = 8 . 4 , = 0 . 9 Public T rust 1 2 3 4 5 6 7 8 9 10 0.0 0.1 0.2 0.3 0.4 = 7 . 9 , = 1 . 1 Littering 1 2 3 4 5 6 7 8 9 10 0.0 0.1 0.2 0.3 0.4 Frequency = 7 . 9 , = 1 . 7 Campus Speech 1 2 3 4 5 6 7 8 9 10 0.0 0.1 0.2 0.3 0.4 = 8 . 0 , = 1 . 2 Environment 1 2 3 4 5 6 7 8 9 10 0.0 0.1 0.2 0.3 0.4 0.5 Frequency = 7 . 9 , = 0 . 9 Gun Safety 1 2 3 4 5 6 7 8 9 10 0.0 0.1 0.2 0.3 0.4 0.5 = 7 . 7 , = 1 . 3 F ree Speech 1 2 3 4 5 6 7 8 9 10 0.0 0.1 0.2 0.3 0.4 Frequency = 7 . 9 , = 1 . 2 Immigration 1 2 3 4 5 6 7 8 9 10 0.00 0.05 0.10 0.15 0.20 = 6 . 3 , = 2 . 3 Electoral College 1 2 3 4 5 6 7 8 9 10 0.0 0.1 0.2 0.3 Frequency = 7 . 9 , = 1 . 4 T ech Responsibility 1 2 3 4 5 6 7 8 9 10 0.0 0.1 0.2 0.3 0.4 = 7 . 9 , = 1 . 1 AI in Society 1 2 3 4 5 6 7 8 9 10 0.00 0.05 0.10 0.15 0.20 0.25 Frequency = 7 . 2 , = 1 . 5 Healthcare Access 1 2 3 4 5 6 7 8 9 10 0.00 0.05 0.10 0.15 0.20 = 6 . 2 , = 2 . 5 Abortion 1 2 3 4 5 6 7 8 9 10 Likert Score 0.0 0.1 0.2 0.3 0.4 0.5 Frequency = 8 . 9 , = 0 . 7 P olicing Distribution of Likert Agreement Scores by T opic Figure 4: Lik ert scores of 100 voters on 100 generated statements. Higher Likert scores indicate higher agreemen t. The most p olarizing topics hav e av erage Lik ert scores close to 5 and a wide spread. The top 3 topics b y p olarization are ab ortion, Electoral College, and healthcare. The b ottom 3 p olarizing topics are en vironment, p olicing, and public trust in elections. 33 D.2 Example Persona In this section w e present an example persona that we use as a v oter and for generating statements. Example Persona age: 72 sex: Female race: White alone ancestry: Irish household language: English only education: Bachelor’s degree employment status: Civilian employed, at work class of worker: Employee of a private for-profit company or business, or of an individual, for wages, salary, or commissions industry category: MED-Nursing Care Facilities (Skilled Nursing Facilities) occupation category: MED-Registered Nurses detailed job description: Provides patient care in a nursing home income: 135500.0 marital status: Widowed household type: Cohabiting couple household, no children of the householder less than 18 family presence and age: No family under 18 place of birth: Missouri/MO citizenship: Born in the United States veteran status: Non-Veteran disability: None health insurance: With health insurance coverage big five scores: Openness: Average, Conscientiousness: Average, Extraversion: Average, Agreeableness: Extremely High, Neuroticism: Low defining quirks: Collects vintage medical equipment mannerisms: Speaks with a soft, soothing voice personal time: Spends free time gardening or reading lifestyle: Active and community-oriented ideology: Conservative political views: Republican religion: Catholic D.3 Alternativ e Metho ds to Generate Alternativ es D.3.1 Description of Metho ds to Generate Alternatives In addition to the exp eriment set-up presen ted in the b o dy (listed b elow as P ersona Only), w e also explored three different metho ds of generating statemen ts. • Blind : Giv en only the topic, the LLM is queried using v erbalized sampling ( Zhang et al. , 2025 ) to generate div erse statemen ts. • P ersona Only : Given the topic and a p ersona to conditioned on, the LLM is queried to pro duce a resp onse. This is used for the exp erimen ts presented in the b o dy . • Deliberation Round Only : Within a rep, given 100 statemen ts generated using Persona, the LLM is queried using v erbalized sampling ( Zhang et al. , 2025 ) to generate diverse state- men ts taking in to accoun t the 100 statemen ts. This is to simulate a ”deliberation round” 34 where a user sees statements written b y others and is informed by their stances to write a new statement. • P ersona+Delib eration Round : Within a rep, first generate 100 statements using Per- sonas. Then conditioning on eac h p ersona, the LLM is queried to pro duce a single statemen t that also takes in to account the other 99 statemen ts. In Figures 5 and 6 w e sho w the CDFs for the same exp erimen t as in the bo dy but using differen t metho ds of generating alternativ es. Using the P ersona metho d giv es a more in teresting distribution of alternatives and has the added b enefits of b eing relativ ely simple and motiv ated by the theory in Section 6 . 0.0 0.1 0.2 0.3 0.4 0.5 Epsilon 0.5 0.6 0.7 0.8 0.9 1.0 Cumulative P r obability Alt1: Persona Only VB C Bor da Schulze IR V Plurality R andom 0.0 0.1 0.2 0.3 0.4 0.5 Epsilon 0.5 0.6 0.7 0.8 0.9 1.0 Alt2: Persona + Deliberation Round VB C Bor da Schulze IR V Plurality R andom 0.0 0.1 0.2 0.3 0.4 0.5 Epsilon 0.5 0.6 0.7 0.8 0.9 1.0 Alt3: Deliberation Round Only VB C Bor da Schulze IR V Plurality R andom 0.0 0.1 0.2 0.3 0.4 0.5 Epsilon 0.5 0.6 0.7 0.8 0.9 1.0 Alt4: Blind VB C Bor da Schulze IR V Plurality R andom Abortion: T raditional Methods by Alternative Distribution (Uniform V oters, Zoomed) (a) Abortion 0.0 0.1 0.2 0.3 0.4 0.5 Epsilon 0.5 0.6 0.7 0.8 0.9 1.0 Cumulative P r obability Alt1: Persona Only VB C Bor da Schulze IR V Plurality R andom 0.0 0.1 0.2 0.3 0.4 0.5 Epsilon 0.5 0.6 0.7 0.8 0.9 1.0 Alt2: Persona + Deliberation Round VB C Bor da Schulze IR V Plurality R andom 0.0 0.1 0.2 0.3 0.4 0.5 Epsilon 0.5 0.6 0.7 0.8 0.9 1.0 Alt3: Deliberation Round Only VB C Bor da Schulze IR V Plurality R andom 0.0 0.1 0.2 0.3 0.4 0.5 Epsilon 0.5 0.6 0.7 0.8 0.9 1.0 Alt4: Blind VB C Bor da Schulze IR V Plurality R andom Electoral College: T raditional Methods by Alternative Distribution (Uniform V oters, Zoomed) (b) Electoral College 0.0 0.1 0.2 0.3 0.4 0.5 Epsilon 0.5 0.6 0.7 0.8 0.9 1.0 Cumulative P r obability Alt1: Persona Only VB C Bor da Schulze IR V Plurality R andom 0.0 0.1 0.2 0.3 0.4 0.5 Epsilon 0.5 0.6 0.7 0.8 0.9 1.0 Alt2: Persona + Deliberation Round VB C Bor da Schulze IR V Plurality R andom 0.0 0.1 0.2 0.3 0.4 0.5 Epsilon 0.5 0.6 0.7 0.8 0.9 1.0 Alt3: Deliberation Round Only VB C Bor da Schulze IR V Plurality R andom 0.0 0.1 0.2 0.3 0.4 0.5 Epsilon 0.5 0.6 0.7 0.8 0.9 1.0 Alt4: Blind VB C Bor da Schulze IR V Plurality R andom Healthcare: T raditional Methods by Alternative Distribution (Uniform V oters, Zoomed) (c) Healthcare Figure 5: CDF of critical epsilons across v arious topics (top three topics b y degree of polarization). The leftmost subplot (P ersona) allo ws for clearer analysis than other alternative generation meth- o ds. 35 0.0 0.1 0.2 0.3 0.4 0.5 Epsilon 0.5 0.6 0.7 0.8 0.9 1.0 Cumulative P r obability Alt1: Persona Only VB C Bor da Schulze IR V Plurality R andom 0.0 0.1 0.2 0.3 0.4 0.5 Epsilon 0.5 0.6 0.7 0.8 0.9 1.0 Alt2: Persona + Deliberation Round VB C Bor da Schulze IR V Plurality R andom 0.0 0.1 0.2 0.3 0.4 0.5 Epsilon 0.5 0.6 0.7 0.8 0.9 1.0 Alt3: Deliberation Round Only VB C Bor da Schulze IR V Plurality R andom 0.0 0.1 0.2 0.3 0.4 0.5 Epsilon 0.5 0.6 0.7 0.8 0.9 1.0 Alt4: Blind VB C Bor da Schulze IR V Plurality R andom Environment: T raditional Methods by Alternative Distribution (Uniform V oters, Zoomed) (a) En vironment 0.0 0.1 0.2 0.3 0.4 0.5 Epsilon 0.5 0.6 0.7 0.8 0.9 1.0 Cumulative P r obability Alt1: Persona Only VB C Bor da Schulze IR V Plurality R andom 0.0 0.1 0.2 0.3 0.4 0.5 Epsilon 0.5 0.6 0.7 0.8 0.9 1.0 Alt2: Persona + Deliberation Round VB C Bor da Schulze IR V Plurality R andom 0.0 0.1 0.2 0.3 0.4 0.5 Epsilon 0.5 0.6 0.7 0.8 0.9 1.0 Alt3: Deliberation Round Only VB C Bor da Schulze IR V Plurality R andom 0.0 0.1 0.2 0.3 0.4 0.5 Epsilon 0.5 0.6 0.7 0.8 0.9 1.0 Alt4: Blind VB C Bor da Schulze IR V Plurality R andom Policing: T raditional Methods by Alternative Distribution (Uniform V oters, Zoomed) (b) P olicing 0.0 0.1 0.2 0.3 0.4 0.5 Epsilon 0.5 0.6 0.7 0.8 0.9 1.0 Cumulative P r obability Alt1: Persona Only VB C Bor da Schulze IR V Plurality R andom 0.0 0.1 0.2 0.3 0.4 0.5 Epsilon 0.5 0.6 0.7 0.8 0.9 1.0 Alt2: Persona + Deliberation Round VB C Bor da Schulze IR V Plurality R andom 0.0 0.1 0.2 0.3 0.4 0.5 Epsilon 0.5 0.6 0.7 0.8 0.9 1.0 Alt3: Deliberation Round Only VB C Bor da Schulze IR V Plurality R andom 0.0 0.1 0.2 0.3 0.4 0.5 Epsilon 0.5 0.6 0.7 0.8 0.9 1.0 Alt4: Blind VB C Bor da Schulze IR V Plurality R andom T rust in Institutions: T raditional Methods by Alternative Distribution (Uniform V oters, Zoomed) (c) Public T rust Figure 6: CDF of critical epsilons across v arious topics (bottom three topics b y degree of p olariza- tion). The leftmost subplot (P ersona) allows for clearer analysis than other alternative generation metho ds. 36 D.4 Building Preference Profiles In this section, we discuss why we selected iterative ranking as our pro cess for using an LLM to build a preference profile. D.4.1 The Problem of Preference Degeneracy Preference degeneracy o ccurs when the preference rankings pro duced by generative AI are v ery similar ev en for very different profiles. W e found that this can happ en when the AI is “ov erwhelmed” with the task complexity of ranking to o many alternatives at once, and outputs a default ranking of the alternatives (for example, in the order presented to the AI, or its reverse). D.4.2 Mitigating Preference Degeneracy There are tw o natural wa ys to mitigate preference degeneracy: 1. Increase mo del capabilities. 2. Scaffold the task easier to mak e it easier for the mo del to complete. Item 1 has the tradeoff of budget concerns. T o illustrate, order of magnitude capabilit y jumps b et ween gpt-5-nano , gpt-5-mini , and gpt-5.2 are accompanied b y similar order of magnitude price jumps. W e fix the mo del as gpt-5-mini as a compromise b et ween capabilit y and price. Another axis of increasing mo del capabilities is to increase reasoning effort (the length of the mo del’s chain-of-though t). As the num b er of tokens get higher, there is also an asso ciated cost increase. Latency also increases as more tok ens need to b e generated b efore the tokens related to the extractable ranking is pro duced. W e ran a sweep on the a v ailable options for reasoning efforts in T able 4 . There are multiple w ays to go ab out Item 2 : P airwise comparison. W e rep eatedly sho w the mo del t wo alternatives, and ask the mo del which one to pic k, until a full ranking is obtained. Ho wev er, if there are n v oters and m alternativ es, and an API call tak es k tokens, then the num b er of tokens required (which is usually dominated b y input tok ens for seeding tec hniques) is O ( mnk log m ). F or a reasonable experiment of m = 100 , n = 100 , k = 500, a single preference profile will take ab out 33 million tokens, which is ab out $ 8.25. Using this option, the full exp eriment will cost: 6 topics × 10 rep etitions × 3 voter distributions × $ 8.25/profile = $ 1,485. Direct Ranking. The other extreme is to simply give the mo del all the statements and ask it to output its ranking in one API call. This is the c heap est p ossible approach. Unfortunately , this approach frequently giv es degenerate rankings, even for the most capable mo dels currently a v ailable. T op-K/Bottom-K Ranking (Iterativ e Ranking). Given all remaining alternativ es, we ask the mo del to pick its top K statemen ts and b ottom K statements. W e then iterate for m/ 2 k rounds with the subsequent set of remaining alternativ es un til all alternativ es ha ven b een c hosen. 37 Scoring. Given a set of alternatives, we ask the mo del to give a sc ore to each alternative. The b enefit to this approach is that compared to pro ducing the ranking, the model is not heavily constrained b y other alternatives it has pro cessed or will pro cess when pro cessing a new alternative. In other w ords, the mo del could ignore the scores it gav e to an y previous alternatives and fo cus on giving a score to the curren t alternativ e. When the scoring is done, a ranking is induced, and any duplicate scores could b e randomly tie-broken. Another approac h is to ask the mo del not to give duplicate scores. Because pairwise comparisons were too exp ensiv e and direct ranking produced degenerate rank- ings, w e fo cus on the remaining tw o metho ds and rep ort results in T able 4 . When we receiv e a ranking, w e screen it for inv alid rankings (e.g. hallucinated statemen t IDs, or duplicate statement IDs, etc). If it is inv alid, w e retry the query , up to 20 times. T able 4: Degeneracy Mitigation Exp eriment Results Mitigation Reasoning Unique Pres. Order API Avg Time Effort Rankings Corr. Calls /Call T op-K/Bottom-K minimal 79 / 100 0 . 029 1307 3 . 3s T op-K/Bottom-K lo w 98 / 100 0 . 043 567 11 . 1s T op-K/Bottom-K medium 100 / 100 0 . 033 ∼ 500 ∼ 30s Scoring minimal 99 / 100 − 0 . 126 178 8 . 9s Scoring lo w 100 / 100 − 0 . 987 100 16 . 0s Scoring medium 98 / 100 − 0 . 952 ∼ 100 ∼ 30s Note: “Pres. Order Corr.” stands for presen tation order correlations. V alues near ± 1 indicate degenerate rankings. As shown in T able 4 , the scoring method frequen tly resulted in degenerate rankings as mea- sured by correlation with presentation order. T o minimize preference degeneracy , we use the top- K/b ottom-K metho d for all of our exp erimen ts. W e found that the low reasoning effort pro duce a high num b er of unique rankings with minimal retries (67 compared to minimal’s 807) and hav e b etter latency (11.1s vs medium’s 30s). The rankings pro duced with low reasoning also has a Sp ear- man’s correlation of 0.802 with that of medium reasoning. W e th us generate the preference profiles for our full exp eriment using the top-K/bottom-K approach (iterative ranking) using gpt-5-mini on low reasoning effort. D.5 Using different metho ds to find common ground in real election instances W e v alidate the pattern in Equation ( 2 ) on real-w orld election instances from Preflib ( Mattei and W alsh , 2013 ). W e plot our results in Figure 7 . D.6 Inserting a New Statement to a Preference Profile In this section, we discuss differen t metho ds for inserting a single alternative into an already con- structed ranking of 100 existing alternativ es, which is a necessary step for ev aluating generative v oting rules. • Insert into 100: we give the mo del all 100 statemen ts and ask the mo del to output the p osition for the new statemen t. 38 VETO B ORD A SCHULZE IR V PL UR ALITY V oting R ule 0.00 0.01 0.02 0.03 0.04 0.05 Mean Critical Epsilon R andom baseline: 0.1159 Electoral R efor m Society (ERS): Critical Epsilon by V oting R ule (a) Critical epsilons for Electoral Reform So ciet y ( Tideman and Plassmann , 2012 , 2014 ; Plassmann and Tideman , 2014 ) VETO B ORD A SCHULZE IR V PL UR ALITY V oting R ule 0.000 0.001 0.002 0.003 0.004 0.005 0.006 Mean Critical Epsilon R andom baseline: 0.2052 P oland L ocal Elections: Critical Epsilon by V oting R ule (b) Critical epsilons for P oland Lo cal Elections ( Bo ehmer et al. , 2022 ) VETO B ORD A SCHULZE IR V PL UR ALITY V oting R ule 0.000 0.002 0.004 0.006 0.008 0.010 0.012 0.014 0.016 Mean Critical Epsilon R andom baseline: 0.1632 Haber mas: Critical Epsilon by V oting R ule (c) Critical epsilons for Hab ermas ( T essler et al. , 2024 ) VETO B ORD A SCHULZE IR V PL UR ALITY V oting R ule 0.000 0.005 0.010 0.015 0.020 0.025 Mean Critical Epsilon R andom baseline: 0.1629 Eur ovision: Critical Epsilon by V oting R ule (d) Critical epsilons for Euro vision ( B¨ ohmer , 2023 ) Figure 7: Comparison of critical epsilons across voting rules on v arious real-world datasets from PrefLib. Standard errors depicted. • Ch unk ed insertion: w e split the 100 statements in to 5 con tiguous c hunks. W e ask the mo del to output the p osition it will insert the new statement in to for each ch unk. W e then tally the positions and according to its c hunk assign the appropriate ranking. F or example, if the new statemen t gets p osition 0, 3, 15, 8, 9 in the 5 ch unks, then the insertion p osition is 0 + 3 + 15 + 8 + 9 = 35. • P airwise comparison: we ask the mo del to compare the new statement with ev ery other statemen t in separate API calls to obtain the insertion p osition. • Iterativ e ranking: we rerun the algorithm for building preference profiles as in Section 7.1 and extract the resulting p osition of the new statemen t as its insertion p osition. In Figure 8 , w e ev aluate the p erformance of these insertion algorithms by randomly selecting a statemen t from a preference profile to b e (re-)inserted. W e did this for 10 randomly sampled statemen ts and 100 v oters for 1,000 insertion tests for each metho d. W e found that the iterativ e ranking pro vided the b est fit while still b eing cost-efficien t, and this is the method used in our main exp erimen ts. 39 (a) Insert 100 Metho d (b) Ch unked Metho d (c) P airwise Metho d (d) Iterativ e Ranking Method Figure 8: Binned scatter plots comparing v arious statement insertion metho ds by plotting recon- struction p osition v ersus original position. Error units are in the ranks, e.g. an error of -20 means that the metho d ranks the new statemen t on av erage 20 p ositions b elo w its original. D.7 Detailed Results for Critical Epsilons of V oting Rules In T ables 5 and 6 and Fig. 9 , we present additional detailed statistics of the critical epsilons achiev ed b y v arious traditional v oting rules. T able 5: P99 of critical epsilons for v arious voting rules across v arious topics Metho d Ab ortion Electoral College Healthcare Policing En vironmen t T rust in Institutions VBC 0.0161 0.0000 0.0061 0.0061 0.0000 0.0230 Borda 0.1432 0.0200 0.0100 0.0366 0.0230 0.0265 Sc hulze 0.1432 0.0361 0.0300 0.0522 0.0300 0.0265 IR V 0.2327 0.1244 0.0500 0.1427 0.0925 0.0265 Random 0.3101 0.1700 0.1200 0.1401 0.1801 0.0801 Pluralit y 0.3344 0.2088 0.1720 0.1583 0.1030 0.0990 40 T able 6: P ercentage of critical epsilons that are less than 0.01 for v arious voting rules across v arious topics Metho d Abortion Electoral College Healthcare P olicing Environmen t T rust in Institutions VBC 95.0000 100.0000 97.5000 97.5000 100.0000 91.6667 Borda 87.5000 85.0000 95.0000 97.5000 91.6667 83.3333 Sc hulze 75.0000 77.5000 85.0000 87.5000 80.5556 77.7778 IR V 65.0000 42.5000 75.0000 75.0000 69.4444 66.6667 Random 58.1000 71.4000 72.4000 71.7000 72.6667 73.7778 Pluralit y 45.0000 22.5000 57.5000 62.5000 58.3333 58.3333 0.00 0.05 0.10 0.15 0.20 0.25 0.30 0.35 0.40 Epsilon 0.0 0.2 0.4 0.6 0.8 1.0 Cumulative P r obability Policing VB C Bor da Schulze IR V Plurality R andom 0.00 0.05 0.10 0.15 0.20 0.25 0.30 0.35 0.40 Epsilon 0.0 0.2 0.4 0.6 0.8 1.0 Environment VB C Bor da Schulze IR V Plurality R andom 0.00 0.05 0.10 0.15 0.20 0.25 0.30 0.35 0.40 Epsilon 0.0 0.2 0.4 0.6 0.8 1.0 T rust in Institutions VB C Bor da Schulze IR V Plurality R andom Critical Epsilons of V oting Methods for T opics: Policing, Environment, T rust in Institutions Figure 9: CDF of critical epsilons for least contro v ersial topics for v arious voting rules. D.8 LLM-P o wered V oting Rules as a Selector In addition to testing LLM methods that generate their own statement, we also tested methods that use LLMs to select an existing statemen t. W e tested six different v ariants that v ary in how m uch information is given to the mo del. • GPT-Select: the model is giv en the 20 sampled statemen ts. • GPT-Select+Rankings: the mo del is given the 20 sampled statemen ts, and the 20 × 20 pref- erence profile. • GPT-Select+P ersonas: the mo del is given the 20 sampled statements and the p ersonas of the 20 voters. • GPT-F ull: the mo del is giv en the 100 statements. • GPT-F ull+Rankings: the mo del is given the 100 statements, and the 20 × 100 preference profile. • GPT-F ull+Personas: the mo del is giv en the 100 statements and the p ersonas of the 20 v oters. W e presen t the results in T ables 7 to 9 . VBC still outp erforms the LLM metho ds. In terestingly , that providing more information, lik e voter p ersonas or the rankings, slightly degrades performance. 41 T able 7: Mean critical epsilons for VBC, v oting rules with GPT as a selector and a random baseline across v arious topics. Smallest epsilons are b olded. Metho d Ab ortion Electoral College Healthcare P olicing Environmen t T rust in Institutions VBC 0.0008 0.0000 0.0003 0.0003 0.0000 0.0014 GPT-Select 0.0038 0.0048 0.0048 0.0108 0.0103 0.0094 GPT-Sel+Rank 0.0143 0.0365 0.0163 0.0085 0.0075 0.0056 GPT-Sel+P ers 0.0125 0.0028 0.0095 0.0195 0.0100 0.0067 GPT-F ull 0.0013 0.0050 0.0068 0.0055 0.0014 0.0053 GPT-F ull+Rank 0.0593 0.0425 0.0055 0.0115 0.0114 0.0075 GPT-F ull+Pers 0.0050 0.0023 0.0083 0.0143 0.0086 0.0039 Random 0.0609 0.0108 0.0082 0.0103 0.0108 0.0072 T able 8: P99 critical epsilons for for VBC, v oting rules with GPT as a selector and a random baseline across v arious topics. Smallest epsilon for each topic is b olded. Metho d Ab ortion Electoral College Healthcare Policing Environmen t T rust in Institutions VBC 0.0161 0.0000 0.0061 0.0061 0.0000 0.0230 GPT-Select 0.0505 0.0422 0.0361 0.1166 0.1190 0.0400 GPT-Sel+Rank 0.1859 0.2088 0.2149 0.0722 0.0820 0.0265 GPT-Sel+P ers 0.1954 0.0422 0.0900 0.0900 0.0865 0.0365 GPT-F ull 0.0100 0.0322 0.0666 0.0805 0.0100 0.0400 GPT-F ull+Rank 0.3461 0.2205 0.0461 0.0922 0.0925 0.0465 GPT-F ull+Pers 0.1032 0.0261 0.1254 0.1000 0.1700 0.0465 Random Insertion 0.3161 0.0861 0.0622 0.1449 0.0300 0.0600 Random 0.3101 0.1700 0.1200 0.1401 0.1801 0.0801 T able 9: P ercentage of critical epsilons that are less than 0.01 for VBC, v oting rules with GPT as a selector and a random baseline across v arious topics. Largest p ercen tages for each topic is bolded. Metho d Abortion Electoral College Healthcare Policing Environmen t T rust in Institutions VBC 0.950 1.000 0.975 0.975 1.000 0.917 GPT-Select 0.850 0.775 0.750 0.725 0.750 0.667 GPT-Sel+Rank 0.700 0.450 0.700 0.825 0.694 0.639 GPT-Sel+P ers 0.900 0.900 0.775 0.550 0.778 0.722 GPT-F ull 0.875 0.700 0.675 0.875 0.861 0.778 GPT-F ull+Rank 0.500 0.350 0.775 0.700 0.611 0.583 GPT-F ull+Pers 0.900 0.875 0.750 0.650 0.889 0.889 Random Insertion 0.500 0.650 0.600 0.725 0.550 0.600 Random 0.581 0.714 0.724 0.717 0.727 0.738 D.9 Details on Clustered V oters D.9.1 Keyw ords Used for Classification T o cluster voters, w e applied case-insensitiv e keyw ord matching on the idealogy field in the p er- sonas using the follo wing sets of keyw ords. Conserv ative/T raditional. • conserv ative 42 • traditional • traditionalist • libertarian • libertarianism • fiscal conserv atism • social conserv atism • c hristian v alues • family v alues • small gov ernmen t Progressiv e/Lib eral. • progressiv e • liberal • social lib eral • social justice • feminist • feminism • egalitarian • en vironmen talism • en vironmen talist • en vironmen tal conserv ation • en vironmen tal protection • social equalit y • w ork ers’ righ ts • social w elfare • h umanism • h umanistic • h umanitarian D.9.2 More Results on Conserv ativ e V oters W e rep ort additional statistics in T ables 10 and 11 . D.9.3 Results on Progressiv e V oters W e presen t the critical epsilons of generativ e v oting rules on progressiv e v oters in T ables 12 to 14 . 43 T able 10: P99 critical epsilons for for VBC, generativ e voting rules and random baselines across v arious topics for conserv ativ e voters. Smallest epsilon for eac h topic is b olded. Metho d Abortion Electoral College Healthcare Policing Environmen t T rust in Institutions VBC 0.0161 0.0061 0.0061 0.0000 0.0061 0.0000 GPT-Blind 0.5005 0.0900 0.0461 0.1022 0.3588 0.1161 GPT-Syn thesize 0.3300 0.1832 0.0944 0.2298 0.1166 0.3461 GPT-Syn th+Rank. 0.3544 0.1261 0.1144 0.1022 0.2722 0.0300 GPT-Syn th.+Pers. 0.2700 0.0461 0.0322 0.0200 0.0361 0.0100 Random Insertion 0.3261 0.4805 0.3683 0.3600 0.1000 0.2286 Random 0.4601 0.5100 0.4200 0.4201 0.3301 0.3901 T able 11: Percen tage of critical epsilons that are less than 0.01 for VBC, generative voting rules and random baselines across v arious topics for conserv ative voters. Largest p ercentages for each topic is b olded. Metho d Abortion Electoral College Healthcare Policing Environmen t T rust in Institutions VBC 0.900 0.975 0.975 1.000 0.975 1.000 GPT-Blind 0.000 0.225 0.750 0.425 0.100 0.275 GPT-Syn thesize 0.000 0.350 0.325 0.175 0.175 0.325 GPT-Syn th+Rank. 0.025 0.400 0.575 0.425 0.500 0.675 GPT-Syn th.+Pers. 0.250 0.550 0.725 0.750 0.575 0.900 Random Insertion 0.425 0.100 0.575 0.400 0.525 0.750 Random 0.338 0.242 0.609 0.389 0.484 0.539 T able 12: Mean critical epsilons for for VBC, generativ e v oting rules and random baselines across v arious topics for progressive voters. Smallest epsilon for eac h topic is b olded. Metho d Abortion Electoral College Healthcare Policing Environmen t T rust in Institutions VBC 0.0000 0.0018 0.0000 0.0005 0.0000 0.0003 GPT-Blind 0.0185 0.0280 0.0113 0.0048 0.0035 0.0215 GPT-Syn thesize 0.0095 0.0103 0.0058 0.0135 0.0108 0.0200 GPT-Syn th+Rank. 0.0055 0.0075 0.0005 0.0025 0.0025 0.0093 GPT-Syn th.+Pers. 0.0058 0.0050 0.0013 0.0033 0.0018 0.0143 Random Insertion 0.2205 0.0130 0.0220 0.0532 0.0388 0.0120 Random 0.1751 0.0989 0.0428 0.0625 0.0382 0.0330 T able 13: P99 critical epsilons for for VBC, generativ e voting rules and random baselines across v arious topics for progressive voters. Smallest epsilon for eac h topic is b olded. Metho d Abortion Electoral College Healthcare Policing Environmen t T rust in Institutions VBC 0.0000 0.0405 0.0000 0.0122 0.0000 0.0069 GPT-Blind 0.1622 0.1805 0.0822 0.0261 0.0283 0.0922 GPT-Syn thesize 0.0844 0.0600 0.0300 0.1710 0.0927 0.1161 GPT-Syn th+Rank. 0.0200 0.0461 0.0100 0.0322 0.0161 0.0661 GPT-Syn th.+Pers. 0.0200 0.0300 0.0161 0.0300 0.0100 0.1083 Random Insertion 0.6444 0.1781 0.2544 0.3966 0.3149 0.0761 Random 0.4601 0.5100 0.4200 0.4201 0.3301 0.3901 44 T able 14: Percen tage of critical epsilons that are less than 0.01 for VBC, generative voting rules and random baselines across v arious topics for progressive voters. Largest p ercentages for eac h topic is b olded. Metho d Abortion Electoral College Healthcare Policing Environmen t T rust in Institutions VBC 1.000 0.950 1.000 0.975 1.000 0.969 GPT-Blind 0.500 0.350 0.600 0.650 0.725 0.350 GPT-Syn thesize 0.600 0.500 0.575 0.625 0.525 0.350 GPT-Syn th+Rank. 0.650 0.600 0.950 0.850 0.775 0.650 GPT-Syn th.+Pers. 0.650 0.650 0.900 0.800 0.825 0.500 Random Insertion 0.275 0.600 0.675 0.625 0.550 0.600 Random 0.338 0.242 0.609 0.389 0.484 0.539 45 D.10 Prompts Here we present the prompt templates used to generate statements, build preference profiles, and insert statements. D.10.1 Generating Alternatives With p ersona, without delib eration round. These are the prompts we used for the main exp erimen ts. System Prompt You are writing a statement that reflects your perspective on a topic. User Prompt You are a person with the following characteristics: { persona } Topic: " { topic } " Write a bridging statement expressing your views on this topic. Your statement should: - Reflect your background, values, and life experiences - Aim to find common ground or bridge different viewpoints - Be 2-4 sentences long - NOT write in first-person - NOT explicitly reference your identity or demographics (avoid "As a [X]...") Write only the statement: With p ersona, with delib eration round. System Prompt You are writing a statement that reflects your perspective on a topic. User Prompt You are a person with the following characteristics: { persona } Topic: " { topic } " Here are 100 statements from people with diverse perspectives on this topic: { statements_list } Write a NEW bridging statement expressing your views on this topic. Your statement should: 46 - Reflect your background, values, and life experiences - Synthesize key themes you observed across the discussion - Aim to find common ground or bridge different viewpoints - Be 2-4 sentences long - NOT write in first-person - NOT explicitly reference your identity or demographics (avoid "As a [X]...") - Be self-contained (do not reference "the statements above" or "other people") Write only the statement: Without p ersona, with delib eration round. System Prompt You are a helpful assistant that generates statements. Return only the statement text, no JSON or additional commentary. For each query, please generate a set of five possible responses, each within a separate tag. Each must include a and a numeric . Please sample at random from the tails of the distribution, such that the probability of each response is less than 0.10. User Prompt Topic: " { topic } " Here are 100 statements from people with diverse perspectives on this topic: { statements_list } Write a NEW bridging statement on this topic. Your statement should: - Synthesize key themes across the different viewpoints - Aim to find common ground or bridge different viewpoints - Be 2-4 sentences long - Be self-contained (do not reference "the statements above" or "other people") Without p ersona, without delib eration round. System Prompt You are a helpful assistant that generates statements. Return only the statement text, no JSON or additional commentary. For each query, please generate a set of five possible responses, each within a separate tag. Each must include a and a numeric . Please sample at random from the tails of the distribution, such that the probability of each response is less than 0.10. 47 User Prompt Topic: " { topic } " Write a bridging statement on this topic. Your statement should: - Aim to find common ground or bridge different viewpoints - Be 2-4 sentences long D.10.2 Building Preference Profiles Using iterative ranking (App endix D.4.2 ), the first few rounds ask the mo del to pick the top and b ottom K statemen ts, and the final round asks the model to rank the remaining statemen ts. Initial Rounds. User Prompt Topic: " { topic } " Here are { n } statements (identified by 4-letter codes): { stmt_lines } From these { n } statements, identify: 1. Your TOP { k } most preferred (in order, most preferred first) 2. Your BOTTOM { k } least preferred (in order, least preferred last) IMPORTANT: Do NOT simply list codes in the order they appear above. Your preferences should reflect your persona’s values and background. Return JSON: { "top_ { k } ": ["code1", "code2", ...], "bottom_ { k } ": ["code1", "code2", ...] } Where stmt_lines is formatted as: User Prompt XXXX: "Statement text here..." YYYY: "Another statement..." Final Round. User Prompt Topic: " { topic } " Here are { n } statements (identified by 4-letter codes): { stmt_lines } Rank ALL of these statements from most to least preferred. IMPORTANT: Do NOT simply list codes in the order they appear above. 48 Your preferences should reflect your persona’s values and background. Return JSON: { "ranking": ["most_preferred", "second", ..., "least_preferred"] } D.10.3 Winner Selection GPT-Select: Select from P Alternatives. System Prompt You are a helpful assistant that selects consensus statements. Return ONLY valid JSON. User Prompt Here are { n } statements from a discussion: { statements_text } Which statement would be the best choice as a consensus/bridging statement? Consider which one best represents a reasonable middle ground that could satisfy diverse perspectives. Return your choice as JSON: { "selected_statement_index": } Where the value is the index (0- { n-1 } ) of the statement you select. Where statements_text is formatted as: F ormat Statement 0: Statement text here... Statement 1: Another statement... GPT-Select+Rank: Select with Rankings. System Prompt You are a helpful assistant that selects consensus statements. Return ONLY valid JSON. User Prompt Here are { n } statements from a discussion: { statements_text } Here are preference rankings from { n_voters } voters: 49 { rankings_text } Based on both the statements and the preference rankings, which statement would be the best choice as a consensus/bridging statement? Return your choice as JSON: { "selected_statement_index": } Where the value is the index (0- { n-1 } ) of the statement you select. Where rankings_text is formatted as ( K = 20 sampled voters, full rankings ov er P = 20 alternativ es): F ormat Voter 1: 5 > 3 > 1 > 8 > 2 > 0 > 7 > 6 > 4 > 9 > 10 > 11 > 12 > 13 > 14 > 15 > 16 > 17 > 18 > 19 Voter 2: 3 > 5 > 8 > 1 > 2 > 0 > 7 > 6 > 4 > 9 > 10 > 11 > 12 > 13 > 14 > 15 > 16 > 17 > 18 > 19 ... Voter 20: 8 > 3 > 5 > 1 > 2 > 0 > 7 > 6 > 4 > 9 > 10 > 11 > 12 > 13 > 14 > 15 > 16 > 17 > 18 > 19 GPT-Select+P ers: Select with P ersonas. System Prompt You are a helpful assistant that selects consensus statements. Return ONLY valid JSON. User Prompt Here are { n } statements from a discussion: { statements_text } Here are the { n_voters } voters who will be voting on these statements: { personas_text } Based on both the statements and the voter personas, which statement would be the best choice as a consensus/bridging statement? Return your choice as JSON: { "selected_statement_index": } Where the value is the index (0- { n-1 } ) of the statement you select. Where personas_text is formatted as ( K = 20 sampled v oters, filtered to 7 k ey fields to sav e tok en costs): 50 F ormat Voter 1: age: 53 sex: Male race: White alone education: Master’s degree occupation: MGR-Education And Childcare Administrators political views: Liberal religion: Protestant Voter 2: age: 54 sex: Male race: White alone education: Master’s degree occupation: ENT-News Analysts, Reporters, And Journalists political views: Democrat religion: Catholic ... Voter 20: ... GPT-F ull: Select from All 100. System Prompt You are a helpful assistant that selects consensus statements. Return ONLY valid JSON. User Prompt Topic: { topic } A group of participants submitted the following { n_all } statements on this topic: { all_text } Select the statement that would best serve as a consensus or bridging position - one that: - Engages substantively with the topic - Could be acceptable to participants with diverse viewpoints - Avoids extreme or polarizing framing Return your choice as JSON: { "selected_statement_index": } Where the value is the index (0- { n_all-1 } ) of the statement you select. The GPT-F ull+Rank and GPT-F ull+P ers v arian ts add rankings_text and personas_text resp ectiv ely , using the same format as GPT-Select. GPT-Syn thesize: Generate New Statemen t. 51 System Prompt You are a helpful assistant that generates consensus statements. Return ONLY valid JSON. User Prompt Topic: { topic } Here are some existing statements from a discussion: { statements_text } Generate a NEW statement that could serve as a better consensus/bridging statement. The statement should: - Represent a reasonable middle ground that could satisfy diverse perspectives - Be different from the existing statements but address the same topic - Be clear and substantive (2-4 sentences) Return your new statement as JSON: { "new_statement": "" } The GPT-Synthesize+Rank and GPT-Synthesize+P ers v arian ts add rankings_text and personas_text resp ectiv ely as in GPT-Select. GPT-Blind: Blind Generation. System Prompt You are a helpful assistant that generates bridging statements. Return ONLY valid JSON. User Prompt Given the topic: " { topic } " Generate a bridging statement that could serve as a consensus position on this topic. The statement should: - Represent a reasonable middle ground that could satisfy diverse perspectives - Acknowledge different viewpoints while finding common ground - Be clear and substantive (2-4 sentences) Return your statement as JSON: { "bridging_statement": "" } 52
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment