Model error moment estimation via data assimilation
Using a dynamical model to make predictions about a system has many sources of error. These can include errors in how the model was initialised but also errors in the dynamics of the model itself. For many applications in data assimilation, probabili…
Authors: P.A. Browne
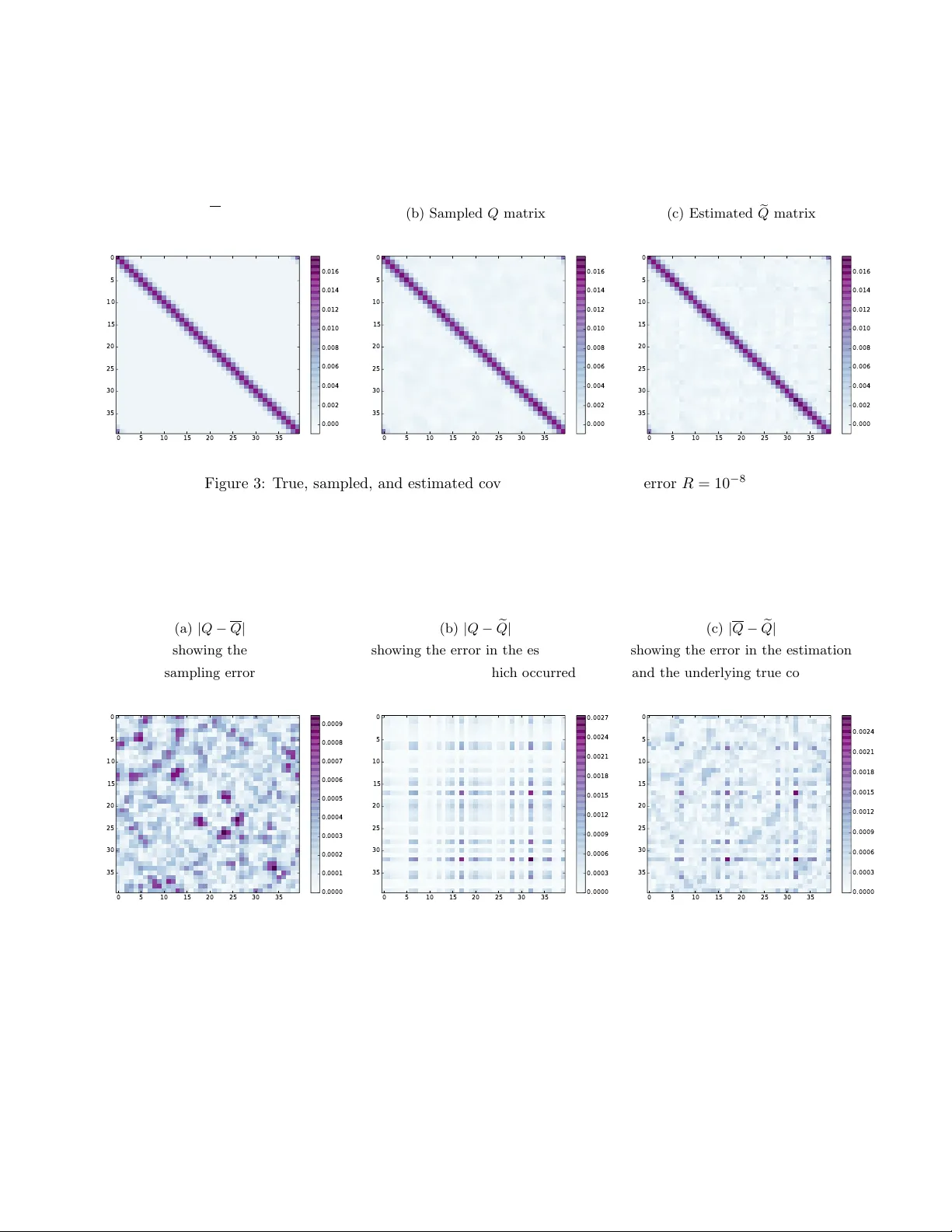
F or review SIAM UQ Mo del error momen t estimation via data assimilation P .A. Bro wne 1,* 1 Departmen t of Meteorology , Universit y of Reading, UK * Corresp ondence to p.bro wne@reading.ac.uk No vem ber 7, 2018 Abstract Using a dynamical mo del to make predictions ab out a system has man y sources of error. These can include errors in how the mo del was initialised but also errors in the dynamics of the mo del itself. F or man y applications in data assimilation, probabilistic forecasting, or mo del improv emen t, these mo del errors need to b e known ov er the timestep of the mo del, not o ver a time-av eraged p eriod. Using a forecast from a state that combines observ ational information as well as prior information we can gain an approximation to the statistics of the mo del errors on the timescale of the mo del that is required. Here we give bounds on the errors in the estimation of the mean and co v ariance of the errors in the mo del equations in terms of the errors made in the state estimation. This is the first time that suc h a result has b een derived. The result sho ws to what extent the state estimation m ust constrain the analysis in order to obtain a sp ecified error on the mean or co v ariance of the model errors. This is particularly useful for exp erimen tal design as it indicates the necessary information conten t required in observ ations of the dynamical system. Keyw ords: mo del error estimation, data assimilation, analysis forecast, mo del error cov ariance estimation 1 In tro duction Supp ose w e ha ve a numerical mo del, f , for a dynamical pro cess: x k +1 = f ( x k ) (1) where x ∈ R N is the state at time indexed by k . Then it is almost certain that such a n umerical mo del f will con tain errors. A large amount of uncertaint y quan tification has rev olved around providing b ounds of the accuracy of 1 F or review SIAM UQ the numerical sc heme used to approximate the underlying mathematical or statistical problem [Owhadi et al., 2013; T eck entrup et al., 2013]. This ignores one large issue: the underlying mathematical problem do es not represen t all of the features of the real w orld system in which one is interested. F or example, when mo delling wind around a wind farm, drag induced by individual trees/plants will likely not b e included. Instead, some approximate homogenised quan tity will be used. As another example, when mo delling carb on fibre composites, sp ecific manufacturing defects will not b e included in the mo del un til measurements of the materials response under v arious loading conditions are incorp orated. The ubiquitous quote on this issue is from Box and Drap er [1987]: “All mo dels are wrong but some are useful”. The problem we address is ho w to estimate the distribution of the errors that are made by the mathematical mo del in sim ulating a physical system. T o get a measure of how far a mathematical mo del is deviating from the real world, it is necessary to use observ ations from the system as an indep enden t source of information. T ypically we shall never b e able to fully observe a system (in time and/or space) and so one has to b e careful ho w to compare a small set of observ ations with the larger model of the system. The theoretical framework to do this rigorously is w ell established: using data assimilation to numerically implemen t Ba yes’ theorem [Jazwinski, 1970, for example]. A physical system that occurs in nature has only one realisation. W e refer to that realisation as the truth and denote it x t . If we use such a truth with the n umerical model of the system we hav e the follo wing ev olution equation, x k +1 t = f ( x k t ) + β k . (2) Here β k is the mo del error term which is a realisation of a stochastic process which occurs at time k . W e wish to estimate, through the use of data assimilation, the prop erties of the distribution that β k follo ws. The first tw o momen ts of this unkno wn distribution, its mean and cov ariance, are denoted µ and Q resp ectiv ely . Knowledge of β k can b e fed back in to the dynamical mo del f as a wa y to systematically improv e the mo del. F or example, directly subtracting µ from the mo del w ould b e an example of a bias correction metho d [e.g. Dee and Uppala, 2009], whereas the sources of these errors can b e attributed to comp onen ts of the mo del equations Lang et al. [2016] and thus can b e corrected to impro ve the mathematical mo del. W e use an y or all prior information we hav e, along with observ ations of the system to obtain a “b est estimate” of the truth. This is the data assimilation stage and results in what is referred to as the “analysis” , x a . There are many differen t tec hniques for data assimilation, each which make v arious assumptions or simplifications to Bay es’ theorem. See Evensen [2007] or Law et al. [2015] for an ov erview of the field. Once we hav e x a w e define our appro ximation to the mo del error at timestep k , e β k , with the equation x k +1 a = f ( x k a ) + e β k . (3) 2 F or review SIAM UQ This makes no assumptions on ho w x a is calculated. Ho wev er, w e can immediately see that one traditional metho d of data assimilation is inappropriate to estimate the β k term. Remark 1. T o estimate β k , x a should not b e obtaine d fr om str ong c onstr aint 4DV ar (SC-4DV ar). In SC-4DV ar the analysis at time 0, x 0 a is given as x 0 a = arg min x 0 || x 0 − x b || 2 B − 1 + m X i =1 || y k i − H k i ( f k i ( x 0 )) || 2 R − 1 k i . (4) Here, x b is a background estimate for the state at time 0, assumed to b e Gaussian with bac kground error co v ariance matrix B . Observ ations of the system y are tak en at m separate times k i . The observ ation is related to the system through the observ ation equation y k i = H k i ( x k i t ) + η k i , where the observ ation errors η k i are assumed to b e Gaussian with an observ ation error co v ariance matrix R k i . Then at subsequent times in the assimilation window, x k +1 a = f ( x k a ) = f k +1 ( x 0 a ) (5) and thus e β k = 0 ∀ k ∈ { 0 , . . . , τ − 1 } . 1.1 Usage of the mo del error co v ariance matrix Q Ha ving an estimate for Q is imp ortan t as it plays a vital role in many mo dern data assimilation metho ds. In the v ariational metho d of data assimilation known as weak constraint 4DV ar (WC-4D V ar), in addition to the background and observ ation terms of SC-4DV ar, a third term is introduced to p enalise the addition of mo del error [Jazwinski, 1970], which is implicitly assumed to follow a Gaussian distribution. min x 0 ,β 0 ,...,β k − 1 || x 0 − x b || 2 B − 1 + m X i =1 || y k i − H k i ( x 0 , β 0 , . . . , β k i − 1 ) || 2 R − 1 k i + k − 1 X j =0 || β j || 2 Q − 1 (6) In this formulation, x 0 is the initial state which the metho d seeks to find, along with mo del error terms β 0 , . . . , β k − 1 . The first term penalises the difference in the initial state x 0 and an initial guess kno wn as the bac kground term x b , weigh ted by the in verse of the bac kground error cov ariance matrix B . The second term p enalises discrepancies b et w een observ ations of the system y k i and the mo del equiv alent of the observ ations at the corresp onding time, H k i ( x 0 , β 0 , . . . , β k i − 1 ), all weigh ted by the appropriate observ ation error cov ariance matrix R k i . This notation hides the fact that H k i ( x 0 , β 0 , . . . , β k i − 1 ) = H k i ( x k i ) = H k i ( f ( x k i − 1 ) + β k i − 1 ) = H k i ( f ( f ( x k i − 2 ) + β k i − 2 ) + β k i − 1 ) = . . . etc. The final term p enalises the in tro duction of mo del error at each model timestep j , weigh ted by the model error co v ariance matrix Q . 3 F or review SIAM UQ In particle filters, such as the equiv alen t w eights particle filter [v an Leeuw en, 2010], Q is used as part of the prop osal densit y to bring the ensemble closer to the observ ations. It also appears in the computation of weigh ts asso ciated with eac h particle. Bro wne and v an Leeu wen [2015] sho wed that the lack of information regarding Q is the limiting factor to applying particle filters in large-scale geoph ysical systems. 1.2 Previous w ork on model error estimation Muc h of the work to estimate Q has b een undertaken at the European Centre for Medium-range W eather F orecasting (ECMWF) in the con text of implemen ting a form of WC-4D V ar for operational n umerical weather forecasting. The lac k of kno wledge of Q is one of the main reasons that suc h weak-constrain t metho ds are not operational. T r´ emolet [2006] notes “W eak-constraint 4D-V ar has never b een implemented fully with a realistic forecast mo del b ecause of the computational cost and b ecause of the lac k of information to define the mo del-error cov ariance matrix required to solv e the problem”. It has b een shown [T r´ emolet, 2007] that for the atmospheric case, the background error cov ariance matrix ( B ) is not successful as an appro ximation to the mo del-error cov ariance matrix ( Q ). As an ad ho c approximation to Q , T r´ emolet [2007] suggests the following. A t time k , get an ensemble of analysis states { x k i } . As each ensemble member should b e indistinguishable from the truth, eac h forecast f ( x k i ) could b e considered a “p ossible evolution of the atmosphere from the true state”. F rom this, T r´ emolet concluded that the differences in these forecast increments could b e in terpreted as “an ensemble of p ossible realisations of mo del error”. The real world, how ever, has only one realisation. Hence one needs to compare these forecasts not with themselves, but with the observ ations instead. In this wa y , one disco vers not just where the mo del div erges based on its initial conditions, but where it has failed to capture the realisation of the underlying sto c hastic dynamics. A smo other is a sequen tial metho d of data assimilation that gives an estimate of x a for all k , not simply at timesteps where observ ations are presen t. Recently , the concept of using a forecast from a lag-1 smoother estimate to appro ximate the mo del error cov ariances has b een inv estigated [T o dling, 2015]. This work only considers estimating the Q the problem in observ ation space, and do not lo ok at the full information av ailable to them in state space. This is ph ysically motiv ated as in the case where only the observ ed v ariables of the dynamical system are w ell constrained, only the pro jection of Q in to the observ ation space will b e accurate. Suc h deriv ations from a smo other tra jectory hav e b een inv estigated by Lang et al. [2016] in the context of parameter and parameterization estimation. When the mo del error can be attributed to incorrect co efficien ts in the formulation of the mo del equations then it has b een shown that the first momen t of the derived mo del error can b e used to determine the necessary corrections to the parameters used in the n umerical mo del. This can b e extended to estimation of parameterizations when the first momen t of the mo del error is regressed on to differen t functions of the mo del state 4 F or review SIAM UQ v ector. How ever higher order moments ha ve not b een inv estigated. 2 Error b ounds on the estimation of the first t w o momen ts of mo del error W e now set out on the main path of this pap er: to find a b ound on the error in the approximation of µ and Q in terms of the accuracy of x a in approximating x t . The main assumption w e shall make is that the dynamical mo del f is (Lipschitz) con tinuous. If the mo del were not con tinuous at x k t then regardless of how close w e appro ximate this argumen t, the resulting mo del tra jectory could b e wildly different. This w ould lead to a p o or appro ximation of the mo del error. Theorem 2. Supp ose f is Lipschitz with c onstant L and | x k t − x k a | < ε L +1 ∀ k . Then | e β k − β k | < ε . Pr o of. f Lipschitz = ⇒ ∃ L > 0 s.t. | f ( a ) − f ( b ) | ≤ L | a − b | ∀ a, b . β k = x k +1 t − f ( x k t ) , e β k = x k +1 a − f ( x k a ) . Hence | β k − e β k | = | x k +1 t − x k +1 a − f ( x k t ) + f ( x k a ) | ≤ | x k +1 t − x k +1 a | + | f ( x k t ) − f ( x k a ) | . As | x n t − x n a | < ε L +1 then | β k − e β k | ≤ ε L + 1 + εL L + 1 = ε. The sample mean of the mo del error, µ , is calculated simply as µ = 1 τ τ X k =1 β k . (7) The approximated sample mean of the mo del error, ˜ β k , in similarly calculated as e µ = 1 τ τ X k =1 e β k . (8) 5 F or review SIAM UQ Using these definitions and Theorem 2, w e can sho w the following b ound on the estimation of the mean of the model error distribution. Corollary 3. Supp ose f is Lipschitz and | x k t − x k a | < ε L +1 ∀ k . Then | e µ − µ | < ε . Pr o of. | µ − e µ | = 1 τ τ X k =1 β k − 1 τ τ X k =1 e β k (9) = 1 τ τ X k =1 β k − τ X k =1 e β k (10) = 1 τ τ X k =1 ( β k − e β k ) (11) ≤ 1 τ τ X k =1 β k − e β k (12) ≤ 1 τ τ X k =1 ε (13) = ε (14) W e now consider the second moment of the mo del error distribution. The sample co v ariance of model error is defined and approximated as, resp ectively , Q = 1 τ − 1 τ X k =1 ( β k − µ )( β k − µ ) T and e Q = 1 τ − 1 τ X k =1 ( e β k − e µ )( e β k − e µ ) T . (15) Lemma 4. If | f − L | < min { 1 , ε 2 | M | } and | g − M | < min { 1 , ε 2 | L | +2 } then | f g − LM | < ε . Pr o of. By the triangle inequality | f | − | L | ≤ | f − L | < 1 = ⇒ | f | < 1 + | L | . Hence | f g − LM | = | f ( g − M ) + M ( f − L ) | (16) ≤ | f || g − M | + | M || f − L | (17) < (1 + | L | ) ε 2 | L | + 2 + | M | ε 2 | M | (18) < ε 2 + ε 2 = ε. (19) 6 F or review SIAM UQ In tro ducing a subscript notation where · i refers to the i th comp onen t of a v ector and · ij refers to the i th , j th comp onen t of a matrix, we show the following preliminary result. Lemma 5. Supp ose f is Lipschitz with c onstant L and for al l k ∈ { 1 , . . . , τ } | β k i − e β k i | < min ( 1 , ε 8 | β k j | τ − 1 τ , ε 8 | µ j | τ − 1 τ ) , (20) | β k j − e β k j | < min 1 , ε 8 | β k i | + 8 τ − 1 τ , ε 8 | µ i | + 8 τ − 1 τ , (21) | µ i − e µ i | < min ( 1 , ε 8 | β k j | τ − 1 τ , ε 8 | µ j | τ − 1 τ ) , (22) | µ j − e µ j | < min 1 , ε 8 | β k i | + 8 τ − 1 τ , ε 8 | µ i | + 8 τ − 1 τ . (23) Then | Q ij − e Q ij | < ε . Pr o of. Q ij − e Q ij = 1 τ − 1 τ X k =1 h ( β k i − µ i )( β k j − µ j ) − ( e β k i − e µ i )( e β k j − e µ j ) i (24) = 1 τ − 1 τ X k =1 h ( β k i β k j − e β k i e β k j ) − ( β k i µ j − e β k i e µ j ) − ( µ i β k j − e µ i e β k j ) + ( µ i µ j − e µ i e µ j ) i (25) Hence Q ij − e Q ij ≤ 1 τ − 1 τ X k =1 h β k i β k j − e β k i e β k j − β k i µ j − e β k i e µ j − µ i β k j − e µ i e β k j + µ i µ j − e µ i e µ j i (26) By Lemma 4, if | e β k i − β k i | < min ( 1 , ε 8 | β k j | τ − 1 τ ) and | e β k j − β k j | < min 1 , ε 8 | β k i | + 8 τ − 1 τ (27) then β k i β k j − e β k i e β k j < ε 4 τ − 1 τ . (28) If | e µ i − µ i | < min 1 , ε 8 | µ j | τ − 1 τ and | e µ j − µ j | < min 1 , ε 8 | µ i | + 8 τ − 1 τ (29) 7 F or review SIAM UQ then | µ i µ j − e µ i e µ j | < ε 4 τ − 1 τ . (30) If | e β k i − β k i | < min 1 , ε 8 | µ j | τ − 1 τ and | e µ j − µ j | < min 1 , ε 8 | β k i | + 8 τ − 1 τ (31) then β k i µ j − e β k i e µ j < ε 4 τ − 1 τ . (32) Similarly , if | e µ i − µ i | < min ( 1 , ε 8 | β k j | τ − 1 τ ) and | e β k j − β k j | < min 1 , ε 8 | µ i | + 8 τ − 1 τ (33) then µ i β k j − e µ i e β k j < ε 4 τ − 1 τ . (34) Th us w e can combine these so that Q ij − e Q ij < 1 τ − 1 τ X k =1 ε 4 τ − 1 τ + ε 4 τ − 1 τ + ε 4 τ − 1 τ + ε 4 τ − 1 τ < ε. (35) It is now p ossible to obtain a b ound on the error in the cov ariance of the mo del error distribution in terms of the analysis error. F or clarit y , the notation · ,i also refers to the i th comp onen t of a vector that already has a subscript. Theorem 6. Supp ose f is Lipschitz with c onstant L . Supp ose further that, for al l k , the analysis satisfies | x k t,i − x k a,i | < 1 L + 1 min ( 1 , ε 8 | β k j | τ − 1 τ , ε 8 | µ j | τ − 1 τ ) (36) and | x k t,j − x k a,j | < 1 L + 1 min 1 , ε 8 | β k i | + 8 τ − 1 τ , ε 8 | µ i | + 8 τ − 1 τ (37) Then the c orr esp onding estimate d sample err or c ovarianc e satisfies | Q ij − e Q ij | < ε . Pr o of. By Theorem 2, if | x k t,i − x k a,i | < 1 L + 1 min ( 1 , ε 8 | β k j | τ − 1 τ , ε 8 | µ j | τ − 1 τ ) (38) 8 F or review SIAM UQ then | e β k i − β k i | < min ( 1 , ε 8 | β k j | τ − 1 τ , ε 8 | µ j | τ − 1 τ ) . (39) Similarly if | x k t,j − x k a,j | < 1 L + 1 min 1 , ε 8 | β k i | τ − 1 τ , ε 8 | µ i | τ − 1 τ (40) then | e β k j − β k j | < min 1 , ε 8 | β k i | τ − 1 τ , ε 8 | µ i | τ − 1 τ . (41) By Corollary 3 if | x k t,i − x k a,i | < 1 L + 1 min ( 1 , ε 8 | β k j | τ − 1 τ , ε 8 | µ j | τ − 1 τ ) ∀ k . (42) then | e µ i − µ i | < min ( 1 , ε 8 | β k j | τ − 1 τ , ε 8 | µ j | τ − 1 τ ) (43) and if | x k t,j − x k a,j | < 1 L + 1 min 1 , ε 8 | β k i | + 8 τ − 1 τ , ε 8 | µ i | + 8 τ − 1 τ (44) then | e µ j − µ j | < min 1 , ε 8 | β k i | + 8 τ − 1 τ , ε 8 | µ i | + 8 τ − 1 τ . (45) Hence we can use Lemma 5. Thus | Q ij − e Q ij | < ε . Corollary 3 sho ws that if one desires to know the mean of the mo del error to an accuracy of ε , then the analysis of that v ariable m ust b e within ε L +1 of the truth at ev ery timestep. Contrast this with the result from Theorem 6: to estimate the v ariance of a v ariable to within ε , the analysis of that v ariable must b e within 1 L + 1 min 1 , ε 8 | β k i | + 8 τ − 1 τ , ε 8 | µ i | + 8 τ − 1 τ (46) of the truth at each timestep. With the factor of 8 in the denominator, this can b e seen as approximately an order of magnitude more accuracy needed in the analysis to ac hieve the same accuracy in the approximation. Moreov er, the accuracy in the v ariance depends on the mean v alue of that v ariable. The larger the mean v alue, the more accuracy required in the analysis to give the same error in the v ariance. This may b e more easily understo o d con versely: the larger the mean v alue in a v ariable, the larger the error in the estimation of its v ariance. 9 F or review SIAM UQ 3 Numerical exp erimen ts In this section we apply the mo del error moment estimation metho d as detailed in the previous sections to the Lorenz 96 system [Lorenz, 1996]. This is a very simple example to show numerically that the errors in the approximations of µ and Q are dep enden t on the quality of the analysis x a . The Lorenz 96 system is given by the follo wing ODE: d x i d t = − x i − 2 x i − 1 + x i − 1 x i +1 − x i + 8 , (47) where i ∈ 1 , . . . , N with cyclic b oundary conditions. W e choose N = 40. W e prescribe the truth to ev olve as (2) with β ∼ N ( µ, Q ) where µ ( x i ) = 1 5 sin( π i N ) , (48) and Q = 1 10 2 3 2 C where C ij = 1 if i = j 2 3 if | i − j | = 1 1 6 if | i − j | = 2 0 otherwise . (49) µ and Q ha ve been chosen to be inter esting and Q in particular, for implementation purposes, has a rather simple symmetric square ro ot. W e tak e observ ations of the true state at every timestep. The observ ations are related to the state via the equation y k = H ( x k t ) + η k where η ∼ N (0 , R ) . (50) Here we consider H = I and will show t wo different exp erimen ts with observ ations of v arying accuracy . The first exp erimen t will ha ve R = 10 − 8 I , and represents very informative observ ations. The second exp erimen t will ha ve R = 10 − 3 I , and represen ts observ ations con taining less information. T o get an analysis x a , we p erform a simple 3DV ar at each timestep. That is, x k a = arg min x 1 2 ( x − f ( x k − 1 a )) T B − 1 ( x − f ( x k − 1 a )) + 1 2 ( y k − H ( x )) T R − 1 ( y k − H ( x )) . (51) W e use B = 10 12 I as a particularly uninformative prior. The mo del is evolv ed for 3000 timesteps, giving us 2999 samples of e β k . Figure 1 shows Ho vm¨ oller diagrams of the analysis error as a result of the data assimilation pro cess. The higher precision observ ations lead to significantly low er estimation errors. Using these analyses, estimates for e µ and e Q are calculated. Results for R = 10 − 8 are shown in Figures 2 to 4 and for R = 10 − 3 are sho wn in Figures 5 to 7. These results sho w that the second order moment of mo del error, Q , is m uch 10 F or revie w S IAM U Q more sensitive to the quality of the analysis than the first order moment, µ . This is consistent with the theory set out in the previous section. (a) R = 10 − 8 ↓ (b) R = 10 − 3 ↓ Figure 1: Ho vm¨ oller plots of | x t − x a | for the t wo differen t precision observ ations. Observe that the 3D V ar algorithm can reduce the error in the state by 2 − 3 orders of magnitude when the observ ations are more precise. 4 Conclusions This pap er has considered using the problem of estimating the moments of mo del error of a dynamic mo del. The mo del error is appro ximated b y the difference of the analysis and the model forecast of the analysis at the previous timestep. Bounds for the errors in b oth the first and second momen t of the approximated model error compared to the sample mo del error are deriv ed, in terms of the error in the analysis from the truth. It is sho wn that to ac hieve the same error estimation in the second momen t compared with the first, the analysis must b e an order of magnitude closer to the truth. 11 F or review SIAM UQ 0 10 20 30 40 0 0 . 05 0 . 1 0 . 15 0 . 2 gridp oin t µ Estimated Sampled T rue µ (a) Estimated, sampled, and true mean of mo del error 0 10 20 30 40 0 . 000 0 . 001 0 . 002 0 . 003 0 . 004 gridp oin t Error | µ − ˜ µ | | µ − µ | | µ − ˜ µ | (b) Errors in the mean Figure 2: The first moment of mo del error for R = 10 − 8 Numerical exp erimen ts were conducted to elucidate how the quality of the analysis affects the estimation of b oth the mean and the cov ariance of the mo del error. It is shown numerically with the Lorenz 96 system that the estimation of the cov ariance of the mo del error is muc h more sensitiv e to the quality of the data assimilation than the estimation of the mean of the mo del error. 12 F o r rev iew SIAM U Q (a) T rue Q matrix 0 5 10 15 20 25 30 35 0 5 10 15 20 25 30 35 0.000 0.002 0.004 0.006 0.008 0.010 0.012 0.014 0.016 (b) Sampled Q matrix 0 5 10 15 20 25 30 35 0 5 10 15 20 25 30 35 0.000 0.002 0.004 0.006 0.008 0.010 0.012 0.014 0.016 (c) Estimated e Q matrix 0 5 10 15 20 25 30 35 0 5 10 15 20 25 30 35 0.000 0.002 0.004 0.006 0.008 0.010 0.012 0.014 0.016 Figure 3: T rue, sampled, and estimated cov ariance of the mo del error R = 10 − 8 (a) | Q − Q | sho wing the sampling error 0 5 10 15 20 25 30 35 0 5 10 15 20 25 30 35 0.0000 0.0001 0.0002 0.0003 0.0004 0.0005 0.0006 0.0007 0.0008 0.0009 (b) | Q − e Q | sho wing the error in the estimate and the samples which o ccurred 0 5 10 15 20 25 30 35 0 5 10 15 20 25 30 35 0.0000 0.0003 0.0006 0.0009 0.0012 0.0015 0.0018 0.0021 0.0024 0.0027 (c) | Q − e Q | sho wing the error in the estimation and the underlying true co v ariance 0 5 10 15 20 25 30 35 0 5 10 15 20 25 30 35 0.0000 0.0003 0.0006 0.0009 0.0012 0.0015 0.0018 0.0021 0.0024 Figure 4: Errors in the mo del error co v ariance matrix R = 10 − 8 13 F o r rev iew SIAM UQ 0 10 20 30 40 0 0 . 05 0 . 1 0 . 15 0 . 2 gridp oin t µ Estimated Sampled T rue µ (a) Estimated, sampled, and true mean of mo del error 0 10 20 30 40 0 . 000 0 . 001 0 . 002 0 . 003 0 . 004 gridp oin t Error | µ − ˜ µ | | µ − µ | | µ − ˜ µ | (b) Errors in the mean Figure 5: The first moment of mo del error for R = 10 − 3 (a) T rue Q matrix 0 5 10 15 20 25 30 35 0 5 10 15 20 25 30 35 0.0000 0.0025 0.0050 0.0075 0.0100 0.0125 0.0150 0.0175 (b) Sampled Q matrix 0 5 10 15 20 25 30 35 0 5 10 15 20 25 30 35 0.0000 0.0025 0.0050 0.0075 0.0100 0.0125 0.0150 0.0175 (c) Estimated e Q matrix 0 5 10 15 20 25 30 35 0 5 10 15 20 25 30 35 0.0000 0.0025 0.0050 0.0075 0.0100 0.0125 0.0150 0.0175 Figure 6: T rue, sampled, and estimated cov ariance of the mo del error R = 10 − 3 14 F or revie w S I AM UQ (a) | Q − Q | sho wing the sampling error 0 5 10 15 20 25 30 35 0 5 10 15 20 25 30 35 0.0000 0.0001 0.0002 0.0003 0.0004 0.0005 0.0006 0.0007 0.0008 0.0009 (b) | Q − e Q | sho wing the error in the estimate and the samples which o ccurred 0 5 10 15 20 25 30 35 0 5 10 15 20 25 30 35 0.0000 0.0005 0.0010 0.0015 0.0020 0.0025 0.0030 0.0035 0.0040 0.0045 (c) | Q − e Q | sho wing the error in the estimation and the underlying true co v ariance 0 5 10 15 20 25 30 35 0 5 10 15 20 25 30 35 0.0000 0.0005 0.0010 0.0015 0.0020 0.0025 0.0030 0.0035 0.0040 0.0045 Figure 7: Errors in the mo del error co v ariance matrix R = 10 − 3 15 F or review SIAM UQ References Bo x, G. E. and Drap er, N. R. (1987). Empiric al mo del-building and r esp onse surfac es. John Wiley & Sons. Bro wne, P . and v an Leeuw en, P . (2015). Twin exp erimen ts with the equiv alent weigh ts particle filter and HadCM3. Quarterly Journal of the R oyal Mete or olo gic al So ciety , 141(693 Octob er 2015 Part B):3399–3414. Dee, D. P . and Uppala, S. (2009). V ariational bias correction of satellite radiance data in the ERA-Interim reanalysis. Quarterly Journal of the R oyal Mete or olo gic al So ciety , 135(Octob er):1830–1841. Ev ensen, G. (2007). Data assimilation . Springer. Jazwinski, A. H. (1970). Sto chastic Pr o c esses and Filtering The ory . Academic Press. Lang, M., v an Leeu wen, P . J., and Bro wne, P . (2016). A systematic method of parameterisation estimation using data assimilation. T el lus A , 68:1–10. La w, K., Stuart, A., and Zygalakis, K. (2015). Data Assimilation: A Mathematic al Intr o duction . T exts in Applied Mathematics. Springer In ternational Publishing. Lorenz, E. (1996). Predictabilit y: A problem partly solved. Pr o c. Seminar on pr e dictability , 1(1):40–58. Owhadi, H., Scov el, C., Sulliv an, T. J., McKerns, M., and Ortiz, M. (2013). Optimal Uncertaint y Quantification. SIAM R eview , 55(2):271–345. T eck entrup, A. L., Sc heichl, R., Giles, M. B., and Ullmann, E. (2013). F urther analysis of multilev el Monte Carlo metho ds for elliptic PDEs with random co efficien ts. Numerische Mathematik , pages 24–29. T o dling, R. (2015). A lag-1 smo other approach to system-error estimation: sequen tial metho d. Quarterly Journal of the R oyal Mete or olo gic al So ciety , 141(690):1502–1513. T r´ emolet, Y. (2006). Accoun ting for an imp erfect mo del in 4D-V ar. Quarterly Journal of the R oyal Mete or olo gic al So ciety , 132(621):2483–2504. T r´ emolet, Y. (2007). Mo del-error estimation in 4D-V ar. Quarterly Journal of the R oyal Mete or olo gic al So ciety , 1280(July):1267–1280. v an Leeuw en, P . (2010). Nonlinear data assimilation in geosciences: an extremely efficien t particle filter. Quarterly Journal of the R oyal Mete or olo gic al So ciety , 136(653):1991–1999. 16
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment