Safe Flow Q-Learning: Offline Safe Reinforcement Learning with Reachability-Based Flow Policies
Offline safe reinforcement learning (RL) seeks reward-maximizing policies from static datasets under strict safety constraints. Existing methods often rely on soft expected-cost objectives or iterative generative inference, which can be insufficient …
Authors: Mumuksh Tayal, Manan Tayal, Ravi Prakash
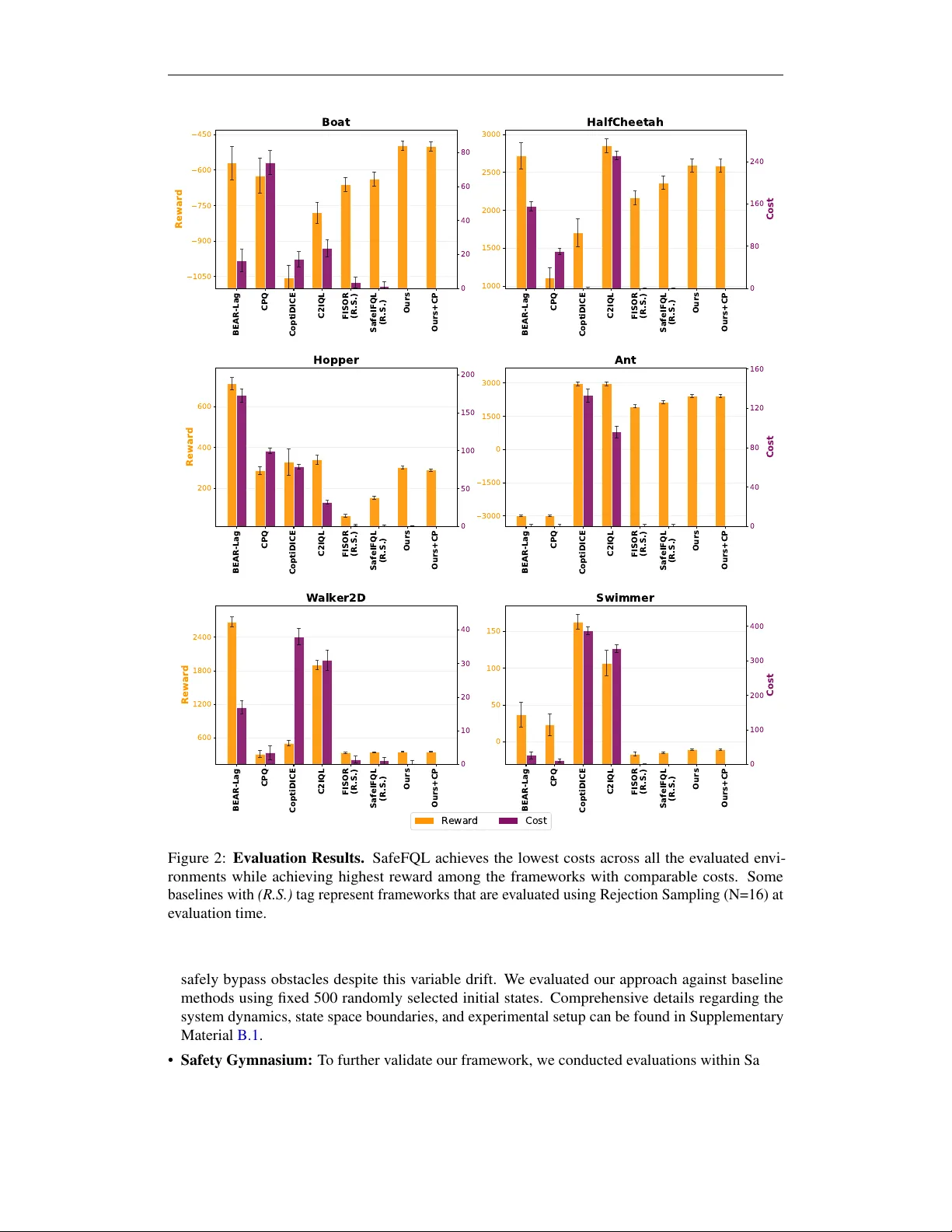
Cover P age Safe Flow Q-Lear ning: Offline Safe Reinf or cement Lear ning with Reachability-Based Flow P olicies Mumuksh T ayal, Manan T ayal, Ra vi Prakash Keyw ords: Safe reinforcement learning, offline reinforcement learning, flo w matching, Hamilton-Jacobi reachability , conformal prediction. Summary Safe of fline reinforcement learning seeks re ward-maximizing control from static datasets under strict safety constraints. W e propose Safe Flow Q-Learning (SafeFQL) , which e xtends FQL to the safe setting by combining a Hamilton-Jacobi reachability-inspired safety value func- tion with an efficient one-step flo w policy for safe action selection without rejection sampling at deployment. T o account for finite-data learning error, SafeFQL includes a conformal prediction calibration step that adjusts the safety threshold and yields finite-sample probabilistic safety cov erage. Empirically , SafeFQL trades modestly higher of fline training cost for substantially lower inference latency than diffusion-style safe generati ve baselines, making it attracti ve for real-time safety-critical control. Across boat navigation and all Safe V elocity based Gymnasium MuJoCo tasks, SafeFQL matches or exceeds prior of fline safe RL performance while reducing constraint violations. Contrib ution(s) 1. W e propose Safe Flow Q-Learning (SafeFQL) , a reachability-aware extension of Flow Q-Learning for safe offline reinforcement learning that learns an expressi ve one-step policy without iterativ e denoising or rejection sampling at inference. Context: The method is ev aluated in offline settings with fixed datasets and does not claim online-training safety guarantees. 2. W e provide a computation-time analysis sho wing that SafeFQL trades modestly higher offline training cost for substantially lower inference latency than diffusion-style safe generative baselines, supporting real-time deployment in safety-critical loops. Context: Latency gains are reported for the ev aluated implementations, hardware, and benchmark settings. 3. W e introduce a conformal prediction calibration step that adjusts the learned safety threshold to account for finite-data approximation errors, pro viding finite-sample probabilistic safety cov erage. Context: The guarantee is probabilistic and depends on calibration data and the assumed exchangeability conditions of conformal prediction. 4. Across boat navigation and all Safety Gymnasium MuJoCo tasks, SafeFQL co-optimizes safety and rew ard, matching or exceeding prior of fline safe RL performance while reducing constraint violations. Context: Empirical findings are established on the reported benchmarks and may vary across datasets and task distributions. Safe Flow Q-Lear ning: Offline Safe Reinf orcement Lear ning with Reachability-Based Flow P olicies Mumuksh T ayal 1 , Manan T ayal 2 , Ra vi Prakash 1 mumukshtayal@iisc.ac.in, manantayal@microsoft.com, ravipr@iisc.ac.in 1 Centre f or Cyber-Ph ysical Systems, Indian Institute of Science, India 2 Microsoft Resear ch, India Abstract Offline safe reinforcement learning (RL) seeks rew ard-maximizing policies from static datasets under strict safety constraints. Existing methods often rely on soft e xpected-cost objectiv es or iterative generati ve inference, which can be insuf ficient for safety-critical real-time control. W e propose Safe Flow Q-Learning (SafeFQL) , which e xtends FQL to safe of fline RL by combining a Hamilton–Jacobi reachability-inspired safety v alue function with an efficient one-step flo w policy . SafeFQL learns the safety value via a self-consistency Bellman recursion, trains a flow policy by behavioral cloning, and distills it into a one-step actor for reward-maximizing safe action selection without rejection sampling at deployment. T o account for finite-data approximation error in the learned safety boundary , we add a conformal prediction calibration step that adjusts the safety threshold and pro vides finite-sample probabilistic safety co verage. Empirically , SafeFQL trades modestly higher of fline training cost for substantially lower inference latency than diffusion-style safe generative baselines, which is adv antageous for real-time safety-critical deployment. Across boat navigation, and Safety Gymnasium MuJoCo tasks, SafeFQL matches or exceeds prior offline safe RL performance while substantially reducing constraint violations. 1 Introduction Constrained reinforcement learning (CRL) methods incorporate safety objectiv es during policy learn- ing, but most establis hed approaches rely on extensi ve online interaction and repeated en vironment rollouts ( Achiam et al. , 2017 ; Altman , 2021 ; Alshiekh et al. , 2018 ; Zhao et al. , 2023 ). This depen- dence is problematic in safety-critical domains, where training-time failures are costly and many systems do not have sufficiently faithful simulators to absorb risky exploration. As also reflected in safe-RL benchmarks and datasets ( Liu et al. , 2024 ), the online setting can expose both training and deployment to unacceptable safety risk. These limitations motiv ate a shift to ward of fline policy synthesis from logged data, including of fline RL and imitation-style pipelines ( Le vine et al. , 2020 ; Kumar et al. , 2020 ). Howe ver , ev en in offline settings, many methods still enforce safety through expected cumulati ve penalties or Lagrangian dual updates, yielding soft constraint satisfaction rather than strict state-wise guarantees ( Xu et al. , 2022 ; Ciftci et al. , 2024 ; Stooke et al. , 2020 ). Such formulations can be insufficient when a single violation is unacceptable, and the safety-performance trade-off becomes particularly brittle when safety-critical transitions are sparse in static datasets ( Lee et al. , 2022 ). Control-theoretic safety methods provide a complementary perspectiv e with stronger notions of state-wise safety . Control Barrier Functions (CBFs) ( Ames et al. , 2014 ) and Hamilton–Jacobi (HJ) 1 reachability ( Bansal et al. , 2017 ; Fisac et al. , 2019 ) can encode forw ard in variance and worst-case safety explicitly . Y et, classical grid-based HJ methods face the curse of dimensionality ( Mitchell , 2005 ). In addition, many practical CBF/HJ-inspired learning pipelines require either known dynamics or a learned dynamics surrogate to compute safety deriv atives and synthesize actions (e.g., through QP-based filtering( Ames et al. , 2017 )). When dynamics are unkno wn, model-learning errors can propagate into safety estimates and policy decisions, particularly under dataset shift and out-of- support actions, which weakens practical robustness in purely of fline settings ( T ayal et al. , 2025a ; b ). Recent offline safety framew orks also report this trade-off explicitly: learned models can enable scalable controller synthesis, but they may become a dominant error source for high-confidence safety if not carefully calibrated ( T ayal et al. , 2025b ). In parallel, safe generative-polic y methods hav e emer ged to improv e action expressi vity under offline distrib utional constraints. Sequence-model approaches such as the Constrained Decision Transformer (CDT) condition generation on return and cost budgets ( Liu et al. , 2023 ), while diffusion-based methods model multimodal action distributions and can better represent complex behavior support in static datasets ( Janner et al. , 2022 ).These advances are important because safety-critical datasets are often heterogeneous and multimodal, where unimodal Gaussian actors can fail to recover rare but important safe maneuvers. Ho we ver , current safe generative policies still face practical bottlenecks: sequence-model conditioning is indirect for step-wise safety control, and diffusion-style policies require iterati ve denoising and often additional rejection sampling to reliably pick safe high-v alue actions at test time, increasing latency and deployment complexity ( Liu et al. , 2023 ; Zheng et al. , 2024 ). At the same time, recent progress in offline RL suggests that improving v alue learning alone is often insuf ficient: ev en with a reasonably accurate critic, extracting an ef fective polic y remains non- trivial ( Park et al. , 2024 ). Flow matching pro vides a useful alternati ve to dif fusion-style generation by learning a continuous transport (velocity-field) map from noise to actions, enabling expressi ve policy classes with simpler sampling dynamics ( Lipman et al. , 2023 ). Building on this idea, Flow Q-Learning (FQL) in unconstrained offline RL separates flow-based behavior modeling from one-step RL policy optimization, so the final actor can be optimized efficiently without backpropagating through iterativ e generation ( Park et al. , 2025 ). Extending this idea to safety-critical offline RL is not a tri vial drop-in adaptation. In the safe setting, policy e xtraction must simultaneously (i) maximize rew ard, (ii) remain inside a safety-feasible re gion under future e volution, and (iii) av oid excessiv e conservatism that de grades performance. Moti vated by this, we propose Safe Flo w Q-Learning (SafeFQL) , an of fline safe RL frame work that combines reachability-inspired safety v alue learning with one-step flo w policy e xtraction. SafeFQL learns a safety value function that captures feasibility through a Bellman-style recursion over of fline data, and trains a distilled one-step actor that is directly optimized by Q-learning while regularized tow ard the behavior -supported flow policy . This av oids recursiv e backpropagation through iterati ve generativ e sampling and removes the need for rejection sampling at deployment, while retaining expressi ve action modeling. A second challenge in offline safe RL is that both the safety value function and policy are learned under finite data and approximation errors; thus, the nominal safety le vel set can be miscalibrated. T o address this, we incorporate a conformal prediction (CP) calibration step that adjusts the safety threshold using held-out calibration errors, yielding finite-sample probabilistic co verage guarantees ( Shafer & V ovk , 2008 ; Lindemann et al. , 2025 ). This step makes the safety boundary explicitly uncertainty-aware, impro ving its reliability . T o summarize, our main contrib utions are: • W e formulate SafeFQL , a reachability-a ware e xtension of FQL for safe of fline RL that learns an expressi ve one-step policy without iterati ve denoising or rejection sampling at inference. • W e provide a dedicated computation-time analysis showing that, while SafeFQL may incur higher offline training cost, it delivers substantially lower inference latency than dif fusion-style safe generativ e baselines, enabling real-time deployment in safety-critical control loops. • W e introduce a conf ormal calibration mechanism for safety value le vel sets, which compensates for offline learning errors and pro vides probabilistic safety coverage guarantees for deployment. 2 • W e show that SafeFQL co-optimizes safety and performance across custom na vigation and Safety Gymnasium benchmarks, consistently achie ving lower safety violations while maintaining strong rew ard relati ve to prior constrained of fline RL and safe generative baselines. 2 Background and Pr oblem Setup W e study safe offline reinforcement learning in en vironments with hard state constraints. The en vironment is modelled as a Constrained Markov Decision Process (CMDP), defined by the tuple M = ( X , A , P, r , ℓ, γ ) , where X and A denote the state and action spaces, P ( x ′ | x, a ) denotes the transition probability function defining the system dynamics, r : X → R is the reward function, ℓ : X → R is an instantaneous state-based safety function, typically defined as the negati ve of signed distance function to failure set F , and γ ∈ (0 , 1) is the discount factor . W e define the failure set F := { x ∈ X | ℓ ( x ) > 0 } , which represents unsafe states that must be av oided at all times (e.g., collisions or constraint violations). A trajectory is considered safe if it ne ver enters F . W e assume access to an offline dataset D = { ( x t , a t , r t , ℓ t , x t +1 ) } , collected by an unknown behavior policy , with no further interaction with the en vironment permitted. Any policy π ( a | x ) which induces trajectories τ = ( x 0 , a 0 , x 1 , . . . ) , does it through the transition probability function P . Gi ven an initial state x , the objective is to compute the maximum achiev able discounted return subject to state safety at all future time steps. This requirement can be formalized through the following formulation: sup π ∞ X k =0 γ k r ( x k ) x 0 = x s.t. x t / ∈ F , ∀ t ≥ 0 . (1) Unlike formulations based on expected cumulati ve penalties, ( 1 ) encodes a har d safety r equir ement , i.e., only policies that admit trajectories remaining entirely outside the failure set are considered feasible. This formulation directly captures safety-critical requirements where even a single violation is unacceptable. 2.1 Generative P olicies for Offline RL T o o vercome the limitations of traditional limitations for policy extraction, recent literature has in ves- tigated generati ve polic y representations in offline RL, such as sequence models and dif fusion-based policies ( Chen et al. , 2021 ; Janner et al. , 2022 ), along with their extensions to safety-constrained en vironments ( Liu et al. , 2023 ; Lin et al. , 2023 ; Zheng et al. , 2024 ; LIU et al. , 2025 ). Although highly effecti ve at capturing data distributions, diffusion models necessitate the simulation of stochastic processes across numerous discrete time steps during inference. This iterativ e sampling is compu- tationally burdensome, making real-time deployment in high-frequency control loops particularly challenging. Con versely , flow matching ( Lipman et al. , 2023 ; Zhang et al. , 2025b ; Alles et al. , 2025 ) presents a deterministic alternativ e. By directly learning the vector field of the generative process, flow matching f acilitates highly efficient polic y sampling through a single ODE integration. A con venient w ay to view flo w-matching policies is as the time-1 pushforward of a state-conditioned, time-dependent velocity field. Let v θ ( t, x, z ) denote the state-conditioned velocity field and define the flow ψ θ ( t, x, z ) by the ODE d dt ψ θ ( t, x, z ) = v θ t, x, ψ θ ( t, x, z ) , ψ θ (0 , x, z ) = z . (2) The corresponding flow polic y is defined as the ODE terminal map µ θ ( x, z ) : = ψ θ (1 , x, z ) = z + Z 1 0 v θ t, x, ψ θ ( t, x, z ) dt, (3) which is a deterministic mapping in ( x, z ) but induces a stochastic policy π θ ( a | x ) via z ∼ N (0 , I ) . W e will di ve deeper into this aspect of deterministic mapping of ( x, z ) in the later sections. 3 2.2 Safe Offline Reinfor cement Learning Safe reinforcement learning has conv entionally relied on online Lagrangian-based constrained optimization and trust-region methods ( Cho w et al. , 2017 ; T essler et al. , 2018 ; Stooke et al. , 2020 ; Achiam et al. , 2017 ). Howe ver , the necessity for online interaction and the use of soft cost penalties in these approaches ha ve catalyzed a shift to ward safe of fline RL. Se veral prominent offline RL methods such as CPQ ( Xu et al. , 2022 ) and C2IQL ( LIU et al. , 2025 ) attempt to ensure safety by penalizing unsafe actions by restricting the expected cumulativ e costs below a pre-defined cost limit l , i.e., max π E τ ∼ π [ P ∞ t =0 γ t r ( x t , a t )] s.t. E τ ∼ π [ P ∞ t =0 γ t c ( x t )] ≤ l ; but these techniques often degrade value estimation and generalization ( Li et al. , 2023 ). Some Hamilton–Jacobi (HJ) reachability based safety frameworks connect HJ reachability with offline RL ( Zheng et al. , 2024 ) to identify states that can enter the failure set F = { x : ℓ ( x ) ≥ 0 } within a giv en time horizon ( Bansal et al. , 2 017 ; Fisac et al. , 2019 ). They often define the HJ v alue as the best worst-time safety mar gin V ∗ ℓ ( x 0 ) : = inf π sup t ∈ [0 ,T ] ℓ ( x t ) s.t. a t ∼ π ( · | x t ) , (4) Or , V ∗ ℓ ( x 0 ) : = max { ℓ ( x 0 ) , inf π V π ℓ ( x 1 ) } ∀ t ∈ { 0 , 1 , 2 , ... } (5) so that V ∗ ℓ ( x 0 ) measures the smallest maximum value of ℓ attainable along trajectories from x 0 . Intuitiv ely , V ∗ ℓ ( x 0 ) > 0 indicates that ev en the best policy leads the trajectory inside the failure set (i.e., ℓ ( x t ) ≥ 0 for some t ), while V ∗ ℓ ( x 0 ) < 0 implies there exists an optimally safe policy that keeps the system in the safe region from state x 0 within the horizon. The classical HJ PDE / Hamiltonian formulation and numerical solution methods are used for computation ( Bansal et al. , 2017 ). Such frameworks often use Generativ e Policy based techniques like DDPM ( Zheng et al. , 2024 ) and Flow Matching to learn expressi ve policies in offline RL. Howe ver , such frame works struggle to extract an exact optimal polic y and rather tend to learn a polic y which only encourages the desired safety and performance with the use of Advantage W eighted Regression ( Peters & Schaal , 2007 ). And ev en though A WR is a simple and easy-to-implement approach in offline RL, it is often considered as the least ef fecti ve polic y extraction method ( P ark et al. , 2024 ), and therefore, man y a times has to be accompanied by Rejection Sampling to selecti vely choose an action that best suites the requirements. Perhaps, a more effecti ve technique for policy extraction can be using Deterministic Policy Gradient with Beha vior Cloning ( Fujimoto & Gu , 2021 ) where the policy directly maximizes Q-value function. But using DPG with multi-step denoising based generative policy frame works like Flow Matching requires backward gradient through the entire re verse denoising process, inevitably introducing tremendous computational costs. Meanwhile, other set of frameworks use Barrier Function based approaches ( W ang et al. , 2023a ; T ayal et al. , 2025b ) to achie ve safety . Unfortunately , these frame works also come with their own set of limitations. Barrier Functions require knowledge of system dynamics which is generally rare to be known for most systems. Although such frameworks choose to learn the approximate dynamics of the system, they can become a significant source of noise, which can be fatal in safety-critical cases. T o overcome these bottlenecks, recent works hav e focused on distilling the multi-step generative processes into single-step policies ( Prasad et al. , 2024 ; Zhang et al. , 2025a ; Park et al. , 2025 ). These distilled models are designed to match the action outputs of their full-fledged, multi-step counterparts, yielding fast and accurate performance at a fraction of the computational cost for both training and inference. 3 Safe Flow Q-Lear ning Building on the CMDP formulation and the of fline safe RL objecti ve introduced in Section 2 , this section presents SafeFQL in full detail. The design follo ws the decoupled learning principle of FQL ( Park et al. , 2025 ) where v alue functions and the policy are trained with separate objecti ves so that policy optimization is ne ver destabilized by errors in critic bootstrapping. W e extend this principle to 4 Offline Data Collection Multi-Step Flo w Matching P olicy ….. P olicy Distillation Safe & Optimal One-Step P olicy Reward Critic Safety Critic Held out Calibration Data Flo w Matching T eacher P olicy T raining F easibility Gated Actor T raining Conf ormal Pr ediction Statistical Safety Guarantee DEPLO Y Figure 1: Framework Overview . SafeFQL framework proposes a safe offline RL approach using an efficient one-step flo w policy extraction. the safety-constrained setting by introducing a second critic system whose semantics are governed by worst-case reachability rather than cumulativ e discounted return. A post-hoc conformal δ -calibration then provides a statistical finite-sample safety guarantee on top of the learned polic y . The ov erall procedure decomposes into four phases: (i) learning reward and safety critics from D ; (ii) fitting a behavior flow teacher and distilling it into a one-step actor; (iii) optimizing the actor under a feasibility-gated objectiv e; and (iv) selecting a correction level δ via conformal testing on a held-out set. These four phases are sequentially dependent, the policy cannot be trained before critics con verge, and calibration requires a fix ed policy . Within each phase, all netw orks are trained in parallel to con vergence. W e describe each phase in turn. 3.1 Learning Reward and Safety Critics The offline dataset D = { ( x i , a i , r i , ℓ i , x ′ i ) } N i =1 provides tuples of state, action, scalar reward, signed safety signal, and next state. W e recall from Section 2 that the safety signal ℓ ( x ) is defined so that ℓ ( x ) ≤ 0 if and only if x / ∈ F , i.e., the state is safe. All critic learning is performed entirely within the support of D , so that no out-of-distrib ution action queries are required. 5 Reward critics. W e train a reward Q-function Q r ( x, a ; ϕ r ) and a corresponding state-value function V r ( x ; ψ r ) using the implicit Q-learning (IQL) approach of K ostriko v et al. ( 2022 ). IQL avoids querying the actor during critic updates, which is the primary source of instability in of fline actor– critic methods ( Fujimoto et al. , 2019 ). The value function V r approximates the expectile of the Q-value distrib ution under the behavior policy , and is trained via the asymmetric squared loss L V r ( ψ r ) = E ( x,a ) ∼D [ L τ ( Q r ( x, a ; ϕ r ) − V r ( x ; ψ r ))] , (6) where L τ ( u ) = | τ − I ( u < 0) | u 2 is the expectile loss with τ ∈ (0 . 5 , 1) . For τ close to 1 the loss upweights positi ve residuals, causing V r to track a high quantile of the in-sample Q-v alue distribution rather than its mean. This implicitly represents the adv antage of actions better than average in the dataset without ev er ev aluating the policy . Given V r , the Q-function is updated via one-step Bellman regression against a tar get network ¯ V r : y r = r + γ ¯ V r ( x ′ ) , (7) L Q r ( ϕ r ) = E ( x,a,r,x ′ ) ∼D h ( Q r ( x, a ; ϕ r ) − y r ) 2 i . (8) T ar get netw ork parameters ¯ ψ r are updated via Exponential Moving A verage (EMA), details for which are cov ered in Supplementary Material D . Safety critics. For the safety constraint, a naiv e approach w ould be to train a discounted cumulati ve cost Q-function Q sum c ( x, a ) = E [ P t γ t I { x t ∈ F } ] and penalize its expectation below a threshold, as in standard CMDP Lagrangian methods. This leads to a soft constraint that enforces safety in expectation but cannot prev ent individual trajectory violations ( Xu et al. , 2022 ; Lee et al. , 2022 ). Moreov er , the non-negativity of the cumulati ve cost makes the threshold a free hyperparameter that must be tuned per task. SafeFQL instead adopts a reachability-inspired formulation that encodes worst-case safety along the trajectory . W e define the safety critic Q c ( x, a ) as an approximation of the Hamilton–Jacobi feasibility value V ∗ ℓ ( x 0 ) = min π max t ≥ 0 ℓ ( x t ) from Section 2 , trained via a max-backup Bellman recursion ( Fisac et al. , 2019 ): y c ( x, a, x ′ ) = max ℓ ( x ) , γ ¯ V c ( x ′ ) . (9) The tar get y c takes the maximum of the immediate safety margin ℓ ( x ) and the discounted future safety value γ ¯ V c ( x ′ ) . This ensures that a low safety margin at any future time step propagates backward to the current state, so that Q c ( x, a ) < 0 carries a strong meaning: not only is x currently safe, b ut the predicted future ev olution also remains in the safe region under behavior -policy-like actions. Con versely , Q c ( x, a ) ≥ 0 indicates that follo wing the behavior distrib ution from ( x, a ) is predicted to ev entually enter the failure set F . The safety Q-function Q c ( x, a ; ϕ c ) and safety v alue function V c ( x ; ψ c ) are trained with L Q c ( ϕ c ) = E ( x,a,ℓ,x ′ ) ∼D h ( Q c ( x, a ; ϕ c ) − y c ) 2 i , (10) L V c ( ψ c ) = E ( x,a ) ∼D [ L τ ( Q c ( x, a ; ϕ c ) − V c ( x ; ψ c ))] . (11) Note the use of the same expectile loss in ( 11 ) and ( 6 ) , but applied to the safety residual Q c − V c . Here τ < 0 . 5 causes V c to track the lower quantile of the in-sample safety Q-distrib ution, yielding a conservati ve approximation of the feasibility boundary . In implementation we share the same τ hyperparameter across both critics, with opposite sign conv entions in expectile regression (i.e., u > 0 where u = Q c ( x, a ; ϕ c ) − V c ( x ; ψ c ) ) for what constitutes a desirable extreme; the rew ard critic targets the upper quantile while the safety critic tar gets the lo wer quantile. The max-backup structure of y c means that clipped double-Q techniques familiar from re ward critics must be applied with a maximum operation (i.e., taking the most pessimistic safety estimate): we use two safety Q-networks and set ¯ V c ( x ′ ) = max { Q (1) c ( x ′ , · ) , Q (2) c ( x ′ , · ) } , consistently avoiding overoptimistic feasibility estimates at OOD next states. 6 3.2 Behavior Flo w Policy and One-Step Distillation W ith critics in place, we turn to policy learning. The central challenge is to produce a policy that (a) stays close to the behavior distrib ution to avoid distrib utional shift, (b) is expressiv e enough to model multimodal and structured action distrib utions common in robotics datasets, and (c) can be ex ecuted at test time with negligible latency . Diffusion-based policies satisfy (a) and (b) through score-matched generati ve modeling, but their iterative re verse-process sampling incurs O ( T ) network ev aluations per step ( Zheng et al. , 2024 ; W ang et al. , 2023b ). SafeFQL therefore adopts the FQL strategy ( P ark et al. , 2025 ) of using a flow-matching model as a fixed behavior teacher and distilling it into an efficient one-step deplo yment policy . Flow beha vior teacher . W e parameterize the beha vior policy π β via a conditional flo w-matching model µ θ ( x, z , t ) , which defines a time-dependent v elocity field ov er actions ( Lipman et al. , 2023 ). Giv en a state x ∼ D , a Gaussian sample z ∼ N (0 , I ) , and a time t ∼ Uniform ([0 , 1]) , the teacher is trained to transport z to the empirical action distribution via the regression objecti ve L flow ( θ ) = E ( x,a ) ∼D , z ∼N (0 ,I ) , t ∼U ([0 , 1]) h ∥ µ θ ( x, x t , t ) − ( a − z ) ∥ 2 2 i , (12) where x t = (1 − t ) z + ta is the straight-line interpolation between the noise sample and the target action. At con ver gence, integrating the learned velocity field from t = 0 to t = 1 starting from z generates an action a ∼ π β ( ·| x ) . The flow teacher is trained with behavioral cloning only (no critic signal enters L flow ), which keeps this stage unconditionally stable. One-step student actor . The deployed policy is a deterministic one-step actor µ ω ( x, z ) : X × R d a → A that maps a state and a latent noise vector directly to an action, without any iterativ e integration. T o endow the student with the expressi veness of the flow teacher , we define a distillation loss that penalizes deviation from the one-step teacher output ˜ µ θ ( x, z ) , which is the action produced by running a single integration step of the trained flo w model from z conditioned on x : L distill ( ω ) = E ( x,z ) ∼D×N (0 ,I ) h ∥ µ ω ( x, z ) − ˜ µ θ ( x, z ) ∥ 2 2 i . (13) The distillation term serves as a beha vior regularizer: it pulls the student actor toward the support of the offline dataset, prev enting it from exploiting critic extrapolation errors in regions far from the data ( Park et al. , 2025 ). Crucially , the one-step actor µ ω is the only component of SafeFQL that is queried at deployment time, so inference cost is that of a single forward pass through a feedforward network reg ardless of how man y flow steps were used to train the teacher . 3.3 Feasibility-Gated Actor Objecti ve Giv en the reward critic Q r , the safety critic Q c , and the distillation anchoring from the flow teacher , we now describe ho w to combine these signals into a well-motiv ated actor objecti ve. This is the crux of the method, and the design choice here distinguishes SafeFQL from both vanilla FQL and prior soft-constraint offline safe RL approaches. Limitations of the naiv e Lagrangian formulation. A natural baseline is to treat the safety constraint as a soft penalty and jointly optimize reward and safety with a Lagrangian multiplier η > 0 : L naiv e actor ( ω ) = E x,z [ − Q r ( x, a ω ) + η max(0 , Q c ( x, a ω ))] + λ L distill ( ω ) , (14) where a ω = µ ω ( x, z ) . The penalty term max(0 , Q c ) is zero when Q c < 0 (predicted feasible) and equal to Q c when Q c ≥ 0 (predicted infeasible). Objective ( 14 ) is computationally straightforward since gradients with respect to ω flo w through both terms simultaneously , b ut it has a critical structural flaw , the two terms are commensurate in magnitude and can trade of f against each other . Concretely , near the feasibility boundary where Q c is small but positi ve, a sufficiently lar ge gradient from − Q r 7 can dominate and push the actor into the infeasible region. The multiplier η would need to be tuned precisely per task to pre vent this, and the right v alue is not kno wn without online interaction. Empirically , soft-constraint offline methods that rely on this kind of Lagrangian penalty are known to be highly sensitiv e to the choice of cost limit and multiplier ( Zheng et al. , 2024 ; Xu et al. , 2022 ); the coupled optimization of reward, safety , and behavior re gularization further exacerbates instability ( Lee et al. , 2022 ). Feasibility-gated objective. SafeFQL replaces the additiv e tradeoff with an exclusive-gate mech- anism that enforces strict priority ordering, when the predicted policy action violates feasibility ( Q c ≥ 0 ), the actor update completely ignores re ward and focuses solely on recov ering feasibility; only once the action is predicted feasible ( Q c < 0 ) does the update switch to re ward maximization. This is implemented via the binary gate ζ ( x, z ) = I { Q c ( x, µ ω ( x, z )) < 0 } , (15) and the combined actor loss L actor ( ω ) = λ L distill ( ω ) + E ( x,z ) ζ ( x, z ) · − Q r ( x, a ω ) + 1 − ζ ( x, z ) · max(0 , Q c ( x, a ω )) . (16) The three terms in ( 16 ) hav e distinct and complementary roles. The distillation term L distill serves as a universal behavioral anchor , keeping the actor within the support of the offline dataset at all times regardless of the feasibility state. The second term ζ · ( − Q r ) is the reward-maximization signal, which is active only at state-latent pairs where the current actor output is already in the predicted feasible region. The third term (1 − ζ ) · max(0 , Q c ) is the feasibility reco very signal, acti ve only when the current output violates the predicted safety boundary , and it pushes the actor in the direction of decreasing Q c rather than in the direction of reward. Such a feasibility gate ζ eliminates the instability that arises when rew ard and safety gradients are simultaneously activ e and point in opposing directions. In-sample action generation. At each actor update step, the action a ω = µ ω ( x, z ) with z ∼ N (0 , I ) is sampled fresh, so the stochastic policy π ω induced by µ ω is implicitly e valuated at man y points per gradient step. No replay buf fer of policy actions is needed; the randomness of z provides the necessary cov erage of the action distribution to av oid mode collapse under the distillation constraint. 3.4 Safety V erification using Conformal Pr ediction Ideally , the rollout cost from a gi ven state under the learned actor from gated objecti ve ( 16 ) should match the value of the safety value function at that state. Howe ver , due to learning inaccuracies, discrepancies can arise. This becomes critical when a state, x i , is deemed safe by the safety v alue function ( V c ( x ) < 0 ) but is unsafe under the learned policy ( V π c ( x ) > 0 ). T o address this, we introduce a uniform value function correction mar gin, δ , which guarantees that the sub- δ lev el set of the safety v alue function remains safe under the learned polic y . Mathematically , the optimal δ ( δ ∗ ) can be expressed as: δ ∗ := min ˆ x ∈X { V c ( x ) : V π c ( x ) ≥ 0 } (17) Intuiti vely , δ ∗ identifies the tightest lev el of the value function that separates safe states under learned policy from unsafe ones. Hence, any initial state within the sub- δ ∗ lev el set is guaranteed to be safe under the ideal learned policy π ∗ . Howe ver , calculating δ ∗ exactly requires infinitely many state-space points. T o o vercome this, we adopt a conformal-prediction-based approach to approximate δ ∗ using a finite number of samples, pro viding a probabilistic safety guarantee. For additional details, please refer Supplementary Material A . Algorithm 2 in the Supplementary Material A presents the steps to calculate δ used for this approach. 8 Algorithm 1 Safe Flow Q-Learning (SafeFQL) Require: Offline dataset D = { ( x, a, r, ℓ, x ′ ) } , discounts γ , expectile τ , distillation weight λ , calibration parameters ( ϵ s , β s , N cal ) Ensure: Deployed policy µ ω ; corrected safe set S δ ∗ 1: / / P H A S E 1 : C R I T I C L E A R N I N G 2: Initialize Q r , V r (rew ard critics) and Q c , V c (safety critics) 3: for each gradient step do 4: Update V r via expectile loss ( 6 ); update Q r via Bellman loss ( 8 ) 5: Update Q c via max-backup Bellman loss ( 10 ); update V c via expectile loss ( 11 ) 6: EMA-update target netw orks ¯ V r , ¯ V c 7: end for 8: / / P H A S E 2 : F L OW T E A C H E R T R A I N I N G 9: T rain behavior flo w teacher µ θ via flow-matching loss ( 12 ) 10: / / P H A S E 3 : F E A S I B I L I T Y - G AT E D A C T O R T R A I N I N G 11: Initialize one-step actor µ ω 12: for each gradient step do 13: Sample ( x, z ) ∼ D × N (0 , I ) ; compute a ω = µ ω ( x, z ) 14: Compute gate ζ via ( 15 ); update µ ω by minimizing ( 16 ) 15: end for 16: / / P H A S E 4 : S A F E T Y V E R I FI C AT I O N U S I N G C O N F O R M A L P R E D I C T I O N 17: Refer Algorithm 2 for implementation 18: retur n µ ω , S δ ∗ = { x : V c ( x ) < δ ∗ } 4 Experiments W e ev aluate SafeFQL against baseline methods to inv estigate three critical aspects: (i) its safety rate relativ e to state-of-the-art constrained offline RL algorithms, (ii) the tradeoff between safety compliance and cumulativ e re ward P ∞ k =0 r ( x k ) , and (iii) its sampling efficiency during inference compared to prominent alternativ e generativ e modeling based frameworks. Our findings confirm that SafeFQL successfully co-optimizes safety and performance, deli vering state-of-the-art safety rates while maintaining high rew ard accumulation. Baselines: W e compare SafeFQL ag ainst a di verse set of safety constrained of fline reinforcement learning methods. W e include BEAR-Lag (Lagrangian dual v ersion of Kumar et al. ( 2019 )), COp- tiDICE ( Lee et al. , 2022 ), CPQ ( Xu et al. , 2022 ), C2IQL ( LIU et al. , 2025 ), FISOR ( Zheng et al. , 2024 ) and also SafeIFQL (Safe Flow Matching version of K ostrikov et al. ( 2022 )). In contrast to these methods, SafeFQL learns a one step policy from offline demonstrations that accounts for future unsafe interactions in adv ance and therefore, accordingly taking actions that maximize the cumulati ve rew ard while staying within the safe region. Evaluation Metrics: W e e v aluate all methods based on (i) safety/cost , measured as the total number of safety violations incurred before episode termination, and (ii) performance , measured via the cumulativ e episode rewards. These metrics allow us to assess the trade-off between strict safety enforcement and task performance across different of fline RL approaches. 4.1 Experimental Case Studies For thorough e valuation of our frame work against the baselines, we use the follo wing varied set of en vironments: • Safe Boat Navigation: For our first experiment, we address a two-dimensional collision av oidance problem where a boat, modeled with point mass dynamics, na vigates a ri ver ( T ayal et al. , 2025b ). The river’ s drift velocity changes according to the boat’ s y-coordinate. The primary goal is to 9 BEAR-Lag CPQ CoptiDICE C2IQL FISOR (R .S.) SafeIFQL (R .S.) Ours Ours+CP 1050 900 750 600 450 Reward Boat BEAR-Lag CPQ CoptiDICE C2IQL FISOR (R .S.) SafeIFQL (R .S.) Ours Ours+CP 1000 1500 2000 2500 3000 HalfCheetah BEAR-Lag CPQ CoptiDICE C2IQL FISOR (R .S.) SafeIFQL (R .S.) Ours Ours+CP 200 400 600 Reward Hopper BEAR-Lag CPQ CoptiDICE C2IQL FISOR (R .S.) SafeIFQL (R .S.) Ours Ours+CP 3000 1500 0 1500 3000 Ant BEAR-Lag CPQ CoptiDICE C2IQL FISOR (R .S.) SafeIFQL (R .S.) Ours Ours+CP 600 1200 1800 2400 Reward W alk er2D BEAR-Lag CPQ CoptiDICE C2IQL FISOR (R .S.) SafeIFQL (R .S.) Ours Ours+CP 0 50 100 150 Swimmer 0 20 40 60 80 0 80 160 240 Cost 0 50 100 150 200 0 40 80 120 160 Cost 0 10 20 30 40 0 100 200 300 400 Cost R ewar d Cost Figure 2: Evaluation Results. SafeFQL achieves the lowest costs across all the ev aluated envi- ronments while achieving highest reward among the frame works with comparable costs. Some baselines with (R.S.) tag represent frame works that are e valuated using Rejection Sampling (N=16) at ev aluation time. safely bypass obstacles despite this variable drift. W e ev aluated our approach against baseline methods using fixed 500 randomly selected initial states. Comprehensive details regarding the system dynamics, state space boundaries, and experimental setup can be found in Supplementary Material B.1 . • Safety Gymnasium: T o further v alidate our frame work, we conducted e valuations within Safety Gymnasium ( Ji et al. , 2023 ), specifically focusing on the Safe V elocity suite. For these Safe V elocity tasks, we tested SafeFQL on se veral high-dimensional MuJoCo en vironments, including Hopper , Half Cheetah, Swimmer , W alk er2D, and Ant. The goal in these settings is to maximize 10 the agent’ s reward while strictly maintaining its speed below a specified threshold. T o ensure a fair comparison against baseline methods, we ev aluated performance across a fixed set of 500 randomly sampled initial states for each en vironment. All the additional details of the frame work are av ailable in Supplementary Material B.2 for the readers to refer . For our experiments within the Safety Gymnasium suite, we employ the standard DSRL dataset for safe offline RL ( Liu et al. , 2024 ) while preserving the framew ork’ s original reward and safety- violation metrics ( Ji et al. , 2023 ). T o benchmark our approach against existing baselines, we e valuate performance across a fixed collection of 500 randomly sampled safe initial states for each task. 4.2 Results While refering the results from Figure 2 for the custom Safe Boat Navigation en vironment, SafeFQL achiev es a significant increase in reward compared to all baselines while maintaining zero violations across all e valuation episodes . This strong performance e xtends to the high-dimensional Safety Gym- nasium tasks (HalfCheetah, Hopper , Ant, W alker2D, and Swimmer), where SafeFQL consistently achiev es the lo west safety violations and the highest re ward among framew orks with comparable near-zero costs . SafeFQL ’ s success stems from learning a one-step optimal policy that directly outputs high-reward, safe actions . In contrast, baselines optimizing for expected cumulative cost (e.g., BEAR-Lag, CPQ, and COptiDICE) struggle to strictly enforce safety without sacrificing rew ard , while C2IQL achiev es high rewards b ut incurs inconsistent costs in safety-critical task. Furthermore, while generati ve base lines like FISOR and SafeIFQL also account for w orst-case safety , they fail to directly learn a single optimal action. Instead, they rely on computationally expensi ve and suboptimal rejection sampling at inference to filter safe actions from multiple generated candidates. SafeFQL circumvents this entirely by directly outputting the optimal action at each timestep without the need for sampling, establishing it as the most ef fective and ef ficient policy among the e valuated framew orks . 4.3 Comparison to Generative P olicy Baselines T o further in vestigate the performance benefits of SafeFQL, we analyzed the safety rate, defined as the percentage of episodes without collisions, in the Figure 3 for the Safe Boat Navigation en vironment. Generativ e baseline framew orks like FISOR and SafeIFQL require a large number of action samples (N=16) to achie ve safety rates comparable to our method. Because SafeFQL learns a one-shot optimal policy , it successfully outputs the optimal action e ven when N is restricted to 1. Besides, we also e v aluated the computation time gains of SafeFQL ov er FISOR and SafeIFQL by analyzing both training and inference times in Figure 4 . While SafeFQL requires a longer training compute time compared to the other two framew orks, it more than compensates for this upfront cost with minimal inference latency during deployment. Because FISOR heavily relies on rejection sampling, significant latency is introduced as every time an action must be selected from N candidates based on cost and rew ard Q-values. Even when N is set to 1 for FISOR and SafeIFQL and rejection sampling is disabled, inference time remains high due to the multi-step denoising process inherent to both DDPM and Flow Matching policies. This demonstrates that trading a one-time higher training cost for SafeFQL yields a v astly more efficient, highly accurate, single-step polic y . Ultimately , this highlights the immense practical ef fecti veness of SafeFQL for high-frequenc y , real-time control loops once the model is trained. 5 Conclusion, Limitations and Future w orks W e introduced Safe Flo w Q-Learning (SafeFQL), a scalable of fline safe reinforcement learning framew ork that synthesizes the expressi vity of generativ e flow models with the rigorous safety principles of Hamilton-Jacobi reachability . By distilling a multi-step flow policy into an efficient one-step actor , SafeFQL eliminates the prohibitive computational costs of iterati ve action sampling at 11 N=1 N=2 N=4 N=8 N=16 Rejection Sampling Budget (N) 0 25 50 75 100 Safety Rate (%) FISOR SafeIFQL SafeFQL (Ours) Figure 3: Action Sampling Efficiency . Generativ e policy–based methods (FISOR, SafeIFQL) require rejection sampling to reach high safety rates; SafeFQL achieves highest safety in the Safe Boat Navigation en vironment with only N=1 action sample, while other baselines require larger N. 0 40 80 120 T raining Time (seconds) FISOR SafeIFQL Ours 113s 64s 128s T raining Compute Time 0.0 0.1 0.2 0.3 0.4 Inference Time per Episode (seconds) N=1 N=4 N=8 N=16 N=1 N=4 N=8 N=16 N=1 0.24s 0.33s 0.34s 0.33s 0.21s 0.35s 0.35s 0.35s 0.14s FISOR SafeIFQL Ours Inference Compute Time Figure 4: Computation Time Analysis. Training T ime (Left) and Inference T ime (Right) taken by each of the three generativ e policy based frameworks. deployment, achie ving an inference time speedup of 2 . 5 × . Additionally , we incorporated conformal prediction to dynamically calibrate safety thresholds, ensuring probabilistic constraint satisfaction without relying on manual tuning or restrictiv e adv antage-weighted re gression. Empirically , SafeFQL maintains competiti ve re wards while achieving near -zero violations using a single action proposal across both high-dimensional Safety Gymnasium and custom navigation tasks. While SafeFQL demonstrates robust empirical safety , we identify some scope of algorithmic refine- ment. Currently we use hard indicator mask for the use of Q-critic functions in Algorithm 1 which could theoretically yield a non-smooth loss landscape and might impact training at times. Therefore, 12 one could explore use of continuous masking functions or soft Lagrangian relaxations to improv e framew ork stability , ho wev er, that requires hyperparameter finetuning, which can be undesirable. References Joshua Achiam, David Held, A vi v T amar , and Pieter Abbeel. Constrained policy optimization. In Pr oceedings of the 34th International Conference on Mac hine Learning - V olume 70 , ICML ’17, pp. 22–31. JMLR.org, 2017. Marvin Alles, Nutan Chen, Patrick v an der Smagt, and Botond Cseke. Flowq: Energy-guided flo w policies for offline reinforcement learning, 2025. URL 14139 . Mohammed Alshiekh, Roderick Bloem, Rüdiger Ehlers, Bettina Könighofer, Scott Niekum, and Ufuk T opcu. Safe reinforcement learning via shielding. Pr oceedings of the AAAI Conference on Artificial Intelligence , 32(1), Apr . 2018. DOI: 10.1609/aaai.v32i1.11797. URL https: //ojs.aaai.org/index.php/AAAI/article/view/11797 . Eitan Altman. Constrained Markov decision pr ocesses . Routledge, 2021. Aaron D Ames, Jessy W Grizzle, and Paulo T ab uada. Control barrier function based quadratic programs with application to adapti ve cruise control. In 53r d IEEE Conference on Decision and Contr ol , pp. 6271–6278. IEEE, 2014. Aaron D. Ames, Xiangru Xu, Jessy W . Grizzle, and Paulo T abuada. Control barrier function based quadratic programs for safety critical systems. IEEE T ransactions on A utomatic Contr ol , 62(8): 3861–3876, 2017. DOI: 10.1109/T A C.2016.2638961. Anastasios N. Angelopoulos and Stephen Bates. A gentle introduction to conformal prediction and distribution-free uncertainty quantification, 2022. URL 07511 . Somil Bansal, Mo Chen, Sylvia Herbert, and Claire J T omlin. Hamilton-jacobi reachability: A brief ov erview and recent adv ances. In 2017 IEEE 56th Annual Confer ence on Decision and Contr ol (CDC) , pp. 2242–2253. IEEE, 2017. Lili Chen, Ke vin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Gro ver , Misha Laskin, Pieter Abbeel, Aravind Srini vas, and Igor Mordatch. Decision transformer: Reinforcement learning via sequence modeling. Advances in neural information pr ocessing systems , 34:15084–15097, 2021. Y inlam Chow , Mohammad Ghav amzadeh, Lucas Janson, and Marco Pa v one. Risk-constrained reinforcement learning with percentile risk criteria. The Journal of Machine Learning Resear ch , 18(1):6070–6120, 2017. Y usuf Umut Ciftci, Darren Chiu, Zeyuan Feng, Gaurav S Sukhatme, and Somil Bansal. Safe-gil: Safety guided imitation learning for robotic systems. arXiv preprint , 2024. Jaime F . Fisac, Neil F . Lugovo y , V icenç Rubies-Royo, Shromona Ghosh, and Claire J. T omlin. Bridging hamilton-jacobi safety analysis and reinforcement learning. In 2019 International Confer ence on Robotics and Automation (ICRA) , pp. 8550–8556, 2019. DOI: 10.1109/ICRA.2019. 8794107. Scott Fujimoto and Shixiang Gu. A minimalist approach to offline reinforcement learning. In A. Beygelzimer , Y . Dauphin, P . Liang, and J. W ortman V aughan (eds.), Advances in Neural Information Pr ocessing Systems , 2021. URL https://openreview.net/forum?id= Q32U7dzWXpc . Scott Fujimoto, Herke Hoof, and Da vid Meger . Addressing function approximation error in actor - critic methods. In International conference on mac hine learning , pp. 1587–1596. PMLR, 2018. 13 Scott Fujimoto, David Meger , and Doina Precup. Off-polic y deep reinforcement learning without exploration. In International confer ence on machine learning , pp. 2052–2062. PMLR, 2019. Michael Janner, Y ilun Du, Joshua T enenbaum, and Serge y Levine. Planning with diffusion for flexible beha vior synthesis. In International Confer ence on Machine Learning , pp. 9902–9915. PMLR, 2022. Jiaming Ji, Borong Zhang, Jiayi Zhou, Xuehai P an, W eidong Huang, Ruiyang Sun, Y iran Geng, Y if an Zhong, Josef Dai, and Y aodong Y ang. Safety gymnasium: A unified safe reinforcement learning benchmark. In Thirty-seventh Confer ence on Neural Information Pr ocessing Systems Datasets and Benchmarks T rac k , 2023. URL https://openreview.net/forum?id=WZmlxIuIGR . Ilya Kostrik ov , Ashvin Nair , and Sergey Levine. Of fline reinforcement learning with implicit q-learning. In International Conference on Learning Repr esentations , 2022. A viral Kumar , Justin Fu, Matthew Soh, George T ucker , and Serge y Levine. Stabilizing off-policy q-learning via bootstrapping error reduction. Advances in neural information pr ocessing systems , 32, 2019. A viral Kumar , Aurick Zhou, George T ucker , and Sergey Le vine. Conservati ve q-learning for offline reinforcement learning. In H. Larochelle, M. Ranzato, R. Hadsell, M.F . Balcan, and H. Lin (eds.), Advances in Neural Information Pr ocessing Systems , volume 33, pp. 1179–1191. Curran Asso- ciates, Inc., 2020. URL https://proceedings.neurips.cc/paper_files/paper/ 2020/file/0d2b2061826a5df3221116a5085a6052- Paper.pdf . Jongmin Lee, Cosmin Paduraru, Daniel J Mankowitz, Nicolas Heess, Doina Precup, Kee-Eung Kim, and Arthur Guez. COptiDICE: Offline constrained reinforcement learning via stationary distribution correction estimation. In International Conference on Learning Repr esentations , 2022. URL https://openreview.net/forum?id=FLA55mBee6Q . Serge y Le vine, A viral Kumar , George T ucker , and Justin Fu. Offline reinforcement learning: T utorial, revie w , and perspectives on open problems. arXiv pr eprint arXiv:2005.01643 , 2020. Jianxiong Li, Xianyuan Zhan, Haoran Xu, Xiangyu Zhu, Jingjing Liu, and Y a-Qin Zhang. When data geometry meets deep function: Generalizing offline reinforcement learning. In The Eleventh International Confer ence on Learning Repr esentations , 2023. Qian Lin, Bo T ang, Zifan W u, Chao Y u, Shangqin Mao, Qianlong Xie, Xingxing W ang, and Dong W ang. Safe offline reinforcement learning with real-time budget constraints. In International Confer ence on Machine Learning , 2023. Lars Lindemann, Y iqi Zhao, Xinyi Y u, George J Pappas, and Jyotirmoy V Deshmukh. Formal verification and control with conformal prediction: Practical safety guarantees for autonomous systems. IEEE Control Systems , 45(6):72–122, 2025. Y aron Lipman, Ricky T . Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matthew Le. Flow matching for generati ve modeling. In The Eleventh International Confer ence on Learning Repre- sentations , 2023. URL https://openreview.net/forum?id=PqvMRDCJT9t . Zifan LIU, Xinran Li, and Jun Zhang. C2IQL: Constraint-conditioned implicit q-learning for safe offline reinforcement learning. In F orty-second International Confer ence on Machine Learning , 2025. URL https://openreview.net/forum?id=97N3XNtFwy . Zuxin Liu, Zijian Guo, Y ihang Y ao, Zhepeng Cen, W enhao Y u, Tingnan Zhang, and Ding Zhao. Con- strained decision transformer for offline safe reinforcement learning. In International Conference on Machine Learning , 2023. Zuxin Liu, Zijian Guo, Haohong Lin, Y ihang Y ao, Jiacheng Zhu, Zhepeng Cen, Hanjiang Hu, W enhao Y u, T ingnan Zhang, Jie T an, and Ding Zhao. Datasets and benchmarks for offline safe reinforcement learning. Journal of Data-centric Machine Learning Resear ch , 2024. 14 Ian M. Mitchell. A toolbox of level set methods. In A T oolbox of Level Set Methods , 2005. URL https://api.semanticscholar.org/CorpusID:59892255 . F . W . J. Olver , A. B. Olde Daalhuis, D. W . Lozier , B. I. Schneider, R. F . Boisvert, C. W . Clark, B. R. Miller , B. V . Saunders, H. S. Cohl, and eds. M. A. McClain. NIST Digital Library of Mathematical Functions . National Institute of Standards and T echnology , 2023. URL https: //dlmf.nist.gov/ . Release 1.1.11 of 2023-09-15. Seohong Park, K e vin Frans, Serge y Levine, and A viral Kumar . Is value learning really the main bot- tleneck in offline RL? In The Thirty-eighth Annual Confer ence on Neural Information Pr ocessing Systems , 2024. URL https://openreview.net/forum?id=nyp59a31Ju . Seohong Park, Qiyang Li, and Serge y Levine. Flow q-learning. In International Confer ence on Machine Learning (ICML) , 2025. Jan Peters and Stefan Schaal. Reinforcement learning by reward-weighted regression for operational space control. In Proceedings of the 24th International Confer ence on Machine Learning , ICML ’07, pp. 745–750, New Y ork, NY , USA, 2007. Association for Computing Machinery . ISBN 9781595937933. DOI: 10.1145/1273496.1273590. URL https://doi.org/10.1145/ 1273496.1273590 . Aaditya Prasad, K evin Lin, Jimmy W u, Linqi Zhou, and Jeannette Bohg. Consistenc y policy: Accelerated visuomotor policies via consistency distillation, 2024. Glenn Shafer and Vladimir V ovk. A tutorial on conformal prediction. Journal of Machine Learning Resear ch , 9(3), 2008. Adam Stooke, Joshua Achiam, and Pieter Abbeel. Responsiv e safety in reinforcement learning by PID lagrangian methods. In Hal Daumé III and Aarti Singh (eds.), Pr oceedings of the 37th International Confer ence on Machine Learning , volume 119 of Pr oceedings of Machine Learning Resear ch , pp. 9133–9143. PMLR, 13–18 Jul 2020. URL https://proceedings.mlr.press/v119/ stooke20a.html . Manan T ayal and Mumuksh T ayal. Epigraph-guided flow matching for safe and performant of fline reinforcement learning. arXiv preprint , 2026. Manan T ayal, Aditya Singh, Shishir Kolathaya, and Somil Bansal. A physics-informed machine learning framew ork for safe and optimal control of autonomous systems. In F orty-second Interna- tional Confer ence on Mac hine Learning , 2025a. URL https://openreview.net/forum? id=SrfwiloGQF . Mumuksh T ayal, Manan T ayal, Aditya Singh, Shishir K olathaya, and Ra vi Prakash. V -ocbf: Learning safety filters from offline data via value-guided of fline control barrier functions. arXiv pr eprint arXiv:2512.10822 , 2025b. Chen T essler , Daniel J Manko witz, and Shie Mannor . Rew ard constrained polic y optimization. In International Confer ence on Learning Repr esentations , 2018. Vladimir V ovk. Conditional validity of inductiv e conformal predictors, 2012. URL https:// arxiv.org/abs/1209.2673 . Y ixuan W ang, Simon Sinong Zhan, Ruochen Jiao, Zhilu W ang, W anxin Jin, Zhuoran Y ang, Zhaoran W ang, Chao Huang, and Qi Zhu. Enforcing hard constraints with soft barriers: Safe reinforcement learning in unknown stochastic en vironments. In International Confer ence on Machine Learning , pp. 36593–36604. PMLR, 2023a. Zhendong W ang, Jonathan J Hunt, and Mingyuan Zhou. Diffusion policies as an e xpressive polic y class for of fline reinforcement learning. The Eleventh International Conference on Learning Repr esentations , 2023b. 15 Haoran Xu, Xianyuan Zhan, and Xiangyu Zhu. Constraints penalized q-learning for safe offline rein- forcement learning. In Pr oceedings of the AAAI Confer ence on Artificial Intelligence , v olume 36, pp. 8753–8760, 2022. Jiazhi Zhang, Y uhu Cheng, C.L. Philip Chen, Hengrui Zhang, and Xuesong W ang. Diffusion policy distillation for of fline reinforcement learning. Neural Networks , 190:107694, 2025a. ISSN 0893-6080. DOI: https://doi.org/10.1016/j.neunet.2025.107694. Shiyuan Zhang, W eitong Zhang, and Quanquan Gu. Energy-weighted flow matching for offline reinforcement learning. In The Thirteenth International Confer ence on Learning Repr esentations , 2025b. URL https://openreview.net/forum?id=HA0oLUvuGI . W eiye Zhao, T airan He, Rui Chen, Tianhao W ei, and Changliu Liu. Safe reinforcement learning: A surve y . arXiv preprint , 2023. Y inan Zheng, Jianxiong Li, Dongjie Y u, Y ujie Y ang, Shengbo Eben Li, Xianyuan Zhan, and Jingjing Liu. Safe of fline reinforcement learning with feasibility-guided diffusion model. In International Confer ence on Learning Repr esentations , 2024. URL https://openreview.net/forum? id=cM95sT3gM3 . 16 Supplementary Materials The following content was not necessarily subject to peer r evie w . A Safety V erification using Conf ormal Calibration A.1 Theorem Theorem (Safety V erification Using Conformal Prediction) Let S δ be the set of states satis- fying V c ( x ) ≤ δ , and let ( x i ) i =1 ,...,N s be N s i.i.d. samples from S δ . Define α δ as the safety error rate among these N s samples for a giv en δ lev el. Select a safety violation parameter ϵ s ∈ (0 , 1) and a confidence parameter β s ∈ (0 , 1) such that: l − 1 X i =0 N s i ϵ i s (1 − ϵ s ) N s − i ≤ β s , (18) where l = ⌊ ( N s + 1) α δ ⌋ . Then, with the probability of at least 1 − β s , the following holds: P x i ∈S δ ( V c ( x i ) < 0) ≥ 1 − ϵ s . (19) The safety error rate α δ is defined as the fraction of samples satisfying V c < δ and V π c ≥ 0 out of the total N s samples. Pr oof. Before we proceed with the proof of the Theorem, let us look at the following lemma which describes split conformal prediction: Lemma 1 (Split Conformal Prediction Angelopoulos & Bates ( 2022 )) . Consider a set of independent and identically distributed (i.i.d.) calibration data, denoted as { ( X i , Y i ) } n i =1 , along with a new test point ( X test , Y test ) sampled independently fr om the same distribution. Define a scor e function s ( x, y ) ∈ R , wher e higher scor es indicate poor er alignment between x and y . Compute the calibration scor es s 1 = s ( X 1 , Y 1 ) , . . . , s n = s ( X n , Y n ) . F or a user-defined confidence level 1 − α , let ˆ q r epr esent the ⌈ ( n + 1)(1 − α ) ⌉ /n quantile of these scor es. Construct the prediction set for the test input X test as: C ( X test ) = { y : s ( X test , y ) ≤ ˆ q } . Assuming exc hangeability , the pr ediction set C ( X test ) guarantees the mar ginal coverag e pr operty: P ( Y test ∈ C ( X test )) ≥ 1 − α. Follo wing the Lemma 1 , we employ a conformal scoring function for safety verification, defined as: s ( X ) = V π c ( x ) , ∀ x ∈ S ˜ δ , where S δ denotes the set of states satisfying V c ( x ) ≤ δ and the score function measures the alignment between the induced safe policy and the auxiliary v alue function. Next, we sample N s states from the safe set S δ and compute conformal scores for all sampled states. For a user -defined error rate α ∈ [0 , 1] , let ˆ q denote the ( N s +1) α N s th quantile of the conformal scores. According to V ovk ( 2012 ), the following property holds: P x i ∈S ˜ δ ( V π c ( x i ) < ˆ q ) ∼ Beta ( N s − l + 1 , l ) , (20) where l = ⌊ ( N s + 1) α ⌋ . 17 Define E s as: E s := P x i ∈S δ ( V π c ( x i ) < ˆ q ) . Here, E s is a Beta-distributed random variable. Using properties of cumulati ve distrib ution functions (CDF), we assert that E s ≥ 1 − ϵ s with confidence 1 − β s if the following condition is satisfied: I 1 − ϵ s ( N − l + 1 , l ) ≤ β s , (21) where I x ( a, b ) is the regularized incomplete Beta function and also serves as the CDF of the Beta distribution. It is defined as: I x ( a, b ) = 1 B ( a, b ) Z x 0 t a − 1 (1 − t ) b − 1 dt, where B ( a, b ) is the Beta function. From Olver et al. ( 2023 )( 8 . 17 . 5 ), it can be shown that I x ( n − k , k + 1) = P k i =1 n i x i (1 − x ) n − i . Then ( 21 ) can be rewritten as: l − 1 X i =1 N s i ϵ i s (1 − ϵ ) N s − i ≤ β s , (22) Thus, if Equation ( 22 ) holds, we can say with probability 1 − β s that: P x i ∈S ˜ δ ( V π c ( x i ) < ˆ q ) ≥ 1 − ϵ s . (23) Now , let k denote the number of allowable safety violations. Thus, the safety error rate is given by α δ = k +1 N s +1 . Let ˆ q represent the ( N s +1) α δ N s th quantile of the conformal scores. Since k denotes the number of samples for which the conformal score is positiv e, the ( N s +1) α δ N s th quantile of scores corresponds to the maximum ne gative scor e amongst the sampled states. This implies that ˆ q ≤ 0 . From this and Equation ( 23 ), we can conclude with probability 1 − β s that: P x i ∈S δ ( V π c ( x i ) < 0) ≥ 1 − ϵ s . And as can be inferred that ∀ x , V c ( x i ) ≤ V π c ( x i ) . Hence, with probability 1 − β s , the following holds: P x i ∈S δ ( V c ( x i )) < 0) ≥ 1 − ϵ s . Algorithm 2 shows the algorithm to implement Safety V erification using Conformal Prediction, which is to be used in Algorithm 1 . A.2 Calibrated δ -values f or V arious Envir onments T able 1: Calibrated Conformal δ = δ ∗ values for Safe Boat Na vigation en vironment and the MuJoCo Safety Gymnasium en vironments used in our experiments. En vironment Boat Hopper HalfCheetah Ant W alker2D Swimmer δ ∗ 0.0 -0.07 0.0 0.0 -0.04 0.0 W e e v aluate the safety and performance of all the test experiments using Conformal Prediction based calibration procedure, the results for which can be referred from Figure 2 . Howe ver , we also report the calibrated δ ∗ values for the these en vironments in the T able 1 for the reader’ s reference. From T able 1 we observ e that most en vironments already achieve reasonably well defined boundaries and hence, there δ ∗ values are equal to 0. Only environments like Hopper and W alker2D have non-zero δ ∗ values which further statistically v alidates the performance of our proposed framework. 18 Algorithm 2 Safety V erification using Conformal Prediction Require: S, N s , β s , ϵ s , V π c ( x i ) , V c ( x i ) , M (number of δ -levels to search for δ ) 1: D 0 ← Sample N s IID states from S δ =0 2: δ 0 ← min ˆ x j ∈ D 0 { V c ( x i ) : V π c ( x i ) ≥ 0 } 3: ϵ 0 ← (14) (using α δ =0 ) 4: ∆ ← Ordered list of M uniform samples from [ δ 0 , 0] 5: for i = 0 , 1 , . . . , M − 1 do 6: while ϵ i ≤ ϵ s do 7: δ i ← ∆ i 8: Update α δ i from δ i 9: ϵ i ← (14) (using α δ i ) 10: end while 11: end for 12: retur n δ ← δ i B Description of the Experiments Figure 5: Illustration of Evaluation En vir onments. (T opLeft): Environment depicts the Safe Boat Navigation task with 2 obstacles and a goal point in a drifting ri ver . (Remaining): En vironments are the standard Safety Gymnasium en vironments ( Ji et al. , 2023 ) from its Safe V elocity suite. B.1 Boat Navigation The 2D Boat state is x ∈ X = [ − 3 , 2] × [ − 2 , 2] , with x = [ x 1 , x 2 ] ⊤ representing the boat’ s Cartesian coordinates ( x 1 , x 2 ) . W e use a dense, distance-based step re ward that encourages progress to ward a fixed goal: r ( x ) = C · − [ x 1 , x 2 ] ⊤ − [ x g 1 , x g 2 ] ⊤ , (24) where the goal is [ x g 1 , x g 2 ] ⊤ = [0 . 5 , 0 . 0] ⊤ and C = 0 . 1 . Maximizing r ( x ) therefore driv es the boat tow ard the goal location. The discrete-time dynamics are giv en by x 1 ,t +1 = x 1 ,t + a 1 ,t + 2 − 0 . 5 x 2 2 ,t ∆ t, x 2 ,t +1 = x 2 ,t + a 2 ,t ∆ t, where ∆ t is the integration timestep, ( a 1 ,t , a 2 ,t ) are the control inputs satisfying a 2 1 ,t + a 2 2 ,t ≤ 1 , and the term 2 − 0 . 5 x 2 2 ,t models the state-dependent longitudinal drift along the x 1 -axis. 19 Obstacles and the failure re gion are encoded via the safety function ℓ ( x ) . W e define ℓ ( x ) using the negati ve of signed distance (plus the obstacle radius) to two circular obstacles: ℓ ( x ) := max 0 . 4 − ∥ x − [ − 0 . 5 , 0 . 5] ⊤ ∥ , 0 . 5 − ∥ x − [ − 1 . 0 , − 1 . 2] ⊤ ∥ . (25) By this definition, ℓ ( x ) > 0 indicates that the boat lies inside an obstacle; the super-le vel set { x : ℓ ( x ) > 0 } therefore defines the failure re gion. Offline data generation. Because this en vironment is custom, we construct an offline dataset for training and ev aluation. W e sample 2 , 500 initial states uniformly from X and simulate each trajectory for 400 discrete timesteps with step size ∆ t = 0 . 005 s. During data collection control inputs are sampled uniformly at random from the admissible action set (subject to the norm constraint), ensuring a wide variety of state–action co verage for downstream learning of safe controllers. B.2 Safety MuJoCo En vironments T o e valuate performance on higher -dimensional systems we use the MuJoCo-based Safety Gymna- sium en vironments Ji et al. ( 2023 ). These environments implement safe velocity tasks in which the agent incurs a cost whenev er its instantaneous velocity exceeds a task-specific threshold. At each step the en vironment provides a binary cost defined by the velocity constraint: cost t = I V current ,t > V threshold , (26) where I [ · ] is the indicator function. Equi v alently , we express safety with the continuous safety function ℓ ( x ) = V current ( x ) − V threshold , (27) so that ℓ ( x ) ≤ 0 corresponds to the safe set. Using ℓ ( x ) provides a dense, continuous safety signal rather than a sparse { 0 , 1 } cost. The per -en vironment threshold v elocities V threshold , integration timeste ps ∆ t , and action-space bounds U are taken from the of ficial documentation; the v alues we used are summarized in T able 2 . T able 2: V elocity thresholds V threshold , timestep ∆ t , and action-space U for the MuJoCo Safety Gymnasium en vironments used in our experiments (values from the of ficial docs). En vironment Hopper HalfCheetah Ant W alker2D Swimmer V threshold 0.7402 3.2096 2.6222 2.3415 0.2282 ∆ t (s) 0.008 0.05 0.05 0.008 0.04 U [ − 1 , 1] 3 [ − 1 , 1] 6 [ − 1 , 1] 8 [ − 1 , 1] 6 [ − 1 , 1] 2 C Additional Results T o V isually compare action sample ef ficiency for the generative policy based methods (FISOR, SafeIFQL and SafeFQL (Ours)), the trajectories across different sample sizes (Figure 6 ) highlights the dif ference. SafeFQL not only achie ves zero collisions across its trajectories, b ut it also reaches closest to the goal among all safe trajectories by the baselines. Furthermore, because SafeFQL circumvents the need for rejection sampling, it preserves its mathematically optimal nature while completely av oiding the computational hassle of multi-action sampling at inference time. 20 3 2 1 0 1 2 x 2 1 0 1 2 y FISOR (N=1) FISOR (N=4) FISOR (N=8) FISOR (N=16) SafeIFQL (N=1) SafeIFQL (N=4) SafeIFQL (N=8) SafeIFQL (N=16) Ours (N=1) Figure 6: Boat Navigation En vironment T rajectory Rollouts for Generative Polic y based Frame- works when diff erent candidate action pool sizes (represented by N) are used. For this plot, we use N ∈ { 1 , 4 , 8 , 16 } for FISOR and SafeIFQL frame works. For SafeFQL, we stick to N=1 as the framew ork doesn’t require action rejection sampling. D Experimental Details D.1 Experimental Hardware T o ensure a f air comparison, all e xperiments were performed on the same system with a 14th-Gen Intel Core i9-14900KS CPU with 64 GB of RAM and an NVIDIA GeForce R TX 5090 GPU, used for both training and ev aluation. D.2 Network Architectur e and T raining Details of the Pr oposed Algorithm W e ha ve compiled and listed do wn all the hyperparameters that we used to perform our experiments and report the results. These training settings for all the environments are detailed in the T able 3 . For the MuJoCo en vironments, we use the widely accepted DSRL Liu et al. ( 2024 ) dataset. During the training, we set the τ for expectile regression in section 3 to 0.9. And we use clipped double Q-learning ( Fujimoto et al. , 2018 ) for both reward and safety Q-critic functions, taking a minimum of the two Q values. W e update the target Q networks using Exponential Moving A verage (EMA) where the weight to the new parameters is set to 0.005. Following K ostrikov et al. ( 2022 ), we clip exponential adv antages to ( −∞ , 100] in feasible part and ( −∞ , 150] in infeasible part. For our paper , we used Flow Q-Learning implementation from Park et al. ( 2025 ). D.3 Hyperparameters for the Baselines Hyperparameters for the remaining safe of fline-RL baselines (COptiDICE, BEAR-Lag, CPQ, C2IQL, FISOR) are listed in T able 4 . W e employ the of ficial implementations of BEAR-Lag, CPQ and COptiDICE from Liu et al. ( 2024 ), C2IQL from LIU et al. ( 2025 ), and FISOR from Zheng et al. ( 2024 ). For SafeIFQL we follo w the hyperparameter choices of Zheng et al. ( 2024 ) ho we ver , Flow- 21 T able 3: Hyperparameters for the Algorithm (SafeFQL). Hyperparameter V alue Network Architecture Multi-Layer Perceptron (MLP) Activ ation Function ReLU Optimizer Adam optimizer Learning Rate 3 × 10 − 4 Discount Factor ( γ ) 0.99 T ime Step Interv als (FM Policy) 10 Boat Navigation Number of Hidden Layers ( Q r , V r , Q c , V c ) 2 Number of Hidden Layers ( π ) 3 Hidden Layer Size (Both) 256 neurons per layer Dataset Size 1M Safe V elocity Hopper Number of Hidden Layers ( Q r , V r , Q c , V c ) 3 Number of Hidden Layers ( π ) 4 Hidden Layer Size (Both) 256 neurons per layer Dataset Size 1.32M Safe V elocity Half-Cheetah Number of Hidden Layers ( Q r , V r , Q c , V c ) 3 Number of Hidden Layers ( π ) 4 Hidden Layer Size (Both) 256 neurons per layer Dataset Size 249K Safe V elocity Ant Number of Hidden Layers ( Q r , V r , Q c , V c ) 3 Number of Hidden Layers ( π ) 4 Hidden Layer Size (Both) 256 neurons per layer Dataset Size 2.09M Safe V elocity W alker2D Number of Hidden Layers ( Q r , V r , Q c , V c ) 3 Number of Hidden Layers ( π ) 4 Hidden Layer Size (Both) 256 neurons per layer Dataset Size 2.12M Safe V elocity Swimmer Number of Hidden Layers ( Q r , V r , Q c , V c ) 3 Number of Hidden Layers ( π ) 4 Hidden Layer Size (Both) 256 neurons per layer Dataset Size 1.68M Matching implementation for its IFQL component is adapted from P ark et al. ( 2025 ). All methods are trained on the same DSRL datasets. 22 T able 4: Detailed Hyperparameters for Baseline Special Networks. (Layers, Units) notation refers to hidden layers and units per layer . All baselines utilize the DSRL dataset standards Liu et al. ( 2024 ). Baseline Network Component Architectur e Specification C2IQL ( LIU et al. , 2025 ) Actor / Critic / V alue Nets MLP , (256, 2) Cost Reconstruction Model MLP , (5 lay ers, 512 units each) Rew ard / Cost Advantage MLP , (256, 2) CPQ ( Xu et al. , 2022 ) Actor (Policy) Net MLP , (256, 2) Constraint-Penalized Q Ensemble DoubleQCritic, (256, 2) Cost Critic Net MLP , (256, 2) FISOR ( Zheng et al. , 2024 ) Diffusion Denoiser (Actor) DiffusionDenoiserMLP , (256, 2) Feasibility Classifier MLP , (256, 2), Sigmoid Output Energy/V alue Guidance MLP , (256, 2) COptiDICE ( Lee et al. , 2022 ) Dual / ν Network DualNet (V alue-lik e), (256, 2) Actor (Extraction) Net MLP , (256, 2) BEAR-Lag (Lag. dual of ( Kumar et al. , 2019 )) V AE (Support Model) MLP , (750, 2) Actor (Policy) Net SquashedGaussianMLP Actor , (256, 2) Cost / Rew ard Critics MLP , (256, 2) 23
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment