Advanced Black-Box Tuning of Large Language Models with Limited API Calls
Black-box tuning is an emerging paradigm for adapting large language models (LLMs) to better achieve desired behaviors, particularly when direct access to model parameters is unavailable. Current strategies, however, often present a dilemma of subopt…
Authors: Zhikang Xie, Weilin Wan, Peizhu Gong
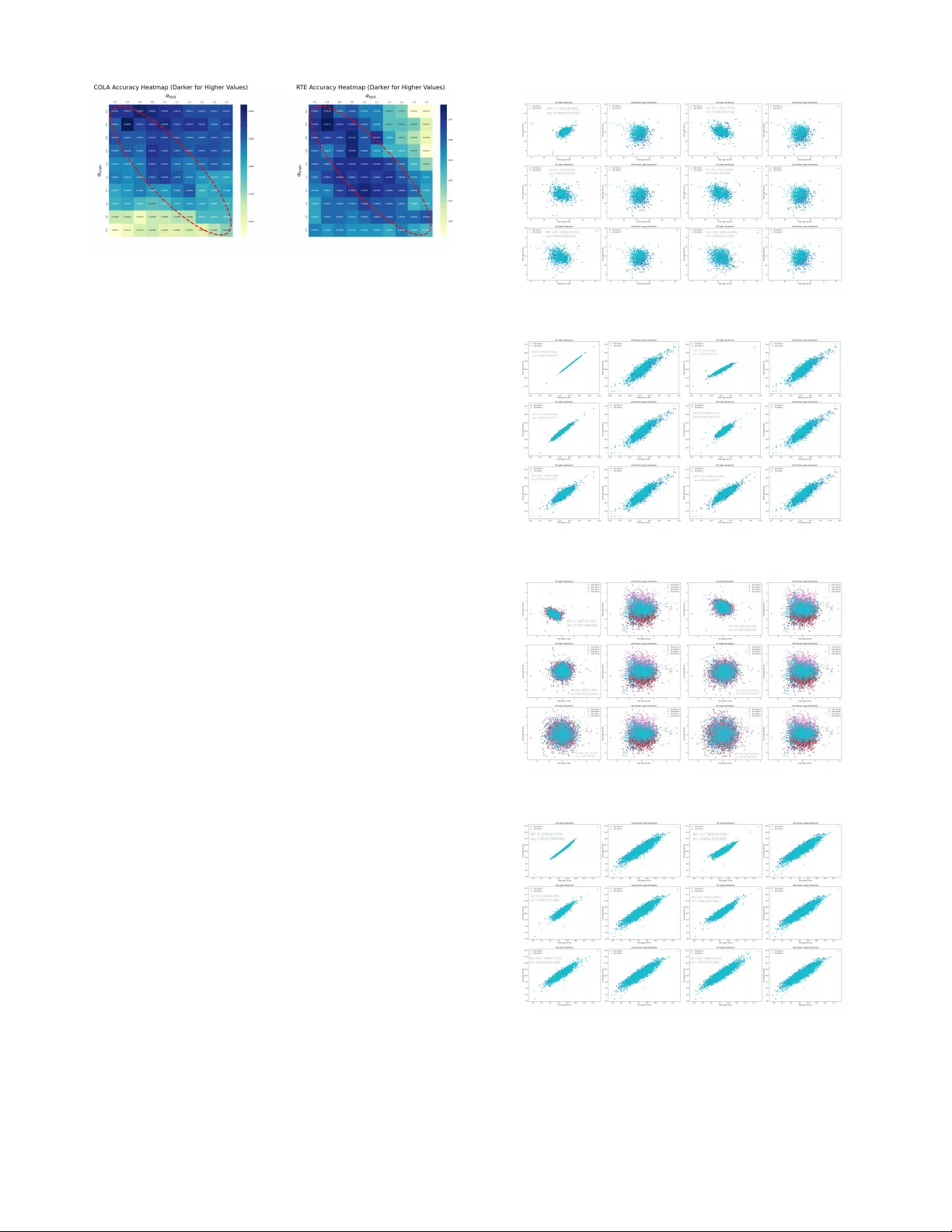
Advanced Black-Box T uning of Large Language Models with Limited API Calls Zhikang Xie 1 , W eilin W an 1 , Peizhu Gong 1 * , W eizhong Zhang 2 , Cheng Jin 1,3 * 1 College of Computer Science and Artificial Intelligence, Fudan Uni versity 2 School of Data Science, Fudan Univ ersity 3 Shanghai Ke y Laboratory of Intelligent Information Processing { 22307110187, wlwan23 } @m.fudan.edu.cn, { pzgong, weizhongzhang, jc } @fudan.edu.cn Abstract Black-box tuning is an emer ging paradigm for adapting lar ge language models (LLMs) to better achiev e desired behav- iors, particularly when direct access to model parameters is unav ailable. Current strategies, ho wev er , often present a dilemma of suboptimal e xtremes: either separately train a small proxy model and then use it to shift the predictions of the foundation model, offering notable ef ficiency b ut of- ten yielding limited improvement; or making API calls in each tuning iteration to the foundation model, which entails prohibitiv e computational costs. In this paper , we argue that a more reasonable way for black-box tuning is to train the proxy model with limited API calls. The underlying intu- ition is based on tw o ke y observ ations: first, the training sam- ples may exhibit correlations and redundancies, suggesting that the foundation model’ s predictions can be estimated from previous calls; second, foundation models frequently demon- strate low accuracy on do wnstream tasks. Therefore, we pro- pose a novel advanced black-box tuning method for LLMs with limited API calls. Our core strategy in volv es training a Gaussian Process (GP) surrogate model with “LogitMap Pairs” deriv ed from querying the foundation model on a min- imal but highly informative training subset. This surrogate can approximate the outputs of the foundation model to guide the training of the proxy model, thereby effecti vely reducing the need for direct queries to the foundation model. Exten- siv e experiments verify that our approach ele vates pre-trained language model accuracy from 55.92% to 86.85% , reducing the frequency of API queries to merely 1.38% . This signif- icantly outperforms offline approaches that operate entirely without API access. Notably , our method also achiev es com- parable or superior accuracy to query-intensive approaches, while significantly reducing API costs. This offers a robust and high-ef ficiency paradigm for language model adaptation. Code — https://github .com/kurumi8686/EfficientBBT Introduction Large Language Models (LLMs) have demonstrated re- markable capabilities in recent years. Adapting them to specific downs tream tasks or aligning them with desired behaviors is essential for unlocking their full potential in real-world applications. Gradient-based methods, such as Adapter modules (Houlsby et al. 2019) and LoRA (Hu et al. * Corresponding Author . 2022), are widely recognized as standard parameter-efficient fine-tuning techniques for LLMs. These methods adapt the pre-trained model to new tasks by tuning only a small sub- set of the model’ s parameters, and they have consistently achiev ed promising results in the literature. Howe ver , these methods require full access to model parameters, which is not feasible for many state-of-the-art LLMs, such as GPT -4 (Achiam et al. 2023) and Gemini (T eam et al. 2023). Black-box tuning is an emerging paradigm for adapt- ing LLMs without direct parameter access. Howe ver , cur- rent strategies often inv olve a challenging trade-off. Specif- ically , offline methods (Liu et al. 2024) train a smaller proxy model independently and use it to adjust the black- box model’ s outputs during inference. While these meth- ods are efficient, their performance is limited because the proxy model does not have direct access to the foundation model’ s internal knowledge during training. In contrast, on- line methods , such as Consistent Proxy T uning (CPT) (He et al. 2024), integrate the black-box model into the proxy’ s training loop via iterative API calls. This approach impro ves alignment and performance but incurs significant computa- tional and monetary costs. Consequently , practitioners face a dilemma: either sacrifice performance for efficienc y or ac- cept substantial costs for better adaptation. In this paper , we argue that a more reasonable and resource-efficient way for black-box tuning is to train a proxy model with a strictly limited budget of these costly API calls. The underlying intuition for this approach is rooted in two ke y observ ations. Firstly , the training sam- ples may e xhibit inherent correlations and redundancies. This suggests that the foundation model’ s predictions for new , unseen inputs can often be ef fectiv ely estimated or in- ferred from its responses to a smaller subset of previous calls. Secondly , ev en po werful foundation models do not al- ways achie ve perfect accuracy across all instances within the training data. Consequently , we posit that a well-informed approximation, rather than exhaustiv e querying of the foun- dation model, can still provide ef fecti ve and comparable su- pervision for training a high-performing proxy model. Therefore, we propose a novel advanced black-box tun- ing method specifically designed for LLMs operating under the limited API calls. Our core strategy inv olves leverag- ing a Gaussian Process (GP) surrogate (Williams and Ras- mussen 2006) to approximate the outputs of the foundation T raining Phase1: GP Surr ogate Model T raining T raining Dataset Large Black-box Untuned Model Small White-box Untuned Model Output Logits Initial LogitMap Pairs Filter Pairs via Euclidian Distance Final LogitMap Pairs API Calls Gaussian Process Surrogate Model Fit GP Model Small White-box Untuned Model Gaussian Process Surrogate Model Small White-box T uning Model ... ... - + ... ... Softmax ... ... Ground T ruth Loss Small White-box Untuned Model Small White-box T uning Model ... ... ... - + ... ... Softmax ... ... Ground T ruth T raining Phase2: GP-Based Proxy T uning Inference Phase Large Black-box Untuned Model Right Answer! Large Black-box Untuned Model ... ... Figure 1: Overvie w of our proposed algorithmic framework. T raining Phase 1: GP Surrogate Model T raining. A Gaussian Process model M g p is trained on a filtered subset of data to approximate the mapping between input embeddings and the output logits of the lar ge black-box model M l . T raining Phase 2: GP-based Pr oxy T uning. The trained M g p guides the fine- tuning of a small white-box proxy model M + s , effecti vely incorporate knowledge from M l into M + s via standard supervised training. Inference Phase. The final predictions are obtained by combining the outputs from the tuned proxy model M + s with an ensemble of the original proxy model M − s and the large black-box model M l . model to guide the training of the proxy model. As illus- trated in Figure 1, the central idea is to train this GP surro- gate model on a small yet highly informativ e subset of the training data. W e refer to these data points as “LogitMap Pairs”, which consist of input embeddings and their corre- sponding output logits obtained from the foundation model. Once trained, the GP effecti vely approximates the founda- tion’ s predictive behavior , thereby enabling logit-lev el su- pervision for a lightweight proxy model and highly reducing the need for expensi ve black-box queries. GPs, as non-parametric Bayesian models, are exception- ally well-suited for approximating complex functions and hav e been shown to emulate deep neural networks under cer- tain conditions (Damianou and Lawrence 2013; Lee et al. 2017). A crucial advantage of GPs is their probabilistic na- ture, which allows for robust uncertainty estimation. This capability can help quantify the reliability of the surrogate’ s predictions and further inform strategic training decisions for the proxy model. W e lev erage this property to enhance the proxy model training process. Specifically , when the GP surrogate yields a prediction with high associated un- certainty (e.g., a large variance τ 2 exceeding a pre-defined threshold θ ), we deem its prediction potentially unreliable. In such instances, our method falls back on in v oking the black-box target model to obtain the true output. This adap- tiv e mechanism ensures that primarily high-confidence sur- rogate predictions are utilized for training, thereby reducing the propagation of noise and improving the ov erall robust- ness and capabilities of the proxy model. Extensiv e experiments across multiple NLP benchmarks demonstrate the ef fectiv eness and scalability of our ap- proach. It boosts the a verage accuracy of pre-trained lan- guage models from 55.92% to 86.85% , while reducing API query usage to just 1.38% of that required by query- intensiv e methods such as CPT (He et al. 2024). Remark- ably , despite this drastic reduction, our method achie ves comparable or superior accuracy to these online methods, and significantly outperforms fully offline baselines. This highlights our approach as a robust and highly efficient paradigm for adapting LLMs in black-box settings. Our contributions can be summarized as follo ws: 1. W e propose a novel black-box tuning method that em- ploys a GP surrogate to approximate foundation model outputs, enabling efficient proxy training with minimal API queries. As far as we have studied, our method im- prov es from 55.92% to 86.85% , achieving state-of-the- art results and demonstrating its superior effecti veness. 2. W e propose an effecti ve data selection method for GP model training, requiring only 1.38% training data. 3. Extensi ve experiments show that our method drasti- cally reduces API usage compared to previous online approaches, while achieving better performance. This demonstrates a practical and cost-efficient paradigm for black-box tuning in real-world scenarios. Related W orks Efficient Fine-tuning. The substantial cost of fully fine- tuning large models (Roziere et al. 2023; Groeneveld et al. 2024) has driv en the development of parametric-efficient fine-tuning (PEFT) techniques (He et al. 2021; Lialin, Desh- pande, and Rumshisky 2023). PEFT methods adapt mod- els by modifying only a small parameter subset, aiming to preserve pre-trained knowledge while reducing resource demands. Common strategies inv olve inserting lightweight modules (e.g., Adapters (Houlsby et al. 2019), Compacter (Karimi Mahabadi, Henderson, and Ruder 2021)), optimiz- ing continuous prompts or prefixes (e.g., Prompt T uning (Lester , Al-Rfou, and Constant 2021), Prefix T uning (Li and Liang 2021), P-T uning v2 (Liu et al. 2021b)), or adjust- ing internal model parameters through approaches like low- rank updates (LoRA (Hu et al. 2022), QLoRA (Dettmers et al. 2023)), selecti ve tuning (e.g., BitFit (Zaken, Ra vfogel, and Goldberg 2021)), or learned activ ation scaling ( (IA) 3 (Liu et al. 2022)). Despite their resource ef ficiency , these approaches typically require internal model access (weights and gradients), restricting their use in black-box scenarios. Black-box Fine-tuning. Adapting LLMs without param- eter access (i.e., in black-box settings) requires special- ized fine-tuning techniques. Gradient-free optimization of- fers one approach, e xemplified by Black-Box T uning (BBT) (Sun et al. 2022), which optimizes input prompts by ev alu- ating model outputs without gradient information. A domi- nant alternative in volv es employing smaller auxiliary mod- els. Proxy-based methods, such as Proxy Tuning (PT) (Liu et al. 2024) and Consistent Proxy T uning (CPT) (He et al. 2024), train an accessible white-box proxy and transfer task- specific kno wledge by using differential signals from the proxy to guide the black-box model at inference. Other strategies train surrogate models to post-process or align the black-box outputs directly , using methods like sequence-to- sequence aligners (Ji et al. 2024) or adapting output prob- abilities (Ormazabal, Artetxe, and Agirre 2023; Lu et al. 2023). A key challenge across many methods relying on auxiliary models, especially CPT , is the potentially high cost associated with frequent API queries to the black-box LLM needed for training the auxiliary component. Logit Arithmetic. In volving techniques that directly ma- nipulate pre-softmax logits, often by aggre gating signals from multiple sources or model states, is essentially an ap- plication of ensemble learning principles (Dong et al. 2020). For example, logit manipulation facilitates domain adapta- tion through ensembling logits from distinct models (Dou et al. 2019). In controllable generation, approaches include subtracting anti-expert logits (DExperts (Liu et al. 2021a)) and contrasting expert versus amateur model logits (CD (Li et al. 2022)). More recently , the principle has been extended to intra-model comparisons, where different layers are con- trasted to enhance factuality (DoLa (Chuang et al. 2023)) or guide decoding via auto-contrastive objectives (Gera et al. 2023). The effecti veness and flexibility of logit ensembling motiv ate our exploration of logit-based adjustments as an ef- ficient mechanism for black-box tuning. Gaussian Process Models. Gaussian Processes (GPs) are non-parametric Bayesian methods well-suited for modeling complex functions and quantifying uncertainty (W illiams and Rasmussen 2006). K ey advances include sophisticated cov ariance functions, such as additiv e kernels for inter- pretable decomposition (Durrande, Ginsbourger , and Rous- tant 2011) and multiple kernel learning for integrating di- verse properties (G ¨ onen and Alpaydın 2011). GPs hav e also been integrated into more comple x probabilistic frame- works to capture complex data structures. Notable exam- ples include W arped GPs (Snelson, Ghahramani, and Ras- mussen 2003), which transform the output space to model non-Gaussian lik elihoods, and Gaussian Process Regression Networks (W ilson, Knowles, and Ghahramani 2011), which compose multiple GPs into deeper hierarchical models. The broad applicability of GPs across various natural lan- guage processing (NLP) tasks (Cohn, Preot ¸ iuc-Pietro, and Lawrence 2014) further highlights their versatility . These advancements demonstrate the flexibility and modeling ca- pabilities of Gaussian Processes, motiv ating our adoption of GP-based models as efficient surrog ates. Methodology This section outlines our GP-based approach for ef ficient black-box tuning of large language models. Central to our method is a GP surrogate that approximates target models behavior , enabling high-quality adaptation with significantly fewer direct queries. W e first provide a brief ov erview of e x- isting proxy-based approaches, followed by a comprehen- siv e and detailed description of our adv anced framework, highlighting its key inno vations and practical benefits. Basics on Existing Proxy-based Methods Proxy-T uning Proxy-T uning (PT) (Liu et al. 2024) adapts pre-trained LLMs at decoding time without access to their internal parameters, ideal for black-box or computationally constrained scenarios. It employs a small white-box proxy model, with a tuned version M + s and an untuned version M − s . PT adjusts the logits of the large black-box model M l by adding the logit difference from the small proxy models: s pt ( x ) = s M l ( x ) + s M + s ( x ) − s M − s ( x ) , (1) where s M ( x ) are logits from model M . Originally , M + s (parameters θ + s ) is trained independently on a task-specific dataset D = { ( x, y ) } to minimize a loss L : θ + s = arg min θ + s E ( x,y ) ∼ D L ( M + s ( x ; θ + s ) , y ) , (2) this independent training of M + s , ho wev er , overlooks its in- teraction with M l and M − s during inference, potentially limiting performance. Consistent Proxy T uning Consistent Proxy T uning (CPT) (He et al. 2024) refines PT by aligning the training objectiv e of the small proxy model M + s with its actual us- age during inference. This consistency is achie ved by incor - porating the influence of M l and M − s into the training loss for M + s . The training objectiv e of CPT is: θ + s = arg min θ + s E ( x,y ) ∼ D h L M + s ( x ; θ + s ) + α train M l ( x ; θ l ) − M − s ( x ; θ − s ) , y i . (3) During this training, parameters θ l of M l and θ − s of M − s are frozen, only θ + s are fine-tuned. While CPT demonstrates improv ed performance due to this consistent objectiv e, a significant practical drawback arises: optimizing M + s via Equation 3 necessitates frequent queries to the large black- box model M l , incurring substantial computational costs and API call limitations. Proposed Method T o mitigate the high API call dependency of CPT , we intro- duce a GP model as a data-efficient surrogate for the large black-box model M l . The core idea is to pre-train a GP to approximate the logit outputs of M l on the task-specific dataset D , and then use this GP surrogate during the CPT training of the small proxy model M + s . Gaussian Process Modeling of M l Logits GPs are non- parametric Bayesian models adept at function approxima- tion from limited data. Formally , a GP defines a prior distri- bution o ver f ( x ) ∼ G P ( m ( x ) , k ( x, x ′ )) , where m ( x ) is the mean function and k ( x, x ′ ) is the kernel function. The kernel encodes prior beliefs about the function’ s properties, such as smoothness, by defining the co variance between function values at dif ferent input points x and x ′ . Giv en a training dataset D ′ = { ( x j , s j ) } M j =1 , where s j = s M l ( x j ) ∈ R V are the observed target black-box model out- put logits, the GP conditions on this data to form a poste- rior distribution. For a new input x ∗ , the predictive distri- bution for the logits s M l ( x ∗ ) is also Gaussian. A common and effecti ve strategy for handling such multi-dimensional outputs, which we adopt in our implementation, is to model each of the V logit dimensions independently . This indepen- dent modeling assumption simplifies computation and often yields strong empirical results. The predictiv e mean for the v -th logit dimension, ˆ s G P ,v ( x ∗ ) , which serves as our approximation s G P ,v ( x ∗ ) , is giv en by formula 2.25 and 2.27 in page 17 of (W illiams and Rasmussen 2006): ˆ s G P ,v ( x ∗ ) = k ( x ∗ , X D ′ ) T ( K D ′ D ′ + σ 2 n,v I ) − 1 s D ′ ,v , (4) where the terms are defined as follows: • X D ′ = { x j } M j =1 represents the set of M training data. • k ( x ∗ , X D ′ ) is a vector in R M denoting the covariances between the new input x ∗ and each training input x j ∈ X D ′ , with its j -th element being k ( x ∗ , x j ) . • K D ′ D ′ is the M × M cov ariance matrix computed from the training inputs, where each entry ( K D ′ D ′ ) ij = k ( x i , x j ) is the kernel e valuation between x i , x j ∈ X D ′ . • σ 2 n,v is the noise variance hyperparameter for the v - th logit dimension, accounting for potential observation noise or model misspecification. • I is the M × M identity matrix. • s D ′ ,v is a vector in R M containing the observed values of the v -th logit dimension from the training set D ′ . This framew ork, by applying independent GPs to each logit dimension, allows us to construct a composite multi-output GP model to predict the full logit vector s M l ( x ) . Data Acquisition for GP via Selective Sampling A crit- ical aspect is to train the GP ef fectiv ely with minimal queries to M l . Instead of querying M l for all x ∈ D , we construct a small but highly informativ e subset D ′ = { ( x j , s M l ( x j )) } M j =1 , where M ≪ | D | (T ypically , D ′ is ap- proximately 1% the size of D ). Then, D ′ is used by a filter- ing algorithm (detailed in Algorithm 1) that aims to maxi- mize div ersity and representativ eness. Algorithm 1: Algorithm for GP T raining Set Construction Require: Dataset D ; proxy model M − s ; foundation model M l ; thresholds τ in , τ out Ensure: GP training set D ′ 1: Initialize D cand = ∅ , D ′ = ∅ 2: For all x ∈ D , compute v x = embedding ( x ) as input, compute s x = M − s ( x ) as output 3: if D = ∅ then 4: Seed D cand with ( x 1 , s x 1 ) 5: end if 6: f or each x ∈ D \ { x 1 } do 7: div erse ← true 8: for each ( x k , s k ) ∈ D cand do 9: if ∥ v x − v x k ∥ ≤ τ in ∨ ∥ s x − s k ∥ ≤ τ out then 10: div erse ← false; br eak 11: end if 12: end for 13: if div erse then 14: Add ( x, s x ) to D cand 15: end if 16: end f or 17: f or each ( x, s x ) ∈ D cand do 18: Query M l for s ′ x ; add ( x, s ′ x ) to D ′ 19: end f or 20: r eturn D ′ This filtering process primarily uses the input vector rep- resentations v x and the output logits from the frozen small model M − s . This ensures that the selection process itself is computationally inexpensi ve. Only once an input x is se- lected through this filtering, do we query the black-box large model M l to obtain its true output logits s M l ( x ) . These ( x, s M l ( x )) then constitute the training set D ′ (i.e., Log- itMap Pairs) for our GP model M g p . As part of this filtering strategy , we experimented with sev eral rule-based approaches to quantify the dif ference. Specifically , we e valuated Manhattan distance, Euclidean distance, and cosine similarity . Our results indicate that all three metrics can perform comparably , assuming appropri- ate input-output thresholds are set (details in B.1). Among them, Euclidean distance emerged as the most consistently effecti ve and computationally simple choice, and is there- fore adopted in our final approach. The Euclidean distances used for filtering are: • Input distance: d input ( x, x ′ ) = ∥ v x − v x ′ ∥ 2 . • Output distance: d output ( x, x ′ ) = ∥ s M − s ( x ) − s M − s ( x ′ ) ∥ 2 . If two data points have highly similar input representa- tions and their outputs (as predicted by the inexpensi ve small proxy model) are also similar, they lik ely provide redundant information for training the GP model. By filtering based on these cheaper-to-obtain metrics, we ensure D ′ is compact yet rich in information, capturing diverse aspects of the in- put space and the proxy’ s initial assessment of output vari- ations. This curated selection allows the GP to generalize effecti vely from fe wer actual M l queries. GP-Enhanced Pr oxy T raining With the trained GP model M g p providing approximation for the outputs of the large foundation model M l , we introduce an uncertainty- aware training objectiv e for the small proxy model M + s . The objectiv e is defined as: θ + s = arg min θ + s E ( x,y ) ∼ D h L M + s ( x ; θ + s ) + α train S g ate ( x ) − M − s ( x ; θ − s ) , y i , (5) where the gated supervision S g ate ( x ) is determined by: S g ate ( x ) = M g p ( x ; θ g p ) · 1 τ 2 M gp ( x ) ≤ θ + M l ( x ; θ l ) · 1 τ 2 M gp ( x ) >θ , (6) where, τ 2 M gp ( x ) is the predictiv e variance of the GP model M g p ( x ; θ g p ) for input x , and θ is the pre-defined variance threshold. The term 1 denotes the indicator function, where 1 condition is 1 if the condition is true, and 0 otherwise. During training, the parameters of the GP surrogate M g p ( · ; θ g p ) and the untuned proxy model M − s ( · ; θ − s ) are kept frozen, while only the trainable proxy M + s ( · ; θ + s ) is fine-tuned. T o ensure robust supervision, we introduce a gat- ing mechanism based on the GP’ s predictiv e uncertainty . For each input x , if the GP variance τ 2 M gp ( x ) ≤ θ , its prediction is used as the guidance signal S gate ( x ) ; otherwise, we query the target black-box model M l ( x ) to obtain a reliable label. Inference At inference time, our procedure closely fol- lows that of PT / CPT . The adjusted logits for a new input x are computed as: s final ( x ) = s M + s ( x ) + α test s M l ( x ) − s M − s ( x ) , (7) where s M l ( x ) denotes the output of the target black-box large model. T ypically , we set α test = α train . The final pre- diction is then obtained by applying the softmax function to s final ( x ) . Experiments Experimental Setup Models Selection. T o balance efficiency and reliability , we select models from Llama2 (T ouvron et al. 2023), Mistral-7B (Jiang et al. 2023), Qwen3 (Y ang et al. 2025) and DeepSeek-R1-Distill (DeepSeek-AI et al. 2025) fami- lies. For each series, we use a small model as the proxy and a larger one as the target. While the selected large models are technically white-box, we treat them as black-box dur- ing validation to simulate realistic constraints. W e also di- rectly fine-tune them to obtain an oracle upper bound, which serves as a reference for ev aluating our method’ s effecti ve- ness. For ev aluations inv olving truly inaccessible black-box models, please refer to Appendix, where we conduct exper - iments under genuine black-box conditions. Datasets Selection. W e conducted experiments across di- verse NLP datasets to showcase the versatility of our method. Our approach was ev aluated on three major tasks: (a). T ext Classification: W e use A G-News (Zhang, Zhao, and LeCun 2015), CoLA (Corpus of Linguistic Acceptabil- ity) (W arstadt, Singh, and Bowman 2019), SST -2 (Stan- ford Sentiment T reebank) (Socher et al. 2013), and QQP (Quora Question P airs) (Shankar and Nikhil 2017). (b). Question Answering: W e include ARC-C (AI2 Reason- ing Challenge - Challenge Set) (Clark et al. 2018), Cs- QA (CommonsenseQA) (T almor et al. 2018), and OB-QA (OpenBookQA) (Mihaylov et al. 2018). (c). Natural Lan- guage Inference: W e consider MNLI (Multi-Genre Natu- ral Language Inference) (W illiams, Nangia, and Bowman 2017), QNLI (Question Natural Language Inference) (Ra- jpurkar , Jia, and Liang 2018), R TE (Recognizing T extual Entailment) (Dagan, Glickman, and Magnini 2005), and CoP A (Choice of Plausible Alternatives) (Roemmele, Be- jan, and Gordon 2011). These datasets are widely used and well-established benchmarks, covering div erse linguis- tic phenomena and ev aluation challenges. Baselines. W e compare our proposed GP-based proxy tun- ing method for black-box LLMs against several represen- tativ e baselines to demonstrate its effecti veness: (a). Zero- shot Inference: W e ev aluate the pretrained LLMs without any tuning, by directly applying them to the test sets. This provides a fundamental reference point for all tuning meth- ods. (b). Direct Fine-tuning: W e apply both LoRA (Hu et al. 2022) and full-precise fine-tuning on the LLMs. Although these methods require full access to model parameters, which is impractical in black-box scenarios, they provide upper-bound references to demonstrate the performance of our approach. (c). Proxy-T uning and CPT : W e compare our method with leading black-box tuning approaches, includ- ing Proxy-T uning (Liu et al. 2024) and CPT (He et al. 2024), demonstrating that our approach achiev es superior perfor- mance while requiring substantially fewer API calls. Empirical Data Selection. As shown in T able 2, we em- pirically determined the data proportions for both random and filter selection strategies. For the random strategy , we iterativ ely adjusted the sampling ratio until the resulting ac- curacy matched that of CPT . For the filter strategy , we tuned the input and output thresholds, and repeatedly applied Al- gorithm 1 to construct LogitMap Pairs, aiming to strike a balance between efficienc y and performance. Based on extensiv e empirical ev aluation, we make the fol- Model & Method Accuracy (%) ↑ A vg.API ↓ AG-Ne ws CoLA CoP A SST -2 ARC-C Cs-QA OB-QA MNLI QNLI R TE QQP A vg. Llama2-7B / Mistral-7B-v0.1 Qwen3-8B / DeepSeek-R1-14B Pretrain 52.03 / 85.33 85.86 / 87.39 69.22 / 72.48 83.22 / 69.13 65.40 / 87.20 93.60 / 95.00 51.72 / 87.16 92.09 / 92.32 40.47 / 68.56 86.62 / 88.29 26.04 / 64.21 78.13 / 77.31 32.40 / 66.60 83.20 / 84.00 35.74 / 36.88 84.20 / 65.79 50.45 / 74.48 85.54 / 49.70 54.87 / 72.56 85.56 / 52.71 35.89 / 78.71 83.38 / 53.65 46.75 / 72.20 85.58 / 74.12 - LoRA-Tune 93.59 / 93.57 90.21 / 91.30 84.28 / 82.84 84.28 / 69.61 81.60 / 91.20 96.20 / 86.00 95.76 / 95.18 95.87 / 91.28 48.83 / 70.57 90.30 / 89.63 75.92 / 79.28 80.02 / 79.77 75.60 / 83.60 88.40 / 90.60 90.78 / 88.63 89.56 / 84.77 88.36 / 88.80 88.96 / 88.25 83.03 / 81.59 81.23 / 79.42 89.89 / 88.10 90.34 / 90.57 82.51 / 85.76 88.67 / 85.56 - Full Fine-tune 94.76 / 94.58 92.57 / 92.80 84.85 / 84.28 84.95 / 81.59 90.60 / 92.60 97.40 / 97.60 96.56 / 96.22 96.33 / 96.33 53.85 / 74.58 91.30 / 90.64 76.17 / 80.92 82.72 / 81.98 78.80 / 84.60 90.00 / 93.20 91.27 / 89.64 90.59 / 87.35 95.13 / 93.37 93.61 / 95.26 84.84 / 83.39 87.73 / 90.61 91.81 / 88.63 91.72 / 91.52 85.33 / 87.53 90.81 / 90.81 - Llama2-13B / Mistral-7B-v0.2 Qwen3-14B / DeepSeek-R1-32B Pretrain 66.61 / 80.46 83.78 / 88.88 65.00 / 77.76 84.85 / 72.20 68.20 / 93.80 96.40 / 93.60 71.33 / 86.24 88.42 / 91.51 57.19 / 76.92 88.96 / 92.31 47.42 / 68.71 80.51 / 82.15 55.60 / 76.80 85.60 / 89.00 42.03 / 48.43 81.03 / 80.92 51.47 / 83.95 82.67 / 54.15 47.65 / 78.70 83.39 / 64.98 42.65 / 77.64 77.86 / 62.21 55.92 / 77.22 84.86 / 79.26 - LoRA-Tune 93.80 / 93.91 88.67 / 91.93 83.70 / 85.04 81.50 / 70.09 89.60 / 95.60 94.00 / 89.40 95.18 / 95.76 95.41 / 94.72 65.89 / 77.59 91.30 / 92.31 79.12 / 81.16 81.57 / 84.68 80.40 / 85.60 90.20 / 94.20 90.91 / 89.27 90.51 / 86.01 89.84 / 91.93 92.88 / 91.05 85.56 / 85.20 89.17 / 86.28 89.65 / 87.16 90.97 / 90.89 85.79 / 88.02 89.65 / 88.32 - Full Fine-tune 93.86 / 94.97 93.46 / 94.45 87.44 / 87.06 87.25 / 88.11 92.80 / 96.80 98.40 / 98.40 97.13 / 97.25 97.59 / 97.36 74.92 / 81.94 93.31 / 94.98 79.12 / 83.78 87.22 / 90.01 80.40 / 87.00 90.20 / 95.40 91.73 / 90.43 91.20 / 91.73 95.83 / 94.60 94.62 / 96.41 89.17 / 89.17 91.70 / 94.22 92.01 / 91.15 93.21 / 93.78 88.58 / 90.38 92.56 / 94.08 - Proxy Model Blac k-Box Tuning Methods Proxy-Tune 94.12 / 82.38 82.07 / 89.24 84.08 / 79.00 69.32 / 80.35 89.40 / 94.20 86.20 / 79.80 96.79 / 90.48 90.60 / 90.60 57.53 / 77.26 88.96 / 90.97 75.35 / 70.52 77.56 / 81.57 78.60 / 77.60 86.20 / 91.60 90.79 / 74.00 88.16 / 90.39 95.00 / 90.65 88.19 / 89.93 82.67 / 80.14 82.31 / 88.45 89.78 / 84.12 84.75 / 89.11 84.92 / 81.85 84.03 / 87.46 0% CPT 95.45 / 93.83 93.54 / 93.51 85.91 / 81.59 86.29 / 86.67 90.60 / 95.00 98.20 / 98.40 97.02 / 96.22 95.87 / 96.10 59.87 / 77.59 93.31 / 93.65 77.89 / 75.18 85.01 / 87.80 79.80 / 83.20 90.40 / 93.80 91.01 / 89.15 90.06 / 91.41 95.28 / 93.26 93.78 / 95.42 85.92 / 80.14 90.61 / 90.97 91.81 / 89.07 92.28 / 92.56 86.41 / 86.75 91.76 / 92.75 100% GP-random (ours) 95.30 / 92.20 92.18 / 92.38 85.43 / 81.21 85.71 / 86.86 90.60 / 94.80 98.60 / 98.40 97.02 / 96.10 95.18 / 95.76 58.19 / 78.26 91.97 / 91.64 78.87 / 73.96 85.01 / 86.16 79.60 / 82.20 89.20 / 93.00 90.99 / 89.79 91.01 / 90.04 94.89 / 92.18 92.99 / 94.64 86.64 / 81.95 90.97 / 90.25 90.46 / 88.60 91.25 / 91.40 86.18 / 86.48 91.28 / 91.87 6.94% GP-filter (ours) 95.22 / 93.11 93.22 / 93.08 85.81 / 81.02 86.77 / 87.54 92.00 / 95.40 98.80 / 98.80 97.13 / 96.44 96.10 / 96.67 61.20 / 78.26 92.31 / 91.64 78.95 / 75.35 86.49 / 88.62 79.20 / 82.60 90.80 / 93.40 91.42 / 90.55 91.05 / 90.89 94.98 / 94.38 93.57 / 95.22 87.73 / 81.59 92.06 / 89.89 91.71 / 90.07 91.93 / 92.09 86.85 / 87.16 92.10 / 92.53 1.38% / 1.45% 1.58% / 1.51% T able 1: Experimental results comparing our GP tuning with other approaches, including white-box LoRA and black-box proxy tuning methods, across 11 datasets. Our techniques are denoted by GP-random and GP-filter . W e separately use Llama2-7B, Mistral-7B-Instruct-v0.1, Qwen3-8B, DeepSeek-R1-Distill-Qwen-14B as a small white-box proxy model, and Llama2-13B, Mistral-7B-Instruct-v0.2, Qwen3-14B, DeepSeek-R1-Distill-Qwen-32B as the black-box foundation model. “Pretrain” refers to zero-shot inference using of ficial pretrained parameters, “LoRA-T une” denotes fine-tuning via LoRA (Hu et al. 2022), and “Full Fine-tune” refers to directly fine-tuning all model parameters. The methods Proxy-Tune, CPT , GP-random, and GP-filter are grouped as Pr oxy Model Black-Box T uning Methods . All datasets are e valuated by Accurac y (higher is better). Model & Method API Call Efficiency (%) ↓ A G-News CoLA CoP A SST -2 ARC-C Cs-QA OB-QA MNLI QNLI R TE QQP A vg. CPT (He et al. 2024) 100.00 100.00 100.00 100.00 100.00 100.00 100.00 100.00 100.00 100.00 100.00 100.00 GP-random (ours) 3.33 11.69 10.00 5.94 9.83 10.27 8.07 1.02 4.77 10.04 1.37 6.94 GP-filter (ours) 1.08 / 0.87 1.21 / 1.25 0.09 / 0.18 0.74 / 0.20 0.60 / 1.60 1.20 / 1.90 1.07 / 1.02 1.38 / 1.27 3.31 / 2.14 2.95 / 2.86 1.95 / 3.07 2.77 / 1.98 0.87 / 1.43 2.08 / 1.39 0.70 / 0.78 0.83 / 0.81 1.92 / 1.13 1.79 / 1.83 2.17 / 2.21 1.08 / 2.13 1.39 / 1.48 1.37 / 1.04 1.38 / 1.45 1.58 / 1.51 T able 2: Large model API call efficienc y . This table compares the percentage of large model API calls used by our methods versus CPT (He et al. 2024). For CPT , an API call is made for e very training instance (i.e., 100% usage). Our GP-filter method requires only an av erage of 1.38% ( Llama2 family models) of these calls. lowing recommendations: • Random-based: For datasets fewer than 100K samples, 5% random sampling performs well. For larger datasets, sampling 5K examples is suf ficient. • Filter -based: For most datasets, selecting around 1% of the data via our filtering algorithm is sufficient to achiev e strong performance. Howe ver , for extremely large datasets such as MNLI and QQP , which contain nearly 400K samples, fitting a GP model on a propor- tional subset becomes computationally infeasible and may lead to numerical instability (e.g., NaN predictions). T o address this, we recommend sampling approximately 2K examples, which balances ef ficiency and accurac y . Compared to tuning the small proxy model, the phase of constructing LogitMap P airs and T raining Gaussian Process model is significantly more efficient in both time and mem- ory . Detailed results are provided in Appendix. Main Results The main experimental results are presented in T able 1. Our proposed GP-based tuning methods, particularly GP-filter , exhibit consistently strong performance across all ev aluated models and datasets. Focusing first on the Llama2 fam- ily , GP-filter improves the average accuracy from 55.92% (pretrained) to 86.85% (GP-filter tuned), ev en outperform- ing LoRA-T une (85.79%) and approaching the performance of full fine-tuning (88.58%) on Llama2-13B . Compared to other proxy-based approaches, GP-filter achiev es a higher av erage accuracy than CPT (86.41%) while using only 1.38% of its API calls—to the best of our knowledge, this represents the state-of-the-art in both performance gain and API efficienc y—demonstrating both effecti veness and re- markable cost-efficienc y . It also outperforms offline Proxy- T une by an av erage margin of 1.93 percentage points. T o v alidate generalizability , we conduct extensi ve ex- periments across other model families including Mistral- 7B , Qwen3 , and DeepSeek-R1-Distill . In all cases, GP-filter yields consistent improvements over the pretrained mod- els, achieving av erage accuracy gains of +9.94 , +7.24 , and +13.27 percentage points, respecti vely . Notably , in each set- ting, GP-filter uses few API calls (below 2%), highlighting its extreme cost-ef ficiency alongside strong performance. W e also apply GP-filter in a simulated real-world black- box LLM setting ( Qwen-Plus model from T ongyi Qianwen) to further assess its practical applicability . As detailed in Appendix F, the method remains highly effecti ve ev en un- der multiple realistic constraints, confirming its robustness in truly black-box en vironments. Ablation Study: Different Usage of API Calls W e trained GP models on 6 datasets—CoP A, ARCC, CoLA, R TE, OBQA, and MRPC—using different API calls to gen- erate variant GP surrogates, which were then used to guide the small proxy via the GP-filter method. Figure 2 compares the output logits distributions of GP model and the target foundation model for CoLA and ARCC. Results for other datasets are provided in Appendix C. In each subfigure, the left panel shows the GP’ s output distrib ution, while the right panel shows that of the Llama2-13B pretrained model. Under extreme data scarcity , the GP logits distribution be- comes highly compressed, as observed in Figure 2a (the top left subfigure). W ith only 2 API calls (out of 8,551), the distribution nearly degenerates into a one-dimensional form, effecti vely reducing the GP model to a linear function. Sur- prisingly , the performance of the GP-filter method remains robust. In contrast, Figure 2b (the bottom right subfigure) shows the opposite extreme, where nearly all av ailable data (1,101 out of 1,119) is used. In this case, GP logits closely match those of the Llama2-13B pretrained model, and the GP-filter method achiev es performance comparable to CPT . These results highlight that GP-filter can perform well ev en with extremely limited API calls . Rather than replicat- ing the large model’ s logits, the GP appears to approximate its underlying knowledge structure, with added noise that may serve as implicit regularization, enhancing the proxy’ s robustness. Even in extreme minimal-data regimes (e.g., 2 samples in CoLA), the GP model provides a useful correc- tiv e signal, capturing high-level structural patterns such as distributional tendencies and relati ve logit relationships. Additional ablation studies provide further insights into the strengths of our approach. As shown in appendix D.1, under extreme data scarcity , directly fine-tuning the Llama2- 7B model yields lo w effecti veness. In contrast, our GP-filter method maintains high performance, achieving 6.31 per- centage points higher accuracy . Furthermore, appendix D.2 shows that on more challenging datasets, our method signif- icantly outperforms of fline approaches such as Proxy-T une. This impro vement stems from the fact that Proxy-T une only lev erages the foundation model at the reference stage; how- ev er , in dif ficult tasks, both the fine-tuned proxy model and the pretrained large model may perform suboptimally . In contrast, our approach incorporates the foundation model’ s knowledge throughout the training process, leading to more effecti ve proxy fine-tuning and consistently better results. GP D istr ib u tion GP D istr ib u tion 13b D istr ib u tion 13b D istr ib u tion A PI : 2/ 8551 A PI : 38/8551 A PI : 97/8551 A PI : 17 0 / 85 5 1 A PI : 326/855 1 A PI : 52 7 / 85 5 1 Dim1 Lo git Dim1 Lo git Dim 1 L ogi t Dim1 Lo git Dim1 Logit Dim1 Logit Dim1 L ogi t Dim1 Logit Dim1 Logit Dim1 Logit Dim1 L ogi t Dim1 Logit Dim0 Lo git Dim0 Lo git Dim0 Lo git Dim0 Lo git Dim0 Lo git Dim0 Lo git Dim0 Lo git Dim0 Lo git Dim0 Lo git Dim0 Lo git Dim0 Lo git Dim0 Lo git (a) CoLA: across six API call budgets GP D istr ib u tion GP D istr ib u tion 13b D istr ib u tion 13b D istr ib u tion A PI : 2/ 1119 A PI : 23/1119 A PI : 41 / 1119 A PI : 92/1119 A PI : 370/1119 A PI : 1101 / 1119 Dim1 Lo git Dim1 Lo git Dim 1 L ogi t Dim1 Lo git Dim1 Logit Dim1 Logit Dim1 L ogi t Dim1 Logit Dim1 Logit Dim1 Logit Dim1 L ogi t Dim1 Logit Dim0 Lo git Dim0 Lo git Dim0 Lo git Dim0 Lo git Dim0 Lo git Dim0 Lo git Dim0 Lo git Dim0 Lo git Dim0 Lo git Dim0 Lo git Dim0 Lo git Dim0 Lo git (b) ARCC: across six API call budgets Figure 2: Logits distributions produced by the GP mod- els (each left subfigures) and the target black-box model (each right subfigures) across two datasets. The figure con- sists of four columns, grouped as two pairs: the first and third columns show the output logits distributions of six GP models trained under different API budgets; the second and fourth columns display the output logits of the same Llama2- 13b pretrained model under the same inputs, repeated for clearer comparison. The 2 and 4 colors in (a) and (b) repre- sent the 2 and 4 classes in their respectiv e datasets. Conclusion In this paper, we introduce a Gaussian Process (GP) based proxy tuning approach that directly addresses the central challenge in black-box LLM adaptation: aligning models effecti vely while minimizing expensi ve API interactions. Our approach trains a GP surrogate on a small, curated dataset to approximate the target model’ s behavior and uses its predictive uncertainty to guide selectiv e querying dur- ing proxy fine-tuning. Extensive experiments demonstrate that our method matches or outperforms competitiv e online black-box tuning techniques while using substantially fewer queries, and consistently surpasses existing offline strate- gies. These results not only highlight the practicality and cost-efficienc y of GP-based proxy tuning, but also confirm its effecti veness in realistic black-box adaptation scenarios. Acknowledgments This work was supported by the National Natural Science Foundation of China Y outh Student Basic Research Pro- gram (Grant No. 625B1002). It was also supported by High- Quality Development Project of Shanghai Municipal Com- mission of Economy and Informatization (Grant No. 2024- GZL-RGZN-02010) and AI for Science Foundation of Fu- dan Univ ersity (FudanX24AI028). References Achiam, J.; Adler , S.; Agarwal, S.; Ahmad, L.; Akkaya, I.; Aleman, F . L.; Almeida, D.; Altenschmidt, J.; Altman, S.; Anadkat, S.; et al. 2023. Gpt-4 technical report. arXiv pr eprint arXiv:2303.08774 . Chuang, Y .-S.; Xie, Y .; Luo, H.; Kim, Y .; Glass, J.; and He, P . 2023. Dola: Decoding by contrasting layers im- prov es factuality in large language models. arXiv preprint arXiv:2309.03883 . Clark, P .; Cowhe y , I.; Etzioni, O.; Khot, T .; Sabharwal, A.; Schoenick, C.; and T afjord, O. 2018. Think you ha ve solved question answering? try arc, the ai2 reasoning challenge. arXiv pr eprint arXiv:1803.05457 . Cohn, T .; Preot ¸ iuc-Pietro, D.; and Lawrence, N. 2014. Gaus- sian processes for natural language processing. In Pr oceed- ings of the 52nd Annual Meeting of the Association for Com- putational Linguistics: T utorials , 1–3. Dagan, I.; Glickman, O.; and Magnini, B. 2005. The pascal recognising te xtual entailment challenge. In Machine learn- ing challenges workshop , 177–190. Springer . Damianou, A.; and Lawrence, N. D. 2013. Deep gaussian processes. In Artificial intelligence and statistics , 207–215. PMLR. DeepSeek-AI; Guo, D.; Y ang, D.; Zhang, H.; Song, J.; Zhang, R.; Xu, R.; Zhu, Q.; Ma, S.; W ang, P .; Bi, X.; Zhang, X.; Y u, X.; W u, Y .; W u, Z. F .; Gou, Z.; Shao, Z.; Li, Z.; Gao, Z.; Liu, A.; Xue, B.; W ang, B.; W u, B.; Feng, B.; Lu, C.; et al. 2025. DeepSeek-R1: Incentivizing Rea- soning Capability in LLMs via Reinforcement Learning. Dettmers, T .; Pagnoni, A.; Holtzman, A.; and Zettlemoyer , L. 2023. Qlora: Ef ficient finetuning of quantized llms. Advances in neural information pr ocessing systems , 36: 10088–10115. Dong, X.; Y u, Z.; Cao, W .; Shi, Y .; and Ma, Q. 2020. A sur- ve y on ensemble learning. F rontier s of Computer Science , 14: 241–258. Dou, Z.-Y .; W ang, X.; Hu, J.; and Neubig, G. 2019. Domain differential adaptation for neural machine translation. arXiv pr eprint arXiv:1910.02555 . Durrande, N.; Ginsbourger , D.; and Roustant, O. 2011. Ad- ditiv e kernels for Gaussian process modeling. arXiv pr eprint arXiv:1103.4023 . Gera, A.; Friedman, R.; Arviv , O.; Gunasekara, C.; Szna- jder , B.; Slonim, N.; and Shnarch, E. 2023. The benefits of bad advice: Autocontrasti ve decoding across model layers. arXiv pr eprint arXiv:2305.01628 . G ¨ onen, M.; and Alpaydın, E. 2011. Multiple kernel learning algorithms. The J ournal of Machine Learning Researc h , 12: 2211–2268. Groenev eld, D.; Beltagy , I.; W alsh, P .; Bhagia, A.; Kinney , R.; T afjord, O.; Jha, A. H.; Ivison, H.; Magnusson, I.; W ang, Y .; et al. 2024. Olmo: Accelerating the science of language models. arXiv preprint . He, J.; Zhou, C.; Ma, X.; Ber g-Kirkpatrick, T .; and Neu- big, G. 2021. T owards a unified view of parameter-efficient transfer learning. arXiv preprint . He, Y .; Huang, Z.; Xu, X.; Goh, R. S. M.; Khan, S.; Zuo, W .; Liu, Y .; and Feng, C.-M. 2024. CPT : Consistent Proxy T uning for Black-box Optimization. arXiv preprint arXiv:2407.01155 . Houlsby , N.; Giurgiu, A.; Jastrzebski, S.; Morrone, B.; De Laroussilhe, Q.; Gesmundo, A.; Attariyan, M.; and Gelly , S. 2019. Parameter-ef ficient transfer learning for NLP . In International conference on machine learning , 2790–2799. PMLR. Hu, E. J.; Shen, Y .; W allis, P .; Allen-Zhu, Z.; Li, Y .; W ang, S.; W ang, L.; Chen, W .; et al. 2022. Lora: Lo w-rank adapta- tion of large language models. ICLR , 1(2): 3. Ji, J.; Chen, B.; Lou, H.; Hong, D.; Zhang, B.; P an, X.; Qiu, T . A.; Dai, J.; and Y ang, Y . 2024. Aligner: Efficient align- ment by learning to correct. Advances in Neural Information Pr ocessing Systems , 37: 90853–90890. Jiang, A. Q.; Sablayrolles, A.; Mensch, A.; Bamford, C.; Chaplot, D. S.; de las Casas, D.; Bressand, F .; Lengyel, G.; Lample, G.; Saulnier, L.; Lav aud, L. R.; Lachaux, M.-A.; Stock, P .; Scao, T . L.; Lavril, T .; W ang, T .; Lacroix, T .; and Sayed, W . E. 2023. Mistral 7B. Karimi Mahabadi, R.; Henderson, J.; and Ruder , S. 2021. Compacter: Efficient low-rank hypercomplex adapter lay- ers. Advances in Neural Information Processing Systems , 34: 1022–1035. Lee, J.; Bahri, Y .; Nov ak, R.; Schoenholz, S. S.; Pennington, J.; and Sohl-Dickstein, J. 2017. Deep neural networks as gaussian processes. arXiv preprint . Lester , B.; Al-Rfou, R.; and Constant, N. 2021. The power of scale for parameter-ef ficient prompt tuning. arXiv pr eprint arXiv:2104.08691 . Li, X. L.; Holtzman, A.; Fried, D.; Liang, P .; Eisner , J.; Hashimoto, T .; Zettlemoyer , L.; and Lewis, M. 2022. Con- trastiv e decoding: Open-ended text generation as optimiza- tion. arXiv preprint . Li, X. L.; and Liang, P . 2021. Prefix-tuning: Optimiz- ing continuous prompts for generation. arXiv pr eprint arXiv:2101.00190 . Lialin, V .; Deshpande, V .; and Rumshisky , A. 2023. Scaling down to scale up: A guide to parameter -ef ficient fine-tuning. arXiv pr eprint arXiv:2303.15647 . Liu, A.; Han, X.; W ang, Y .; Tsvetko v , Y .; Choi, Y .; and Smith, N. A. 2024. T uning language models by proxy . arXiv pr eprint arXiv:2401.08565 . Liu, A.; Sap, M.; Lu, X.; Swayamdipta, S.; Bhagav atula, C.; Smith, N. A.; and Choi, Y . 2021a. DExperts: Decoding- time controlled text generation with experts and anti-experts. arXiv pr eprint arXiv:2105.03023 . Liu, H.; T am, D.; Muqeeth, M.; Mohta, J.; Huang, T .; Bansal, M.; and Raffel, C. A. 2022. Few-shot parameter- efficient fine-tuning is better and cheaper than in-context learning. Advances in Neural Information Pr ocessing Sys- tems , 35: 1950–1965. Liu, X.; Ji, K.; Fu, Y .; T am, W . L.; Du, Z.; Y ang, Z.; and T ang, J. 2021b. P-tuning v2: Prompt tuning can be compara- ble to fine-tuning univ ersally across scales and tasks. arXiv pr eprint arXiv:2110.07602 . Lu, X.; Brahman, F .; W est, P .; Jang, J.; Chandu, K.; Ravichander , A.; Qin, L.; Ammanabrolu, P .; Jiang, L.; Ram- nath, S.; et al. 2023. Inference-time policy adapters (ipa): T ailoring extreme-scale lms without fine-tuning. arXiv pr eprint arXiv:2305.15065 . Mihaylov , T .; Clark, P .; Khot, T .; and Sabharwal, A. 2018. Can a suit of armor conduct electricity? a new dataset for open book question answering. arXiv pr eprint arXiv:1809.02789 . Ormazabal, A.; Artetxe, M.; and Agirre, E. 2023. Comblm: Adapting black-box language models through small fine- tuned models. arXiv preprint . Rajpurkar , P .; Jia, R.; and Liang, P . 2018. Know what you don’t know: Unanswerable questions for SQuAD. arXiv pr eprint arXiv:1806.03822 . Roemmele, M.; Bejan, C. A.; and Gordon, A. S. 2011. Choice of Plausible Alternativ es: An Ev aluation of Com- monsense Causal Reasoning. In AAAI spring symposium: logical formalizations of commonsense r easoning , 90–95. Roziere, B.; Gehring, J.; Gloeckle, F .; Sootla, S.; Gat, I.; T an, X. E.; Adi, Y .; Liu, J.; Sauvestre, R.; Remez, T .; et al. 2023. Code llama: Open foundation models for code. arXiv pr eprint arXiv:2308.12950 . Shankar , I.; and Nikhil, C., Dandekarand K ornel. 2017. First Quora Dataset Release: Question Pairs. https://quoradata. quora.com/First- Quora- Dataset- Release- Question- Pairs. Snelson, E.; Ghahramani, Z.; and Rasmussen, C. 2003. W arped gaussian processes. Advances in neural information pr ocessing systems , 16. Socher , R.; Perelygin, A.; W u, J.; Chuang, J.; Manning, C. D.; Ng, A. Y .; and Potts, C. 2013. Recursiv e deep models for semantic compositionality over a sentiment treebank. In Pr oceedings of the 2013 confer ence on empirical methods in natural languag e pr ocessing , 1631–1642. Sun, T .; Shao, Y .; Qian, H.; Huang, X.; and Qiu, X. 2022. Black-box tuning for language-model-as-a-service. In Inter - national Confer ence on Machine Learning , 20841–20855. PMLR. T almor , A.; Herzig, J.; Lourie, N.; and Berant, J. 2018. Commonsenseqa: A question answering chal- lenge targeting commonsense kno wledge. arXiv pr eprint arXiv:1811.00937 . T eam, G.; Anil, R.; Borgeaud, S.; Alayrac, J.-B.; Y u, J.; Sori- cut, R.; Schalkwyk, J.; Dai, A. M.; Hauth, A.; Millican, K.; et al. 2023. Gemini: a family of highly capable multimodal models. arXiv preprint . T ouvron, H.; Martin, L.; Stone, K.; Albert, P .; Almahairi, A.; Babaei, Y .; Bashlykov , N.; Batra, S.; Bharga va, P .; Bhosale, S.; et al. 2023. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint . W arstadt, A.; Singh, A.; and Bowman, S. R. 2019. Neural network acceptability judgments. T ransactions of the Asso- ciation for Computational Linguistics , 7: 625–641. W illiams, A.; Nangia, N.; and Bo wman, S. R. 2017. A broad-cov erage challenge corpus for sentence understand- ing through inference. arXiv preprint . W illiams, C. K.; and Rasmussen, C. E. 2006. Gaussian pr o- cesses for machine learning , volume 2. MIT press Cam- bridge, MA. W ilson, A. G.; Knowles, D. A.; and Ghahramani, Z. 2011. Gaussian process regression networks. arXiv preprint arXiv:1110.4411 . Y ang, A.; Li, A.; Y ang, B.; Zhang, B.; Hui, B.; Zheng, B.; Y u, B.; Gao, C.; Huang, C.; Lv , C.; Zheng, C.; Liu, D.; Zhou, F .; Huang, F .; Hu, F .; Ge, H.; W ei, H.; Lin, H.; T ang, J.; Y ang, J.; Tu, J.; Zhang, J.; Y ang, J.; Y ang, J.; Zhou, J.; et al. 2025. Qwen3 T echnical Report. Zaken, E. B.; Ravfogel, S.; and Goldberg, Y . 2021. Bitfit: Simple parameter -efficient fine-tuning for transformer- based masked language-models. arXiv pr eprint arXiv:2106.10199 . Zhang, X.; Zhao, J.; and LeCun, Y . 2015. Character-le vel con volutional networks for text classification. Advances in neural information pr ocessing systems , 28. This appendix can be divided into six parts: 1. Section A provides details on the experimental setup, including model selection, prompt engineering under black-box constraints, and ev aluation configurations. 2. Section B presents the heuristic selection strategies and sensitivity analyses for key hyperparameters, including: (1) the input / output thresholds ( τ in , τ out ) in B.1 , (2) the re-querying gate threshold ( θ ) in B.2 , and (3) the logit difference weight ( α ) in B.3 . 3. Section C presents supplementary visualizations compar- ing the GP surrogate’ s output logits distrib utions with those of the target foundation model. 4. Section D presents more ablation results, showcasing the strength of GP-filter method through: (1) strong perfor- mance under e xtreme data scarcity in D.1, (2) significant advantages on challenging datasets in D.2, and (3) ro- bustness across v arying API call budgets in D.3. 5. Section E provides time and memory analysis for Log- itMap pair construction and GP training, demonstrating that our GP training phase is highly efficient and incurs minimal computational ov erhead. 6. Section F conducts real-world black-box tuning experi- ments with Qwen-Plus API, showing the practical effec- tiv eness of the our method under realistic constraints. A Implementation Details Prompt Construction As described in the main text, we separately employ Llama2-7B, Mistral-7B-Instruct- v0.1, Qwen3-8B, DeepSeek-R1-Distill-Qwen-14B as a small proxy model and Llama2-13B, Mistral-7B-Instruct-v0.2, Qwen3-14B, DeepSeek-R1-Distill-Qwen-32B as black-box foundation model. Although both models are inherently generativ e, many of our target tasks are classification- oriented. In strict black-box settings, we do not hav e ac- cess to model internals—such as modifying the architecture to append classification heads or accessing final-layer pa- rameters. T o accommodate this constraint, we design task- specific prompts that elicit the model to generate outputs consistent with the task’ s classification labels. For instance, in multiple-choice tasks, we craft prompts that guide the model to output a single option token (e.g., “ A”, “B”, “C”, etc.). For binary classification tasks (e.g., true / false), the model is prompted to respond with “Y es” or “No”. This approach allo ws us to interpret predictions by inspecting the logits of specific output tokens, without mod- ifying the model architecture, thus strictly adhering to the black-box setting. Each prompt is composed of sev eral components derived from the target dataset: • { sentence1 } , { sentence2 } or { text } : The main context. • { question } : The main question context. • { options } : The reasonable choices for the task (From original dataset or designed by us). • { answer } : The correct answer , which is included during training but omitted during testing. Our prompt details for 11 datasets are giv en in T able S1. Dataset Train Size T est Size Prompt Construction Details AG-Ne ws 120,000 7,600 This is a news article: { te xt } Question: { question } Options: { options } Answer: { answer } CoLA 8,551 1,043 Sentence: { text } Determine whether the given sentence is grammatically correct according to standard English grammar rules. Respond with a single word: ’Y es’ if the sentence is grammatically correct, or ’No’ if it is not. Answer: { answer } CoP A 1,000 500 Premise: { te xt } Question: What was the cause (or effect) ? Options: { options } Answer: { answer } SST -2 67,349 872 Sentence: { text } Question: What is the sentiment of the sentence? Options: { options } Answer: { answer } ARC-C 1,119 299 Question: { question } Options: { options } The correct answer is: { answer } Cs-QA 9,741 1,221 Question: { question } Options: { options } The correct answer is: { answer } OB-QA 4,957 500 Background Fact: { text } Question: { question } Options: { options } The correct answer is: { answer } MNLI 392,702 9,815 Premise: { sentence1 } Hypothesis: { sentence2 } Question: What is the relationship between the Premise and the Hypothesis? Options: { options } Please choose one option (A, B, or C) as your answer . Answer: { answer } QNLI 104,743 5,463 Question: { question } Sentence: { text } Does the sentence entail the answer to the question? Reply with ’Y es’ or ’No’. Answer: { answer } R TE 2,490 277 Premise: { sentence1 } Hypothesis: { sentence2 } Does the premise entail the hypothesis? Reply with ’Y es’ or ’No’. Answer: { answer } QQP 363,846 40,430 Question1: { sentence1 } Question2: { sentence2 } Question: Are these two questions semantically equiv alent? (Y es or No) Answer: { answer } T able S1: Prompt Construction for Each Dataset. Experimental Methods and Configurations All exper- iments are conducted using the PyT orch frame work, with comprehensiv e e valuations and comparisons of multiple tun- ing approaches: (1) LoRA-tuning and full-precision direct tuning on both small proxy and large black-box model. (2) Proxy-based tuning methods for black-box settings, includ- ing Proxy-T uning (PT) (Liu et al. 2024), Consistent Proxy T uning (CPT) (He et al. 2024), and our proposed Gaussian Process-based proxy tuning method, with both random sam- pling and rule-based filtering strategies. T o ensure a fair and reproducible comparison, we use con- sistent training settings across all proxy-based tuning meth- ods. All experiments are conducted on a single machine equipped with 6 NVIDIA GeForce R TX 4090 GPUs. W e uti- lize mixed-precision training (fp16) for efficienc y . The key hyperparameters are summarized in T able S2. Setting V alue Number of GPUs 6 (NVIDIA GeForce R TX 4090) T raining epochs 2 Batch size per device 4 Gradient accumulation steps 8 Optimizer paged adamw 32bit Learning rate 2 × 10 − 4 Learning rate scheduler Linear Precision Mixed precision (fp16) torch.dtype torch.float16 T able S2: Experimental settings details. B Hyperparameter Selection B.1 Input and Output Thresholds τ in , τ out The thresholds τ in and τ out are hyperparameters for our GP filtering method (Algorithm 1). τ in is the criterion for the input embedding space, and τ out is the criterion for the out- put logits. These thresholds jointly gov ern the filtering strin- gency for selecting LogitMap P airs, which form the training dataset for our GP surrogate model. T o determine these thresholds heuristically , we conduct an initial calibration run of Algorithm 1 using permissiv e (i.e., very low) values for τ in and τ out . This allows the col- lection of scalar metric values from all potential input em- beddings (forming set M in ) and their corresponding output logits (forming set M out ). After sorting these metrics, we set τ in and τ out to the 1st percentile of the sorted values in M in and M out , respectively . This percentile-based heuristic of- fers a simple yet effecti ve way to adapti vely set τ in and τ out . In our experiments, this strategy results in only ≈ 0 . 7% of API calls being used during the filtering process on av erage, while still preserving high data div ersity . B.2 Gate Threshold θ T o efficiently manage API calls during proxy model M + s fine-tuning, we employ an uncertainty-guided re-querying strategy . When GP model predictions are highly uncertain (i.e., exhibit a large standard de viation σ M gp ( x ) ), a gating threshold θ determines whether to consult M l . This θ is heuristically initialized at the 1st percentile of sorted GP un- certainty v alues, thereby targeting the top 1% of the most un- certain training queries for re-e valuation by M l . This adap- tiv e mechanism aims to mitigate noise from lo w-confidence GP predictions, preserving the quality of supervision and en- hancing both training stability and task performance. The selection of the 1st percentile as this initial threshold is empirically validated by the characteristic distribution of GP uncertainties across datasets, as illustrated in Figure S1. These distributions consistently show a steep decline in un- certainty for a small fraction of examples (typically the top 1%), followed by a gradual decrease or plateau. Notably , this 1st percentile threshold (demarcated by the orange segment in Figure S1) often coincides with a discernible elbow or inflection point in the uncertainty curves of many datasets (e.g., CoLA, A G-Ne ws, QNLI, SST -2, and MNLI). For other datasets (COP A, OBQA, R TE), this top 1% region also reli- ably isolates instances of acutely high, rapidly diminishing uncertainty . These observations underscore that this top 1% subset generally comprises the least reliable GP predictions, making them primary candidates for re-querying via M l . Building upon the 1st percentile as an empirically grounded default, we further refine API e xpenditure by opti- mizing the re-querying budget per dataset. Starting from this 1% target, we reduce the re-querying volume while moni- toring task performance to prev ent degradation. The CoLA dataset ex emplifies this strategy’ s efficac y: re-querying only ≈ 0 . 07% of its most uncertain examples during fine- tuning—coupled with an initial data construction cost of just ≈ 0 . 02% —deli vered strong results with a total API over - head of merely ≈ 0 . 09% . On average, across all datasets, Figure S1: V isualization of sorted Gaussian Process predic- tion uncertainties ( τ M gp ( x ) ) across 8 benchmark datasets: CoLA, A G-News, QNLI, SST -2, MNLI, COP A, OBQA, and R TE. The orange se gment in each plot highlights the top 1% of queries with the highest uncertainty , prompting the system to query the large model M l . The red dashed line marks the 1st percentile uncertainty value, serving as the gate threshold θ , which consistently aligns with a sharp de- cline or “elbow” in the uncertainty distrib ution. this active re-querying phase during fine-tuning accounts for only ≈ 0 . 7% of API calls. This adaptiv e, cost-aw are methodology achiev es an effecti ve balance between com- putational efficienc y and high-quality supervision, fostering reliable proxy model training with minimal ov erhead. B.3 W eight of Logit Difference α The hyperparameters α train and α test control the influence of the logit difference term, which quantifies the div ergence be- tween the logits of the primary model (GP model or large black-box model) and the untrained proxy model. W e con- sistently set α train to 0.8 across all datasets in experiments. For main results reported in T able 1, α test was also set to 0.8 to maintain consistency with the training configuration. T o assess the sensitivity of our method to different α val- ues, we conducted additional experiments on the CoLA and R TE using our GP-filter method. The results, visualized as heatmaps in Figure S2, rev eal sev eral key trends. Firstly , the highest performance scores are generally achiev ed when α train and α test are aligned (i.e., their v al- ues are approximately equal). This corresponds to the re- gions along the main diagonal of the heatmaps, highlighted Figure S2: Heatmaps illustrating the performance (i.e., accu- racy scores, where darker shades indicate higher values) on the CoLA and R TE for various combinations of α train and α test . The red ellipses highlight regions where α train ≈ α test , generally corresponding to optimal performance. by the red ellipses. This finding underscores the importance of maintaining consistency in the weighting of the logit dif- ference term between the training and inference phases. Secondly , while aligning α train and α test is generally bene- ficial, an important pattern emerges when observing perfor- mance along the main diagonal of the heatmaps (Figure S2). Specifically , as both α train and α test concurrently increase to very high values (bottom-right corner), an obvious degra- dation in performance is observed. This decline appears to stem primarily from two interconnected factors: • Over -reliance on the Large Model. When α becomes excessi vely large, the proxy model may become overly influenced by the large model’ s outputs during fine tun- ing, leading to an ov er-reliance on its guidance. This, in turn, can diminish the supervision of the fine tuning data, making it difficult for proxy to capture task-specific nu- ances and generalize effecti vely . • Pr opagation of Large Model’s Noise. When the large model’ s output logits are inherently noisy or exhibit high uncertainty for data instances, an overly large α may lead the proxy model to internalize this noise. Moreover , the large model’ s guidance can substantially deviate from the true output distribution, thereby disrupting the proxy’ s learning process and ultimately undermining its predic- tiv e stability and ov erall accuracy . These observations indicate that both aligning and prop- erly scaling α train and α test are critical. The proxy model should be able to benefit from the large model’ s guidance without compromising its own learning capacity . Based on our empirical analyses (as illustrated in Figure S2), we rec- ommend selecting α values within the approximate range of [0.6, 1.4]. Across all our main experiments, setting α train = α test = 0 . 8 consistently provided a strong balance and rob ust performance across all ev aluated datasets. C Comparison of Output Logits Distributions f or Additional Datasets This appendix pro vides supplementary visualizations for the ablation study on API call usage presented in the main text. (a) CoP A: across six API call budgets (b) R TE: across six API call budgets (c) OBQA: across six API call budgets (d) MRPC: across six API call budgets Figure S3: Supplementary distribution comparisons, com- plementing Figure 2 from the main text. While the main text discusses CoLA (Figure 2a) and ARC-C (Figure 2b), this section presents the corresponding output logits distribution comparisons for the remaining four datasets: COP A, R TE, OBQA, and MRPC. The methodol- ogy for comparison remains consistent: for each dataset and varying API calls, we compare the logits distributions from GP models against those of the Llama2-13B target model. Figure S3 displays these comparisons for the 4 additional datasets. As with the figures in main text (Figure 2), within each dataset’ s visualization, the left panel depicts the output logits distribution from the GP model, while the right panel shows the distrib ution from the large tar get model. The visualizations for COP A (Figure S3a), R TE (Fig- ure S3b), OBQA (Figure S3c), and MRPC (Figure S3d) gen- erally exhibit trends consistent with those detailed for CoLA and ARC-C in the main te xt. Notably , under se vere API call limitations, the GP logit distributions tend to be more com- pressed. Con versely , with lar ger API call b udgets, these dis- tributions more closely mirror those of the 13B model. This consistency across di verse datasets and data regimes further underscores the robustness of our GP-filter method. D Ablation Study Supplement This section presents additional details and results from the ablation studies discussed in the main text, with a focus on ev aluating the performance of our GP-filter method under extreme data scarcity , across challenging datasets, and under varying API call b udgets. D.1 Perf ormance under Extreme Data Scar city The main text highlights that our GP-filter method maintains high performance ev en under conditions of extreme train- ing data scarcity , where direct fine-tuning of proxy models (i.e., Llama2-7B ) can be significantly less effecti ve. T able S3 presents the detailed experimental results that substantiate this claim. As indicated by the average scores, the GP-filter approach achie ves an accuracy of 72.91%, which is 6.31 percentage points higher than the 66.60% achiev ed by full- precise fine-tuning Llama2-7B . This strong performance is achiev ed with minimal API usage: the combined cost of GP model training and re-querying stages during proxy training av eraged only 2.91% of the data in the scarcity experiments (see API Usage Percentage in T able S3). Model & Method Accuracy (%) ↑ AG-Ne ws CoLA CoP A SST-2 ARC-C Cs-QA OB-QA MNLI QNLI RTE QQP Avg. 7B Full Fine-tune 92.88 74.40 61.40 81.31 43.81 32.76 53.40 87.61 63.41 54.15 87.42 66.60 Proxy-Tune 92.63 74.88 78.40 80.85 56.19 49.96 57.60 87.55 74.70 57.76 87.45 7 2.54 GP-filter 92.68 73.73 78.80 83.14 56.52 49.71 57.20 88.06 76.66 58.12 87.40 72.91 T otal Data Size 12,000 800 500 200 100 120 500 10,000 500 100 10,000 - API Usage Amount 266 6 10 8 5 4 9 21 35 5 75 - API Usage Percentage 2.22% 0.75% 2.00% 4.00% 5.00% 3.33% 1.80% 0.21% 7.00% 5.00% 0.75% 2.91% T able S3: Experiment on small subset training data. Perfor- mance is measured by Accuracy (%). D.2 Perf ormance on Challenging Datasets As mentioned in the main text, our GP-filter method demon- strates a clear performance advantage o ver offline black- box tuning methods such as Proxy Tuning (Liu et al. 2024), particularly on inherently challenging datasets. This section presents a detailed comparative analysis on such tasks, with results summarized in T able S4. T o further assess robustness, we ev aluate on three ad- ditional dif ficult datasets for lar ge language models: the Microsoft Research Paraphrase Corpus (MRPC), Winograd Schema Challenge (WSC), and Adversarial Natural Lan- guage Inference (ANLI). T ogether with the three main datasets (ARC-C, Cs-QA, and R TE), this yields a suite of six challenging benchmarks. As shown in T able S4, our GP-filter method consistently and substantially outperforms Proxy-T une across all tasks, achie ving an av erage accuracy of 73.47%, with 4.19 percentage point improv ement over Proxy-T une (69.28%). Notably , this improvement is attained with only 1.99% average API usage of the large model M l , highlighting the efficienc y of our method. Model & Method Accuracy (%) ↑ ARC-C Cs-QA R TE MRPC WSC ANLI A vg. 7B Full Fine-tune 53.85 76.17 84.84 86.03 50.00 69.00 69.98 Proxy-T une 57.53 75.35 82.67 84.07 47.67 68.40 69.28 GP-filter 61.20 78.95 87.73 87.50 54.65 70.80 73.47 GP API Usage 3.31% 1.95% 2.17% 2.37% 1.51% 0.64% 1.99% T able S4: Experiment on challenging datasets. Performance is measured by Accuracy (%). The superior performance of our GP-filter method on challenging datasets stems from its fundamentally differ - ent approach to leveraging foundation model knowledge. In contrast, Proxy-T une first trains a smaller proxy model in isolation and then combines its predictions with those of a zero-shot foundation model at inference time. On complex tasks, both components in Proxy-Tune can face limitations: the small proxy model is constrained by its capacity , while the large foundation model may be hampered by the inher- ent task difficulty or suboptimal prompting. Consequently , a simple inference-time amalgamation of their outputs, as em- ployed by Proxy-T une, often yields only marginal improv e- ments or can e ven underperform a directly fine-tuned small model on these specific tasks. In stark contrast, our GP-filter approach integrates the large model’ s insights more deeply and adaptiv ely through- out the proxy model’ s training phase, addressing the afore- mentioned limitations: • Continuous and Adaptive Guidance: The GP surrogate model is trained to emulate the foundation model’ s be- havior , offering a rich, continuous, and adaptive guidance signal to the proxy model M + s during fine-tuning. This is substantially more effecti ve than a static inference-time combination. • Impr oved Knowledge Internalization: The GP model aims to capture the underlying “kno wledge structure” or decision manifold of the large foundation model. By fine- tuning the proxy model M + s with this dynamically in- formed GP surrogate, M + s dev elops a more nuanced and robust task-specific representation, thereby elev ating its ov erall performance ceiling and intrinsic capabilities. The superior performance of our GP-guided fine-tuning on challenging datasets (T able S4) demonstrates the proxy model’ s enhanced ability to internalize sophisticated reason- ing patterns. These empirical results underscore the impor- tance of dynamically integrating knowledge from M l dur- ing training, especially in scenarios where con ventional of- fline proxy fine-tuning prov es inadequate. D.3 Perf ormance under Different API Usage T o further in vestigate the impact of API call volume on the performance of our GP surrogate model, we conducted a se- ries of ablation studies. This section details our e xperiments on the COP A and ARC-C datasets, examining ho w varying the number of API calls used to train the GP surrogate influ- ences its ability to guide the proxy model. Our findings indicate that increasing the number of API calls does not necessarily lead to improv ed final accuracy . As illustrated in Figure S4a and Figure S4b, the perfor- mance on both COP A and ARC-C datasets does not exhibit a monotonically increasing trend with more API calls. Al- though the GP surrogate’ s output distribution becomes pro- gressiv ely more refined to closely mimic the target model’ s (as detailed in Section C), this refinement leads the over - all proxy model performance to con ver ge towards the CPT baseline, rather than achieving continuous impro vement. (a) Accuracy on COP A with varying numbers of API calls (b) Accuracy on ARCC with v arying numbers of API calls Figure S4: Accuracy comparison on COP A and ARCC with varying numbers of API calls used for GP model training. Interestingly , the figures highlight two key observations: First, peak accuracy is often achie ved with a relati vely small number of API calls. This aligns with our hypothesis that ef- fectiv e guidance from the GP surrogate hinges on capturing the ov erall structure of the tar get model’ s logits distribution, rather than requiring an exact replication of the logits them- selves. Second, the consistent outperformance of our GP- filter method compared to the GP (random) approach under- scores the effecti veness of our filter mechanism in facilitat- ing this efficient kno wledge transfer . Furthermore, experiments on large-scale datasets such as MNLI and QQP (about 400,000 instances each) demonstrate that training the GP surrogate on a small filtered subset (e.g., 300 samples) can yield strong performance, even surpass- ing the CPT baseline. In contrast, using larger subsets (e.g., 10,000 samples) led to degraded performance and frequent GP training failures, including NaN predictions. These is- sues likely arise from two factors: (1) the O ( N 3 ) computa- tional complexity of GP regression, which makes training on 10,000 samples impractical; and (2) increased risks of over - fitting and numerical instability during kernel matrix in ver - sion (especially with dense or collinear data points), which can result in NaN outputs. Our filtering strategy mitigates both challenges by selecting a diverse and informative sub- set, enabling stable and efficient GP training. In summary , this ablation study underscores the effecti ve- ness of a “less is more” strategy: a small, well-curated subset not only ensures stable and ef ficient learning, but also im- prov es generalization, making GP-filter methods both scal- able and effecti ve in practice. E Time and Memory Analysis of LogitMap Pair Construction and GP T raining T o better assess the efficienc y of our LogitMap pair con- struction and the subsequent Gaussian Process (GP) model training, we record both time and memory consumption un- der two distinct data selection strategies. Experiments are conducted on the QQP dataset (Shankar and Nikhil 2017) using models from the Mistral-7B family (Jiang et al. 2023). Specifically , as described in the “Empirical Data Selection” section in “Experiments”: • In the random-based setup, we randomly sample 5K training examples, following the upper bound suggested in the “Empirical Data Selection” section. • In the filter-based setup, we apply Algorithm 1 to se- lect approximately 3K informati ve e xamples (specifi- cally , 2,825), also in line with the upper bound recom- mendation. Execution time was recorded using Python’ s time li- brary , while peak memory consumption was recorded via the tracemalloc library . For training GP model, we uti- lize GaussianProcessRegressor from sklearn li- brary . W e split the process into two phases. Phase 1: Con- structing LogitMap Pairs. Phase 2: Training the GP model using the selected subset. As shown in T able S5, both phases are highly efficient in terms of time and memory consumption. Notably , ev en in the computationally intensi ve filter -based setup, the total time required is approximately 1,912 seconds, or just over 0.53 hours . In contrast, fine-tuning the small proxy model Method Time (s) Memory (MB) Phase 1 Phase 2 Phase 1 Phase 2 Random-based 557.76 138.14 41.77 841.24 Filter-based 1890.36 21.63 19.95 216.25 T able S5: T ime and peak memory usage for constructing LogitMap Pairs (Phase 1) and training the GP model (Phase 2) under two data selection strategies on the QQP dataset. requires approximately 16 hours on 6 R TX 4090 GPUs for a standard two-epoch training, highlighting the negligible ov erhead of our data selection and GP-fitting pipeline. From a memory perspective, both strate gies maintain a re- markably low footprint. The peak memory usage stays well below 1 GB in all phases, with the filter-based strate gy con- suming only 216.25 MB during GP training—further high- lighting the lightweight nature of our method. These results demonstrate that our approach not only scales effecti vely to large datasets but also offers a practical, resource-efficient alternativ e to con ventional proxy tuning. F Real-W orld Black-box T uning Experiment W e accessed the Qwen-Plus model via API calls as follows: 1 completion = client.chat.completions. create( 2 model="qwen-plus", 3 messages=[ 4 {"role": "system", "content": " You are a helpful assistant." }, 5 {"role": "user", "content": prompt} 6 ], 7 logprobs=True, 8 top_logprobs=5, 9 max_tokens=512 10 ) 11 lp = completion.choices[0].logprobs. content[0].top_logprobs In realistic black-box settings, LLM pro viders (e.g., Chat- GPT , Qwen) typically offer log-probability access limited to only the top-5 most likely tokens. For our GP-filter tun- ing, we le verage this constraint by e xtracting the top-5 token IDs and their associated log-probabilities from the black-box model’ s response. These token IDs are then aligned with the white-box proxy model’ s v ocabulary to enable logit-le vel supervision. Despite this restriction, we find that careful prompt de- sign can ensure the critical tokens are consistently included in the top-5 set. For instance, when using classification-style prompts (e.g., yes / no questions), the relev ant tokens (such as “yes” and “no”) almost always appear among the top- 5 predictions. In generati ve settings, we assume the black- box model’ s top-ranked token IDs to guide the white-box model’ s fine-tuning, ensuring stylistic and semantic align- ment between the two. This strategy allo ws our method to operate effecti vely within realistic API constraints, while still achieving precise logit-le vel guidance. W e e valuate on the R TE (Recognizing T extual Entail- ment) dataset (Dagan, Glickman, and Magnini 2005) using Qwen3-series models (1.7B, 4B, 8B, 14B) (Y ang et al. 2025) as white-box proxies. Results are summarized in T able S6. Method 1.7B 4B 8B 14B Qwen3-Pretrain 66.18% 84.73% 85.82% 83.64% Qwen3-GP-tuned 80.73% 86.55% 87.64% 92.36% Qwen-Plus (origin) 90.91% Qwen-Plus (GP-filter) 91.27% 91.27% 92.36% 93.45% Few-shot (1-shot) 90.91% Few-shot (5-shot) 91.27% Few-shot (10-shot) 91.64% T able S6: V alidation accuracies on R TE under GP-filter black-box tuning. Notes: two R TE validation examples were filtered by the provider’ s safety mechanism, resulting in a to- tal of 275 examples. T able S6 reports the R TE validation accuracies under various inference and tuning settings. The row “Qwen3- Pretrain” shows zero-shot performance using the origi- nal pretrained weights of the four Qwen3 proxy models (1.7B–14B). “Qwen3-GP–tuned” gives the accuracies after fine-tuning those proxies with our GP-filter method. “Qwen- Plus (origin)” is direct zero-shot inference with the black- box Qwen-Plus model, while “Qwen-Plus (GP-filter)” per- forms inference by ensembling the logits from Qwen3 prox- ies and the Qwen-Plus model (see Equation 7). “Few-shot” refers to the performance of the black-box Qwen-Plus model under few-shot inference. It is immediately clear that GP-filter yields consistent improv ements: for example, the Qwen-Plus improv es from 90.91% to 93.45% when ensembled with GP-tuned Qwen3- 14B proxies. Crucially , we only issued 31 API calls to Qwen-Plus to train the Gaussian Process surrogate (total 2,490 training samples), demonstrating exceptional effec- tiv eness and cost-efficienc y . By contrast, static few-shot prompting requires much larger input contexts (slower inference) and delivers no sub- stantial accuracy gains (1-shot: 90.91%, 5-shot: 91.27%, 10-shot: 91.64%). W e attrib ute this to few-shot examples teaching only formatting con ventions rather than the model’ s internal reasoning. In contrast, GP-filter integrates black- box model guidance directly into proxy training, effecti vely transferring do wnstream dataset kno wledge. This adv antage is especially pronounced on harder examples: further in- creasing the number of few-shot examples fails to improve accuracy , whereas our GP-filter method continues to yield gains (see Appendix D.2).
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment