Beyond NNGP: Large Deviations and Feature Learning in Bayesian Neural Networks
We study wide Bayesian neural networks focusing on the rare but statistically dominant fluctuations that govern posterior concentration, beyond Gaussian-process limits. Large-deviation theory provides explicit variational objectives-rate functions-on…
Authors: Katerina Papagiannouli, Dario Trevisan, Giuseppe Pio Zitto
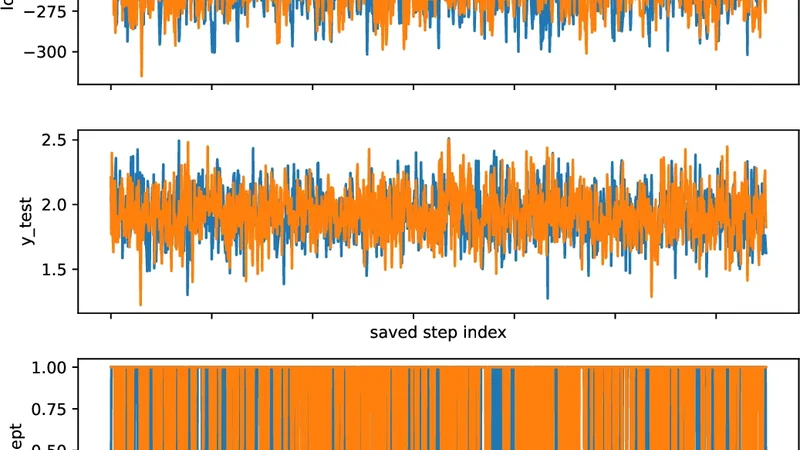
B E Y O N D N N G P : L A R G E D E V I A T I O N S A N D F E A T U R E L E A R N I N G I N B A Y E S I A N N E U R A L N E T W O R K S A P R E P R I N T Katerina Papagiannouli Dipartimento di Matematica Univ ersità di Pisa aikaterini.papagiannouli@unipi.it Dario T re visan Dipartimento di Matematica Univ ersità di Pisa dario.trevisan@unipi.it Giuseppe Pio Zito Dipartimento di Matematica Univ ersità di Pisa g.zito7@studenti.unipi.it February 27, 2026 A B S T R AC T W e study wide Bayesian neural networks focusing on the rare b ut statistically dominant fluctuations that go vern posterior concentration, be yond Gaussian-process limits. Large-de viation theory pro- vides explicit v ariational objectives-rate functions-on predictors, providing an emer ging notion of complexity and feature learning directly at the functional le vel. W e show that the posterior output rate function is obtained by a joint optimization ov er predictors and internal kernels, in contrast with fixed-kernel (NNGP) theory . Numerical experiments demonstrate that the resulting predictions accurately describe finite-width beha vior for moderately sized networks, capturing non-Gaussian tails, posterior deformation, and data-dependent kernel selection ef fects. 1 Intr oduction Bayesian neural networks of fer a principled framework for uncertainty quantification and regularization in modern machine learning. In the ov erparameterized and infinite-width regime, their beha vior is no w well understood: under mild assumptions, wide neural networks con verge to Gaussian processes (NNGPs), and training dynamics remain close to kernel methods described by neural tangent kernels (NTKs). These limits pro vide tractable models and sharp theoretical insights, but the y also exhibit a fundamental rigidity: the induced feature representation becomes fixed and independent of data. As a result, genuine feature learning disappears in the infinite-width limit, and Bayesian inference reduces to kernel regression with a predetermined k ernel. This limitation raises a natural question: which objects govern learning be yond the Gaussian-pr ocess scale? Most existing approaches address this question through training dynamics, mean-field limits, or finite-width corrections. In this work, we take a complementary perspecti ve, by studying Bayesian inference and focusing on posterior concentration in the large-width limit. Our approach is based on large deviations theory . While weak con ver gence results describe typical fluctuations of network outputs, large deviation principles characterize the exponentially unlik ely—but statistically dominant— configurations that control posterior beha vior . At this scale, Bayesian inference becomes v ariational: posterior mass concentrates near minimizers of explicit rate functions defined directly on predictors. These rate functions act as emergent, architecture-dependent comple xity penalties, modified by conditioning on data. The central contribution of this paper is to identify these large-de viation rate functions as learning-rele vant objects. In contrast to NNGP and NTK limits, the resulting variational formulation re veals a mechanism for feature learning e ven in the infinite-width regime. Rather than fixing a kernel in adv ance, posterior concentration selects data-dependent kernels through a nested v ariational principle. Crucially , we argue that the theory is not merely qualitativ e but can be numerically implemented. W e show that the resulting predictions accurately describe finite-width behavior , including non-Gaussian tails, posterior modes, and systematic deviations from NNGP predictions. Beyond NNGP: Lar ge Deviations and Feature Learning in Bayesian Neural Netw orks A P R E P R I N T Contributions. In this work, we provide (i) a v ariational framework for Bayesian learning based on large-de viation rate functions, operating directly at the lev el of predictors; (ii) theoretical explanation of feature learning in wide Bayesian neural networks as a lar ge-deviation phenomenon be yond Gaussian-process limits; (iii) numerical e vidence showing that these rate functions are computable and accurately predict finite-width behavior . Or ganization. Section 2 introduces a general v ariational perspecti ve on Bayesian learning via large de viations. Section 3 connects this viewpoint to learning-theoretic notions such as implicit re gularization, capacity control, and P A C-Bayes theory . Section 4 dev elops the main theoretical results, starting from Gaussian processes and extending to deep Gaussian neural networks. In Section 5 presents numerical experiments v alidating the theory . T echnical proofs and additional numerical details are deferred to the appendix. 2 A variational perspecti ve on Bayesian lear ning W e begin by fixing notation and introducing the probabilistic viewpoint that underlies the paper . W e consider a supervised regression problem with a training dataset D = { ( x i , y i ) } i ∈ D ⊂ R d in × R d out , and a family of predictors h θ : R d in → R d out parametrized by θ . Although learning algorithms are typically formulated in parameter space, prediction, generalization, and uncertainty depend only on the induced functional behavior x 7→ h θ ( x ) . In modern overparameterized models—most notably deep neural networks—many distinct parameter configurations induce essentially the same predictor , moti vating an analysis that operates directly at the lev el of functions rather than parameters. Throughout the paper we focus on wide models , indexed by a width parameter n (e.g., the number of hidden units per layer). For each width n , the predictor h n θ is random, either under a prior distribution on parameters or under the corresponding Bayesian posterior obtained by conditioning on data D . T o describe prediction in a finite-sample setting, we ev aluate the predictor on a fixed finite set of inputs X , containing both training and test points, and consider the resulting random v ector H n := h n θ ( x ) x ∈X . This object takes v alues in a finite-dimensional function space and captures all quantities relev ant for prediction on X . As the width n increases, the distribution of H n usually exhibits strong concentration phenomena: most of the probability mass accumulates near a small set of typical functional behaviors. W eak con ver gence results, such as Gaussian-process limits, characterize typical fluctuations around a mean behavior . Howe ver , such analysis alone discards information about rare but statistically relev ant events. Large deviations theory provides a complementary description, by quantifying the exponential decay of probabilities of atypical configurations. Informally , one expects P ( H n ≈ h ) ≈ exp {− n I ( h ) } , where I is a non-negati ve functional, called the rate function . At a conceptual lev el, it assigns a cost to each functional configuration h , measuring how unlik ely it is to arise from random parameters at large width. Conditioning on data via a n -tempered likelihood exp ( − n L ( H n )) modifies this picture in a particularly transparent way . At the large-de viation scale, Bayesian updating corresponds to adding the empirical loss to the prior rate function, yielding a posterior rate of the schematic form I post ( h ) = I prior ( h ) + L ( h ) (+ constant ) (2.1) where L denotes the loss function, and the additi ve normalization constant ensures that inf I post = 0 . As a consequence, posterior concentration balances data fit and the probabilistic cost encoded by the prior rate. T ypical predictions correspond to minimizers of this effecti ve objectiv e, while uncertainty can be studied through the geometry of the rate function around its minimizers. Focusing on predictions at a test point x test , the v ariational analogue of mar ginalizing the posterior distribution is giv en by the contraction principle, which replaces integration by minimization. As a result, the maximum a posteriori (MAP) prediction reads h ∗ ( x test ) , where h ∗ ∈ arg min h I post ( h ) (2.2) This perspectiv e identifies a concrete object—the functional rate function—that governs both prior and posterior behavior in wide Bayesian models and operates directly at the le vel of predictors. In the remainder of this work, we specialize this frame work to neural networks with Gaussian weights, where these rate functions can be characterized explicitly and computed numerically . 2 Beyond NNGP: Lar ge Deviations and Feature Learning in Bayesian Neural Netw orks A P R E P R I N T 3 Learning-theor etic interpr etation and connections W e ar gued above that posterior concentration in wide Bayesian models is governed by large-de viation rate functions defined directly on predictors. Here we explain how rate functions can be viewed as emergent notions of comple xity and capacity control, providing a bridge between probabilistic modeling and learning-theoretic reasoning. Emer gent comple xity and implicit r e gularization. A central observation is that the prior rate function I prior acts as an intrinsic penalty on functional beha vior . Unlike classical regularization, which is imposed explicitly through design choices, this penalty emerges from concentration of measure in parameter space as the width grows. At the level of macroscopic network behavior , the rate function assigns a cost to each predictor h , quantifying how statistically accessible that behavior is under random (prior) parameterization. This interpretation is consistent with a broad body of work on implicit re gularization in overparameterized models, where generalization is governed by biases induced by the model and training procedure rather than by explicit constraints [ 5 , 9 , 28 ]. Capacity contr ol beyond hypothesis classes. From a learning-theoretic viewpoint, the rate function formalism induces a form of capacity control that dif fers from uniform notions such as VC dimension or global norm constraints. Rather than defining a hard hypothesis class, the rate function induces a non-uniform weighting over functional behaviors. This perspecti ve is particularly natural again in highly o verparameterized settings, where the dimension of parameter space alone provides little information about effecti ve comple xity . Related analyses hav e emphasized geometry- and norm-based notions of capacity o ver parameter counting, highlighting the limitations of classical uniform bounds in modern regimes [ 2 , 3 , 11 , 13 ]. V ariational principles and posterior concentr ation. At the large-de viation scale, Bayesian updating corresponds to a change of measure that adds the empirical loss to the prior rate function. This structure clearly mirrors regularized empirical risk minimization, with a crucial difference: the regularizer is not postulated a priori, but is induced by the stochastic architecture and the probabilistic wide-network limit. From this viewpoint, implicit regularization in Bayesian neural networks can be understood as posterior mass concentrating near minimizers of an emergent, complexity-re gularized objectiv e. Related variational perspectiv es on learning and implicit bias have appeared in mean-field and information-theoretic analyses of neural networks [ 8 , 21 , 24 ]. Connections to P AC-Bayes theory . The variational structure induced by lar ge-deviation rate functions also connects, at least in a conceptual le vel, to P A C-Bayes formulations. In P A C-Bayes theory , generalization guarantees are expressed through a trade-of f between empirical risk and a comple xity term giv en by the Kullback–Leibler di ver gence between posterior and prior distrib utions [ 6 , 7 , 20 ]. Large-de viation principles suggest that, in the wide-netw ork regime, this complexity term ef fectiv ely concentrates on a functional rate ev aluated at the typical predictor induced by the posterior . In this sense, the rate function may be vie wed as a sort of KL-type complexity penalty acting on macroscopic observ ables rather than on distributions ov er parameters. This connection is currently heuristic rather than quantitativ e, and is intended to clarify structure rather than to yield explicit bounds. Related perspectives in neural networks. Infinite-width limits of neural networks leading to Gaussian-process behavior are by now well understood and provide a tractable description of typical fluctuations in wide models [ 17 , 19 , 22 ]. Neural tangent kernel limits further formalize this picture by sho wing that, in certain regimes, training dynamics remain close to a fixed kernel model [ 15 ]. More recent work has explored infinite-width limits that mov e beyond fixed kernels and admit data-dependent kernels capturing aspects of feature learning [ 10 , 16 , 23 , 27 ]. Other works hav e shown that shallow—and more recently deep—neural networks are more accurately characterized by suitable reproducing k ernel Banach spaces, whose norms promote structured sparsity and adapti vity in learned representations [ 4 , 26 , 29 ]. While these approaches characterize the ambient function space associated with a neural architecture, our focus is dif ferent: we study the probabilistic geometry gov erning which functions are statistically dominant in wide Bayesian models. This probabilistic viewpoint complements functional-analytic characterizations and yields concrete predicti ve and numerical consequences. 4 Gaussian Pr ocesses and Gaussian Neural Networks W e specialize the general variational perspecti ve sketched in Section 2 to two models. First, as a warm-up, we consider a fixed Gaussian-process (GP) prior , where the rate function reduces to an RKHS norm. Then, we turn to wide Gaussian neural networks, where we prove that rate functions lead to a joint variational problem over predictors and kernels, providing a tractable mechanism for feature learning. All proofs are deferred to the appendix. 3 Beyond NNGP: Lar ge Deviations and Feature Learning in Bayesian Neural Netw orks A P R E P R I N T GP case – Fixed K ernels. W e fix a finite input set X = x (1) , . . . , x ( m ) ⊆ R d in containing both training and test points, and let H = ( H ( x )) x ∈X ∼ N (0 , κ ) be a centered Gaussian vector with cov ariance matrix κ (for simplicity we present the scalar-output case d in = 1 ). Prior rate . The large-de viation scaling is obtained by introducing H n := 1 √ n H , so that the Gaussian vector induces (by Cramér theorem, see Appendix A ) the prior rate I κ prior ( h ) = 1 2 ∥ h ∥ 2 κ = 1 2 h ⊤ κ + h ∈ [0 , ∞ ] h ∈ R m , (4.1) where κ + denotes the Moore–Penrose pseudoin verse, if h orthogonal to Ker( κ ) , otherwise we set I κ prior ( h ) = ∞ . Equiv alently , ∥ · ∥ κ is the RKHS (extended) norm on X associated with the kernel κ . P osterior rate under quadr atic loss. Write y D = ( y i ) i ∈ D for the train set outputs, and consider the usual quadratic loss. Then, the posterior rate formula ( 2.1 ) reads I κ post ( h ) = 1 2 X i ∈ D ( h ( x i ) − y i ) 2 + 1 2 ∥ h ∥ 2 κ (+ constant ) . (4.2) MAP pr ediction. For a test input x test ∈ X , the prediction ( 2.2 ) for h ∗ becomes explicitly h ∗ ∈ arg min h ∈ R ( 1 2 X i ∈ D ( h ( x i ) − y i ) 2 + 1 2 ∥ h ∥ 2 κ ) . (4.3) Of course, these formulas are equiv alent to the usual GP/RKHS approach, hence an explicit formula for h ∗ is av ailable. Denote by κ DD the restriction of K to training indices, and κ xD the row v ector ( κ ( x, x i )) i ∈ D . Then, the classical GP posterior is H ( x test ) ∼ N ( m ( x test ) , σ 2 ( x test )) , m ( x ) = κ xD ( κ DD + Id) − 1 y D , σ 2 ( x ) = κ ( x, x ) − κ xD ( κ DD + Id) − 1 κ Dx . (4.4) and therefore since MAP and mean coincide for Gaussians, we obtain h ∗ ( x test ) = m ( x test ) . Wide Gaussian Neural Networks – K ernel Selection. W e now mov e to fully connected networks with Gaussian weights and biases. Let L ≥ 2 , d 0 = d in , d L = d out (= 1) , and hidden layers widths d 1 = · · · = d L − 1 = n (all equal for simplicity). For an input x ∈ R d 0 define the forward recursion h (0) ( x ) = x, h ( ℓ ) ( x ) = W ( ℓ ) σ ( ℓ − 1) ( h ( ℓ − 1) ( x )) + b ( ℓ ) , ℓ = 1 , . . . , L, (4.5) with (Lipschitz) activ ation functions acting componentwise, and independent Gaussian parameters according to LeCun scaling W ( ℓ ) ij ∼ N (0 , 1 /d ℓ − 1 ) , b ( ℓ ) j ∼ N (0 , 1) , independently over indices and layers. Fix a input (train/test) set X , and define the empirical layerwise kernels by K ( ℓ ) n ( X ) via K ( ℓ ) n ( x, x ′ ) := 1 n n X j =1 σ ( ℓ ) ( h ( ℓ ) j ( x )) ⊤ σ ( ℓ ) ( h ( ℓ ) j ( x ′ )) , x, x ′ ∈ X , ℓ = 1 , . . . , L − 1 , and K (0) n ( X ) = 1 d 0 X X ⊤ for the input layer . In the wide limit n → ∞ , K ( ℓ ) n con ver ges to a deterministic limit κ ( ℓ ) 0 , the NNGP kernel, that can be recursi vely computed ([ 19 ]). Prior rate for kernels. The point of the LDP approach is to describe the exponential cost of rare deviations a way from κ ( ℓ ) 0 , and to understand ho w the posterior selects atypical kernels. The following reslust w as first obtained in [ 18 ], see also [ 1 ]. Proposition 4.1 (Prior LDP for layerwise kernels; NNGP as unique minimizer) . F ix X and a depth L , and consider the Gaussian network ( 4.5 ) with hidden widths n . F or each ℓ = 1 , . . . , L − 1 , the sequence ( K ( ℓ ) n ( X )) n ≥ 1 satisfies a lar ge-deviation principle with r ate function I ( ℓ ) ( κ ( ℓ ) ) = inf κ ( ℓ − 1) n J σ ( ℓ ) ( κ ( ℓ ) | κ ( ℓ − 1) ) + I ( ℓ − 1) ( κ ( ℓ − 1) ) o , (4.6) wher e J σ ( ℓ ) ( ·| κ ( ℓ − 1) ) is a layer cost – given as a Le gendr e–F enchel transform of the conditional log -MGF of K ( ℓ ) , given K ( ℓ − 1) = κ ( ℓ − 1) . Mor eover , the NNGP kernel κ ( ℓ ) 0 minimizes I ( ℓ ) . Equation ( 4.6 ) is the large-de viation analogue of the forward pass: typical behavior sets κ ( ℓ ) = κ ( ℓ ) 0 , whereas atypical kernels incur a cost accumulated layer -by-layer . Prior rate for outputs. Let H n := 1 √ n ( h θ ( x )) x ∈X be the rescaled output vector . Conditionally on K ( L − 1) n = κ ( L − 1) , the output is Gaussian with cov ariance κ ( L − 1) , hence deviations of H n hav e a conditionally quadratic RKHS-type cost. Such intuition is made rigorous in [ 18 ]. 4 Beyond NNGP: Lar ge Deviations and Feature Learning in Bayesian Neural Netw orks A P R E P R I N T Theorem 4.2 (Prior LDP for outputs) . Under the assumptions of Pr oposition 4.1 , the sequence ( H n ) n ≥ 1 satisfies an LDP with speed n and rate function given by ( ∥ · ∥ κ being the RKHS norm induced by κ ) I ( L ) prior ( h ) = inf κ 1 2 ∥ h ∥ 2 κ + I ( L − 1) ( κ ) . (4.7) Compared to the GP case ( 4.1 ) , the difference is the extra minimization over κ . Thus, even under the prior , outputs deviations H n ≈ h will select a kernel κ ( ℓ ) , ∗ = κ ( ℓ ) , ∗ ( h ) for each hidden layer . P osterior rate. Let D = { ( x i , y i ) } i ∈ D and consider as in the GP case the quadratic loss L ( h ) = 1 2 P i ∈ D ∥ h ( x i ) − y i ∥ 2 2 . W e consider the posterior law via the tempered change of measure, i.e. proportional to exp {− n L ( H n ) } (or equiv alently , a width-dependent in verse temperature). In this situation, we argue that the scaled network outputs H n follow the posterior rate obtained from ( 2.1 ) . The proof is a consequence of V aradhan’ s lemma and is pro vided in Appendix B . Let us point out that a similar argument appears in [ 1 ], for losses that depend uniquely on empirical kernels, not for scaled network outputs. Theorem 4.3 (Posterior LDP for rescaled outputs under quadratic loss) . Under the assumptions of Theor em 4.2 and the temper ed posterior described above, ( H n ) n ≥ 1 satisfies an LDP , with speed n , and r ate function I ( L ) post ( h ) = inf κ ∈ S m + ( 1 2 X i ∈ D ∥ h ( x i ) − y i ∥ 2 2 + 1 2 ∥ h ∥ 2 κ + I ( L − 1) ( κ ) ) (+ constant ) . (4.8) MAP pr ediction and kernel selection. For a test input x test ∈ X , the prediction rate is obtained by contraction principle and the MAP prediction by ( 2.2 ) , which specialized to ( 4.8 ) makes e xplicit a nested optimization structure: prediction jointly selects a predictor h ⋆ ( x test ) but also internal k ernels κ ( ℓ ) , ∗ , depending on data, which we can be intepreted as emergent feature representation. Corollary 4.4 (Posterior -optimal kernel dif fers from the NNGP k ernel) . Assume Theorem 4.3 . The posterior kernel rate, obtained by setting h = h ∗ in the rhs cost in ( 4.8 ) , r eads I ( L − 1) ( κ |D , x test ) = I ( L − 1) ( κ ) + 1 2 y ⊤ D ( κ DD + Id) − 1 y D (4.9) If y D = 0 , the posterior-optimal k ernel κ ⋆ ∈ arg min κ I ( L − 1) ( κ |D , x test ) satisfies κ ⋆ = κ 0 . The posterior rate ( 4.9 ) is obtained by noticing that in the nested optimization leading to y ∗ ( x test ) by exchanging the order, i.e. minimizing first over y , for fixed κ and h ( x D ) = y D , we reduce the problem to the fixed kernel case, hence y ∗ ( x t est ) is the mean prediction ( 4.4 ) and the loss contribution is also explicit. This can be intepreted as follows: the posterior rate selects a data-dependent kernel by trading of f the kernel rarity cost I ( L − 1) ( κ ) against the standard kernel-regression fit term: by this mechanism feature learning appears at the LDP scale, beyond the rigidity of NNGP limits at the weak-con ver gence scale. 5 Numerical Experiments W e demonstrate the theoretical predictions from the large-deviation frame work and assess their relev ance for finite- width neural networks, v alidating that the resulting rate functions are computable, interpretable, and predictive be yond Gaussian approximations. Numerical experiments are conducted in Python using J AX, with the complete codebase shared on GitHub [ 25 ]. While our implementation may be e xtended to support various architectures, we focus on a shallo w case (one hidden layer) for clarity , capturing key phenomena from Sections 2 - 4 . Computations are lightweight and run on standard CPUs, though caution is advised for numerical instabilities. Further diagnostics and stabilization strategies are discussed in Appendix D . Experiment 01: prior and posterior rate functions, LDP-MAP prediction 01A: Prior rate function. W e compute the prior output large-deviation rate function I prior on a one-dimensional output grid to illustrate its geometry . W e consider a single hidden layer network in the wide regime, and two acti vation 5 Beyond NNGP: Lar ge Deviations and Feature Learning in Bayesian Neural Netw orks A P R E P R I N T 1 0 1 2 3 4 y 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 LDP rate P rior LDP rate (R eL U) 1 0 1 2 3 4 y 0 2 4 6 8 LDP rate P rior LDP rate (tanh_heaviside) Fig. 1: Prior output large-deviation rate functions. Prior rate I prior ( y ) as a function of the output y for a wide Gaussian neural network with ReLU (left) and tanh (right) acti vation. 1 0 1 2 3 4 y 0.00 0.25 0.50 0.75 1.00 1.25 1.50 1.75 2.00 LDP rate P osterior vs prior LDP rates (R eL U_heaviside) LDP posterior rate (R eL U_heaviside) LDP prior rate 1 0 1 2 3 4 y 0.0 2.5 5.0 7.5 10.0 LDP rate LDP posterior rate (tanh_heaviside) LDP prior rate Fig. 2: Posterior def ormation of the output large-de viation rate function. Prior and posterior rate functions I prior ( y ) and I post ( y ) at a fixed test input x test = 3 , for a wide Gaussian neural network (left, ReLU activ ation; right tanh activ ation) trained on a Heaviside target functions: σ ( z ) = ReLU( z ) and σ ( z ) = tanh( z ) . Input and output dimensions are d in = d out = 1 . The test input is fixed at x test = 3 . W e compute rate function I prior ( y ) ev aluated on a uniform grid y ∈ [ − 1 , 4] . The results are plotted in Figure 1 . While typical fluctuations are Gaussian at the NNGP scale, the rate function geometry depends strongly on the activ ation function (both in scale and in shape). The ReLU activ ation, being unbounded, leads to a rate function with markedly non-quadratic growth (see also C ), in contrast with the smoother behavior observed for bounded activ ations. 01B: Posterior rate function. The goal is to compute the posterior output large-de viation rate function I post and illustrate how conditioning on data deforms the prior lar ge-deviation geometry . W e consider the same fully connected neural network with a single hidden layer and Gaussian weights as in Experiment 01A. Again we plot both the case of ReLU activ ation function and tanh , for comparison and consistency . The training set consists of samples from a one-dimensional Heaviside target function, ev aluated at the inputs x train ∈ {− 3 , − 2 , − 1 , 0 , 1 , 2 } . Input and output dimensions are d in = d out = 1 , and the test input is fixed at x test = 3 . W e are interested in the posterior output rate function I post ( y ) induced by a quadratic loss, ev aluated on the grid y ∈ [ − 1 , 4] and compared with the corresponding prior rate function. The results are shown in Figure 2 . Conditioning on data induces a nontrivial deformation of the large-de viation landscape: the posterior rate function is shifted and dilated relative to the prior , taking into account the contribution of the loss function. 01C: MAP prediction (mode) as a function of the input. W e compute the large-deviation MAP prediction induced by the posterior rate function, defined for each test input x test the prediction y ∗ ( x test ) as in ( 2.2 ) . W e consider the same 6 Beyond NNGP: Lar ge Deviations and Feature Learning in Bayesian Neural Netw orks A P R E P R I N T 4 3 2 1 0 1 2 3 4 x 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 MAP estimate LDP pr ediction curve (R eL U_heaviside) 4 3 2 1 0 1 2 3 4 x 0.2 0.0 0.2 0.4 0.6 MAP estimate LDP pr ediction curve (T anh_heaviside) Fig. 3: Posterior MAP pr ediction curves. Large-deviation MAP prediction y ∗ ( x test ) as a function of the test input x test , for a wide Gaussian neural network trained on a Heaviside target. Left: ReLU activ ation. Right: tanh activ ation. shallow Gaussian neural network and training set as in Experiment 01B, with ReLU and tanh activ ation functions. Input and output dimensions are d in = d out = 1 . The test input x test is varied o ver a uniform grid x test ∈ [ − 4 , 4] . For each value of x test , the corresponding MAP prediction y ∗ ( x test ) is obtained by minimizing the posterior rate function with respect to the output variable. he resulting prediction curves are shown in Figure 3 . Although the posterior MAP predictor does not interpolate the training data exactly—an expected ef fect giv en the quadratic loss and the limited size of the training set—it captures the qualitativ e monotone transition of the tar get function from 0 to 1 . Differences induced by the activ ation function are clearly visible: the ReLU activ ation produces a steeper transition and does not saturate at 1 , while the tanh activ ation leads to a smoother profile with saturation effects. Experiment 02: LDP versus NNGP (Gaussian) predictions This experiment compares LDP predictions with the fixed-kernel NNGP approximation, highlighting the regimes where Gaussian limits correctly describe typical behavior b ut fail at the lar ge-deviation scale. 02A: Prior rate — LDP versus NNGP quadratic rate W e compare the prior large-deviation rate function with the quadratic rate induced by the Neural Network Gaussian Process (NNGP) limit. W e consider the same architecture and input configuration as in Experiment 01A, restricting to the ReLU acti vation for simplicity . Input and output dimensions are d in = d out = 1 , and the test input is fixed at x test = 3 . W e compute, on the same output grid y ∈ [ − 1 , 4] , the prior large-de viation rate function I LDP prior ( y ) and the quadratic rate I NNGP prior ( y ) = 1 2 ∥ y ∥ 2 κ 0 , where κ 0 denotes the NNGP kernel. In addition, for each output value y we compute the relativ e kernel gap between the kernel κ ⋆ ( y ) ∈ arg min κ I LDP prior ( y ) selected by the LDP variational problem and the NNGP k ernel κ 0 , defined as ∥ κ ⋆ ( y ) − κ 0 ∥ op / ∥ κ 0 ∥ op . The results are sho wn in Figure 4 . The left panel displays the prior LDP rate function together with the quadratic NNGP rate, while the right panel sho ws the corresponding relativ e kernel gap as a function of the output v alue. As expected, the two rates coincide around y = 0 (up to small numerical imprecisions), which is the unique minimizer of the prior rate function. A way from this typical regime, the LDP rate departs from the quadratic approximation and the kernel gap becomes non-zero, indicating that rare output fluctuations are gov erned by non-Gaussian kernel configurations. 02B: Posterior rate — LDP versus NNGP posterior W e compare the posterior large-de viation rate function with the posterior rate induced by Gaussian-process regression using the fixed NNGP kernel. The goal is to assess that Bayesian conditioning does not attenuate non-Gaussian behavior at the lar ge-deviation scale. W e consider the same shallow Gaussian neural network architecture and training set as in Experiment 01B, restricting again to the ReLU activ ation for simplicity . On a common output grid y ∈ [0 , 2] , we compute, the posterior large-de viation rate function and the posterior quadratic rate induced by Gaussian-process regression with the fixed NNGP kernel. In addition, for each output value y we compute the relative k ernel gap similarly as in Experiment 02A. The results are sho wn in Figure 5 . The left panel displays the posterior LDP rate function together with the posterior quadratic rate induced by the NNGP kernel, while the right panel shows the corresponding relati ve k ernel gap. Unlike 7 Beyond NNGP: Lar ge Deviations and Feature Learning in Bayesian Neural Netw orks A P R E P R I N T 1 0 1 2 3 4 y 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 LDP rate LDP rate vs NNGP log-density (prior) NNGP prior log-density 1 0 1 2 3 4 y 0.00 0.25 0.50 0.75 1.00 1.25 1.50 1.75 2.00 k er nel r elative gap Fig. 4: Prior LDP versus NNGP . Left: prior large-deviation rate function compared with the quadratic rate induced by the NNGP kernel. Right: relativ e operator-norm gap between the kernel selected by the LDP v ariational problem and the NNGP kernel. 0.00 0.25 0.50 0.75 1.00 1.25 1.50 1.75 2.00 y 0.0 0.2 0.4 0.6 0.8 1.0 LDP rate LDP rate vs NNGP log-density (posterior) NNGP posterior log-density 0.0 0.5 1.0 1.5 2.0 2.5 3.0 NNGP posterior log-density 0.00 0.25 0.50 0.75 1.00 1.25 1.50 1.75 2.00 y 0.35 0.40 0.45 0.50 0.55 0.60 0.65 0.70 k er nel r elative gap Fig. 5: P osterior LDP versus NNGP . Left: posterior large-deviation rate function compared with the quadratic posterior rate induced by Gaussian-process regression with the NNGP kernel. Right: relati ve operator-norm gap between the kernel selected by the posterior LDP v ariational problem and the NNGP kernel. the prior case in Experiment 02A, the kernel gap is non-zero throughout the output domain. This indicates that posterior concentration selects kernel configurations that differ from the NNGP kernel at all output values, including near the posterior mode. As a result, the posterior large-de viation geometry cannot be captured by a fixed-kernel Gaussian approximation. This behavior reflects genuine feature-learning ef fects that are absent in the NNGP theory . 02C: Predicti ve curve — LDP-MAP versus NNGP posterior mean W e compare the predicti ve behavior induced by the large-de viation posterior with that of the Gaussian-process approximation based on the fixed NNGP kernel. Specifically , we contrast the LDP-MAP predictor with the posterior mean of the NNGP regression model. W e consider the same shallow (ReLU) Gaussian neural netw ork architecture, training set, and loss function as in Experiments 01C and 02B, restricting again to the ReLU acti vation. For each test input x test ∈ [ − 4 , 4] , we compute the large-de viation MAP prediction and the posterior mean prediction induced by Gaussian-process regression with the fix ed NNGP kernel. In addition, along the same grid of test inputs, we compute a kernel-gap diagnostic quantifying the de viation between the kernel selected by the LDP posterior and the NNGP kernel. The results are shown in Figure 6 . The two predictors agree near regions where the posterior geometry remains close to the Gaussian regime. Ho wev er , systematic discrepancies appear as the test input moves a way from the training set, in correspondence with non-negligible kernel gaps. This confirms that predictiv e differences between LDP and NNGP formulations are directly associated with kernel-selection effects arising at the large-de viation scale, rather than with finite-width noise. 8 Beyond NNGP: Lar ge Deviations and Feature Learning in Bayesian Neural Netw orks A P R E P R I N T 4 3 2 1 0 1 2 3 4 x 0.00 0.25 0.50 0.75 1.00 1.25 1.50 MAP estimate LDP vs NNGP pr ediction (R eL U, gamma = 1) LDP pr ediction NNGP pr ediction 4 3 2 1 0 1 2 3 4 x 0.4 0.5 0.6 0.7 0.8 0.9 k er nel r elative gap Fig. 6: Predictiv e curves: LDP-MAP versus NNGP . Left: large-de viation MAP prediction compared with the NNGP posterior mean as a function of the test input. Right: kernel-gap diagnostic along the same input grid, quantifying deviations from the fix ed NNGP kernel. 4 3 2 1 0 1 2 3 4 y 0.0 0.2 0.4 0.6 0.8 t a i l r a t e ( 1 / w ) l o g P ( ) P rior tails vs LDP (R eL U) MC tail (w=32) MC tail (w=64) MC tail (w=128) MC tail (w=256) LDP tail envelope 2.0 1.5 1.0 0.5 0.0 0.5 1.0 1.5 2.0 0.0 0.2 0.4 0.6 0.8 1.0 Estimated densities vs LDP (linear k er nel, R eL U) shape e xp(-w(I-min)), w=256 MC (w=32) hist MC (w=64) hist MC (w=128) hist MC (w=256) hist 0.0 0.5 1.0 1.5 2.0 2.5 3.0 density (MC / implied) Fig. 7: Prior tails: Monte Carlo versus LDP . Left: empirical tail decay rates − 1 n log ˆ p n ( y ) for increasing widths compared with the prior large-de viation rate function. Right: empirical output histograms compared with the heuristic density ∝ exp( − n I prior ( y )) . 5.1 Experiment 03: finite-width validation via Monte Carlo W e finally compare LDP predictions to Monte Carlo simulations of finite-width networks. The focus is on v alidating large-de viation scaling for the prior and posterior concentration 03A: prior tails — empirical decay vs LDP rate W e verify that the LDP prior rate function gov erns the decay of empirical tail probabilities as width increases. W e sample from finite-width randomly LeCun initialized netw orks at widths n ∈ { 32 , 64 , 128 , 256 } and empirically estimate the tail probabilities ˆ p n ( y ) = P ( 1 √ n h n θ ( x test ) ≥ y ) (for positiv e y , and ≤ y for negati ve side). W e then compare empirical rates − 1 n log ˆ p n ( y ) with I prior ( y ) . The total number of Monte Carlo samples is 10 7 for each width, and when no samples are observ ed in the tail region for a gi ven width and threshold, the corresponding empirical probability is not reported. The results are shown in Figure 7 , panel left. The left panel displays empirical tail rates for increasing widths together with the theoretical LDP prior rate function. As the width increases, the empirical tail rates progressiv ely align with the LDP prediction, providing evidence that the prior output distribution obe ys the large-de viation scaling predicted by the theory . 03B: Posterior samples — MC vs LDP and NNGP . W e compare finite-width posterior samples with the posterior geometry predicted by the large-de viation principle and by the fixed-k ernel NNGP approximation. W e consider the same shallo w Gaussian neural network with ReLU acti vation and the Hea viside training set as in Experiments 01B–02C. Finite-width posterior samples are generated at width n = 128 using a n -temper ed likelihood , so that the posterior concentrates at the large-de viation scale. Sampling is performed using the Metropolis-adjusted Langevin algorithm (MALA), which we found to provide more reliable con vergence than SGLD in this lo w-dimensional setting. Diagnostics 9 Beyond NNGP: Lar ge Deviations and Feature Learning in Bayesian Neural Netw orks A P R E P R I N T 0.5 1.0 1.5 2.0 2.5 3.0 y 0.7 0.8 0.9 1.0 1.1 1.2 I(y) P osterior : LDP vs MC (LDP scaling, n-temper ed) vs NNGP (Gaussian) LDP curve MC samples NNGP mean 0.0 0.5 1.0 1.5 2.0 MC density 0.5 1.0 1.5 2.0 2.5 3.0 y 0.7 0.8 0.9 1.0 1.1 1.2 I(y) P osterior : LDP vs MC (NNGP scaling, standar d) vs NNGP (Gaussian) LDP curve MC samples NNGP mean 0.0 0.1 0.2 0.3 0.4 0.5 MC density Fig. 8: Posterior samples: MC vs LDP and NNGP . Finite-width posterior samples at n = 128 for a ReLU network trained on a Heaviside tar get. Left: n -tempered (LDP) scaling, showing concentration around the LDP-MAP prediction. Right: standard NNGP scaling on the same x -axis, showing much broader Gaussian fluctuations centered at the NNGP posterior mean. and additional implementation details are reported in Appendix D . Samples of the output h θ ( x test ) are collected at a fixed test input x test = 5 , which is chosen to exhibit wider discrepanc y between NNGP and LDP modes. W e compare tw o scalings: (i) the LDP scaling, for which the posterior rate function I post predicts concentration at speed n of posterior samples of 1 √ n h n θ ( x test ) ; (ii) the standard NNGP scaling, corresponding to fix ed-kernel Gaussian-process regression. W e overlay the posterior LDP rate function (shown as an energy curve) and the NNGP posterior mean prediction. Under LDP scaling, the empirical posterior exhibits strong concentration around a mode that is accurately predicted by the LDP-MAP estimator . Numerically , we observe mean = 1 . 936 , std = 0 . 187 , with an av erage MALA acceptance rate of 0 . 75 across chains. In contrast, under standard NNGP scaling the posterior distribution has mean = 1 . 879 , std = 1 . 977 , hence shifted and much broader (with acceptance rate 0 . 82 ). The results are shown in Figure 8 . 6 Conclusion W e ha ve sho wn that large-de viations provide a principled v ariational frame work for understanding Bayesian learning in wide neural networks beyond Gaussian-process limits. Our numerics demonstrate that these effects are visible at moderate widths. Natural directions for future work include scaling the numerical framework to larger datasets, systematic benchmarking against fix ed-kernel and Bayesian neural network baselines, and extending the theoretical analysis to more structured architectures. 7 Acknowledgments D.T . thanks the HPC Italian National Centre for HPC, Big Data and Quantum Computing - Proposal code CN1 CN00000013, CUP I53C22000690001, the PRIN 2022 Italian grant 2022-WHZ5XH - “understanding the LEarning process of Q Uantum Neural networks (LeQun)”, CUP J53D23003890006, the project G24-202 “V ariational methods for geometric and optimal matching problems” funded by Univ ersità Italo Francese. D.T . and K.P . acknowledge the partial support of the project PNRR - M4C2 - In vestimento 1.3, Partenariato Esteso PE00000013 - “F AIR - Future Artificial Intelligence Research” - Spoke 1 “Human-centered AI”, funded by the European Commission under the Ne xtGeneration EU programme, and the MUR Excellence Department Project awarded to the Department of Mathematics, Uni versity of Pisa, CUP I57G22000700001, 10 Beyond NNGP: Lar ge Deviations and Feature Learning in Bayesian Neural Netw orks A P R E P R I N T Refer ences [1] Luisa Andreis, Federico Bassetti, and Christian Hirsch. Ldp for the cov ariance process in fully connected neural networks. arXiv preprint , 2025. [2] Peter L Bartlett, Dylan J Foster , and Matus J T elgarsky . Spectrally-normalized margin bounds for neural networks. Advances in neural information pr ocessing systems , 30, 2017. [3] Peter L Bartlett, Philip M Long, Gábor Lugosi, and Alexander Tsigler . Benign ov erfitting in linear regression. Pr oceedings of the National Academy of Sciences , 117(48):30063–30070, 2020. [4] Francesca Bartolucci, Ernesto De V ito, Lorenzo Rosasco, and Stefano V igogna. Understanding neural networks with reproducing kernel banach spaces. Applied and Computational Harmonic Analysis , 62:194–236, 2023. [5] Mikhail Belkin, Daniel Hsu, Siyuan Ma, and Soumik Mandal. Reconciling modern machine-learning practice and the classical bias–v ariance trade-off. Pr oceedings of the National Academy of Sciences , 116(32):15849–15854, 2019. [6] Ioar Casado, Luis A Ortega, Aritz Pérez, and Andrés R Masegosa. Pac-bayes-chernof f bounds for unbounded losses. Advances in Neural Information Pr ocessing Systems , 37:24350–24374, 2024. [7] Olivier Catoni. Pac-bayesian supervised classification: the thermodynamics of statistical learning. arXiv pr eprint arXiv:0712.0248 , 2007. [8] Lenaic Chizat and Francis Bach. On the global con vergence of gradient descent for ov er-parameterized models using optimal transport. Advances in neural information pr ocessing systems , 31, 2018. [9] Lenaic Chizat and Francis Bach. Implicit bias of gradient descent for wide two-layer neural networks trained with the logistic loss. In Confer ence on learning theory , pages 1305–1338. PMLR, 2020. [10] Lénaïc Chizat, Maria Colombo, Xa vier Fernández-Real, and Alessio Figalli. Infinite-width limit of deep linear neural networks. Communications on Pure and Applied Mathematics , 77(10):3958–4007, 2024. [11] Massimiliano Datres, Gian P Leonardi, Alessio Figalli, and Da vid Sutter . A two-scale complexity measure for deep learning models. Advances in Neural Information Pr ocessing Systems , 37:23013–23039, 2024. [12] A. Dembo and O. Zeitouni. Lar ge Deviations T echniques and Applications . Stochastic Modelling and Applied Probability . Springer Berlin Heidelberg, 2009. ISBN 9783642033117. URL https://books.google.it/ books?id=iT9JRlGPx5gC . [13] Gintare Karolina Dziugaite and Daniel M Ro y . Computing non v acuous generalization bounds for deep (stochastic) neural networks with many more parameters than training data. arXiv pr eprint arXiv:1703.11008 , 2017. [14] Richard S Ellis. Entr opy , larg e deviations, and statistical mechanics , v olume 271. Springer Science & Business Media, 2012. [15] Arthur Jacot, Franck Gabriel, and Clément Hongler . Neural tangent kernel: Con vergence and generalization in neural networks. Advances in neural information pr ocessing systems , 31, 2018. [16] Clarissa Lauditi, Blake Bordelon, and Cengiz Pehlev an. Adaptiv e kernel predictors from feature-learning infinite limits of neural networks. arXiv preprint , 2025. [17] Jaehoon Lee, Y asaman Bahri, Roman Nov ak, Samuel S. Schoenholz, Jeffre y Pennington, and Jascha Sohl- Dickstein. Deep Neural Networks as Gaussian Processes. February 2018. URL https://openreview.net/ forum?id=B1EA- M- 0Z . [18] Claudio Macci, Barbara Pacchiarotti, and Giovanni Luca T orrisi. Large and moderate deviations for gaussian neural networks. arXiv preprint , 2024. [19] Alexander G. de G. Matthe ws, Jiri Hron, Mark Rowland, Richard E. T urner , and Zoubin Ghahramani. Gaussian Process Behaviour in W ide Deep Neural Networks. February 2018. URL https://openreview.net/forum? id=H1- nGgWC- . [20] David A McAllester . Pac-bayesian model averaging. In Pr oceedings of the twelfth annual conference on Computational learning theory , pages 164–170, 1999. [21] Song Mei, Andrea Montanari, and Phan-Minh Nguyen. A mean field view of the landscape of tw o-layer neural networks. Proceedings of the National Academy of Sciences , 115(33):E7665–E7671, 2018. [22] Radford M. Neal. Priors for Infinite Networks. In Radford M. Neal, editor, Bayesian Learning for Neural Networks , Lecture Notes in Statistics, pages 29–53. Springer , Ne w Y ork, NY , 1996. ISBN 978-1-4612-0745-0. doi: 10.1007/978- 1- 4612- 0745- 0_2. URL https://doi.org/10.1007/978- 1- 4612- 0745- 0_2 . 11 Beyond NNGP: Lar ge Deviations and Feature Learning in Bayesian Neural Netw orks A P R E P R I N T [23] Rosalba Pacelli, Sebastiano Ariosto, Mauro Pastore, Francesco Ginelli, Marco Gherardi, and Pietro Rotondo. A statistical mechanics frame work for bayesian deep neural networks beyond the infinite-width limit. Natur e Machine Intelligence , 5(12):1497–1507, 2023. [24] Naftali Tishby and Noga Zaslavsky . Deep learning and the information bottleneck principle. In 2015 ieee information theory workshop (itw) , pages 1–5. Ieee, 2015. [25] Dario Tre visan, Katerina Papagiannouli, and Giuseppe Pio Zito. ldnn: Large deviations for neural networks, 2026. URL https://github.com/DarioTrevisan/ldnn . J AX-based solvers for prior , posterior , and mode large-de viation rate functions. [26] Rui W ang, Y uesheng Xu, and Mingsong Y an. Sparse representer theorems for learning in reproducing kernel banach spaces. Journal of Mac hine Learning Resear ch , 25(93):1–45, 2024. [27] Greg Y ang and Edward J Hu. T ensor programs iv: Feature learning in infinite-width neural networks. In International Confer ence on Machine Learning , pages 11727–11737. PMLR, 2021. [28] Chiyuan Zhang, Samy Bengio, Moritz Hardt, Benjamin Recht, and Oriol V inyals. Understanding deep learning requires rethinking generalization. In International Confer ence on Learning Repr esentations , 2017. [29] Haizhang Zhang, Y uesheng Xu, and Jun Zhang. Reproducing kernel banach spaces for machine learning. Journal of Machine Learning Resear ch , 10(12), 2009. A A short guide to large-de viation calculus Large deviations theory provides a systematic description of rar e events , namely ev ents whose probabilities decay exponentially with a scale parameter . Throughout this appendix, we present an informal and calculus-oriented introduction, mirroring familiar notions from elementary probability theory . Standard references include [ 12 , 14 ]. Large de viation principle. Let ( Z n ) n ≥ 1 be random v ariables taking values in a fixed Euclidean space R d . W e say that ( Z n ) satisfies a larg e deviation principle (LDP) with speed β n → ∞ and rate function r : R d → [0 , ∞ ] (lower semicontinuous with compact lev el sets) if, for ev ery Borel set A , inf z ∈ A ◦ r ( z ) ≤ lim inf n →∞ − 1 β n log P ( Z n ∈ A ) ≤ lim sup n →∞ − 1 β n log P ( Z n ∈ A ) ≤ inf z ∈ A r ( z ) , where A ◦ and A denote the interior and closure of A . Heuristically , this is often summarized as P ( Z n ∈ A ) ≈ exp − β n r ( A ) , r ( A ) := inf z ∈ A r ( z ) . The rate function thus provides a “skeleton” of the probability la w , encoding which configurations are exponentially more likely than others. Idempotent viewpoint. A useful intuition is that lar ge deviations obe y the algebra of idempotent (or tr opical) pr obability , where addition and multiplication are replaced by min and + . This perspective becomes transparent through the Laplace–V aradhan principle: for ev ery bounded continuous φ : R d → R , lim n →∞ − 1 β n log E exp − β n φ ( Z n ) = min z ∈ R d φ ( z ) + r ( z ) . (A.1) The right-hand side is the idempotent analogue of an expectation. Motiv ated by this analogy , it is conv enient to introduce a formal idempotent random variable Z and write r ( Z = z ) = r ( z ) . W e may then define the idempotent expectation of φ ( Z ) as follo ws min z φ ( z ) + r ( Z = z ) . Definition A.1 (LDP con ver gence) . W e say that Z n con ver ges to Z in the LDP sense with speed β n , and write Z n β n → Z , if for ev ery bounded continuous φ , lim n →∞ − 1 β n log E exp − β n φ ( Z n ) = min z φ ( z ) + r ( Z = z ) . (A.2) This notion plays the role of con ver gence in law for rare-e vent asymptotics. 12 Beyond NNGP: Lar ge Deviations and Feature Learning in Bayesian Neural Netw orks A P R E P R I N T Basic calculus rules. Many standard probabilistic constructions admit direct idempotent analogues. 1. Normalization. Setting φ ≡ 0 in ( A.2 ) yields min z r ( z ) = 0 , the idempotent analogue of total mass one. Accordingly , writing r ( Z ) ∝ f means r ( Z = z ) = f ( z ) − min u f ( u ) , mirroring normalization of probability densities. 2. Change of measure . If Z n β n → Z and we tilt the law of Z n by exp( − β n ℓ ( z )) , where ℓ is bounded and continuous, then the LDP still holds with modified rate ˜ r ( Z = z ) ∝ r ( Z = z ) + ℓ ( z ) . This is the LDP analogue of stability of weak con ver gence under bounded Radon–Nikodym deri vati ves. 3. Contraction principle. If Z n β n → Z and g : R d → R m is continuous, then g ( Z n ) β n → g ( Z ) with rate r g ( Z ) = y = min z : g ( z )= y r ( Z = z ) . This replaces marginalization by minimization. 4. Conditional LDP (Chaganty-type). If X n β n → X and Y n satisfies an LDP conditionally on X n = x n for ev ery x n → x , then ( X n , Y n ) β n → ( X , Y ) with r ( X = x, Y = y ) = r ( X = x ) + r ( Y = y | X = x ) . 5. Gärtner–Ellis theor em. If the limit ˆ r ( λ ) = lim n →∞ 1 β n log E h e β n ⟨ λ,Z n ⟩ i exists, is finite in a neighborhood of 0 , and is dif ferentiable there, then Z n β n → Z with rate r ( Z = z ) = ˆ r ∗ ( z ) = sup λ ∈ R d ⟨ λ, z ⟩ − ˆ r ( λ ) . This is the LDP analogue of Lévy’ s continuity theorem. 6. Cramér’ s theorem. For empirical means ¯ X n = 1 n P n i =1 X i of i.i.d. variables, with MGF E e ⟨ λ,X ⟩ finite in a neighbourhood of λ = 0 , r ( ¯ X = x ) = sup λ n ⟨ λ, x ⟩ − log E e ⟨ λ,X ⟩ o , the rare-ev ent counterpart of the law of lar ge numbers and central limit theorem. T aken together , these rules form a compact “large-de viation calculus” in which probabilistic operations are replaced by variational ones. This viewpoint underlies the v ariational formulations used throughout the paper . B Pr oofs of the main large-deviation statements This appendix collects concise proofs (or proof sketches when the result is taken from the literature) for the statements in the main body . Throughout we work on a fix ed finite input set X (containing training and test inputs) and identify kernels with PSD matrices in S |X | + . W e use the “lar ge-deviation calculus” notation from Appendix A : for a sequence ( Z n ) n we write Z n β n → Z and r ( Z = z ) for the associated rate function. B.1 Prior LDP f or layerwise ker nels (sketch fr om [ 18 ]) W e recall the kernel recursion for Gaussian MLPs. For ℓ ≥ 1 , define the empirical kernel at layer ℓ on X by K ( ℓ ) n ( X ) := 1 n n X j =1 σ ( ℓ ) ( h ( ℓ ) j ( X )) ⊗ 2 ∈ S |X | + , 13 Beyond NNGP: Lar ge Deviations and Feature Learning in Bayesian Neural Netw orks A P R E P R I N T where h ( ℓ ) j ( X ) ∈ R |X | denotes the j -th neuron pre-activ ation vector restricted to X and v ⊗ 2 = v v ⊤ . Under LeCun scaling, conditional on K ( ℓ − 1) n ( X ) = κ , the vectors h ( ℓ ) j ( X ) are i.i.d. Gaussian with co variance κ . In particular , K ( ℓ ) n ( X ) { K ( ℓ − 1) n ( X ) = κ } law = 1 n n X j =1 Ξ ( ℓ ) j ( κ ) , Ξ ( ℓ ) j ( κ ) := σ ( ℓ ) ( √ κ N j ) ⊗ 2 , (B.1) with ( N j ) j i.i.d. N (0 , I |X | ) . Conditional LDP and the layer cost. For fixed κ , ( B.1 ) is an empirical mean of i.i.d. matrices, hence Cramér/Gärtner– Ellis yields an LDP at speed n with conditional rate given by the Legendre–Fenchel transform of the conditional log-MGF: J σ ( ℓ ) ( κ ′ | κ ) := sup Λ ∈ S |X | n ⟨ Λ , κ ′ ⟩ − log E exp ⟨ Λ , Ξ ( ℓ ) 1 ( κ ) ⟩ o , κ ′ ∈ S |X | + . (B.2) Induction and joint LDP . Assume inducti vely that K ( ℓ − 1) n ( X ) n → K ( ℓ − 1) ( X ) with rate I ( ℓ − 1) . Under mild regularity , the conditional LDP in κ abov e is continuous in the sense of Chaganty’ s theorem (Appendix A ), and yields a joint LDP for K ( ℓ − 1) n ( X ) , K ( ℓ ) n ( X ) with joint rate I ( ℓ − 1) ( κ ) + J σ ( ℓ ) ( κ ′ | κ ) . By contraction onto the second coordinate we obtain the recursion I ( ℓ ) ( κ ′ ) = inf κ ∈ S |X | + n I ( ℓ − 1) ( κ ) + J σ ( ℓ ) ( κ ′ | κ ) o , (B.3) which is ( 4.6 ) . This argument (and the required regularity conditions) is carried out in detail in [ 18 ], see also [ 1 ]. In particular , the unique minimizer is the NNGP kernel κ ( ℓ ) 0 , characterized by the law-of-large-numbers fix ed-point recursion. B.2 Prior LDP f or outputs (sketch from [ 18 ]) Let H n := 1 √ n h θ ( x ) x ∈X ∈ ( R d out ) |X | . Conditional on K ( L − 1) n ( X ) = κ , the output is Gaussian with co variance κ (componentwise in R d out ). Consequently , conditional large de viations of H n hav e the quadratic rate r H = h K ( L − 1) = κ = 1 2 ∥ h ∥ 2 κ , (B.4) where ∥ · ∥ κ denotes the (finite-dimensional) RKHS norm induced by κ on X , applied componentwise. Combining ( B.4 ) with the kernel LDP at layer L − 1 and applying Chaganty’ s theorem plus contraction yields the unconditional output rate I ( L ) prior ( h ) = inf κ ∈ S |X | + n 1 2 ∥ h ∥ 2 κ + I ( L − 1) ( κ ) o , (B.5) which is ( 4.7 ). A complete proof appears in [ 18 ]. B.3 Posterior LDP under temper ed quadratic loss W e no w prove Theorem 4.3 from Theorem 4.2 by a change-of-measure ar gument. Lemma B.1 (Change of measure / Bayes rule for LDP) . Let Z n be random variables taking values in R d for some d ≥ 1 , and assume Z n β n → Z with rate function r ( Z = · ) . Let ℓ : R d → R be bounded and continuous and define the tilted laws d e P n d P n ( z ) = exp {− β n ℓ ( z ) } E P n [exp {− β n ℓ ( Z n ) } ] . Then under e P n , Z n satisfies an LDP at speed β n with rate e r ( Z = z ) = ℓ ( z ) + r ( Z = z ) − inf u ℓ ( u ) + r ( Z = u ) . 14 Beyond NNGP: Lar ge Deviations and Feature Learning in Bayesian Neural Netw orks A P R E P R I N T Pr oof. For an y bounded continuous φ on R d , − 1 β n log e E n h e − β n φ ( Z n ) i = − 1 β n log E n e − β n ( φ + ℓ )( Z n ) E n e − β n ℓ ( Z n ) . Apply V aradhan’ s lemma to the numerator and denominator and subtract the limits, yielding inf z { φ ( z ) + ℓ ( z ) + r ( z ) } − inf z { ℓ ( z ) + r ( z ) } . This is exactly the LDP in the form of V aradhan-Laplace principle with rate e r . Pr oof of Theor em 4.3 . Apply Lemma B.1 to Z n = H n with speed β n = n and ℓ ( h ) = L ( h ) := 1 2 X i ∈ D ∥ h ( x i ) − y i ∥ 2 2 , corresponding to the tempered posterior density proportional to exp {− n L ( H n ) } with respect to the prior law of H n . Since H n n → H under the prior with rate I ( L ) prior by Theorem 4.2 , Lemma B.1 giv es the posterior rate I ( L ) post ( h ) = L ( h ) + I ( L ) prior ( h ) − inf u {L ( u ) + I ( L ) prior ( u ) } . Substituting ( 4.7 ) into the right-hand side yields I ( L ) post ( h ) = inf κ ∈ S |X | + ( 1 2 X i ∈ D ∥ h ( x i ) − y i ∥ 2 2 + 1 2 ∥ h ∥ 2 κ + I ( L − 1) ( κ ) ) + ( additive constant ) , which is ( 4.8 ). Remark B.2. Although we prov ed Theorem 4.3 only for bounded loss functions, the quadratic case follows along the same lines, from a refined v ersion of V aradhan-Laplace principle, [ 12 , Theorem 4.3.1], which allo ws for unbounded continuous functions, provided an exponential tail condition is satisfied, which holds true in the quadratic (and more generally non-neg ativ e) cases. Hence, the posterior rate function is obtained by adding the loss to the prior rate function, up to normalization exactly as in ( 4.8 ). B.4 K ernel selection and separation fr om NNGP W e now prove Corollary 4.4 . For clarity we present the argument for d out = 1 ; the matrix-valued case follows by replacing quadratic forms by traces. Pr oof of Cor ollary 4.4 . Fix κ ∈ S |X | + and consider the inner minimization problem appearing in ( 4.8 ): inf h : X → R ( 1 2 X i ∈ D ( h ( x i ) − y i ) 2 + 1 2 ∥ h ∥ 2 κ ) . By the representer theorem on the finite set X , the minimizer has the form h ( · ) = P j ∈ D α j κ ( · , x j ) , i.e. h = κ · D α . Writing K := κ DD , k x := κ xD , we hav e ∥ h ∥ 2 κ = α ⊤ K α , h D = K α. Therefore the objectiv e becomes, as a function of α , 1 2 ∥ K α − y D ∥ 2 2 + 1 2 α ⊤ K α. This is strictly con ve x on Ran( K ) and its minimizer satisfies ( K + Id) K α = K y D = ⇒ ( K + Id) α = y D on Ran( K ) , hence we may take α = ( K + Id) − 1 y D (interpreting the in verse as the Moore–Penrose in verse if needed). Plugging back yields the minimal value inf h ( 1 2 X i ∈ D ( h ( x i ) − y i ) 2 + 1 2 ∥ h ∥ 2 κ ) = 1 2 y ⊤ D ( K + Id) − 1 y D . 15 Beyond NNGP: Lar ge Deviations and Feature Learning in Bayesian Neural Netw orks A P R E P R I N T Consequently , after minimizing out h , the κ -dependent posterior objectiv e becomes I ( L − 1) ( κ ) + 1 2 y ⊤ D ( κ DD + Id) − 1 y D , which is exactly ( 4.9 ) (up to an additi ve constant independent of κ ). Finally , let κ 0 be the unique minimizer of I ( L − 1) (the NNGP k ernel). If y D = 0 , the map κ 7→ 1 2 y ⊤ D ( κ DD + Id) − 1 y D is strictly decr easing along positive semidefinite directions, hence it is not constant in any neighborhood of κ 0 . Therefore κ 0 cannot minimize the sum unless the data-term is identically constant, which only happens for y D = 0 . Thus any posterior-optimal k ernel κ ⋆ satisfies κ ⋆ = κ 0 . The computation abov e is the precise form of the “min–min exchange” discussed in the main text: the posterior selects κ by minimizing a kernel-le vel objectiv e obtained after eliminating h (equiv alently , the dual v ariables α ). This makes explicit that, unlike GP re gression with fixed kernel, the LDP posterior performs an implicit k ernel selection step. C Linear activ ation: explicit large-de viation formulas This appendix illustrates the large-de viation frame work in the simplest analytically tractable setting: linear acti vation functions and a single input. While overly simplistic from a modeling perspecti ve, this case provides e xplicit formulas that clarify the structure of kernel and output rate functions and explain the non-quadratic geometries observed numerically in Section 5 . Throughout, we consider the linear activ ation σ ( x ) = √ a x, a > 0 , and adopt the notation and layer indexing of the main te xt. Prior rate function for lay er -wise kernels Let K ( ℓ ) denote the random kernel at layer ℓ , and let I ( ℓ ) ( κ ) := r K ( ℓ ) = κ denote its prior lar ge-deviation rate function. W e work in the single-input setting, so kernels reduce to non-ne gativ e scalars κ ∈ R + . For linear acti v ation, the conditional log-moment generating function can be computed explicitly , yielding the Legendre transform J ( κ | κ 0 ) = sup λ ∈ R λκ + 1 2 log 1 − 2 λaκ 0 . (C.1) Stationarity giv es κ = aκ 0 1 − 2 λaκ 0 , and substitution yields the explicit formula J ( κ | κ 0 ) = 1 2 κ aκ 0 − log κ aκ 0 − 1 . (C.2) Shallow case ( L = 1 ). For a single hidden layer , the kernel rate function coincides with J ∗ : I (1) ( κ ) = 1 2 h κ aκ (0) − log κ aκ (0) − 1 i . (C.3) This function is con ve x, with a unique minimum at κ = aκ (0) , corresponding to the NNGP kernel. Deeper networks. For depth L ≥ 2 , the kernel rate functions satisfy the recursiv e variational relation I ( ℓ ) ( κ ) = inf κ ′ n I ( ℓ − 1) ( κ ′ ) + Φ ∗ ( κ | κ ′ ) o . This recursion can be solved e xplicitly by induction. 16 Beyond NNGP: Lar ge Deviations and Feature Learning in Bayesian Neural Netw orks A P R E P R I N T Theorem C.1 (Explicit kernel rate functions for linear activ ation) . Assume linear activation σ ( x ) = √ a x and a single input. Then for every depth L ≥ 1 and κ ≥ 0 , I ( L ) ( κ ) = L 2 κ a L κ (0) 1 /L − log κ a L κ (0) 1 /L − 1 . (C.4) The function I ( L ) has a unique global minimum at κ = a L κ (0) . F or L > 1 , it is not globally con vex. This loss of con ve xity reflects the increasing flexibility of kernel fluctuations as depth grows and foreshadows the non-quadratic behavior of output rate functions. Prior rate function f or the network output W e no w turn to the prior large-de viation rate function of the netw ork output. In the single-input, scalar-output setting, this reduces to a function I ( L ) prior ( y ) with y ∈ R . Shallow case ( L = 1 ). Using ( C.3 ), the output rate function is obtained by minimizing over κ ≥ 0 : I (1) prior ( y ) = inf κ ≥ 0 1 2 h κ aκ (0) − log κ aκ (0) − 1 i + y 2 2 κ . The minimization can be performed explicitly , yielding to the follo wing expression: I (1) prior ( y ) = 1 4 1 + q 1 + 4 y 2 aκ (0) − 1 2 log h 1 2 1 + q 1 + 4 y 2 aκ (0) i − 1 2 + y 2 aκ (0) 1 + q 1 + 4 y 2 aκ (0) . (C.5) Actually , still in the single-input setting, the case of multi-dimensional outputs y ∈ R d out can be handled similarly , leading to radial rate functions, I (1) prior ( y ) (just replace y 2 with the squared norm | y | 2 ) and satisfying I (1) prior ( y ) ∼ | y | as | y | → ∞ . This linear growth should be compared also the tails observ ed numerically for ReLU activ ations. Deep case ( L > 1 ). For L > 1 , an explicit formula is no longer av ailable, but the asymptotic gro wth of I ( L ) prior can be characterized. Let κ ∗ ( y ) = κ ( L ) , ∗ ( y ) denote the minimizer in the definition of I ( L ) prior ( y ) . The first-order optimality condition implies that κ ⋆ ( y ) satisfies 1 ( a L κ (0) ) 1 /L κ ⋆ L +1 L − κ ⋆ − y 2 = 0 . (C.6) This relation can be rewritten as κ ⋆ = a L κ (0) 1 L +1 y 2 + κ ⋆ L L +1 . (C.7) T o extract the asymptotic behavior , assume that κ ⋆ ( y ) ∼ | y | d for some exponent d > 0 . If d ≥ 2 , then the right-hand side of ( C.7 ) scales as | y | dL/ ( L +1) , which is inconsistent since d = dL/ ( L + 1) for L ≥ 1 . Hence d < 2 , and the dominant contribution comes from the y 2 term, yielding d = 2 L L + 1 . Substituting this scaling into the variational definition of I ( L ) prior giv es I ( L ) prior ( y ) ≍ | y | 2 L +1 , | y | → ∞ . (C.8) Thus, the prior output rate function exhibits sublinear gr owth , with an exponent that decreases as depth increases. This consideration may suggest why deeper networks with ReLU activ ation exhibit increasingly hea vy-tailed large-de viation behavior (e ven in the absence of nonlinear feature learning). 17 Beyond NNGP: Lar ge Deviations and Feature Learning in Bayesian Neural Netw orks A P R E P R I N T D Numerical diagnostics and optimization stability This appendix collects numerical diagnostics supporting the stability and reliability of the computations reported in Section 5 . All experiments are implemented in Python/JAX . While the large-de viation formulations lead to finite- dimensional con ve x or nearly con vex optimization problems, some care is required to handle numerical conditioning and curvature, especially when optimizing ov er kernel v ariables. The figures in this appendix illustrate that these issues are well controlled in practice. Optimization of prior and posterior rate functions. Figures 9 , 10 and 11 report diagnostics for the computation of the prior , posterior output rate functions, and prediction respecti vely , in the ReLU case and Heaviside training dataset. Each figure consists of four panels. T op panel: the prior/posterior rate function ev aluated on the output grid. Second panel: In orange, the norm of the gradient during the final iterations of the inner optimization , corresponding to the Legendre–Fenchel transform J σ ( κ | κ 0 ) of the conditional log -MGF in ( 4.6 ) . This optimization is performed using a hybrid Adam–L-BFGS scheme, with Adam providing robust initial e xploration and L-BFGS ensuring fast local con ver gence. In blue, the norm of the gradient during the outer optimization over the kernel variable κ , carried out using Adam only . Thir d panel: The kernel is parametrized via its Cholesky factorization to enforce positiv e semidefiniteness. The plot reports the minimum diagonal entry of the optimized kernel, confirming that the solution remains well inside the positiv e definite cone and away from numerical de generacy . Bottom panel: the relative operator -norm gap between the optimized kernel κ ⋆ and the NNGP kernel κ 0 . As discussed in the main text, this g ap vanishes at the typical point for the prior and remains nonzero under posterior conditioning, reflecting kernel selection ef fects. T ogether , these diagnostics indicate stable conv ergence of both the inner and outer optimization loops, with no signs of numerical pathologies. Monte Carlo diagnostics f or posterior sampling. Figure 12 reports diagnostics for the Monte Carlo simulations used in Experiment 03B. Samples are dra wn using the Metropolis-adjusted Langevin algorithm (MALA), which was preferred ov er SGLD due to its superior stability in the presence of the strong curvature induced by the n -tempered likelihood. The figure shows trace plots for multiple (2 for clearer visibility – while the main body experiment was performed on 10) independent chains targeting the finite-width posterior at width n = 128 . Despite the strong concentration induced by the large-de viation scaling, the chains mix adequately and do not exhibit sticking or metastability . Acceptance rates are reported in the main text and remain in a stable re gime across chains. These diagnostics support the claim that the empirical posterior distributions used for comparison are reliably sampled and that discrepancies between Monte Carlo estimates and NNGP predictions are not due to sampling artifacts. 18 Beyond NNGP: Lar ge Deviations and Feature Learning in Bayesian Neural Netw orks A P R E P R I N T 1 0 1 2 3 4 0.0 0.2 0.4 0.6 LDP rate P rior LDP rate and solver diagnostics 1 0 1 2 3 4 1 0 3 1 0 2 1 0 1 grad RMS grad_a_r ms(last) grad_L_r ms(last) 1 0 1 2 3 4 2.5 3.0 3.5 4.0 k er nel diagnostics min_chol_diag_v(last) cond_v(last) 1 0 1 2 3 4 y 0.0 0.5 1.0 1.5 2.0 k er nel r elative gap Fig. 9: Diagnostics f or prior rate computation (ReLU). Rate function, inner and outer gradient norms, minimum kernel diagonal entry , and kernel gap relati ve to the NNGP k ernel. 19 Beyond NNGP: Lar ge Deviations and Feature Learning in Bayesian Neural Netw orks A P R E P R I N T 1 0 1 2 3 4 0.0 0.5 1.0 1.5 2.0 LDP rate P osterior LDP curve and solver diagnostics (R eL U_heaviside) 1 0 1 2 3 4 1 0 3 1 0 2 1 0 1 grad RMS grad_a_r ms(last) grad_L_r ms(last) 1 0 1 2 3 4 0.24 0.26 0.28 0.30 0.32 0.34 k er nel diagnostics min_chol_diag_v(last) cond_v(last) 1 0 1 2 3 4 y 0.2 0.4 0.6 0.8 1.0 1.2 k er nel r elative gap Fig. 10: Diagnostics for posterior rate computation (ReLU , Heaviside data). Same layout as Figure 9 , illustrating stable optimization under posterior conditioning. 20 Beyond NNGP: Lar ge Deviations and Feature Learning in Bayesian Neural Netw orks A P R E P R I N T 4 3 2 1 0 1 2 3 4 0.0 0.5 1.0 1.5 MAP estimate LDP pr ediction curve and solver diagnostics (R eL U_heaviside) 4 3 2 1 0 1 2 3 4 1 0 4 1 0 3 1 0 2 1 0 1 1 0 0 grad RMS grad_a_r ms(last) grad_L_r ms(last) 4 3 2 1 0 1 2 3 4 0.2 0.3 0.4 0.5 k er nel diagnostics min_chol_diag_v(last) cond_v(last) 4 3 2 1 0 1 2 3 4 x 0.2 0.4 0.6 0.8 k er nel r elative gap Fig. 11: Diagnostics for MAP pr ediction computation (ReLU , Heaviside data). Same layout as Figure 9 , illustrating stable optimization also for the prediction. 21 Beyond NNGP: Lar ge Deviations and Feature Learning in Bayesian Neural Netw orks A P R E P R I N T 300 275 250 225 logp saved step inde x 1.5 2.0 2.5 y_test 0 200 400 600 800 1000 1200 saved step inde x 0.00 0.25 0.50 0.75 1.00 accept 03B_mc_post_ldp_w128_R eL U_heaviside_MC_diag.npz | temperatur e=1.0 Fig. 12: MCMC diagnostics f or finite-width posterior sampling. T race plots for multiple (2) MALA chains targeting the n -tempered posterior at width n = 128 . 22
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment