CounterRefine: Answer-Conditioned Counterevidence Retrieval for Inference-Time Knowledge Repair in Factual Question Answering
In factual question answering, many errors are not failures of access but failures of commitment: the system retrieves relevant evidence, yet still settles on the wrong answer. We present CounterRefine, a lightweight inference-time repair layer for r…
Authors: Tianyi Huang, Ying Kai Deng
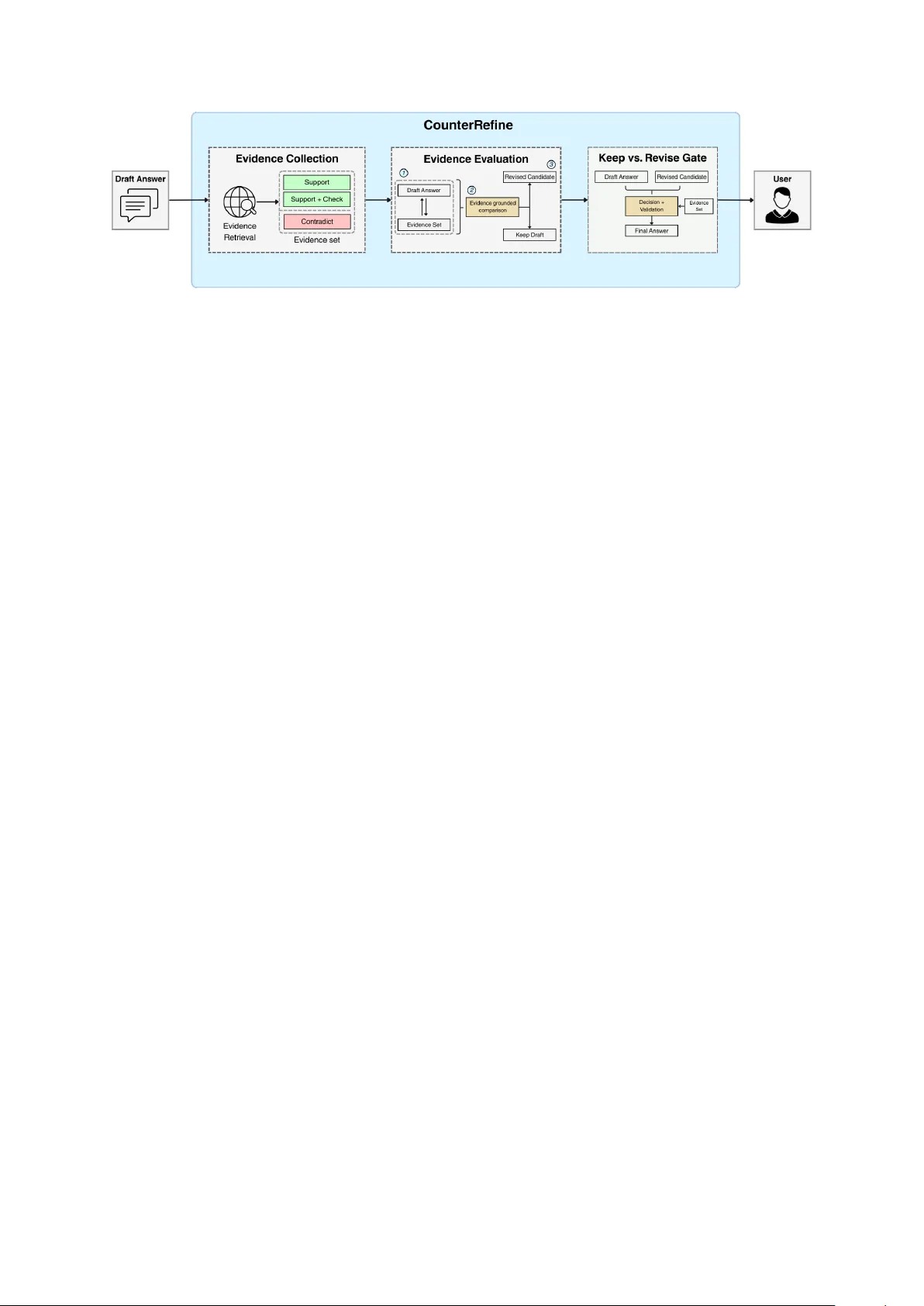
CounterRefine: Answer -Conditioned Counter evidence Retrie val f or Infer ence-T ime Knowledge Repair in F actual Question Answering Tianyi Huang * Ryquo tianyi@ryquo.com Y ing Kai Deng App-In Club kai.deng@appinclub.org Abstract In factual question answering, man y errors are not failures of access b ut failures of commit- ment: the system retrie ves rele vant e vidence, yet still settles on the wrong answer . W e present C O U N T E R R E FI N E , a lightweight inference- time repair layer for retriev al-grounded QA. C O U N T E R R E FI N E first produces a short an- swer from retrie ved evidence, then g athers ad- ditional support and conflicting e vidence with follow-up queries conditioned on that draft an- swer , and finally applies a restricted refine- ment step that outputs either KEEP or REVISE , with proposed revisions accepted only if they pass deterministic validation. In effect, C O U N - T E R R E FI N E turns retriev al into a mechanism for testing a provisional answer rather than merely collecting more context. On the full SimpleQA benchmark, C O U N T E R R E FI N E im- prov es a matched GPT -5 B A S E L I N E - R A G by 5.8 points and reaches a 73.1% correct rate, while exceeding the reported one-shot GPT -5.4 score by roughly 40 points. These findings sug- gest a simple but important direction for kno wl- edgeable foundation models: beyond accessing evidence, they should also be able to use that evidence to reconsider and, when necessary , repair their own answers. 1 Introduction Large language models are increasingly used as kno wledge interfaces, but a central dif ficulty re- mains unresolved: a model can retrie ve relev ant material and still commit to the wrong fact. In short-form f actual QA, these errors are unfor giving. A wrong year , nearby entity , or almost-right title is still fully incorrect. This mak es factual QA a useful setting for studying a broader question that matters for knowledgeable foundation models: if some kno wledge is wrong, can we repair it at in- ference time rather than only during pre-training or parameter editing? * Corresponding author . Retrie v al-augmented generation (RA G) im- prov es factuality by grounding generation in ex- ternal evidence rather than relying only on para- metric memory ( Lewis et al. , 2021 ; Karpukhin et al. , 2020 ). Y et retrie val alone does not eliminate candidate-selection errors. A first-pass retriever is optimized for topic rele vance , not necessarily for candidate discrimination . Howe ver , once a draft answer exists, the retrie v al problem changes. The most useful next query is often not the original question, but the question conditioned on that can- didate answer . If the draft year is wrong, adding that year to the query can yield a snippet that di- rectly falsifies it. If the draft entity is too broad or ambiguous, answer-conditioned re-querying can re veal a more discriminati ve title, list entry , or sen- tence. W e build on this observ ation with C O U N T E R - R E FI N E , a retrie val-based short-answer system that first drafts an answer from web snippets and then performs one answer-conditioned countere vidence pass. The second stage is intentionally narro w . It is not tasked with solving the question from scratch. Instead, it decides whether to KEEP the draft or REVISE it in light of additional evidence, and a deterministic validator blocks unsupported or ill- formed rewrites. The result is a simple repair layer that can sit on top of an existing retrie val pipeline. Our empirical evidence is centered on full- benchmark official ev aluation. On the full 4,326- question SimpleQA benchmark with the of ficial grader ( W ei et al. , 2024 ; OpenAI , 2025 ), C O U N - T E R R E FI N E improves a matched B A S E L I N E - R A G from 63.7% to 67.7% correct and from 64.1% to 68.1% F1 on Claude Sonnet 4.6. On GPT -5, cor- rect rate improves from 67.3% to 73.1% and F1 from 58.6% to 72.1%. W e also ev aluate transfer on 100- and 300-example slices from HotpotQA distractor de velopment ( Y ang et al. , 2018 ), where C O U N T E R R E FI N E improv es exact match on both Claude Sonnet 4.6 and GPT -5. Qualitativ e exami- nation sho ws that most successful re visions repair entity confusions, dates, and numeric values, while the remaining failures are dominated by relation confusion and e vent mismatch. Our contributions are: (1) we formalize answer - conditioned counterevidence retriev al as a sim- ple keep-or-re vise layer for factual QA; (2) we sho w that this layer improves ov er a matched re- trie v al baseline under the of ficial SimpleQA ev alu- ation pipeline and also transfers to HotpotQA e xact match; and (3) we provide a targeted qualitati ve analysis of where the method helps and where its remaining failure modes arise. 2 Related W ork Retriev al-grounded factual QA. Retrie v al- augmented generation improv es knowledge- intensi ve NLP by grounding generation in external documents ( Le wis et al. , 2021 ). Dense Passage Retrie v al further improved open-domain QA with learned neural retriev al ( Karpukhin et al. , 2020 ). More recent work has explored adapti ve retrie val and critique, for example by teaching models when to retrie ve and ho w to reflect on retrieved e vidence ( Asai et al. , 2024 ). Other w ork has targeted robustness to noisy retriev al ( Y u et al. , 2024 ) or refreshed model kno wledge through search-engine augmentation ( V u et al. , 2024 ). Our method differs in focus: rather than redesigning the retriever or the full RA G stack, we add a minimal second retrie v al phase to stress-test the first answer . V erification and self-correction. A broad line of work impro ves f actuality by checking or revising an initial answer . Chain-of-V erification generates verification questions before producing a final an- swer ( Dhuliaw ala et al. , 2024 ). CRITIC uses tool- interacti ve critique to v alidate and amend outputs ( Gou et al. , 2024 ). RARR retrieves e vidence and re vises unsupported claims while trying to preserv e the original text ( Gao et al. , 2023 ). SelfCheckGPT detects likely hallucinations through disagreement across samples ( Manakul et al. , 2023 ). C O U N T E R - R E FI N E is closest in spirit to this family , but it is narro wer and cheaper: one extra retriev al pass, one extra model call, and a constrained short-answer decision rather than broad long-form editing. Knowledge repair and model editing. Wrong kno wledge can also be addressed by editing model parameters directly . R OME and MEMIT show that factual associations in language models can be modified through targeted weight updates ( Meng et al. , 2022 , 2023 ). Those methods operate on the model’ s stored kno wledge itself. C O U N T E R - R E FI N E is complementary: it performs answer- le vel repair at inference time instead of changing model parameters, using external e vidence to chal- lenge and re vise a candidate answer . Benchmarks and conflicting evidence. Factu- ality has been studied through claim verification datasets such as FEVER ( Thorne et al. , 2018 ), factual QA benchmarks such as T ruthfulQA ( Lin et al. , 2022 ), long-form f actuality metrics such as F A CTSCORE ( Min et al. , 2023 ), and broader sur- ve ys of LLM factuality ( W ang et al. , 2024 ). Sim- pleQA is particularly rele vant here because it iso- lates short-form factual precision in a benchmark of 4,326 questions with a single indisputable answer ( W ei et al. , 2024 ). Recent work has also empha- sized that retrie val errors are not limited to irrel- e v ant documents; systems often face ambiguous, noisy , or conflicting e vidence ( W ang et al. , 2025 ). Our setting is simpler than that literature’ s multi- document conflict benchmarks, but the moti vating issue is related: ev en in short-answer QA, retrie ved snippets can weakly support multiple nearby can- didates. Answer -conditioned re-querying is one lightweight way to make those conflicts visible be- fore finalizing an answer . 3 Method 3.1 Overview W e refer to the first-pass retrie v al system as B A S E L I N E - R AG . Giv en a question q , C O U N T E R - R E FI N E first runs B A S E L I N E - R A G to produce an initial answer a 0 , then runs one answer-conditioned refinement stage: R 0 = Retriev e( q ) , (1) a 0 = f draft ( q , R 0 ) , (2) R 1 = Retriev eRefine( q , a 0 , R 0 ) , (3) a ⋆ = f refine ( q , a 0 , R 1 ) . (4) The goal is not to replace a standard retriev al pipeline with a more complicated agent, but to add a focused reliability layer on top of it. 3.2 Stage 1: r etriev al-based drafting The baseline stage retriev es up to k b e vidence snip- pets for the original question: R 0 = Retriev e( q , k b ) . (5) Figure 1: Schematic ov erview of C O U N T E R R E FI N E . Starting from a draft answer produced by B A S E L I N E - R AG , CounterRefine collects additional e vidence intended to support, check, or contradict that candidate, ev aluates the draft answer against the resulting evidence set, and then passes the result to a constrained keep-vs.-re vise gate. The final answer is either the original draft or a re vised candidate accepted under e vidence-based validation using the same e vidence set. For readability , the figure abstracts a way some implementation details from the text (question-type-conditioned query selection and per-query snippet aggre gation) but it is aligned with the three-stage pipeline described in Section 3. In the current implementation, k b = 5 . The re- trie ver returns tuples of title, URL, and evidence text, and duplicates are remov ed before prompt construction. The drafting model answers using only the re- trie ved e vidence: a 0 = f draft ( q , R 0 ) . (6) The draft prompt enforces a short answer and dis- allo ws hedging or explanation. If retriev al fails to yield a v alid answer , the code falls back to a closed-book short-answer prompt; if that also fails, a minimal type-dependent default is emitted. 3.3 Stage 2: answer -conditioned countere vidence retriev al The central design choice is that refinement queries depend on the draft answer . Let t ( q ) denote a coarse question type inferred heuristically from the question string. The refinement query set is Q ( q , a 0 ) = { q , q ∥ " a 0 " } ∪ I [ t ( q ) ∈ T ] { " a 0 " } , (7) where ∥ denotes string concatenation and T = { who , where , when , year , number } . Intuiti vely , the second retrie v al stage asks not just “what documents are about this question?” b ut “what evidence most directly supports or contra- dicts this candidate answer?” For each q ′ ∈ Q ( q , a 0 ) , the system retrie ves up to k r e vidence snippets, with k r = 5 in the current implementation, and mer ges them with the baseline support set: R 1 = Dedup e R 0 ∪ [ q ′ ∈ Q ( q ,a 0 ) Retriev e( q ′ , k r ) . (8) 3.4 Stage 3: constrained r efinement The refiner receiv es the question, the baseline an- swer , and the mer ged e vidence set, and must output exactly three fields: DECISION: KEEP or REVISE ANSWER: EVIDENCE: The prompt instructs the model to KEEP when the baseline is already the best supported answer and to REVISE only when the additional e vidence strongly supports a dif ferent or more exact short answer . Let ( d, ˆ a, e ) denote the parsed refinement output. If d = KEEP , the system returns a 0 . If d = REVISE , the proposed answer must pass deterministic v ali- dation before it is accepted. 3.5 Deterministic validation and canonicalization The v alidator is a core part of the method. It blocks re visions that are unsupported, ill-typed, or stylisti- cally incompatible with short-answer e valuation. A proposed rewrite is rejected if an y of the following hold: 1. it is empty , non-responsi ve, or identical to the draft after normalization; 2. for yes/no questions, it is not exactly yes or no ; 3. for entity-style questions, it is clause-like, o verly long, or begins with a descriptor phrase; 4. for temporal or numeric questions, it lacks an explicit temporal or numeric mark er; 5. the refiner provides no e vidence snippet; 6. lexical o verlap between the revised answer and the e vidence snippet is too weak. Accepted re visions are then canonicalized with question-type-specific rules, such as extracting a 4-digit year , compacting number spans, stripping leading prepositions for locations, or remo ving par- enthetical descriptors from names. Only proposed re visions are v alidated; KEEP decisions preserve the baseline answer unchanged. The final output is a ⋆ = ( Canon( q , ˆ a ) , if the revision is accepted, a 0 , otherwise. (9) 4 Experimental Setup 4.1 Benchmarks and metrics W e ev aluate on two benchmarks. Our primary benchmark is SimpleQA, which contains 4,326 short, fact-seeking questions with a single in- disputable answer ( W ei et al. , 2024 ). W e use the of ficial SimpleQA grader from the public simple-evals implementation ( OpenAI , 2025 ). Follo wing the of ficial setup, we report the correct rate and F1 score. As a second transfer setting, we ev aluate on 100-example and 300-e xample slices from the Hot- potQA distractor de velopment set ( Y ang et al. , 2018 ). HotpotQA is useful here because it is more multi-hop and span-oriented than SimpleQA. W e report the standard exact match (EM) and token- ov erlap F1 metrics. 4.2 Systems Our primary full-benchmark run uses Claude Son- net 4.6 for both drafting and refinement ( Anthropic , 2026 ). Retriev al is implemented through the Ope- nAI web search API in a simple RAG pipeline that returns web e vidence for subsequent answer gen- eration ( OpenAI , 2026 ; Lewis et al. , 2021 ). The baseline system, B A S E L I N E - R A G , uses the same retrie v al component and the same drafting back- bone b ut does not run the answer-conditioned re- finement stage. This keeps the comparison focused Figure 2: Correct-rate comparison on the full SimpleQA benchmark. C O U N T E R R E FI N E is compared with a matched one-pass retriev al baseline ( B A S E L I N E - R A G ) and representativ e one-shot leaderboard models. on the contribution of C O U N T E R R E FI N E rather than on backbone or retrie v al differences. W e also ran matched experiments with GPT -5 on SimpleQA and HotpotQA ( OpenAI , 2025 ). Unless noted otherwise, the benchmark results in the main paper are produced with the of ficial ev aluation pro- cedures for the corresponding task. 5 Results 5.1 Perf ormance across benchmarks and backbones T able 1 reports the main quantitative results. The central pattern is consistent: the addition of C O U N - T E R R E FI N E on top of B A S E L I N E - R AG improv es the primary exactness-oriented metric across e very reported setting. This holds for the full SimpleQA benchmark under the official grader , on smaller SimpleQA slices, and on HotpotQA across both 100-example and 300-example e valuations. The gains are therefore not confined to a single back- bone, a single dataset, or a single e v aluation scale. T wo aspects of the result are especially impor- tant. First, the improv ement appears on top of an already retriev al-grounded baseline rather than a no-retrie v al model. The comparison is therefore not between a weak closed-book system and a stronger retriev al system, but between a matched Benchmark Metric Claude 4.6 GPT -5 Base-RA G C O U N T E R R E FI N E ∆ Base-RA G C O U N T E R R E FI N E ∆ SimpleQA (100) Correct ↑ 65.0 75.0 +10.0 57.0 71.0 +14.0 F1 ↑ 65.0 75.0 +10.0 59.7 73.2 +13.5 SimpleQA (4,326) Correct ↑ 63.7 67.7 +4.0 67.3 73.1 +5.8 F1 ↑ 64.1 68.1 +4.0 58.6 72.1 +13.5 HotpotQA (100) EM ↑ 74.0 79.0 +5.0 71.0 76.0 +5.0 F1 ↑ 82.2 84.9 +2.7 83.7 84.5 +0.8 HotpotQA (300) EM ↑ 70.0 74.0 +4.0 68.0 71.0 +3.0 F1 ↑ 83.9 86.0 +2.1 83.6 84.9 +1.3 T able 1: Main results across backbones and benchmarks. B A S E L I N E - R AG is the matched one-pass retrie v al baseline using the same retriev er and backbone as C O U N T E R R E FI N E . SimpleQA uses the of ficial grader . HotpotQA uses the distractor dev elopment setting on 100-example and 300-example slices. All values are percentages. one-pass retrie val pipeline and the same pipeline augmented with answer-conditioned refinement. Second, the gains are strongest on metrics that re ward final answer exactness. This is most vis- ible in the SimpleQA correct rate and HotpotQA EM, which matches the intended role of C O U N T E R - R E FI N E as a repair layer for final factual precision rather than a general-purpose reasoning scaf fold. The cross-benchmark pattern is also informa- ti ve. On SimpleQA, where a near-miss entity , date, or number is scored as fully wrong, answer- conditioned refinement yields clear gains under the of ficial ev aluation pipeline. On HotpotQA, the same mechanism continues to improv e exact match, including at the larger 300-example slice. F1 gains are positi ve in most reported settings, but are gener - ally smaller and less uniform than the exact-match gains, which again aligns with the design goal of correcting final answer identity rather than optimiz- ing partial lexical o verlap. 5.2 Intervention pr ofile The full Claude SimpleQA run clarifies how C O U N - T E R R E FI N E achiev es these gains. It changes only a small fraction of predictions, yet the changes are ov erwhelmingly beneficial: the system revises 5.6% of examples, helps 180, hurts 8, and pro- duces zero refiner failures. Beneficial outcome- changing re visions therefore outnumber harmful ones by 22.5 to 1. Just as importantly , the not- attempted rate remains fix ed at 1.2%, so the im- prov ement is not driv en by abstaining more often or by becoming artificially conserv ati ve. Figure 3 makes the structure of the gain explicit. Most examples are unchanged, but among changed outcomes, incorrect → correct transitions dominate Figure 3: Outcome transitions on the full SimpleQA benchmark for Claude 4.6. Of all examples, 63.5% stay correct, 32.1% stay not-correct, 4.2% are corrected (incorrect → correct), and 0.2% are harmed (correct → incorrect). correct → incorrect ones by a wide margin. This is the behavior we want from a post-retriev al repair layer: it should intervene selecti vely , and when it does, it should usually mov e the answer in the right direction. The same qualitativ e picture also appears across smaller runs. Earlier 100-example and 300- example SimpleQA e xperiments showed gai ns in the same direction, and during de velopment-stage 300-example iterations we repeatedly observed zero hurt cases. T ak en together with the full- benchmark results, this suggests that the method is capturing a stable error mode of one-pass retriev al QA rather than e xploiting a narro w artifact of one dataset slice. 5.3 Representati ve failures and successes T able 2 illustrates the main failure and success pat- terns. The hurt cases are not random; they are Question (abridged) B A S E L I N E - R A G Final Gold Diagnosis Representati ve hurt cases Who appointed the Chief Justice of India, Mirza Hameedullah Beg, in 1977? Fakhruddin Ali Ahmed Indira Gandhi Fakhruddin Ali Ahmed Nearby evidence named the gov ernment behind the elev ation rather than the appointing president requested by the question. What day , month, and year was the municipality of Arboletes, Antioquia, Colombia, founded? 1920 August 1958 July 20, 1920 The refinement e vidence referred to municipal establishment rather than the original founding date. On what day , month, and year did Manny P acquiao marry Jinkee Jamora? May 10, 1999 May 10, 2000 May 10, 1999 A noisy timeline-style snippet ov errode an already correct baseline year . Representati ve helped cases Who was aw arded the Oceanography Society’ s Jerlov A ward in 2018? Collin Roesler Annick Bricaud Annick Bricaud Answer-conditioned retrie val surfaced an aw ard-list entry explicitly naming the 2018 winner . What were the day , month, and year of death of Mehr Chand Mahajan? 5 December 1984 11 December 1967 11 December 1967 The refinement stage found a biographical snippet containing the exact parenthetical death date. In which year did Fazal Ilahi Chaudhry join the Muslim League? 1940s 1942 1942 Re-querying with the draft answer surfaced the exact year instead of a decade-lev el answer . T able 2: Representative f ailures and successes from the full Claude trace log. mostly cases of relation confusion or event mis- match . In these examples, the refinement stage retrie ves e vidence about a nearby b ut different re- lation, milestone, or date, and that adjacent fact is plausible enough to o verride an initially correct answer . This suggests that the main remaining weakness is not lack of evidence, but insuf ficient discrimination between closely related factual rela- tions. The helped cases sho w the complementary pat- tern. B A S E L I N E - R A G is often nearly correct but too coarse, under-specified, or anchored on the wrong nearby candidate. Once the draft answer is injected back into retriev al, the second-stage search surfaces a decisi ve snippet that the first pass failed to isolate. In that sense, the value of C O U N T E R - R E FI N E is not that it “reasons more” in the abstract, but that it changes what evidence becomes visible after a concrete hypothesis has been formed. 6 Discussion The results support a simple interpretation: one- pass retrie val often fails not because the correct e vidence is globally unav ailable, b ut because the system commits too early to a plausible candidate before retrie ving the evidence that w ould best test that candidate. C O U N T E R R E FI N E impro ves this by shifting the role of retrie val after drafting. The second retrie val pass is no longer only about find- ing topic-rele vant material, b ut about verifying or ov erturning a concrete factual hypothesis. This is precisely why the method fits the broader agenda of kno wledgeable foundation models. The core issue is not only ho w much knowledge a model contains, but whether the system can recognize when an initially plausible answer should be up- dated in light of ne w e vidence. C O U N T E R R E FI N E provides one concrete inference-time mechanism for that update process. It neither edits model pa- rameters nor assumes perfect retrie val from the out- set; instead, it uses answer-conditioned e vidence gathering to make factual repair possible after an initial answer has already been formed. 7 Conclusion W e presented C O U N T E R R E FI N E , a retriev al-based QA system that answers first and then retriev es specifically to challenge its own answer . Across our ev aluations, the results indicate that a meaning- ful share of error arises not from missing e vidence, but from committing too quickly to an insufficiently tested candidate answer . By revisiting and, when warranted, ov erturning plausible but incorrect re- sponses, C O U N T E R R E FI N E shows that a simple inference-time intervention can turn kno wledge ac- cess into kno wledge repair . Limitations For C O U N T E R R E FI N E , the empirical evidence is strongest for short-form factual settings, particu- larly SimpleQA, where exact entity , date, and value corrections are central to e valuation. Although the transfer results on HotpotQA are encouraging, the y cov er limited slices rather than the full benchmark and therefore should be interpreted as e vidence of generalization potential rather than as a complete characterization of multi-hop performance. Additionally , C O U N T E R R E FI N E is designed to repair a draft answer after retrie val, not to replace retrie v al itself or to solve long-form generation problems. Its effecti veness therefore depends on whether the retrie val stage surfaces suf ficiently in- formati ve supporting evidence. Extending the same repair principle to further long-form settings, more relation-sensiti ve v alidation, and broader multi-hop benchmarks is a natural ne xt step. W e vie w these as promising directions for expanding an inference- time kno wledge repair pattern that already prov es ef fecti ve in the present setting. Broader Impact and Ethical Considerations C O U N T E R R E FI N E points to a practical and hope- ful direction for knowledgeable foundation models: not only to store more facts, b ut also to detect and repair wrong answers before they reach the user . Because the method is modular and compatible with standard retriev al pipelines, it can serve as a practical reliability layer for search assistants, edu- cational tools, and scientific interfaces where small factual errors can ha ve outsized consequences. At the same time, inference-time repair should be understood as improving reliability rather than guaranteeing truth. If retriev ed evidence reflects social, historical, or institutional bias, a repair layer may reinforce those patterns rather than correct them. In high-stakes settings, repaired answers should therefore be treated as better-supported out- puts rather than as definitiv e verification. The most responsible role for systems like C O U N T E R R E FI N E is not to replace human judgment, b ut to raise the standard of e vidence behind model outputs, espe- cially in domains such as medicine, law , public policy , and education. In that sense, the broader promise of inference-time repair is not just fewer mistakes, but a more accountable form of kno wl- edge use. References Anthropic. 2026. Introducing claude sonnet 4.6 . Akari Asai, Zeqiu W u, Y izhong W ang, A virup Sil, and Hannaneh Hajishirzi. 2024. Self-RA G: Learning to retrie ve, generate, and critique through self-reflection . In The T welfth International Confer ence on Learning Repr esentations . Shehzaad Dhulia wala, Mojtaba Komeili, Jing Xu, Roberta Raileanu, Xian Li, Asli Celikyilmaz, and Jason W eston. 2024. Chain-of-verification reduces hallucination in large language models . In F indings of the Association for Computational Linguistics: A CL 2024 , pages 3563–3578, Bangkok, Thailand. Association for Computational Linguistics. Luyu Gao, Zhuyun Dai, Panupong Pasupat, Anthony Chen, Arun T ejasvi Chaganty , Y icheng Fan, V incent Zhao, Ni Lao, Hongrae Lee, Da-Cheng Juan, and Kelvin Guu. 2023. RARR: Researching and revising what language models say , using language models . In Pr oceedings of the 61st Annual Meeting of the Association for Computational Linguistics (V olume 1: Long P apers) , pages 16477–16508, T oronto, Canada. Association for Computational Linguistics. Zhibin Gou, Zhihong Shao, Y eyun Gong, yelong shen, Y ujiu Y ang, Nan Duan, and W eizhu Chen. 2024. CRITIC: Large language models can self-correct with tool-interactiv e critiquing . In The T welfth Inter- national Confer ence on Learning Representations . Vladimir Karpukhin, Barlas Oguz, Sew on Min, Patrick Lewis, Ledell W u, Sergey Edunov , Danqi Chen, and W en-tau Y ih. 2020. Dense passage retriev al for open- domain question answering . In Pr oceedings of the 2020 Confer ence on Empirical Methods in Natural Language Pr ocessing (EMNLP) , pages 6769–6781, Online. Association for Computational Linguistics. Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Hein- rich Küttler, Mike Lewis, W en tau Y ih, T im Rock- täschel, Sebastian Riedel, and Douwe Kiela. 2021. Retriev al-augmented generation for kno wledge- intensiv e nlp tasks . Pr eprint , Stephanie Lin, Jacob Hilton, and Owain Evans. 2022. T ruthfulqa: Measuring ho w models mimic human falsehoods . Pr eprint , Potsawee Manakul, Adian Liusie, and Mark Gales. 2023. SelfcheckGPT : Zero-resource black-box hallucina- tion detection for generati ve large language models . In The 2023 Confer ence on Empirical Methods in Natural Language Pr ocessing . Ke vin Meng, David Bau, Alex J Andonian, and Y onatan Belinkov . 2022. Locating and editing factual associ- ations in GPT . In Advances in Neural Information Pr ocessing Systems . Ke vin Meng, Arnab Sen Sharma, Alex J Andonian, Y onatan Belinkov , and David Bau. 2023. Mass- editing memory in a transformer . In The Eleventh International Confer ence on Learning Repr esenta- tions . Sew on Min, Kalpesh Krishna, Xinxi L yu, Mike Le wis, W en-tau Y ih, Pang Koh, Mohit Iyyer, Luke Zettle- moyer , and Hannaneh Hajishirzi. 2023. F ActScore: Fine-grained atomic e valuation of factual precision in long form text generation . In Pr oceedings of the 2023 Confer ence on Empirical Methods in Natural Language Pr ocessing , pages 12076–12100, Singa- pore. Association for Computational Linguistics. OpenAI. 2025. Gpt-5 is here . OpenAI. 2025. simple-ev als . GitHub repository . Archiv ed benchmark results table and reference im- plementation; accessed March 12, 2026. OpenAI. 2026. W eb search. https: //developers.openai.com/api/docs/guides/ tools- web- search . OpenAI API documentation. James Thorne, Andreas Vlachos, Christos Christodoulopoulos, and Arpit Mittal. 2018. FEVER: a large-scale dataset for fact extraction and VERification . In Pr oceedings of the 2018 Confer ence of the North American Chapter of the Association for Computational Linguistics: Human Language T echnologies, V olume 1 (Long P apers) , pages 809–819, Ne w Orleans, Louisiana. Association for Computational Linguistics. T u V u, Mohit Iyyer , Xuezhi W ang, Noah Constant, Jerry W ei, Jason W ei, Chris T ar, Y un-Hsuan Sung, Denn y Zhou, Quoc Le, and Thang Luong. 2024. Fresh- LLMs: Refreshing large language models with search engine augmentation . In F indings of the Association for Computational Linguistics: ACL 2024 , pages 13697–13720, Bangkok, Thailand. Association for Computational Linguistics. Han W ang, Archiki Prasad, Elias Stengel-Eskin, and Mohit Bansal. 2025. Retriev al-augmented generation with conflicting evidence . Pr eprint , Y uxia W ang, Minghan W ang, Muhammad Arslan Man- zoor , Fei Liu, Georgi Nenko v Georgiev , Rocktim Jy- oti Das, and Preslav Nako v . 2024. F actuality of large language models: A survey . In Pr oceedings of the 2024 Confer ence on Empirical Methods in Natural Language Pr ocessing , pages 19519–19529, Miami, Florida, USA. Association for Computational Lin- guistics. Jason W ei, Nguyen Karina, Hyung W on Chung, Y unxin Joy Jiao, Spencer Papay , Amelia Glaese, John Schulman, and W illiam Fedus. 2024. Mea- suring short-form factuality in large language models . Pr eprint , Zhilin Y ang, Peng Qi, Saizheng Zhang, Y oshua Bengio, W illiam Cohen, Ruslan Salakhutdinov , and Christo- pher D. Manning. 2018. HotpotQA: A dataset for div erse, explainable multi-hop question answering . In Proceedings of the 2018 Confer ence on Empiri- cal Methods in Natural Language Pr ocessing , pages 2369–2380, Brussels, Belgium. Association for Com- putational Linguistics. W enhao Y u, Hongming Zhang, Xiaoman Pan, Peixin Cao, Kaixin Ma, Jian Li, Hongwei W ang, and Dong Y u. 2024. Chain-of-note: Enhancing robustness in retriev al-augmented language models . In Pr oceed- ings of the 2024 Conference on Empirical Methods in Natural Language Pr ocessing , pages 14672–14685, Miami, Florida, USA. Association for Computational Linguistics.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment