Domain Adversarial for Acoustic Emotion Recognition
The performance of speech emotion recognition is affected by the differences in data distributions between train (source domain) and test (target domain) sets used to build and evaluate the models. This is a common problem, as multiple studies have s…
Authors: Mohammed Abdelwahab, Carlos Busso
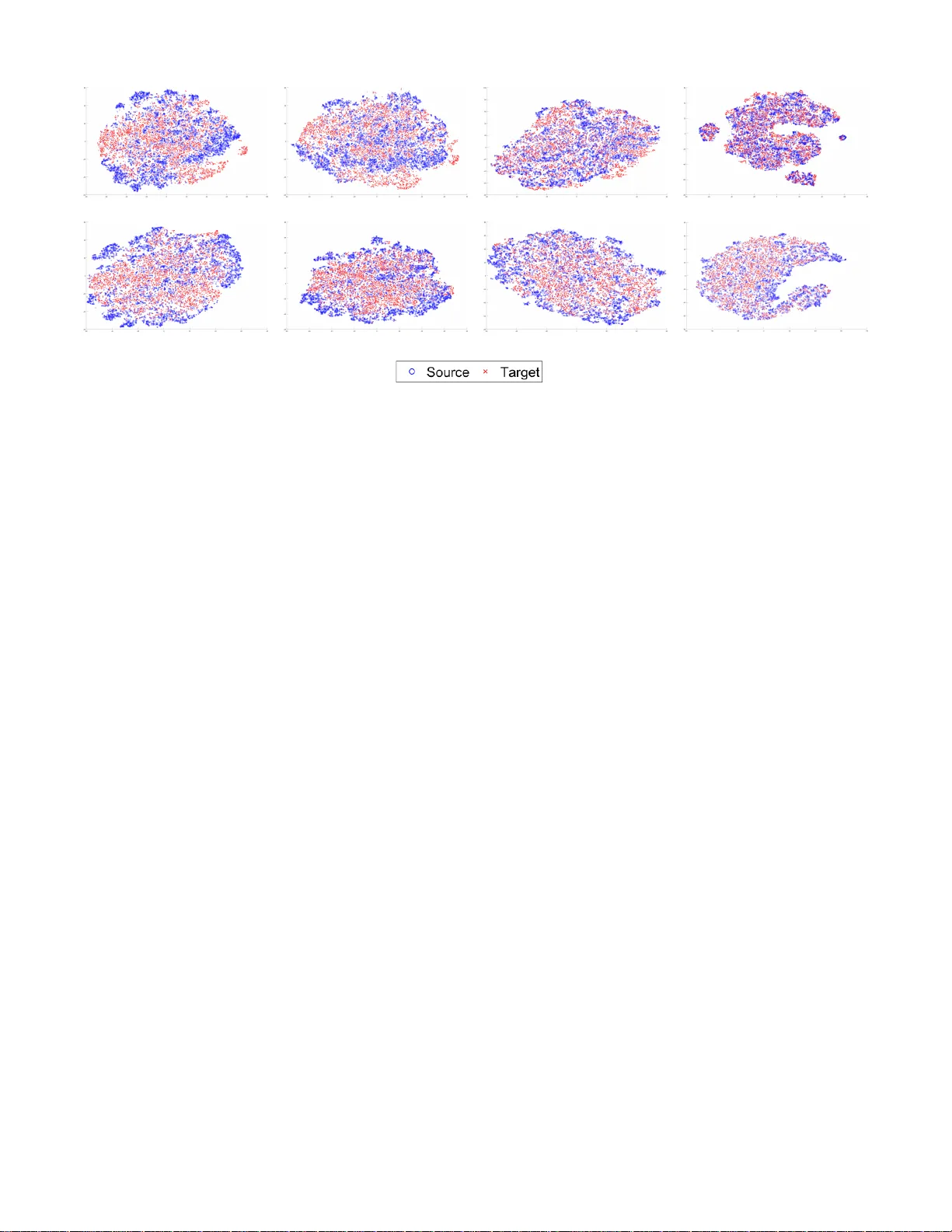
IEEE TRANSA CTIONS ON A UDIO, SPEECH AND LANGU A GE PR OCESSING, V OL. XX, NO. XX, MARCH 2018 1 Domain Adv ersarial for Acoustic Emotion Recognition Mohammed Abdelwahab, Student Member , IEEE, and Carlos Busso, Senior Member , IEEE Abstract —The performance of speech emotion recognition is affected by the differences in data distrib utions between train (source domain) and test (target domain) sets used to build and evaluate the models. This is a common problem, as multiple studies ha ve shown that the performance of emotional classifiers drop when they are exposed to data that does not match the distribution used to build the emotion classifiers. The difference in data distributions becomes v ery clear when the training and testing data come from different domains, causing a large performance gap between validation and testing performance. Due to the high cost of annotating new data and the abundance of unlabeled data, it is crucial to extract as much useful information as possible from the available unlabeled data. This study looks into the use of adversarial multitask training to extract a common repr esentation between train and test domains. The primary task is to pr edict emotional attribute-based descriptors f or ar ousal, valence, or dominance. The secondary task is to learn a common repr esentation where the train and test domains cannot be distinguished. By using a gradient r eversal layer , the gradients coming from the domain classifier are used to bring the source and target domain r epresentations closer . W e show that exploiting unlabeled data consistently leads to better emotion r ecognition performance across all emotional dimensions. W e visualize the effect of adversarial training on the feature representation across the pr oposed deep learning ar chitecture. The analysis shows that the data repr esentations for the train and test domains conver ge as the data is passed to deeper layers of the network. W e also evaluate the difference in perf ormance when we use a shallow neural network v ersus a deep neural netw ork (DNN) and the effect of the number of shared lay ers used by the task and domain classifiers. Index T erms —Speech emotion recognition, adversarial train- ing, unlabeled adaptation of acoustic emotional models. I . I N T RO D U C T I O N I N many practical applications for speech emotion recogni- tion systems, the testing data (target domain) is dif ferent from the labeled data used to train the models (source domain). The mismatch in data distribution leads to a performance degradation of the trained models [1]–[5]. Therefore, it is vital to de velop more robust systems that are more resilient to changes in train and test conditions [6]–[9]. One approach to ensure that models perform well on the target domain is to use training data drawn from the same distribution. Ho wev er , this approach can be expensi ve, since it requires enough data with emotional labels to build models specific to a new target domain. A more practical approach is to use av ailable labeled data from similar domains along with unlabeled data from the M. Abdelwahab and C. Busso are with the Department of Elec- trical and Computer Engineering, The Univ ersity of T exas at Dallas, Richardson TX, 75013 USA e-mail: Mohammed.Abdel-W ahab@utdallas.edu; busso@utdallas.edu Manuscript recei ved March 26, 2018; revised xxx xx, 2018. sou rce target training testing Fig. 1: Formulation of the problem of data mismatch between train (source domain) and test (target domain) datasets. Our solution uses unlabeled data from the target domain to reduce the differences between domains. target domain, creating models that generalize well to the new testing conditions without the need to annotate extra data with emotional labels. This study proposes an elegant solution for the problem of mismatch in train-test data distributions based on domain adversary training. W e formulate the machine-learning problem as follows. W e have a sour ce domain(s) with annotated emotional data, which is used to train the models, and a large targ et domain with unlabeled data (see Fig. 1). The testing data come from the tar get domain. Due to the prohibitiv e cost of annotating new data e very time we change the target domain and the abundance of unlabeled data, we aim to use the unlabeled target data to e xtract useful information, reducing the dif- ferences between source and target domains. The envisioned system generalizes better and is more robust by maximizing the performance using a shared data representation for source and tar get domains. The ke y principle in our approach is to find a consistent feature representation for the source and target domains. Common approaches to address this problem include feature transformation methods, where the representation of the source data is mapped into a representation that resembles the features in the target domain [10], and finding a common representation between the domains, such that the features are inv ariant across domains [11]–[13]. The common domain- in v ariant features do not necessarily contain useful information about the main task. Therefore, it is vital to constrain the learned common feature representation to ensure that it is discriminativ e with respect to the main task. This paper explores the idea of finding a common repre- sentation between the source and target domains, such that data from the domains become indistinguishable while main- taining the critical information used in emotion recognition. This work is inspired by the work of Ganin et al. [14], IEEE TRANSA CTIONS ON A UDIO, SPEECH AND LANGU A GE PR OCESSING, V OL. XX, NO. XX, MARCH 2018 2 which proposed training an adversarial multitask network. The approach searches the feature space for a representation that accurately describes the data from either domain, containing the rele vant information to accurately classify the main task, in our study , the prediction of emotional attributes (arousal, valence, and dominance). The discriminative and domain- in v ariant features are learned by aligning the data distributions from the domains through back-propagation. This approach allows our framew ork to use unlabeled target data to learn a flexible representation. This paper sho ws that adversarial training using unlabeled training data benefits emotion recognition. By using the abun- dant unlabeled target data, we gain on average 27.3% relativ e improv ement in concor dance corr elation coefficient (CCC) compared to just training with the source data. W e e v aluate the effect of adversarial training by visualizing the similarity of the data representation learned by the network from both domains. The visualization shows that adversarial training aligns the data distributions as expected, reducing the gap between source and target domains. The study also sho ws the effect of the number of shared layers between the domain classifier and the emotion predictor on the performance of the system. The size of the source domain is an important factor that determines the optimal number of shared layers in the network. This nov el frame w ork for emotion recognition provides an appealing approach to ef fecti vely le verage unlabeled data from a ne w domain, generalizing the models and improving the classification performance. This paper is or ganized as follows. Section II discusses previous work on speech emotion recognition, with emphasis on frameworks that aim to reduce the mismatch between train and test datasets. Section III presents our proposed model, providing the motiv ation and the details of the proposed frame- work. Section IV presents the experiment ev aluation including the databases, network structure and acoustic features. Section V presents the experimental results and the analysis of the main findings. Section VI finalizes the study with conclusions and future research directions. I I . R E L A T E D W O R K The ke y challenge in speech emotion recognition is to build classifiers that perform well under various conditions. The cross-corpora ev aluation in Shami and V erhels [15] demon- strated the drop in classification performance observed when training on one emotional corpus and testing on another . Other studies have shown similar results [5], [16]–[18]. Sev eral approaches hav e been proposed to solve this problem. Shami and V erhels [15] proposed to include more v ariability in the training data by merging emotional databases. They demon- strated that it is possible to achieve classification performance comparable to within-corpus results. More recently , Chang and Scherer [19] sho wed that data from other domains can impro ve the within-corpus performance of a neural network. They employed deep convolutional generative adversarial network (DCGAN) to extract and learn useful feature representation from unlabeled data from a different domain. This led to better generalization compared to a model that did not make use of unlabeled data. The main approach to attenuate the mismatch between train and test conditions is to minimize the dif ferences in the feature space between both domains. Zhang et al. [20] sho wed that by separately normalizing the features of each corpus, it is possible to minimize cross-corpus variability . Hassan et al. [21] increased the weight of the train data that matches the test data distrib ution by using kernel mean matching (KMM), K ullbac k-Leibler importance estimation pr ocedur e (KLEIP), and unconstrained least-squar es importance fitting (uLSIF). Zong et al. [8] used least square r e gr ession (LSR) to mitigate the projected mean and cov ariance differences between source data and unlabeled target samples while learning the regression coefficient matrix. Because the learned coef ficient matrix de- pends on the samples selected from the target domain, multiple matrices were estimated and used to test new samples. Each matrix was used to predict an emotional label for a test sample, combining the results with the majority v ote rule. Studies ha ve also explored mapping both train and test domains to a common space, where the feature representation is more robust to the v ariations between the domains. Deng et al. [11] used auto-encoders to find a common feature representation across the domains. They trained an auto- encoder such that it minimized the reconstruction error on both domains. Building upon this work, Mao et al. [22] proposed to learn a shared feature representation across domains by constraining their model to share the class priors across domains. Sagha et al. [23], also moti v ated by the work of Deng et al. [11], used principal component analysis (PCA) along with kernel canonical corr elation analysis (KCCA) to find vie ws with the highest correlation between the source and target corpora. First, they used PCA to represent the feature space of the source and target data. Th e n, the features for the source and target domains were projected using the PCA in both domains. Finally , they used KCCA to select the top N dimensions that maximized the correlation between the views. Inspired by univ ersum learning where unlabeled data is used to regularize the training process for support vector machine (SVM), Deng et al. [24] proposed adding an univ ersum loss to the reconstruction loss of an auto-encoder . The added loss function was defined as the addition of the L 2 -margin loss and the -insensitive loss, making use of both labeled and unlabeled data. This approach aimed to learn auto-encoder classifier has lo w reconstruction and classification errors on both domains. Song et al. [25] proposed a couple of methods based on non- ne gative matrix factorization (NMF) that utilized data from both train and test domains. The proposed methods aimed to represent a matrix formed by data from both domains as two non-negati v e matrices whose product is an approximation of the original matrix. The factorization was regularized by max- imum mean discr epancy (MMD) to ensure that the differences in the feature distributions of the two corpora were minimized. The proposed methods aim to learn a robust low dimensional feature representation using either unlabeled data or labels as hard constraints on the problem. Abdelwahab and Busso [6] proposed creating an ensemble of classifiers, where each classifier focuses on a dif ferent feature space (each classifier maximized the performance for a giv en emotion category). The IEEE TRANSA CTIONS ON A UDIO, SPEECH AND LANGU A GE PR OCESSING, V OL. XX, NO. XX, MARCH 2018 3 features were selected over the labeled data from the tar get domain obtained with activ e learning. This semisupervised approach learned discriminant features for the target domain, increasing the robustness against shift in the data distributions between domains. Instead of finding a common representation between do- mains, Deng et al. [26] trained a sparse auto-encoder on the target data and used it to reconstruct the source data. This approach used feature transformation in a way that e xploits the underlying structure in emotional speech learned from the target data. Deng et al. [27] used two denoising auto-encoders. The first auto-encoder was trained on the tar get data and the second auto-encoder was trained on the source data, but it was constrained to be close to the first auto-encoder . The second auto-encoder was then used to reconstruct the data from both source and target domains. Our proposed approach takes an innov ati ve formulation with respect to previous work relying on domain adversarial neural network (D ANN) [14]. While Shinohara [28] sho wed that the use of DANN can increase the robustness of a automatic speec h r ecognition (ASR) system against certain types of noise, this framework has not been used for speech emotion recognition, which is an important contribution as this framew ork can reduce the mismatch between train and test sets in a principled way . D ANN relies on adv ersarial training for domain adaptation to learn a flexible representation during the training of the emotion classifier . As the training data changes, both the emotion and domain classifiers readjust their weights to find the new representation that satisfies all conditions. The domain classifier can be considered as a regularizer that prev ents the main classifier from o ver -fitting to the source domain. The final learned representation performs well on the tar get domain without sacrificing the performance on the source domain. I I I . P RO P O S E D A P P R OAC H A. Motivation W e present an unsupervised approach to reduce the mis- match between source and target domains by creating a discriminativ e feature representation that lev erages unlabeled data from the target domain. W e aim to learn a common representation between the source and target domains, where samples from both domains are indistinguishable to a domain classifier . This approach is useful because all the kno wledge learned while training the classifier on the source domain is directly applicable to the target domain data. W e learn the representation by using a gradient re versal layer where the gradient produced by the domain classifier is multiplied by a ne gati ve v alue when it is propagated back to the shared layers. Changing the sign of the gradient causes the feature representation of the samples from both domains to con verge, reducing the gap between domains. Ideally , the performance of the domain classifiers should be at random le v el where both domains “look” the same. When such a representation is learned, the data distributions of both domains are aligned. This approach leads to a large performance improv ement in the tar get domain, Fig. 2: Architecture of the domain adversarial neural network (D ANN) proposed for emotion recognition. The network has three parts: a feature representation common to both tasks, a task classifier layer , and a domain classifier layer . as demonstrated by our experimental e valuation (see Section V). A key feature of this framework is that it is unsupervised, since it does not require labeled data from the target domain. Howe ver , this framework would continue to be useful when labeled data from the target domain is av ailable, working as a semi-supervised approach. B. Domain Adversarial Neural Network for Emotion Recog- nition Ganin et al. [14], inspired by the recent work on genera- tive adversarial networks (GAN) [29], proposed the domain adversarial neural network (D ANN). The network is trained using labeled data from the source domain and unlabeled data from the target domain. The network learns two classifiers: the main classification task, and the domain classifier , which determines whether the input sample is from the source or target domains. Both classifiers share the first few layers that determine the representation of the data used for classification. The approach introduced a gradient rev ersal layer between the domain classifier and the feature representation layers. The layer passes the data during forward propagation and in verts the sign of the gradient during backward propagation. The network attempts to minimize the task classification error and find a representation that maximizes the error of the domain classifier . By considering these two goals, the model ensures a discriminative representation for the main recognition task that makes the samples from either domain indistinguishable. Figure 2 sho ws an example structure of the D ANN network. The network is fed labeled source data and unlabeled tar get data in equal proportions. In our formulation, we propose to predict emotional attribute descriptors as the primary goal. W e train the primary recognition task with the source data, for which we have emotional labels. For the domain classifier, IEEE TRANSA CTIONS ON A UDIO, SPEECH AND LANGU A GE PR OCESSING, V OL. XX, NO. XX, MARCH 2018 4 we train the classifier with data from the source and tar get domains. Notice that the domain classifier does not require emotional label, so we can rely on unlabeled data from the target domain. The classifiers are trained in parallel. The network’ s objectiv e is defined as: E ( θ f , θ y , θ d ) = 1 n n X i =1 L i y ( θ f , θ y ) − λ 1 n n X i =1 L i d ( θ f , θ d ) + 1 m m X i =1 L i d ( θ f , θ d ) (1) where θ f represents the parameters of the shared layers pro- viding the regularized feature representation, θ y represents the parameters of the layers associated with the main prediction task, and θ d represents the parameters of the layers of the domain classifier ( n is the number of labeled training samples, m is the number of unlabeled training samples). The optimiza- tion process consists of two loss functions. L i y is the prediction loss for the main task, and L i d is the domain classification loss. The prediction loss and the domain classification loss compete against each other in an adversarial manner . The parameter λ is a regularization multiplier that controls the tradeoff between the losses. This is a minimax problem. It attempts to find a saddle point parametrized by ˆ θ f , ˆ θ y , ˆ θ d , ( ˆ θ f , ˆ θ y ) = arg min θ f ,θ y E ( θ f , θ y , ˆ θ d ) (2) ˆ θ d = arg max θ d E ( ˆ θ f , ˆ θ y , θ d ) (3) At the saddle point, the classification loss on the source domain is minimized and the domain classification loss is maximized. The maximization is achiev ed by introducing a gradient re versal layer that changes the sign of the gradient going from the domain classification layers to the feature representation layers (see white layer in Fig. 2). The updates taken on the feature representation parameters are in opposite direction to the gradient. W ith this approach, stochastic gradi- ent descent tries to make the features similar across domains, so what is learned from the source domain remains ef fecti ve for the target domain without loss in performance. The simple concept of choosing a representation that con- fuses a competent domain classifier leads to models that perform better in the target domain without impacting the performance in the source domain. This approach is particu- larly useful for emotion recognition, as most annotated corpora come from studio settings that greatly dif fers from real world testing conditions. This unsupervised approach uses av ailable unlabeled data to align the distributions of both domains. The aligned distributions lead to a common representation, causing the domain classifier’ s performance to drop to random chance le vels. The common indistinguishable representation retains discriminati ve information learned during the training of the models with data from the source domain. W e improve the classifier’ s performance on the target domain without having to collect ne w annotated data. This is an important contribution in this field, taking us one step closer to ward robust speech emotion classifiers that generalize well in most testing conditions. I V . E X P E R I M E N T A L E V A L UAT I O N W e define the main task as a regression problem to esti- mate the emotional content con v eyed in speech described by the emotional attributes arousal (calm versus activ ated), va- lence (negativ e versus positi ve), and dominance (weak versus strong). This section describes the databases (Section IV -A), the acoustic features (Section IV -B) and the specific network structures (Section IV -C) used in the experimental ev aluation. A. Emotional Databases The experimental ev aluation consider a multi-corpus setting with three databases. The source domain (test set) corre- sponds to two databases: the USC-IEMOCAP [30] and MSP- IMPR O V [31] corpora. The target domain corresponds to the MSP-Podcast [32] database. 1) The USC-IEMOCAP Corpus: The USC-IEMOCAP database is an audiovisual corpus recorded from ten actors during dyadic interactions [30]. It has approximately 12 hours of recordings with detailed motion capture information care- fully synchronized with audio (this study only uses the audio). The goal of the data collection was to elicit natural emotions within a controlled setting. This goal was achieved with two elicitation framew orks: emotional scripts, and improvisation of hypothetical scenarios. These approaches allowed the actors to express spontaneous emotional beha viors dri v en by the context, as opposed to read speech displaying prototypical emotions [33]. Sev eral dyadic interactions were recorded and manually segmented into turns. Each turn was annotated with emotional labels by at least two ev aluators across emo- tional attributes (valence, arousal, dominance). Dimensional attributes take integer values that range from one to fiv e. The dimensional attrib ute of an utterance is the average of the values gi ven by the annotators. W e linearly map the scores between − 3 and 3. 2) The MSP-IMPR O V Corpus: The MSP-IMPR O V database is a multimodal emotional database recorded from actors interacting in dyadic sessions [31]. The recordings were carefully designed to promote natural emotional beha viors, while maintaining control over lexical and emotional contents. The corpus relied on a novel elicitation scheme, where two actors improvised scenarios that lead one of them to utter target sentences. For each of these target sentences, four emotional scenarios were created to contextualize the sentence to elicit happy , angry , sad and neutral reactions, respecti vely . The approach allows the actor to express emotions as dictated by the scenarios, avoiding prototypical reactions that are characteristic of other acted emotional corpus. Busso et al. [31] showed that the tar get sentences occurring within these improvised dyadic interactions were perceived more natural than read renditions of the same sentences. The MSP-IMPR O V corpus includes not only the target sentences, but also other sentences during the improvisations that led one of the actors to utter the tar get sentence. It also includes the natural interactions between the actors during the breaks. IEEE TRANSA CTIONS ON A UDIO, SPEECH AND LANGU A GE PR OCESSING, V OL. XX, NO. XX, MARCH 2018 5 The corpus consists of 8,438 turns of emotional sentences recorded from 12 actors (over 9 hours). The sessions were manually segmented into speaking turns, which were an- notated with emotional labels using perceptual ev aluations conducted with crowdsourcing [34]. Each turn was annotated by at least fiv e e valuators, who annotated the emotional content in terms of the dimensional attributes arousal, v alence, and dominance. Dimensional attrib utes take integer v alues that range from one to five. The consensus label assigned to each speech turn is the av erage value of the scores provided by the ev aluators, which we linearly map between − 3 and 3. 3) The MSP-P odcast Corpus: The MSP-P odcast corpus is an extensi ve collection of natural speech from multiple speakers appearing in Creative Commons licensed recordings downloaded from audio-sharing websites [32]. Some of the key aspects of the corpus are the different conditions in which the recordings are collected, large number of speak- ers, and a large variety of natural content from spontaneous con v ersations con veying emotional behaviors. The audio was preprocessed removing portions that contain noise, music or ov erlapped speech. The recordings were then segmented into speaking turns creating a big audio repository with sentences that are between 2.75 seconds and 11 seconds. Emotional models trained with e xisting databases are then used to retrieve speech turns with tar get emotional content. The candidate segments were annotated with emotional labels using an improv ed v ersion of the cro wdsourcing framework proposed by Burmania et al. [34]. Each speech segment was annotated by at least fiv e raters, who provided scores for the emotional dimensions arousal, valence and dominance using sev en-likert scales. The consen- sus scores are the average scores assigned by the ev aluators, which are shifted such that they are in the range between − 3 and 3. The collection of this corpus is an ongoing ef fort. This study uses 14,227 labeled sentences. From this set, we use 4,283 labeled sentences coming from 50 speakers as our test set, which is consistently used across conditions. For the within corpus ev aluation (i.e., training and testing in the same domain), we define a dev elopment set with 1,860 sentences from 10 speakers, and a train set with the remainder of the corpus (8,084 sentences). This study also uses 73,209 unlabeled sentences from the audio repository of segmented speech turns. The unlabeled segments are used to train the domain classifier in the DANN approach. B. Acoustic F eatur es The acoustic features correspond to the set proposed for the INTERSPEECH 2013 Computational Paralinguistics Chal- lenge (ComParE) [35]. This feature set includes 6,373 acoustic features extracted at the sentence level (one feature vector per sentence). First, it extracts 65 frame-by-frame low-level descriptors (LLDs) which includes various acoustic character- istics such as Mel-frequency cepstral coefficients (MFCCs), fundamental frequency , and energy . The externalization of emotion is conv eyed through different aspects of speech production so including these LLDs is important to capture emotional cues. After estimating LLDs, a list of functions are estimated for each LLD, which are referred to as high-level descriptors (HLD) features. These HLDs include standard deviation, minimum, maximum, and ranges. The acoustic features are extracted using OpenSMILE [36]. W e separately normalize the features from each domain (i.e., corpus) to have zero mean and a unit standard devi- ation. The mean and the variance of the data is calculated considering only the v alues of the features within the 5% and 95% quantiles to avoid outliers ske wing the values. After normalization, we ignore any v alue greater than 10 times its standard deviation by setting their v alues to zero. C. Network Structur e As discussed in Section III-B, the DANN approach has three main components: the domain classifier layers, task classifier layers, and feature representation layers. The domain classifier layers are implemented with two layers across all the experimental ev aluation. The task classifier layers are also implemented with two layers, except for the shallow network described belo w . The number of layers in the featur e r epr esentation layers is a parameter of the network that is set on the dev elopment set. W e consider dif ferent number of shared layers, ev aluating the performance of the system with one, two, three or four layers. W e also study whether a simple shallow network can achiev e similar performance compared to the deep network. In the shallo w network, the task classifier layer and the feature r epr esentation layer are implemented with one layer each. W e implement the domain classifier layer with two layers. D. Baseline Systems W e establish two baselines. The first baseline is a network trained and v alidated only on the source data. This condition creates a mismatch between the train and test conditions. The second baseline corresponds to within corpus e v aluations, where the models are trained and tested with data from the target domain. This model assumes that training data from the target domain is av ailable, so it corresponds to the ideal condition. The parameters of the networks are optimized using the development set. The baselines are implemented with similar architectures, serving as a fair comparison with the proposed method (e.g., number of layers, number of nodes). The key difference with the D ANN models is the lack of the domain classification layers , where the feature representation layers only consider the primary classification task. E. Implementation W e train the networks using K eras [37] with T ensorflow as back-end [38]. W e use batch normalization and dropout. The dropout rates are p =0.2 for the input layer and p =0.5 for the rest of the layers. W e further regularize the models using max-norm on the weights of value four and a clip norm on the gradient of v alue ten. The loss function used for the main regression task is the mean squar e err or (MSE). The loss function for the domain classification task is the categorical cross-entropy . W e use Adam as an optimizer with a learning IEEE TRANSA CTIONS ON A UDIO, SPEECH AND LANGU A GE PR OCESSING, V OL. XX, NO. XX, MARCH 2018 6 rate of 5 e − 4 [39]. W e train the models for 100 epochs with a batch size of 256 sentences. A parameter of the D ANN model is λ in Equation 1, which controls the tradeoff between the task and domain classification losses. W e follow a similar approach to the one proposed by Ganin et al. [14], where λ is initialized equal to zero for the first ten training epochs. Then, we slowly increase its value until reaching λ = 1 by the end of the training. W e train each model twenty times to reduce the effect of initialization on the performance of the classifiers. W e report the av erage performance across the trails. In adversarial training, we need unlabeled data to train the domain classifier . W e randomly select samples from the unlabeled portion of the target domain to be fed to the domain classifier . The number of selected samples from the audio repository of unlabeled speech turns is equal to the number of samples in the source domain, keeping the balance in the training set of the domain classification task. V . E X P E R I M E N T A L R E S U L T S The performance results for the baseline models and the D ANN models are reported in terms of the r oot mean squar e err or (RMSE), P earson’ s correlation coefficient (PR), and con- cor dance corr elation coefficient (CCC) between the ground- truth labels and the estimated values. While we presented PR and RMSE, the analysis focus on CCC as the performance metric, which combines mean square err or (MSE) and PR. CCC is defined as: ρ c = 2 ρσ x σ y σ 2 x + σ 2 y + ( µ x − µ y ) 2 (4) where ρ is the Pearson’ s correlation coefficient, σ x and σ y , and µ x and µ y are the standard deviations and means of the predicted score x and the ground truth label y , respecti vely . A. Number of Layers F or the Shar ed F eatur e Repr esentation W e first study the ef fect of the number of shared layers between the domain classifier and the primary regression task on the D ANN model’ s performance (e.g., feature r ep- r esentation layers in Fig. 2). The domain and task classifier layers are implemented with tw o layers each. W e vary the number of shared layers between the classifiers and observe how the changes in feature representation af fect the regression performance. This ev aluation is conducted exclusi v ely on the validation set of the target domain (e.g., MSP-Podcast corpus). T able I shows the average RMSE, PR, and CCC for the models trained with one, two, three and four shared layers. For arousal, we consistently observ e better performance (lo wer RMSE and higher PR and CCC) with one shared layer between the domain and task classifiers. For the CCC values, the differences are statistically significant for all the cases, except when the source domain is the MSP-IMPRO V corpus and the D ANN model is implemented with two layers (one-tailed t-test ov er the a verage across the twenty trails, asserting significance if p -value < 0 . 05 ). The performance degrades as more shared layers are added. For valence and dominance, the number of shared layers that provides the best performance varies from one corpus to another . In most cases, tw o or three shared layers provide the best performance. Based on these results on the validation set, we set the number of shared layers for the feature representation networks to one for arousal, two for valence and three for dominance. T ABLE I: Performance of D ANN frame work implemented with different number of shared layers for the domain and task classifiers [ Iem : USC-IEMOCAP corpus, Imp : MSP-IMPRO V corpus, All : All corpora combined] Arousal V alence Dominance src n RMSE PR CCC RMSE PR CCC RMSE PR CCC Iem 1 1.26 .412 .365 1.57 .140 .135 1.30 .151 .124 2 1.29 .379 .332 1.64 .152 .144 1.27 .160 .135 3 1.32 .353 .305 1.67 .150 .140 1.27 .217 .181 4 1.31 .347 .296 1.67 .147 .135 1.27 .192 .161 Imp 1 1.62 .497 .284 1.58 .171 .137 0.80 .485 .448 2 1.57 .506 .303 1.47 .203 .176 0.82 .514 .476 3 1.71 .399 .218 1.48 .202 .173 0.87 .478 .403 4 1.73 .382 .202 1.43 .210 .193 0.85 .442 .383 All 1 1.37 .432 .341 1.56 .181 .165 1.01 .395 .356 2 1.41 .396 .313 1.56 .173 .160 1.05 .345 .309 3 1.46 .369 .286 1.58 .183 .170 1.06 .339 .308 4 1.45 .371 .282 1.56 .161 .149 1.06 .307 .270 B. Re gression P erformance of the DANN Model This section presents the re gression results achie v ed by the D ANN model, and the baseline models. T able II lists the performance for the within-corpus e v aluation where the models are trained and tested with data from the MSP-Podcast corpus (referred to as targ et on the table), and the cross- corpus e v aluations, where the models are trained with other corpora (referred to as src on the table). These baseline results are compared with our proposed D ANN method (referred to as dann on the table). The results are tabulated in terms of emotional dimensions and networks structures. These v alues are the av erage of twenty trails to account for different initializations and set of unlabeled data used to train the D ANN models. For the rows denoted “ All Databases”, we combine all the source domain together (IEMOCAP and MSP- IMPR O V corpora), treating them as a single source domain. T o determine statistical differences between the src and dann conditions, we use the one-tailed t-test over the twenty trails, asserting significance if p -value < 0 . 05 . W e highlight in bold when the dif ference between these conditions is statistically significant. T o visualize the results in T able II, we create figures showing the a verage performance under different conditions (Figs. 3-6). W e use statistical significance tests to compare different conditions (values obtained from T able II). W e test the hypothesis that population means for matched conditions are dif ferent using one-tailed z-test. W e assert significance if p -value < 0 . 05 . W e use an asterisk in the figures to indicate if there is a statistically significant difference relati ve to the baseline model trained with the source domain. Figure 3 shows the a verage concordance correlation coef- ficient across emotional dimensions, training sources, trails, and networks structures (three emotional dimensions × twenty trails × three sources × five structures = 900 matched conditions). The average performance for the within-corpus IEEE TRANSA CTIONS ON A UDIO, SPEECH AND LANGU A GE PR OCESSING, V OL. XX, NO. XX, MARCH 2018 7 T ABLE II: Performance of the proposed DANN approach across different structures and emotional dimensions. T raining Data Arousal Source Approach deep shallow RMSE PR CCC RMSE PR CCC MSP-Podcast target 0.67 .786 .776 0.66 .787 .767 USC-IEMOCAP src 1.01 .515 .452 1.00 .510 .434 dann 1.10 .503 .489 1.07 .520 .503 MSP-IMPR O V src 1.57 .551 .267 1.53 .555 .263 dann 1.48 .607 .381 1.46 .614 .381 All Databases src 1.20 .496 .386 1.18 .506 .378 dann 1.18 .555 .499 1.18 .551 .486 T raining Data V alence Source Approach deep shallow RMSE PR CCC RMSE PR CCC MSP-Podcast target 1.08 .327 .294 1.03 .344 .283 USC-IEMOCAP src 1.30 .202 .198 1.19 .227 .207 dann 1.44 .218 .215 1.34 .267 .255 MSP-IMPR O V src 1.42 .142 .122 1.29 .154 .127 dann 1.43 .163 .161 1.37 .180 .178 All Databases src 1.33 .214 .201 1.16 .245 .228 dann 1.39 .299 .294 1.33 .272 .267 T raining Data Dominance Source Approach deep shallow RMSE PR CCC RMSE PR CCC MSP-Podcast target 0.57 .718 .697 0.57 .723 .704 USC-IEMOCAP src 0.95 .437 .393 0.87 .461 .426 dann 1.10 .437 .401 1.03 .497 .457 MSP-IMPR O V src 0.86 .563 .368 0.87 .520 .353 dann 0.89 .565 .456 0.88 .578 .472 All Databases src 0.85 .481 .418 0.81 .493 .437 dann 0.92 .526 .499 0.90 .550 .516 Fig. 3: A verage concordance correlation coef ficient across con- ditions. The DANN models provide significant improv ements ov er the baseline model trained with the source domain. ev aluation (target) is close to double the performance for the cross-corpus ev aluations (source). This result demonstrates the importance of minimizing the mismatch between train and test conditions in emotion recognition. The figure shows that the proposed DANN approach greatly improv es the performance, achieving 6.6% gain compared to the systems trained with the source domains. As highlighted by the asterisk, the im- prov ement is statistically significant. The proposed approach reduces the gap between within-corpus and cross-corpus emo- tion recognition results, effecti vely using unlabeled data from the target domain. Fig. 4: A verage concordance correlation coefficient across conditions for each emotional dimension. Fig. 5: A verage concordance correlation coefficient across condition for each source domain. The solid line represents the within corpus performance. Figure 4 shows the a verage concordance correlation coef- ficient for each emotional dimension (twenty trails × three sources × five structures = 300 matched conditions). On av erage, the figure shows that models trained using DANN consistently outperform models trained with the source data. The asterisk denotes that the dif ference is statistically sig- nificant across all emotional dimensions. The relative im- prov ements o ver the source models are 22.8% for arousal, 33.4% for valence and 15.5% for dominance. In general, the values for CCC are lower for valence, validating findings from previous studies, which indicated that acoustic features are less discriminativ e for this emotional attribute [40]. Figure 5 sho ws the av erage concordance correlation co- efficient per source domain (three emotional dimensions × twenty trails × fiv e structures = 300 matched conditions). The figure shows the within-corpus performance (target) with a solid horizontal line. The results consistently show significant improv ements when using DANN. The relativ e improvements in performance ov er training with the source domain are 7.7% for the USC-IEMOCAP corpus, 36.4% for the MSP-IMPR O V corpus, and 25% when we combine all the corpora. Figure 5 also shows that, on a verage, combining all the sources into one domain improv es the performance of the systems in recognizing emotions. Adding v ariability during the training of the models is important, as also demonstrated by Shami and V erhels [15]. D ANN models also benefit from adding v ari- IEEE TRANSA CTIONS ON A UDIO, SPEECH AND LANGU A GE PR OCESSING, V OL. XX, NO. XX, MARCH 2018 8 Fig. 6: A verage concordance correlation coefficient across conditions for deep and shallow structures. ability . By lev eraging the added data representations, DANN models are able to find a common representation between the domains without sacrificing the critical features rele vant for learning the primary task. Figure 6 compares the performance for deep and shal- low networks (see Section IV -C). The figure summarizes the results for the within-corpus e v aluations (target), cross- corpus ev aluations (source) and with our proposed D ANN model (three emotional dimensions × twenty trails × three sources = 180 matched conditions). For the target models, we observe significant improvements when using deep structures ov er shallow structures. Howe ver , the differences are not statistically significant for the source and D ANN models. (a) Feature representation using the D ANN model (b) Feature representation using the baseline source model Fig. 7: Feature representation at the last shared layer for arousal models trained on USC-IEMOCAP corpus. The figures are created with the t-SNE toolkit. C. Data Repr esentation The results in T ables I and II demonstrate the benefits of using the proposed D ANN framework. This section aims to understand the key aspect of the D ANN approach by visu- alizing the feature representation created during the training process. W e use the t-SNE toolkit [41] to create 2D projections of the feature distributions at different layers of the networks. Figure 7 shows the distributions of the data from the source domain (blue circles) and the target domain (red crosses) after projecting them in the feature representation created by two models. This example corresponds to the models trained for arousal using the USC-IEMOCAP corpus as the source domain (as explained in Section V -A, the DANN model for arousal has only one shared layer as a feature representation). Figure 7a shows the data representation at the shared layer of the D ANN model. Figure 7b shows the data represen- tation at the equiv alent layer of the DNN model trained with the source domain (i.e., the USC-IEMOCAP database). By using adversarial domain training, the feature distrib ution for samples from both domains are almost indistinguishable, demonstrating that the proposed approach is able to find a common representation. W ithout adversarial domain training, in contrast, there are large regions in the feature space where it is easy to separate samples from the source and tar get domains. Figure 7b suggests the presence of a source-tar get mismatch which affects the performance of the emotion classifier . W e also explore the feature representation when the DANN model is trained with four shared layers using the t-SNE toolkit. The objecti ve of this ev aluation is to visualize the distribution of the data in each of the shared layers. This ev aluation is implemented using the models for dominance, using the MSP-IMPRO V corpus as the source domain. Figures 8a-8d show the changes in the data representation for each of the four shared layers in the D ANN model. At the first layer (Fig. 8a), the feature representation for the source data (blue circles) and the target data (red crosses) are dissimilar enough for the domain classifier to be able to distinguish them. While the difference between domains in the feature representation has decreased at the second layer (Fig. 8b), there are still some regions dominated by samples from one of the two domains. At the third layer (Fig. 8c), the feature representation of the domains are similar enough to confuse the domain classifier . The common representation is maintained in the fourth layer (Fig. 8d), where the data from the target domain is indistinguishable from the data from the source domain. This final representation is used by the emotion regression to predict the emotional state of the target speech. For comparison, we also trained a baseline model with six layers, matching the combined number of shared and task classifier layers in the D ANN model. Figures 8e-8h sho w the feature representation of the corresponding first four layers of this model. In the D ANN model, the data representation of the samples from the source and target domains become more similar in deeper layers. This trend is not observed in the model trained with only the source data. The DANN model ef fecti vely reduces the mismatch in the feature representation across domains, which leads to significant improvements in the re gression models. IEEE TRANSA CTIONS ON A UDIO, SPEECH AND LANGU A GE PR OCESSING, V OL. XX, NO. XX, MARCH 2018 9 (a) Layer 1 - D ANN (b) Layer 2 - D ANN (c) Layer 3 - D ANN (d) Layer 4 - D ANN (e) Layer 1 - Source (f) Layer 2 - Source (g) Layer 3 - Source (h) Layer 4 - Source Fig. 8: Feature representation at each layer using the D ANN model, and the baseline DNN trained with the source domain. The figures are created with the t-SNE toolkit. The example corresponds to models for dominance with four shared layers, using the MSP-IMPR O V corpus as the source domain. Figures (a)-(d) report the results for D ANN model. Figures (e)-(h) report the results for DNN trained with the source domain. V I . C O N C L U S I O N S This study proposed an appealing framework for emotion recognition that exploits av ailable unlabeled data from the target domain. The proposed approach relies on domain ad- versarial neural network (D ANN), which creates a fle xible and discriminant feature representation that reduces the gap in the feature space between the source and tar get domains. By using adversarial training, we learned domain in v ariant representations that can ef fectiv ely discriminate the primary regression task. The model aims to find a balanced repre- sentation that aligns the domain distributions, while retaining crucial information for the primary regression task. The pro- posed adversarial training leads to significant improvements in the emotion recognition classifier’ s performance ov er models exclusi v ely trained with data from the source domain, which was demonstrated by the experimental ev aluation. W e visual- ized the data representation of both domains by projecting the features into the shared layers of the proposed D ANN model. The results showed that the model con ver ged to a common representation, where the source and tar get domains became indistinguishable. The experimental ev aluation also showed that the amount of labeled data from the source domain plays a small role in determining how many shared layers are needed between the domain and regression tasks. Since the number of shared layers has a strong impact on the system’ s performance, it is vital to identify the optimal number of shared layers, given a specific source domain. One challenging aspect in using the proposed approach is the difficulty of training adversarial networks. For example, Shinohara [28] noted that in ASR problems, the improv ements of D ANN were large for some types of noises, but less effecti ve for others. They suggested that tuning the param- eters could lead to better results. W e also observed that the framew ork failed to con ver ge for certain parameters, which is common in minimax problems. When properly trained, howe ver , this powerful framework can elegantly solve one of the most important problems in speech emotion recognition: reducing the mismatch between train and test domains. In the case of multiple sources, our approach seems to work well when multiple sources are combined, treating them as one. This approach forces the network to learn a representation that is common across all the source domains. W e hypothesize that a better approach is to use asymmetric transformations, where the model learns multiple possible representations for the test data, creating one representation for each source. During testing, the netw ork chooses the most useful repre- sentation for each data point. Another alternativ e approach is to transform the av ailable sources to match the target domains. Finally , this unsupervised approach can be easily extended to the cases where limited labeled data from the target domain is a v ailable (semi-supervised approach), creating a flexible framew ork to create emotion recognition systems that can generalize across domain. A C K N O W L E D G M E N T This study was funded by the National Science Foundation (NSF) CAREER grant IIS-1453781. R E F E R E N C E S [1] C. Busso, M. Bulut, and S.S. Narayanan, “T oward effecti ve automatic recognition systems of emotion in speech, ” in Social emotions in nature and artifact: emotions in human and human-computer interaction , J. Gratch and S. Marsella, Eds., pp. 110–127. Oxford Univ ersity Press, New Y ork, NY , USA, No vember 2013. [2] Y . Kim and E. Mo wer Provost, “Say cheese vs. smile: Reducing speech- related v ariability for facial emotion recognition, ” in ACM International Confer ence on Multimedia (MM 2014) , Orlando, FL, USA, November 2014, pp. 27–36. [3] D. V erveridis and C. Kotropoulos, “ Automatic speech classification to fiv e emotional states based on gender information, ” in European Signal Pr ocessing Confer ence (EUSIPCO 2004) , V ienna, Austria, September 2004, pp. 341–34. [4] T . V ogt and E. Andr ´ e, “Comparing feature sets for acted and spontaneous speech in view of automatic emotion recognition, ” in IEEE International Confer ence on Multimedia and Expo (ICME 2005) , Amsterdam, The Netherlands, July 2005, pp. 474–477. IEEE TRANSA CTIONS ON A UDIO, SPEECH AND LANGU A GE PR OCESSING, V OL. XX, NO. XX, MARCH 2018 10 [5] S. Parthasarathy and C. Busso, “Jointly predicting arousal, v alence and dominance with multi-task learning, ” in Interspeech 2017 , Stockholm, Sweden, August 2017, pp. 1103–1107. [6] M. Abdelwahab and C. Busso, “Ensemble feature selection for domain adaptation in speech emotion recognition, ” in IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP 2017) , New Orleans, LA, USA, March 2017, pp. 5000–5004. [7] M. Abdelwahab and C. Busso, “Incremental adaptation using active learning for acoustic emotion recognition, ” in IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP 2017) , New Orleans, LA, USA, March 2017, pp. 5160–5164. [8] Y . Zong, W . Zheng, T . Zhang, and X. Huang, “Cross-corpus speech emotion recognition based on domain-adaptive least-squares regression, ” IEEE Signal Processing Letters , vol. 23, no. 5, pp. 585–589, May 2016. [9] M. Abdelw ahab and C. Busso, “Supervised domain adaptation for emotion recognition from speech, ” in International Confer ence on Acoustics, Speech, and Signal Pr ocessing (ICASSP 2015) , Brisbane, Australia, April 2015, pp. 5058–5062. [10] T . Rahman and C. Busso, “ A personalized emotion recognition system using an unsupervised feature adaptation scheme, ” in International Confer ence on Acoustics, Speech, and Signal Pr ocessing (ICASSP 2012) , Kyoto, Japan, March 2012, pp. 5117–5120. [11] J. Deng, R Xia, Z. Zhang, Y . Liu, and B. Schuller , “Introducing shared- hidden-layer autoencoders for transfer learning and their application in acoustic emotion recognition, ” in International Confer ence on Acoustics, Speech, and Signal Processing (ICASSP 2014) , Florence, Italy , May 2014, pp. 4818–4822. [12] Y . Zhang, Y . Liu, F . W eninger, and B. Schuller , “Multi-task deep neural network with shared hidden layers: Breaking down the wall between emotion representations, ” in IEEE International Conference on Acoustics, Speech and Signal Pr ocessing (ICASSP 2017) , New Orleans, LA, USA, March 2017, pp. 4490–4494. [13] X. Glorot, A. Bordes, and Y . Bengio, “Domain adaptation for large-scale sentiment classification: A deep learning approach, ” in International confer ence on machine learning (ICML 2011) , Bellevue, W A, USA, June-July 2011, pp. 513–520. [14] Y . Ganin, E. Ustinov a, H. Ajakan, P . Germain, H. Larochelle, F . Lavio- lette, M. Marchand, and V . Lempitsky , “Domain-adversarial training of neural networks, ” Journal of Machine Learning Researc h , vol. 17, no. 59, pp. 1–35, April 2016. [15] M. Shami and W . V erhelst, “ Automatic classification of expressi veness in speech: A multi-corpus study , ” in Speaker Classification II , C. M ¨ uller , Ed., vol. 4441 of Lectur e Notes in Computer Science , pp. 43–56. Springer-V erlag Berlin Heidelberg, Berlin, Germany , August 2007. [16] A. Austermann, N. Esau, L. Kleinjohann, and B. Kleinjohann, “Fuzzy emotion recognition in natural speech dialogue, ” in IEEE International W orkshop on Robot and Human Interactive Communication , Nashville, TN, USA, August 2005, pp. 317–322. [17] B. Schuller , B. Vlasenko, F . Eyben, M. W ¨ ollmer , A. Stuhlsatz, A. W en- demuth, and G. Rigoll, “Cross-corpus acoustic emotion recognition: V ariances and strategies, ” IEEE T ransactions on Affective Computing , vol. 1, no. 2, pp. 119–131, July-Dec 2010. [18] L. V idrascu and L. Devillers, “ Anger detection performances based on prosodic and acoustic cues in several corpora, ” in Second International W orkshop on Emotion: Corpora for Researc h on Emotion and Affect, International conference on Language Resources and Evaluation (LREC 2008) , Marrakech, Morocco, May 2008, pp. 13–16. [19] J. Chang and S Scherer, “Learning representations of emotional speech with deep conv olutional generativ e adversarial networks, ” in IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP 2017) , Ne w Orleans, LA, USA, March 2017, pp. 2746–2750. [20] Z. Zhang, F . W eninger , M. W ollmer, and B. Schuller, “Unsuper- vised learning in cross-corpus acoustic emotion recognition, ” in IEEE W orkshop on A utomatic Speech Recognition and Understanding (ASRU 2011) , W aikoloa, HI, USA, December 2011, pp. 523–528. [21] A. Hassan, R. Damper, and M. Niranjan, “On acoustic emotion recognition: compensating for cov ariate shift, ” IEEE T r ansactions on Audio, Speech, and Language Pr ocessing , vol. 21, no. 7, pp. 1458–1468, July 2013. [22] Q. Mao, W . Xue, Q. Rao, F . Zhang, and Y . Zhan, “Domain adaptation for speech emotion recognition by sharing priors between related source and target classes, ” in IEEE International Conference on Acoustics, Speech and Signal Pr ocessing (ICASSP 2016) , Shanghai, China, March 2016, pp. 2608–2612. [23] H. Sagha, J. Deng, M. Gavryukov a, J. Han, and B. Schuller , “Cross lingual speech emotion recognition using canonical correlation analysis on principal component subspace, ” in IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP 2016) , Shanghai, China, March 2016, pp. 5800–5804. [24] J. Deng, X. Xu, Z. Zhang, S. Fr ¨ uhholz, and B. Schuller, “Universum autoencoder-based domain adaptation for speech emotion recognition, ” IEEE Signal Pr ocessing Letters , vol. 24, no. 4, pp. 500–504, April 2017. [25] P . Song, W . Zheng, S. Ou, X. Zhang, Y . Jin, J. Liu, and Y . Y u, “Cross- corpus speech emotion recognition based on transfer non-ne gativ e matrix factorization, ” Speech Communication , vol. 83, pp. 34–41, October 2016. [26] J. Deng, Z. Zhang, E. Marchi, and B. Schuller, “Sparse autoencoder- based feature transfer learning for speech emotion recognition, ” in Affective Computing and Intelligent Interaction (ACII 2013) , Geneva, Switzerland, September 2013, pp. 511–516. [27] J. Deng, Z. Zhang, F . Eyben, and B. Schuller, “ Autoencoder-based unsupervised domain adaptation for speech emotion recognition, ” IEEE Signal Pr ocessing Letters , vol. 21, no. 9, pp. 1068–1072, September 2014. [28] Y . Shinohara, “ Adversarial multi-task learning of deep neural networks for rob ust speech recognition, ” in Interspeec h 2016 , San Francisco, CA, USA, September 2016, pp. 2369–2372. [29] I. Goodfellow , J. Pouget-Abadie, M. Mirza, B. Xu, D. W arde-Farle y , S. Ozair , A. Courville, and Y . Bengio, “Generativ e adversarial nets, ” in Advances in neural information pr ocessing systems (NIPS 2014) , Montreal, Canada, December 2014, vol. 27, pp. 2672–2680. [30] C. Busso, M. Bulut, C.C. Lee, A. Kazemzadeh, E. Mower , S. Kim, J.N. Chang, S. Lee, and S.S. Narayanan, “IEMOCAP: Interacti ve emotional dyadic motion capture database, ” Journal of Language Resources and Evaluation , vol. 42, no. 4, pp. 335–359, December 2008. [31] C. Busso, S. Parthasarathy , A. Burmania, M. AbdelW ahab, N. Sadoughi, and E. Mower Provost, “MSP-IMPRO V: An acted corpus of dyadic interactions to study emotion perception, ” IEEE T ransactions on Affective Computing , vol. 8, no. 1, pp. 67–80, January-March 2017. [32] R. Lotfian and C. Busso, “Building naturalistic emotionally balanced speech corpus by retrie ving emotional speech from existing podcast recordings, ” IEEE T ransactions on Affective Computing , vol. T o appear , 2018. [33] C. Busso and S.S. Narayanan, “Recording audio-visual emotional databases from actors: a closer look, ” in Second International W orkshop on Emotion: Corpora for Resear ch on Emotion and Affect, International confer ence on Language Resources and Evaluation (LREC 2008) , Mar- rakech, Morocco, May 2008, pp. 17–22. [34] A. Burmania, S. Parthasarathy , and C. Busso, “Increasing the reliability of crowdsourcing ev aluations using online quality assessment, ” IEEE T r ansactions on Affective Computing , vol. 7, no. 4, pp. 374–388, October-December 2016. [35] B. Schuller , S. Steidl, A. Batliner , A. V inciarelli, K. Scherer , F . Ringev al, M. Chetouani, F . W eninger , F . Eyben, E. Marchi, M. Mortillaro, H. Salamin, A. Polychroniou, F . V alente, and S. Kim, “The INTER- SPEECH 2013 computational paralinguistics challenge: Social signals, conflict, emotion, autism, ” in Interspeech 2013 , Lyon, France, August 2013, pp. 148–152. [36] F . Eyben, M. W ¨ ollmer , and B. Schuller, “OpenSMILE: the Munich versatile and fast open-source audio feature extractor , ” in ACM Inter- national confer ence on Multimedia (MM 2010) , Florence, Italy , October 2010, pp. 1459–1462. [37] F . Chollet, “Keras: Deep learning library for Theano and T ensorFlow, ” https://keras.io/, April 2017. [38] M. Abadi, P . Barham, J. Chen, Z. Chen, A. Davis, J. Dean, M. Devin, S. Ghemawat, G. Irving, M. Isard, M. Kudlur , J. Levenberg, R. Monga, S. Moore, D.G. Murray , B. Steiner , P . T ucker , V . V asudevan, P . W arden, M. W icke, Y . Y u, and X. Zheng, “T ensorFlow: A system for lar ge-scale machine learning, ” in Symposium on Operating Systems Design and Implementation (OSDI 2016) , Sav annah, GA, USA, Nov ember 2016, pp. 265–283. [39] T . Dozat, “Incorporating Nesterov momentum into Adam, ” in W orkshop trac k at International Conference on Learning Representations (ICLR 2015) , San Juan, Puerto Rico, May 2015, pp. 1–4. [40] C. Busso and T . Rahman, “Un veiling the acoustic properties that describe the valence dimension, ” in Interspeec h 2012 , Portland, OR, USA, September 2012, pp. 1179–1182. [41] L. V an Der Maaten, “ Accelerating t-SNE using tree-based algorithms, ” Journal of machine learning resear c h , vol. 15, no. 1, pp. 3221–3245, October 2014.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment