Augmented Probability Simulation Methods for Sequential Games
We present a robust framework with computational algorithms to support decision makers in sequential games. Our framework includes methods to solve games with complete information, assess the robustness of such solutions and, finally, approximate adv…
Authors: Tahir Ekin, Roi Naveiro, Alberto Torres-Barran
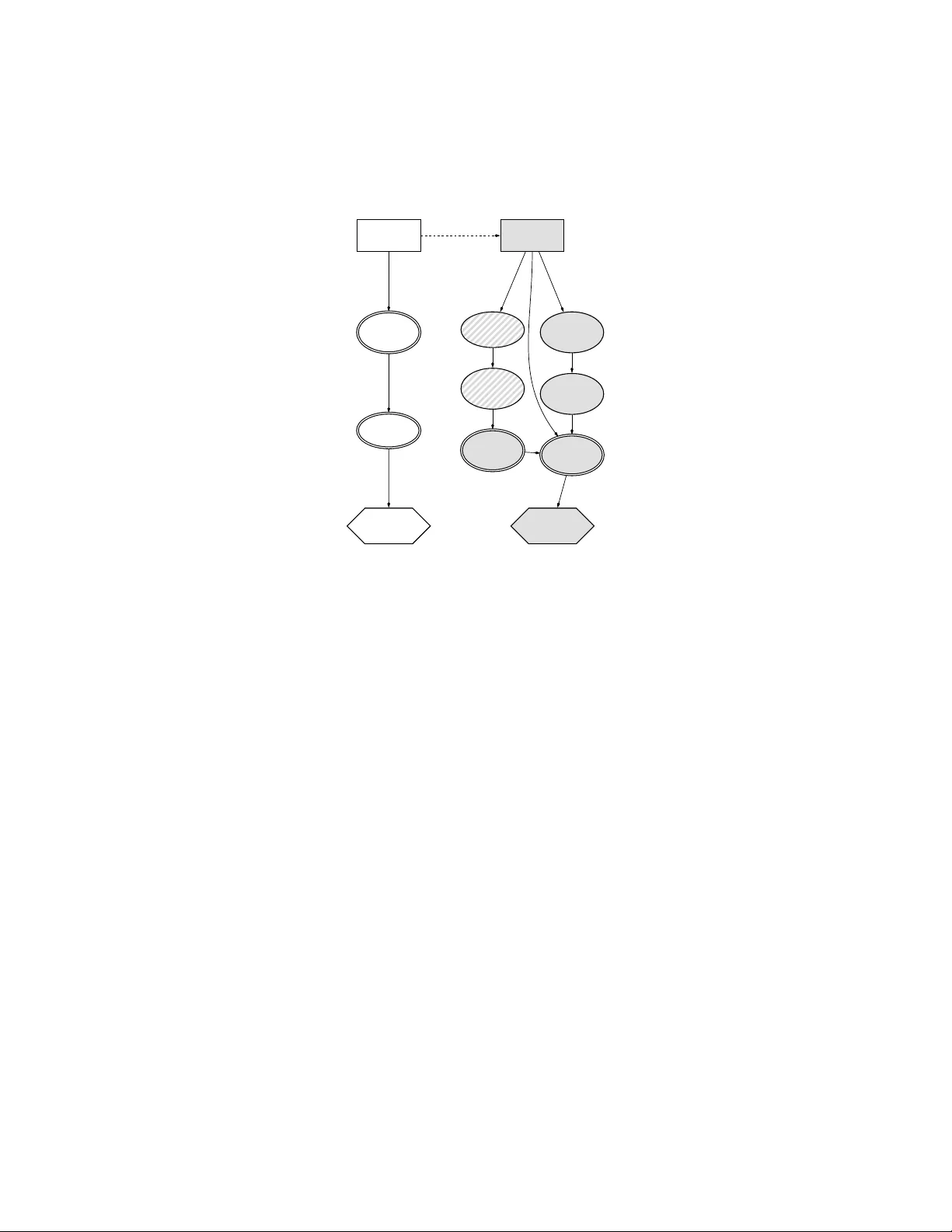
Augmen ted Probabilit y Sim ulation Metho ds for Sequen tial Games T ahir Ekin a , Roi Na veiro b, ˚ , Da vid R ´ ıos Insua c , Alb erto T orres-Barr´ an d a McCoy Col le ge of Business, T exas State University. b CUNEF Universidad, Madrid, Sp ain. c Institute of Mathematic al Scienc es (ICMA T), Madrid, Sp ain. d Komor ebi AI, Madrid, Sp ain. Abstract W e presen t a robust framew ork with computational algorithms to supp ort decision mak ers in sequential games. Our framework includes metho ds to solv e games with complete information, assess the robustness of such solutions and, finally , approximate adversarial risk analysis solutions when lac king complete information. Existing sim ulation based approac hes can b e inefficient when dealing with large sets of feasible decisions; the game of interest may not even be solv able to the desired precision for contin uous decisions. Hence, w e provide a nov el alternative solution metho d based on the use of augmen ted probabilit y simulation. While the prop osed framework conceptually applies to m ulti- stage sequential games, the discussion fo cuses on tw o-stage sequential defend-attack problems. Keywor ds: Decision analysis, Sequen tial games, Augmented probability simulation, Adv ersarial risk analysis 1. In tro duction Sequen tial games refer to decision making environmen ts where decision mak ers c ho ose actions alternately o v er time. In articular, we shall emphasise non-co op erativ e sequen tial games, co vering conflict situations in which t w o or more agents make decisions whose pa y offs dep end on the actions implemen ted b y all of them and, possibly , on some random outcomes. Under complete information ab out the agen ts’ preferences and b eliefs, the analysis is usually done through Nash equilibria (NE) and related refinemen ts which provide a prediction of the agents’ decisions. On the other hand, games with incomplete information corresp ond to cases where the agents do not p ossess ˚ Corresp onding author Email addr ess: roi.naveiro@cunef.edu (Roi Na veiro) Pr eprint submitte d to Eur op e an Journal of Op er ational R ese ar ch F ebruary 22, 2024 full information ab out their opp onents, and are traditionally solved with Bay es Nash equilibrium (BNE) concepts (Harsan yi, 1967). Heap and V aroufakis (2004) provide an in-depth critical assessmen t. The standard common prior h yp othesis underlying BNE (An tos and Pfeffer, 2010) is relaxed with the adv ersarial risk analysis (ARA) (Banks et al., 2015) metho dology which assesses the prior ov er agents’ types using decision analytic argumen ts. In addition, ARA pro vides prescriptiv e supp ort to one of the decision makers based on a sub jectiv e exp ected utility mo del encompassing a forecast of the adversaries’ decisions. Banks et al. (2020) show that the ARA solution algorithmically coincides with the BNE for tw o-stage sequential games. F urther comparisons and discussions of relationships b et ween ARA and traditional game-theoretic concepts can b e found in Banks et al. (2015, 2020). Our realm in this pap er will b e within algorithmic decision (F otakis and Rios Insua, 2021) and game (Nisan et al., 2007) theories, prop osing scalable metho ds to approximate solutions for sequen tial games with large (even con tin uous) decision sets and uncertain outcomes. Discussions concerning the complexity of computing game-theoretic solutions in security games ma y b e seen in Korzh yk et al. (2011) and references therein. A v ariet y of simulation based approaches could b e utilized for cases where analytical solutions are not av ailable (Amaran et al., 2016). Among those, Monte Carlo (MC) metho ds are straightforw ard and widely implemen ted (Shao, 1989). Ho wev er, they can b e inefficient in face of a large n um b er of alternativ es, as in counter-terrorism and cyb ersecurit y problems which may inv olv e thousands of p ossible decisions and large uncertain ties about the attack ers’ goals and resources (Zhuang and Bier, 2007). In addition, in problems with contin uous decision sets and decision dep endent uncertainties, MC requires discretizing decision spaces, with its p erformance critically dep ending on the precision of such discretization. Increasing accuracy may require dealing with man y more decision alternativ es at a prohibitive computational cost. Pro cedures that fo cus on high-probabilit y high-impact ev ents, such as imp ortance sampling, could improv e the estimations b y reducing their v ariance. Ho w ever, an optimization problem w ould still need to b e solved. As an alternative, Bielza et al. (1999) in tro duced augmen ted probabilit y sim ulation (APS) to appro ximate optimal solutions in decision analytic problems. APS transforms the problem in to a grand sim ulation in the join t space of decision and random v ariables, constructing an auxiliary augmented distribution (from no w on, the augmente d distribution ) which is prop ortional to the pro duct of the utility function and the original distribution. Then, the optimal decision alternativ e would coincide with the mo de of the marginal of the augmented distribution o ver the decisions. As a consequence, sim ulation from the augmen ted distribution enables 2 undertaking the ev aluation and optimization tasks simultaneously . W e fo cus on comparing APS and MC metho ds in solving games b ecause of their shared broad applicability . More sp ecific metho ds could b e preferred in certain con texts. F or instance, when dealing with con tin uous decision sets, extensions of sim ulation optimization metho ds (Nelson et al., 2001) that incorp orate gradient information could b e useful, esp ecially in high-dimensional settings (Na veiro and Insua, 2019). When gradien ts cannot b e directly ev aluated, sto c hastic approximation or resp onse surface metho ds (F u, 2015) could be p otential alternatives. Nevertheless, these other metho ds are only applicable for games with con tinuous decision sets. This pap er presen ts a robust decision supp ort framework with no v el APS-based computational algorithms for decision mak ers in sequen tial games. The framew ork co vers cases of b oth complete and incomplete information, in terlinked through sensitivity analysis. T o the b est of our kno wledge, this is the first sequential use of APS algorithms to solv e sequential decision problems with more than one sto c hastic decision stage and, moreo ver, with more than one decision maker. A key adv an tage of APS in our setting is that, unlike plain MC metho ds, its complexity do es not dep end on the cardinality of the decision sets, thus b eing the preferred approach when dealing with large decision spaces. Indeed, our approac h do es not require discretization in con tin uous decision sets; this mak es it scalable in imp ortan t contexts such as adversarial machine learning (AML) (R ´ ıos Insua et al., 2020), entailing v ery high dimensional contin uous decision spaces and, consequen tly , hardly solv able using standard metho ds. Moreov er, APS can b e used to sample from a p ow er transformation of the distribution of interest, this b eing more p eak ed around the mo de, thus facilitating iden tification of the optimal alternativ e. Finally , our approac h provides sensitivity analysis to ols at no extra computational cost. T o mak e the presen tation more concise, we fo cus on sequen tial games in whic h the supp orted agent mak es a decision first, then observ ed b y another agent who makes his o wn decision. These corresp ond to t wo-stage sequential defend-attack (Brown et al., 2006) or, more generally , to Stack elberg (Korzhyk et al., 2011) games. Their imp ortance in the literature of security games (Sinha et al., 2018a; Zhuang and Bier, 2007) and AML (R ´ ıos Insua et al., 2020) inspires our developmen ts. It is also worth mentioning that suc h games are relev ant in numerous other areas, from its original conception in business comp etition (v on Stack elberg, 1952) to automated driving systems (Y u et al., 2018). Although we fo cus on illustrating our metho ds in t w o stage defend-attack games, the framew ork conceptually extends to multi-stage sequential games, as sketc hed in our discussion and outlined in detail in the supplementary materials, including a demonstration for a three stage game. 3 The pap er proceeds as follows. Sections 2 and 3 present the k ey steps of the framew ork: appro ximating equilibria under complete information, assessing robustness of suc h equilibria and, finally , if necessary , approximating ARA solutions under incomplete information. A computational assessment is presen ted in Section 4, follo w ed b y a cyb ersecurit y case study in Section 5. Section 6 concludes with a discussion. An App endix sk etches key proofs. A Supplementary Materials (SM) file presents additional results, algorithms, and details of the case study . Co de to repro duce the results is a v ailable in a GitHub rep ository (T orres-Barr´ an and Nav eiro, 2019). 2. Sequen tial games with complete information This section fo cuses on computational methods for finding equilibria in sequen tial defend-attac k games with complete information. Assume, thus, a Defender ( D , she)c ho oses her defense d P D , where D is her set of feasible alternativ es. After observing this, an A ttack er ( A , he) c ho oses his attack a P A , with A his set of av ailable alternativ es. The consequences of the interaction for b oth agents dep end on a random outcome θ P Θ, with Θ the space of outcomes. Figure 1 displays the corresp onding bi-agen t influence diagram (Banks et al., 2015) which serves as a template for later discussions. Arc D - A reflects that the A ttack er observes the Defender’s decision. The agen ts ha ve their own assessmen t of the outcome probabilit y , resp ectively p D p θ | d, a q and p A p θ | d, a q . The Defender’s utility u D p d, θ q is a function of her chosen defense and the outcome. Similarly , the A ttack er’s utility function is u A p a, θ q . Θ D A U D U A Figure 1: Basic tw o play er sequential defend-attack game. White nodes affect solely the Defender; grey no des affect only the Attac k er; strip ed no des affect both agen ts. In the standard complete information setup, the basic game-theoretic solution do es not require A to kno w D ’s probabilities and utilities, as he observes her actions. Ho wev er, the Defender m ust know p u A , p A q , the common knowledge assumption in this case. Then, b oth agen ts’ exp ected utilities are computed as ψ A p d, a q “ ş u A p a, θ q p A p θ | d, a q d θ and ψ D p d, a q “ ş u D p d, θ q p D p θ | d, a q d θ . Next, the Attac k er’s best resp onse to D ’s action d , is 4 a ˚ p d q “ arg max a P A ψ A p d, a q . The optimal attack er resp onse to defense d is then used to find the Defender’s optimal action d ˚ GT “ arg max d P D ψ D p d, a ˚ p d qq . In case of multiple b est resp onses for the attack er given some defender action d , a ˚ p d q b ecomes a set. W e can then either use all global optimal alternatives or break the ties. In particular, ties are generally addressed by either c ho osing the most fa vorable attac k for the defender, leading to a str ong Stackelb er g e quilibrium (SSE) (solving max d P D ,a P a ˚ p d q ψ D p a, d q ); or choosing the worst attac k for the defender, leading to a we ak Stackelb er g e quilibrium (solving max d P D min a P a ˚ p d q ψ D p a, d q ), see Leitmann (1978). While, in principle, the algorithms can accommo date any tie breaking rule, in what follows, when necessary , we shall assume that ties are brok en in fa vor of the defender, the standard solution in security games (Korzh yk et al., 2011). Hence, in case of ties, the elemen t of a ˚ p d q maximizing the Defender’s exp ected utility will b e recorded as a ˚ p d q . The pair p d ˚ GT , a ˚ p d ˚ GT qq is a Nash equilibrium (and, indeed, a sub-game p erfect equilibrium (Heap and V aroufakis, 2004)). W e shall designate d ˚ GT as the game-theoretic defense under complete information. These sequen tial games require solving a bilevel optimization problem (Bard, 1991) whic h rarely ha v e analytical solutions, other than b y explicit enumeration in basic mo dels. Even extremely simple instances of bilevel problems hav e b een shown to b e NP- hard (Jeroslo w, 1985); Korzhyk and Conitzer (2010) provide additional computational complexit y results in such problems. Th us, numerical techniques are required. A v ariet y of metho ds are av ailable, see e.g. Nisan et al. (2007). In particular, sev eral classical and ev olutionary approaches ha v e been prop osed, review ed by Sinha et al. (2018b). When the inner problem adheres to certain regularity conditions, it is p ossible to reduce the bilevel problem to a single level one, replacing the inner problem by its Karush-Kuhn-T uck er conditions (Gordon and Tibshirani, 2012). Then, evolutionary tec hniques ma y b e used to solve this single-lev el problem, enabling to relax the upp er lev el requiremen ts. As this single-level reduction is not generally feasible, other approac hes suc h as nested ev olutionary algorithms or metamo deling metho ds hav e been prop osed. How ev er, most of these approac hes lac k scalability . Y et problems in emerging areas in secure artificial in telligence (AI) suc h as AML (R ´ ıos Insua et al., 2020) may require dealing with high dimensional con tin uous decision spaces, and, consequently , can hardly b e solved with standard metho ds. Some scalable gradient based solution approaches hav e b een recen tly in tro duced (Na v eiro and Insua, 2019); ho wev er, they are restricted to games under certain ty or in which exp ected utilities can b e computed analytically . On the other hand, MC sim ulation methods, see e.g. P onsen et al. (2011) and Johanson et al. (2012), are broadly applicable, as describ ed next. 5 2.1. Monte Carlo simulation for games Sim ulation based metho ds for sequential games t ypically approximate exp ected utilities using MC and, then, optimize with resp ect to decision alternatives, first to appro ximate A ’s b est resp onses, then to appro ximate the optimal defense. Algorithm 1 reflects a generic MC approach to solve sequen tial defend-attac k games when the decision sets A and D are discrete, 1 where Q and P are the sample sizes required to, resp ectively , appro ximate the exp ected utilities ψ A p d, a q and ψ D p d, a q to the desired precision. input: Q , P for al l d P D do for al l a P A do Generate samples θ 1 , . . . , θ Q „ p A p θ | d, a q Compute p ψ A p d, a q “ 1 Q ř i u A p a, θ i q Appro ximate a ˚ p d q via arg max a p ψ A p d, a q . Generate samples θ 1 , . . . , θ P „ p D p θ | d, a ˚ p d qq Compute p ψ D p d q “ 1 P ř i u D p d, θ i q Compute p d ˚ GT “ arg max d p ψ D p d q Algorithm 1: MC approach for sequential defend-attack games with complete information Con vergence of Algorithm 1, sketc hed in SM Section 1.1, follows under mild conditions and is based on t w o applications of a uniform v ersion of the strong la w of large num bers (SLLN) (Jennric h, 1969). F rom a computational p erspective, in addition to the cost of the final optimization and | D | inner loop optimizations, Algorithm 1 requires generating | D | ˆ p| A | ˆ Q ` P q samples, where | ¨ ¨ ¨ | designates the cardinality of the corresp onding set. MC approac hes could b e computationally exp ensiv e when dealing with decision dep endent uncertainties: sampling from p D p θ | d, a q and p A p θ | d, a q is required for each pair ( d , a ), en tailing lo ops o ver the sets D and A . When these are high dimensional, MC will typically b e inefficient. APS mitigates this issue. 2.2. A ugmente d pr ob ability simulation for games APS solv es for exp ected utilit y maximization by conv erting the tasks of estimation and optimization in to sim ulation from an augmen ted distribution o ver the join t space of decisions and outcomes. It can b e adv an tageous in problems with exp ected utility 1 In contin uous cases, they need to b e discretized to solve the problem to the desired precision, see Section 4.2. 6 surfaces that are exp ensive to estimate rendering the optimization step inefficient. Bielza et al. (1999) introduced it to solve decision analysis problems. Ekin et al. (2014) extend it to solv e constrained sto c hastic optimization mo dels with recourse, where the second stage problem can b e solv ed analytically and uncertaint y is exogenous. Ekin et al. (2017) prop ose APS models to solv e similar sto c hastic programs with endogenous uncertaint y , whereas Ekin et al. (2020) extend it to solve discrete programs. All these algorithms are designed for problems with a single decision maker and, moreo ver, with uncertain t y only at the first stage: APS is actually used to solve single stage problems (p ossibly from bilev el problems in which the second stage problem is solved analytically). Therefore, those APS algorithms cannot b e used to solv e sequential decision mo dels, in particular sequen tial games, with t wo opp osing decision makers and endogenous uncertaint y at b oth stages, which mak es the second stage decision mo del sto c hastic. T o the b est of our kno wledge, this is the first application of APS to solv e general tw o-stage sto c hastic decision problems (in particular, games). F or a giv en defender action d , consider the augmen ted distribution π A p a, θ | d q9 u A p a, θ q p A p θ | d, a q o ver p a, θ q , th us defined as prop ortional to the pro duct of A ’s utilit y function and his original distribution. If u A p a, θ q is p ositiv e and u A p a, θ q p A p θ | d, a q is integrable, the augmen ted distribution is w ell-defined. Moreov er, its marginal ov er actions a , giv en b y π A p a | d q “ ş π A p a, θ | d q dθ , is prop ortional to A ’s exp ected utility ψ A p d, a q . Consequently , given d , the Attac k er’s b est resp onse can be computed as a ˚ p d q “ mode r π A p a | d qs . In case of m ultiple global mo des, w e c ho ose the mo de of in terest by breaking ties via SSE, and record it as a ˚ p d q . T o av oid pathological cases, w e assume that the set of global mo des is finite. No w, assuming that u D p d, θ q is p ositiv e and u D p d, θ q p D p θ | d, a q is integrable, w e solv e D ’s problem by backw ard induction, sampling from the augmented distribution π D p d, θ | a ˚ p d qq9 u D p d, θ q p D p θ | d, a ˚ p d qq . Its marginal π D p d | a ˚ p d qq in d is prop ortional to D ’s exp ected utility ψ D p d, a ˚ p d qq and, consequently , the game-theoretic solution satisfies d ˚ GT “ mo de r π D p d | a ˚ p d qqs . Op erationally , this suggests a tw o-stage nested approach to sequen tial games based, at each stage, on i) sampling from the augmented distribution; ii) marginalizing to the corresp onding decision v ariables; and, iii) estimating the mo de of the marginal samples. Concerning s tep (i), Marko v chain Monte Carlo (MCMC) metho ds (F rench and Insua, 2000) serv e for sampling from the non-standard augmented distributions. These metho ds construct a Marko v c hain in the space of the target distribution (the augmented distributions) con v erging to the target under mild conditions. After conv ergence is detected, samples from the chain can b e used as appro ximate target samples. Of the 7 v arious approac hes a v ailable to construct the c hains, w e adopt versatile Metrop olis- Hastings (MH) v ariants (Chib and Green b erg, 1995) in Algorithm 2. This facilitates sampling appro ximately from π D p d, θ | a ˚ p d qq (outer APS) to solve D ’s problem. Within that, A ’s best resp onse a ˚ p d q is estimated for an y d using another APS (inner APS) based on π A p a, θ | d q . Details of our key MH acceptance/rejection step follow: let d and θ b e the curren t samples in the MH scheme of the outer APS; a candidate ˜ d for D ’s decision is sampled from a prop osal generating distribution g D p ˜ d | d q ; then, A ’s problem is solved using an inner APS to estimate a ˚ p ˜ d q ; the state θ is next sampled using p D p θ | ˜ d, a ˚ p ˜ d qq ; finally , the candidate samples are accepted with probabilit y u D p ˜ d, ˜ θ q¨ g D p d | ˜ d q u D p d,θ q¨ g D p ˜ d | d q . function solve attacker( M , K , d , g A ) : initialize : a p 0 q Dra w θ p 0 q „ p A p θ | d, a p 0 q q for i “ 1 to M do Ź Inner APS Prop ose new attac k ˜ a „ g A p ˜ a | a p i ´ 1 q q . Dra w ˜ θ „ p A p θ | d, ˜ a q Ev aluate acceptance probabilit y α “ min " 1 , u A p ˜ a, ˜ θ q ¨ g A p a p i ´ 1 q | ˜ a q u A p a p i ´ 1 q ,θ p i ´ 1 q q ¨ g A p ˜ a | a p i ´ 1 q q * With probabilit y α set p a p i q , θ p i q q “ p ˜ a, ˜ θ q . Otherwise, set p a p i q , θ p i q q “ p a p i ´ 1 q , θ p i ´ 1 q q . Discard first K samples and compute a ˚ p d q based on the mo de(s) of t a p K ` 1 q , ..., a p M q u return a ˚ p d q input: M , K , N , R , g D and g A prop osal distributions initialize : d p 0 q , a ˚ p d p 0 q q = solve attacker( M , K , d p 0 q , g A ) Dra w θ p 0 q „ p D p θ | d p 0 q , a ˚ p d p 0 q qq for i “ 1 to N do Ź Outer APS Prop ose new defense ˜ d „ g D p ˜ d | d p i ´ 1 q q a ˚ p ˜ d q “ solve attacker( M , K , ˜ d , g A ) if not previously computed Dra w ˜ θ „ p D p θ | ˜ d, a ˚ p ˜ d qq . Ev aluate acceptance probabilit y α “ min " 1 , u D p ˜ d, ˜ θ q ¨ g D p d p i ´ 1 q | ˜ d q u D p d p i ´ 1 q ,θ p i ´ 1 q q ¨ g D p ˜ d | d p i ´ 1 q q * With probabilit y α set p d p i q , a ˚ p d p i q q , θ p i q q “ p ˜ d, a ˚ p ˜ d q , ˜ θ q . Otherwise, set p d p i q , a ˚ p d p i q q ,θ p i q q “ p d p i ´ 1 q , a ˚ p d p i ´ 1 q q ,θ p i ´ 1 q q . Discard first R samples and estimate mo de of t d p R ` 1 q , ..., d p N q u . Record it as p d ˚ GT . Algorithm 2: MH based APS for sequential defend-attack games. Complete information. 8 Algorithm 2 th us defines a Marko v c hain p d p n q , θ p n q q d Ý Ñ π D p d, θ | a ˚ p d qq . 2 Step ii) in the APS sc heme is trivial. F or step iii), we use recent work in m ultiv ariate multiple mo de estimation, see the review in Chacon (2020), and then break ties when necessary. Prop osition 1 requires the follo wing four conditions for the con v ergence of Algorithm 2 output to d ˚ GT , as pro ved in App endix A: a). The A ttack er’s and Defender’s utilit y functions are p ositiv e and contin uous in p a, θ q and p d, θ q , resp ectively . b). The Attac ker’s and Defender’s decision sets, respectively A and D , are compact. c). The A ttack er’s and Defender’s probabilit y distributions of the outcomes are contin u- ous in a and d resp ectiv ely , and are p ositiv e in p d, a q . d). The prop osal generating distributions, g A and g D , ha ve support A and D , respectively . Prop osition 1. Assume that the Attacker’s and Defender’s utility functions, de cision sets, pr ob ability distributions and pr op osal gener ating distributions satisfy c onditions a), b), c) and d). Then, if the b est r esp onse sets a ˚ p d q ar e finite for e ach d , Algorithm 2 defines a Markov chain with stationary distribution π D p d, θ | a ˚ p d qq and a c onsistent mo de estimator b ase d on its mar ginal samples in d c onver ges a.s. to d ˚ GT . 3 The p ositivit y of the utilit y functions u A and u D allo ws for the definition of the augmen ted distributions; it is easily achiev ed taking into accoun t affine uniqueness prop erties of utilit y functions (F rench and Insua, 2000). Con tinuit y of these utilit y functions leads to con tinuous exp ected utilit y functions enabling the existence of optima, when assumption b) holds, a standard condition in optimization. Condition c) is also general and allows for the contin uity of b est resp onses. Finally , assumption d) provides standard sufficient conditions to ensure con vergence of MH samplers (Smith and Rob erts, 1993). Our prop osal generating distributions g D and g A in Algorithm 2 are t distributions cen tered at the current solutions (Gamerman and Lop es, 2006), when dealing with con tinuous decisions. When facing discrete decisions, these are displa y ed in a circular list and generated from neighboring states with equal probability . Chain conv ergence (to discard the first K or R samples) ma y b e assessed with v arious statistics like Bro oks- Gelman-Rubin’s (Bro oks and Rob erts, 1998). Con vergence of the Marko v chain is at 2 The symbol d Ý Ñ represents con vergence in distribution (Ch ung, 2001). 3 W e use standard probabilit y theory terminology (Chung, 2001) to refer to even ts happ ening almost surely (a.s.) when they occur with probability 1. 9 a geometric rate as a function of the minimum and maxim um utility v alues, see SM Section 2.1. Once the c hain is judged to hav e conv erged, initial samples are discarded as burn-in and the remaining simulated v alues are used as an approximate sample from the distribution of in terest. In particular, the marginal draws d p R ` 1 q , ..., d p N q w ould corresp ond to a sample from, approximately , the marginal distribution, π D p d | a ˚ p d qq . The sample mo des m ust b e estimated with a consistent multiple mode estimator in the sense of Chen et al. (2016). W e then select among them with the tie-breaking criteria men tioned ab o v e. See Chacon (2020) and Romano (1988) for additional information and references in mo de estimation. In comparison to Algorithm 1, Algorithm 2 remo ves the lo ops o v er b oth D and A . Th us, its complexity do es not dep end on the dimensions of those sets, pro viding an in trinsic adv antage o v er MC approaches in problems with large or con tinuous spaces, as APS can b e directly used with contin uous decision sets without the need of discretization. Indeed, Algorithm 2 requires N ˆ p 2 ˆ M ` 3 q ` 2 M ` 2 samples plus the cost of con vergence c hecks and (at most) N ` 1 mo de appro ximations, where M and N are, resp ectiv ely , the num b er of MCMC iterations for the attack er’s and defender’s APS required to ac hieve the desired precision. Example 1. Consider the following simple securit y game. An organization ( D ) has to c ho ose among ten security proto cols: d “ 0 (no extra defensive action); d “ i (lev el i proto col with increasing protection), i “ 1 , . . . , 8; d “ 9 (safe but cumbersome proto col). A has t wo alternatives: attack ( a “ 1) or not ( a “ 0). Successful (unsuccessful) attac ks are denoted θ “ 1 ( θ “ 0). When there is no attack, θ “ 0. T able 1: a Def. net costs; b Successful attac k probs.; c Att. net b enefits; d Beta dist. parameters θ d 0 1 0 0.05 7.05 1 0.10 7.10 2 0.15 7.15 3 0.20 7.20 4 0.25 7.25 5 0.30 7.30 6 0.35 7.35 7 0.40 7.40 8 0.45 7.45 9 0.50 7.50 (a) a d 0 1 0 0.0 0.50 1 0.0 0.40 2 0.0 0.35 3 0.0 0.30 4 0.0 0.25 5 0.0 0.20 6 0.0 0.15 7 0.0 0.10 8 0.0 0.05 9 0.0 0.01 (b) θ a 0 1 0 0.00 0.00 1 -0.53 1.97 (c) d α d β d 0 50.0 50.0 1 40.0 60.0 2 35.0 65.0 3 30.0 70.0 4 25.0 75.0 5 20.0 80.0 6 15.0 85.0 7 10.0 90.0 8 5.0 95.0 9 1.0 99.0 (d) 10 Defender non strategic judgments. T able 1a presents costs c D asso ciated with eac h decision and outcome, based on a 7M e business v aluation; and 0 . 05M e base securit y cost plus 0 . 05M e p er each security level increase. Upon successful attac k, D loses the entire business v alue. The probability p D p θ “ 1 | d, a q of successful attack is in T able 1b (complemen tary v alues for unsuccessful attac ks). D is constan t risk a verse in costs, with utilit y strategically equiv alent to u D p c D q “ ´ exp p 0 . 4 ˆ c D q . A ttac k er judgmen ts. The a verage attac k cost is 0 . 03M e . The a verage attac k b enefit is 2M e . An unsuccessful attack has an extra cost of 0 . 5M e . T able 1c presents the Attac ker’s net b enefit c A p a, θ q . D thinks that A is constant risk prone o ver b enefits, with utilit y strategically equiv alent to u A p c A q “ exp p e ˆ c A q , with e ą 0. Complete information case. T o fix ideas, assume p A p θ “ 1 | d, a q “ p D p θ “ 1 | d, a q (T able 1b) and e “ 1. MC and APS approximate optimal decisions using Algs. 1 and 0 1 2 3 4 0 1 2 3 4 5 6 7 8 9 d Expected Utility a 0 1 (a) MC solutions 0.0 0.2 0.4 0.6 0.8 0 1 2 3 4 5 6 7 8 9 d Frequency a 0 1 (b) APS solutions Figure 2: Attac ker problem solutions for each defense 2, resp ectiv ely . Fig. 2a represen ts MC estimates of A ’s exp ected utility for each d and a . F or each d , the b est resp onse a ˚ p d q is the maxim um exp ected utility alternative; e.g. for d “ 5, A ’s optimal decision is to attack; for d “ 8, he should not attac k. Fig. 2b represen ts the frequencies of marginal samples of a from the augmen ted distribution π A p a, θ | d q for each d . Its mode coincides with the optimal attac k. F or d ď 7, the A ttack er should attack. With stronger defenses ( d ě 8), the mo de is a “ 0 and attack is not advised. The Attac ker’s best resp onses a ˚ p d q th us coincide for b oth approac hes. Armed with a ˚ p d q , the optimal defense is computed, again b oth using MC and APS. Figure 3a presen ts the MC estimation of ψ D p d, a ˚ p d qq for eac h d . Figure 3b shows sample frequencies from the marginal augmen ted distribution π D p d | a ˚ p d qq . Both metho ds agree on d ˚ GT “ 8, with d “ 9 a close comp etitor. It could b e argued that finding the exact optimal decision is not that crucial as the exp ected utilities of both decisions 11 0 5 10 15 0 1 2 3 4 5 6 7 8 9 Optimal Decision Expected Utility (a) MC solution 0 2500 5000 7500 10000 0 1 2 3 4 5 6 7 8 9 Optimal Decision Frequency (b) APS solution Figure 3: Solutions of Defender problem are close. Moreo ver, given suc h closeness, it is even challenging to find the exact d ˚ GT . APS is helpful in chec king that, indeed, d “ 8 is optimal. F or this, w e sample d from a distribution more p eak ed around the optimal decision by just raising the marginal augmen ted distribution to a p o wer. SM Section 2.2 and 4.1 presen t the details. △ This emphasizes another adv antage of APS: despite flatness of the exp ected utilit y , APS finds the optimal solution with a relativ ely small additional computational cost while displa ying sensitivity . 2.3. Sensitivity analysis The Defender’s judgments, expressed through p u D , p D q , could b e argued to b e prop erly assessed, as she is the supp orted agen t in the game. How ev er, as argued in Keeney (2007), our knowledge ab out p u A , p A q ma y not b e that precise: it w ould require A to reveal his b eliefs and preferences. This is doubtful in domains suc h as security and cyb ersecurit y where information is concealed and hidden to adv ersaries. One could conduct a sensitivit y analysis to mitigate this, considering that A ’s preferences and b eliefs are mo deled through classes of utilities u P U A and probabilities p P P A summarizing the information a v ailable to D . The stability of the prop osed d ˚ GT could b e assessed by comparing NE defenses d ˚ u,p computed for each pair p u, p q based on criteria prop osed in the areas of sensitivity analysis in decision making under uncertain ty (Insua, 1990) and robust Ba yesian analysis (Insua and Ruggeri, 2012). Of those, we use the regret r u,p p d ˚ GT q “ ψ D p d ˚ GT , a ˚ p d ˚ GT qq ´ ψ D p d ˚ u,p , a ˚ p d ˚ u,p qq , for p u, p q P U A ˆ P A , since it reflects the loss in exp ected utility due to choosing d ˚ GT instead of the defense d ˚ u,p asso ciated with the actual judgments. Small v alues of r u,p p d ˚ GT q w ould indicate robustness with respect to the A ttack er’s utilit y and probability: an y pair p u, p q P U A ˆ P A could b e chosen with no significant changes in the attained exp ected utilities and d ˚ GT is th us robust. Otherwise, the relev ance of the prop osed NE defense d ˚ GT should b e 12 criticized given the p otential losses, and further inv estigated. Operationally , a thr eshold indicating a maximum acceptable loss in exp ected utility should b e sp ecified by the decision mak er (as Algorithm 3 sketc hes). input: d ˚ GT , U A , P A , V , thr eshold for i “ 1 to V do Randomly sample u from U A and p from P A Compute d ˚ u,p using Algorithm 2 Compute r u,p p d ˚ GT q if r u,p p d ˚ GT q ą thr eshold then Robustness requiremen t not satisfied Stop Robustness requiremen t satisfied. Algorithm 3: Robustness assessment of solutions for games with complete information Example 1. (c ont.). W e chec k the robustness of d ˚ GT . The optimal defense is computed for 10 , 000 p erturbations of u A p c A q (sampling e 1 „ U p 0 , 2 q and using u 1 A p c A q “ exp p e 1 ˆ c A qq and the probabilit y p A p θ | d, a “ 1 q of successful attac k in the even t of an attac k for eac h d (sampling from a Beta distribution with mean equal to the original v alue and v ariance 0 . 1% of the corresp onding mean for each d ). Figure 4 reflects the frequency 0.0 0.1 0.2 0.3 0.4 4 5 6 7 8 9 Optimal Decision Frequency Figure 4: Sensitivity analysis of the solution of the game with complete information with whic h each d is optimal. The prop osed solution d ˚ GT “ 8 emerges only 25% of the time as optimal. Moreov er, small p erturbations in the utilities and probabilities lead to other optimal solutions: d “ 9 and d “ 7 resp ectiv ely emerge 42% and 16% of the times as optimal. More imp ortantly , large v ariations in optimal exp ected utilities are observ ed, with a maximum regret of 42 . 5% of the total optimal exp ected utilit y . T o sum up, d ˚ GT “ 8 is clearly sensitiv e to c hanges in u A and p A : it is not robust for even relativ ely high regret thresholds for the loss in exp ected utilit y . △ 13 3. Sequen tial games with incomplete information: ARA As Example 1 sho ws, the solutions of games with complete information might not b e robust to p erturbations in the attac ker’s utilities and probabilities. Moreo ver, in man y situations the complete information assumption will not hold. In b oth cases, the problem ma y b e handled through an incomplete information game. The most common approach in such context uses BNE, see Heap and V aroufakis (2004) for details. Alternativ ely , we use a decision analytic approac h based on ARA. Rios and Insua (2012) and Banks et al. (2020) discuss the differences b et w een b oth concepts in, resp ectiv ely , simultaneous and sequen tial games showing that they ma y lead to differen t solutions, with the interesting feature that ARA mitigates the common prior assumption (Antos and Pfeffer, 2010) and pro vides prescriptive supp ort to a decision maker. ARA facilitates the defender to ac knowledge the uncertain ty she migh t hav e ab out p u A , p A q . Her problem is depicted in Figure 5a as an influence diagram, where A ’s action app ears as an uncertaint y . Her exp ected utilit y is ψ D p d q “ ş ψ D p d, a q p D p a | d q d a whic h requires p D p a | d q , her assessment of the probability that the Attac ker will c ho ose a after having observed d . Then, her optimal decision is d ˚ ARA “ arg max d P D ψ D p d q . Example 1 (con t.) b elow shows that it ma y b e d ˚ ARA ‰ d ˚ GT , due to the differences in informational assumptions. Θ D A U D (a) Defender’s decision problem. Θ D A U A (b) Defender analysis of Attac ker problem. Figure 5: Influence diagrams for Defender and A ttack er problems. Eliciting p D p a | d q , with its strategic comp onent, is facilitated b y analyzing A ’s problem from D ’s p ersp ectiv e (Figure 5b). In order to accomplish it, the defender w ould use all information and judgmen t av ailable to her ab out A ’s utilities and probabilities. Ho wev er, instead of using p oin t estimates for u A and p A to find A ’s b est resp onse a ˚ p d q giv en d (Section 2), her uncertain t y ab out the attacks w ould deriv e from modeling p u A , p A q through a distribution F “ p U A , P A q on the space of utilities and probabili- ties. With no loss of generality , assume that U A and P A are defined ov er a common probabilit y space p Ω , A , P q with atomic elemen ts ω P Ω (Ch ung, 2001). This induces a distribution o v er the A ttack er’s exp ected utilit y ψ A p d, a q , where the random exp ected 14 utilit y w ould b e Ψ ω A p d, a q “ ş U ω A p a, θ q P ω A p θ | d, a q d θ . In turn, this induces a random optimal alternativ e defined through A ˚ p d q ω “ arg max x P A Ψ ω A p d, x q . Then, the Defender w ould find p D p a | d q “ P F r A ˚ p d q “ a s “ P t ω : A ˚ p d q ω “ a u in the discrete case (and, similarly in the con tinuous one). Computationally , ARA mo dels entail integration and optimization pro cedures that can b e c hallenging in many cases. Therefore, we explore sim ulation based metho ds. 3.1. Monte Carlo b ase d appr o ach for ARA MC sim ulation approximates p D p a | d q for eac h d , dra wing J samples ␣` u i A , p i A ˘( J i “ 1 from F and making ˆ p D p A ď a | d q “ # t A ˚ p d qď a u J with A ˚ p d q “ arg max a ş u i A p a, θ q p i A p θ | d, a q d θ . In case of multiple b est attack er resp onses, ties are broken via SSE. This is then used as input to the Defender’s exp ected utility maximization, as reflected in Algorithm 4, whic h requires D and A to b e discrete (or discretized to the required precision as shown in Section 4.2). input: J , Q , P for al l d P D do for j “ 1 to J do Sample u j A p a, θ q „ U ω A p a, θ q , p j A p θ | d, a q „ P ω A p θ | d, a q for a P A do Generate samples θ 1 , . . . , θ Q „ p j A p θ | d, a q Appro ximate p ψ j A p d, a q “ 1 Q ř i u j A p a, θ i q Find a ˚ j p d q , via arg max a p ψ j A p d, a q . ˆ p D p a | d q “ 1 J ř J j “ 1 I r a ˚ j p d q “ a s for al l d P D do Generate samples p θ 1 , a 1 q , . . . , p θ P , a P q „ p D p θ | d, a q ˆ p D p a | d q Appro ximate p ψ D p d q “ 1 P ř i u D p d, θ i q Compute p d ˚ ARA “ arg max d p ψ D p d q Algorithm 4: MC based approac h to solv e the t wo-stage sequential defend-attac k ARA mo del Algorithm 4 requires | D | ˆ “ J ˆ p| A | ˆ Q ` 2 q ` 2 P ‰ samples where Q and P are the n umber of samples required to resp ectiv ely appro ximate ş u i A p a, θ q p i A p θ | d, a q d θ and ş ş u D p d, θ q p D p θ | d, a q ˆ p D p a | d q d θ d a to the desired precision. Con vergence follo ws b y applying a uniform version of the SLLN t wice, see SM Section 1.2 for details. In high dimensional or contin uous cases, and when mo del uncertain t y dominates, metho ds that automatically fo cus on high probability-high impact ev ents, as APS do es, would t ypically b e faster and more robust. 15 3.2. A ugmente d pr ob ability simulation for ARA APS solv es the ARA mo del by constructing augmented distributions. T o solve A ’s decision problem, an APS in the space of the A ttack er’s random utilities and prob- abilities is constructed. F or a given d , the random augmented distribution built is Π ω A p a, θ | d q9 U ω A p a, θ q P ω A p θ | d, a q , its marginal Π ω A p a | d q “ ş Π ω A p a, θ | d q d θ b eing pro- p ortional to A ’s random exp ected utility Ψ ω A p d, a q . Then, the random optimal attack A ˚ p d q ω coincides a.s. with the mode of the marginal Π ω A p a | d q . Consequen tly , by sampling u A p a, θ q „ U A p a, θ q and p A p θ | d, a q „ P A p θ | d, a q , one can build π A p a, θ | d q9 u A p a, θ q p A p θ | d, a q whic h is a sample from Π A p a, θ | d q . Then, mo de p π A p a | d qq is a sample of A ˚ p d q , whose dis- tribution is P F r A ˚ p d q ď a s “ p D p A ď a | d q , thus providing a mec hanism to sample from suc h distribution. As b efore, if π A p a | d q has m ultiple global mo des, ties are brok en via SSE to c hose the mo de of interest. Next, using backw ards induction, an augmented distribu- tion for the Defender’s problem is introduced as π D p d, a, θ q9 u D p d, θ q p D p θ | d, a q p D p a | d q . Its marginal π D p d q “ ş ş π D p d, a, θ q d a d θ is proportional to the exp ected utility ψ D p d q and, consequen tly , d ˚ ARA “ mo de p π D p d qq . Th us, one just needs to sample p d, a, θ q „ π D p d, a, θ q and estimate its mo de in d . Algorithm 5 summarizes a nested MH based pro cedure for APS with states ( d , a , θ ) whose stationary distribution is π D p d, a, θ q . Prop osition 2 pro vides conditions for the a.s. con vergence of the output of the Algorithm to the optimal decision d ˚ ARA . Assumptions a), b), c), and d), are similar to those of Prop osition 1, hence are not rep eated. Prop osition 2. Assume that u D and the utilities in the supp ort of U A (a.s.) satisfy c ondition a); A and D satisfy c ondition b); p D p θ | d, a q and the distributions in the supp ort of P A p θ | d, a q (a.s.) satisfy c ondition c); the pr op osal gener ating distributions g A and g D , satisfy c ondition d); and the A ttacker’s b est r esp onse set is finite for every p u A , p A q P U A ˆ P A . Then, Algorithm 5 defines a Markov chain with stationary distribution π D p d, θ , a q . Mor e over, a c onsistent mo de estimator b ase d on the mar ginal samples of d fr om this Markov chain a.s. appr oximates d ˚ ARA . Algorithm 5 requires generating N ˆ p 2 M ` 5 q ` 2 M ` 4 samples from multiv ariate distributions, in addition to the cost of the conv ergence chec ks and mo de computations, where M and N are the num b er of MCMC iterations for the attack er and defender’s APS, respectively . W e emphasize that this algorithm remov es the need for lo ops o ver A and D , and can be applied to contin uous decision sets without discretizing. Finally , note that it ma y b e b eneficial to combine MC and APS in some discrete cases. F or instance, if | D | is lo w, it is conv enient to use MC to estimate p D p a | d q for eac h d b y 16 function sample attack( d , M , K , g A , U A , P A ) : initialize : a p 0 q Dra w u A p a, θ q „ U A p a, θ q Dra w p A p θ | d, a q „ P A p θ | d, a q Dra w θ p 0 q „ p A p θ | d, a p 0 q q for i “ 1 to M do Ź Inner APS Prop ose new attac k ˜ a „ g A p ˜ a | a p i ´ 1 q q Dra w ˜ θ „ p A p θ | d, ˜ a q Ev aluate acceptance probabilit y α “ min " 1 , u A p ˜ a, ˜ θ q ¨ g A p a p i ´ 1 q | ˜ a q u A p a p i ´ 1 q ,θ p i ´ 1 q q ¨ g A p ˜ a | a p i ´ 1 q q * With probabilit y α set p a p i q , θ p i q q “ p ˜ a, ˜ θ q . Otherwise, set p a p i q , θ p i q q “ p a p i ´ 1 q , θ p i ´ 1 q q . Discard first K samples and compute a ˚ p d q based one the mo de(s) of the remaining dra ws t a p K ` 1 q , ..., a p M q u . return a ˚ p d q input: d , U A , P A , M , K , N , R , g D and g A prop osal distributions initialize : d p 0 q “ d Dra w a p 0 q „ p A p a | d p 0 q q using sample attack( d p 0 q , M , K , g A , U A , P A ) Dra w θ p 0 q „ p D p θ | d p 0 q , a p 0 q q for i “ 1 to N do Ź Outer APS Prop ose new defense ˜ d „ g D p ˜ d | d p i ´ 1 q q Dra w ˜ a „ p A p a | ˜ d q using sample attack( ˜ d , M , K , g A , U A , P A ) Dra w ˜ θ „ p D p θ | ˜ d, ˜ a q Ev aluate acceptance probabilit y α “ min " 1 , u D p ˜ d, ˜ θ q ¨ g D p d p i ´ 1 q | ˜ d q u D p d p i ´ 1 q ,θ p i ´ 1 q q ¨ g D p ˜ d | d p i ´ 1 q q * With probabilit y α set p d p i q , a p i q , θ p i q q “ p ˜ d, ˜ a, ˜ θ q . Otherwise, set p d p i q , a p i q , θ p i q q “ p d p i ´ 1 q , a p i ´ 1 q , θ p i ´ 1 q q . Discard first R samples and estimate mo de from the rest of dra ws t d p R ` 1 q , ..., d p N q u as p d ˚ ARA Record p d ˚ ARA . Algorithm 5: MH based APS to approximate ARA solution in the t wo-stage sequen tial defend-attack game. dra wing J samples a „ p D p a | d q and counting frequencies as in Section 3.1. Using direct samples from this estimate, ˆ p D p a | d q , instead of inv oking the attack er’s APS could b e more efficien t for retrieving samples from a „ p D p a | d q within the Defender’s APS. Example 1 (Cont.). Complete information is no longer a v ailable. D ’s beliefs ov er A ’s judgmen ts are describ ed through P A and U A . Assume A ’s random probability of success is mo deled as P A p θ “ 1 | d, a “ 1 q „ B eta p α d , β d q with α d and β d in T able 1d (with p D p θ “ 1 | d, a q in T able 1b as exp ected v alues). In addition, A ’s risk co efficient e is uncertain, with e „ U p 0 , 2 q , inducing the random utilit y U A p c A q . In this case, for 17 0.00 0.25 0.50 0.75 1.00 0 1 2 3 4 5 6 7 8 9 d p D (a|d) a 0 1 (a) MC estimation of p D p a | d q 0.00 0.25 0.50 0.75 1.00 0 1 2 3 4 5 6 7 8 9 d p D (a|d) a 0 1 (b) APS estimation of p D p a | d q Figure 6: Estimation of p D p a | d q through ARA 0 5 10 15 0.0 2.5 5.0 7.5 Optimal Decision Expected Utility (a) MC solution 0.00 0.04 0.08 0.12 0 1 2 3 4 5 6 7 8 9 Optimal Decision Frequency (b) APS solution Figure 7: ARA solutions for the Defender APS, as the cardinality of D is small, one can estimate the v alue of p D p a | d q for eac h d . Figure 6 presents the estimates ˆ p D p a | d q , obtained using MC and APS, whic h app ear quite similar: the maximum absolute difference b et ween MC and APS estimates is less than 0 . 01. Next, the ARA solution is computed. Figure 7a shows the MC estimation of her exp ected utility; Figure 7b presents the frequency of samples from the marginal π D p d q . Its mo de coincides with the optimal defense, d ˚ ARA “ 9, in agreement with the MC solution. Observe that in this case the ARA decision d ˚ ARA differs from the game-theoretic solution d ˚ GT , the informational assumptions b eing differen t: the ARA decision app ears to b e more conserv ative, as it suggests a safer but more expensive defense. SM Section 4.2 replicates the exp eriment dividing α d and β d b y 100 in T able 1d, th us inducing more uncertaint y about the attack er’s probabilities. The ARA solution ( d ˚ ARA “ 9) remains stable despite these changes. △ 3.3. Sensitivity analysis of the ARA solution The ARA approach leads to a decision analysis problem with the p eculiarit y of including a sampling pro cedure to forecast A ’s actions. A sensitivit y analysis should b e conducted with resp ect to its inputs p u D p d, θ q , p D p θ | d, a q , p D p a | d qq , with fo cus on p D p a | d q , the most conten tious one as it comes from adversarial calculations based on 18 the random ingredients U A and P A . W e w ould pro ceed as has b een done in Section 2.3 ev aluating the impact of the imprecision on U and P o ver the attained exp ected utilit y ψ p d ˚ U P ARA q using classes U A , P A of random utilities and probabilities; for each feasible p U, P q , p U P D p a | d q w ould b e obtained to compute d ˚ U P ARA , estimating then the maxim um regret. 4. Computational assessmen t This section discusses computational complexity results, emphasizing the adv an tages of APS in large scale game-theoretic settings. 4.1. Computational c omplexity T able 2 summarizes the computational complexit y of MC and APS for solving games with complete and incomplete information. Recall that parameters P , Q , N and M w ould typically dep end on the desired precision, as outlined in SM (Section 1.1). T able 2: MC and APS required sample sizes for games with complete and incomplete information MC APS Complete | D | ˆ p| A | ˆ Q ` P q N ˆ p 2 M ` 3 q ` 2 M ` 2 Incomplete | D | ˆ r J ˆ p| A | ˆ Q ` 2 q ` 2 P s N ˆ p 2 M ` 5 q ` 2 M ` 4 Con tinuous decision spaces need to be discretized to approximate the MC solution, as Section 4.2 illustrates. The discretization step impacts the solution precision and the cardinalities of D and A whic h, in turn, affect complexit y . In contrast, APS do es not discretize the decision sets. As T able 2 shows, the num b er of MC samples dep ends on the cardinality of the Defender’s and Attac ker’s decision spaces, whereas this dep endence is not present in APS. Thus, this approac h would b e exp ected to b e more efficient than MC for problems with large decision spaces as sho wcased in the following subsection. 4.2. A c omputational c omp arison A simple game with con tinuous decision spaces serves to compare the scalability of the prop osed approaches. The agents make their respective decisions d, a P r 0 , 1 s concerning the prop ortion of resources inv ested to defend and attack a serv er whose v alue is s . Let θ b e the prop ortion of losses for the defender under a successful attack, mo deled with a Beta distribution with parameters α p d, a q and β p d, a q , with α ( β ) increasing in a ( d ) and decreasing in d ( a ). D ’s pa yoff is f p d, θ q “ p 1 ´ θ q ˆ s ´ c ˆ d , where c denotes her unit resource cost. She is constant risk a verse with utilit y strategically equiv alent 19 to 1 ´ exp p´ h ˆ f p d, θ qq , h ą 0. A ’s pa yoff is g p a, θ q “ θ ˆ s ´ e ˆ a , where e denotes A ’s unit resource cost. He is constant risk prone with utilit y strategically equiv alent to exp p´ k ˆ g p a, θ qq , k ą 0. Figure 8 provides MC estimates of D ’s exp ected utility , which is arguably flat around the optimal defense. T o increase efficiency of APS in detecting the mo de, we replace the marginal augmented distribution π D p d | a ˚ p d qq b y its p o wer transformation π H D p d | a ˚ p d qq (with H designated augmentation p ar ameter ) to make the distribution more p eaked around the mo de (M ¨ uller, 2005). This underlines another adv antage of APS o ver MC, as it impro ves the efficiency of direct MC sampling from flat regions. SM Section 2.2 presen ts details and sketc hes a conv ergence pro of. Sampling from π H D p d | a ˚ p d qq can b e p erformed using Algorithm 2 dra wing H copies of ˜ θ , instead of just one. The acceptance probabilit y for D ’s problem at a given iteration would b e min " 1 , ś H t “ 1 u D p ˜ d, ˜ θ t q u D p d p i ´ 1 q ,θ p i ´ 1 q t q * , (Section 2.2). A ’s problem includes a similar augmen tation. The augmen tation parameters for A and D will b e designated inner and outer p o wers, respectively . 0.00 0.25 0.50 0.75 0.00 0.25 0.50 0.75 1.00 Defender's Decision Defender's Expected Utility Figure 8: Defender’s exp ected utility surface. Optimal decision in y ellow. T o solv e this problem with MC, the decision sets m ust b e discretized. The chosen discretization step will affect the solution precision as w ell as the cardinalit y of the (discretized) decision spaces, th us affecting MC p erformance. F or instance, to get a solution with precision 0 . 1, we discretize D through d “ t 0 , 0 . 1 , 0 . 2 , ..., 1 u P D , and the cardinalities of the decision spaces are | D | “ | A | “ 11. With precision 0 . 01, | D | “ | A | “ 101, and so on. In contrast, APS do es not require discretizing. T o deal with con tin uous decision sets, all w e need is to use contin uous prop osals g D and g A in Algorithm 5. In this example, we use uniform distributions. Let us inv estigate the trade-off b et w een precision and sample size, finding a threshold b ey ond which APS (MC) is faster for greater (smaller) precision. T o do so, the minimum n umber of required MC and APS samples to achiev e an optimal decision within a giv en precision are computed for b oth A and D problems, resp ectiv ely designated as inner and outer samples. In addition, for APS, w e also rep ort the inner and outer p o wers 20 used to achiev e that precision. F or fair comparison, this study conducts several parallel replications of MC and APS with an increasing num b er of samples. When 90% of the solutions coincide with the optimal decision (computed with MC using a large num b er of samples) with the required precision, the algorithm is declared to hav e c onver ge d for such n um b er of iterations. Using this num b er of iterations, the time employ ed to compute the optimal decision is recorded. T able 3: Computational time, minim um num b er of required MC and APS samples and augmen tation parameters at optimalit y for differen t precisions Samples P ow er Precision Algorithm Outer Inner Outer Inner Time (s) 0.1 MC 1000 100 - - 0.007 APS 60 100 900 20 0.240 0.01 MC 717000 100 - - 13.479 APS 300 100 6000 100 2.461 T able 3 presents MC and APS computational times for precisions 0 . 1 and 0 . 01, using a serv er no de with 16 cores Intel(R) Xeon(R) CPU E5-2640 v3 @ 2.60GHz. Computational runs show the need for only 1 , 000 and 100 MC samples to, resp ectively , reac h optimality to solve D and A problems with precision 0 . 1: MC outp erforms APS. Ho wev er, the p erformance of MC diminishes for higher precision. F or instance, for precision 0 . 01, APS outp erforms MC. Indeed, for MC, there is a factor of 200 b etw een the time needed to obtain the solutions with precision 0.01 and 0.1. F or APS, this factor is just 10, suggesting that it scales m uch b etter with precision. F or smaller precision, such as 0 . 001, we could not get a stable solution using MC even with a large num b er of samples ( P “ 10M, Q “ 100k). Finally , Figure 8 suggests that as the exp ected utilit y is flat around the optimal decision, MC will require a high num b er of samples to resolv e the maxim um. F or cases like this, APS is ev en more con venien t, as it enables sampling from the transformed marginal augmen ted distribution, more p eaked around the mo de than the initial distribution. 5. A cyb ersecurit y application W e consider a cyb ersecurit y case which illustrates the prop osed framew ork in a real w orld setting. It simplifies the example in Rios Insua et al. (2021) by retaining only the adv ersarial cyb er threat. The complexities of applications are apparen t when observing the bi-agen t influence diagram in Figure 9, which has additional uncertain ty nodes b ey ond those in our template in Figure 1. An organisation ( D ) faces a comp etitor ( A ) 21 that ma y attempt distributed denial of service (DDoS) attacks to undermine D ’s site a v ailability and compromise her customer services. Security controls s Competitor attack a | s Security controls cost c s | s T otal costs c d Defender utility u D ( c d ) Duration DDoS p ( l | a, s ) Detection of attacker p ( t | a ) Impact on market share p ( m | l ) Costs when detected p ( c t | t ) Attacker earnings e | m Result of the attack c a Attacker utility u A ( c a ) Figure 9: Bi-agent influence diagram of the cybersecurity application. D has to determine the subscription lev el to a monthly cloud-based DDoS protection system, with choices 0 (not subscribing), 5 , 10 , . . . , 190 , and 195 gbps. A m ust decide the in tensity of his DDoS attac k, viewed as the num b er of da ys (from 0 to 30) that he will attempt to launch it. The duration of the DDoS may impact D ’s mark et share, due to reputational loss. A gains all market share lost by D , whic h determines his earnings. Ho wev er, he runs the risk of b eing detected with significant costs. Both agents aim at maximizing exp ected utilit y . Details of the mo dels at v arious no des are in SM Section 5. This is a problem with incomplete information and large decision spaces. W e compute the ARA solution using APS. W e first estimate the probabilities p D p a | d q for eac h defense d . W e replace A ’s marginal augmented distribution π A b y its p ow er transformation π H A to increase APS efficiency in finding the mo de. In addition, as in simulated annealing, within eac h APS iteration w e increase H using an appropriate co oling schedule (M ¨ uller et al., 2004), see SM Section 2.2 for details. Figure 10a displays p D p a | d q for four defenses p 0 , 5 , 10 , 15 q . If no defensive action is adopted ( d “ 0), A will launc h the longest DDoS attac k. Subscribing to a low protection plan ( d “ 5) makes little practical difference. Ho wev er, when increasing the protection to 10 gbps, the attac k forecast (from D ’s p erspective) b ecomes a mixture of high and lo w intensit y v alues: small p erturbations in D ’s assumptions ab out A ’s elements, induce big changes in the optimal attac k. Finally , a 22 15 gbps protection convinces D that she should av oid the attac k, attaining a deterrence effect. The optimal solution remains the same for d ą 15. 10 15 0 5 0 3 6 9 12 15 18 21 24 27 30 0 3 6 9 12 15 18 21 24 27 30 0.00 0.25 0.50 0.75 1.00 0.00 0.25 0.50 0.75 1.00 Attacker's Decision p(a|d) (a) Attac k intensit y for each decision 0.00 0.01 0.02 0 50 100 150 200 Defender's Decision Frequency (b) APS solution of the Defender problem Figure 10: ARA solution computed using APS Figure 10b shows a histogram of the APS samples for D ’s decision. As exp ected, the frequency of samples with v alue 15 is similar to the ones with higher v alues. The histogram (and consequen tly the exp ected utility surface) is very flat. Finding the exact optimal decision might not b e crucial since the exp ected utilities for differen t protections are close. How ever, it should b e noted that APS permits finding the optimal solution b y sampling from a p ow er transformation of the marginal augmented distribution, even with flat exp ected utilities, at a relatively small extra computational cost. This emphasizes another adv antage of APS: the pro vision of the distribution π D p d | a ˚ p d qq as part of the solution, deliv ering sensitivit y analysis at no extra cost. The decision maker ma y w ant to tak e such sensitivity of the optimal decision into account, and consider a defense which could b e more robust. Thus, as with A ’s problem, we sample iteratively , increasing the p o w er H of D ’s marginal augmented distribution at eac h iteration. Figure 11 illustrates ho w increasing H mak es the distribution more p eak ed around the optimal decision d ˚ ARA “ 15, the cheapest plan that av oids the attack from D ’s p ersp ectiv e. 0.00 0.05 0.10 0.15 0.20 0 50 100 150 200 Defender's Decision Frequency H = 1500 (a) 0.0 0.2 0.4 0.6 0 50 100 150 200 Defender's Decision Frequency H = 8500 (b) Figure 11: APS solutions of defender’s problem for different augmen tation parameter v alues 23 6. Discussion This pap er considers pro viding robust supp ort to a decision mak er facing adv ersaries in an environmen t where random consequences dep end on the actions of all participan ts: w e prop ose a framew ork that computes a game-theoretic solution under assumptions of complete information and p erform a sensitivit y analysis; if the solution is stable, it ma y b e used with confidence and no further analysis is required. Otherwise, or when complete information is actually lacking, we use ARA as a decision analytic approach that mitigates common prior ass umptions. If such solution is stable, one ma y use it with confidence and stop the analysis. Otherwise, one must refine the relev ant probabilit y and utilit y classes, even tually declaring the robustness of the ARA solution. If the solution is not robust, one could undertak e a minimum regret or other (robust) analysis. W e hav e pro vided MC and APS metho ds to supp ort this process. With large, discrete decision spaces, APS w ould b e more efficien t as its complexit y do es not dep end on the decision sets’ cardinalities. In addition, APS do es not need discretization and can be directly applied to problems with con tin uous decision sets, for which MC may not provide feasible solutions at the desired precision. It should also b e noted that MC errors asso ciated with appro ximating the exp ected utilit y could ov erwhelm the calculation of the optimal decision. Samples from p p θ | d, a q will typically need to b e recomputed for eac h pair p d, a q . In contrast, APS performs the exp ectation and optimization simultaneously , sampling d from regions with high utilit y with draws of θ from the utilit y-tilted augmen ted distribution. This reduces the MC error as the optimization effort in parts of the parameter space with low utility v alues is limited, resulting in reduced sample sizes for the same precision. Besides, when the exp ected utilit y surface is flat, MC simulation may need man y draws or result in p o or estimates, b eing also inefficient for random v ariables with skew ed distributions. APS b etter handles those cases as it is based on sampling from the optimizing p ortions of the decision space; moreov er, it can sample from a p ow er transformation of the marginal augmented distribution, more p eaked around the mo de. APS also provides sensitivity analysis at no extra computational cost. T o keep the discussion concise, we illustrated the prop osed framework with tw o stage (defend-attac k) games, although it extends to m ulti-stage sequen tial games with complete or incomplete information. F or instance, for the sequential defend-attack game with complete information, we pro ved that finding Nash equilibria is equiv alent to finding the mo de of the marginal Defender’s augmen ted distribution that uses the Attac ker’s APS output. This setup extends to solving n -stage sequen tial games by nesting n APS algorithms (details in Section 3). Similarly , the prop osed framew ork is conceptually 24 applicable to multi-stage games with incomplete information as w ell (Section 4 of the SM). While extensions to n -stage games are technically viable, from a computational p erspective they w ould suffer from the standard inefficiencies of dynamic programming. Th us, for a large num b er of stages, it may b e worth exploring reinforcemen t learning based strategies (Po w ell, 2019). Ov erall, multi-stage sequen tial games w ould b enefit from further illustration and computational exp eriments, which are left for future research. Moreo ver, extensions to sim ultaneous defend-attack games and the generic defend-attack in teractions in the general bi-agent influence diagrams in Gonz´ alez-Ortega et al. (2019) could b e considered for securit y applications. Regarding algorithmic asp ects, there is relev ant future w ork. W e ha ve explored MC and APS as techniques to appro ximate Nash and ARA solutions in sequential t wo-stage games. W e highligh t that although we hav e used APS with MH, other MCMC samplers could b e used. F urthermore, as men tioned, MC and APS may not b e the b est c hoices for sp ecific settings, and it would b e w orth exploring extensions of existing sim ulation optimization metho ds (Nelson et al., 2001). Nav eiro and Insua (2019) prop ose a metho dology to solve Stac kelberg games with certain outcomes and contin uous decision sets where gradient information ab out the utilities and probabilities is av ailable. This w ork could b e extended to games with uncertain outcomes, by using Hamiltonian Mon te Carlo (HMC) tec hniques (Bishop, 2006) in place of our MH algorithms. In the last decade, game-theoretic mo dels hav e gained imp ortance in AML (R ´ ıos Insua et al., 2020). Efficient scalable algorithmic approaches to solve typical games app earing in this new context are essential. In addition, the ARA solution of suc h games turn to b e imp ortant, as common knowledge assumptions rarely hold in AML. Thus, this pap er w ould contribute to that end, prop osing a no v el sim ulation based approac h to solv e sequential defend-attack games b oth from the classic and the ARA p ersp ectiv es. A cknow le dgements. T.E. ackno wledges the supp ort of T exas State Universit y through Stev en R. “Stev e” Gregg Endow ed Professorship and Presidential Research Leav e Aw ard. R.N. ackno wledges supp ort of the Spanish Ministry of Education for his FPU15-03636 grant. D.R.I. is grateful to the MTM2017-86875-C3-1-R AEI/FEDER EU pro ject, the AXA-ICMA T Chair in ARA and the EU’s Horizon 2020 pro ject 740920 CYBECO. This material is based up on work supp orted b y the Air F orce Scientific Office of Research (AF OSR) aw ard F A-9550-21-1-0239, AFOSR European Office of Aerospace Researc h and Developmen t aw ard F A8655-21-1-7042 and w as partially supp orted b y the National Science F oundation under Grant DMS-1638521 to the SAMSI, and the AMALFI BBV A F oundation pro ject. 25 References Amaran, S., Sahinidis, N.V., Sharda, B., Bury , S.J., 2016. Simulation optimization: a review of algorithms and applications. Annals of Op erations Research 240, 351–380. An tos, D., Pfeffer, A., 2010. Represen ting Bay esian games without a common prior, in: v an der Ho ek, Kanink a, L., Sen (Eds.), Pro c. AAMAS 2010. IF AMAS. Banks, D., Gallego, V., Nav eiro, R., Rios Insua, D., 2020. Adv ersarial risk analysis: An o verview. Wiley In terdisciplinary Reviews: Computational Statistics 14, e1530. Banks, D.L., Aliaga, J.R., Insua, D.R., 2015. Adversarial Risk Analysis. CR C Press. Bard, J.F., 1991. Some prop erties of the bilev el programming problem. Journal of optimization theory and applications 68, 371–378. Bielza, C., M ¨ uller, P ., Insua, D.R., 1999. Decision analysis by augmented probability sim ulation. Management Science 45, 995–1007. Bishop, C.M., 2006. Pattern recognition and machine learning. Springer. Bro oks, S.P ., Rob erts, G.O., 1998. Assessing c on vergence of Mark o v chain Monte Carlo algorithms. Statistics and Computing 8, 319–335. Bro wn, G., Carlyle, M., Salmer´ on, J., W o od, K., 2006. Defending critical infrastructure. In terfaces 36, 530–544. Chacon, J., 2020. The mo dal age of statistics. In ternational Statistical Review 88, 122–141. Chen, Y., Genov ese, C., W asserman, L., 2016. A comprehensive approac h to mode clustering. Electronic Journal of Statistics 10, 210–241. Chib, S., Green b erg, E., 1995. Understanding the Metrop olis-Hastings algorithm. The American Statistician 49, 327–335. Ch ung, K.L., 2001. A Course in Probabilit y Theory . Ac Press. Ekin, T., Polson, N.G., So yer, R., 2014. Augmen ted Marko v c hain Monte Carlo sim ulation for t wo-stage sto c hastic programs with recourse. Decision Analysis 11, 250–264. Ekin, T., Polson, N.G., So yer, R., 2017. Augmented nested sampling for sto chastic programs with recourse and endogenous uncertaint y . Nav al Research Logistics (NRL) 64, 613–627. 26 Ekin, T., W alker, S., Damien, P ., 2020. Augmen ted simulation metho ds for discrete sto c hastic optimization with recourse. Annals of Op erations Research , 1–23. F otakis, D., Rios Insua, D., 2021. Algorithmic Decision Theory . v olume 13023. Springer. F renc h, S., Insua, D.R., 2000. Statistical decision theory . Wiley . F u, M.C., 2015. Handb o ok of sim ulation optimization. volume 216. Springer. Gamerman, D., Lop es, H.F., 2006. Marko v c hain Monte Carlo: Sto c hastic simulation for Ba yesian inference. Chapman and Hall/CRC. Gonz´ alez-Ortega, J., Insua, D.R., Cano, J., 2019. Adversarial risk analysis for bi-agen t influence diagrams: An algorithmic approach. Europ ean Journal of Op erational Researc h 273, 1085–1096. Gordon, G., Tibshirani, R., 2012. Karush-Kuhn-Tuck er conditions. Optimization 10, 725. Harsan yi, J., 1967. Games with incomplete information play ed b y Bay esian play ers. Managemen t Science 14, 159–182. Heap, S.H., V aroufakis, Y., 2004. Game Theory . Routledge. Insua, D.R., 1990. Sensitivity Analysis in Multiob jectiv e Decision Making. Springer V erlag. Insua, D.R., Ruggeri, F., 2012. Robust Bay esian Analysis. volume 152. Springer Science & Business Media. Jennric h, R., 1969. Prop erties on non-linear least squares estimators. Annals of Mathematical Statistics 40, 633–643. Jeroslo w, R.G., 1985. The p olynomial hierarch y and a simple mo del for comp etitiv e analysis. Mathematical programming 32, 146–164. Johanson, M., Bard, N., Lanctot, M., Gibson, R.G., Bowling, M., 2012. Efficien t Nash equilibrium appro ximation through Monte Carlo counterfactual regret minimization, in: AAMAS, pp. 837–846. Keeney , R., 2007. Mo deling v alues for an ti-terrorism analysis. Risk Analysis 27, 585–596. 27 Korzh yk, D., Conitzer, V.and Parr, R., 2010. Stack elb erg vs. Nash in security games: An extended inv estigation of in terc hangeability , equiv alence, and uniqueness. Pro c. 24th AAAI Conf. , 805–810. Korzh yk, D., Yin, Z., Kiekintv eld, C., Conitzer, V., T am b e, M., 2011. Stac kelberg vs. Nash in security games: An exte nded inv estigation of interc hangeability , equiv alence, and uniqueness. Jour. Art. Intell. Res. 41, 297–327. Leitmann, G., 1978. On generalized Stack elb erg strategies. Jour. Optim. Theory Appl. 26, 637–643. M ¨ uller, P ., 2005. Simulation based optimal design. Handb o ok of Statistics 25, 509–518. M ¨ uller, P ., Sans´ o, B., De Iorio, M., 2004. Optimal Bay esian design by inhomogeneous Mark ov chain simulation. Journal of the American Statistical Asso ciation 99, 788–798. Na veiro, R., Insua, D.R., 2019. Gradient metho ds for solving Stack elb erg games, in: In ternational Conference on Algorithmic DecisionTheory , Springer. pp. 126–140. Nelson, B.L., Swann, J., Goldsman, D., Song, W., 2001. Simple pro cedures for selecting the b est sim ulated system when the n umber of alternatives is large. Op erations Researc h 49, 950–963. Nisan, N., Roughgarden, T., T ardos, E., V azirani, V.V., 2007. Algorithmic Game Theory . v olume 1. Cambridge Univ ersit y Press Cambridge. P onsen, M., de Jong, S., Lanctot, M., 2011. Computing approximate Nash equilibria and robust b est responses using sampling. Journal of AI Researc h 42, 575–605. P ow ell, W.B., 2019. A unified framework for sto c hastic optimization. Europ ean Journal of Op erational Researc h 275, 795–821. Rios, J., Insua, D.R., 2012. Adversarial risk analysis for counterterrorism mo deling. Risk Analysis 32, 894–915. Rios Insua, D., Couce-Vieira, A., Rubio, J.A., Pieters, W., Labunets, K., G. Rasines, D., 2021. An adv ersarial risk analysis framework for cyb ersecurit y . Risk Analysis 41, 16–36. doi: DOI:10.1111/risa.13331 . R ´ ıos Insua, D., Na veiro, R., Gallego, V., P oulos, J., 2020. Adv ersarial Ma- c hine Learning: P ersp ectiv es from adversarial risk analysis. arXiv e-prin ts , arXiv:1908.06901. 28 Romano, J.P ., 1988. On w eak conv ergence and optimalit y of k ernel density estimates of the mo de. The Annals of Statistics , 629–647. Shao, J., 1989. Mon te Carlo approximations in Ba yesian decision theory . Journal of the American Statistical Asso ciation 84, 727–732. Sinha, A., F ang, F., An, B., Kiekintv eld, C., T ambe, M., 2018a. Stack elb erg security games: lo oking b ey ond a decade of success. Proc. IJCAI-18 , 5494–5501. Sinha, A., Malo, P ., Deb, K., 2018b. A review on bilevel optimization: from classical to ev olutionary approaches and applications. IEEE T ransactions on Evolutionary Computation 22, 276–295. Smith, A.F., Rob erts, G.O., 1993. Ba y esian computation via the Gibbs sampler and related Mark ov chain Monte Carlo metho ds. Journal of the Roy al Statistical So ciety: Series B (Metho dological) 55, 3–23. v on Stack elb erg, H., 1952. The Theory of the Market Econom y . Oxford U.P . T orres-Barr´ an, A., Nav eiro, R., 2019. Augmen ted Probabilit y Simulation. https: //github.com/albertotb/aps . Y u, H., Tseng, H.E., Langari, R., 2018. A human-lik e game theory-based con troller for automatic lane changing. T ransp ortation Researc h Part C: Emerging T ec hnologies 88, 140–158. Zh uang, J., Bier, V.M., 2007. Balancing terrorism and natural disasters—defensive strategy with endogenous attac ker effort. Operations Research 55, 976–991. Acron yms AI Artificial In telligence AML Adv ersarial machine learning APS Augmen ted probability simulation ARA Adv ersarial risk analysis BNE Ba yes Nash equilibrium DDoS Distributed denial of service HMC Hamiltonian Mon te Carlo MC Mon te Carlo MCMC Mark ov chain Monte Carlo MH Metrop olis Hastings NE Nash equilibrium NP Non-deterministic p olynomial time SLLN Strong la w of large num b ers SM Supplemen tary Material SSE Strong Stac kelberg equilibrium 29 App endix A. Pro ofs of Prop ositions Pr op osition 1 : F or a fixed d , given the assumptions ab out u A and p A , ψ A p a, d q is con tinuous in a and, since A is compact, there exists a ˚ p d q “ arg max a P A ψ A p a, d q , which is contin uous in d . Moreov er, π A p a, θ | d q9 u A p a, θ q p A p θ | d, a q is well-defined. Using Smith and Rob erts (1993) conv ergence results for MH algorithms, the samples generated by the inner APS lo op in Alg.2 define a Mark ov c hain with π A p a, θ | d q as stationary distribution. Once con vergence is detected, the remaining M ´ K marginal samples a p i q of the c hain are appro ximate samples from π A p a | d q . Then, for a large enough M ´ K , a consisten t sample mo de estimator, in the sense of Chen et al. (2016), based on suc h approximate sample detects a ˚ p d q a.s., from whic h we select the desired mo de. Next, under the stated conditions, and taking into account the contin uity of a ˚ p d q in d , ψ D p d, a ˚ p d qq is contin uous in d . Since D is compact, there exists d ˚ GT . Besides, π D p d, θ | a ˚ p d qq9 u D p d, θ q p D p θ | d, a ˚ p d qq is w ell-defined. The samples generated b y the outer APS in Algorithm 2 define a Marko v chain with π D p d, θ | a ˚ p d qq as stationary distribution. Once con vergence is detected, the remaining N ´ R marginal samples d p i q constitute an appro ximate sample from π D p d | a ˚ p d qq . Then, a consistent sample mo de estimator a.s. conv ergen t to d ˚ GT ma y b e built (Chen et al., 2016), b y selecting the appropriate mo de, facilitated, if wished, b y the p eaking tric k. △ Pr op osition 2 : F or eac h d and ω P Ω, giv en the assumptions ab out U A p a, θ q , P A p θ | d, a q and A , w e ha ve: 1) Ψ ω A p d, a q “ ş U ω A p a, θ q P ω A p θ | d, a q is a.s. con tin uous in a ; 2) there exists A p d q ˚ ω “ arg max Ψ ω A p d, a q a.s. which is con tinuous in d ; 3) the distribution Π ω A p a, θ | d q 9 U ω A p a, θ q P ω A p θ | d, a q is well defined. The samples generated through the sample attack function are distributed according to p D p a | d q . By construction, through sampling u A p a, θ q „ U A p a, θ q and p A p θ | d, a q „ P A p θ | d, a q , one can build π A p a, θ | d q9 u A p a, θ q p A p θ | d, a q , which is a sample from Π A p a, θ | d q . F ollowing an ar- gumen t similar to that of Prop osition 1, the a samples generated through the MH routine in sample attack define a Mark ov c hain whose stationary distribution is π A p a, θ | d q „ Π A p a, θ | d q . Once conv ergence is detected, a consistent estimator of the mo des of the a samples can b e built which conv erges a.s. to mo de p π A p a | d qq , whose distribution is P F r A ˚ p d q ď a s “ p D p A ď a | d q . As D is compact and ψ D p d q is contin uous, d ˚ ARA exists. Since u D is p ositiv e and in tegrable, π D p d, a, θ q9 u D p d, θ q p D p θ | d, a q p D p a | d q is well-defined, and is the stationary distribution of the MH Marko v chain of the outer APS routine in Algorithm 5. Once con vergence is detected, the marginal samples in d are approximately distributed as π D p d q , from which we approximate a.s. d ˚ ARA through a consistent mo de estimator. △ 30
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment