Reinforcement Learning for Angle-Only Intercept Guidance of Maneuvering Targets
We present a novel guidance law that uses observations consisting solely of seeker line of sight angle measurements and their rate of change. The policy is optimized using reinforcement meta-learning and demonstrated in a simulated terminal phase of …
Authors: Brian Gaudet, Roberto Furfaro, Richard Linares
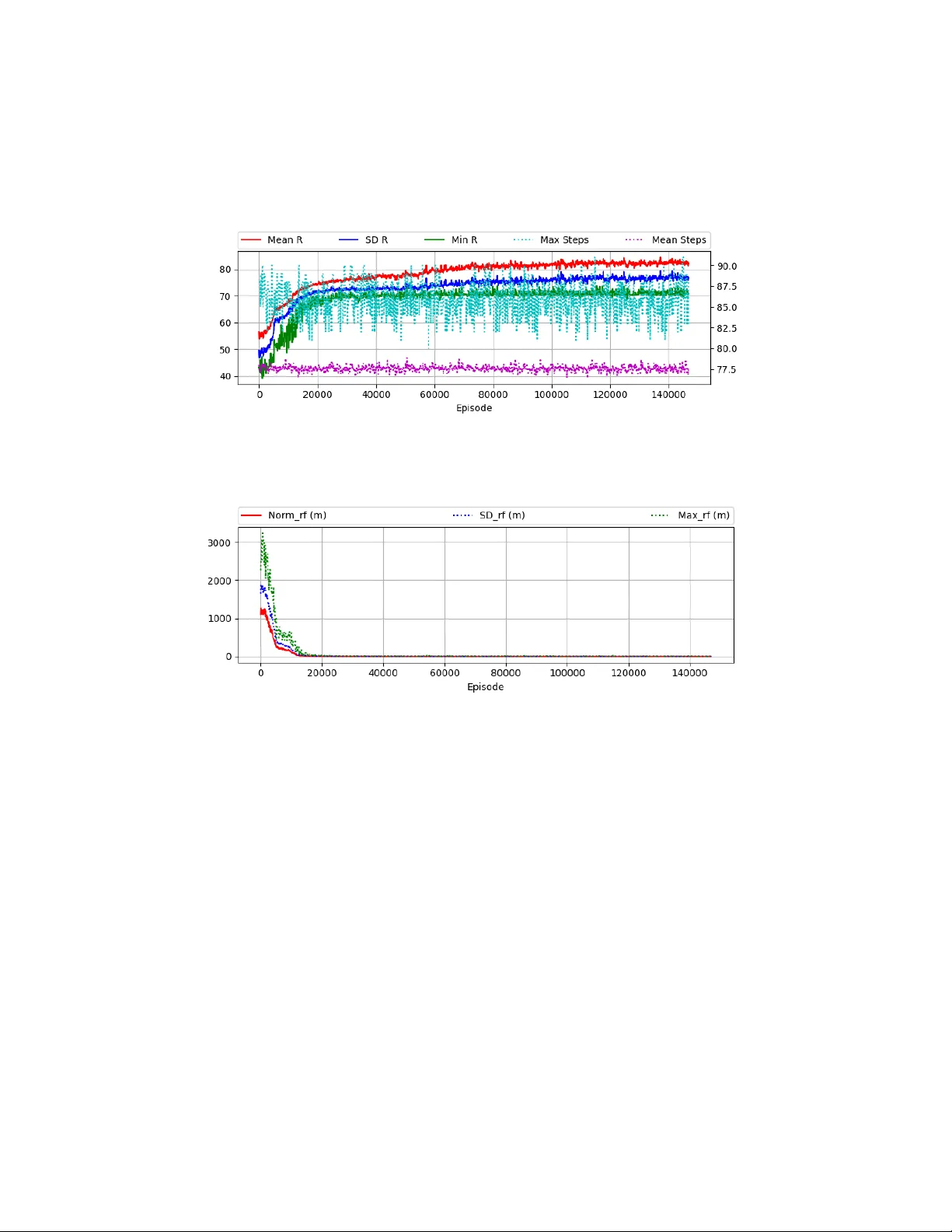
R einf or cement Learning f or Angle-Onl y Intercep t Guidance of Maneuv ering T arg ets Brian Gaudet ∗ and R ober to F urfaro † U niv ersity of Arizona, 1127 E. Rog er W ay, T ucson Arizona, 85721 Richard Linares ‡ Massac husetts Institut e of T ec hnology, Cambridg e, MA 02139 W e present a no v el guidance law that uses observations consisting solely of seek er line of sight angle measurements and their rate of change. The policy is optimized using reinf orcement meta- learning and demonstrated in a simulated terminal phase of a mid-course ex o-atmospheric interception. Importantly , the guidance la w does not require range estimation, making it particularl y suitable for passive seek ers. The optimized policy maps stabilized seeker line of sight angles and their rate of chang e directl y to commanded thrust for the missile ’s divert thrusters. The use of reinfor cement meta-learning allow s the optimized policy to adapt to t arge t acceleration, and w e demonstrate that the policy performs as well as augmented zero-effort miss guidance with perfect target acceleration kno wledge. The optimized policy is computationall y efficient and requir es minimal memory , and should be compatible with today’ s flight processors. I. Intr oduction E x o-a tmospheric interception of ballistic targ ets is par ticularl y challenging due to the hit to kill requirement and relativ ely small size of a ballistic re-entr y vehicle (BR V), typically 45 to 60 centimeters in diameter . Successful interception requires both a small miss distance and a suitable impact angle, with miss distance requirements of 50 cm implied by the BR V and missile dimensions. Moreov er , the missile must autonomousl y discriminate between threats and deco ys. The interception problem is significantly complicated b y warheads with limited maneuvering capability . Both spiral and bang-bang maneuv ers could potentially be e xecuted b y a BR V without compromising the BR V’ s accuracy . These maneuvers could be ex ecuted either in response to the BR V’ s sensor input (if so eq uipped) or periodically e xecuted during the por tion of the trajectory where interception is likel y . Another complication of ex o-atmospheric interception is that the high altitude requires the use of divert thr usters rather than control surfaces, with current implementation using pulsed divert thr usters. As the missile bur ns fuel, its center of mass shifts, and the div er t thr usts cause a tumbling motion that requires compensation from the attitude control thrusters. Fuel efficiency is also critical, as the missile loses all control author ity when its fuel is depleted. Recent w ork in e x o-atmospher ic guidance law de velopment include [ 1 ], where a collision geometry based guidance la w is dev eloped that attempts to keep the missile on a collision tr iangle with the target using range and angle measurements. The authors demonstrate impro v ed capture range and miss distance f or the case of a non-maneuvering targ et as compared to a zero effor t miss guidance law . In [ 2 ], the authors dev elop a guidance la w suitable for e xo-atmospheric intercepts using linear quadratic optimization; impor tantl y the guidance la w requires an estimate of the relativ e range and v elocity v ectors and assumes a non-maneuvering targ et. In [ 3 ], Zarchan dev elops a pulsed guidance la w that remov es the zero effort miss dur ing the homing phase by precomputing the required number of pulses and setting each pulse width based off of the cur rent time to go, closing v elocity , and line-of-sight rate of chang e. The guidance law s described abo v e require, at a minimum, the measurement of range (which allo ws the estimation of closing velocity), with some requiring estimation of the relative positions and v elocities. A ctiv e sensors such as radar can pro vide both range and closing v elocity measurements, and by including angle measurements, a Kalman filter [ 4 ] can estimate relativ e positions, velocities, and targ et acceleration. On the other hand, passive electro-optical IR seekers such as those used in the N avy’ s SM-3 e x o-atmospher ic missile [ 5 ] do not provide rang e measurements. Note that it is possible to estimate range at loc k -on using the target ’ s radiant intensity and an estimate of the attenuation of the signal with distance [ 6 ], after which the chang e in rang e could potentially be estimated from integrated IMU measurements. ∗ Co-Founder , DeepAnalytX LLC, Affiliated Engineer, Depar tment of Aerospace and Mechanical Engineer ing † Prof essor , Depar tment of Systems and Industrial Engineer ing, Department of Aerospace and Mechanical Engineering ‡ Charles Stark Draper Assistant Professor , Depar tment of Aeronautics and Astronautics, Senior Member AIAA, E-mail:linaresr@mit.edu 1 Ho w ev er , it seems likel y that using measured radiant intensity could be easily f ooled by countermeasures. Finall y , w e note that the well-kno wn proportional na vigation guidance la w can be implemented without range inf or mation [ 7 ] a M = N ω v M , where ω is the rate of change of the line-of-sight v ector, a M the commanded missile acceleration, and v M an estimate of the missile’ s velocity v ector . Ho we ver , an accurate estimation of v M is probably a more difficult problem than the estimation of range and rang e rate from angle-only measurements. The w ork relating to a missile guidance law using angle-only measurements is relativ ely scarce. In [ 8 ] the authors dev elop an extended Kalman filter that can estimate range from angle measurements. Ho we ver , the e xperimental results are f or endo-atmospher ic intercepts, and in some sce narios it tak es sev eral seconds for the filter to conv erge, while in other eng agement scenar ios the filter does not con verg e to an accurate estimate. The authors also f ound that it was not possible to reliably estimate acceleration, which is required for adv anced guidance law s such as augmented proportional navig ation. Interestingl y , the authors enhance obser v ability by creating a guidance law that is a function of both the seeker angles and their rate of chang e. In this work w e also use both seeker angles and their rate of chang e, but do not attempt to estimate rang e and closing v elocity . In [ 9 ] an augmented propor tional na vigation guidance la w is modified to induce rotations in the line-of-sight angles dur ing the engag ement, allo wing a modified gain e xtended Kalman filter to estimate the full planar engag ement state from angle-only measurements. In the simulation results presented, the rotations do not impact per f ormance, but that ma y not be the case in general. The method of inducing line-of-sight rotations was used more recently in [ 10 ] to estimate the engag ement state from angle-only measurements. Impor tantl y , the results w ere compared to the Proportional Na vigation (PN) guidance law that was not augmented with a targ et acceleration estimate. In contrast, we compare our guidance la w’s per f or mance to augmented PN with per f ect kno w ledge of the engagement s tate. Finall y , in [ 11 ], the authors dev elop a guidance law using sliding mode theor y that is effectiv e against a stationary targ et and implements impact angle and field of vie w constraints. Reg ardless of seeker type, a sy stem that can map seeker angle measurements directly to actuator commands has sev eral potential adv antages. Firs t, the state estimation problem is simplified, as only the seek er angles need to be estimated. With a f ast enough sensor measurement frequency , this could potentially be accomplished b y simply a v eraging the angle measurements between guidance sy stem updates. Second, there is less potential for problems arising from different estimation biases f or relativ e position, v elocity , and tar get acceleration. Third, with less processing requirements, the guidance frequency can be increased. Finally , using only angle measurements may be less susceptible to counter measures such as range gate pull-off [ 12 ], where the target g enerates a radar signal that f orces the radar’ s tracking g ates to be pulled aw ay from the targ et echo. It seems intuitive that a guidance sys tem that does not use range measurements w ould be immune to such countermeasures. Although there are many deplo yed missiles with guidance sy stems compatible with passiv e seekers, to the best of our kno wledg e, there is cur rently no method to appl y the optimal control framew ork to optimizing such a guidance la w using angle-only measurements, or a robus t, fast-con ver ging method to estimate the full engag ement state solel y from angle measurements without inducing line-of-sight rotation during the eng agement. It is possible that the ability to introduce an e xplicit cost function (re wards in the RL framew ork) and constraints can boost per f or mance bey ond what is possible toda y with passiv e seekers. The pur pose of this paper to take the first step tow ards that goal. In this work w e optimize a guidance law using reinf orcement lear ning (RL) ∗ . The optimized policy maps estimates of the tw o seeker angles and their rate of chang e directly to div er t thr ust commands, and respects seeker field of vie w and maximum thr ust constraints. The policy is lear ned b y having an agent instantiating the policy interact episodically with an environment. Each episode consists of an engag ement scenar io with randomized parameters. Here w e consider a maneuv erable ballistic re-entr y v ehicle high-altitude interception scenar io, where the intercepting missile must destro y the targ et kinetically via a direct hit (miss less than 50 cm). The engagement scenario is considerably simplified from a realistic eng agement. First, w e only simulate the interception ’ s ter minal phase. Second, w e do not generate realistic ballistic trajectories for the missile or target, and neglect the f orce of gravity . Note that it is a common practice to neglect gravity when initiall y dev eloping a new guidance la w [ 1 , 3 , 9 , 8 ]. Third, we do not address targ et discrimination or attitude control. The engag ement scenar io is then a simple head on engag ement with the targ et having the sp eed adv antage, with initial missile and target speeds of 3000 m/s and 4000 m/s respectiv ely . The target ex ecutes a randomized bang-bang maneuv er dur ing the intercept. This is a realistic maneuv er f or a re-entry v ehicle to ex ecute in order to ev ade interception, as it does not dramatically modify the re-entry vehicles tra jectory . W e use a 2:1 ratio of missile to target thrust capability . The details of this engag ement scenar io are provided in Section II.B. The optimized policy is then then tested, and performance is compared to an augmented zero-effor t-miss (ZEM) policy [ 13 ] using the full ground-tr uth engag ement state (relativ e position and velocity , and targ et acceleration). Since ∗ See Section III.A for an ov er view of RL 2 the engag ement parameters are randomized f or each episode, the test engag ements are nov el in that the engag ement parameters w ere not e xper ienced b y the agent dur ing optimization. W e find that the RL policy has slightl y better accuracy , but at the expense of slightly increased a verag e fuel consumption. W e attr ibute the RL policy’ s per f or mance to the use of a recur rent neural network la yer in the policy and value function, which allo ws the policy to adapt to a particular targ et maneuver in real time. Specificall y , the recur rent la y er’ s hidden state e v ol ves differently in response to targ et maneuvers in a particular engag ement, allo wing the mapped actions to take into account the maneuv er . As opposed to augmented ZEM, where the state estimation filter must estimate an acceleration, the RL policy instead adapts to the targ et maneuver in real time. In pre vious work regarding an adaptive policy f or asteroid close pro ximity maneuv ers that could adapt to unknown en vironments and actuator failures [ 14 ], w e also found that using a recur rent la y er in the policy and value function boosted per f or mance. Mapping observations to actions requires only f our small matrix multiplications, which tak es less than 1 ms on a 2.3 Ghz CPU and requires around 64KB of memor y . In this w ork we use a 100 ms guidance cy cle, and we e xpect that the policy would easily run on moder n flight computers. II. Pr oblem F ormulation A. Missile Configuration The missile is modeled as a cylinder of height 1 m and radius 0.25 m about the missile’ s body frame x-axis with a w et and dr y mass of 50 kg and 25 kg, respectiv ely . Four divert thrusters thrusters are positioned as sho wn in T able 1. W e assume that attitude control thr usters keep the missile ’ s attitude constant during the engag ement, but do not address an implementation of an attitude control policy in this work. The div er t thrusters can be switched on or off at the guidance frequency of 10 Hz. T able 1 Body Frame Thruster Locations. Div ert Thrust Direction V ector Location Thruster x y z x (m) y (m) z (m) 1 0.00 -1.00 0.00 0.00 -0.25 0.00 2 0.00 1.00 0.00 0.00 0.25 0.00 3 0.00 0.00 1.00 0.00 0.00 0.25 4 0.00 0.00 -1.00 0.00 0.00 -0.25 W e assume that the seeker is per fectl y stabilized and has per f ect tracking capability , with a 135 deg ree field of vie w . At the start of the homing phase, the seeker ’s attitude is set to the missile body frame attitude, where it remains fixed (stabilized) dur ing the homing phase. T o be clear, in the absence of any chang e in the missile ’ s attitude during the homing phase, this implies that the seeker and body ref erence frames remain aligned, i.e., the y both hav e the same attitude with respect to the iner tial frame. How ev er if the missile’ s attitude chang es dur ing the engag ement, the seeker ’s attitude remains at the missile body frame attitude measured at the star t of the engag ement. This stabilization insures that missile attitude changes are not interpreted as targ et maneuv ers dur ing the engag ement. As the seeker ’ s sensor tracks the tar get from this stabilized ref erence frame, we can define the angles between the seeker boresight axis and the seeker ref erence frame y and z ax es as the seeker angles θ u and θ v . Further , define C SN ( q 0 ) as the direction cosine matrix (DCM) mapping from the inter tial frame to the stabilized seeker platform ref erence frame, with q 0 being the missile’ s attitude at the start of the homing phase. W e can now transf or m the target ’ s relativ e position in the iner tial reference frame r N TM into the seeker ref erence frame as shown in Eq. (1). r S TM = [ C SN ( q 0 )] r N TM (1) Defining the line-of-sight unit v ector in the seeker ref erence frame as ˆ λ S = r S TM k r TM k S and the seeker frame unit v ectors ˆ u = h 0 1 0 i , ˆ v = h 0 0 1 i w e can then compute the seeker angles as the or thogonal projection of the 3 seeker frame LOS v ector onto ˆ u and ˆ v as shown in Eqs. (2a) and (2b). θ u = arcsin ( ˆ λ S · ˆ u ) (2a) θ v = arcsin ( ˆ λ S · ˆ v ) (2b) The guidance policy descr ibed in the follo wing will map these seeker angles θ u and θ v and their rate of change to div ert thrust commands. B. Engag ement Scenario In this work w e use a simplified engag ement scenario. Instead of modeling the missile and targ et trajectories using Lambert guidance to deter mine the homing phase initial conditions, the engagement is modeled as a simple head-on engag ement. Ref er r ing to Fig. 1 † , where the missile v elocity vector , targ et velocity v ector , and relativ e range v ector are giv en as v M , v T , and r TM , we can define the targ et’ s initial position r T in a missile centered ref erence frame in ter ms of the range v ector from missile to targ et k r TM k and angles θ and φ as giv en in Equations (3a), (3b), and (3c). r T x = k r TM k sin ( θ ) cos ( φ ) (3a) r T y = k r TM k sin ( θ ) sin ( φ ) (3b) r T z = k r TM k cos ( θ ) (3c) Further, w e can represent the targ et’ s initial velocity v ector v T in ter ms of the magnitude of the targ et v elocity k v T k and angles α and β as sho wn in Equations (4a), (4b), and (4c). v T x = k v T k sin ( β ) cos ( α ) (4a) v T y = k v T k sin ( β ) sin ( α ) (4b) v T z = k v T k cos ( β ) (4c) Fig. 1 Engag ement A collision tr iangle can be defined in a plane that is not in general aligned with the coordinate frame shown in Fig. 1, and is illustrated in Fig. 2. Here we define the required lead angle L f or the missile’ s v elocity v ector v m as the angle that will put the missile on a collision tr iangle with the targ et in terms of the targ et velocity v T , line-of-sight angle γ , and the magnitude of the missile v elocity as shown in Eqs. (5a) through (5c). L = arcsin k v T k sin ( β + γ ) k v M k (5a) v m y = k v M k cos ( L + γ ) (5b) v m z = k v M k sin ( L + γ ) (5c) (5d) † In this figure, the illustrated vectors are not in general within the y-z plane 4 Fig. 2 Planar Heading Error This f or mulation is easil y e xtended to a three dimensional engagement by defining a plane nor mal as ˆ v t × ˆ λ , rotating v t and ˆ λ onto the plane, calculating the required planar missile velocity , and then rotating this back into the original ref erence frame. Thus in R 3 w e define a heading er ror (HE) as the the angle between the missile ’ s initial velocity v ector and the velocity v ector associated with the lead angle required to put the missile on a collision heading with the targ et. W e also define the initial attitude er ror as the angle between the missile ’s v elocity vector and the body frame x-axis at the start of the engag ement. W e consider a bang-bang target maneuv er , where the acceleration is applied or thogonal to the target ’ s velocity v ector . The maneuver has varying acceleration lev els up to a maximum of 5 ∗ 9 . 81 m / s 2 , and with random star t time, duration, and switching time. A sample target maneuv er is sho wn Fig. 3, note that in some cases the maneuv er duration is considerably long er, with a complete cy cle extending bey ond the time of intercept. Fig. 3 Sample T arg et Maneuv er W e can no w list the range of eng agement scenario parameters in T able 2. During optimization and testing, these parameters are drawn uniforml y between their minimum and maximum v alues. The generation of heading error is handled as f ollo ws. W e first calculate the optimal missile v elocity v ector that puts the missile on a collision tr iangle with the targ et as descr ibed previousl y . T reating this v elocity v ector as the axis of a cone, the heading er ror defined in R 3 is then θ HE = atan r h , where r and h are the cone’ s radius and height. Similarl y , w e define an ideal initial attitude as having the missile’ s x-axis aligned with its velocity v ector, and use a similar method to per turb this by the attitude er ror such that angle between the missile ’s ideal and actual v elocity v ector is equal the the attitude er ror . 5 T able 2 Initial Conditions Parameter min max Range k r TM k (km) 50 55 Missile V elocity Magnitude (m/s) 3000 3000 T ar get P osition angle θ (degrees) -10 10 T ar get P osition angle φ (deg rees) -10 10 T ar get V elocity Magnitude (m/s) 4000 4000 T ar get V elocity angle β (degrees) -10 10 T ar get V elocity angle α (degrees) -10 10 Heading Er ror (degrees) 0 5 Attitude Error (deg rees) 0 5 T ar get A cceleration m / s 2 -5*9.81 5*9.81 C. Equations of Motion The f orce F B and torque L B in the missile’ s body frame for a giv en commanded thr ust depends on the placement of the thrusters in the missile structure. W e can descr ibe the placement of each thr uster through a body-frame direction v ector d and position v ector r , both in R 3 . The direction v ector is a unit vector giving the direction of the body frame f orce that results when the thr uster is fired. The position v ector giv es the body frame location with respect to the missile centroid, where the force resulting from the thr uster firing is applied f or pur poses of computing torque, and in general the center of mass ( r com ) varies with time as fuel is consumed. For a missile with k thrusters, the body frame force and torque associated with one or more thrusters fir ing is then as sho wn in Eqs. (6a) and (6b) , where T c m d i ∈ [ T mi n , T m a x ] is the commanded thr ust f or thr uster i , T mi n and T m a x are a thr uster ’ s minimum and maximum thrust, d ( i ) the direction v ector f or thr uster i , and r ( i ) the position of thr uster i . The total body frame f orce and torque are calculated by summing the individual f orces and torques. F B = k Õ i = 1 d ( i ) T ( i ) c m d (6a) L B = k Õ i = 1 ( r ( i ) − r com ) × F ( i ) B (6b) The dynamics model uses the missile ’ s cur rent attitude q to conv er t the body frame thr ust v ector to the iner tial frame as sho wn in in Eq. (7) where [ BN ]( q ) is the direction cosine matr ix mapping the iner tial frame to body frame obtained from the cur rent attitude parameter q . F N = [[ BN ] ( q ) ] T F B (7) The missile’ s translational motion is modeled as sho wn in 8a through 8c. Since w e are not accurately modeling the initial conditions as a ballistic intercept (i.e., using Lamber t guidance), we do not model the g ra vitational acceleration. Û r = v (8a) Û v = F N m (8b) Û m = − Í k i k F B ( i ) k I sp g ref (8c) Here F N ( i ) is the iner tial frame f orce as given in Eq. (7) , k is the number of thr usters, g ref = 9 . 8 m / s 2 , r is the missile’ s position in the engag ement reference frame 6 The targ et is modeled as shown in Eqs. (9a) and (9b) , where a T com is the commanded acceleration for the target maneuv er . Û r = v (9a) Û v = a T com (9b) The equations of motion are updated using fourth order R unge-K utta integration. For ranges greater than 1000 m, a timestep of 20 ms is used, and f or the final 1000 m of homing, a timestep of 0.067 ms is used in order to more accuratel y measure miss distance; this technique is bor ro wed from [ 15 ]. For the ZEM guidance law , this results in a 100% hit rate (miss < 50 cm) with no targ et maneuv er and zero heading er ror at a guidance frequency of 10 Hz. W e also check ed that decreasing the integration step size to 10 ms did not impro v e per f or mance f or the augmented ZEM guidance law . III. Guidance La w De v elopment A. Reinf orcement Learning Overvie w In the RL framew ork, an agent lear ns through episodic interaction with an en vironment ho w to successfully complete a task b y learning a policy that maps obser vations to actions. The environment initializes an episode b y randoml y generating a g round truth state, mapping this state to an observation, and passing the observation to the agent. These observations could be an estimate of the ground tr uth state from a Kalman filter or could be raw sensor outputs such as seeker angle measurements and radar range and closing v elocity measurements, or a multi-channel pixel map from an electro-optical sensor . The agent uses this observation to g enerate an action that is sent to the environment; the en vironment then uses the action and the cur rent ground tr uth state to generate the ne xt state and a scalar rew ard signal. The rew ard and the observation cor responding to the ne xt state are then passed to the agent. The process repeats until the en vironment ter minates the episode, with the ter mination signaled to the agent via a done signal. Possible termination conditions include the agent completing the task, satisfying some condition on the ground tr uth state (such negativ e closing speed), or violating a constraint. T ypically , tra jector ies from some fixed number of episodes (referred to as rollouts) are collected dur ing interaction between the ag ent and environment, and used to update the policy and value functions. The inter f ace between ag ent and environment is depicted in Fig. 4. Fig. 4 Engag ement A Marko v Decision Process (MDP) is an abstraction of the environment, which in a continuous state and action space, can be represented by a s tate space S , an action space A , a state transition distribution P ( x t + 1 | x t , u t ) , and a re ward function r = R ( x t , u t )) , where x ∈ S and u ∈ A , and r is a scalar rew ard signal. W e can also define a par tiall y 7 observable MDP (POMDP), where the state x becomes a hidden state, generating an observation o using an obser vation function O ( x ) that maps states to observations. The POMDP f or mulation is useful when the observation consists of ra w sensor outputs, as is the case in this work. In the follo wing, we will refer to both fully observable and par tially observable environments as POMDPs, as an MDP can be considered a POMDP with an identity function mapping states to observations. The ag ent operates within an environment defined by the POMDP , g enerating some action u t based off of the observation o t , and receiving re ward r t + 1 and next obser vation o t + 1 . Optimization in v olv es maximizing the sum of (potentially discounted) re wards o ver the tra jectories induced by the interaction betw een the agent and environment. Constraints such as minimum and maximum thr ust, attitude compatible with sensor field of vie w , maximum angle of attack, and maximum rotational v elocity , can be included in the rew ard function, and will be accounted f or when the policy is optimized. Note that there is no guarantee on the optimality of trajectories induced b y the policy , although in practice it is possible to get close to optimal performance by tuning the re ward function. Reinf orcement meta-learning differs from generic reinf orcement learning in that the agent learns to quickl y adapt to no v el POMPDs by learning ov er a wide range of POMDPs. These POMDPs can include different environmental dynamics, actuator failure scenarios, mass and iner tia tensor v ar iation, and varying amounts of sensor distortion. Learning within the RL meta-lear ning frame w ork results in an agent that can quic kly adapt to no v el POMDPs, often with just a f ew steps of interaction with the en vironment. There are multiple approaches to implementing meta-RL. In [ 16 ], the authors design the objectiv e function to e xplicitly make the model parameters transf er well to new tasks. In [ 17 ], the authors demonstrate state of the art performance using temporal conv olutions with soft attention. And in [ 18 ], the authors use a hierarch y of policies to achiev e meta-RL. In this proposal, w e use a different approach [ 19 ] using a recur rent policy and value function. N ote that it is possible to train o ver a wide rang e of POMDPs using a non-meta RL algor ithm. Although such an approach typically results in a robust policy , the policy cannot adapt in real time to no v el environments. T o better understand the differences betw een RL and cur rent practice using optimal control, a compar ison of RL and optimal control approaches to guidance and control are given in T able 3. The point of the comparison is not to make the case that one approach should be preferred o v er the other , but rather to sugg est the scenarios where it might make sense to use the RL framew ork to solv e guidance and control problems. T able 3 A Comparison of Optimal Control and RL [20] Optimal Control Reinf orcement Learning Single trajectory (ex cept for tr ivial cases where HJB equations can be solv ed) Global o v er theatre of operations U nbounded r un time e x cept f or special cases such as con v e x constraints Extremely fast run time f or trained pol- icy ( < 1ms in this work) Dynamics need to be represented as ODE, possibly constraining fidelity of model used in optimization No cons traints on dynamics representa- tion. Agent can learn in a high fidelity simulator (i.e., Na vier-S tokes modeling of aerodynamics) Open Loop (requires a controller to track the optimal trajectory) Closed Loop (Integrated guidance and control) Output f eedback (co-optimization of state estimation and guidance law) an open problem f or non-linear systems Can learn from ra w sensor outputs al- lo wing fully integ rated GNC (pix els to actuator commands). Can lear n to com- pensate f or sensor distortion. Req uires full state f eedback Does not require full state f eedback Elegantl y handles state constraints State constraints handled either via lar ge negativ e re wards and episode termina- tion or more recently , modification of policy gradient algor ithm. Control con- straints straightf orward to implement Deterministic Optimization Stoc hastic Optimization, learning does not conv erg e e very time, ma y need to run multiple policy optimizations In this work, w e implement meta-RL using pro ximal policy optimization (PPO) [ 21 ] with both the policy and value 8 function implementing recurrent lay ers in their networks. T o unders tand ho w recur rent la y ers result in an adaptiv e agent, consider that given some ground tr uth agent position, v elocity , attitude, and rotational velocity x t , and action vector u t output by the agent ’s policy , the next state x t + 1 and obser vation o t + 1 depends not only on x t and u t , but also on the ground tr uth agent mass, iner tia tensor, targ et maneuvers, and e xter nal f orces acting on the agent. Consequentl y , dur ing training, the hidden s tate of a network’ s recur rent network ev olv es differently depending on the obser ved sequence of observations from the en vironment and actions output by the policy . Specifically , the trained policy’ s hidden state captures unobserved (potentiall y time-varying) inf or mation such as e xter nal forces that are useful in minimizing the cost function. In contrast, a non-recur rent policy (which w e will ref er to as an MLP policy), which does not maintain a persistent hidden state vector , can only optimize using a set of cur rent obser v ations, actions, and advantag es, and will tend to under -perform a recur rent policy on tasks with randomized dynamics, although as w e hav e sho wn in [ 22 ], training with parameter uncer tainty can giv e good results using an MLP policy , provided the parameter uncer tainty is not too extreme. After training, although the recur rent policy’ s network weights are frozen, the hidden state will continue to ev olv e in response to a sequence of observations and actions, thus making the policy adaptive. In contrast, an MLP policy’ s behavior is fix ed by the netw ork parameters at test time. The PPO algorithm used in this w ork is a policy gradient algorithm which has demonstrated state-of-the-art performance f or many RL benchmark problem. PPO appro ximates the TRPO optimization process[ 23 ] by accounting f or the policy adjustment constraint with a clipped objectiv e function. The objective function used with PPO can be e xpressed in ter ms of the probability ratio p k ( θ ) giv en by , p k ( θ ) = π θ ( u k | o k ) π θ old ( u k | o k ) (10) where the PPO objective function is then as f ollo ws: J ( θ ) = E p ( τ ) min [ p k ( θ ) , clip ( p k ( θ ) , 1 − , 1 + ) ] A π w ( o k , u k ) (11) This clipped objectiv e function has been shown to maintain a bounded KL diver gence with respect to the policy distributions between updates, which aids con v erg ence by insuring that the policy does not chang e drasticall y between updates. Our implementation of PPO uses an approximation to the advantag e function that is the difference between the empirical return and a state value function baseline, as sho wn in Equation 12: A π w ( x k , u k ) = " T Õ ` = k γ ` − k r ( o ` , u ` ) # − V π w ( x k ) (12) Here the value function V π w is lear ned using the cost function giv en by L ( w ) = M Õ i = 1 V π w ( o i k ) − " T Õ ` = k γ ` − k r ( u i ` , o i ` ) # ! 2 (13) In practice, policy gradient algorithms update the policy using a batch of trajectories (roll-outs) collected by interaction with the environment. Eac h trajectory is associated with a single episode, with a sample from a trajectory collected at step k consisting of observation o k , action u k , and rew ard r k ( o k , u k ) . Finally , gradient ascent is per f ormed on θ and gradient decent on w and update equations are given b y w + = w − − β w ∇ w L ( w ) | w = w − (14) θ + = θ − + β θ ∇ θ J ( θ ) | θ = θ − (15) where β w and β θ are the lear ning rates f or the value function, V π w ( o k ) , and policy , π θ ( u k | o k ) , respectiv ely . In our implementation, we dynamically adjust the clipping parameter to targ et a KL div erg ence between policy updates of 0.001. The policy and value function are lear ned concur rently , as the estimated value of a state is policy dependent. The policy uses a Multi-categorical policy distr ibution, where a separate observation conditional categorical distribution is maintained for each element of the action vector . Note that e xploration in this case is conditioned on the obser vation, with the tw o logits associated with each element of the action v ector deter mining how peaked the softmax distribution becomes f or each action. Because the log probabilities are calculated using the logits, the degree of e xploration automatically adapts during lear ning such that the objective function is maximized. 9 B. Guidance La w Optimization Our guidance law w as motivated b y recent experimental research into the method falcons use to intercept prey [ 24 ], where it was f ound that the f alcons attempt to k eep the pre y centered at the shallo w f o v ea, a region of high photo-receptor density off set appro ximately 9 degrees from the falcon ’ s body frame axis that is kept aligned with its v elocity v ector . The falcon then maneuv ers in a wa y that keeps the pre y centered at this location while minimizing the optical flo w field. W e f ound that results improv ed if we targ eted seeker angles at their value at the start of the homing phase. Specifically , (see Eqs. 2a and 2b) we define θ u o and θ v o as the seeker angles at the start of the homing phase, and define the er ror signals e u = θ u − θ u o and e v = θ v − θ v o . W e also define the change in θ u and θ v o v er the 100 mS guidance cy cle as d θ u , d θ v . The obser v ation given to the agent is then as sho wn in Eq. (16). obs = h e u e v d θ u d θ v i (16) The action space f or the guidance policy is in Z k , where k is the number of thr usters. W e use a multi-categor ical policy distribution. Dur ing optimization, the policy samples from this distribution, returning a value in Z k , Each element of the agent action u ∈ 0 , 1 is used to inde x T able 1, where if the action is 1, it is used to compute the body frame f orce and torque contr ibuted by that thruster . For testing and deplo yment, the sampling is tur ned off, and the action is just the argmax of the tw o logits across each element of the action v ector . The policy and value functions are implemented using f our lay er neural netw orks with tanh activations on each hidden lay er . Lay er 2 for the policy and value function is a recur rent lay er implemented using gated recur rent units [ 25 ]. The netw ork architectures are as shown in T able 4, where n hi is the number of units in la y er i , obs _ dim is the observation dimension, and act _ dim is the action dimension. The policy and value functions are per iodicall y updated during optimization after accumulating trajectory rollouts of 30 simulated episodes. T able 4 P olicy and V alue Function netw ork architectur e Policy Netw ork V alue Netw ork La y er # units activation # units activation hidden 1 10 ∗ obs _ dim tanh 10 ∗ obs _ dim tanh hidden 2 √ n h1 ∗ n h3 tanh √ n h1 ∗ n h3 tanh hidden 3 10 ∗ act _ dim tanh 5 tanh output act _ dim linear 1 linear The agent receiv es a ter minal rew ard if the miss distance is less than 50 cm at the end of an episode. Because it is highly unlikel y that the agent will experience these rew ards through random exploration, we augment the rew ard function using shaping re wards [ 26 ]. These shaping re wards are given to the agent at each timestep, and guide the agent ’ s behavior in such a wa y that the agent will begin to experience the ter minal rew ard. Specifically , the shaping re wards encourag e beha vior that minimizes the angle er rors e u , e v and the angular rate of chang e d θ u , d θ v , as shown in Eq. (17a) , where α , σ e and σ d θ are h yper parameters. The multiplicativ e Gaussian f orm maximizes shaping rew ards when both the angle er rors and angular rate of change are minimized. r shaping = e xp © « − k h e u e v i k σ e − k h d θ u d θ v i k σ d θ ª ® ® ¬ (17a) r terminal = ( 10 , if miss < 50cm 0 , otherwise (17b) r = α r shaping + r terminal (17c) During optimization, the policy and value function are updated using rollouts collected o ver 30 episodes. An episode is ter minated if one of the seeker angles θ u , θ v e xceeds the maximum field of view (135 degrees). Note that this termination condition co v ers the cases of successful intercepts and misses, and indirectly implements a field of view constraint. W e use the dual discount rate approach first sugg ested in [ 22 ], with shaping re wards discounted b y γ 1 = 0 . 90 and ter minal re wards discounted b y γ 2 = 0 . 995 . Fig. 5 plots the rew ard statis tics f or the rew ards received by the agent 10 and number of steps per episode o v er the 30 episodes of rollouts used to update the policy and value function. N ote that a 100 step episode will hav e a duration of 10s. Fig. 6 giv es statistics f or miss distance during optimization, again with the statistics calculated o ver 30 episodes of rollouts. Here the "SD R" cur v e is the mean re ward less one standard deviation. Note that the guidance policy was optimized assuming stabilized attitude, i.e., the missile ’ s attitude remains fix ed dur ing the engag ement. Fig. 5 Learning Curves: Re war ds Fig. 6 Learning Curves: Re war ds W e did experiment with sev eral variations f or the RL problem formulation, and f ound that including the bonus re ward for a successful hit w as cr ucial in obtaining good per f or mance. Including the d θ u and d θ v terms is also impor tant. W e did not test different policy and value function architectures or deter mine the effect of varying the ter minal and shaping re ward coefficients, and it is possible performance could be improv ed with a more extensiv e hyperparameter search. IV . Experiments A. Augmented ZEM Guidance La w Benchmark In the f ollo wing e xper iments, w e compare the performance of the RL der ived guidance la w to that of the augmented zero-effort miss (ZEM) guidance law . The augmented ZEM guidance law maps an estimate of the relativ e position and v elocity betw een the missile and target and an estimate of the targ et acceleration to a commanded acceleration in the 11 inertial ref erence frame, as shown in Eqs. (18a) through (18d), where N is optimally set to 3 f or augmented ZEM. ZEM = r TM + v TM t go + 1 2 a T t 2 go (18a) v c = − r TM · v TM k r TM k (18b) t go = k r TM k v c (18c) a com = N ZEM t 2 go (18d) (18e) W e then con v er t the commanded acceleration to a body frame acceleration a B com b y projecting it onto the thr uster model direction v ectors in the first f our ro ws of T able 1. Pulsed thr ust is then ac hiev ed by tur ning on an engine when the cor responding element of a B com e xceeds 1/3 of the maximum acceleration (the ratio of maximum thrust to dry mass). W e chec ked that per f or mance is close to that of acceleration limited augmented ZEM where the acceleration is directly applied to the missile (i.e., Eq. (9b) ). Our approach allo ws a closer comparison of the two guidance law s as w e can use the same equations of motion. B. Comparison of RL guidance policy with A ugmented ZEM In order to pro vide a good compar ison with the augmented ZEM guidance law , w e assume that the missile’ s attitude is perfectl y stabilized, i.e., the attitude remains unchang ed from that at the start of the homing phase. The RL policy and augmented ZEM policy are tested agains t the engag ement scenario descr ibed in Section II.B, where the values giv en in T able 2 are randomized in each episode. The environment used f or optimization is also used f or testing. Randomizing each episode’ s engag ement parameters insures that during testing, the ag ent e xper iences no v el engag ement scenar ios not e xperienced during optimization. T able 5 tabulates the results from r unning 5000 simulations for the RL optimized policy and the augmented ZEM policy using randomized initial conditions with bounds given in T able 2. The RL policy e xhibits better accuracy , despite the fact that the augmented ZEM policy is giv en the full engag ement state (relative position, v elocity , and targ et acceleration) as an obser v ation, whereas the RL policy is only using seeker angles and their rate of chang e. The RL policy is also more fuel efficient, which is important f or e x o-atmospher ic intercepts where the interceptor will lose all control author ity when its fuel is e xhausted. W e repeat this experiment, but without randomizing heading er ror and targ et acceleration (they are set to the maximum values) with the heading er ror at 5 degrees, attitude er ror at 5 degrees, and maximum targ et acceleration. N ote that f or these w orst case values, the heading er ror and attitude er ror is still random, i.e., there are an infinite number of initial missile velocity v ectors with an angle of 5 deg rees with respect to the ideal missile velocity vector in R 3 . Results are sho wn in T able 6. T able 5 RL / Augmented ZEM Comparison: Randomized Heading Error and T arge t A cceleration Parameter Miss (cm) Fuel (kg) V alue < 100 cm (%) < 50 cm (%) µ σ A ug. ZEM (N=3) 97 45 9.4 3.7 RL 99 68 7.8 2.8 T able 6 RL / Augmented ZEM Comparison: Maximum Heading Error and T arge t A cceleration Parameter Miss (cm) Fuel (kg) V alue < 100 cm (%) < 50 cm (%) µ σ A ug. ZEM (N=3) 83 28 17.5 2.1 RL 95 53 16.1 2.1 12 Figs. 7 and 8 illus trate a trajectory corresponding to randomly generated (and different in each case) initial conditions. Position is the missile ’ s position in a target centered ref erence frame. In the seeker angle and angle rate of chang e plots, Theta_u and Theta_v cor respond to θ u and θ v respectiv ely . Although the augmented ZEM policy does not use the seeker , the simulator still instantiates a seeker so that w e can view the seeker angles and their rate of change during the engag ement. The subplot labeled "Theta_CV" plots the angle between the missile ’s velocity v ector and the missile ’ s body frame x-axis. N ote that ev en f or the case where Theta_CV star ts at zero, missile div ert thrusts will in general cause a misalignment between these vectors. Although in theor y these could be cor rected using attitude control thrusters, this would require kno w ledge of the missile ’ s v elocity v ector , which in this work we assume is unknown. At an y rate, the effect on performance is minimal. It appears that the RL policy is doing what we w ould hope, expending most of the control effor t earl y in the engag ement. Fig. 7 Sample RL T ra jectory 13 Fig. 8 Sample A ugmented ZEM T ra jectory C. P olicy Generalization to No v el Engag ement Scenarios In order to tes t the ability of the optimized policy to g eneralize to engag ement parameters outside the rang e e xperienced during optimization, we e xtend the range of sev eral engag ement parameters as sho wn in T able 7, with the other engagement parameters unchanged from T able 2. W e found accuracy was unchang ed, with fuel consumption increasing b y approximatel y 1kg. Ne xt we test the RL policy on a nov el targ et maneuv er not seen dur ing optimization, a bar rel roll maneuv er [ 27 ] with randomized wea ve per iod ranging from 1s to 5s, and the magnitude of targ et acceleration constant at the tar get ’ s maximum acceleration capability . This ended up being a more difficult maneuver for both the RL and augmented ZEM policies. The results are shown in T able 8, with augmented ZEM results given f or compar ison. It is possible that the per f ormance of the RL policy could be improv ed in this case by optimizing ov er a mix of bang-bang and bar rel roll maneuvers. Intuitivel y , w e expect good g eneralization if the no vel eng agement scenarios result in seeker angles and their rates of chang e sta ying within the ranges e xper ienced dur ing optimization. Finally w e compare performance betw een the RL policy and the augmented ZEM policy when the heading er ror is increased to 6 degrees. Here w e do not randomize the heading er ror and target acceleration (the y are set to the maximum values). Otherwise the engag ement parameters are as shown in T able 2. Since w e chose the eng agement scenario parameters in T able 2 to create an engag ement at the limit of the augmented ZEM policy’ s capability , w e expect the performance f or both policies to deter iorate as compared to the results sho wn in T able 6. The results are shown in T able 9. It is possible that w e could hav e improv ed the RL policy results by optimizing o ver an e xtended range of heading er rors. 14 T able 7 Extended Initial Conditions Parameter min max Range (km) 50 75 Missile V elocity Magnitude (m/s) 3000 3500 T ar get P osition angle θ (degrees) -20 20 T ar get P osition angle φ (deg rees) -20 20 T ar get V elocity Magnitude (m/s) 3000 4000 T ar get V elocity angle β (degrees) -15 15 T ar get V elocity angle α (degrees) -15 15 T able 8 RL / Augmented ZEM Comparison f or Barrel Roll T arg et Maneuv er Parameter Miss (cm) Fuel (kg) V alue < 100 cm (%) < 50 cm (%) µ σ A ug. ZEM (N=3) 58 19 21.8 3.2 RL 59 25 13.5 3.5 T able 9 RL / Augmented ZEM Comparison f or 6 degree Heading Error Parameter Miss (cm) Fuel (kg) V alue < 100 cm (%) < 50 cm (%) µ σ A ug. ZEM (N=3) 79 28 18.8 1.97 RL 93 49 16.1 2.1 V . Conclusion W e ha v e demonstrated that it is possible to formulate a missile guidance problem in the RL framew ork that maps seeker angles and their rate of chang e directly to actuator commands. The resulting guidance policy has per f ormance close to that of state of the ar t methods such as augmented ZEM with access to the ground tr uth engag ement state. W e sho w that the guidance la w generalizes w ell to nov el engag ement scenar ios not e xper ienced during optimization, specifically an e xtended initial condition range, no v el target maneuv ers, and increased heading er ror . The guidance la w dev eloped in this work is par ticularl y applicable to passive seekers, which are not capable of measuring range or range rate. T o date it has not been possible to formulate a guidance law using angle-onl y measurements using the optimal control framew ork (which typically req uires full state f eedback), and estimating the full eng agement s tate from angle-only measurements is an open problem. Further, optimizing a guidance la w in a framew ork allowing the specification of a cost (rew ard) function and constraints has the potential to impro v e per f or mance as compared to the state of the ar t sys tems using passive seek ers. W e therefore sugg est that the RL framew ork is a good candidate for impro ving the performance of guidance sys tems compatible with passive seek ers. Future work might include endo-atmospheric intercepts, more realistic engag ement scenar ios, higher fidelity dynamics, and applying RL to targ et discr imination. Ref erences [1] Ratnoo, A., and Ghose, D., “Collision-geometry -based pulsed guidance law for ex oatmospheric interception, ” Jour nal of guidance, control, and dynamics , V ol. 32, No. 2, 2009, pp. 669–675. [2] Gutman, S., “Ex oatmospher ic Interception via Linear Quadratic Optimization, ” Journal of Guidance, Contr ol, and Dynamics , V ol. 42, N o. 3, 2019, pp. 624–631. [3] Zarchan, P ., T actical and strategic missile guidance , Amer ican Ins titute of Aeronautics and Astronautics, Inc., 2012, pp. 338–347. doi:doi.org/10.2514/4.868948. [4] Kalman, R. E., and Bucy , R. S., “Ne w results in linear filter ing and prediction theory , ” Journal of basic engineering , V ol. 83, No. 1, 1961, pp. 95–108. 15 [5] Sullins, G., “Ex o-atmospher ic intercepts- Br inging new challenges to Standard Missile, ” Johns Hopkins APL T echnical Diges t , V ol. 22, N o. 3, 2001, pp. 260–274. [6] Siouris, G. M., Missile guidance and contr ol syst ems , Spr inger Science & Business Media, 2004. [7] Shne ydor , N . A., Missile guidance and pursuit : kinematics, dynamics and control , Elsevier , 1998. [8] T aur , D.-R., and Chern, J.-S., “Passiv e ranging for dog-fight air -to-air IR missiles, ” Guidance, Navig ation, and Control Conf erence and Exhibit , 1999, p. 4289. [9] Song, T . L., and Um, T . Y ., “Practical guidance for homing missiles with bearings-only measurements, ” IEEE T ransactions on Aer ospace and Electr onic Syst ems , V ol. 32, N o. 1, 1996, pp. 434–443. [10] Reisner , D., and Shima, T ., “Optimal guidance-to-collision la w f or an accelerating e x oatmospher ic interceptor missile, ” Journal of Guidance, Control, and Dynamics , V ol. 36, N o. 6, 2013, pp. 1695–1708. [11] Kim, H.-G., Lee, J.- Y ., and Kim, H. J., “Look Angle Constrained Impact Angle Control Guidance Law f or Homing Missiles With Bear ings-Only Measurements, ” IEEE T r ansactions on A erospace and Electr onic Syst ems , V ol. 54, No. 6, 2018, pp. 3096–3107. [12] Desk, E. C., “Electronic warfare and radar sy stems engineer ing handbook, ” Published in association with MTTS & IEEE , 1997. [13] Zarchan, P ., T actical and strat egic missile guidance , Amer ican Institute of A eronautics and Astronautics, Inc., 2012, pp. 18–21. doi:doi.org/10.2514/4.868948. [14] Gaudet, B., and Linares, R., “ A daptive Guidance with Reinf orcement Meta-Lear ning, ” arXiv preprint arXiv :1901.04473 , 2019. [15] Zarchan, P ., T actical and strat egic missile guidance , Amer ican Institute of A eronautics and Astronautics, Inc., 2012, pp. 18–21. doi:doi.org/10.2514/4.868948. [16] Finn, C., Abbeel, P ., and Levine, S., “Model-agnostic meta-lear ning f or fast adaptation of deep netw orks, ” arXiv preprint arXiv :1703.03400 , 2017. [17] Mishra, N., R ohaninejad, M., Chen, X., and Abbeel, P ., “ A simple neural attentive meta-learner, ” 2018. [18] Frans, K., Ho, J., Chen, X., Abbeel, P ., and Schulman, J., “Meta lear ning shared hierarchies, ” arXiv pr eprint arXiv :1710.09767 , 2017. [19] W ang, J. X., Kurth-Nelson, Z., Tirumala, D., So yer , H., Leibo, J. Z., Munos, R., Blundell, C., Kumaran, D., and Botvinick, M., “Learning to reinforcement lear n, ” arXiv preprint arXiv :1611.05763 , 2016. [20] T edrak e, R., “Lecture notes from Underactuated R obotics, ” , Februar y 2015. URL http://underactuated.csail.mit. edu/underactuated.html . [21] Schulman, J., W olski, F ., Dhar iw al, P ., Radf ord, A., and Klimov , O., “Pro ximal policy optimization algor ithms, ” arXiv preprint arXiv :1707.06347 , 2017. [22] Gaudet, B., Linares, R., and Furfaro, R., “Deep R einf orcement Learning for Six Degree-of-Freedom Planetary P ow ered Descent and Landing, ” arXiv preprint arXiv :1810.08719 , 2018. [23] Schulman, J., Le vine, S., Abbeel, P ., Jordan, M., and Moritz, P ., “T r ust region policy optimization, ” International Confer ence on Machine Lear ning , 2015, pp. 1889–1897. [24] Kane, S. A., and Zamani, M., “F alcons pursue prey using visual motion cues: ne w perspectiv es from animal-bor ne cameras, ” Journal of Experimental Biology , V ol. 217, No. 2, 2014, pp. 225–234. [25] Chung, J., Gulcehre, C., Cho, K., and Bengio, Y ., “Gated f eedback recur rent neural networks, ” International Conf erence on Mac hine Learning , 2015, pp. 2067–2075. [26] Ng, A. Y ., “Shaping and policy search in reinf orcement learning, ” Ph.D. thesis, Univ ersity of Calif ornia, Berkele y , 2003. [27] Zarchan, P ., T actical and strategic missile guidance , Amer ican Ins titute of Aeronautics and Astronautics, Inc., 2012, pp. 120–121. doi:doi.org/10.2514/4.868948. 16
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment